这篇文章核心点在于轻量级的将depth anything 融合到实时立体匹配中:
1.单目神经网络特征层与单目纹理特征融合有点像fast foundation stereo
2.没有构建3D cnn 而是利用深度信息指导特征聚合过程,构建动态卷积核,应对病态区域。
3.虽然超过了现有实时立体匹配,但是没有在板端数据
总结来说,创新性有,但是针对实时性网络,感觉针对性没有那么强,没有fast foundation stereo工作那么扎实,也没有fast foundation stereo工程价值这么高。
Generalized Geometry Encoding Volume for Real-time Stereo Matching
(Jiaxin Liu, Gangwei Xu, et al.,CVPR/TPAMI 2025)
文章目录
- [*Generalized Geometry Encoding Volume for Real-time Stereo Matching*](#Generalized Geometry Encoding Volume for Real-time Stereo Matching)
-
- 一句话总结
- [0. 论文概述(Executive Summary)](#0. 论文概述(Executive Summary))
- [1. 问题背景与动机](#1. 问题背景与动机)
- [2. 相关工作与创新关联](#2. 相关工作与创新关联)
-
- [2.1 前人工作综述](#2.1 前人工作综述)
- [2.2 存在的问题与不足](#2.2 存在的问题与不足)
- [2.3 本论文与前人工作的关系](#2.3 本论文与前人工作的关系)
- [3. 贡献与核心创新点](#3. 贡献与核心创新点)
-
- [3.1 创新点一:泛化几何编码体积(Generalized Geometry Encoding Volume, GGEV)](#3.1 创新点一:泛化几何编码体积(Generalized Geometry Encoding Volume, GGEV))
- [3.2 创新点二:深度感知动态代价聚合(Depth-aware Dynamic Cost Aggregation, DDCA)](#3.2 创新点二:深度感知动态代价聚合(Depth-aware Dynamic Cost Aggregation, DDCA))
- [4. 方法与网络设计](#4. 方法与网络设计)
-
- [4.1 整体网络架构概览](#4.1 整体网络架构概览)
-
- [4.1.1 网络四层结构](#4.1.1 网络四层结构)
- [4.1.2 信息流向图示(文字描述)](#4.1.2 信息流向图示(文字描述))
- [4.1.3 各模块功能概述](#4.1.3 各模块功能概述)
- [4.2 网络详细分析](#4.2 网络详细分析)
-
- [4.2.1 SCF(Selective Channel Fusion)模块详解](#4.2.1 SCF(Selective Channel Fusion)模块详解)
- [4.2.2 DDCA(Depth-aware Dynamic Cost Aggregation)模块详解](#4.2.2 DDCA(Depth-aware Dynamic Cost Aggregation)模块详解)
- [4.2.3 深度感知迭代细化(Depth-aware Iterative Refinement)](#4.2.3 深度感知迭代细化(Depth-aware Iterative Refinement))
- [4.2.4 损失函数与训练策略](#4.2.4 损失函数与训练策略)
- [5. 实验结果](#5. 实验结果)
-
- [5.1 数据集与评估指标](#5.1 数据集与评估指标)
- [5.2 消融研究(Ablation Study)](#5.2 消融研究(Ablation Study))
- [5.3 性能对比](#5.3 性能对比)
- [5.4 限制条件下的性能分析](#5.4 限制条件下的性能分析)
- [6. 不足之处与未来工作](#6. 不足之处与未来工作)
- [7. 总体评价](#7. 总体评价)
- 附录:关键中英对照
- 深度感知动态代价聚合(DDCA)模块全面解析
-
- [1. 白话解释:DDCA 在做什么?](#1. 白话解释:DDCA 在做什么?)
- [2. 结合论文表述与公式的详细解释](#2. 结合论文表述与公式的详细解释)
-
- [2.1 输入与目标](#2.1 输入与目标)
- [2.2 步骤一:构建 Query 和 Key(公式 4)](#2.2 步骤一:构建 Query 和 Key(公式 4))
- [2.3 步骤二:生成动态卷积核并聚合(公式 6)](#2.3 步骤二:生成动态卷积核并聚合(公式 6))
- [2.4 大核 + 小核组合](#2.4 大核 + 小核组合)
- [2.5 最终输出:泛化几何编码体积](#2.5 最终输出:泛化几何编码体积)
- [2.6 为什么 DDCA 能增强泛化能力?(论文图 3 解释)](#2.6 为什么 DDCA 能增强泛化能力?(论文图 3 解释))
- [3. DDCA 与普通 3D 卷积(沙漏网络)的计算量对比](#3. DDCA 与普通 3D 卷积(沙漏网络)的计算量对比)
-
- [3.1 普通 3D 卷积计算量](#3.1 普通 3D 卷积计算量)
- [3.2 DDCA 的计算量](#3.2 DDCA 的计算量)
- [3.3 定量对比](#3.3 定量对比)
- [3.4 实验数据佐证(论文表 4)](#3.4 实验数据佐证(论文表 4))
- [4. 动态卷积核的含义及与普通卷积核的区别](#4. 动态卷积核的含义及与普通卷积核的区别)
-
- [4.1 普通卷积核:固定、全局共享、不依赖输入](#4.1 普通卷积核:固定、全局共享、不依赖输入)
- [4.2 DDCA 的动态卷积核:根据输入动态生成、像素级自适应](#4.2 DDCA 的动态卷积核:根据输入动态生成、像素级自适应)
- [4.3 为什么叫"动态"?](#4.3 为什么叫“动态”?)
