nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
L09 结束时,schedule() 返回了一批 scheduled_seqs。这批 seq 由 model_runner.run(seqs, is_prefill) 处理,执行一次完整的 forward,得到新 token。
但 forward 内部并不只读 input_ids 和 positions 这两个常规张量。最深处的 attention 内核还要读一组描述本批 token 切分方式与 KV cache 布局的元数据:
-
cu_seqlens_q/cu_seqlens_k:一维数组,标记本批 query / key 拼接张量上每条 seq 的起止下标。例:2 条 seq 长度为 3、2,则cu_seqlens_q = [0, 3, 5]------seq 0 占索引[0, 3)、seq 1 占索引[3, 5)。attention 内核靠它区分不同 seq,避免跨 seq 互相算 attention(见下图)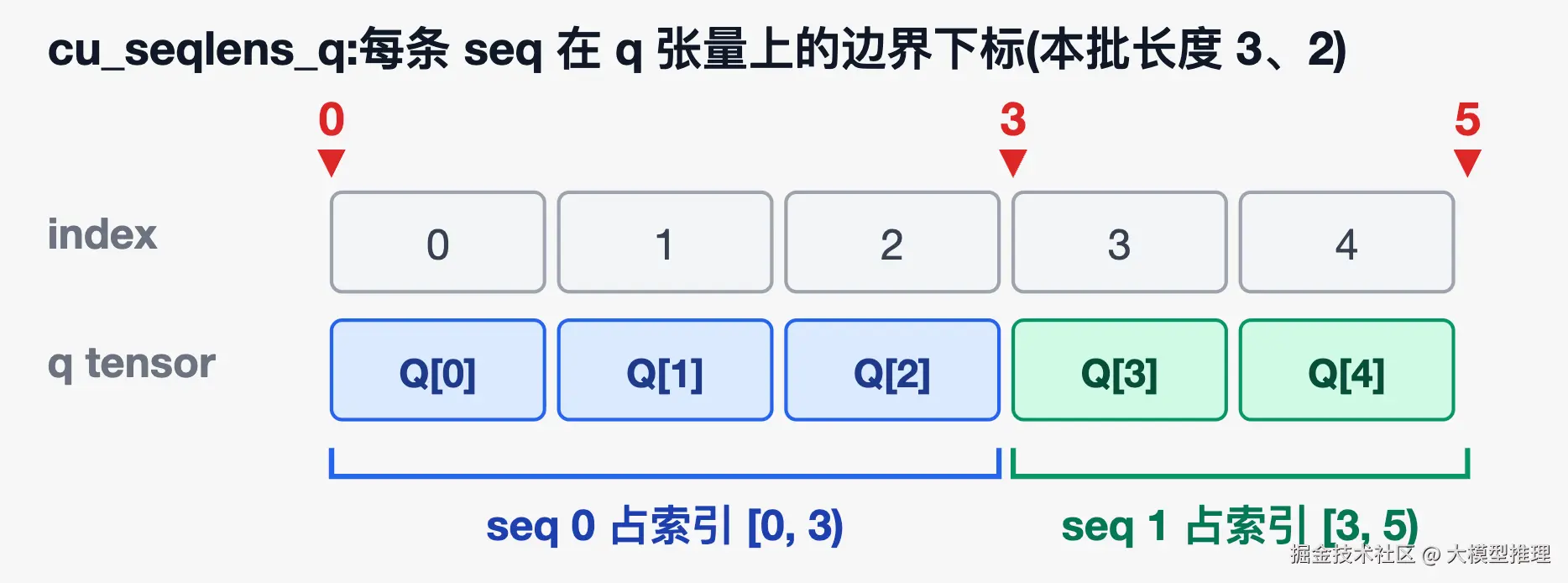
-
slot_mapping:本批每个 token 算出的新 KV 要写到 KV cache 的哪个物理槽位 -
context_lens:decode 路径下,每条 seq 当前 KV 已累积的 token 数 -
block_tables:每条 seq 的 KV 分布在哪些物理块上
LM head 还要根据 is_prefill 决定是否取 last_indices(prefill 路径下只对每条 seq 最后一个 token 算 logits)。
问题是:这些元数据在最深的 attention 才被读到,而 Qwen3ForCausalLM.forward(input_ids, positions) 的签名只有两个参数。Embedding、DecoderLayer、SelfAttention、Attention 依次调用,这些元数据如何被传递到内核?
