🌈个人主页: 秦jh__https://blog.csdn.net/qinjh_?spm=1010.2135.3001.5343
🔥 系列专栏: https://blog.csdn.net/qinjh_/category_13137010.html

目录
[stream() 同步传输](#stream() 同步传输)
[astream() 异步传输](#astream() 异步传输)
[使用 StrOutputParser 解析模型的输出](#使用 StrOutputParser 解析模型的输出)
[SSE 协议介绍](#SSE 协议介绍)
[LangChain 流式传输流程分析](#LangChain 流式传输流程分析)
[LangChain 请求 OpenAI 使用什么协议?](#LangChain 请求 OpenAI 使用什么协议?)
[LangChain 如何支持流式传输?](#LangChain 如何支持流式传输?)
[OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk ?](#OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk ?)
[使用 LangSmith 跟踪 LLM 应用](#使用 LangSmith 跟踪 LLM 应用)
前言
💬 hello! 各位铁子们大家好哇。
今日更新了LangChain相关内容
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
流式传输
流式处理对于使基于 LLM 的应用程序能够响应最终用户至关重要。其通过逐步显示输出,甚至在完整 的响应准备就绪之前,流式传输可以显着改善用户体验。
我们之前直接使用 invoke 的调用方式属于非流式传输,看到的现象是聊天模型直接返回全量内容,若 模型思考时间较长,则我们等待的时间就越长。
stream() 同步传输
在 LangChain 聊天模型中,可以使用其 .stream() 方法,来同步生成流式响应的效果。 聊天模型的 .stream() 方法返回一个迭代器,该迭代器在生成输出时同步产生输出 消息块 。可以 使用 for 循环实时处理每个块。代码如下:
python
model = ChatOpenAI(model="gpt-4o-mini")
# 返回一个迭代器,产生的消息块
chunks = []
for chunk in model.stream("写一段关于春天的作文,1000字"):
chunks.append(chunk)
# chunk: AIMessageChunk
print(chunk.content, end="|", flush=True)通过调试,让我们来看下 chunk 是什么,见下图:

我们得到了一个叫做 AIMessageChunk 的东西,它代表 AIMessage 的一部分,也就是消息块。 消息块还可以直接相加,来看效果:
python
print(chunks[0] + chunks[1] + chunks[2] + chunks[3] + chunks[4])结果如下( AIMessageChunk ):
python
content='有一天,兔' additional_kwargs={} response_metadata={} id='run--
e619cbc3-9ee9-4ae7-a73e-32edb166d401'astream() 异步传输
对于流式传输,通常我们可以选择异步调用。先来了解下异步相关知识。
异步相关概念
想象一个场景:你需要煮一壶水,同时还要给朋友发一条短信。我们分别用同步(传统)和异步两种 方式来完成,以此对比并引入 协程 和 事件循环 的概念。
- **同步(阻塞)方式:**这就像是一个"死心眼"的人,做事必须一件一件来:
python
import time
def boil_water():
print("开始煮水...")
time.sleep(5) # 模拟阻塞等待5秒
print("水开了!")
def send_message():
print("开始发短信...")
time.sleep(2) # 模拟阻塞等待2秒
print("短信发送成功!")
# 主程序
def main():
boil_water() # 先花5秒煮水,期间什么也不能做
send_message() # 水开后再花2秒发短信
main()总耗时:7秒
问题: 在 boil_water 函数等待的5秒里,CPU 完全空闲,但却不能去做 send_message 任务, 效率低下。
- 异步方式:我们请出 asyncio 、 协程 和 事件循环 。
什么是协程?