- [4.4 训练 vs 推理](#4.4 训练 vs 推理)
- [4.5 与其他动态卷积变体的对比](#4.5 与其他动态卷积变体的对比)
- [5. 总结](#5. 总结)
一句话总结
GGEV 是一种新型实时立体匹配网络,通过融合单目深度先验(Depth Anything V2)与动态卷积聚合机制,在保持实时推理速度的同时,显著提升了在未见场景下的零样本泛化能力,在 KITTI、ETH3D 等基准上超越了现有实时方法。
0. 论文概述(Executive Summary)
本文针对实时立体匹配中 泛化能力(generalization) 与 推理延迟(inference latency) 之间的权衡问题,提出了一种名为 GGEV(Generalized Geometry Encoding Volume) 的轻量化网络。现有实时方法(如 RT-IGEV)虽然速度快,但在遮挡、无纹理区域、重复纹理和细结构等挑战性场景中匹配关系脆弱,泛化性能差;而基于单目基础模型(MFM)的最新方法(如 FoundationStereo、MonSter)虽然泛化能力强,但依赖高容量骨干网络和复杂迭代机制,推理延迟高。
GGEV 的核心思想是:将预训练的单目深度基础模型(Depth Anything V2)作为冻结的特征提取器,获取领域不变的深度结构先验,然后通过轻量的选择性通道融合(SCF)和深度感知动态代价聚合(DDCA)模块,将这些先验自适应地注入到代价聚合过程中,从而增强代价体积的鲁棒性。该方法在 Scene Flow 合成数据集上训练即可在真实数据集上取得优异的零样本泛化性能,并在 KITTI、ETH3D 等基准上达到实时方法的最优结果。
主要贡献:
- 提出了一种新的泛化几何编码体积(GGEV),高效融合深度先验以增强泛化能力。
- 设计了深度感知动态代价聚合(DDCA)模块,基于视差假设与深度特征之间的亲和度自适应生成动态卷积核。
- 即使在仅使用合成数据训练的情况下,也能在真实场景中表现出强泛化能力。
- 在 KITTI 2012、KITTI 2015 和 ETH3D 基准上超越了现有实时方法。
1. 问题背景与动机
立体匹配(Stereo Matching)旨在从一对已校正的立体图像中估计密集的像素级视差图,广泛应用于 3D 重建、自动驾驶和机器人导航。这些实际场景对泛化能力 (在不同域、未见场景中的表现)和推理延迟(实时性)有严格要求。
现有实时方法的局限性:
- 使用下采样或稀疏代价体积、轻量聚合网络、2D 卷积替代 3D 卷积等策略实现快速推理。
- 但它们在未见领域 (unseen domains)中,尤其是在遮挡(occlusions)、无纹理区域(textureless areas)、重复纹理(repetitive patterns)、细结构(thin structures) 等挑战区域,匹配关系脆弱,信息聚合困难。
现有高泛化方法的局限性:
- 将单目基础模型(如 Depth Anything、DINOv2)引入立体匹配,取得优异的零样本泛化。
- 但依赖昂贵的骨干网络和复杂的迭代机制,推理延迟高(如 DEFOM-Stereo 需 255ms,MonSter 需 450ms)。
本文的核心问题 :如何设计一个实时 立体匹配网络,在保持高精度的同时实现强泛化能力?
2. 相关工作与创新关联
2.1 前人工作综述
| 类别 | 代表方法 | 特点 |
|---|---|---|
| 实时立体匹配 | AANet, BGNet+, RT-IGEV, IINet | 使用稀疏代价体积、2D 卷积、少量迭代;速度快,但泛化弱 |
| 零样本泛化立体匹配 | RAFT-Stereo, FoundationStereo, MonSter, DEFOM-Stereo | 引入单目基础模型(MFM)、大容量聚合网络;泛化强,但延迟高 |
| 单目深度基础模型 | MiDaS, DINOv2, Depth Anything V2 | 零样本深度估计能力极强;Depth Anything V2 提供轻量高效的学生模型 |
2.2 存在的问题与不足
- 实时方法:对所有视差假设统一处理,忽略关键区域在不同视差上的差异;在未见场景中匹配关系高度脆弱。
- 高泛化方法:使用 ViT-L 等大骨干提取细粒度特征,并采用复杂迭代机制解决单目仿射深度的尺度偏移问题,计算开销大。
- 共同问题:如何将单目先验高效地注入代价聚合过程,而不引入大量计算,尚未得到有效解决。
2.3 本论文与前人工作的关系
- 借鉴 Depth Anything V2 的轻量级学生模型作为冻结的深度特征编码器,获得领域不变的结构先验。
- 不同于 FoundationStereo、MonSter 等直接使用大模型构建代价体积或双分支迭代,GGEV 仅将深度特征用于引导代价聚合,避免了尺度偏移问题和额外的大计算量。
- 改进 传统统一处理的代价聚合(如 hourglass 结构),提出深度感知动态代价聚合(DDCA),让不同视差假设自适应地关注各自的关键区域。
3. 贡献与核心创新点
3.1 创新点一:泛化几何编码体积(Generalized Geometry Encoding Volume, GGEV)
- 核心思想:将单目深度先验通过轻量融合模块(SCF)与纹理特征融合,形成深度感知先验特征,然后在代价聚合阶段自适应地注入这些先验,从而构建具有强泛化能力的几何编码体积。
- 优势:相比传统几何编码体积(如 IGEV),GGEV 对未见场景中的纹理变化、遮挡和重复模式更加鲁棒。
3.2 创新点二:深度感知动态代价聚合(Depth-aware Dynamic Cost Aggregation, DDCA)
- 核心思想 :对于每个视差假设,计算其与深度特征图之间的亲和度矩阵(affinity matrix),利用亲和度生成动态卷积核,对代价图进行自适应聚合。
- 关键步骤 :
- 将视差假设特征 C d \mathbf{C}d Cd 映射为 Query Q \mathbf{Q} Q,深度特征 f d a \mathbf{f}{da} fda 池化为 Key K \mathbf{K} K。
- 计算亲和度矩阵 A = Q T K \mathbf{A} = \mathbf{Q}^{\mathrm{T}}\mathbf{K} A=QTK。
