使用LangChain开发Agent相较于其他语言来说可以节省不必要的工作量,就拿工具来举例,在LangChain中只需写好工具即可,调用模型时,LangChain自动将工具信息拿给模型
环境准备
开发LangChain依赖Python环境,版本和开发工具都有要求
python version >=3.13
pycharm version >= 2024.3.2 ,因为要集成UV虚拟环境,所以高版本工具才有支持
在项目中添加LangChain环境
bash
uv add langchain在项目中添加要集成的大语言模型依赖
这里采用deepseek,当然也有其他的模型依赖支持情况,比如langchain-openai langchain-ropic langchain-ollama等langchain集成页面
bash
uv add langchain-deepseek安装过后,在UV的配置依赖管理中可以看到当前的执行效果和依赖项
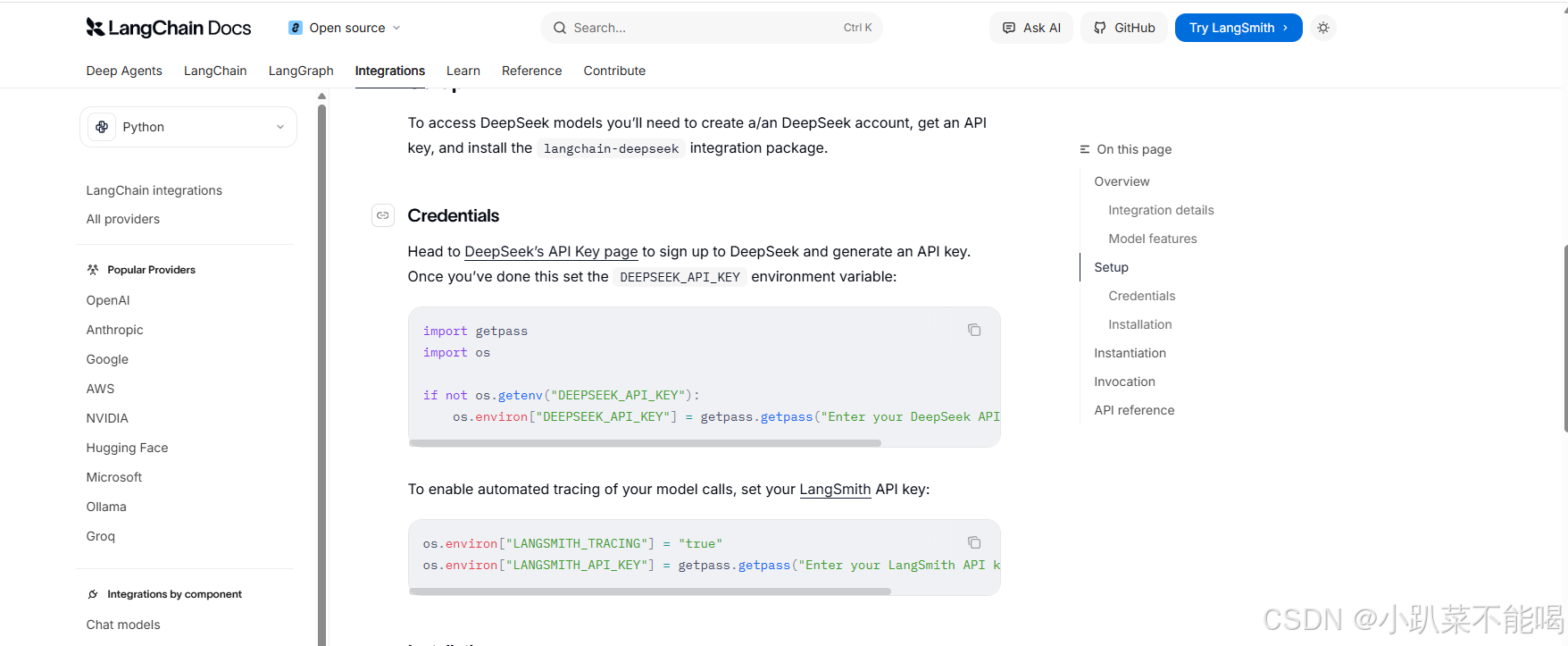
配置环境变量.env
这里的环境变量名称不是随意写的,需要参考langchain的官网进行写入,比如deepseek的env就要这样写DEEPSEEK_API_KEY
调用模型
.env文件如下所示,这里边的API_KEY经过加工,不可以直接使用
bash
DEEPSEEK_API_KEY=sk-80ad1wertwetrewrterwtb6调用模型python代码
python
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
load_dotenv()
# init_chat_model会根据前缀匹配模型,自动获取base_url,并从环境变量中获取api key
model = init_chat_model(model="deepseek-v4-pro",temperature=0.7)
# 阻塞式调用模型
#response=model.invoke("你是谁?")