- 多进程通常利用的是多核 CPU 的优势,同时执行多个计算任务。每个进程有自己独立的内存管 理,所以不同进程之间要进行数据通信比较麻烦。
- 多线程是在一个 cpu 上创建多个子任务,当某一个子任务休息的时候其他任务接着执行。多线程 的控制是由 python 自己控制的。线程存在数据同步问题,所以要有锁机制。
- 协程的实现是在一个线程内实现的,相当于流水线作业。由于线程切换的消耗比较大,所以对于 并发编程,可以优先使用协程。
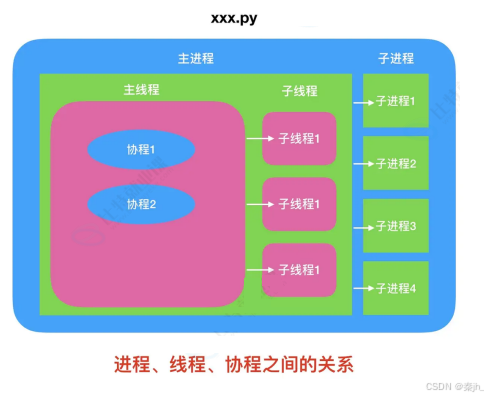
协程,作为一种轻量级的并发编程模型,可以被视为用户态的"轻量级线程"。 与传统线程相比,协 程的核心优势在于其调度完全由用户空间掌控,避免了操作系统内核的频繁介入,从而显著降低了上 下文切换的开销。 在诸如网络数据刷新、资源加载、用户界面更新、以及 I/O 读写等场景下,如果并 发任务的计算量相对较小、对系统资源占用较低,则不必动用操作系统级别的线程。
协程的切换则由程序员和编程语言控制,程序员决定在何时暂停或恢复协程。协程是一个特殊的函 数,它可以在执行过程中暂停,并在稍后恢复执行。它用 async def 定义,并在需要暂停的地方使 用 await 。
在我们的例子里, boil_water_async 和 send_message_async 就是两个协程。
python
# 异步 IO
import asyncio
# 协程
async def boil_water_async():
print("开始烧水...")
await asyncio.sleep(5) # 关键! await表示等待这个操作完成,但期间可以做别的事
print("烧水完成...")
# 协程
async def send_message_async():
print("开始发消息...")
await asyncio.sleep(2) # 模拟烧水2s
print("发消息完成...")什么是事件循环?
事件循环是 asyncio(Python 标准库中的模块,用于编写异步 I/O 操作的代码)的核心,你可以把它 想象成一个总调度员或一个高效的待办事项 (To-Do List) 管理员。
它的工作流程非常简单:
- 它维护着一个任务列表(比如:煮水、发短信)。
- 它不断地循环检查每个任务:
- 如果任务处于 "等待I/O" 状态(比如等水开、等网络响应),就暂停它,立即去执行下一个 已经 "就绪" 的任务。
- 如果任务的等待时间到了或者 I/O 操作完成了,事件循环就恢复执行这个任务。
如何运行?
python
# 协程:调度
# 事件循环
async def main():
# 1、烧水(任务)
task1 = asyncio.create_task(boil_water_async())
# 2、发消息(任务)
task2 = asyncio.create_task(send_message_async())
await task1
await task2
# 5s
# run 会创建一个事件循环
asyncio.run(main())输出结果:
python
开始煮水... # 任务1开始
开始发短信... # 任务1遇到await,立即让出控制权,事件循环马上启动任务2
(此时两个任务都在后台"等待")
(等待约2秒后...)
短信发送成功! # 任务2的等待时间先到,任务2完成
(继续等待约3秒后...)
水开了! # 任务1的等待时间也到了,任务1完成总耗时:5秒 (因为两个任务的等待时间是并发的)
通过使用 asyncio ,我们可以在单线程中同时处理多个任务。一个在单线程内调度和管理所有协程 的核心机制,就是事件循环。它不停地检查哪些协程可以执行,哪些在等待。
总结一下:
- 协程是 asyncio 的核心概念之一。它是一个特殊的函数,可以在执行过程中暂停,并在稍后恢 复执行。协程通过 async def 关键字定义,并通过 await 关键字暂停执行,等待异步操作完 成。
- 要运行一个协程,可以使用 asyncio.run() 函数。它会创建一个事件循环,并运行指定的协 程。事件循环是 asyncio 的核心组件,负责调度和执行协程。它不断地检查是否有任务需要执 行,并在任务完成后调用相应的回调函数。
使用
可以使用 .astream() 方法,来异步生成流式响应的效果,这专为非阻塞工作流程而设计。可以在 异步代码中使用它来实现相同的实时流式处理行为。代码如下:
python
# 异步流式输出
async def async_stream():
print("===异步调用===")
async for chunk in model.astream("写一段关于春天的作文,1000字"):
print(chunk.content, end="|", flush=True)
asyncio.run(async_stream())使用 StrOutputParser 解析模型的输出
还记得最早我们讲过 Runnable 接口:
Runnable 接口:
聊天模型、输出解析器等组件,都实现了 LangChain 的 Runnable 接口,他们都是 Runnable 接 口的实例。Runnable 定义了一个标准接口,允许 Runnable 组件:
- Invoked(调用): 单个输入转换为输出。
- Batched(批处理): 多个输入被有效地转换为输出。
- Streamed(流式传输): 输出在生成时进行流式传输。
- Inspected(检查): 可以访问有关 Runnable 的输入、输出和配置的原理图信息。
- Composed(组合): 可以组合多个 Runnable,以使用 LCEL 协同工作以创建复杂的管道。
- ......
