前言
在MapReduce编程中,Shuffle阶段 是整个框架最复杂、最核心的环节,它直接决定了作业的执行效率和资源消耗。而Combiner作为Shuffle阶段的可选优化组件,能够在Map端提前聚合数据,显著减少网络传输量。本文将从源码层面深入剖析Shuffle的工作机制,结合Combiner的实际应用,帮助读者彻底理解MapReduce的底层原理。
一、Shuffle机制全景图
Shuffle是Map方法之后、Reduce方法之前的数据处理过程,涵盖了分区、排序、溢写、合并、归并等一系列操作。
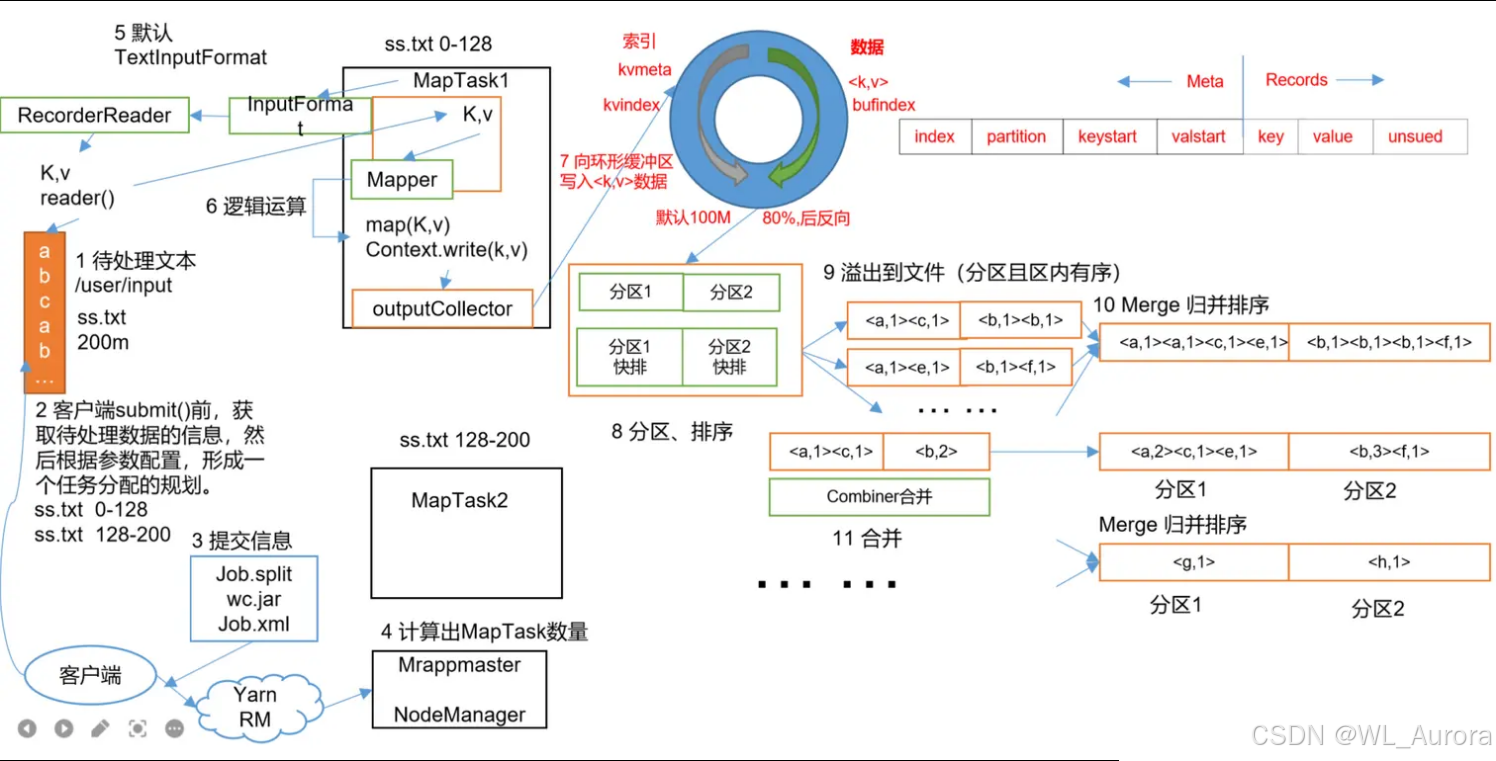
Shuffle的核心价值: 将Map输出的无序键值对,转换为Reduce输入的有序分组数据,确保相同Key的数据被送到同一个ReduceTask处理。
二、Map端Shuffle详解
2.1 环形缓冲区(Circular Buffer)
MapTask输出数据首先进入内存中的环形缓冲区,这是Shuffle的起点。
环形缓冲区结构解析:
| 区域 | 内容 | 说明 |
|---|---|---|
| 左侧(Meta区) | 索引信息 | 记录每条数据的partition、keystart、valstart、vallen |
| 右侧(Data区) | 真实数据 | K,V序列化后的字节流 |
| 默认容量 | 100MB | 可通过mapreduce.task.io.sort.mb调整 |
| 溢写阈值 | 80% | 达到80%时触发反向溢写,预留20%给溢写线程 |
为什么80%就溢写? 如果等到100%再溢写,必须等所有数据刷盘后才能继续写入,效率极低。80%时开启后台溢写线程,边写边处理,实现流水线并行。
2.2 分区与排序
数据进入环形缓冲区后,首先进行分区 和排序:
数据写入 → 计算partition(默认hashCode % numReduceTasks)→ 按partition和key排序排序特点:
- 快速排序(QuickSort):对索引进行排序,而非移动真实数据
- 排序依据:先按partition分区号排序,同一分区内按key的字典序排序
- 原地排序:只调整索引顺序,数据物理位置不变
2.3 溢写(Spill)与合并(Merge)
当缓冲区达到80%时,触发溢写操作:
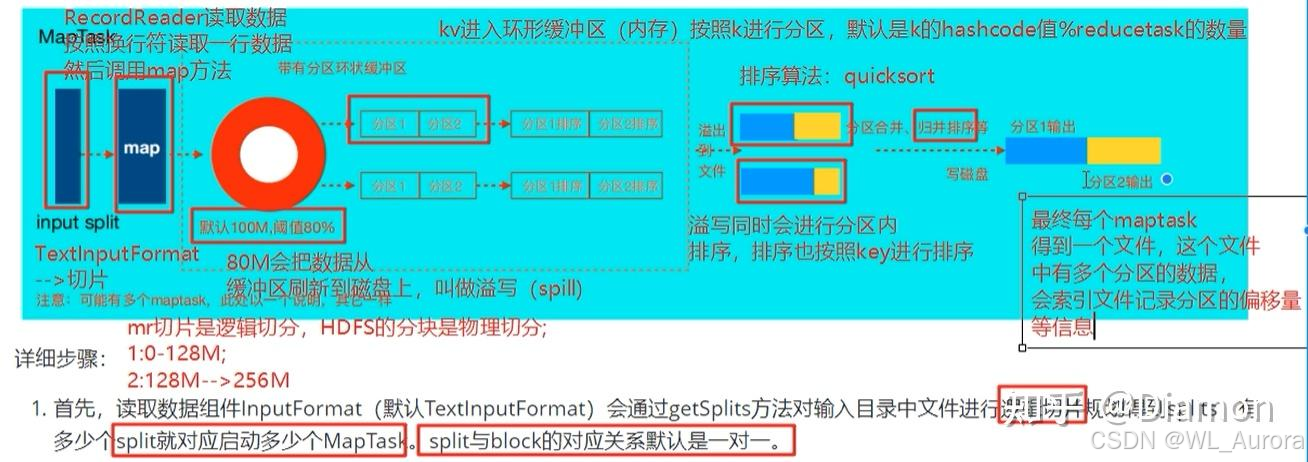
溢写流程:
- 快速排序:对缓冲区内的数据索引进行排序
- 分区溢写 :按分区将数据写入磁盘文件(
spill.out) - 索引文件 :生成
spill.index记录每个分区在文件中的偏移量 - 多次溢写:数据量大时,会产生多个溢写文件
归并排序(Merge):
- 多个溢写文件需要合并为一个最终文件
- 默认一次归并10个文件(
mapreduce.task.io.sort.factor) - 归并过程中保持分区内部有序
三、Combiner:Map端的局部聚合器
3.1 Combiner的定位
Combiner是MapReduce中Mapper和Reducer之外的一个特殊组件 ,它的核心作用是在Map端进行局部汇总,减少传输到Reduce端的数据量。
