一句话总结
RLVR 中失败轨迹被统一惩罚是巨大的信息浪费。CIPO 通过纠错重放,让模型在看到自己错误的条件下重新生成答案,天然区分不同失败模式并提供差异化学习信号,无需任何外部标注
- 论文标题:Learning from Failures: Correction-Oriented Policy Optimization with Verifiable Rewards
- 论文地址 :https://arxiv.org/abs/2605.14539
- 作者背景:中科院软件所、小红书
一、动机
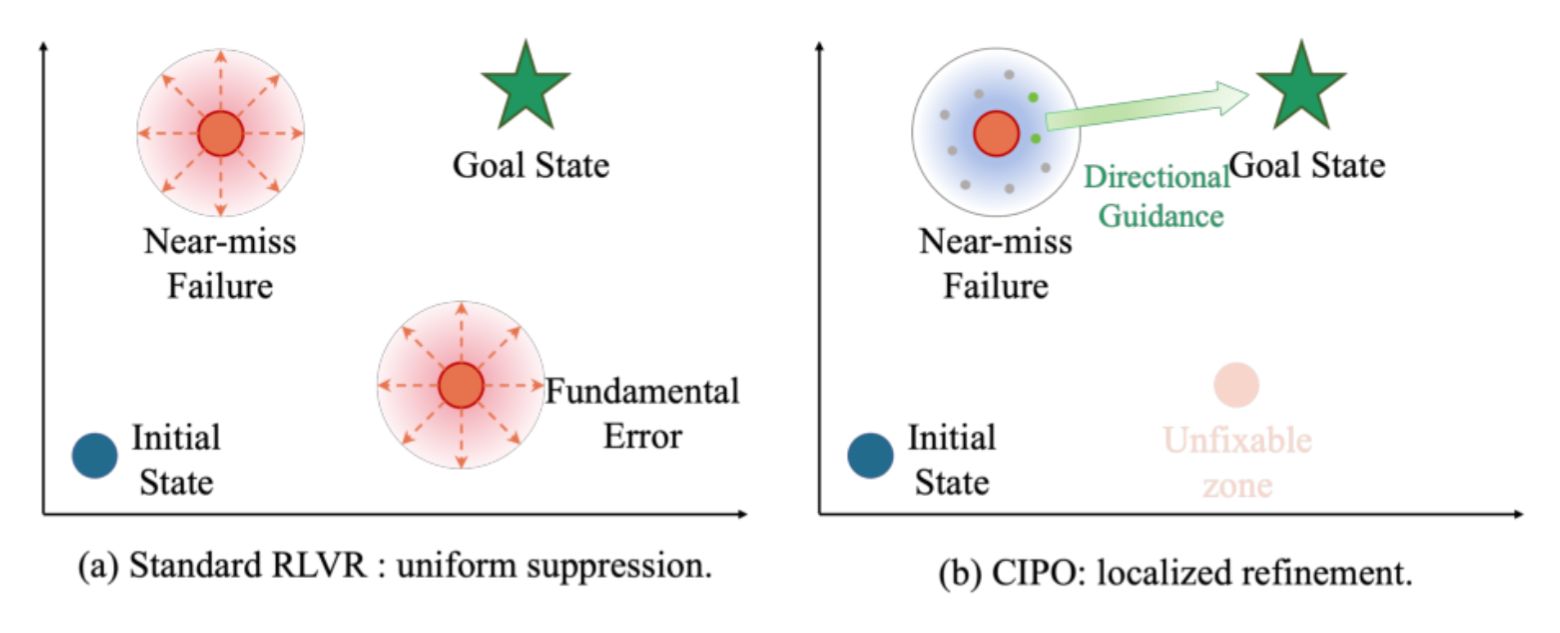
RLVR 的训练逻辑是:模型对同一个问题生成一组回答,答对的加强、答错的抑制。GRPO 在此基础上做了组内归一化,让优势信号更稳定。但核心问题没变 ------ 所有失败轨迹都被统一施加负向梯度,不管它是最后一步算错了还是从第一步就跑偏了
这带来两个问题:
- 梯度信号模糊:"差一步就对" 的轨迹和一个 "完全胡说" 的轨迹,在 GRPO 眼里是同等的坏样本。模型收到的优化方向是 "别这样做",但不知道 "该怎么改"