可以看到,流式传输实际上并不算是聊天模型定义的能力,而是只要实现了Runnable 接口的实例都具 备的能力!!
但要注意,并非所有组件都必须实现流式处理:在某些情况下流式处理要么是不必要的,要么很困 难,要么根本没有意义。例如,以后我们会讲解的 Retrievers检索器 ,就不提供任何流式处理。
那么再得出一个关于流式传输的结论: .stream() 和 .astream() 方法产生的块类型取决于正在 流式传输的组件。例如,我们当前正在使用聊天模型的流式传输,返回的每个块都将是一个 AIMessageChunk 。但是,对于其他组件,块类型可能不同。
接下来让我们使用 LCEL 构建一个简单的链,该链结合了 模型 和 解析器 ,并验证流是否有效。不要 忘了使用 LCEL 创建的链也实现了 Runnable 接口。
我们将使用 StrOutputParser 来解析模型的输出,它从 AIMessageChunk 中提取内容字段,为 我们提供模型返回的令牌 。代码如下:
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出解析器
parser = StrOutputParser()
# 定义链
chain = model | parser
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话"):
print(chunk, end="|", flush=True)结果:
python
|在|星|空|下|许|下|心|愿|,|
|你的|笑|容|如|晨|光|温|暖|,|
|手|握|手|走|过|每|段|光|阴|,|
|无|论|风|雨|依|然|不|离|不|弃|,|
|爱|是|永|恒|,|心|与|心|相|连|。| ||自定义流式输出解析器
上面我们演示了如何让聊天模型进行流式输出。若此时我们希望修改上一步的输出样式(一个字或两 个字的输出),将输出改为一句话一句话的输出,同时保留流式处理功能。那么我们需要在链中使用 生成器函数,即可完成自定义流式输出的能力。
还记得之前说过,聊天模型的 .stream() 方法返回的是一个迭代器,该迭代器在生成输出时同步产 生输出 消息块 。那么我们的将实现的这些生成器的签名应该是 IteratorInput -> IteratorOutput 。或者对于异步生成器: AsyncIteratorInput -> AsyncIteratorOutput 。
下面是句号分隔列表的自定义输出解析器的示例:
python
# 组件1:聊天模型
model = ChatOpenAI(model="gpt-4o-mini")
# 组件2:输出解析器(str)
parser = StrOutputParser()
# 自定义生成器
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input:
buffer += chunk
# 遇到 。 需要刷新
while "。" in buffer:
# 找到 。的位置
stop_index = buffer.index("。")