直接的做法是"作为 forward 签名的参数,逐层传递"。nano-vllm 没这么做,而是引入一个 28 行的 utils/context.py,将所有元数据记录在一个全局 dataclass。一个加速库使用全局变量,这是本节要分析的设计取舍。
读完本节,读者可以:
- 区分 forward 的两类输入(内容型 vs 形状型),并说明为什么"形状型"输入在 nano-vllm 这种深层调用栈下不适合走 forward 签名
- 解释 nano-vllm 选择全局
Context而不是把元数据作为 Module forward 参数的取舍------节省什么、付出什么代价 - 说出
Contextdataclass 8 个字段各自服务于 prefill 还是 decode,以及它们在哪个内核被读取 - 描述
set_context → get_context → reset_context在一轮run()里的调用时序,以及为什么set_context用整体替换而不是字段 mutate - 解释"全局变量不可重入"这个代价为什么在 nano-vllm 的进程模型下可以避免
1. forward 需要的两类输入
Qwen3ForCausalLM 的 forward 签名只有两个参数(见 qwen3.py):
python
def forward(self, input_ids: torch.Tensor, positions: torch.Tensor):
...input_ids 是本轮要算的所有 token id 拼接而成的一维张量,positions 是对应的位置索引。两者都是逐 token 的:第 i 个 token 的内容写在 input_ids[i],它的位置写在 positions[i]。
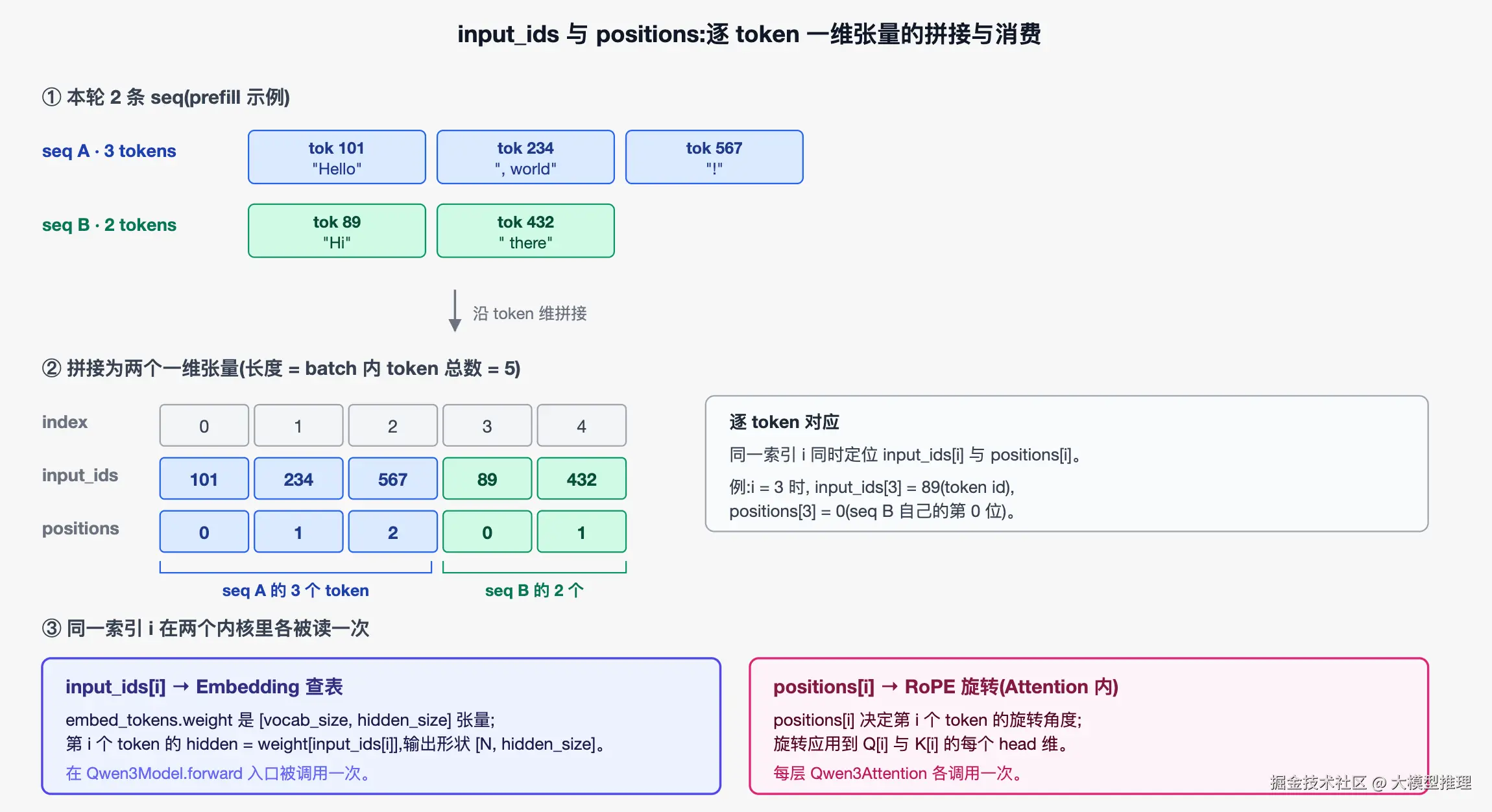
上图用一个具体例子可视化前述描述:本轮 2 条 seq(seq A 共 3 个 token,seq B 共 2 个)的所有 token 沿 token 维拼接,得到长度为 5 的 input_ids 与 positions;同一索引 i 同时定位两张表的同一位置。input_ids 在 Qwen3Model.forward 入口由 Embedding 一次性查表转为逐 token 的 hidden,后续层只持有 hidden;positions 则在每层 Qwen3Attention 内部被 RoPE 用作旋转角度,作用在 Q[i]、K[i] 上,Qwen3DecoderLayer 本身只是把它向下传递给内部 Attention,自己不读取它。
但 forward 内部还需要别的信息才能正确算出结果。观察 attention 在 prefill 路径调 flash-attn 的代码(见 attention.py:67-70):
python
o = flash_attn_varlen_func(q, k, v,
max_seqlen_q=context.max_seqlen_q, cu_seqlens_q=context.cu_seqlens_q,
max_seqlen_k=context.max_seqlen_k, cu_seqlens_k=context.cu_seqlens_k,
softmax_scale=self.scale, causal=True, block_table=context.block_tables)cu_seqlens_q、cu_seqlens_k、max_seqlen_q、max_seqlen_k、block_tables------这些不是 token 的内容,而是描述整个 batch 的切分方式 :第几个 token 属于第几条 seq,每条 seq 的 query 长度多少、key 长度多少,各条 seq 的 KV 分布在哪些物理块。一批 token 共用一份这种描述,不像 input_ids 那样每个 token 各对应一个值。
类似地,store_kvcache 内核要读 slot_mapping(每个 token 的 KV 写到哪个物理槽位),decode 路径下的 attention 要读 context_lens 和 block_tables,LM head 在 prefill 路径要读 cu_seqlens_q 才能定位每条 seq 最后一个 token。
