一、聚类分析定义
1.1 核心定义
聚类分析是无监督机器学习 的核心算法,无需人工标注数据标签,仅根据数据自身的特征相似性(距离、密度、相关性等),将数据集自动划分为若干个簇(类别)。核心准则:簇内样本相似度最大化,簇间样本相似度最小化(物以类聚)。
1.2 关键特点
- 无监督学习:不需要数据标签,纯依靠数据特征自动分组;
- 应用广泛:数据挖掘、用户分群、图像分割、模式识别、异常检测;
- 结果直观:自动将数据分为指定数量的类别,可视化效果清晰。
1.3 K-Means算法
K-Means 聚类是最简单、最常用的聚类算法,也是初学者最容易掌握的聚类算法之一。K-Means 是经典的无监督聚类算法 ,目标:把无标签数据集划分为预先指定的 K 个簇(类别),让同一簇内样本距离尽可能近,不同簇样本距离尽可能远,以样本到簇中心(质心)的误差平方和作为优化目标。该算法无需标注训练数据,常应用于数据分组、用户分群、图像分割等场景,也是学习进阶聚类算法的重要基础。
在应用K-Means算法有几个关键概念需要理解:

其算法的主要步骤如下:
- 确定超参数 K:预先设定要分成多少类;
- 初始化 K 个质心 随机从数据里选 K 个样本作为初始中心点;
- 分配样本(E 步:期望) 遍历全部样本,计算每个样本到 K 个质心的距离(K-Means 一般使用欧式距离计算,距离平方能放大偏差、避免正负抵消,能更直观反映簇内离散程度),将样本划分到距离最近的质心所属簇;
- 更新质心(M 步:最大化) 对每个簇,用簇内所有样本各维度平均值,生成新的簇中心;