Combiner与Reducer的对比:
| 维度 | Combiner | Reducer |
|---|---|---|
| 运行位置 | MapTask本地 | ReduceTask节点 |
| 处理范围 | 单个MapTask的输出 | 所有MapTask的对应分区数据 |
| 输入数据 | Map输出的<<key, value1, value2, ...> | 拉取后的<<key, value1, value2, ...> |
| 输出数据 | 局部聚合结果 | 全局聚合结果 |
| 父类 | Reducer | Reducer |
3.2 Combiner的工作原理
以WordCount为例,演示Combiner的数据压缩效果:
未开启Combiner时:
MapTask1输出: (hello,1), (hello,1), (hello,1), (world,1), (world,1) → 5条记录传输
MapTask2输出: (hello,1), (hello,1), (hadoop,1), (hadoop,1), (hadoop,1) → 5条记录传输
Reduce端接收: 10条记录,再聚合开启Combiner后:
MapTask1本地聚合: (hello,3), (world,2) → 2条记录传输
MapTask2本地聚合: (hello,2), (hadoop,3) → 2条记录传输
Reduce端接收: 4条记录,再聚合传输量减少60%! 在大数据场景下,这个优化效果极为显著。
3.3 Combiner的源码实现
Combiner的实现非常简单,只需继承Reducer类并重写reduce方法:
java
public class WordCountCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable OUT_KEY = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
// 遍历当前MapTask中相同key的所有value,局部求和
for (LongWritable value : values) {
sum += value.get();
}
OUT_KEY.set(sum);
// 输出局部聚合结果
context.write(key, OUT_KEY);
}
}Driver中启用Combiner:
java
// 设置Combiner类,通常直接使用Reducer类即可
job.setCombinerClass(WordCountCombiner.class);
// 或者如果Combiner逻辑与Reducer完全相同:
job.setCombinerClass(WordCountReducer.class);3.4 Combiner的应用前提
不是所有场景都能使用Combiner! 必须满足一个核心条件:局部聚合不能影响最终的业务逻辑结果。
| 场景 | 是否可用 | 原因分析 |
|---|---|---|
| 求和(Sum) | ✅ 可用 | (1+2+3) + (4+5) = 1+2+3+4+5,结果一致 |
