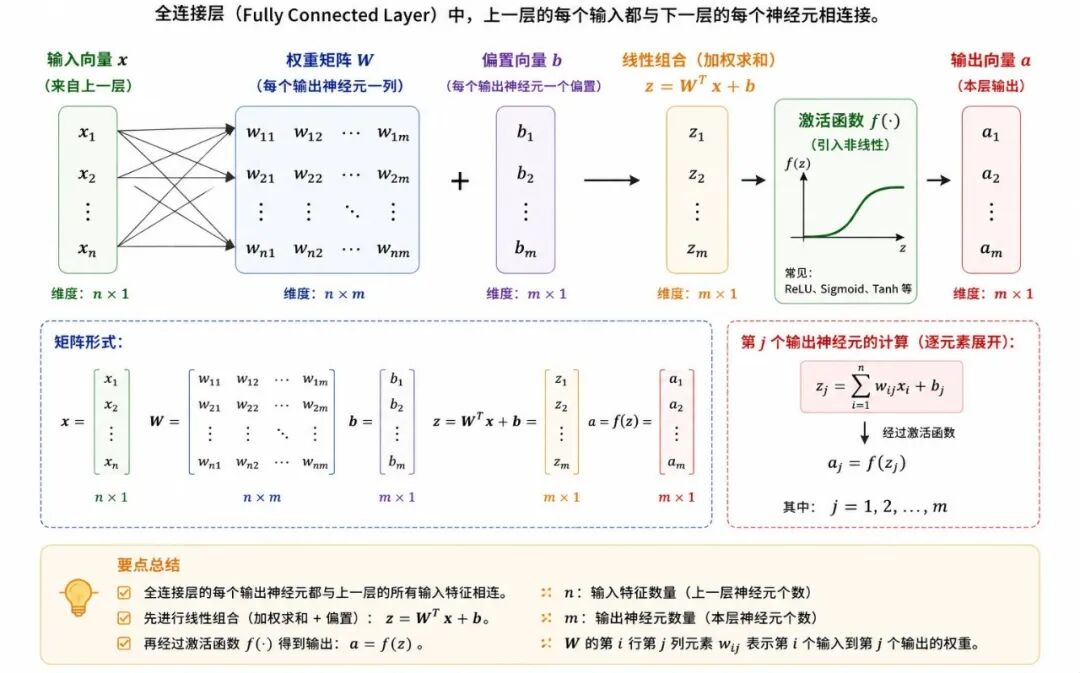
全连接层是深度学习、神经网络、卷积神经网络和人工智能中非常基础的一种层结构。它用来描述一种上一层的每个输入都与下一层的每个神经元相连接的神经网络层。换句话说,全连接层是在回答:模型怎样把上一层提取出的特征综合起来,形成最终判断或新的特征表示。
如果说卷积层更擅长提取局部特征,池化层更擅长压缩特征图,那么全连接层更擅长进行整体信息整合。它通常出现在多层感知器、分类器输出头、回归模型输出层和卷积神经网络末端,是理解神经网络从"特征提取"走向"任务预测"的重要基础。
一、基本概念:什么是全连接层
全连接层(Fully Connected Layer)是一种神经网络层。它的特点是:上一层的每个输入,都连接到下一层的每个输出神经元。
假设上一层输出为:
全连接层有 m 个输出神经元,那么输出可以写为:
其中:
• x 表示输入向量
• W 表示权重矩阵
• b 表示偏置向量
• y 表示全连接层输出
• n 表示输入特征数量
• m 表示输出神经元数量
如果展开来看,第 j 个输出神经元为:
其中:
• yⱼ 表示第 j 个输出
• wⱼᵢ 表示第 i 个输入到第 j 个神经元的权重
• bⱼ 表示第 j 个神经元的偏置
从通俗角度看,全连接层可以理解为:让每个输出神经元都看见上一层的所有信息,然后根据权重进行综合判断。
全连接层的计算过程示意图
因此,全连接层也常被称为密集层(Dense Layer),因为它的连接关系非常密集。
二、为什么需要全连接层
全连接层之所以重要,是因为模型在完成预测前,往往需要把前面得到的特征进行综合。
例如,在图像分类中,前面的卷积层可能已经提取出:
• 边缘特征
• 纹理特征
• 局部形状
• 物体部件
• 高级语义特征
但是,仅仅有这些特征还不够。模型还需要判断:这些特征综合起来,更像猫、狗,还是汽车?