- 通过可学习线性层将亲和度映射为卷积核权重,经 softmax 归一化后得到动态核。
- 对融合特征进行分组动态卷积(大核+小核组合,捕获低频和高频信息)。
- 效果:能够有效过滤错误匹配,在正确视差平面上保留清晰结构(如图 3 所示)。
4. 方法与网络设计
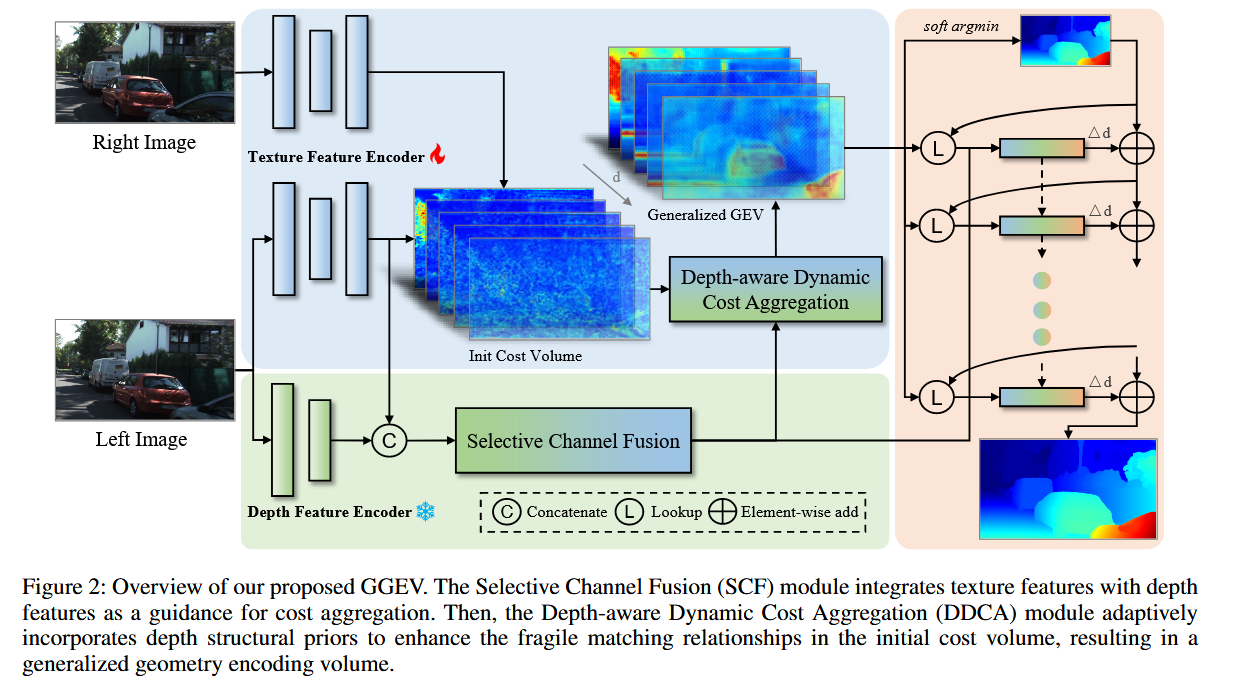
4.1 整体网络架构概览
GGEV 网络包含四个主要阶段(如图 2 所示):
- 多线索特征提取(Multi-cue Feature Extraction)
- 代价体积构建(Cost Volume Construction)
- 深度感知动态代价聚合(DDCA)
- 深度感知迭代细化(Depth-aware Iterative Refinement)
4.1.1 网络四层结构
| 阶段 | 输入 | 输出 | 功能 |
|---|---|---|---|
| 特征提取 | 左图、右图 | 纹理特征 f l , f r f_l, f_r fl,fr,深度特征 f d f_d fd | 提取匹配线索和结构先验 |
| 代价体积构建 | 纹理特征 | 分组相关体积 C \mathbf{C} C | 计算像素匹配相似度 |
| DDCA | 代价体积 + 深度先验 | 泛化几何编码体积 C ′ \mathbf{C}' C′ | 动态聚合,增强脆弱匹配 |
| 迭代细化 | 初始视差 + 几何特征 | 最终全分辨率视差图 | GRU 循环更新残差 |
4.1.2 信息流向图示(文字描述)
左图 (I_l) ──→ Texture Encoder (MobileNetV2) ──→ 纹理特征 f_l ──┐
├→ SCF ──→ 深度先验 f_da
左图 (I_l) ──→ Depth Encoder (Depth Anything V2, frozen) ──→ 深度特征 f_d ──┘
右图 (I_r) ──→ Texture Encoder (MobileNetV2) ──→ 纹理特征 f_r ──┐
├→ Group-wise Correlation ──→ 代价体积 C
└─────────────────────────┘
↓
DDCA (动态卷积,基于亲和度) ──→ 泛化几何编码体积 C'
↓
Soft-argmin ──→ 初始视差 d_0
↓
GRU 迭代更新 (共 N 次) ──→ 残差视差 Δd_k
↓
空间上采样 + 深度特征引导 ──→ 最终全分辨率视差图4.1.3 各模块功能概述
- 纹理特征编码器:MobileNetV2,在 ImageNet 上预训练,提取多尺度纹理特征(尺度 1/4, 1/8, 1/16)。
- 深度特征编码器:Depth Anything V2 Small(冻结),提取多尺度深度特征(尺度 1/2, 1/4, 1/8, 1/16)。
- SCF(Selective Channel Fusion) :1×1 卷积,融合纹理和深度特征,生成深度感知先验 f d a f_{da} fda。
- 代价体积构建 :在 1/4 分辨率上构建分组相关体积( N g = 8 N_g=8 Ng=8 组)。
- DDCA:核心创新,动态聚合代价体积。
- 迭代细化:单层 GRU,基于当前视差和几何特征预测残差,更新视差。
- 空间上采样:利用深度特征辅助恢复全分辨率视差图。
4.2 网络详细分析
4.2.1 SCF(Selective Channel Fusion)模块详解
- 目的 :将纹理特征 f l f_l fl 与深度特征 f d f_d fd 选择性融合,生成更具判别力的深度感知先验特征 f d a f_{da} fda。
- 实现 :对通道拼接后的特征图应用 1×1 卷积。虽然简单,但实验证明比 3×3 卷积或深度可分离卷积效果更好(见表 7)。
- 优势:保留结构细节,避免空间模糊,引入额外参数极少(0.05M)。
4.2.2 DDCA(Depth-aware Dynamic Cost Aggregation)模块详解
DDCA 的完整架构如图 4 所示,其核心在于根据每个位置和每个视差假设自适应生成卷积核。
步骤 1:视差级深度结构表示(Disparity-wise Depth Structural Representation)
给定输入:
- 代价体积中第 d d d 个视差假设切片 C d ∈ R G × H × W \mathbf{C}_d \in \mathbb{R}^{G \times H \times W} Cd∈RG×H×W( G G G 为通道组数)
- 深度感知特征 f d a ∈ R C × H × W \mathbf{f}_{da} \in \mathbb{R}^{C \times H \times W} fda∈RC×H×W
首先通过 1×1 卷积和池化生成 Query 和 Key:
Q = R e ( W q C d ) , Q ∈ R C × H W K = R e ( W k P o o l ( f d a ) ) , K ∈ R C × S 2 \begin{aligned} \mathbf{Q} &= \mathrm{Re}(W_q \mathbf{C}d), \quad \mathbf{Q} \in \mathbb{R}^{C \times HW} \\ \mathbf{K} &= \mathrm{Re}(W_k \mathrm{Pool}(\mathbf{f}{da})), \quad \mathbf{K} \in \mathbb{R}^{C \times S^2} \end{aligned} QK=Re(WqCd),Q∈RC×HW=Re(WkPool(fda)),K∈RC×S2
其中 R e \mathrm{Re} Re 表示 reshape 操作, P o o l \mathrm{Pool} Pool 为自适应平均池化(将空间尺寸 H × W H \times W H×W 降为 S × S S \times S S×S, S S S 为超参数)。
然后计算亲和度矩阵:
A = Q T K , A ∈ R H W × S 2 \mathbf{A} = \mathbf{Q}^{\mathrm{T}} \mathbf{K}, \quad \mathbf{A} \in \mathbb{R}^{HW \times S^2} A=QTK,A∈RHW×S2