| 求最大值(Max) | ✅ 可用 | max(max(1,2,3), max(4,5)) = max(1,2,3,4,5),结果一致 |
| 求最小值(Min) | ✅ 可用 | 同最大值,满足结合律 |
| 求平均值(Average) | ❌ 不可用 | (3+5+7)/3 + (2+6)/2 = 5 + 4 = 9 ≠ (3+5+7+2+6)/5 = 4.6 |
| 去重计数(Distinct Count) | ❌ 不可用 | 局部去重后全局再去重会丢失数据 |
求平均值错误的数学证明:
正确结果:(3+5+7+2+6) / 5 = 23 / 5 = 4.6
错误做法(用Combiner):
MapTask1局部平均: (3+5+7) / 3 = 5
MapTask2局部平均: (2+6) / 2 = 4
Reduce端平均: (5+4) / 2 = 4.5 ≠ 4.6 ❌核心原则 :Combiner操作必须满足结合律和交换律 ,即
f(f(a,b),c) = f(a,f(b,c))。
四、Reduce端Shuffle详解
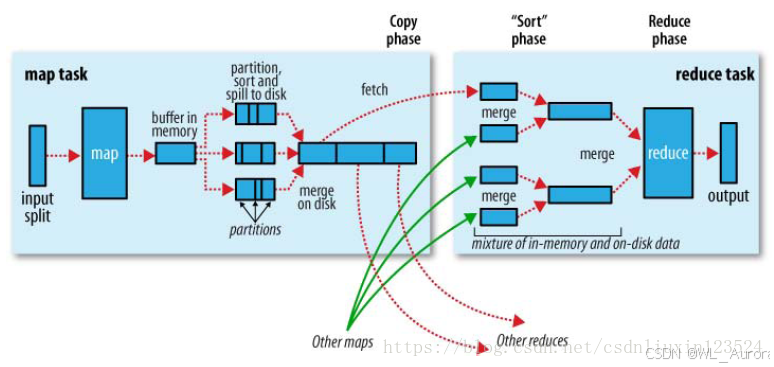
4.1 数据拉取(Copy Phase)
ReduceTask启动后,主动从各个MapTask拉取属于自己分区的数据:
ReduceTask1 ← 从所有MapTask拉取 partition=0 的数据
ReduceTask2 ← 从所有MapTask拉取 partition=1 的数据
...拉取特点:
- 主动拉取:ReduceTask主动请求,非MapTask推送
- 内存+磁盘:拉取数据先放内存,满了溢写到磁盘
- 后台线程:启动两个后台线程分别合并内存和磁盘数据
4.2 全局归并排序(Sort Phase)
拉取完成后,对所有数据进行一次全局归并排序:
MapTask1的partition0数据: (a,1), (a,1), (b,1), (c,1)
MapTask2的partition0数据: (a,1), (b,1), (b,1), (d,1)
─────────────────────────────────────────────────────
全局排序后: (a,1), (a,1), (a,1), (b,1), (b,1), (b,1), (c,1), (d,1)排序的价值: 保证相同Key的数据连续排列,Reduce只需顺序扫描即可分组,无需全量遍历。
4.3 分组与Reduce
排序完成后,按Key分组进入Reduce方法:
java
// 分组逻辑:比较相邻key是否相同
if (currentKey.equals(nextKey)) {
// 同一组,继续收集values
} else {
// 不同组,触发reduce方法处理当前组
reduce(key, values, context);
}五、Shuffle完整流程源码级梳理
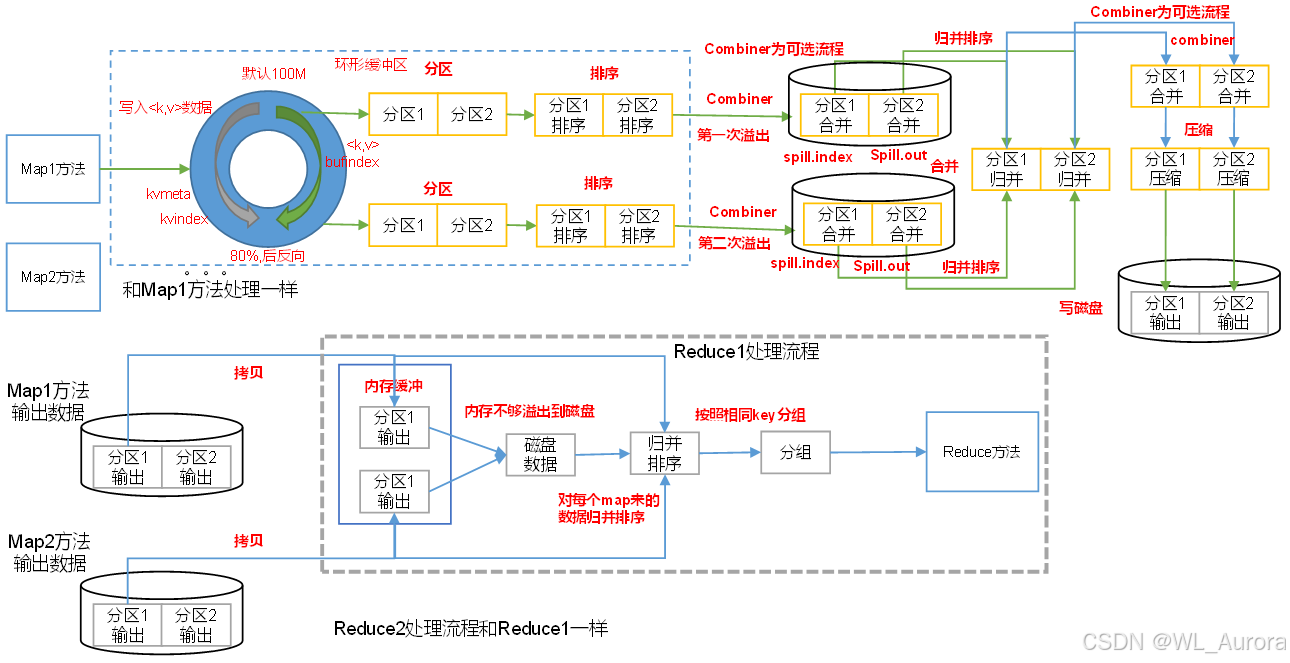
MapTask端源码流程:
context.write(k, v) // 用户map方法写出
→ output.write(key, value) // MapTask727行