#print(response)
# 流式调用模型 end="" 取消换行
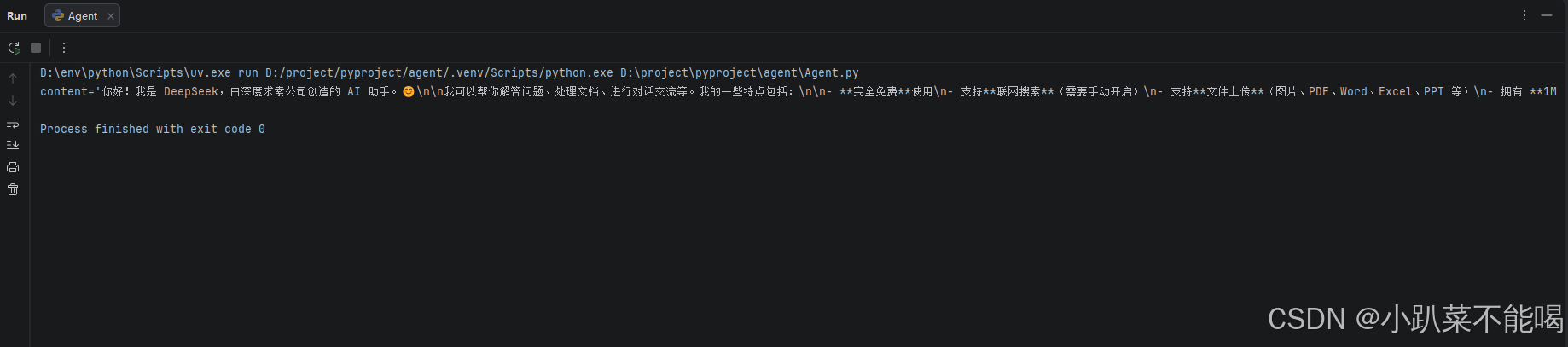
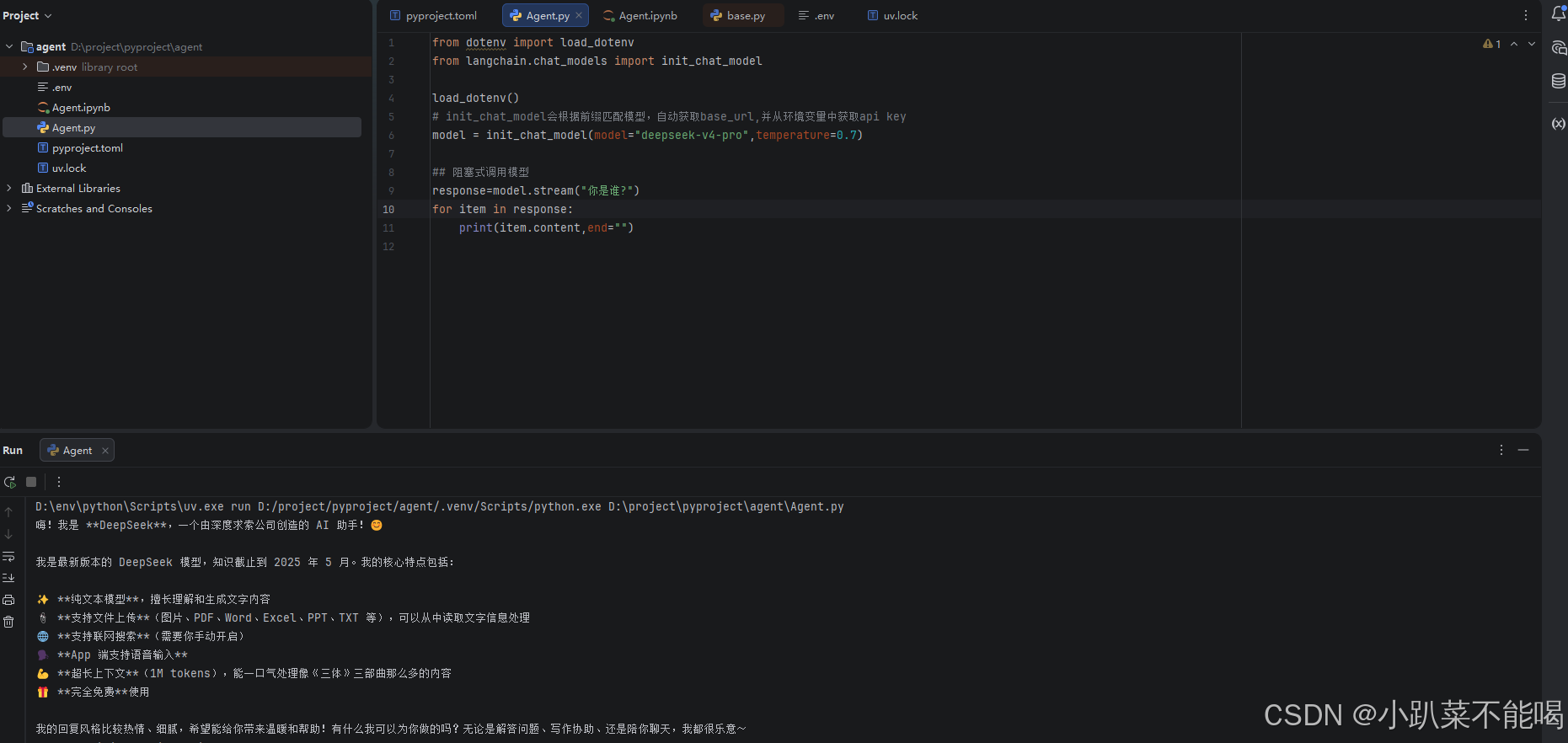
response=model.stream("你是谁?")
for item in response:
print(item.content,end="")调用模型有两种方式,第一种阻塞方式,模型拿到所有的内容返回之后在返回,第二种是流式返回,得到一个返回一个
阻塞方式调用 :response=model.invoke("你是谁?")
流式调用:response=model.stream("你是谁?")
创建智能体
上述集成了使用LangChain调用模型,但是LangChain的主要作用是来做智能体,下面将讲述如何在LangChain中创建智能体,创建智能体有两种方式
第一种直接使用上述初始化好的model:agent = create_agent(model=model)
第二种直接传入model:agent = create_agent(model= "deepseek-v4-pro")
python
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
load_dotenv()
# init_chat_model会根据前缀匹配模型,自动获取base_url,并从环境变量中获取api key
model = init_chat_model(model="deepseek-v4-pro",temperature=0.7)
agent = create_agent(model=model)调用智能体
阻塞式调用
python
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
load_dotenv()
# init_chat_model会根据前缀匹配模型,自动获取base_url,并从环境变量中获取api key
model = init_chat_model(model="deepseek-v4-pro",temperature=0.7)
#初始化Agent
agent = create_agent(model=model)
response = agent.invoke({
"messages": [
{
"content": "你是谁?",
"role": "user"
}
]
})
print(response)流式调用
python
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
load_dotenv()
# init_chat_model会根据前缀匹配模型,自动获取base_url,并从环境变量中获取api key
model = init_chat_model(model="deepseek-v4-pro",temperature=0.7)
#初始化Agent
agent = create_agent(model=model)