先明确两类各自的消费路径------内容型输入(input_ids、positions)每层都要消费,在调用栈的每一层都被使用;形状型输入只在调用栈最末端的 attention 内核与 LM head 被读,中间所有 Module(Qwen3ForCausalLM → Qwen3Model → Qwen3DecoderLayer → Qwen3Attention → Attention)都不消费它们。这种"两类输入在被读位置上的质的差异"正是分类的依据。给出明确定义:内容型输入 是逐 token 提供取值、并被中间每一层消费的张量;形状型输入是描述这一批 token 如何切分、KV 如何布局的元数据,只在调用栈最末端的若干内核被读取。下面用一张表把两类各自的例子、形状特征和消费位置列清楚:
| 类别 | 例子 | 形状 | 在哪里被读 |
|---|---|---|---|
| 内容型 | input_ids、positions |
逐 token 一维张量,长度等于本批总 token 数 | Embedding 层(input_ids 查表)、RoPE(positions 算旋转) |
| 形状型 | cu_seqlens_q/k、max_seqlen_q/k、slot_mapping、context_lens、block_tables、is_prefill |
描述 batch 切分与 KV 布局,长度由 batch 内的 seq 数或 token 数决定,但不是"逐 token 一个值" | 仅在最末端的 attention 内核与 LM head 被读 |
形状型输入的特殊之处在于"中间层只负责向下传递、自己不消费",下一节就以这种情形为反例,分析它的代价。
2. 反例:让 forward 签名携带用不到的字段
假设 nano-vllm 没引入 Context,把形状型元数据全部声明为 forward 签名的参数,代码会长什么样?最直接的写法是逐层透传:
python
# 反例:并非 nano-vllm 实际代码
class Qwen3ForCausalLM(nn.Module):
def forward(self, input_ids, positions,
is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
slot_mapping, context_lens, block_tables):
h = self.model(input_ids, positions,
is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
slot_mapping, context_lens, block_tables)
return self.lm_head(h, is_prefill, cu_seqlens_q)
class Qwen3Model(nn.Module):
def forward(self, input_ids, positions,
is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
slot_mapping, context_lens, block_tables):
h = self.embed_tokens(input_ids)
for layer in self.layers:
h = layer(h, positions,
is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
slot_mapping, context_lens, block_tables)
return self.norm(h)
class Qwen3DecoderLayer(nn.Module):
def forward(self, h, positions,
is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
