前言
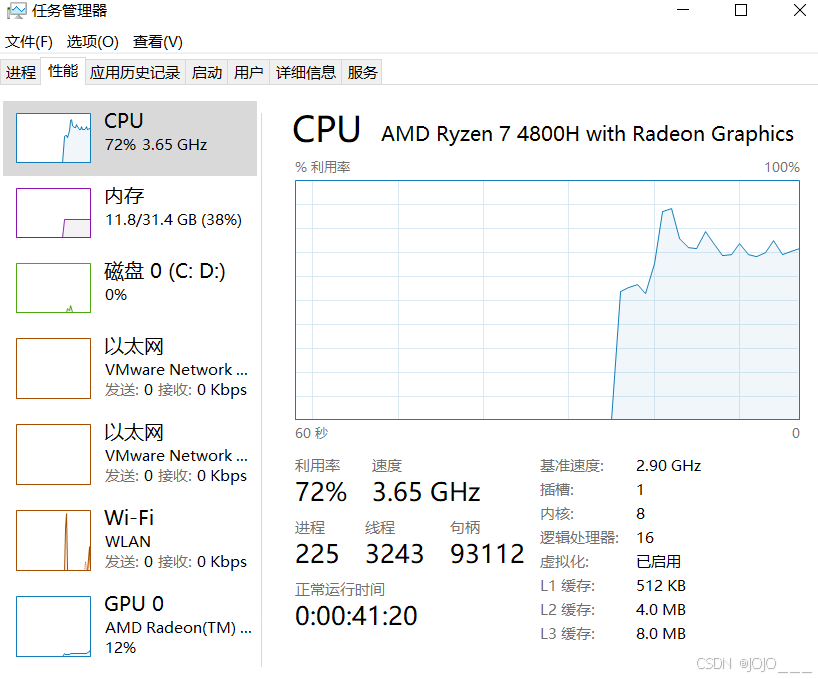
我的电脑是AMD的+32G内存,没有GPU ,偏要玩一玩千问3.5本地大语言模型 ,github上下载的llama安装包,无法使用,只有自己编译试试了。注意我是编译CPU版本的,你有GPU这篇别看了。
以下是我的CPU型号:

1. 下载CMAKE
或者下载我上传的,注意这是64位
链接:https://pan.quark.cn/s/57d6d1f65309
提取码:cYQk
2. 下载VS2022
或者下载我上传的
链接:https://pan.quark.cn/s/57d6d1f65309
提取码:cYQk
勾上这个安装就行
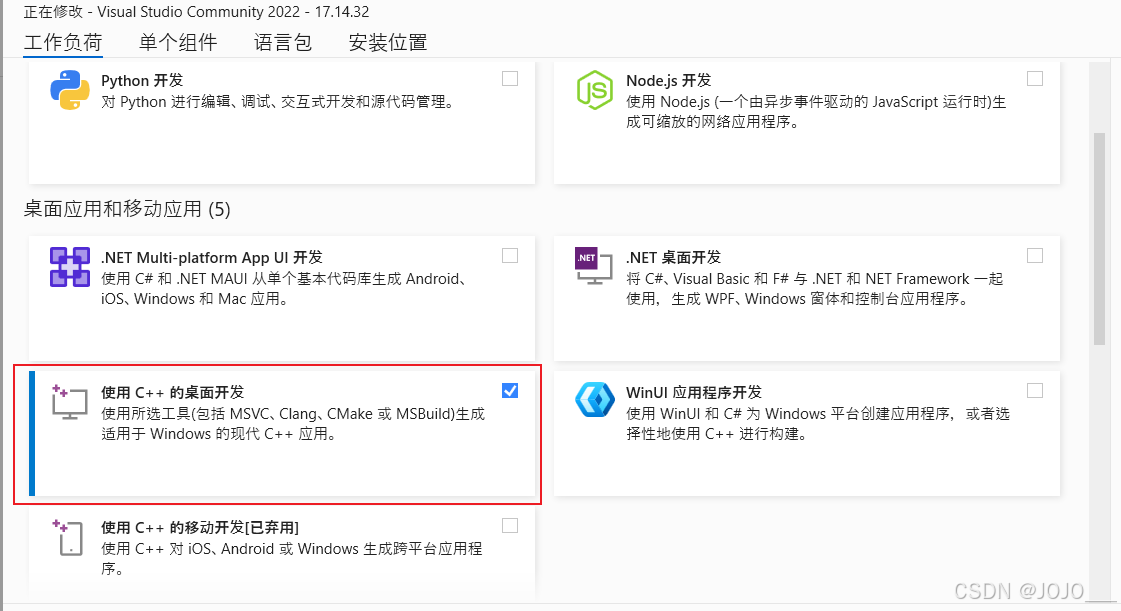
安装后重启电脑
3. 下载大语言模型Qwen3.5-0.8(可选)
我垃圾电脑CPU选择0.8B量化小模型试试,你可以选择别的大一点的模型,也可以选择0.8B的其他量化版本
Qwen3.5-0.8B官网下载地址
或者下载我上传的
链接:https://pan.quark.cn/s/57d6d1f65309
提取码:cYQk
4. 拉取llama代码&编译
打开开始菜单,找到vs2022的专用powershell,单击打开
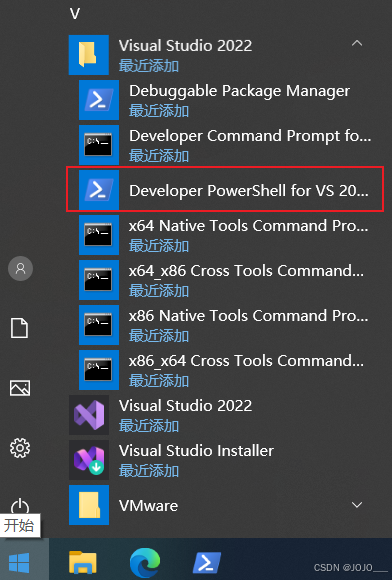