全连接层的作用就是:把前面提取出的各种特征组合起来,形成最终分类或回归结果。
在表格数据任务中,全连接层也非常常见。例如,用年龄、收入、地区、消费次数、历史点击率等特征预测用户是否会购买商品。全连接层可以把这些特征加权组合,学习它们与目标之间的关系。
从通俗角度看:
• 卷积层:负责发现局部特征
• 池化层:负责压缩和汇总特征
• 全连接层:负责综合所有特征并做判断
因此,全连接层经常出现在模型后半部分,承担"决策层"或"分类头"的角色。
三、全连接层的核心计算过程
全连接层的计算本质上是矩阵乘法加偏置。
假设输入向量为:
全连接层有 2 个输出神经元,那么权重矩阵可以写为:
偏置向量为:
输出为:
展开后:
从通俗角度看:每个输出神经元都把所有输入特征按不同权重加起来,再加上自己的偏置。
如果后面接激活函数,就变成:
其中:
• f 表示激活函数
• a 表示经过激活后的输出
例如,在隐藏层中常接 ReLU:
在输出层中,则根据任务不同选择不同形式:
• 回归任务:通常直接输出数值
• 二分类任务:常接 Sigmoid
• 多分类任务:常接 Softmax 或直接输出 logits 给交叉熵损失
四、全连接层与人工神经元的关系
全连接层可以看成许多人工神经元并排组成的一层。
一个人工神经元的计算是:
如果一层中有多个神经元,就会有多个权重向量和多个偏置:
把这些计算合在一起,就得到矩阵形式:
其中:
• W 的每一行可以看作一个神经元的权重向量
• b 的每一个元素对应一个神经元的偏置
• z 的每一个元素对应一个神经元的线性输出
从通俗角度看:一个全连接层就是一组人工神经元共同处理同一个输入向量。
每个神经元都从不同角度综合输入信息:
• 有的神经元可能关注某些特征组合
• 有的神经元可能抑制某些特征
• 有的神经元可能学习某种中间模式
因此,全连接层不是简单"把数字相加",而是让多个神经元同时学习不同的特征组合方式。
五、全连接层在不同任务中的作用
全连接层可以用于不同类型的任务。
1、分类任务
在分类任务中,全连接层常用于输出类别分数。
例如,一个模型要把图片分成 10 类,最后一层全连接层可以输出 10 个 logits:
其中:
• zₖ 表示第 k 个类别的原始分数
logits 经过 Softmax 后可以转换成类别概率。
多分类概率为:
从通俗角度看:分类任务中的全连接层负责给每个类别打分。
2、回归任务
在回归任务中,全连接层可以直接输出连续数值。
例如,预测房价时,最后一层可以只有一个输出神经元:
其中:
• ŷ 表示预测房价
• x₁, x₂, ..., xₙ 表示上一层特征
从通俗角度看:回归任务中的全连接层负责把特征综合成一个数值预测。
3、隐藏表示学习
全连接层也可以作为隐藏层使用。
例如:
输入特征 → 全连接层 → ReLU → 全连接层 → 输出
其中中间的全连接层会学习新的特征表示。
从通俗角度看:隐藏全连接层负责把原始特征重新组合成更适合任务的内部表示。
六、全连接层与卷积层的区别
全连接层常与卷积层进行比较。
1、连接方式不同
全连接层中,每个输出神经元连接上一层所有输入。
如果输入有 n 个特征、输出有 m 个神经元,那么权重数量为:
卷积层则采用局部连接。卷积核每次只看局部区域,而不是一次看完整输入。
从通俗角度看:
• 全连接层:每个神经元看全部输入
• 卷积层:每个卷积核看局部区域
2、参数共享不同
全连接层通常不共享参数。每个连接都有自己的权重。
卷积层使用参数共享。同一个卷积核会在输入的不同位置重复使用。
因此,卷积层在处理图像时参数量通常远小于全连接层。
3、适用场景不同
全连接层适合处理已经整理成向量的特征,例如:
• 表格数据
• 嵌入向量
• 卷积层提取后的高级特征
• 最终分类或回归输出
卷积层更适合处理具有空间局部结构的数据,例如:
• 图像
• 视频
• 语音频谱
• 时间序列局部模式
从通俗角度看:卷积层擅长提取局部模式,全连接层擅长整合全局特征。
七、全连接层的参数量问题
全连接层的一个重要特点是参数量可能很大。
假设输入维度为 n,输出维度为 m,那么权重参数数量为:
偏置参数数量为:
总参数量为:
例如,如果输入维度为 4096,输出维度为 1000,那么参数量为:
也就是约 409.7 万个参数。
从通俗角度看:全连接层很强大,但如果输入维度和输出维度都很大,参数会迅速增多。
这会带来几个问题:
• 计算成本增加
• 存储成本增加
• 训练时间变长
• 过拟合风险增加
因此,在现代卷积神经网络中,常用全局平均池化减少进入全连接层的特征维度,或者使用更轻量的分类头。
例如:
卷积特征图 → 全局平均池化 → 小型全连接分类层
这样可以减少参数量,提高模型泛化能力。
八、全连接层的优势、局限与使用注意事项
1、全连接层的主要优势