- 收敛判断 重复 3、4 两步迭代,直到满足停止条件其一: (1)质心位置不再发生变化; (2)SSE(Sum of Squared Errors) 下降幅度小于设定阈值; (3)达到最大迭代次数。
二、MATLAB 实例 1:经典数值数据聚类(鸢尾花数据集)
2.1 数据集说明
MATLAB 自带 fisheriris 鸢尾花数据集:
- 总样本:150 个,3 种鸢尾花(真实标签用于验证);
- 特征维度:4 个(花萼长 / 宽、花瓣长 / 宽);
- 本文提取花瓣长 + 宽 2 个特征,可视化效果最优。
2.2 完整代码
clear; clc; close all; % 清空工作区、命令行、关闭图形窗口
load fisheriris; % 加载鸢尾花数据集(MATLAB内置,无需外部文件)
X = meas(:,3:4); % 提取特征:花瓣长度、花瓣宽度(2维数据,方便绘图)
k = 3; % 设定聚类数量为3
idx, C = kmeans(X, k); % idx:每个样本的聚类标签(1/2/3) % C:3个聚类中心的坐标矩阵 %% 绘制聚类结果图
figure('Name','K-Means三分类聚类结果');
scatter(X(idx==1,1), X(idx==1,2), 80, 'r', 'filled');
hold on;
scatter(X(idx==2,1), X(idx==2,2), 80, 'g', 'filled');
hold on; scatter(X(idx==3,1), X(idx==3,2), 80, 'b', 'filled');