# response = agent.invoke({
# "messages": [
# {
# "content": "你是谁?",
# "role": "user"
# }
# ]
# })
response = agent.stream({
"messages": [
{
"content": "你是谁?",
"role": "user"
}
],
},
stream_mode="messages",
)
for token,metadata in response:
if token.content:
print(token.content,end="",flush=True)调用智能体返回
可以发现,智能体的返回比直接调用模型返回的信息要复杂的多,这也是调用模型传递参数为字典的原因之一
python
{'messages': [HumanMessage(content='你是谁?', additional_kwargs={}, response_metadata={}, id='b38b9592-306f-49a5-b6d0-fb188117f34e'), AIMessage(content='你好呀!我是DeepSeek,由深度求索公司创造的AI助手。😊\n\n简单来说,我是一个纯文本模型,可以帮你解答问题、处理文档、进行对话交流。虽然我不支持多模态识别(也就是"看"图片),但我可以读取你上传的图像、PDF、Word、Excel等文件中的文字信息来帮助你。\n\n我的一些特点包括:\n- **完全免费**使用\n- **上下文长度1M**(可以一次性处理像《三体》三部曲那么大体量的内容)\n- 支持**联网搜索**(需要你手动点开联网按钮)\n- 在App端还支持**语音输入**\n\n我的知识截止到2025年5月,会尽我所能为你提供准确、有用的帮助。\n\n有什么我可以帮你的吗?无论是学习、工作还是日常问题,尽管问我!🌟', additional_kwargs={'refusal': None, 'reasoning_content': '好的,用户问"你是谁?",这是一个非常简单的自我介绍问题。用户可能是初次接触,想了解我的基本身份和功能。\n\n我需要清晰、友好地介绍自己,说明我是谁、由谁创造、核心特点,并表达愿意提供帮助的态度。可以用热情的开场,然后分点列出关键特点,最后以开放性问题结束,邀请用户提出具体需求。\n\n想到了用"你好呀!"开头,然后说明我是DeepSeek,由深度求索公司开发。接着用几个要点概括主要特点,比如免费、大上下文、文件处理、联网搜索等,最后说明知识截止时间并询问需要什么帮助。'}, response_metadata={'token_usage': {'completion_tokens': 306, 'prompt_tokens': 6, 'total_tokens': 312, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 131, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 6}, 'model_provider': 'deepseek', 'model_name': 'deepseek-v4-pro', 'system_fingerprint': 