# yield 用于创造生成器。将句号之前的内容(去除首尾空格)作为一个句子放入列表中并产出
yield [buffer[:stop_index].strip()]
# 更新缓冲区,保留句号之后的内容
buffer = buffer[stop_index + 1 :]
# 处理buffer最后几个字
yield [buffer.strip()]
# 定义链
chain = model | parser | split_into_list
# 返回一个迭代器,产生的消息块
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话,每句话用中文句号隔开。"):
print(chunk, end="|", flush=True)深度探索流式传输
SSE 协议介绍
HTTP 协议本身设计为无状态的请求-响应模式,严格来说,是无法做到服务器主动推送消息到客户 端,但通过 Server-Sent Events (服务器发送事件,简称 SSE)技术可实现流式传输,允许服 务器主动向浏览器推送数据流。
也就是说,服务器向客户端声明,接下来要发送的是流消息(streaming),这时客户端不会关闭连接, 会一直等待服务器发送过来新的数据流。
SSE(Server-Sent Events)是一种基于 HTTP 的轻量级实时通信协议,浏览器可以通过内置的 EventSource API 接收并处理这些实时事件。
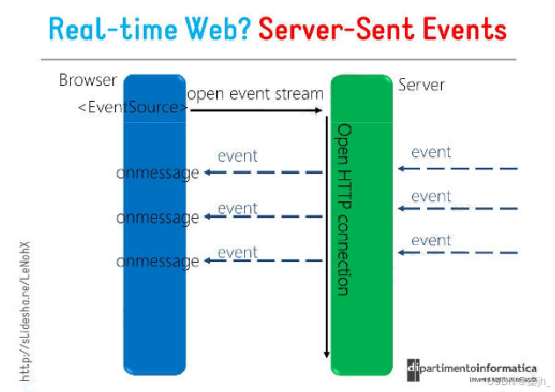
核心特点
- 基于 HTTP 协议
复用标准 HTTP/HTTPS 协议,无需额外端口或协议,兼容性好且易于部署。
- 单向通信机制
SSE 仅支持服务器向客户端的单向数据推送,客户端通过普通 HTTP 请求建立连接后,服务器可持续 发送数据流,但客户端无法通过同一连接向服务器发送数据。
- 自动重连机制
支持断线重连,连接中断时,浏览器会自动尝试重新连接(支持 retry 字段指定重连间隔)
- 自定义消息类型
客户端发起请求后,服务器保持连接开放,响应头设置 Content-Type: text/eventstream ,标识为事件流格式,持续推送事件流。
数据格式
服务端向浏览器发送 SSE 数据,需要设置必要的 HTTP 头信息:
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive
每一次发送的消息,由若干个 message 组成,每个 message 之间由 \n\n 分隔,每个 message 内 部由若干行组成,每一行都是如下格式:
field: value\n
Field 可以取值为:
- data必需:数据内容
- event非必需:表示自定义的事件类型,默认是message事件
- id非必需:数据标识符,相当于每一条数据的编号
- retry非必需:指定浏览器重新发起连接的时间间隔
除此之外,还可以有冒号 : 开头的行,表示注释。
LangChain 流式传输流程分析