slot_mapping, context_lens, block_tables):
h = self.self_attn(self.input_layernorm(h), positions,
is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,
slot_mapping, context_lens, block_tables) + h
return self.mlp(self.post_attention_layernorm(h)) + hQwen3Model 和 Qwen3DecoderLayer 的 forward 签名都包含 8 个形状型参数,但它们自己一个都不读------只是把这 8 个字段原样传给下一层。真正消费这些字段的只有最深的 Attention.forward 和 ParallelLMHead.forward。
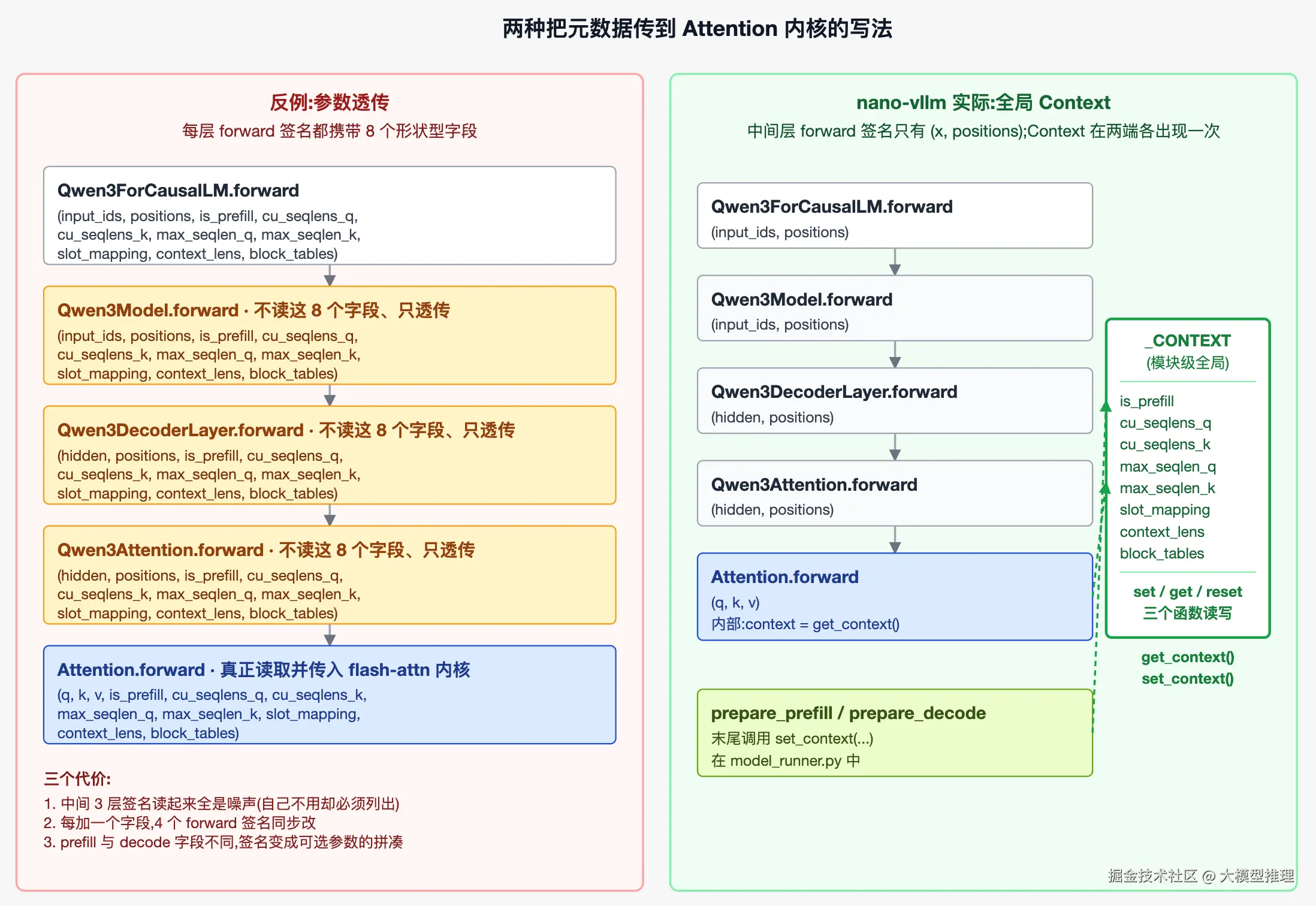
这种写法的三个代价如下:
第一,签名读起来全是噪声 。观察 Qwen3DecoderLayer.forward(h, positions, is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, context_lens, block_tables),签名总共 10 个参数,其中 8 个 DecoderLayer 自己不用。读代码的人不能从签名上看出"这一层关心哪些输入",必须再去看 forward 内部把哪些参数传给了哪个子层。
第二,演化代价线性增长 。形状型元数据不是固定的------prefill 路径要 cu_seqlens_q/k、max_seqlen_q/k,decode 路径要 context_lens,prefix cache 命中时还要 block_tables。每加一个新字段,Qwen3ForCausalLM、Qwen3Model、Qwen3DecoderLayer、Qwen3Attention 四层 forward 签名都要同步加。如果将来加 sliding window attention 还要再加 window_size------又是四层签名同步改。
第三,跨路径的可选字段使签名变得冗杂 。prefill 不需要 context_lens,decode 不需要 cu_seqlens。要么全部声明为 Optional[Tensor] = None,签名变得更长;要么按路径分两套 forward,在调用点根据 is_prefill 选哪一套------后者把分支判定从最深的 attention 移到了最浅的 Qwen3ForCausalLM,反而让分支判定扩散到更多层。
注意,这三个代价不是单层的代价,而是会沿调用栈复制 N 次。Qwen3 默认 28 层 DecoderLayer,每加一个字段就是 28 次重复编辑。
nano-vllm 的选择是另一个极端:把所有形状型元数据声明为一个全局变量的字段,只在两处出现------prepare_* 设值时一次,attention/embed_head 读值时一次。中间所有层都不需要在签名中列出这些字段。
代价是"全局变量不可重入"。这个代价是否可接受、为什么在这套架构下其实可以避免,留到第 4 节展开;先看 Context 本身的结构。
3. Context dataclass 与三个 API
context.py 做三件事:用 dataclass 描述形状型元数据的字段表,在模块加载时创建一份唯一实例,并暴露 get/set/reset 三个函数管控对它的访问。下面是全文,28 行(见 context.py):
python
from dataclasses import dataclass
import torch
@dataclass(slots=True)
class Context:
is_prefill: bool = False
cu_seqlens_q: torch.Tensor | None = None
cu_seqlens_k: torch.Tensor | None = None