'fp_9954b31ca7_prod0820_fp8_kvcache_20260402', 'id': '83c119cf-8c9c-4068-a2ce-bc64cfc9d89f', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019e3a51-8a8f-7180-be04-2e79aafd0ad0-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 6, 'output_tokens': 306, 'total_tokens': 312, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 131}})]}智能体消息
在LangChain中,发送给模型的消息,模型返回的消息都被统一封装为BaseMessage,并且准备了多个BaseMessage的子类对应不同角色类型的消息
- SystemMessge : Role:System
- HumanMessage: Role:user
- AIMessage : Role:assistant
- ToolMessage : Role tool
python
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
load_dotenv()
@tool
def get_weather(location: str) -> str:
"""
获取天气工具
:param location: 接受的地区
:return: 天气返回结果
"""
return f"Current weather at {location} is rain"
#初始化Agent
agent = create_agent(model="deepseek-chat",tools=[get_weather])
response = agent.invoke({
"messages": [
SystemMessage(content="请使用工具获取天气信息"),
AIMessage(content="您好,有什么可以帮您?"),
HumanMessage(content="今天北京天气怎么样?")
],
}
)
for message in response["messages"]:
message.pretty_print()美化输出
for message in response"messages":
message.pretty_print()
bash
================================ System Message ================================
请使用工具获取天气信息
================================== Ai Message ==================================
您好,有什么可以帮您?
================================ Human Message =================================
今天北京天气怎么样?