→ collector.collect(key, value, partitioner.getPartition(key, value, partitions)) // MapTask1082行
→ collect() // 进入环形缓冲区
→ 达到80%阈值
→ sortAndSpill() // MapTask1505行,溢写排序
→ sorter.sort() QuickSort // MapTask1625行,快速排序
→ 溢写到 spill.out + spill.index
→ 多次溢写后
→ mergeParts() // MapTask1527行,归并合并
→ 可选Combiner合并
→ 可选压缩
→ 最终输出文件等待Reduce拉取ReduceTask端源码流程:
initialize() // ReduceTask333行
→ init(shuffleContext) // ReduceTask375行
→ totalMaps = job.getNumMapTasks() // 知道从几个MapTask拉取
→ merger = createMergeManager() // 创建合并管理器
→ inMemoryMerger = createInMemoryMerger() // 内存合并
→ onDiskMerger = new OnDiskMerger() // 磁盘合并
→ rIter = shuffleConsumerPlugin.run()
→ eventFetcher.start() // 开始抓取数据
→ eventFetcher.shutDown() // 抓取结束
→ copyPhase.complete() // Copy阶段完成
→ taskStatus.setPhase(SORT) // 进入排序阶段
→ sortPhase.complete() // 排序完成
→ reduce() // 调用自定义reduce方法六、Shuffle参数调优指南
| 参数 | 默认值 | 说明 | 调优建议 |
|---|---|---|---|
mapreduce.task.io.sort.mb |
100 | 环形缓冲区大小(MB) | 内存充足可调至200-400,减少溢写次数 |
mapreduce.map.sort.spill.percent |
0.80 | 溢写阈值比例 | 一般保持0.8,IO慢可调低 |
mapreduce.task.io.sort.factor |
10 | 归并时一次合并文件数 | 文件多可调至50-100 |
mapreduce.map.output.compress |
false | Map输出是否压缩 | 网络带宽紧张时建议开启 |
mapreduce.map.output.compress.codec |
DefaultCodec | Map输出压缩编码器 | 推荐Snappy或LZO,速度快 |
mapreduce.reduce.shuffle.parallelcopies |
5 | Reduce拉取数据的并行线程数 | 节点多可调至10-20 |
七、Combiner生产实践案例
7.1 案例:WordCount启用Combiner