多组注意力 :将通道分为 G G G 组,分别计算每组亲和度 A g ∈ R H W × S 2 \mathbf{A}^g \in \mathbb{R}^{HW \times S^2} Ag∈RHW×S2。
步骤 2:视差级自适应代价聚合(Disparity-wise Adaptive Cost Aggregation)
利用亲和度生成动态卷积核权重:
M g = s o f t m a x ( A g W m ) , M g ∈ R H W × K 2 \mathbf{M}^g = \mathrm{softmax}\left( \mathbf{A}^g W_m \right), \quad \mathbf{M}^g \in \mathbb{R}^{HW \times K^2} Mg=softmax(AgWm),Mg∈RHW×K2
其中 W m W_m Wm 为可学习线性层, K K K 为卷积核大小。然后将每行 reshape 为 K × K K \times K K×K 核,得到空间自适应的动态卷积滤波器。
分组动态卷积:
C d ′ = C d ∗ M d y n a m i c g ( C d , f d a ) \mathbf{C}_d' = \mathbf{C}d * \mathbf{M}{dynamic}^g (\mathbf{C}d, \mathbf{f}{da}) Cd′=Cd∗Mdynamicg(Cd,fda)
其中 ∗ * ∗ 表示分组卷积操作(每组通道共享相同动态核)。
大核与小核组合:同时使用大卷积核(捕获低频全局结构)和小卷积核(捕获高频细节),结果融合。
最终将所有视差切片聚合结果重新排列,得到泛化几何编码体积 C ′ \mathbf{C}' C′。
初始视差预测:应用 soft-argmin 回归初始视差:
d 0 = ∑ d ∈ D d × S o f t m a x ( C ′ ( d ) ) , 尺度为 H / 4 × W / 4 \mathbf{d}0 = \sum{d \in \mathcal{D}} d \times \mathrm{Softmax}(\mathbf{C}'(d)), \quad \text{尺度为 } H/4 \times W/4 d0=d∈D∑d×Softmax(C′(d)),尺度为 H/4×W/4
图 3 有效性说明:第一行显示原始代价体积在不同视差假设下的特征(脆弱、多错误匹配);第二行显示经过 DDCA 后的结果(错误匹配被过滤,正确结构更清晰)。
4.2.3 深度感知迭代细化(Depth-aware Iterative Refinement)
采用 GRU 进行迭代更新,共 N N N 次(训练 11 次,推理 8 次)。
初始化 :隐藏状态 h 0 h_0 h0 用深度特征 f d a , 4 f_{da,4} fda,4 初始化,注入结构先验。
GRU 更新方程:
z k = σ ( C o n v ( h k − 1 , x k , W z ) ) r k = σ ( C o n v ( h k − 1 , x k , W r ) ) h ~ k = tanh ( C o n v ( r k ⊙ h k − 1 , x k , W h ) ) h k = ( 1 − z k ) ⊙ h k − 1 + z k ⊙ h ~ k \begin{aligned} z_k &= \sigma(\mathrm{Conv}(h_{k-1}, x_k, W_z)) \\ r_k &= \sigma(\mathrm{Conv}(h_{k-1}, x_k, W_r)) \\ \tilde{h}k &= \tanh(\mathrm{Conv}(r_k \\odot h_{k-1}, x_k, W_h)) \\ h_k &= (1 - z_k) \odot h{k-1} + z_k \odot \tilde{h}_k \end{aligned} zkrkh~khk=σ(Conv(hk−1,xk,Wz))=σ(Conv(hk−1,xk,Wr))=tanh(Conv(rk⊙hk−1,xk,Wh))=(1−zk)⊙hk−1+zk⊙h~k
其中 x k x_k xk 为当前视差 d k \mathbf{d}_k dk 与几何特征 f G \mathbf{f}_G fG(从 C ′ \mathbf{C}' C′ 索引)的拼接。
残差预测 :基于 h k h_k hk 通过两个卷积层解码残差 Δ d k \Delta \mathbf{d}_k Δdk,并更新:
d k + 1 = d k + Δ d k \mathbf{d}_{k+1} = \mathbf{d}_k + \Delta \mathbf{d}_k dk+1=dk+Δdk
空间上采样 :将 h k h_k hk 上采样到半分辨率,与深度特征 f d f_d fd 拼接,生成 9 个权重的上采样图,对低分辨率视差图的局部邻域进行加权组合,恢复全分辨率视差图。
4.2.4 损失函数与训练策略
损失函数:
L = ∣ d 0 − d g t ∣ smooth L1 + ∑ i = 1 N γ N − i ∥ d i − d g t ∥ 1 \mathcal{L} = |\mathbf{d}0 - \mathbf{d}{gt}|{\text{smooth L1}} + \sum{i=1}^{N} \gamma^{N-i} \| \mathbf{d}i - \mathbf{d}{gt} \|_1 L=∣d0−dgt∣smooth L1+i=1∑NγN−i∥di−dgt∥1
- 第一项:初始视差的 Smooth L1 损失
- 第二项:迭代视差的 L1 损失,加权衰减因子 γ = 0.9 \gamma = 0.9 γ=0.9
训练细节:
- 优化器:AdamW,梯度裁剪到 − 1 , 1 -1, 1 −1,1
- 学习率:one-cycle 调度
- 预训练:Scene Flow 数据集,35k 步
- 微调:KITTI(混合 KITTI 2012+2015)或 ETH3D(多数据集混合)
5. 实验结果
5.1 数据集与评估指标
| 数据集 | 类型 | 评估指标 |
|---|---|---|