================================== Ai Message ==================================
好的,我来帮您查一下北京今天的天气情况。
Tool Calls:
get_weather (call_00_gVpgkZE6OO67CXBiLA9m5918)
Call ID: call_00_gVpgkZE6OO67CXBiLA9m5918
Args:
location: 北京
================================= Tool Message =================================
Name: get_weather
Current weather at 北京 is rain
================================== Ai Message ==================================
北京今天**下雨** 🌧️,出门记得带伞哦!如果需要了解更多详细信息,随时告诉我~**WARN:**处遇到一个问题,就是使用init_chat_model初始化的模型再创建agent,会调用报错,原因是init_chat_model会走模型底层的dispath流程,而 create_agent会绕开init_chat_model的 provider dispatch 问题
智能体提示词工程
所谓提示词工程(Prompt Engineering),就是通过优化提示词使模型输出的结果更符合业务需要的过程。
系统提示词的组成部分
一般来说,系统提示词(System Prompt)会包含以下几个部分,通常按此顺序排列:
**身份角色(ldentity):**描述AI的职责、沟通风格和总体目标。
**指令说明(Instructions):**请指导模型如何生成所需的响应。它应该遵循哪些规则?模型应该做什么,以及模型绝对不能做什么?
**对话示例(Examples):**提供可能的输入示例,以及模型期望的输出。
**背景信息(Context):**向模型提供生成响应所需的任何额外信息,例如RAG的额外知识库数据,或您认为特别相关的任何其他数据。
在编写System Prompt时,您可以使用Markdown格式和XML标签的组合来帮助模型理解提示和上下文数据的逻辑边界。
Markdown 的标题和列表有助于标记提示的不同部分,并向模型传达层级结构。它们还可以提高开发过程中提示的可读性。
XML标签可以帮助明确区分一段内容(例如用作参考的辅助文档)的起始和结束位置。
智能体工具
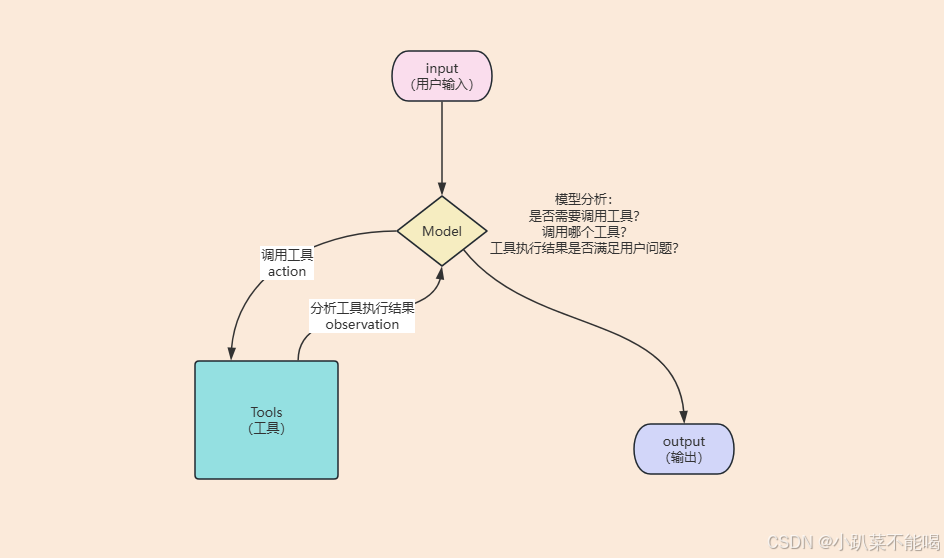
所谓的工具(Tool),本质就是一个可调用的函数,但是这个函数不是我们自己去调用,而是给模型调用。因此除了定义函数外,我们还需要清晰描述这个工具,让模型知道这个工具如何使用,工具会提供以下信息
- 工具名
- 工具的作用
- 工具需要的参数
在LangChain中,定义工具需要用到@tool装饰器,我们可以通过装饰器来定义工具名、工具的作用
如果不@tool装饰器没有定义工具名和作用描述,此时
**工具名:**默认就是函数名工具所需默认就是函数的参数列表**工具所需的参数:**默认就是函数的参数列表
**工具作用的描述:**默认就是函数的文档注释
python
@tool