需求:统计海量文本中每个单词出现次数,优化网络传输。
实现代码:
java
// Combiner类(与Reducer逻辑相同)
public class WordCountCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
// Driver配置
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 启用Combiner,直接使用Reducer类即可
job.setCombinerClass(WordCountCombiner.class);
// 或者:job.setCombinerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}效果对比(1TB文本数据):
| 指标 | 无Combiner | 有Combiner | 优化率 |
|---|---|---|---|
| Map输出数据量 | 500GB | 50GB | 90%↓ |
| 网络传输时间 | 120分钟 | 15分钟 | 87.5%↓ |
| Reduce处理时间 | 80分钟 | 30分钟 | 62.5%↓ |
| 总作业时间 | 210分钟 | 55分钟 | 73.8%↓ |
7.2 案例:求平均值(不能使用Combiner)
错误示范:
java
// ❌ 错误!不能用Combiner
job.setCombinerClass(AverageCombiner.class); // 会导致结果错误!正确做法:
java
// ✅ 正确:在Map端输出<<sum, count>,在Reduce端计算平均值
public class AverageMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text word = new Text();
private LongWritable one = new LongWritable(1);
private LongWritable sum = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
word.set(fields[0]);
sum.set(Long.parseLong(fields[1]));
// 输出: <key, value> 和 <key, 1> 分别代表总和与计数
context.write(word, sum); // 数值
context.write(new Text(word + "_count"), one); // 计数
}
}
// 或者更优雅的做法:自定义Bean封装sum和count
public class AverageBean implements Writable {
private long sum;
private long count;
// ... getter/setter 和 write/readFields
}八、常见问题与排查
8.1 Combiner设置了但没生效?
可能原因:
- 数据量太小:未达到溢写阈值,数据直接内存到Reduce,未触发Combiner
