Claude Code 大型代码库最佳实践:从 CLAUDE.md 到 CODE_MAP.md 的上下文工程
本文根据项目目录中的视频内容整理,重点讲解 Claude Code 在大型代码库中的"(Harness)"搭建方法:如何用
CLAUDE.md、Hooks、Skills、Plugins、MCP、LSP 与 Subagents,把 AI 编程从"盲搜文件"升级成"按工程师方式理解项目后再修改代码"。
一、为什么大型代码库不能只靠一句 Prompt
在小项目里,我们可以直接让 Claude Code 搜索、阅读、修改。但在大型代码库里,常见问题会马上暴露出来:
- 项目目录太大,AI 不知道应该先看哪里;
- 业务模块边界不清,容易跨模块乱改;
- 代码规范、架构约束、陷阱经验散落在团队成员脑子里;
- 每次会话都重新探索,浪费上下文窗口;
- 只靠文本 grep,定位定义、引用和类型关系时噪声很大。
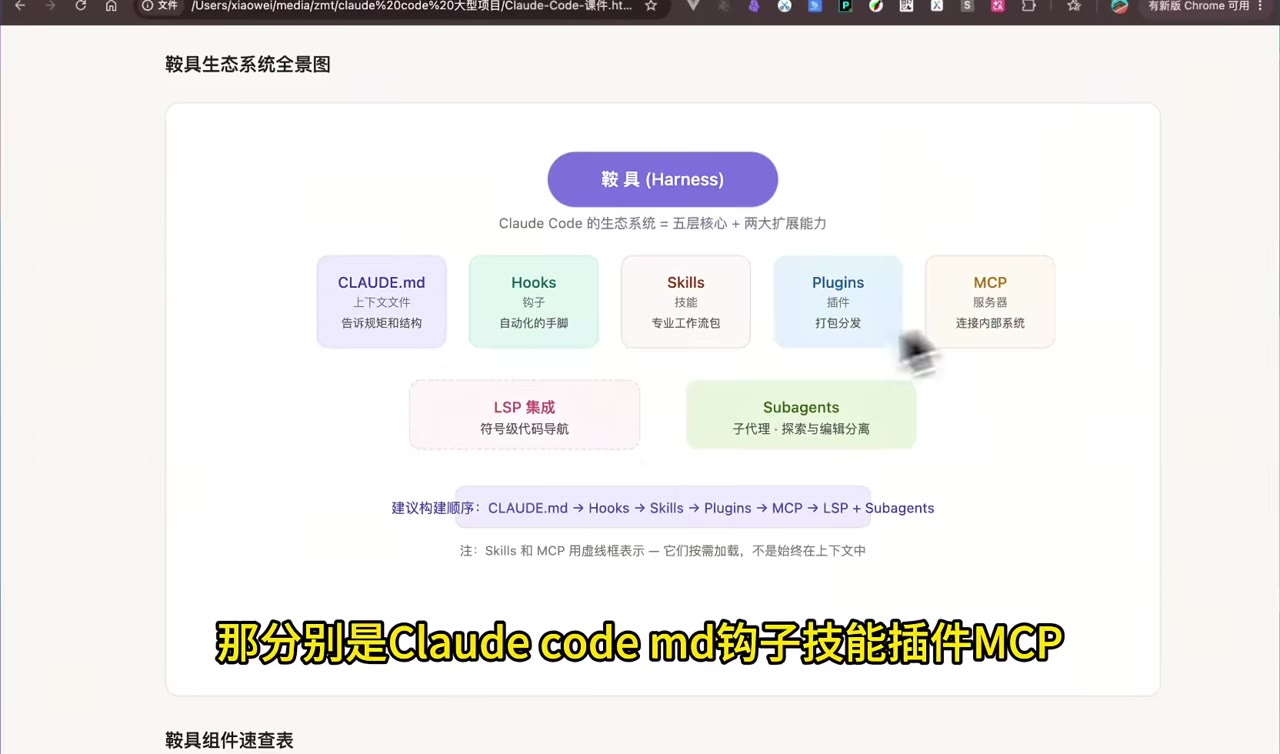
视频里的核心观点是:大型代码库需要先搭好"harness",再让 Claude Code 工作。所谓harness,就是一组上下文、自动化和工具接入机制,让 AI 在进入代码库时先获得地图、规则和边界。