| Scene Flow | 合成 | EPE(End-Point Error) |
| KITTI 2012 | 真实驾驶 | 2-pixel / 3-pixel 错误率,noc/all |
| KITTI 2015 | 真实驾驶 | D1-bg, D1-fg, D1-all(>3px 错误率) |
| ETH3D | 真实室内外 | Bad 0.5, Bad 1.0, Bad 2.0, AvgErr |
| Middlebury V3 | 真实室内 | Bad 2.0(quarter 分辨率) |
5.2 消融研究(Ablation Study)
基线:简化的 RT-IGEV(2 次下采样,8 次迭代)。结果见表 4。
| 模型变体 | DFE | SCF | DCA | Scene Flow EPE | KITTI 2012 D1 | KITTI 2015 D1 | Middlebury Bad2 | ETH3D Bad1 | 参数(M) | 时间(ms) |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | - | - | - | 0.54 | 6.63 | 8.01 | 7.84 | 7.54 | 3.60 | 30 |
| +DFE | ✓ | - | - | 0.52 | 4.40 | 6.32 | 6.47 | 5.02 | 3.57 | 37 |
| +DFE+SCF | ✓ | ✓ | - | 0.49 | 5.14 | 7.58 | 5.57 | 4.85 | 3.65 | 38 |
| +DCA | - | - | ✓ | 0.47 | 6.80 | 6.75 | 7.73 | 5.61 | 3.63 | 39 |
| Full (ViT-S) | ✓ | ✓ | ✓ | 0.46 | 4.11 | 5.56 | 6.53 | 2.84 | 3.68 | 47 |
| Full (ViT-L) | ✓ | ✓ | ✓ | 0.45 | 4.20 | 5.65 | 4.41 | 1.69 | 3.75 | 110 |
关键结论:
- DFE(深度特征编码器):显著提升泛化(ETH3D 错误从 7.54 降至 5.02)。
- SCF:改善 in-domain 拟合,对泛化效果混合。
- DCA:大幅提升 in-domain 性能(EPE 从 0.54 降至 0.47),但单独使用泛化提升有限。
- 全部组件:在所有指标上均取得最佳平衡。引入参数仅 +0.08M(+2%),时间增加 17ms,满足实时要求。
SCF 卷积类型消融 (表 7):1×1 卷积效果最佳。
MFM 泛化性 (表 7):将 Depth Anything V2 替换为 MoGe-2 仍优于 RT-IGEV,证明方法对不同 MFM 通用。
亲和度构建策略(表 8):Query 来自视差假设、Key 来自深度特征(DH→DF)效果最好。
5.3 性能对比
零样本泛化(表 1):仅在 Scene Flow 训练,直接在 KITTI、Middlebury、ETH3D 测试。
| 方法 | KITTI2012 3-noc | KITTI2015 D1-all | Middlebury Bad2 | ETH3D Bad1 | 时间(ms) |
|---|---|---|---|---|---|
| RT-IGEV | 5.8 | 6.6 | 7.8 | 7.8 | 40 |
| GGEV (Ours) | 4.1 | 5.5 | 6.5 | 2.8 | 47 |
| Improvement | -29% | -16% | -16% | -51% | +7ms |
KITTI 2012/2015 基准测试(表 2):GGEV 在所有实时方法中排名第一,D1-all 达到 1.70%,优于 RT-IGEV (1.79%)。
ETH3D 基准测试(表 3):GGEV 的 Bad 1.0 为 1.19%,显著优于 Fast-ACVNet (5.62%) 和 HITNet (2.79%),与精度导向的 GMStereo (1.83%) 相比误差降低约 35%。
Scene Flow 测试集(补充表 6):GGEV (8 iters) 达到 EPE=0.46,优于 RT-IGEV (0.50)。
病态区域(反射区域)性能(表 5):在 KITTI 2012 反射区域,GGEV 的 2-noc 错误率 7.33%,优于 RAFT-Stereo (8.41%) 和 RT-IGEV (9.56%)。
5.4 限制条件下的性能分析
- 迭代次数影响(图 7):GGEV 在各迭代次数下均优于 RT-IGEV,仅 2 次迭代即可达到 RT-IGEV 4 次迭代的性能。
- 参数与时间:全模型 (ViT-S) 参数 3.68M,时间 47ms (KITTI 1248×384),满足 HITNet 提出的 100ms 实时约束。
- 定性结果(图 6、图 8、图 9):GGEV 在边缘、遮挡、无纹理区域、细结构和反射表面均表现出更清晰的视差图。
6. 不足之处与未来工作
- 当前深度先验来源 :使用 Depth Anything V2 提供的相对深度,而非度量深度。未来可探索度量深度基础模型(如 MoGe-2)以提供更精确的深度引导。
- 应用场景扩展:目前针对静态图像立体匹配,未来可扩展至实时视频立体匹配,利用时间一致性进一步提升性能。
- 训练数据依赖:虽然零样本泛化能力强,但加入更多真实/合成数据(如 TartanAir, CREStereo)后性能进一步提升,表明数据质量仍有影响。
7. 总体评价
| 维度 | 评价 |
|---|---|
| 创新性 | ★★★★☆ -- 首次将动态卷积与深度先验结合用于实时立体匹配的代价聚合,设计巧妙且轻量。 |
| 实用性 | ★★★★★ -- 实时(47ms)、参数少(3.68M)、开源代码,适合自动驾驶、机器人等实际部署。 |
| 理论深度 | ★★★★☆ -- 从代价体积脆弱性的分析出发,提出针对性的亲和度建模,理论动机清晰。 |
| 实验完备性 | ★★★★★ -- 涵盖零样本泛化、基准对比、消融、病态区域、不同骨干、不同迭代次数,实验充分。 |
| 写作质量 | ★★★★☆ -- 结构清晰,图表丰富,公式规范,但部分段落略有重复。 |
综合评分:4.6 / 5.0