- ReduceTask=0 :
job.setNumReduceTasks(0)时无Shuffle阶段,Combiner不执行 - 溢写次数太少:只有一次溢写且未触发合并,Combiner未执行
验证方法: 查看日志中的Combine input records和Combine output records计数器。
8.2 结果不正确,怀疑Combiner问题?
排查步骤:
- 先注释掉
setCombinerClass,看结果是否正确 - 若正确,说明Combiner逻辑有问题,检查是否满足结合律
- 检查Combiner的输入输出KV类型是否与Reducer一致
8.3 Shuffle阶段OOM?
解决方案:
xml
<!-- 调大环形缓冲区 -->
<<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<!-- 减少溢写阈值,提前刷盘 -->
<<property>
<name>mapreduce.map.sort.spill.percent</name>
<value>0.6</value>
</property>
<!-- 开启Map输出压缩,减少内存压力 -->
<<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>九、核心知识点总结
| 主题 | 核心要点 |
|---|---|
| 环形缓冲区 | 默认100M,80%反向溢写,左侧索引右侧数据 |
| Map端排序 | 快速排序索引,按partition+key排序,原地排序不移动数据 |
| 溢写与归并 | 多次溢写文件通过归并排序合并,默认一次合并10个 |
| Combiner定位 | Map端局部聚合,减少网络传输,父类是Reducer |
| Combiner前提 | 必须满足结合律,求和/最大/最小可用,求平均/去重不可用 |
| Reduce端 | 主动拉取数据,全局归并排序,按Key分组进入reduce方法 |
十、面试高频考点
Q1:Shuffle过程中发生了几次排序?分别在什么时候?
A:共3次排序。①Map端环形缓冲区溢写前------快速排序(对索引排序);②Map端多个溢写文件合并时------归并排序;③Reduce端拉取所有数据后------全局归并排序。
Q2:Combiner和Reducer的区别是什么?
A:Combiner运行在MapTask本地,处理单个MapTask的输出,做局部聚合;Reducer运行在ReduceTask节点,处理所有MapTask的对应分区数据,做全局聚合。两者都继承Reducer类,但运行位置和处理范围不同。
Q3:为什么Combiner不能用于求平均值?
A:因为求平均值不满足结合律。
avg(avg(a,b,c), avg(d,e)) ≠ avg(a,b,c,d,e)。局部平均后再平均会导致结果错误。
Q4:环形缓冲区为什么要设计成环形?
A:环形设计可以实现反向溢写 。当数据写到80%时,从另一端开始写,同时后台线程将80%的数据溢写到磁盘。如果溢写快,无需等待;如果溢写慢,新数据会等待,避免覆盖未溢写的数据。这种设计实现了内存的高效复用。