我做了一个很有意义的盲人出行辅助系统原型,主要是结合现有导航OSRM/高德,实时感知前方潜在危险目标,辅助视障人士出行。 持续优化中(20260519),欢迎大家尝试,有一些想法也可以提出来。
1. 项目背景
对于视障人群来说,日常出行可以通过高德等等进行路线导航,但是在到达过程中最困难的是持续感知环境风险。传统导航软件可以告诉用户"往哪里走",但是没法告诉用户"前方是否有行人、障碍物、台阶或者车辆"。而纯视觉系统虽然能识别环境,却缺少路径导航和实时位置联动功能。
针对以上问题,我做了一个原型项目 **EyeGuide。**这个系统通将摄像头视觉感知、地图导航、GPS定位和语音播报串成一条完整链路,让系统不仅能"规划路线",还能"观察前方环境实时提醒用户"。
这个项目更偏向一个工程原型和技术验证系统,终点不是做成商业的最终产品,如果要商用,后面可以嵌入开发板。但是嵌入之前还有一些工作需要做,比如功能的完善、推理加速等等,这些内容我还在持续优化中。
2. 项目目标
项目核心目标:
- 实时感知用户前方环境,识别潜在危险目标。
- 支持步行导航,并结合当前GPS定位实时推进导航。
- 通过语音播报,把环境信息和导航信息及时传递给用户。
3. 系统主要功能
界面目前比较简单,还请忽略我这个太草率了。后面功能完善之后会优化界面。
3.1 自由探索模式
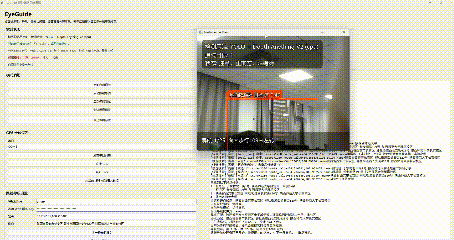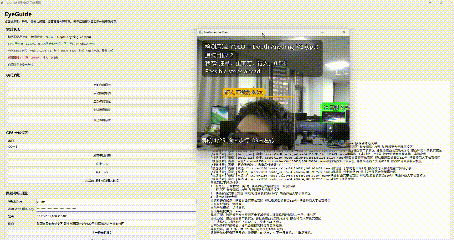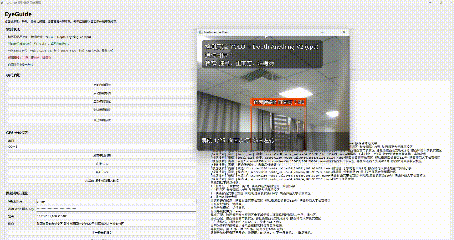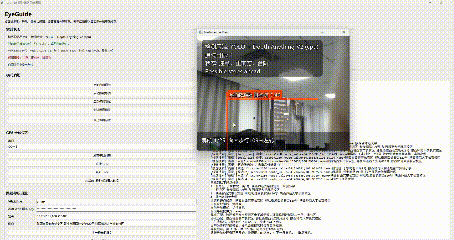
在自由探索模式下,程序会调用摄像头实时读取画面,并进行目标识别。系统会重点关注以下几类对象:行人、汽车、摩托车、台阶/高度变化区域。
对于靠近用户、存在风险的目标,系统会进行语音提示,比如:"注意,正前方,行人,1.0米"
3.2 路线导航模式
在路线导航模式下,用户输入起点和终点后,系统会调用地图服务生成步行路线,并在导航过程中实时播报当前导航步骤以及前方的危险目标。
项目目前支持两类导航来源:
OSM:基于Nominatim + OSRM
高德:基于高德Web服务API
3.3 GPS定位接入
为了实现边走边导航,项目支持接入USB/NMEA GPS模块,读取串口中的定位信息。如果没有外接GPS,系统会尝试调用Windows自带定位服务作为补充。这样可以实现获取当前位置、自动将当前位置填入导航起点、根据实时位置动态推进路线步骤。
4. 核心技术方案
4.1 视觉感知:YOLO 与 OpenCV双路径检测
在视觉感知部分,项目优先采用 Ultralytics YOLO 进行目标检测与目标跟踪,用于识别行人、车辆、自行车、障碍物等目标;在深度模型可用时,再结合 Depth Anything V2 对目标距离进行估计。
与此同时,系统并不完全依赖 YOLO。为了保证在依赖不完整、模型不可用或部署环境受限时仍能运行,项目还实现了一套基于 OpenCV 的启发式检测方案,主要包括:
- 行人检测
- 地面障碍物检测
- 台阶/高度变化风险检测
目前 YOLO 检测用的还是开源权重,后面可能会爬一些数据,针对盲人出行常会遇到的障碍再进行微调训练。
4.2 深度估计:Depth Anything V2
仅仅知道前面有什么肯定不够,所有引入了深度估计进行单目深度估计,用来辅助计算目标和用户之间的大致距离。这里的距离并不是激光雷达那种严格物理测距,而是基于深度模型对单帧图像做推理得到的近似值。这里的距离也会用于风险等级评估,比如估计距离为0.8m以内,那这个风险等级就比较高。
4.3 方位判断
方位判断目前采用的是比较直接但很实用的方法,根据目标框中心点在画面中的横向位置,把目标划分成几个区域:左侧、左前方、正前方、右前方、右侧。这样系统就可以播报更具体的提示,比如:"左前方,行人,1.2米"。
4.4 地图导航
导航采用了两种实现路线。
OSM路线
- 使用 Nominatim 做地理编码与地点搜索
- 使用 OSRM 的 foot 模式做步行路线规划
高德路线
- 使用高德的 POI 搜索、地理编码和步行导航接口
- 更适合中文地址场景,尤其是国内地点检索
此外,为了避免地址模糊匹配错误,系统对候选地点做了多结果展示,让用户自己确认终点,而不是强行只用第一条结果。
4.5 语音播报机制
语音播报使用 Windows 下的 SAPI / pyttsx3 作为输出后端。为了避免播报过于频繁和混乱,系统在语音层做了几项处理:
- 去重
- 冷却时间控制
- 优先级控制
- 队列替换策略
这样可以尽量减少"同一目标每一帧都播报一次"的问题,让播报更接近真实辅助场景。
5. 项目整体架构
整个系统大体可以分成四层:
感知层
负责摄像头读取、YOLO 检测、深度估计、障碍物识别与方位判断。
定位与导航层
负责 GPS 接入、当前位置更新、地址解析、路线规划和自动导航推进。
播报层
负责把检测事件与导航事件统一送入语音队列,再根据优先级和冷却策略进行播报。
界面层
使用桌面 GUI 展示控制面板,同时显示视频窗口、导航信息和运行日志。
6. 当前存在的问题
这个项目目前仍然是原型系统,还存在不少问题:
- 单目深度估计的距离误差仍然比较明显
- 复杂场景下目标检测稳定性还有提升空间
- 语音播报策略还需要继续优化,避免漏报或重复播报
- 导航与视觉提示的融合逻辑还不够细腻
- 打包部署体积较大,依赖项较重
这些问题也说明,视障辅助出行系统并不是单一模型就能解决的,而是一个需要持续工程优化和多模块协同的复杂系统。
7. 后续优化方向(持续优化中)
后续我计划继续完善:
- 优化 YOLO 与深度估计的推理效率
- 进一步减少语音播报重复和队列冲突
- 增强对台阶、坑洞、盲道、路沿等关键场景的识别能力
- 提升路线跟踪与自动重规划能力
- 做更轻量的部署方案,降低安装包体积
- 进一步适配新电脑开箱即用的安装流程
8. 展示
高清视频:
https://live.csdn.net/v/527244![]() https://live.csdn.net/v/527244
https://live.csdn.net/v/527244