hold on; % 绘制聚类中心(黑色五角星)
scatter(C(:,1), C(:,2), 200, 'k', 'p', 'LineWidth',2);
%% 图表标注
xlabel('花瓣长度(cm)');
ylabel('花瓣宽度(cm)');
title('鸢尾花数据集 K-Means三分类聚类结果');
legend('类别1','类别2','类别3','聚类中心','Location','best');
grid on;
%% 聚类效果评估
score = mean(silhouette(X, idx));
fprintf('聚类轮廓系数 = %.4f\n', score);
%% 真实标签对比图
figure('Name','真实分类结果');
gscatter(X(:,1), X(:,2), species, 'rgb', 'o', 20);
xlabel('花瓣长度(cm)');
ylabel('花瓣宽度(cm)');
title('鸢尾花数据集 真实3分类结果');
legend('山鸢尾','变色鸢尾','维吉尼亚鸢尾');
grid on;
2.3 程序的主要运行结果
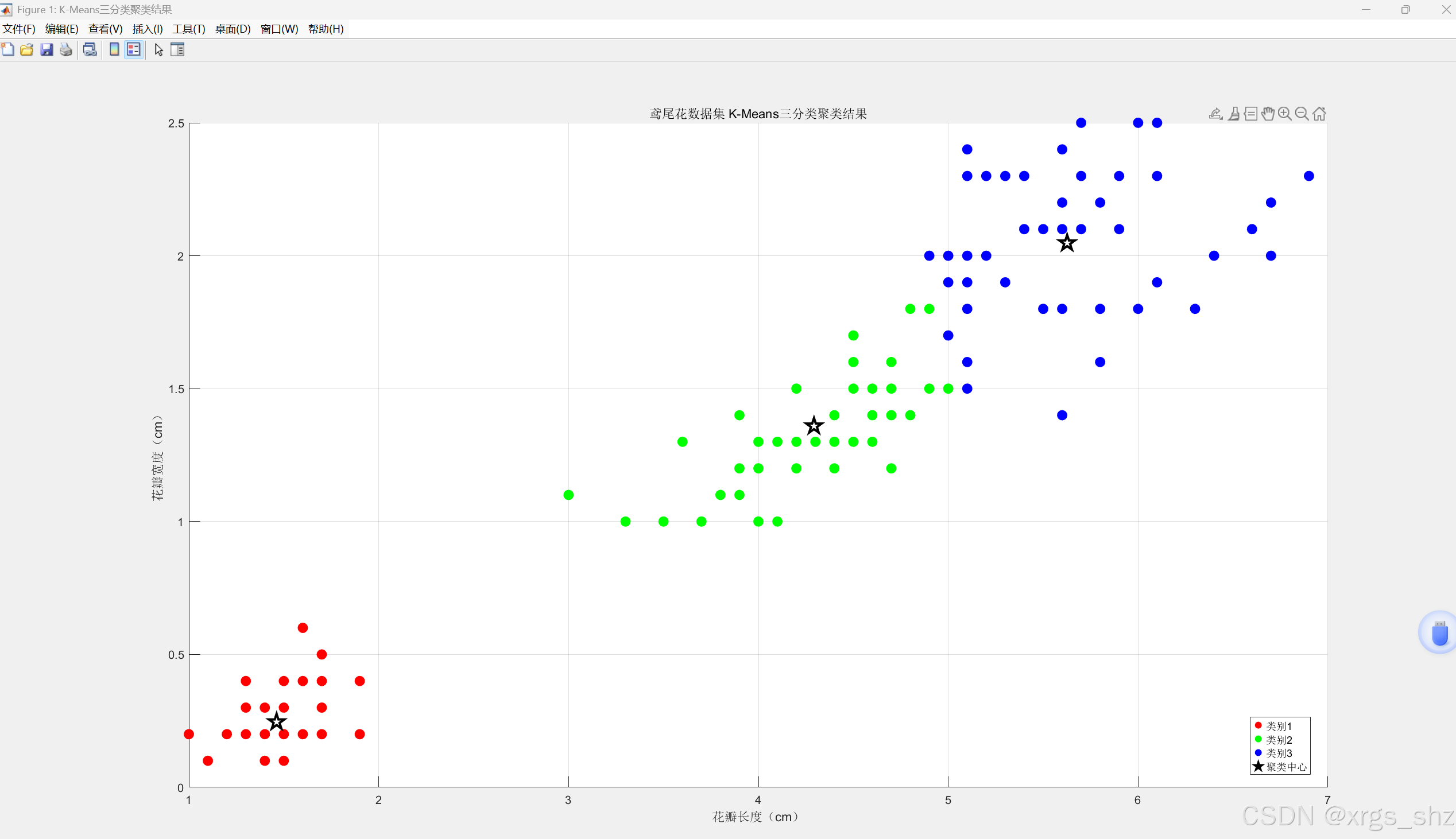
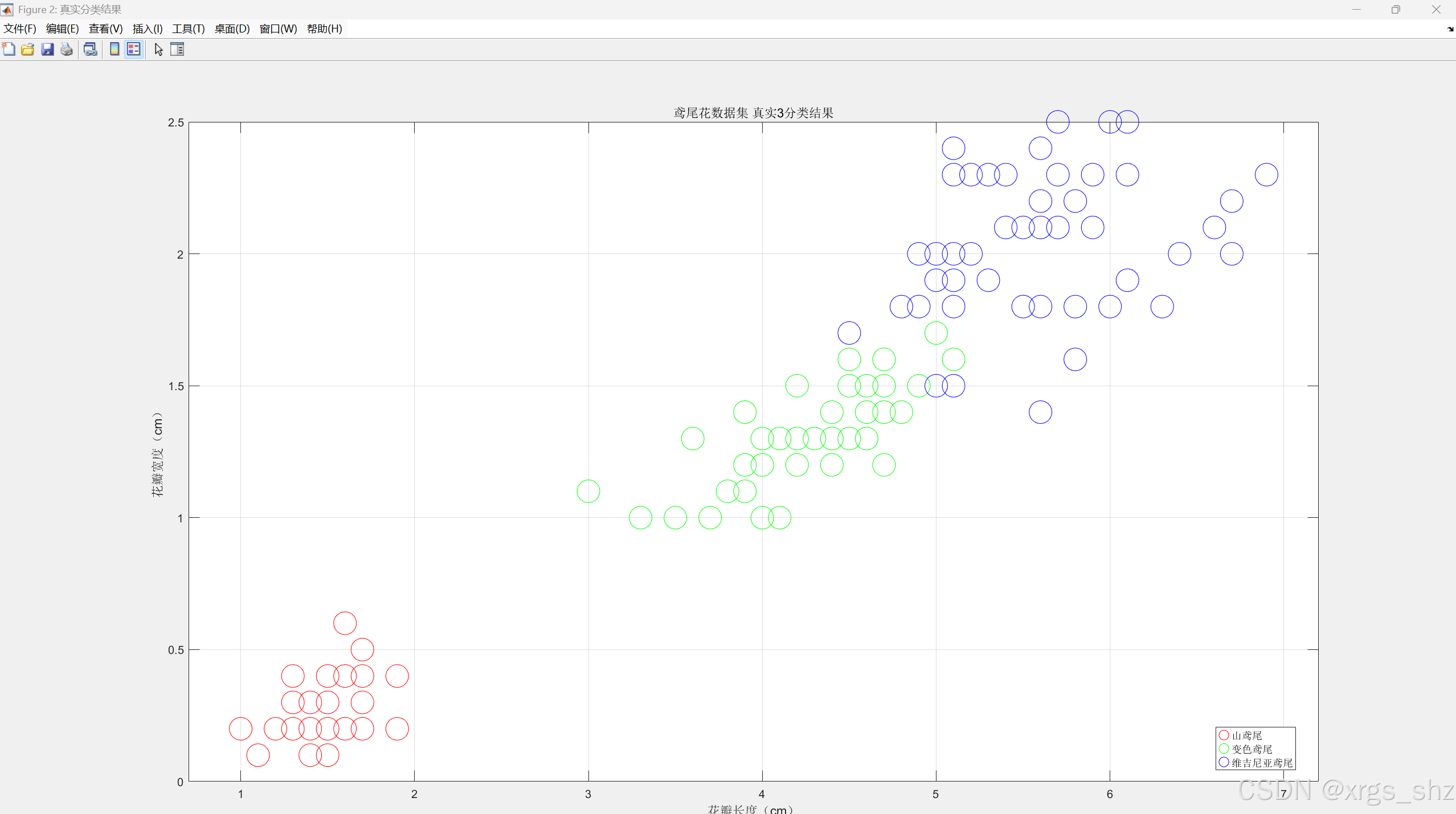

轮廓系数范围是 -1 到 1,数值越大代表聚类效果越好 。通常认为大于 0.5 表示效果较好,0.7 以上为优秀 。从运行结果可以看出,聚类轮廓系数为0.8058聚类效果优秀,也可以从分类结果图看出采用Kmeans可以获得很好的聚类分析结果。