适用读者:计算机视觉、自动驾驶、机器人领域的研究者与工程师,特别是对立体匹配实时性与泛化能力感兴趣的人。
附录:关键中英对照
| 中文 | 英文 |
|---|---|
| 泛化几何编码体积 | Generalized Geometry Encoding Volume (GGEV) |
| 深度感知动态代价聚合 | Depth-aware Dynamic Cost Aggregation (DDCA) |
| 选择性通道融合 | Selective Channel Fusion (SCF) |
| 代价体积 | cost volume |
| 视差假设 | disparity hypothesis |
| 亲和度矩阵 | affinity matrix |
| 动态卷积核 | dynamic convolution kernel |
| 零样本泛化 | zero-shot generalization |
| 单目基础模型 | monocular foundation model (MFM) |
| 分组相关 | group-wise correlation |
| 迭代细化 | iterative refinement |
| 病态区域 | ill-posed region |
| 反射表面 | reflective surface |
以下是根据以上所有对话内容整理而成的详细文档,严格遵循论文原文表述,并保留了所有公式、图表示意及关键分析结论。
深度感知动态代价聚合(DDCA)模块全面解析
1. 白话解释:DDCA 在做什么?
立体匹配中有一个 3D 的"候选匹配网格",叫作代价体积(cost volume):
- x 轴和 y 轴:图像上的每个像素。
- d 轴(视差假设轴):代表"这个像素可能向右偏移了多少像素"。
对于每个像素,我们需要从众多 d 候选里找到正确的那一个。
问题出在哪里?
在复杂场景(如玻璃反光、树叶缝隙、白色墙壁)中,代价体积里大部分"候选匹配"都很不可靠------正确的匹配信号很弱,错误的匹配反而看起来挺像。传统方法(如沙漏网络中的 3D 卷积)对所有 d 都用一样的卷积核去"抹一遍",结果会把错误也保留下来,边缘变得模糊。
DDCA 的核心想法
不是对所有视差假设一视同仁,而是让每个视差假设 d 先"看一眼"深度特征(depth feature),自己判断应该用什么样的卷积核来聚合信息。
具体步骤:
- 每个 d 对应的代价切片( C d C_d Cd)与深度特征( f d a f_{da} fda)计算一个亲和度矩阵:告诉你"这个 d 位置和图像中哪些区域关系最紧密"。
- 根据这个亲和度,当场生成一组独特的卷积核(而不是用训练好的固定核)。
- 用这些动态生成的卷积核去聚合代价体积,实现:
- 在正确的视差平面附近,保留清晰结构;
- 在错误的或模糊的视差区域,压制错误响应。
一句话概括 :
DDCA = 每个候选视差都"定制"一个聚合滤镜,这个滤镜是根据深度先验动态生成的 → 让正确匹配的地方更突出,错误匹配的地方被滤掉。
2. 结合论文表述与公式的详细解释
2.1 输入与目标
DDCA 的输入:
- C d ∈ R G × H × W \mathbf{C}_d \in \mathbb{R}^{G \times H \times W} Cd∈RG×H×W:第 d d d 个视差假设对应的代价切片(已按通道分成 G G G 组)。
- f d a ∈ R C × H × W \mathbf{f}_{da} \in \mathbb{R}^{C \times H \times W} fda∈RC×H×W:深度感知特征(由 SCF 模块融合纹理+深度特征得到)。
目标:输出增强后的代价切片 C d ′ \mathbf{C}_d' Cd′,其中正确的匹配结构被保留,错误匹配被抑制。
2.2 步骤一:构建 Query 和 Key(公式 4)
论文公式:
Q = R e ( W q C d ) , K = R e ( W k P o o l ( f d a ) ) , A = Q T K . \begin{aligned} \mathbf{Q} &= \mathrm{Re}(W_q \mathbf{C}d),\\ \mathbf{K} &= \mathrm{Re}(W_k \mathrm{Pool}(\mathbf{f}{da})),\\ \mathbf{A} &= \mathbf{Q}^{\mathrm{T}} \mathbf{K}. \end{aligned} QKA=Re(WqCd),=Re(WkPool(fda)),=QTK.
- W q , W k W_q, W_k Wq,Wk:1×1 卷积,将通道数变换到统一维度。
- P o o l \mathrm{Pool} Pool:自适应平均池化,把 f d a \mathbf{f}_{da} fda 的空间尺寸从 H × W H\times W H×W 压缩到 S × S S\times S S×S(例如 S = 8 S=8 S=8),目的是降低后续矩阵乘法的计算量,同时保留全局结构信息。
- R e \mathrm{Re} Re:reshape 操作,将特征展平成 C × H W C \\times HW C×HW 和 C × S 2 C \\times S\^2 C×S2。
- A \mathbf{A} A:亲和度矩阵,尺寸 H W × S 2 HW \times S^2 HW×S2。
A i , j A_{i,j} Ai,j 表示第 i i i 个像素(在视差假设 d d d 下)与第 j j j 个深度区域中心之间的相似度。
多组注意力 :将通道分为 G G G 组,分别计算每组亲和度:
Q g ∈ R C G × H W , K g ∈ R C G × S 2 , A g = ( Q g ) T K g . \mathbf{Q}^g \in \mathbb{R}^{\frac{C}{G} \times HW},\quad \mathbf{K}^g \in \mathbb{R}^{\frac{C}{G} \times S^2},\quad \mathbf{A}^g = (\mathbf{Q}^g)^{\mathrm{T}} \mathbf{K}^g. Qg∈RGC×HW,Kg∈RGC×S2,Ag=(Qg)TKg.