def get_weather(location: str) -> str:
"""
获取天气工具
:param location: 接受的地区
:return: 天气返回结果
"""
return f"Current weather at {location} is rain"如果工具比较复杂的话,通过pydantic model来描述参数列表
BaseModel: 用来定义"数据结构"
Field:用来给字段增加规则、描述、默认值等元信息
python
class WeatherInput(BaseModel):
location: str = Field(description="City name or coordinates")
units: Literal["metric", "imperial"] = Field(default="imperial",description="Units of measurement")
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str) -> str:
"""
获取天气工具
:param units:
:param location: 接受的地区
:return: 天气返回结果
"""
return f"Current weather at {location} is rain,{units} is metric"智能体记忆
模型记忆有几种方式:
第一种:上下文记忆(也叫短期记忆),实现方式是滚雪球方式,将一个对话的所有chat问答和回复以全量的形式在次提供给模型
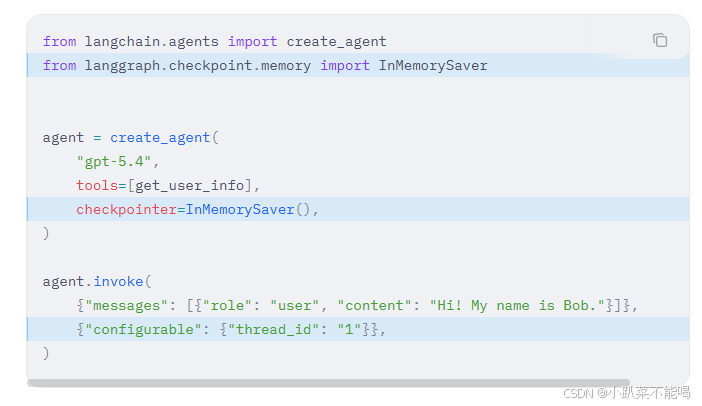
针对于Langchain中使用短期记忆,需要在创建Agent的时候指定checkpointer,这里我使用的是内存的方式,调用模型的时候还需要传入{"configurable": {"thread_id": "1"}},下方有官网的调用示例

python
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
from langgraph.checkpoint.memory import InMemorySaver
load_dotenv()
#初始化Agent
agent = create_agent(model="deepseek-chat",checkpointer=InMemorySaver())
response = agent.invoke({
"messages": [
HumanMessage(content="你好呀 我是二哥?"),
],
},
{"configurable": {"thread_id": "1"}},
)
for message in response["messages"]:
message.pretty_print()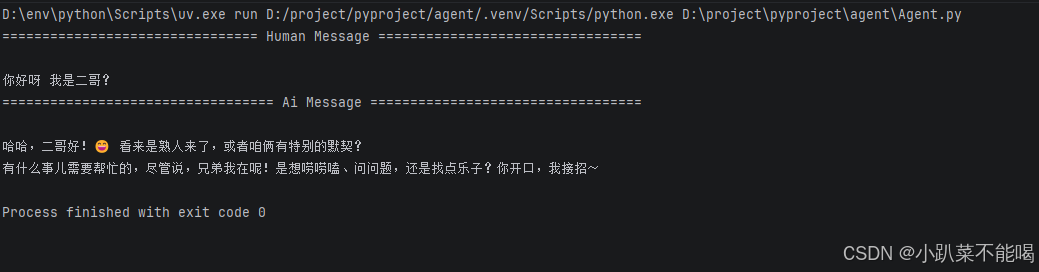
生产中的处理方式,推荐使用的记忆存储在数据库中
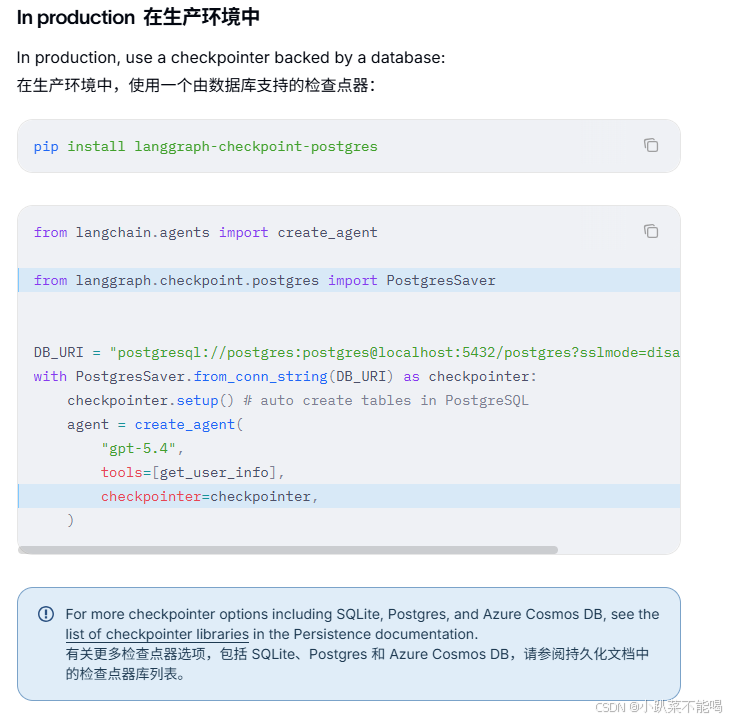
自定义智能体管理内存
LangChain的记忆原理,默认情况下,代理使用
AgentState来管理短期记忆,特别是通过messages键来管理对话历史你可以扩展
AgentState来添加额外的字段。自定义状态模式通过state_schema参数传递给create_agent