- 中间步骤浪费:失败轨迹中往往包含大量正确的推理步骤,直接抑制整条轨迹等于把这些有价值的部分也一起丢弃
之前的解决方案包括训练过程奖励模型(PRM)给每步打分、用 LLM 做 critic 提供反馈等,但都需要额外标注或计算资源,泛化性也存疑
二、实现方案
2.1 纠错重放
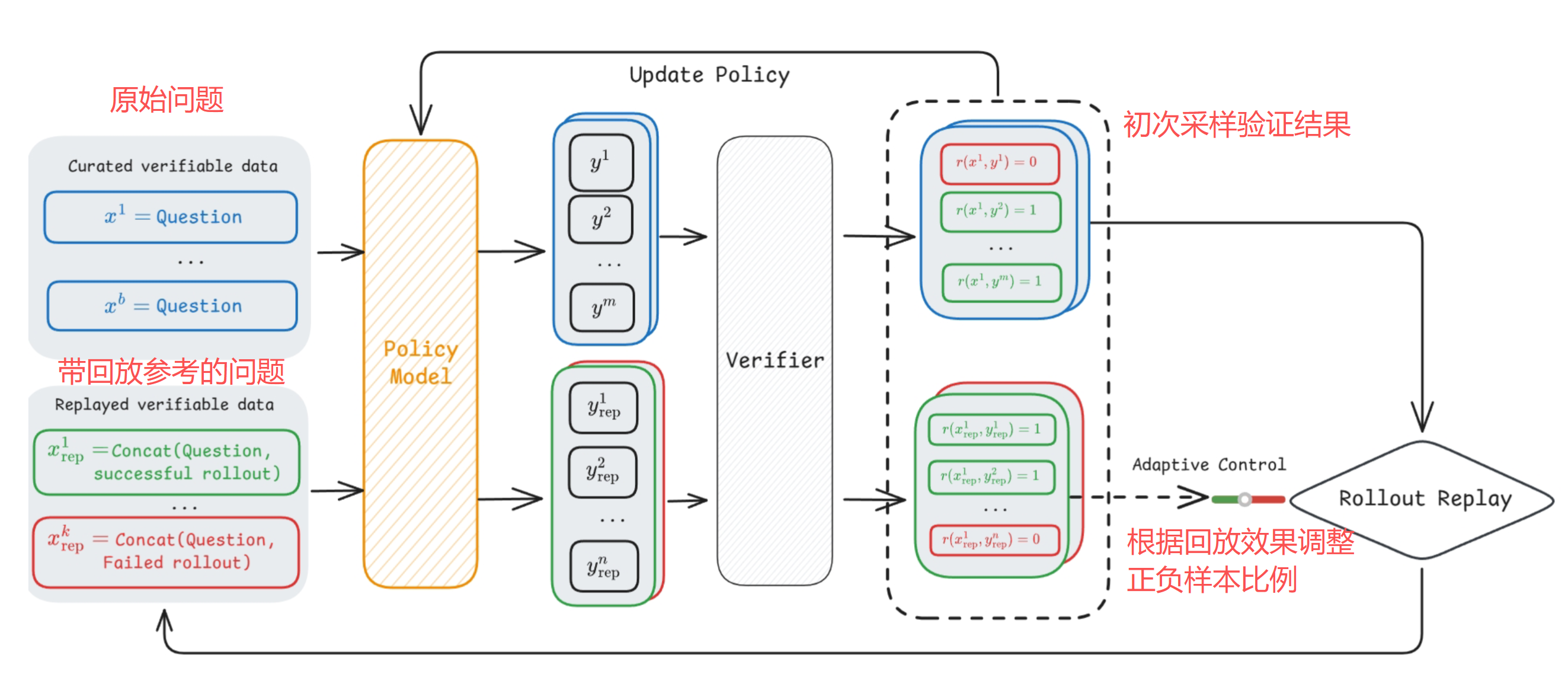
本文提出 CIPO(Correction-OrIented Policy Optimization),核心操作很简单:在每个训练步,除了标准的 GRPO 优化(Base Stream),额外构建一个 Correction Stream。具体做法是把模型的错误输出拼接到原始 prompt 后面,构造一个反思 prompt 让模型尝试优化:
bash
{原始问题}
以下是一个候选解决方案(其正确性未知):
<candidate_solution>
{模型之前的输出}