2.3 步骤二:生成动态卷积核并聚合(公式 6)
M g = s o f t m a x ( A g W m ) , C d ′ = C d ∗ M d y n a m i c g ( C d , f d a ) . \begin{aligned} \mathbf{M}^g &= \mathrm{softmax}\left( \mathbf{A}^g W_m \right),\\ \mathbf{C}_d' &= \mathbf{C}d * \mathbf{M}{dynamic}^g (\mathbf{C}d, \mathbf{f}{da}). \end{aligned} MgCd′=softmax(AgWm),=Cd∗Mdynamicg(Cd,fda).
- W m W_m Wm:可学习的线性层,把亲和度矩阵(每行长度 S 2 S^2 S2)映射成卷积核扁平向量(长度 K 2 K^2 K2)。
- s o f t m a x \mathrm{softmax} softmax:沿核元素维度做 softmax,让卷积核权重和为 1,保持数值稳定。
- M g \mathbf{M}^g Mg:尺寸 H W × K 2 HW \times K^2 HW×K2,每一行对应一个像素的一个 K × K K \times K K×K 动态卷积核 。
每个像素在不同视差假设 d d d 下,都有一个 按像素变化、按视差变化 的专属卷积核。 - ∗ * ∗:分组动态卷积 。将通道分成 G G G 组,每组使用该组的动态核去卷积对应的代价切片通道。这样既保持灵活性,又控制计算量。
2.4 大核 + 小核组合
论文指出:"采用大核和小卷积核组合以融合低频和高频信息"。
实现方式:
- 并行或串行使用两个不同 K K K 的动态卷积(例如 K = 3 K=3 K=3 和 K = 7 K=7 K=7);
- 最后将大、小核的输出相加或拼接,得到最终 C d ′ \mathbf{C}_d' Cd′。
2.5 最终输出:泛化几何编码体积
对所有视差假设 d ∈ { 0 , ... , D / 4 − 1 } d \in \{0,\dots, D/4-1\} d∈{0,...,D/4−1} 执行上述操作后,得到
C ′ ∈ R ( D / 4 ) × G × H × W \mathbf{C}' \in \mathbb{R}^{(D/4) \times G \times H \times W} C′∈R(D/4)×G×H×W
这就是 Generalized Geometry Encoding Volume 。
随后用 soft-argmin 从它回归初始视差 d 0 \mathbf{d}_0 d0。
2.6 为什么 DDCA 能增强泛化能力?(论文图 3 解释)
- 第一行(无 DDCA):很多视差假设上都有杂乱响应,看不出清晰物体轮廓。
- 第二行(加 DDCA):每个视差假设只在自己对应的真实物体深度附近保留响应,背景被抑制,结构变得清晰锐利。
原因:
- 依赖深度先验( f d a \mathbf{f}_{da} fda):Depth Anything V2 在大量真实数据上预训练,对纹理变化、遮挡、反射等具有鲁棒性。这个先验通过亲和度引导动态核的生成。
- 视差级自适应:不同 d d d 使用不同的亲和度矩阵和动态核,允许网络在"可能正确的视差平面"上保留结构,在其他平面上抑制噪声。
3. DDCA 与普通 3D 卷积(沙漏网络)的计算量对比
3.1 普通 3D 卷积计算量
典型 3D 沙漏网络对代价体积 R D × H × W × C \mathbb{R}^{D \times H \times W \times C} RD×H×W×C 做完整 3D 卷积:
- 每个 3D 卷积核尺寸 k d × k h × k w × C i n × C o u t k_d \times k_h \times k_w \times C_{in} \times C_{out} kd×kh×kw×Cin×Cout。
- 计算量 ∝ D × H × W × C i n × C o u t × k d × k h × k w \propto D \times H \times W \times C_{in} \times C_{out} \times k_d \times k_h \times k_w ∝D×H×W×Cin×Cout×kd×kh×kw。
- 即使使用分组卷积或降低分辨率,计算量随视差维度 D D D 线性增长。
3.2 DDCA 的计算量
DDCA 不直接做 3D 卷积,而是:
- 每个视差切片独立处理(2D 操作)。
- 动态生成卷积核开销(轻量线性层 + softmax)。
- 使用动态 2D 卷积聚合每个切片。
对单个视差切片 C d \mathbf{C}_d Cd:
- Query/Key 投影:1×1 卷积 → O ( G × H × W × C p r o j ) O(G \times H \times W \times C_{proj}) O(G×H×W×Cproj)。
- 亲和度矩阵计算: O ( H W × S 2 ) O(HW \times S^2) O(HW×S2), S S S 很小(如 8)。
- 生成动态核: O ( H W × S 2 × K 2 ) O(HW \times S^2 \times K^2) O(HW×S2×K2)。
- 动态 2D 卷积: O ( G × H × W × K 2 ) O(G \times H \times W \times K^2) O(G×H×W×K2)。
关键 :所有操作都是 2D 的 ,不与 D D D 相乘。
总计算量 ≈ D × 2D卷积代价 + 动态核生成代价 D \times \\text{2D卷积代价} + \\text{动态核生成代价} D×2D卷积代价+动态核生成代价。
3.3 定量对比
设输入特征图大小 D × H × W × C D \times H \times W \times C D×H×W×C:
- 普通 3D 卷积(核 3 × 3 × 3 3\times3\times3 3×3×3,输出通道 C C C):
计算量 ≈ D × H × W × C 2 × 27 D \times H \times W \times C^2 \times 27 D×H×W×C2×27。 - DDCA( K = 3 , S = 8 , G K=3, S=8, G K=3,S=8,G 分组, C ≈ G × C g C \approx G\times C_g C≈G×Cg):