max_seqlen_q: int = 0
max_seqlen_k: int = 0
slot_mapping: torch.Tensor | None = None
context_lens: torch.Tensor | None = None
block_tables: torch.Tensor | None = None
_CONTEXT = Context()
def get_context():
return _CONTEXT
def set_context(is_prefill, cu_seqlens_q=None, cu_seqlens_k=None, max_seqlen_q=0, max_seqlen_k=0, slot_mapping=None, context_lens=None, block_tables=None):
global _CONTEXT
_CONTEXT = Context(is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, context_lens, block_tables)
def reset_context():
global _CONTEXT
_CONTEXT = Context()三段:dataclass 定义、模块级实例 _CONTEXT、三个函数。逐段说明。
Context dataclass
@dataclass 是 Python 标准库装饰器,根据类里声明的字段自动生成 __init__、__repr__ 等样板方法,本身不影响实例的存储结构。
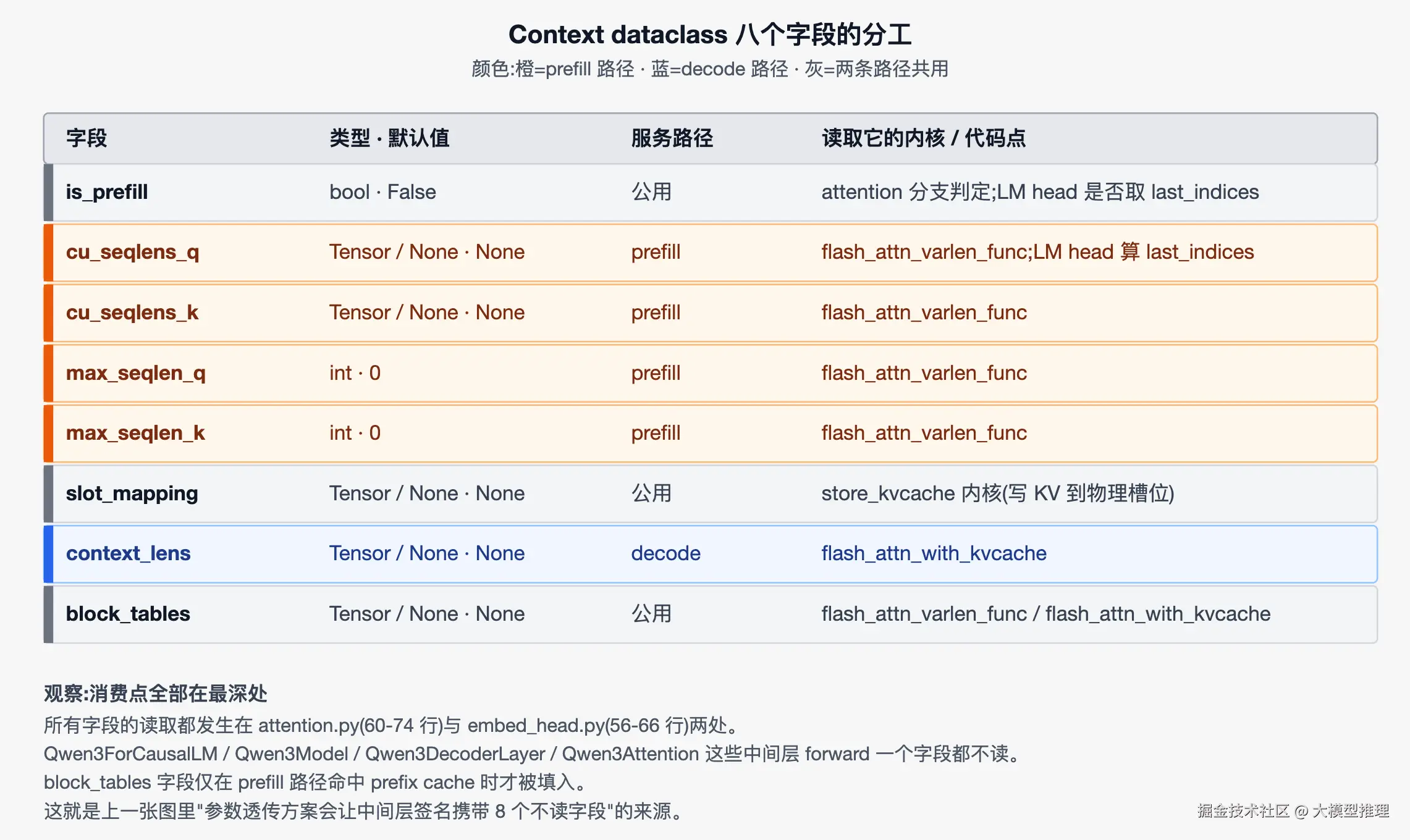
Context 用 @dataclass(slots=True) 声明了 8 个字段。下图最右一列会给出每个字段的消费方,先简要说明这里出现的三个内核名:flash_attn_varlen_func 是 prefill 路径的 attention 实现,flash_attn_with_kvcache 是 decode 路径的 attention 实现,store_kvcache 是把新算出的 KV 写入物理槽位的内核------本节只需知道它们是字段的消费方,实现细节本节不展开。图中"LM head 算 last_indices"指的是 prefill 路径从一维拼接结果中按每条 seq 最后一个 token 位置提取的索引。
下图按服务路径分色(橙=prefill、蓝=decode、灰=两条路径共用),列出 8 个字段的类型、默认值与消费方。
slots=True 这个参数需要说明。你可能以为一个 GPU 加速库不会在乎 Python 端字典字段访问的开销,但 nano-vllm 在这里专门启用了 slots=True------因为 set_context 每轮 forward 都构造一个新 Context 实例,一个 step 几百微秒级,Python 端任何额外开销都会被放大。slots=True 通过把字段表固定为 dataclass 声明的 8 个、不再生成 __dict__(普通 Python 对象的属性存放在一个名为 __dict__ 的字典里),从而减少内存与属性访问开销。这是一项小优化,反映出对"Python 端开销敏感"的整体取舍。
字段默认值有两类。你可能以为既然张量字段用 None 表示"本轮没有这个元数据",统一用 None 作哨兵最整齐------但 nano-vllm 对布尔与数值字段刻意没用 None。is_prefill、max_seqlen_q、max_seqlen_k 默认是 False / 0 / 0,而不是 None,因为读取它们的代码直接将其用于布尔判断或数值运算,默认值必须保持原本的类型。
