很多人对 K-Means 的印象停留在「调个 sklearn 的 KMeans 就出结果」,但真要自己实现一遍,会发现细节比想象中多。这篇从工程视角把它拆开:核心循环、初始化、空簇、复杂度,外加几个容易翻车的点。
它到底在干嘛
一句话:给 n 个点,自动分成 k 组,组内尽量近,无监督、没标签。核心就两步循环:
arduino
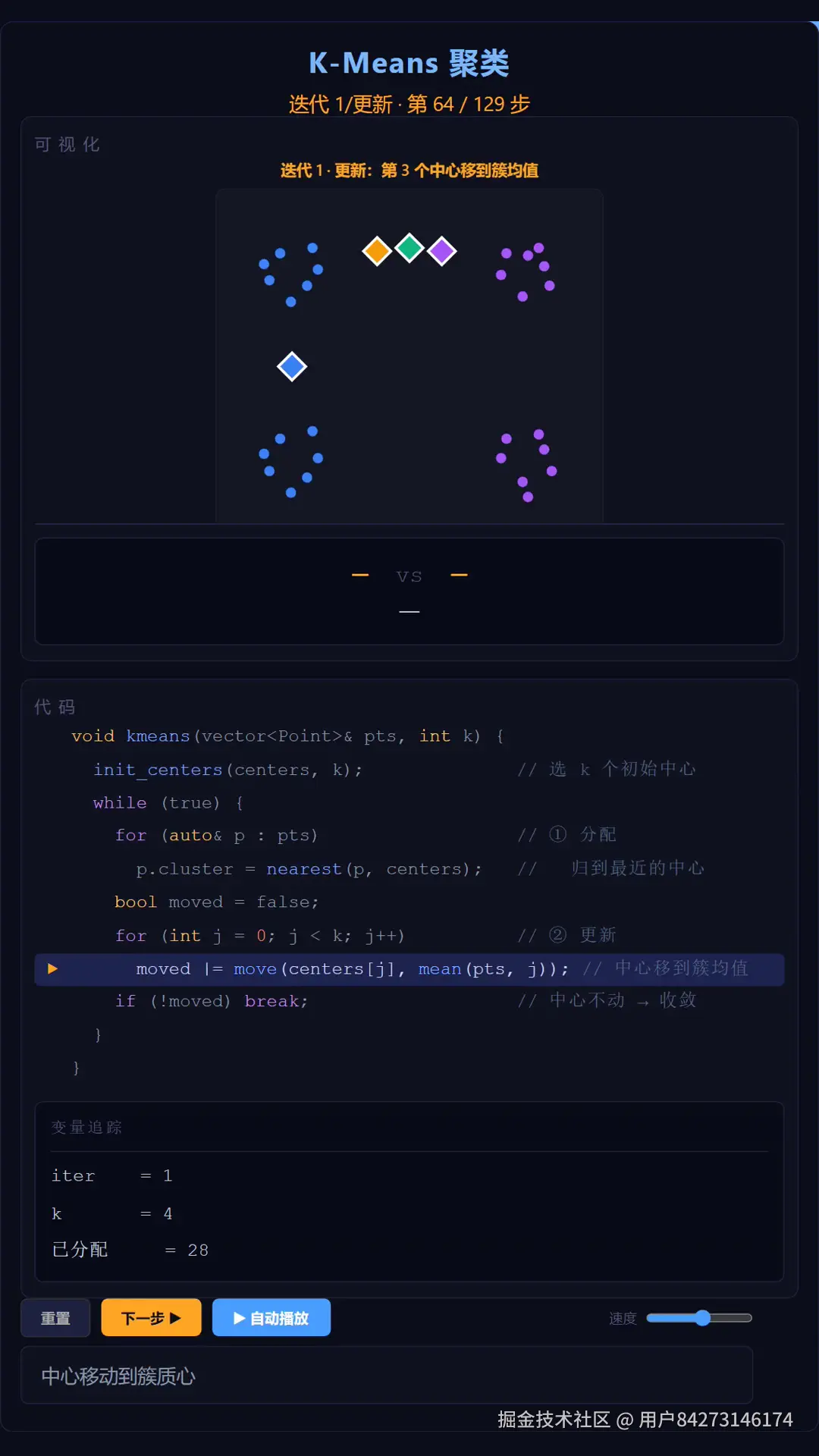
void kmeans(vector<Point>& pts, vector<Point>& centers, int k) {
while (true) {
for (auto& p : pts) // ① 分配
p.cluster = nearest(p, centers); // 归到最近的中心
bool moved = false;
for (int j = 0; j < k; j++) // ② 更新
moved |= moveToMean(centers[j], pts, j); // 中心移到簇均值
if (!moved) break; // 中心不动 → 收敛
}
}nearest 找最近中心,moveToMean 把中心挪到簇均值,if (!moved) break 做收敛判定。逻辑就这么点,但魔鬼在细节。
距离别开方
比较「谁更近」时用距离的平方就够了,省掉每次 sqrt:
arduino
double dist2(const Point& a, const Point& b) {
double dx = a.x - b.x, dy = a.y - b.y;
return dx * dx + dy * dy; // 平方比较,省一次开方
}初始化怎么选
最朴素是随机选 k 个点当初始中心,但结果对初始值很敏感,可能收敛到差的局部最优。两个常见做法:① 多跑几次取最优 (按簇内误差选最好的一次);② 用 k-means++ ,让初始中心彼此尽量分散,质量更稳。演示里用的是固定初始中心,方便看清过程。
空簇要处理
更新步里,如果某个簇一个点都没分到,cnt == 0,均值就没法算。我的写法是这种情况下让中心本轮不动:
arduino
bool moveToMean(Point& center, const vector<Point>& pts, int j) {
double sx = 0, sy = 0; int cnt = 0;
for (const auto& p : pts)
if (p.cluster == j) { sx += p.x; sy += p.y; cnt++; }
if (cnt == 0) return false; // 空簇:本轮不动
center.x = sx / cnt; center.y = sy / cnt;
return true;
}工程上更激进的做法是:把空簇的中心重置到「离现有中心最远的那个点」,避免白白浪费一个簇。
复杂度
每轮算 n 个点到 k 个中心的距离,O(n·k);跑 t 轮就是 O(n·k·t) ,空间 O(n + k)。t 一般不大,所以很快。
几个踩坑总结
- k 要自己定,配合肘部法则;
- 特征量纲差太大先归一化,否则距离被大尺度特征主导;
- 簇非球形(环形/长条)效果差,换 DBSCAN;
- 加个最大迭代次数兜底,别真写死等到完全不动。

把分配、更新、收敛逐帧画出来之后,这算法是真的一目了然。这套可视化在码路星球 里:我不慌----成长杂货铺wobuhuang.com
算法、机器学习、K-Means、C++、聚类、可视化