LangChain 本身并不"创造"或"规定"一个底层的网络传输协议,而是依赖于其底层的大模型供应 商(如 OpenAI)和我们自身服务应用所使用的 Web 框架(如 FastAPI)的协议。
因此对于 LangChain 的流式传输能力,本身是因为大模型供应商提供了流式传输能力,由 LangChain 进行调用后接收并处理成一个个的 AIMessageChunk 。
通过源码分析流程
接下来我们将会通过分析相关源码探索整个传输流程。整个过程我们以 OpenAI 举例,其他大模型方 式类似,可自行探索。当我们向 OpenAI 发起流式请求,LangChain 实际上会通过 BaseChatOpenAI 类中的 _stream() 方法发起调用。
下面来看下 _stream() 方法的关键流程性源码,完整源码见:
class langchain_openai.chat_models.base.BaseChatOpenAI
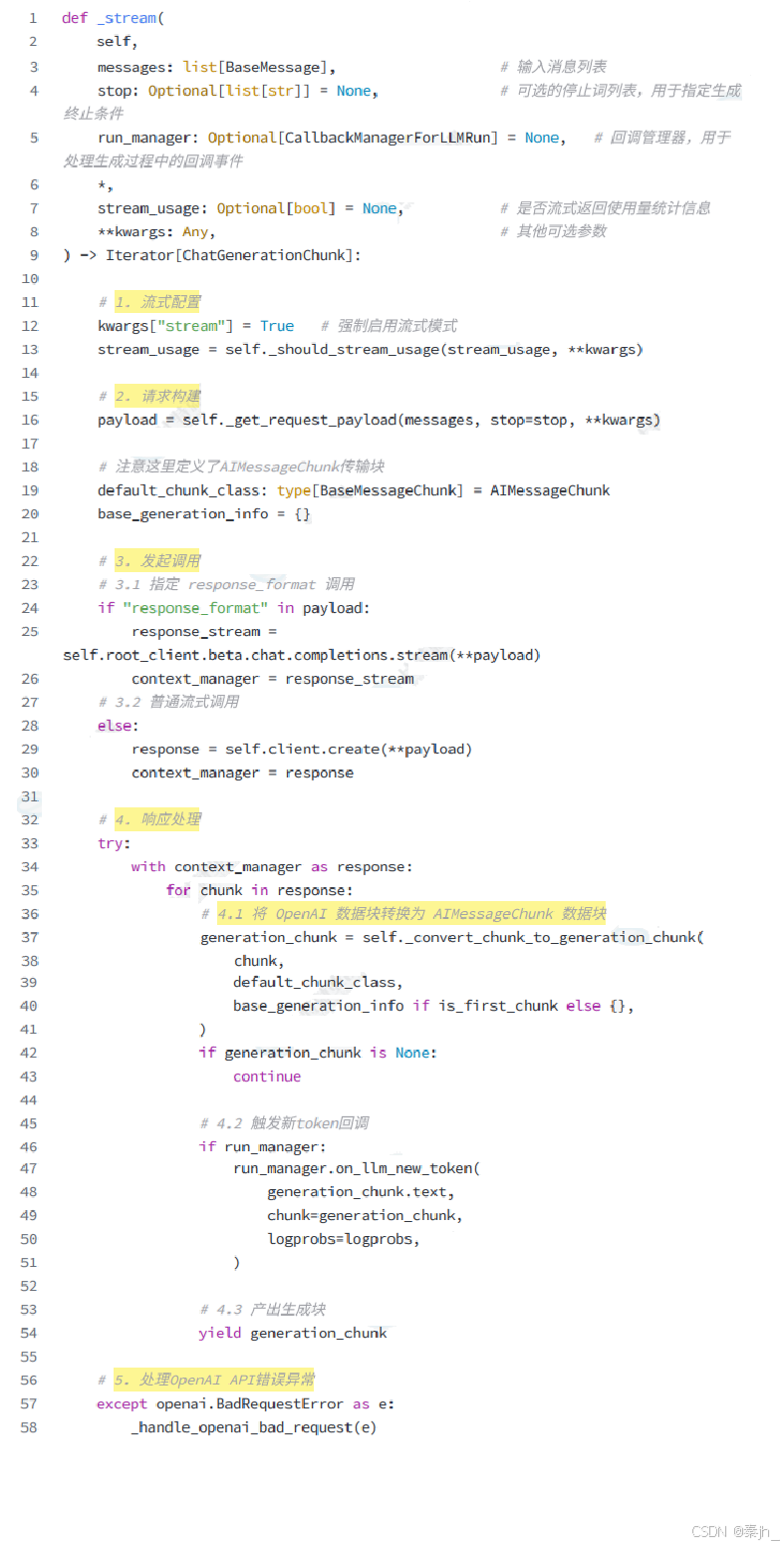
从上述流程看来,这就是流式逐块产生 AIMessageChunk 聊天消息的核心方法。那么接下来看三个 问题:
- 发起调用时,底层使用什么协议?
- 如何支持流式传输?
- 返回的块是什么格式,如何转换成 AIMessageChunk ?
LangChain 请求 OpenAI 使用什么协议?
回答这个问题,需要看 LangChain 关于 OpenAI 的客户端是怎么定义的。让我们找到 class langchain_openai.chat_models._client_utils._SyncHttpxClientWrapper ,如下 所示:
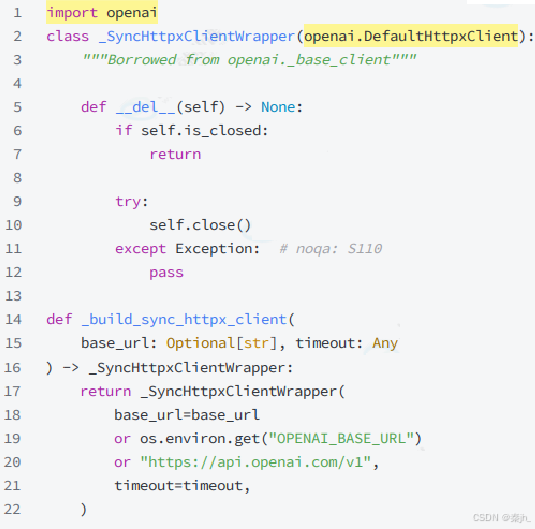
从上面的代码看来,LangChain 使用了 OpenAI 的官方的 OpenAI SDK for Python 接入方式,继承了 openai._base_client 定义了一个 HTTP 客户端。因此在调用时,发起的是 HTTP 调用。
LangChain 如何支持流式传输?
开始我们就说了,LangChain 本身并不"创造"或"规定"一个底层的网络传输协议,而是依赖于其 底层的大模型供应商(如 OpenAI)的协议。
因此当我们发起请求时,会在请求中设置 stream=True ( _stream() 源码中的第一步),表示 OpenAI 服务器将在生成 Response 时向客户端发出数据(server-sent events,SSE)。此时 API 会保持 HTTP 连接打开,并以特定格式发送数据。
例如我们向原生的 GPT 模型发起一次设置了 stream=True 的 HTTP 请求: "你好,我是张 三。" 。此时,我们会收到来自 OpenAI 的事件块(简化后的有效负载序列):

看了上述示例,我们应该可以回答第二个问题。那就是在请求中设置 stream=True 开启 OpenAI 服 务端返回数据块! LangChain 通过 _stream() 方法步骤1、2完成这件事。
OpenAI 返回的块是什么格式,如何转换成 AIMessageChunk ?