如果 is_prefill 默认成 None,虽然 if context.is_prefill: 在布尔上下文里把 None 当 falsy 处理、看似没问题,但下游一旦写出 if context.is_prefill is True: 这种判等检查,prefill 分支永远不会进入(None is True 为 False);或者像 int(context.is_prefill) 这种把它当数值用的代码会直接抛 TypeError。同理,max_seqlen_q 若默认成 None,任何把它传给 flash-attn 的代码立刻报错。换句话说,bool/int 默认值若被 None 替换,部分用法变成隐式错误、部分用法变成显式异常------这种"部分用法报错、部分用法静默出错"的状态比统一类型更难处理。
剩下五个张量字段默认 None,表示"本轮没有这个元数据",此时调用方代码本就该判 None,所以默认 None 反而是自然选择。
_CONTEXT 模块级实例
python
_CONTEXT = Context()模块级语句 _CONTEXT = Context() 在 Python 进程首次 import 此模块时执行一次,之后这个名字就绑定到该实例上,不会再被重置(除非显式赋值)------这就是"全局唯一一份"的来源。8 个字段全部取默认值,得到一个空 Context。注意名字前的下划线------惯例上表示"模块私有,外部不要直接引用"。外部要读 Context,只能通过 get_context();要写 Context,只能通过 set_context()。
三个函数
python
def get_context():
return _CONTEXT
def set_context(is_prefill, cu_seqlens_q=None, ..., block_tables=None):
global _CONTEXT
_CONTEXT = Context(is_prefill, cu_seqlens_q, ..., block_tables)
def reset_context():
global _CONTEXT
_CONTEXT = Context()get_context() 一行,返回当前的 _CONTEXT 实例。它在 attention.py 和 embed_head.py 被调用,内核获取实例后直接读取字段,完整代码见 attention.py:60 和 embed_head.py:57。
set_context() 接收所有 8 个字段(除了 is_prefill 是必传,其余 7 个都用关键字默认值 None / 0),然后整体替换 _CONTEXT ------不是 mutate(就地修改)现有实例的字段,而是直接 _CONTEXT = Context(...) 赋一个新实例。
你可能以为整体替换是不必要的浪费------只改 1-2 个字段,直接 mutate 不是更省吗?但这里恰恰是利用"构造新实例"让没传的字段自动取默认值,从而把上一轮残留一次性覆盖。设想用 mutate 写法:
python
# 反例
def set_context(is_prefill, cu_seqlens_q=None, ...):
_CONTEXT.is_prefill = is_prefill
if cu_seqlens_q is not None:
_CONTEXT.cu_seqlens_q = cu_seqlens_q
# ...如果上一轮是 prefill(_CONTEXT.cu_seqlens_q 是个张量),本轮调 set_context(False) 想切换到 decode,这种 mutate 写法只会改 is_prefill------cu_seqlens_q 仍然指向上一轮的张量,decode 路径下没有代码读取它,看似无影响。但只要后续有新代码在缺少判断的情况下读取了 cu_seqlens_q,bug 就会出现。
整体替换没有这个隐患:本轮没传的字段,在新 Context 实例里就是默认值(None 或 0),与上一轮无关。调用方写 set_context(False, slot_mapping=..., context_lens=..., block_tables=...),5 个没传的字段自动取默认值,用一次构造完成了"把上一轮的残留覆盖为默认值" ------这相当于每轮 forward 都基于干净状态构造 Context,杜绝"上一轮的残留隐式影响本轮"的可能;而且因为 is_prefill=False、max_seqlen=0 都是合法默认值,任何字段遗漏立刻表现为读到 None 或 0,而不是读到上一轮的旧值。