</candidate_solution>
请参考此解决方案,并提供您的解决方案关键设计:不告诉模型候选答案是对是错,避免模型学到 "看到这个模板就知道前面是错的" 这种捷径
一个 "差一步就对" 的轨迹,在纠错采样时很容易产生正确答案(因为大部分推理已经是对的)。而一个 "根本性错误" 的轨迹,纠错成功率很低。这种差异化的纠错概率,自动为不同失败模式提供了不同强度的学习信号,而无需任何过程标注
2.2 退化保护
直接把所有失败轨迹都拿来做纠错训练会导致策略退化,CIPO 设计了三个机制来保证稳定性:
-
自适应重放比例
维护一个动态参数 ρ 控制纠错流中成功/失败轨迹的混合比。当模型在成功轨迹上的保持能力下降时,增加成功轨迹比例防止遗忘;保持能力稳定时,允许更多失败轨迹进入纠错流加速学习。
-
风险规避奖励塑形
专门惩罚 "正确→错误" 的转换,即模型看到一个正确的候选答案却生成了错误的新答案。这是能力退化的直接信号,施加额外的 λ_risk 惩罚
-
难度感知轨迹偏好
优先选择中等难度的 prompt(pass rate 在 3/8~6/8 之间)做纠错重放。太简单的没有增量信息,太难的纠错也大概率失败。只有能力边界附近的题目学习效率最高
三、实验结果
3.1 实验设置
模型与训练数据:数学推理使用 Qwen3-4B-instruct,训练集为 DeepScalerR(约 4 万道数学题);代码生成使用 Seed-Coder-8B,训练集从 AM-DeepSeek-Distilled-40M 中筛选。所有模型训练 500 步,每批 128 题,每题采样 8 条轨迹,最大生成长度 4096 tokens
基线:GRPO(BS=128)为主基线;额外对比 GRPO(BS=256)和 GRPO(m=16, BS=128)以排除 "CIPO 计算量翻倍" 的解释;PRIME 作为引入额外监督信号的代表
3.2 数学推理与代码生成
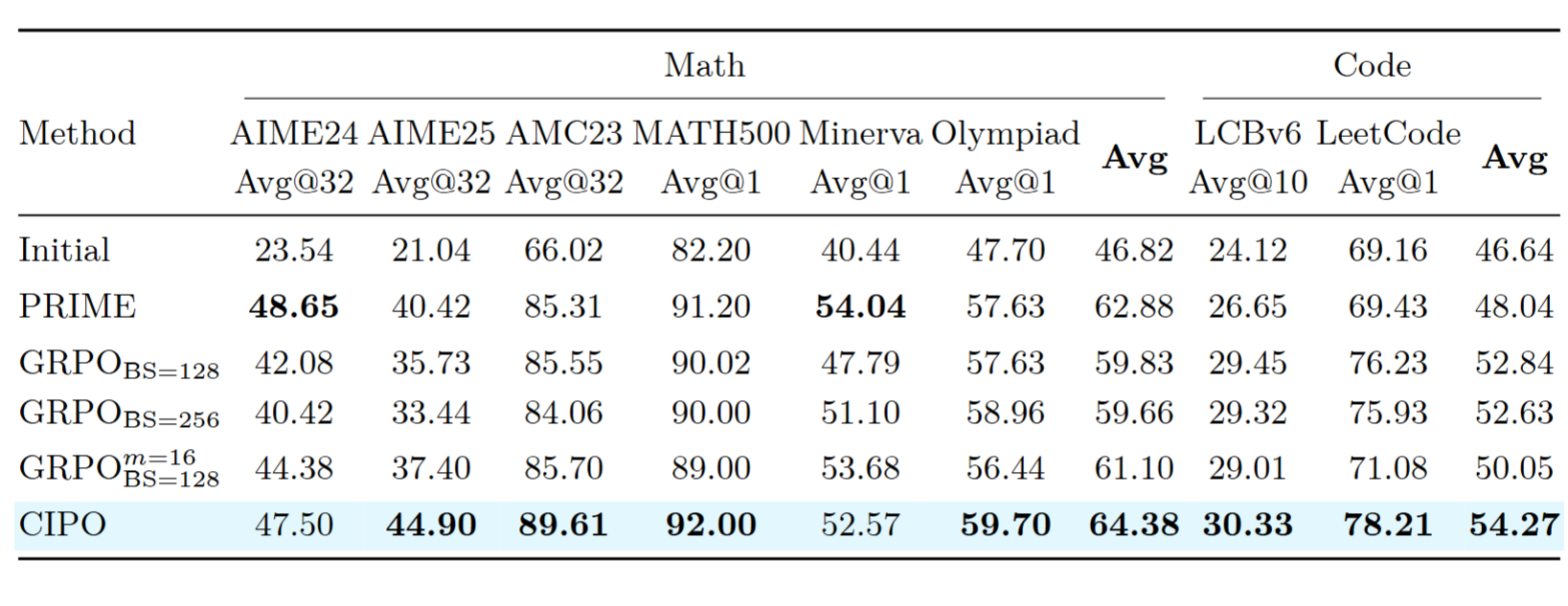
- CIPO 数学均值 64.38%,比 GRPO(BS=128)高 4.55 个百分点,比 PRIME 高 1.5 个百分点。在最难的 AIME25 上优势最明显