OpenAI 返回的数据块格式我们已经看到了,将其转换为 LangChain 自定义的 AIMessageChunk 则 是通过 _convert_chunk_to_generation_chunk() 方法完成的。关键代码如下:


到此我们就知道了LangChain流式传输的完整流程与底层协议。总结一下:
- langchain-openai 包通过集成 OpenAI Python SDK,提供了一个 HTTP 客户端。
- 因此,支持 LangChain 向 OpenAI 的 API 发起调用请求。
- 若希望发起流式传输请求,则需在请求中加入 stream=True ,向 OpenAI 说明以 SSE 协议进行 流式返回。
- LangChain 接收 OpenAI 的 SSE 格式的响应,并将其转换为 LangChain 自封装的消息格式,如 AIMessageChunk 消息。这样就可以以统一的方式处理来自不同模型提供商(OpenAI, Anthropic等)的流式响应。
使用 LangSmith 跟踪 LLM 应用
使用 LangChain 构建的许多应用程序,可能会包含多个步骤和多次的 LLM 调用。随着这些应用程序变 得越来越复杂,作为开发者,我们能够检查链或代理内部到底发生了什么变得至关重要。最好的方法 是使用 LangSmith。
LangSmith 与框架无关,它可以与 langchain 和 langgraph 一起使用,也可以不使用。LangSmith 是 一个用于帮助我们构建生产级 LLM 应用程序的平台,它将密切监控和评估我们的应用。
LangSmith 平台地址:https://smith.langchain.com/ (新用户需要注册)
要想让 LangSmith 跟踪 LLM 应用,第一步申请 LangSmith API Key,点击 Settings,就会跳转 到"API Keys"设置页面,若没有跳转,可以在左侧 tab 栏中找到进入。
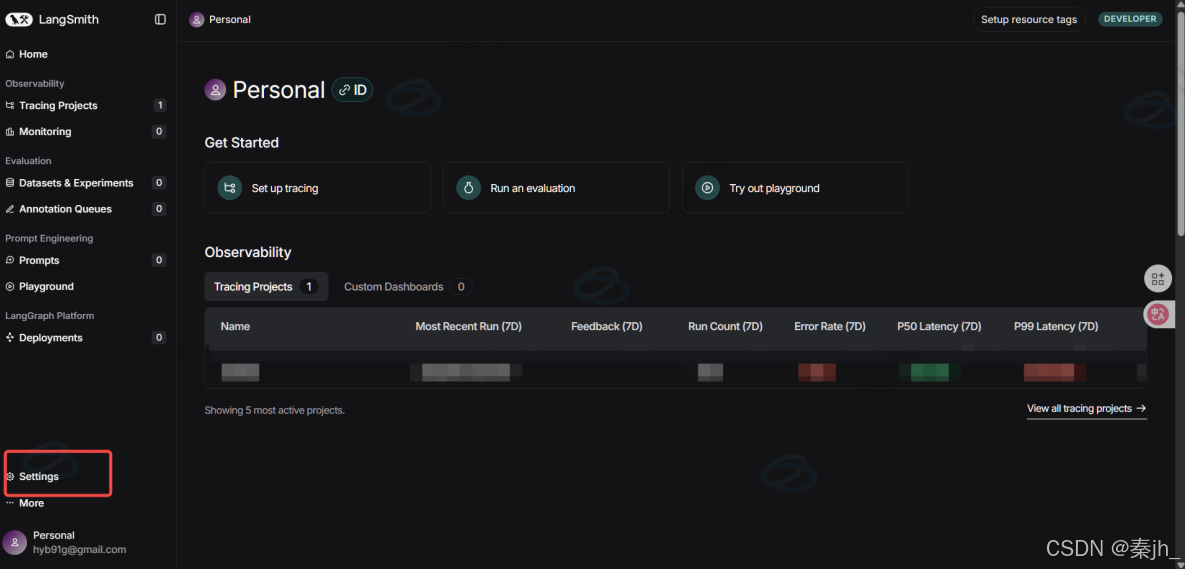
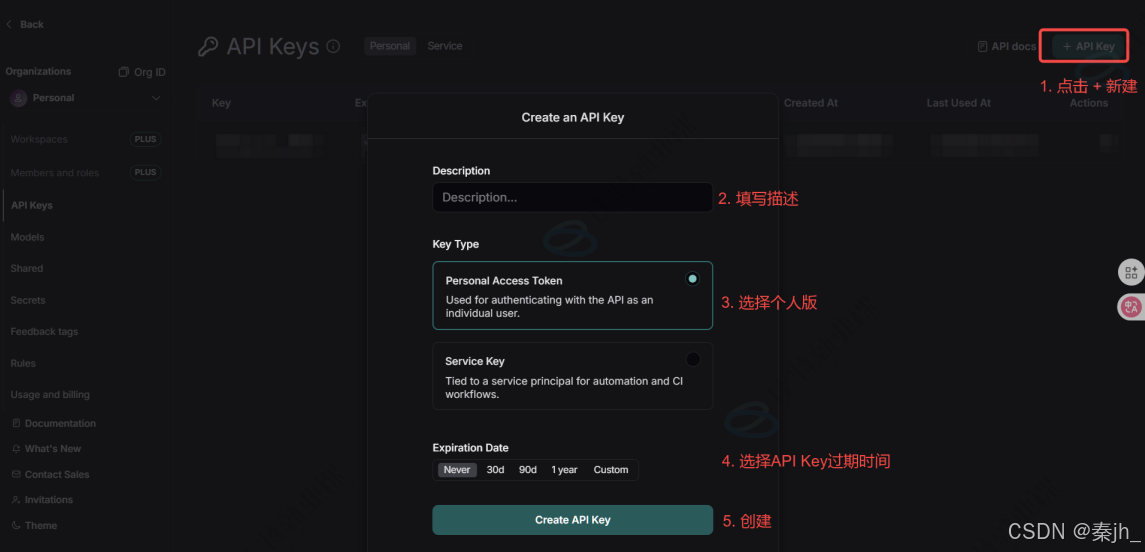
创建完成后,保存好你的 API Key。 接下来配置两个环境变量:
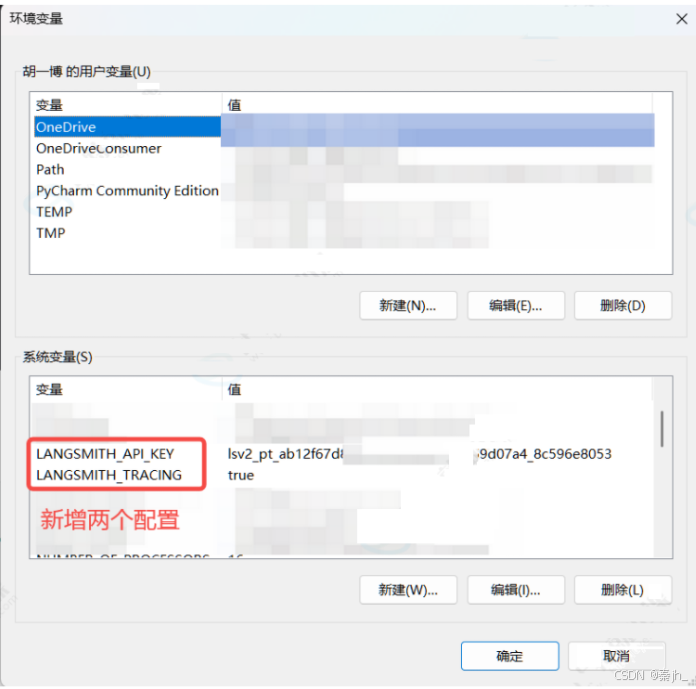
执行任意代码,查看 LangSmith 平台,这将在 LangSmith 的默认跟踪项目中生成调用的跟踪。点击最新一次的调用 追踪:
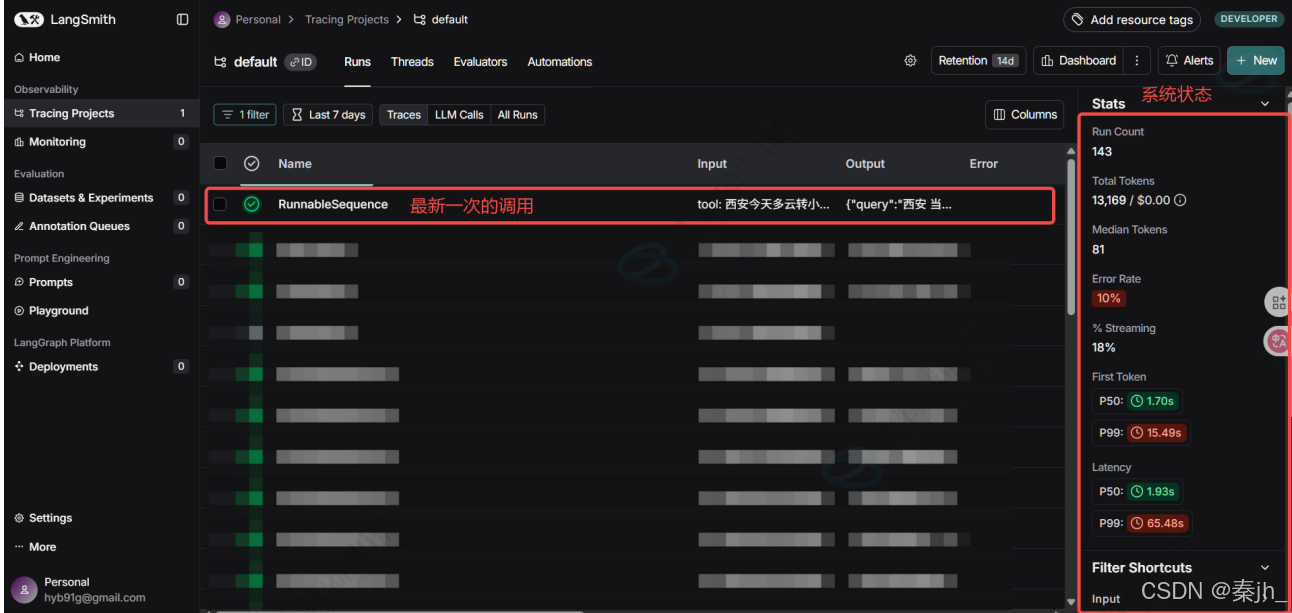
跟踪会以瀑布流形式展示调用的完整步骤,以及每个步骤的详细信息和耗时。让我们能够检查内部到 底发生了什么!!