全连接层最大的优势是信息整合能力强。
它允许每个输出神经元访问所有输入特征,因此可以学习不同特征之间的组合关系。
其次,全连接层结构简单,数学形式清晰:
再次,全连接层适用范围广。
它既可以用于普通多层感知器,也可以作为 CNN、Transformer 或其他模型中的输出模块。
从通俗角度看,全连接层的优势在于:它能把一组特征全面综合起来,形成新的表示或最终判断。
2、全连接层的主要局限
全连接层也有明显局限。
首先,参数量容易很大。
输入维度和输出维度稍大,权重矩阵就会迅速膨胀。
其次,它不利用空间局部结构。
如果直接用全连接层处理图像,模型并不知道哪些像素相邻,也不会自然共享局部模式。
再次,全连接层容易过拟合。
参数越多,模型越容易记住训练集细节,而不是学到可泛化规律。
此外,全连接层对输入维度固定要求较强。
输入向量维度必须与权重矩阵匹配,否则无法计算。
3、使用全连接层时需要注意的问题
使用全连接层时,需要注意:
• 输入通常需要整理成向量形式
• 参数量随输入维度和输出维度快速增长
• 分类任务中最后一层常输出 logits
• 回归任务中最后一层通常直接输出连续值
• 隐藏全连接层后常接 ReLU、GELU 等激活函数
• 过拟合时可考虑 Dropout、权重衰减或减少神经元数量
• 图像任务中不宜过早把大尺寸图像直接展平成全连接输入
从实践角度看,全连接层适合整合高级特征,但不适合替代卷积层去处理原始图像中的局部结构。
九、Python 示例
下面给出几个简单示例,用来帮助理解全连接层的基本使用。
示例 1:用 NumPy 手动计算全连接层
php
import numpy as np
# 输入向量:3个特征x = np.array([1.0, 2.0, 3.0])
# 权重矩阵:2个输出神经元,每个神经元有3个权重(行:神经元,列:输入特征)W = np.array([ [0.2, -0.5, 1.0], [1.5, 0.3, -0.8]])
# 偏置向量:每个神经元一个偏置b = np.array([0.1, -0.2])
# 全连接层的线性变换:y = W·x + by = W @ x + b # @ 表示矩阵乘法
print("全连接层输出:", y) # 输出形状 (2,)这个例子对应公式:
其中:
• W 的每一行对应一个输出神经元的权重
• b 的每个元素对应一个输出神经元的偏置
• y 包含两个输出神经元的结果
示例 2:使用 PyTorch 创建全连接层
python
import torch # PyTorch框架import torch.nn as nn # 神经网络模块
# 创建全连接层(线性层):输入维度3,输出维度2layer = nn.Linear( in_features=3, # 输入特征数 out_features=2 # 输出神经元数)
# 生成一批随机输入:4个样本,每个样本3个特征x = torch.randn(4, 3)
# 前向传播:计算线性变换 y = x·W^T + by = layer(x)
print("输入形状:", x.shape) # torch.Size([4, 3])print("输出形状:", y.shape) # torch.Size([4, 2])这个例子中:
• nn.Linear(3, 2) 表示输入维度为 3,输出维度为 2
• 输入形状为 4 × 3
• 输出形状为 4 × 2
也就是说,每个样本都会被映射成 2 维输出。
示例 3:全连接层 + 激活函数
python
import torch import torch.nn as nn
# 定义一个简单的全连接网络:4维输入 → 16 → ReLU → 3维输出model = nn.Sequential( nn.Linear(4, 16), # 全连接层:4 → 16 nn.ReLU(), # ReLU激活 nn.Linear(16, 3) # 全连接层:16 → 3(输出logits))
# 生成一批数据:5个样本,每个样本4个特征x = torch.randn(5, 4)
# 前向传播,得到未归一化的类别分数(logits)logits = model(x)
print("输出 logits 形状:", logits.shape) # torch.Size([5, 3])print(logits)这个模型结构为:
4 维输入 → 16 维隐藏层 → ReLU → 3 类 logits
其中:
• 第一个全连接层学习隐藏表示
• ReLU 引入非线性
• 第二个全连接层输出类别分数
如果用于多分类任务,通常配合 nn.CrossEntropyLoss()。
示例 4:CNN 中的全连接分类头
python
import torchimport torch.nn as nn