- GRPO(BS=256)把 batch size 翻倍,数学均值反而没涨,说明单纯堆采样量不解决问题
- 代码生成方面 CIPO 同样全面领先,LeetCode 78.21% 比 GRPO 高 2 个百分点
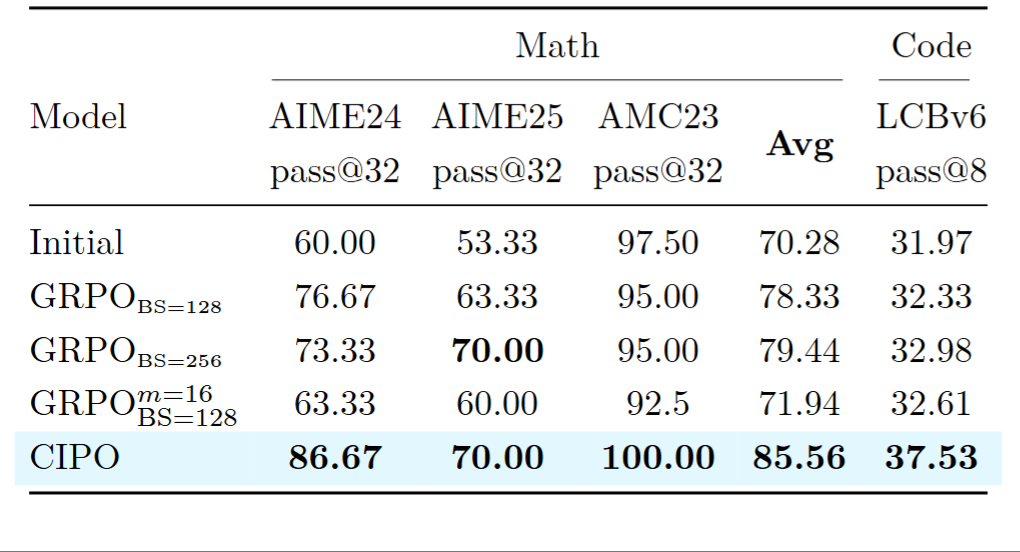
pass@K 衡量 "采样 K 次至少答对一次" 的概率。如果训练只是让模型对已经会做的题更有把握,pass@32 的优势不会太大
但 CIPO 的 pass@32 相比 GRPO 从 78.33 涨到 85.56,代码 pass@8 从 32.33 涨到 37.53,说明模型现在能解出一些之前即使采样 32 次也解不出的题,解题覆盖面真正扩大了
3.3 纠错能力与跨领域泛化
CriticBench 测试结果,展示了 CIPO 的纠错能力与泛化性
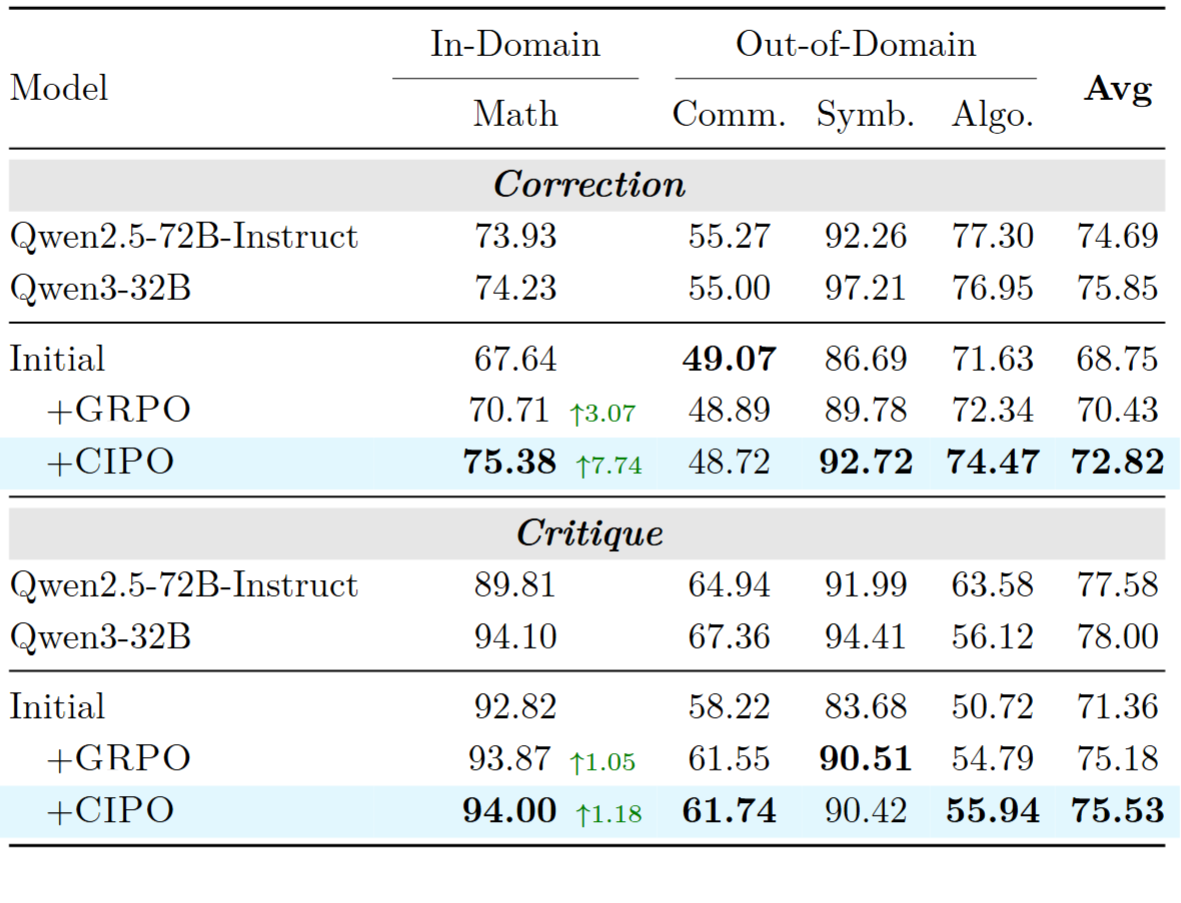