每个 d 的 2D 动态卷积计算量 ≈ H × W × C × K 2 H \times W \times C \times K^2 H×W×C×K2。
总 ≈ D × H × W × C × 9 D \times H \times W \times C \times 9 D×H×W×C×9。
比例:
DDCA 3D conv ≈ D × H × W × C × 9 D × H × W × C 2 × 27 = 1 3 × C \frac{\text{DDCA}}{\text{3D conv}} \approx \frac{D \times H \times W \times C \times 9}{D \times H \times W \times C^2 \times 27} = \frac{1}{3 \times C} 3D convDDCA≈D×H×W×C2×27D×H×W×C×9=3×C1
当 C ≥ 32 C \ge 32 C≥32 时,DDCA 计算量仅为普通 3D 卷积的 1/96 甚至更少 。
即便加上动态核生成开销,也远小于 3D 卷积的 D × H × W × C 2 × 27 D \times H \times W \times C^2 \times 27 D×H×W×C2×27。
3.4 实验数据佐证(论文表 4)
| 模型 | 含 DDCA | 推理时间 (ms) | 参数量 (M) |
|---|---|---|---|
| Baseline(无任何模块) | 否 | 30 | 3.60 |
| +DCA(只加 DDCA) | 是 | 39 | 3.63 |
| Full Model(含 DFE+SCF+DDCA) | 是 | 47 | 3.68 |
- 仅增加 DDCA 模块,时间从 30ms → 39ms,增加 9ms。
- 而典型 3D 沙漏网络(如 IGEV 中的 3D 卷积聚合)时间动辄上百毫秒(Select-IGEV 为 240ms,RAFT-Stereo 380ms)。
结论:DDCA 在显著提升泛化能力的同时,额外计算开销很小,远小于完整 3D 卷积聚合网络。
4. 动态卷积核的含义及与普通卷积核的区别
4.1 普通卷积核:固定、全局共享、不依赖输入
- 核权重固定:训练完成后数值冻结,对所有输入图像、所有像素都用完全一样的核。
- 空间不变:同一个核在整个特征图上滑动,不因像素位置改变。
- 不依赖输入内容:无论边缘、纹理丰富区还是平滑区,核的权重都一样。
4.2 DDCA 的动态卷积核:根据输入动态生成、像素级自适应
核权重由输入实时计算得出 ,而非训练后固定。公式回顾:
M g = s o f t m a x ( A g W m ) \mathbf{M}^g = \mathrm{softmax}(\mathbf{A}^g W_m) Mg=softmax(AgWm)
- A g \mathbf{A}^g Ag 依赖于当前视差切片 C d \mathbf{C}d Cd 和深度特征 f d a \mathbf{f}{da} fda。
- W m W_m Wm 是训练好的投影矩阵(核生成器),不是卷积核本身。
- 最后得到 每个像素、每个视差假设 d d d 的专属卷积核。
关键特性:
- 不同输入图像 → 不同核。
- 同一图像的不同像素 → 不同核。
- 同一像素的不同视差假设 d d d → 不同核。
4.3 为什么叫"动态"?
在深度学习中,"动态卷积"(dynamic convolution)的标准定义是:卷积核的权重随输入变化,而不是"不需要训练"。
- 静态卷积:核权重固定 → 推理时不随输入变化。
- 动态卷积:核权重由输入经过一个可学习的子网络实时生成 → 推理时随输入变化。
DDCA 属于后者,因为推理时每次前传都会根据当前 C d \mathbf{C}d Cd 和 f d a \mathbf{f}{da} fda 重新计算 M g \mathbf{M}^g Mg。
4.4 训练 vs 推理
| 阶段 | 普通卷积核 | DDCA 动态卷积核 |
|---|---|---|
| 训练 | 直接更新核权重本身 | 更新 W q , W k , W m W_q, W_k, W_m Wq,Wk,Wm(核生成器的参数) |
| 推理 | 核权重固定不变 | 每次输入都重新计算核的值(但生成器参数固定) |
| 是否依赖输入 | 否 | 是 |
| 是否需要训练 | 是 | 是 |
一句话总结:
DDCA 的动态卷积核"动态"体现在:推理时核的值是根据当前输入实时计算出来的,而不是从训练完成的固定权重表里直接读取。但计算这个核所需要的投影矩阵 W m W_m Wm 等参数,仍然需要在训练阶段通过反向传播学到。
4.5 与其他动态卷积变体的对比
| 变体 | 生成方式 | 空间差异 | 常见应用 |
|---|---|---|---|
| CondConv | 输入全局池化 → 加权融合多个固定核 | 全局共享(整图一个混合核) | 高效推理 |
| DYNet / DynamicConv | 逐通道/逐组生成,基于全局信息 | 通道自适应,非像素级 | 分类/检测 |
| 像素级动态卷积 | 每个像素用小参数生成模块产生独立核 | 完全空间自适应 | 图像恢复、分割 |
| DDCA | 基于亲和度矩阵 + 深度特征,像素级+视差级生成 | 每个 ( x , y , d ) (x,y,d) (x,y,d) 三元组核都不同 | 立体匹配代价聚合 |
DDCA 属于 像素级+视差级 完全动态卷积,其独特之处在于 亲和度矩阵本身由深度先验引导,而不是单从输入特征自己决定。
5. 总结
| 问题 | 答案 |
|---|---|
| DDCA 的核心思想 | 让每个视差假设根据深度先验动态生成专属卷积核,自适应聚合代价体积。 |
| 与普通 3D 卷积相比计算量 | 小 1~2 个数量级(表 4 显示仅增加 9ms,而 3D 卷积模块通常 >100ms)。 |
| 什么是动态卷积核 | 核的权重由输入实时计算,而非训练后固定。 |
| 动态卷积核需要训练吗 | 需要:训练"核生成器"( W q , W k , W m W_q,W_k,W_m Wq,Wk,Wm),推理时用它们生成具体核。 |
| 为什么能提升泛化 | 深度先验(Depth Anything V2)引导亲和度,使聚合过程自适应于未见场景的结构。 |
最终结论:DDCA 是一种轻量、高效、自适应的代价聚合模块,它在保持实时性的前提下,显著提升了立体匹配网络对真实世界中遮挡、无纹理、反射等挑战区域的泛化能力。