大家好,我是你们的技术伙伴。👋
在深度学习大行其道的2026年,我们往往容易忽略那些经典且强大的传统机器学习算法。今天,我不讲复杂的Transformer,也不讲庞大的LLM,我们来重温机器学习的基石------线性回归(Linear Regression) 。
你可能觉得线性回归太简单了,不就是y = wx + b吗?
但如果你能深入下去,你会发现这里面藏着微积分 、最优化 、概率论 以及工程实现的大学问。
我们将通过波士顿房价预测这个经典数据集,带你打通从理论到代码的任督二脉。准备好了吗?让我们开始吧!🚀
🧮 第一篇章:理论基石------揭开"y=wx+b"的神秘面纱
1. 什么 是线性回归?
简单来说,线性回归就是用一个线性公式 (一次方程)来描述自变量(特征) 和因变量(标签) 之间的关系。
- 一元线性回归: y=wx+by=wx+b (比如:根据房屋面积预测房价)
- 多元线性回归: y=w1x1+w2x2+...+wnxn+by=w1x1+w2x2+...+wnxn+b (比如:根据面积、地段、楼层等多个特征预测房价)
在机器学习中, ww 叫做权重 (Weight) , bb 叫做偏置 (Bias) 。
2. 如何衡量模型的好坏?
模型预测出来的值和真实值总有差距,这个差距叫误差 。
我们要做的就是让所有样本的误差之和最小。这就是损失函数 (Loss Function) 的由来。
最常用的损失函数是均方误差 (MSE) :
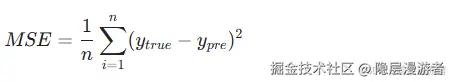 编辑
编辑
3. 如何让损失函数最小?(两大法宝)
这是线性回归的核心灵魂,也是面试必问题:
- 正规方程法 (Normal Equation) :利用矩阵运算,直接一步算出最优解。适合数据量小、特征少的情况。
- 梯度下降法 (Gradient Descent) :像下山一样,一步步寻找最低点。适合数据量大、特征多的情况,是深度学习的基石。
🏠 第二篇章:实战演练------波士顿房价预测
理论说千遍,不如代码敲一遍。我们将使用著名的波士顿房价数据集(506条数据,13个特征),对比两种求解方式。
1. 数据预处理:磨刀不误砍柴工
在把数据喂给模型之前,我们必须进行标准化 (Standardization) 。因为特征"犯罪率"和"房屋面积"的量纲完全不同,不标准化会导致模型被数值大的特征主导。
ini
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 1. 划分训练集和测试集 (8:2)
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
# 2. 特征工程 - 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 注意:测试集必须使用训练集的参数进行转换,这是很多新手容易犯的错误!2. 方案一:正规方程法 (全能选手)
LinearRegression 默认使用正规方程法。它简单粗暴,不需要调参,直接拟合。
python
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, root_mean_squared_error
# 1. 创建模型对象
estimator = LinearRegression(fit_intercept=True) # fit_intercept=True 表示计算截距b
# 2. 模型训练
estimator.fit(x_train, y_train)
# 3. 打印模型参数 (揭秘模型学到了什么)
print(f'权重 (特征系数): {estimator.coef_}')
print(f'偏置 (截距): {estimator.intercept_}')
# 4. 模型预测与评估
y_pre = estimator.predict(x_test)
print(f'均方误差 (MSE): {mean_squared_error(y_test, y_pre)}')
print(f'均方根误差 (RMSE): {root_mean_squared_error(y_test, y_pre)}')3. 方案二:随机梯度下降 (SGD)
如果你的数据集有上亿条,正规方程法会算到天荒地老。这时候就要用 SGDRegressor,它通过迭代的方式一点点逼近最优解。
python
from sklearn.linear_model import SGDRegressor
# 1. 创建模型对象
# learning_rate='constant' 表示学习率固定
# eta0=0.01 是学习率的大小,需要根据实际情况调整
estimator = SGDRegressor(fit_intercept=True, learning_rate='constant', eta0=0.01)
# 2. 模型训练 (和上面一样,但内部逻辑完全不同)
estimator.fit(x_train, y_train)
# 3. 评估
y_pre = estimator.predict(x_test)
print(f'平均绝对误差 (MAE): {mean_absolute_error(y_test, y_pre)}')💡 避坑指南: SGD对学习率(eta0)非常敏感。学太快会"跳过"最优解,学太慢会"累死"。在实际工作中,我们通常会配合GridSearchCV来自动寻找最佳学习率。
🛡️ 第三篇章:进阶艺术------正则化与过拟合的博弈
在机器学习中,最怕遇到两种情况:
- 欠拟合 (Underfitting) :模型太简单,啥也没学会。
- 过拟合 (Overfitting) :模型太复杂,把训练数据的"噪音"都死记硬背下来了,导致在新数据上表现极差。
如何解决?答案是正则化 (Regularization) 。
1. L1正则化 (Lasso):特征选择的"剪刀"
L1正则化可以将不重要的特征权重直接变为0,从而实现自动特征选择。
ini
from sklearn.linear_model import Lasso
# alpha是惩罚系数,越大惩罚越重
estimator = Lasso(alpha=0.1)
estimator.fit(X_train, y_train)2. L2正则化 (Ridge):模型稳定的"压舱石"
L2正则化让权重趋向于0但不等于0,它能有效防止某个特征权重过大,导致模型不稳定。
scss
from sklearn.linear_model import Ridge
estimator = Ridge(alpha=10)
estimator.fit(X_train, y_train)3. 可视化对比(必看)
为了让你直观感受,我编写了代码来模拟这三种情况(基于文档中的模拟数据逻辑):
- 图A (欠拟合) :用一条直线去拟合曲线数据,无论怎么努力,误差都很大。
- 图B (过拟合) :模型生成了一条弯弯曲曲的线,完美穿过每一个训练点,但在测试点上惨不忍睹。
- 图C (L2正则化) :加入Ridge后,曲线变得平滑,虽然没穿过每一个训练点,但在整体测试集上表现最好。
核心技巧:
- 当你发现模型在训练集上准确率99%,测试集上只有50%时,这就是典型的过拟合 ,请立刻使用L2正则化。
- 当你有1000个特征,想筛选出最重要的10个时,请使用L1正则化。
📝 总结与福利
通过这篇文章,我们完成了一个机器学习项目的标准流程:
- 理论推导:理解了线性回归的本质是求解最小二乘。
- 工程实战:对比了正规方程与梯度下降的代码实现。
- 调参艺术:学会了如何利用L1/L2正则化防止过拟合。
独家建议:
在2026年的今天,虽然算法越来越复杂,但线性回归 依然是理解机器学习逻辑的绝佳工具。而正则化则是你面试时展示数学功底的加分项。
希望这篇硬核实战指南能为你打下坚实的基础。
如果你觉得这篇文章对你有帮助,请务必点赞、收藏,并关注我。有任何关于机器学习的问题,欢迎在评论区留言,我会一一解答。💬