目录
[条款05(优点):优先考虑auto类型推导,而非显式类型声明(Prefer auto to explicit type declarations)](#条款05(优点):优先考虑auto类型推导,而非显式类型声明(Prefer auto to explicit type declarations))
优点3:auto可以直接持有闭包(由lambda式创建的运行期对象)。
[优点4.1:auto可以避免由于"类型捷径(type shortcuts)/类型不匹配"所导致的兼容性问题。](#优点4.1:auto可以避免由于“类型捷径(type shortcuts)/类型不匹配”所导致的兼容性问题。)
优点4.2:auto可以避免由于"类型捷径/类型不匹配"所导致的效率问题。
优点5:auto可以简化"代码重构(refactoring)"的流程。
条款05(优点):优先考虑auto类型推导,而非显式类型声明(Prefer auto to explicit type declarations)
优点1 :auto 可以 避免未初始化的变量 。
- 显式类型声明 :变量是否被初始化,取决于具体语境(有时会被初始化,有时不会被初始化)。当使用未初始化的变量时,可能会造成未定义行为。
- auto 类型声明 :由于 变量类型"推导自"其初始化物,因此必须初始化(否则编译错误)。这一特性能够避免因变量未初始化而引发的一系列潜在问题(如未定义行为)。


优点2 :auto 可以 避免啰嗦/ 繁琐的变量声明 。
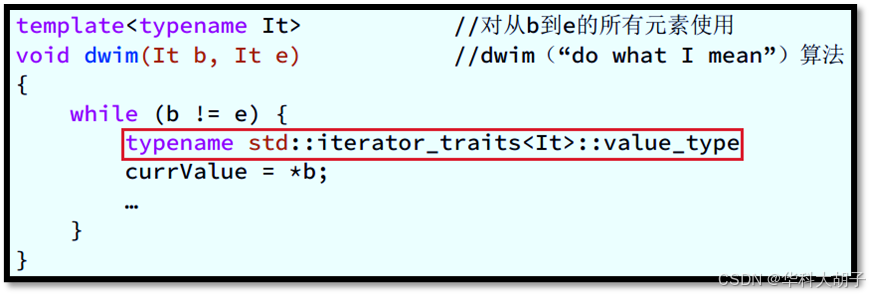
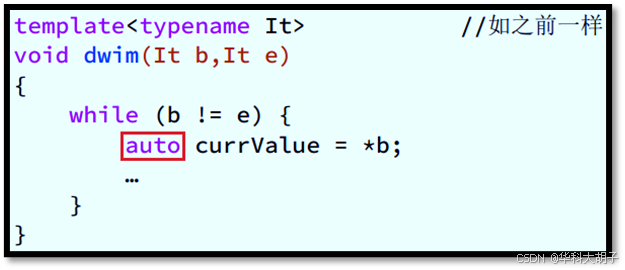
- 场景描述 :使用**"迭代器所指物** / **迭代器的解引用结果"**来初始化"变量"。
- 显式类型声明 :变量类型需要通过"迭代器萃取机iterator_traits"获取。进一步地,若变量声明在模板内部 且 迭代器类型依赖于模板类型参数,则变量类型还需要添加"typename"前缀。(提醒:对于STL 迭代器 而言,使用按值传递更高效。)
- auto 类型声明:
优点3 :auto 可以直接持有闭包 (由lambda式创建的运行期对象 )。
- 场景描述 :使用**"闭包"**来初始化"变量"。
- 显式类型声明 :由于闭包的类型只有编译器知道,因此无法使用"闭包的类型"来声明"变量"(写不出来)。
- auto 类型声明:由于auto使用了类型推导,因此可以用来表示只有编译器才掌握的类型。
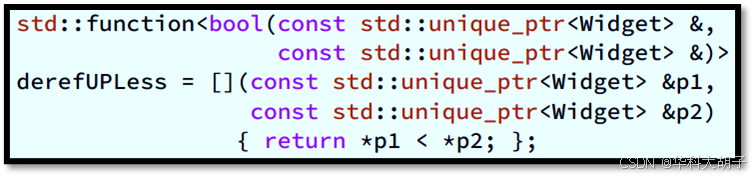
问题引入 :尽管不能使用"闭包的类型" 来声明"变量",但是可以使用" std::function " 来声明"变量",从而持有闭包(如下图所示)。那么,使用std::function和使用auto有何区别 呢?孰优孰劣呢?性能分析 :在"持有闭包"这一问题上,auto 可谓大获全胜(具体分析如下)。
- 内存 :"使用std::function对象"一般比"使用auto声明的变量"使用更多内存 。(还可能有"内存不足out-of-memory"异常)
- 使用"auto声明变量"来存储闭包,该变量与闭包为同一类型。因此,变量要求的内存量也和闭包相同。
- 使用"std::function声明变量"来存储闭包,该变量拥有固定的内存大小(std::function实例)。然而,这个大小可能不足以存储闭包 。这种情况下,std::function的构造函数将会在堆上面分配内存来存储。
- 效率 :"通过std::function对象来调用闭包"几乎必然会比"通过auto声明的变量来调用同一闭包"要来得慢 。
- 使用"std::function声明变量"来存储闭包,编译器的实现细节一般都会限制内联 ,并会产生间接函数调用。
- 打字 :"写一个std::function实例类型"可比"写一个auto"要费事得多 。
- 使用"std::function声明变量"需要输入啰嗦的语法 以及指定重复的形参类型。
- 待补充(std::bind )("条款34 ")