# 定义一个简单的卷积神经网络(CNN)class SimpleCNN(nn.Module): def __init__(self): super().__init__()
# 特征提取部分:卷积 + ReLU + 池化 self.features = nn.Sequential( # 第一层卷积:输入3通道,输出16通道,3x3卷积核,padding=1保持尺寸 nn.Conv2d(3, 16, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2), # 2x2最大池化,尺寸减半(32→16)
# 第二层卷积:输入16通道,输出32通道,3x3卷积核,padding=1 nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2) # 尺寸再减半(16→8) )
# 分类部分:将特征图展平,然后全连接层输出10个类别 self.classifier = nn.Sequential( nn.Flatten(), # 将 [B,32,8,8] 展平为 [B,32*8*8] nn.Linear(32 * 8 * 8, 10) # 全连接层:2048维 → 10维(类别logits) )
def forward(self, x): x = self.features(x) # 通过卷积层提取特征 x = self.classifier(x) # 通过全连接层分类 return x
# 实例化模型model = SimpleCNN()
# 模拟一批输入:8张RGB图像,图像大小为32x32x = torch.randn(8, 3, 32, 32)
# 前向传播,得到输出logits(形状:8×10)logits = model(x)
print("输出 logits 形状:", logits.shape) # torch.Size([8, 10])这个模型中:
• 卷积层提取局部图像特征
• 池化层降低空间尺寸
• Flatten() 把特征图展平成向量
• Linear() 全连接层输出 10 个类别的 logits
从通俗角度看:卷积层提取特征 → 全连接层综合特征并分类。
示例 5:使用全局平均池化减少全连接层参数量
python
import torchimport torch.nn as nn
# 带全局平均池化(GAP)的简单CNNclass CNNWithGAP(nn.Module): def __init__(self): super().__init__() # 卷积特征提取部分 self.features = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3, padding=1), # 3→32通道,保持尺寸 nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3, padding=1), # 32→64通道 nn.ReLU() ) # 全局平均池化:将每个特征图降为1个值(输出形状 [B,64,1,1]) self.pool = nn.AdaptiveAvgPool2d((1, 1)) # 分类器:64维 → 10维(类别logits) self.classifier = nn.Linear(64, 10)
def forward(self, x): x = self.features(x) # 提取特征 x = self.pool(x) # GAP池化 x = torch.flatten(x, start_dim=1) # 展平为 [B,64] x = self.classifier(x) # 分类输出 return x
model = CNNWithGAP()
# 一批8张RGB图像,尺寸32×32x = torch.randn(8, 3, 32, 32)
logits = model(x) # 前向传播得到logits
print("输出 logits 形状:", logits.shape) # torch.Size([8, 10])这个例子中:
• 全局平均池化把每个通道压缩成一个数
• 原本较大的特征图被变成 64 维向量
• 最后的全连接层只需要从 64 维映射到 10 类
这能显著减少全连接层参数量。
📘 小结
全连接层是一种每个输入都连接到每个输出神经元的神经网络层。它的核心计算是 y = Wx + b,常用于整合特征、学习隐藏表示和输出分类或回归结果。全连接层信息综合能力强,但参数量容易较大,也不天然利用图像等数据的局部结构。对初学者而言,可以把全连接层理解为:让每个输出神经元都看到上一层的全部信息,并根据不同权重做综合判断。

"点赞有美意,赞赏是鼓励"