DebugBench 测试结果,展示 CIPO 训练后的代码调试能力。其中 w/ Intent、w/ Full Intent、w/o Intent 分别表示 debug 时提供简要功能描述、 提供完整题目描述、只给 buggy 代码不说明意图
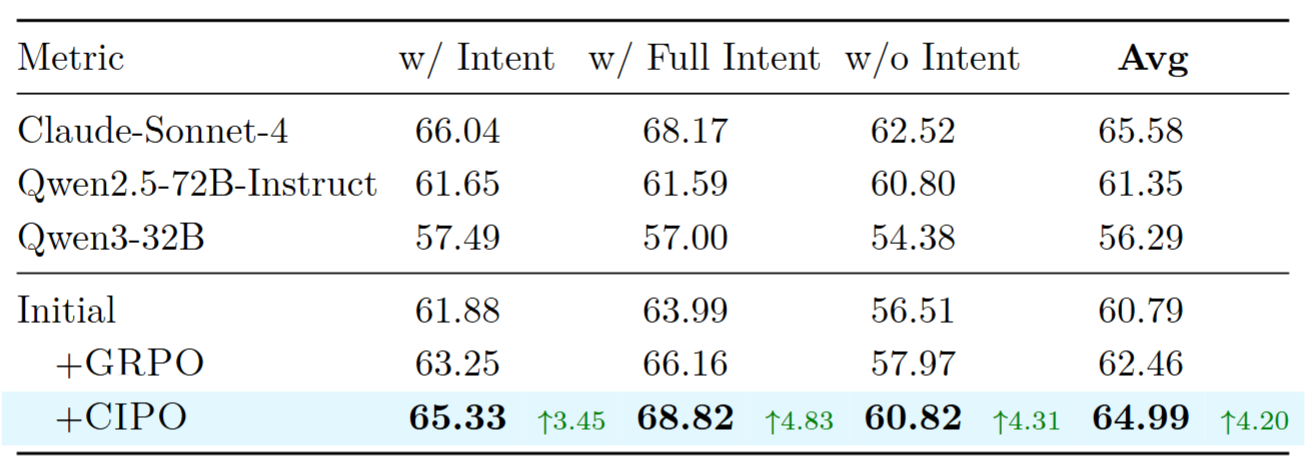
均值 64.99%,接近 Claude-Sonnet-4 的 65.58%,超过 72B 的 Qwen2.5-72B-Instruct
3.4 消融实验
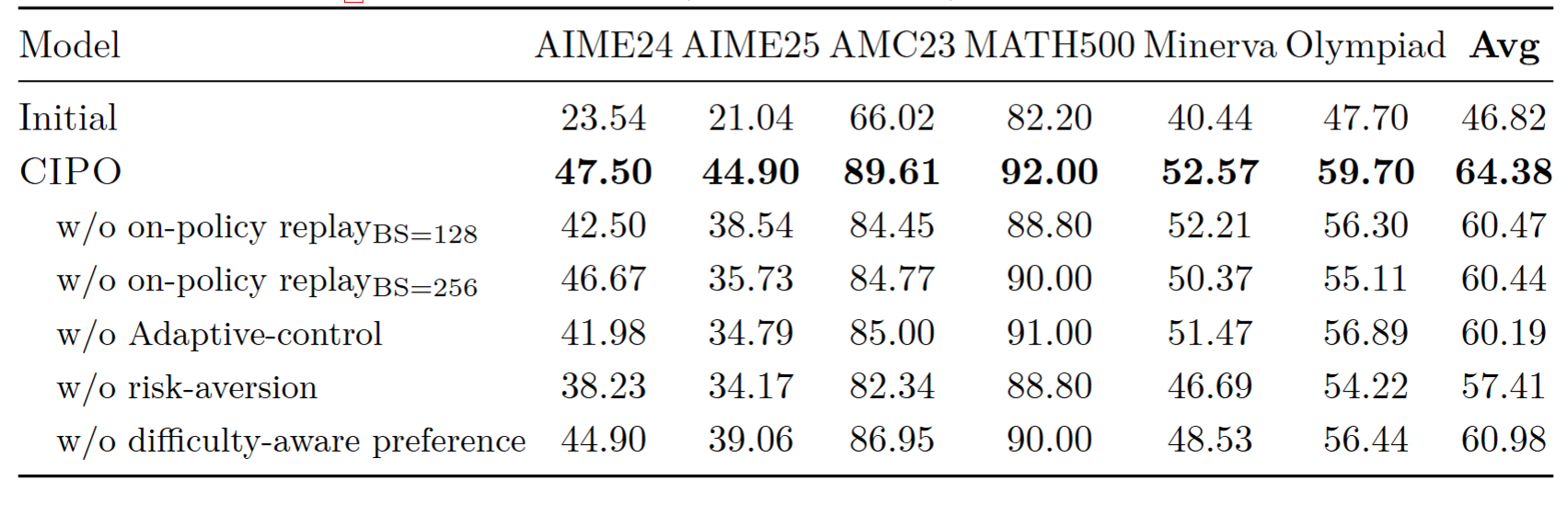
- 风险规避奖励塑形影响最大,去掉后模型在所有 benchmark 上全面退化。说明防止 "正确→错误" 的能力退化比加速学习更关键
- 自适应控制次之,固定 1:1 的成功/失败轨迹比例不如动态调节
- on-policy 重放 vs 离线:即使把离线版的 BS 翻倍,也追不上 on-policy 版,说明关键不是数据量而是纠错样本与当前策略分布的一致性
- 难度感知偏好:优先选中等难度题做纠错重放,避免在太简单或太难的题上浪费计算