python
from dotenv import load_dotenv
from langchain.agents import create_agent, AgentState
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
from langgraph.checkpoint.memory import InMemorySaver
load_dotenv()
class CustomAgentState(AgentState):
user_id: str
preferences: dict
#初始化Agent
agent = create_agent(model="deepseek-chat",state_schema=CustomAgentState,checkpointer=InMemorySaver())
response = agent.invoke({
"messages": [
HumanMessage(content="你好呀 我是二哥?"),
],
"user_id": "user_123",
"preferences": {"theme": "dark"}
},
{"configurable": {"thread_id": "1"}},
)
for message in response["messages"]:
message.pretty_print()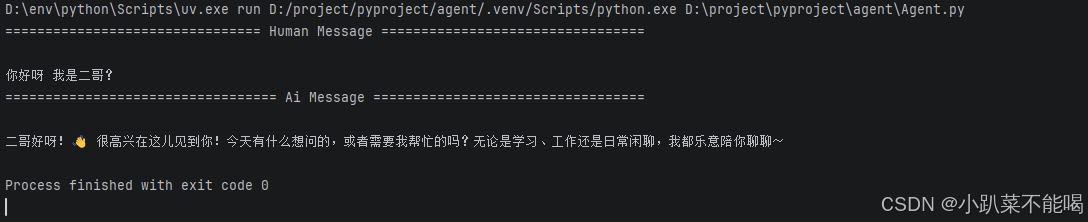
智能体流式输出,打印步骤
这里使用updates,version="v2"必须指定,这代表使用第二代agent协议
- updates:在每个智能体的操作完成后,都会更新相关状态信息。如果在同一操作过程中进行了多次更新(例如,同时处理了多个节点),那么这些更新会分别被传输出去
- messages:从所有调用了大语言模型的图节点中,提取
(token, metadata)的元组数据- custom:利用流式写入器,可以从图节点内部输出自定义数据。
python
from dotenv import load_dotenv
from langchain.agents import create_agent, AgentState
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
from langgraph.checkpoint.memory import InMemorySaver
load_dotenv()
#初始化Agent
agent = create_agent(model="deepseek-chat")
response = agent.stream({
"messages": [
HumanMessage(content="你好呀 我是二哥?"),
]
},
stream_mode="updates",
version="v2",
)
for message in response:
if message["type"] == "updates":
for step, data in message["data"].items():
print(f"step: {step}")
print(f"content: {data['messages'][-1].content_blocks}")