执行如下命令,注意我是编译CPU版本的,你有GPU这篇别看了
bash
git clone git clone https://github.com/ggml-org/llama.cpp.git --depth=1
cd llama.cpp
mkdir build
cd build
cmake .. -G "Visual Studio 17 2022" -A x64 -DLLAMA_CURL=OFF
cmake --build . --config Release编译完后进入目录
bash
cd bin
cd Relase
ls执行
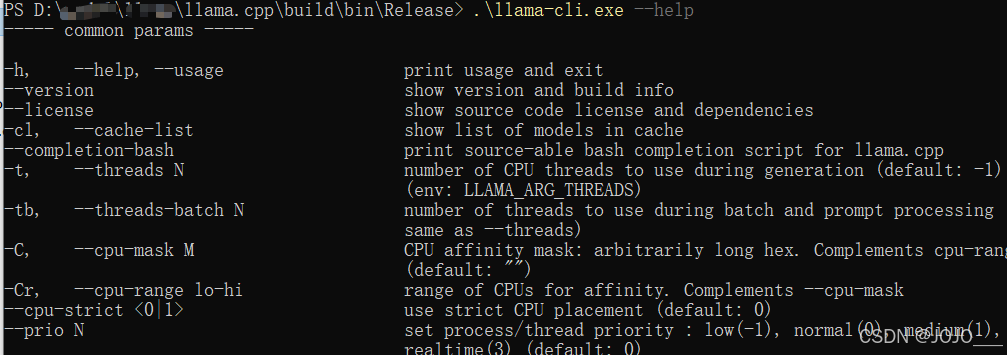
bash
llama-cli --help可以看到打印就算是安装成功了
跑Qwen3.5-0.8B试试
bash
.\llama-cli.exe -m 你的路径\Qwen3.5-0.8B-Q4_K_M.gguf -c 4096-c 4096代表4k上下文,千问3.5-0.8B最大是支持256k,改成
bash
.\llama-cli.exe -m D:\model\Qwen3.5-0.8B-Q4_K_M.gguf -c 262144实测跑起来了速度还行,37 token / s
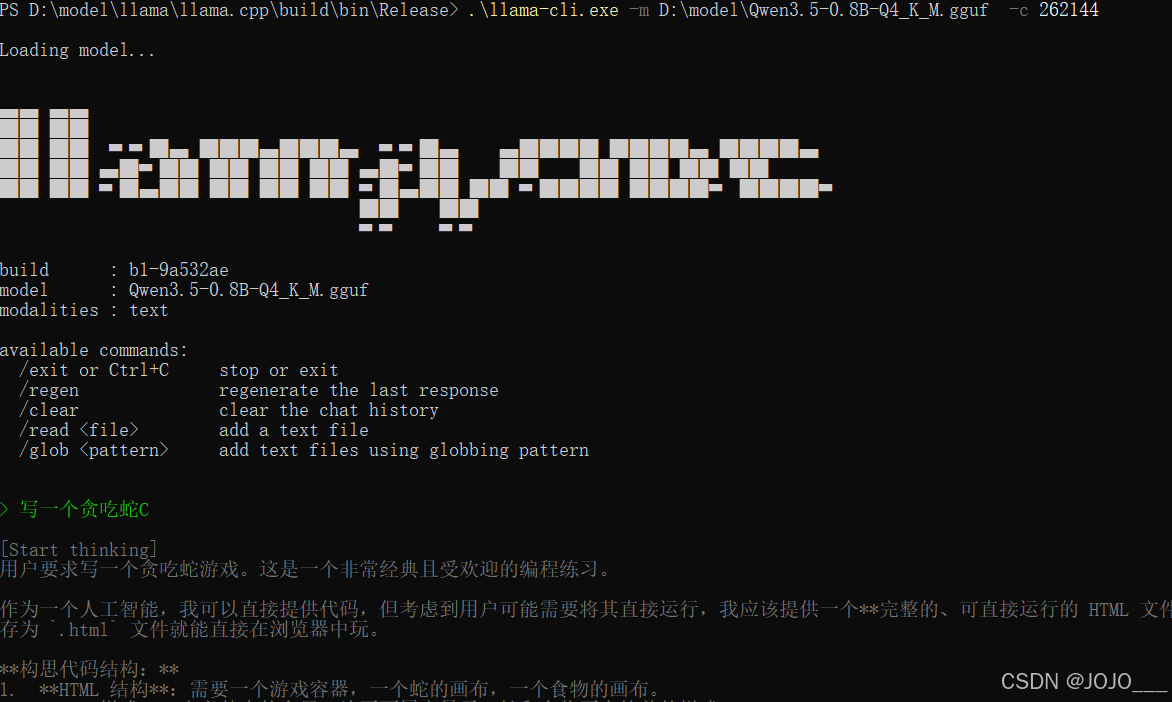

内存使用情况,还不错内存只用了12G左右,CPU用了70%。