下面是 nano-vllm 实际的两条 set_context 调用,对照默认值如何工作:
python
# prepare_prefill 末尾:
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)
# ↑ ↑
# prefill 路径, context_lens 显式传 None
# 所有形状字段都填 (decode 才用,prefill 不用)
# prepare_decode 末尾:
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables)
# ↑ ↑
# decode 路径,只传 4 个字段
# 剩下 4 个 cu_seqlens 与 max_seqlen 全部取默认 None / 0reset_context() 将 _CONTEXT 重置为一个空 Context------所有字段恢复默认值。
Context 的静态结构到此为止,但仅看 dataclass 和三个函数还不够------set_context 在什么时刻被调、get_context 在哪些位置读、reset_context 解决了什么问题,这些动态时序才决定全局变量这套设计是否成立。下一节按一轮 run() 的四步说明时序。
4. set → run → reset:一轮 forward 的生命周期,以及全局变量的代价为什么可以避免
Context 是一份共享状态,共享状态的设计核心是明确什么时刻、哪段代码能读到什么值 。一轮 run() 的完整时序就是这份共享状态的访问规则。
一轮 run() 的四步
model_runner.run() 的实现见 model_runner.py:214-220:
python
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None
logits = self.run_model(input_ids, positions, is_prefill)
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
reset_context()
return token_ids代码中 if self.rank == 0 是多卡场景下"只有主进程做采样"的判定条件------rank 是多卡场景下每张 GPU 对应的子进程编号,rank 0 是主进程;单卡时只有 rank 0 一个进程,这个判定恒为真。多卡架构本身在本节后段「全局变量的代价」小节展开。
四步串行:
- prepare_ *:
prepare_prefill或prepare_decode算出本轮所有元数据,末尾 调一次set_context(...)。这一步把_CONTEXT从空 Context 切换为本轮真实值。 - run_model :模型 forward。Embedding → DecoderLayer × N → 最终 RMSNorm → LM head 依次被调用,中间所有 Module 的 forward 签名只有
(x, positions)或(x),签名上不出现形状型元数据;只有 attention 内核和 LM head 在调用栈末端各调一次get_context()取值。 - sampler :从 logits 采样出 token。这一步不读 Context,但因为它发生在 run_model 之后、reset 之前,如果它内部或它调用的代码意外读了 Context,读到的还是本轮值;无害。
- reset_context :把
_CONTEXT重置为空 Context。
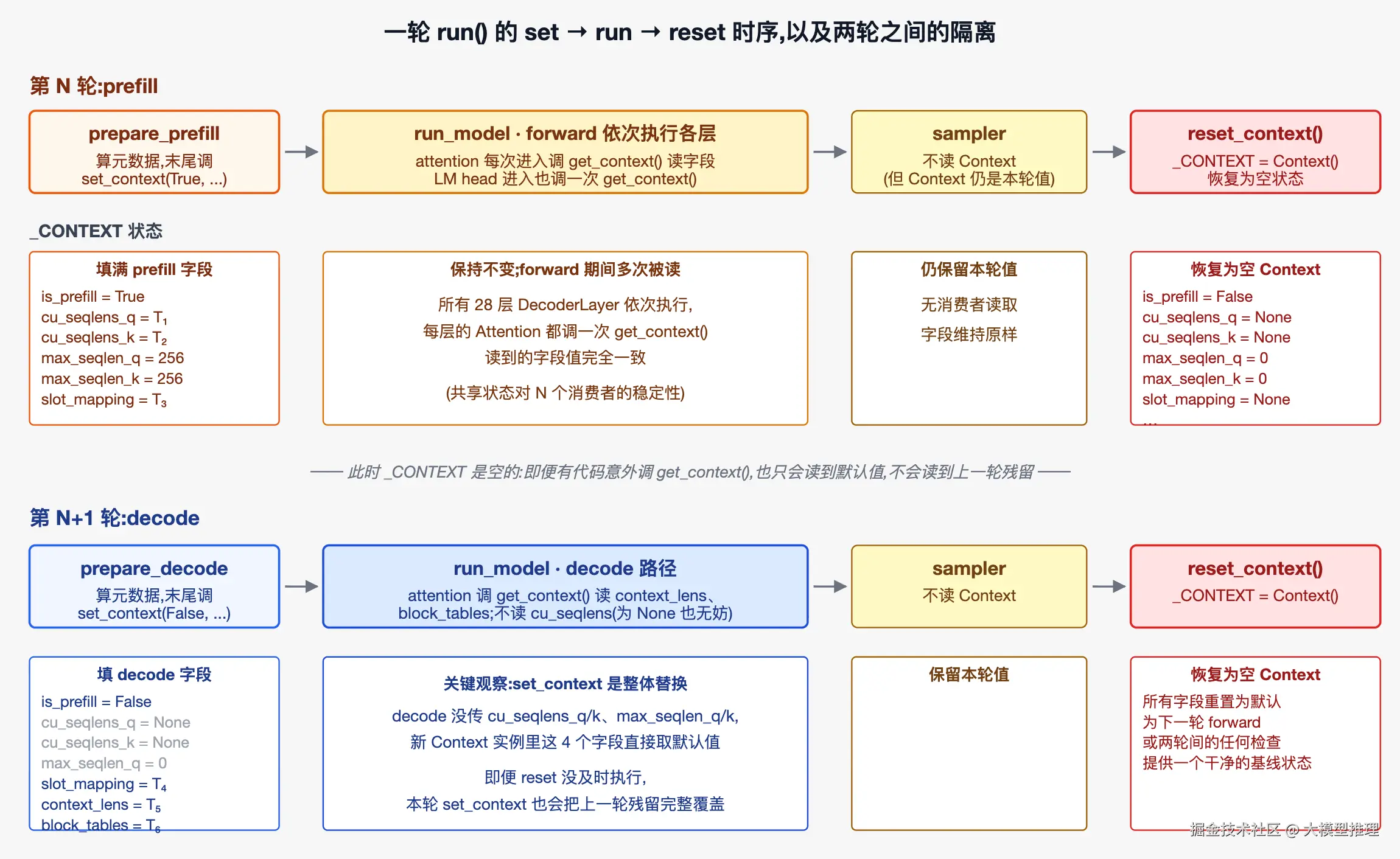
为什么 reset 不可省
这里有一个问题:第 3 节讲过 set_context 是整体替换,本轮没传的字段会被覆盖为默认值。那下一轮 prepare_* 末尾的 set_context 已经能覆盖本轮的所有字段,reset 的意义在哪?