优点4.1 :auto 可以 避免由于"类型捷径(type shortcuts )/ 类型不匹配"所导致的++兼容性问题++。
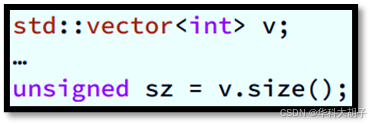
- 场景描述 :使用**"容器成员函数** size() **的结果"**来初始化"变量"。
- 显式类型声明 :v.size()的标准返回值类型应为std::vector<int>::size_type,但是只有少数开发者意识到这点。std::vector<int>::size_type实际上被指定为无符号整型,因此很多程序员认为用unsigned足够了,并编写如下所述的代码。
- Win32 :std::vector<int>::size_type和unsigned的大小一样。
- Win64 :std::vector<int>::size_type是64 位 ,unsigned是32 位。
- 这意味着,在 Windows 32-bit 上 正常工作 的代码可能在 Windows 64-bit 上 会表现异常。
- auto 类型声明:

优点4.2 :auto 可以 避免由于"类型捷径/ 类型不匹配"所导致的++效率问题++。
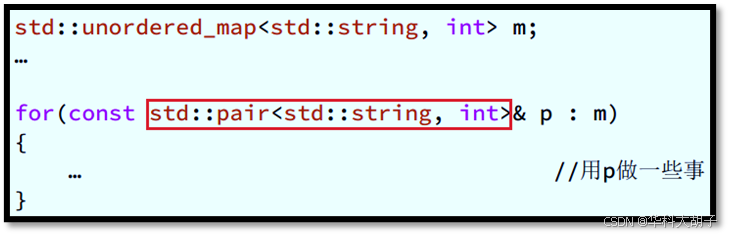
- 场景描述 :遍历unordered_map容器中的元素,并以**"常量左值引用"**的方式存储(绑定)到某一变量中。
- 显式类型声明 :若不小心遗漏pair中first元素的const属性,将会带来以下问题
- 问题1 (效率低) :由于unordered_map的key是const的,因此pair的类型不是 std::pair<std::string , int>,而是 std::pair<const std::string , int>。然而,声明变量p的类型却不是这个。因此,编译器会开足马力找到某种方法把std::pair<const std::string , int>对象(即hashtable 中的元素 )转换为std::pair<std::string , int>对象(即p )。这一步是可以成功的:++首先++ ,对m中的每个对象都做一次复制 操作,形成一个p想要绑定的类型的临时对象 ;++其次++ ,把p的引用绑定到该临时对象上。在每个循环迭代结束时,临时对象都会被析构一次。
- 问题2 (违背预期):p绑定的是容器元素的拷贝副本(临时对象),而不是容器元素本身。(在你的理解中,只是希望让p成为m中各个元素的引用。然而,实际运行结果却可能并不符合这一预期。)
- 问题3 :如果获取p的地址,得到的是指向++临时对象++的指针,该对象在循环迭代结束时会被析构。
- auto 类型声明 :效率更高、书写更容易。
- 优势1:无需对容器元素执行拷贝操作。
- 优势2:p绑定的就是容器元素本身。
- 优势3 :如果获取p的地址,得到的是指向 ++m++ ++中元素++ 的指针。

优点5 :auto 可以 简化"代码重构(refactoring )"的流程 。
- 场景描述:修改函数的返回值类型(比如由int修改为long)。
- 显式类型声明 :若函数调用的结果存储在**++显式声明的变量++** 中,则必须找到函数的所有调用点 ,并逐一手动更新变量类型 (确保变量类型和新的返回值类型一致),代码维护的成本较高。
- auto 类型声明 :若函数调用的结果存储在**++auto++** ++声明的变量++ 中,则调用它的代码**(在下次编译时)自动更新自己** 。由此可见," auto 类型"能够随着"其初始化表达式类型"的变化而自动变化 。这意味着,通过使用auto,减少代码重构时需要手动修改的地方,使部分重构工作在编译阶段就自然完成,提高代码的可维护性。
小结
基于上述原因,建议优先使用auto而非显式类型声明。然而,auto也并不完美,存在以下两个问题。
++首先++ ,auto 变量的类型都是从初始化表达式中推导得到的,而某些表达式的类型既不符合期望也不符合要求(见"条款2"和"条款6")。
++其次++ ,使用auto代替传统的显式类型声明,可能会在一定程度上影响源码的可读性 ,使读者无法一眼从源代码中看出对象的具体类型。不过,这一问题在实践中往往可以得到缓解。(1)现代 IDE 通常具备显示对象类型的能力,从而缓和这个问题(即使考虑到"条款4"中提及的IDE类型显示的局限)。(2)在许多场景下,对于对象类型的抽象理解 和掌握其精确类型 同样具有价值(换言之,并不在乎精确类型 )。比如,只要知道某个对象是一个容器 、计数器 或一个智能指针 ,往往就已经足够,并不一定需要了解它具体是哪种类型的容器 、计数器 或智能指针 。进一步地,如果再配合语义清晰的变量命名,那么抽象类型信息就近乎总是唾手可得。