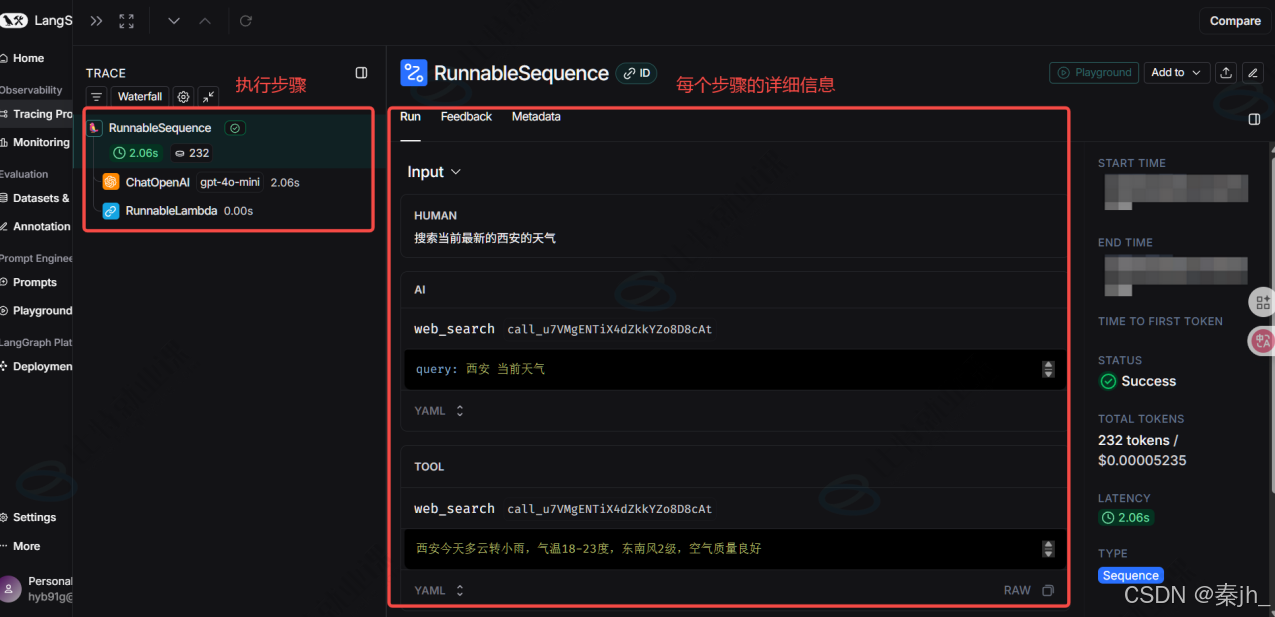
解释:
- RunnableSequence :可运行序列,就是我们之前讲过的 链 ,即我们将 model_with_search.invoke() 的结果(构造成 ToolMessage ),当作入参传递给 structured_search_model.invoke()。
- 说明:本次调用是RunnableSequence。但不是每次都展示RunnableSequence,根据实际情 况而定。
- ChatOpenAI :实际处理的第一步内容,调用聊天模型,生成结果。
- RunnableLambda :实际处理的第二步内容,表示将 python 可调用对象转换为 Runnable , 其实就是将 AI 生成的结果转换成为结构化对象。
可以看到我们在使用 LangSmith 时没有代码介入,只需要配置下环境,就可以直接监控我们的应用。