答案是 reset 针对的不是"下一轮 set_context 到来之前",而是"两次 set_context 之间任何可能读 Context 的代码路径"。reset 的作用是把 Context 维持成一个可被检测出是空的状态------任何不在 forward 内的代码若读了 Context,看到的是默认值,可以立即识别为"当前不在 forward 上下文",避免依赖"下一次 set_context 一定会及时覆盖"的隐式约定。具体三个场景:
场景 1:run() 末尾到下一次 run() 开头之间 。reset_context() 之后、下一次 run() 调用 prepare_* 之前,如果有任何其他代码读了 get_context(),它读到的是空 Context------is_prefill=False、张量字段全 None。这种空状态会让消费者立即报错(读 None 张量后,任何调用其方法或取下标都会立刻抛异常),从而暴露 bug;如果不 reset,读到的是上一轮残留,可能"程序仍能执行完毕但结果错误",这种 bug 更难定位。
场景 2:capture_cudagraph 内的多次捕获 。set_context → forward 这个序列不止 run() 一处会执行。在未启用 enforce_eager 时,启动期会预捕获多张不同 batch size 的 CUDA Graph。每张 graph 的捕获都执行一次 set_context → forward → reset_context(见 model_runner.py:240-248),reset 保证两次捕获之间 Context 是空的,不互相影响。
场景 3:写一个新的元数据消费者。设想未来想加一个 hook,在 forward 之外的某处读 Context 做检查(比如打日志)。reset 让"forward 之外读 Context"这件事有明确语义------读到空就是"当前不在 forward 内"。
综合这三个场景,reset 的角色是让"不在 forward 内"成为可以被检查的状态,而不是依赖"下一次 set_context 一定会及时覆盖"这种隐含假设。
set/get/reset 这套时序之所以足以支持 Context 单例,前提是同一时刻只有一条 forward 流在读写它。这个前提本身就是全局变量这套设计的代价------并发场景下不可重入。既然全局变量是教科书反模式,nano-vllm 选它必然有代价。先列出这个代价,再说明它为何在 nano-vllm 这套架构下可以避免。
全局变量的代价:不可重入,以及它在 nano-vllm 里为什么可以避免
全局变量的经典代价是"不可重入"------所谓不可重入,指函数依赖了一份共享状态,若它在执行过程中被另一次调用打断、而那次调用改写了同一份共享状态,原先这次执行恢复后读到的值已被改写。同一进程内,如果两个并发流都要用这个变量,它们会互相覆盖。具体到 Context,如果同一进程内同时执行两条 forward 流:
- 流 A 调
set_context(True, ...)准备 prefill 元数据 - 流 B 在此期间调
set_context(False, ...)准备 decode 元数据 - 流 A 的 attention 内核调
get_context(),读到的是流 B 设的 decode Context
这种竞争在多线程、async 协程、流水并行下都可能发生。nano-vllm 选了全局变量,意味着接受"不能并发执行两条 forward 流"这个约束。
但代价能否接受要看实际架构。nano-vllm 单进程内 step 严格串行 :llm_engine.step() 一次只调一次 model_runner.run(),run 内部顺序执行到结束,中间不创建协程或线程。下一次 step 必须等本次 step 完整结束(包括 reset_context)才能开始。
多卡情况下,nano-vllm 用 tensor parallel(把模型权重切分到多张 GPU 并行计算)。每张 GPU 对应一个独立子进程,在 nano-vllm 里称为一个 rank。每个进程加载自己那份 utils/context.py,各自持有独立的 _CONTEXT 实例,互不影响。rank 0 与 rank 1 同时 forward 是物理并行,但它们读写的是各自地址空间里的全局变量,不存在竞争。
所以"全局变量不可重入"这个代价在 nano-vllm 这套架构下可以避免------单进程内串行、跨 rank 进程隔离,两条来源都被消除。这是设计选择与架构假设互相印证的例子:Context 单例的实现简洁性,建立在"step 串行 + 多进程 TP"这两个前置条件上;如果将来要把 nano-vllm 改成异步流水(例如 prefill 与 decode 并行交替),Context 这套机制就必须重做。
Context 的接口、生命周期、代价已经分析完毕。第 3 节末尾的两段调用对照已经列出 prepare_prefill 和 prepare_decode 末尾的 set_context 各自传入了哪些张量,但这些张量怎么从一批 seq 算出来,本节没有展开。下一节进入 prepare_prefill,逐步分析 cu_seqlens_q/k、slot_mapping、block_tables 这些字段在 prefill 路径下的构造过程。
5. 总结
本节的核心机制:把 Attention 内核需要的形状型元数据(cu_seqlens_q/k、max_seqlen_q/k、slot_mapping、context_lens、block_tables)从 forward 签名里抽出来,集中存进模块级 dataclass _CONTEXT。读完应记住三件事:
- 为什么用全局 :中间层(
Qwen3Model、DecoderLayer、Qwen3Attention)不消费这些字段、只向下传递;若塞进签名,28 层 DecoderLayer 都得携带 8 个不读的参数,字段演化代价沿调用栈线性放大。 - set/get/reset 的纪律 :
prepare_*末尾用整体替换写入_CONTEXT(不 mutate 已有字段),靠默认值覆盖上一轮残留;get_context只在attention.py与embed_head.py两处被调用;reset_context把"不在 forward 内"维持成可被检测的空状态。 - 代价为什么可以避免 :不可重入只在「同进程多并发流」时才会触发。nano-vllm 单进程内 step 严格串行、多卡用多进程 TP 让每个 rank 各持独立
_CONTEXT,两个触发条件都不存在------Context 单例的简洁性正建立在这两个架构假设上。