推荐构建顺序:
text
CLAUDE.md -> Hooks -> Skills -> Plugins -> MCP -> LSP + Subagents底层先解决"项目地图和规则",再逐步增加自动化、可复用知识包、组织级分发、外部系统连接和多 Agent 协作。
二、harness组件速查
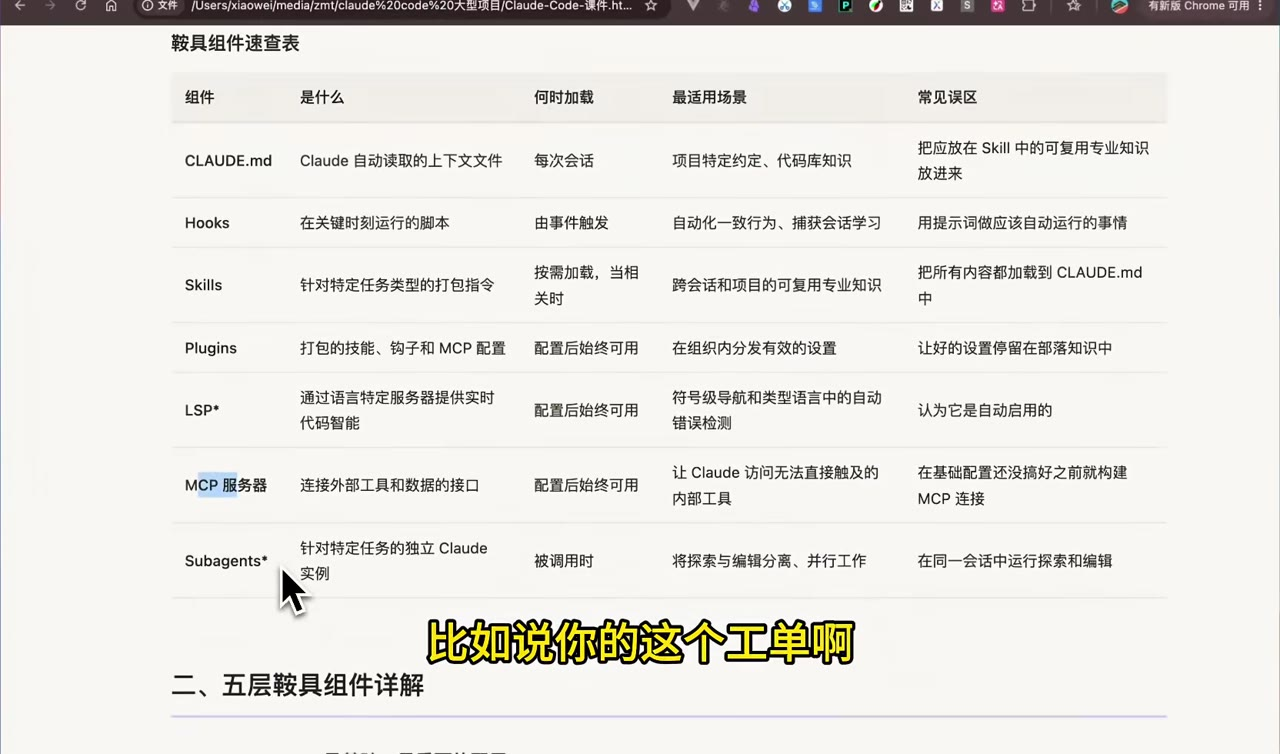
| 组件 | 作用 | 加载时机 | 适合场景 | 常见误区 |
|---|---|---|---|---|
CLAUDE.md |
Claude 自动读取的上下文文件 | 每次会话 | 项目约定、代码库知识、架构边界 | 把所有专业知识都塞进去 |
| Hooks | 关键事件触发的脚本 | 事件触发 | 自动 lint、format、记录经验 | 用 Hook 写提示词来指挥 Claude |
| Skills | 针对任务类型的专业知识包 | 按需加载 | 安全审查、文档更新、部署流程 | 把 Skill 全量展开到 CLAUDE.md |
| Plugins | 打包技能、钩子和 MCP 配置 | 配置后可用 | 团队内统一分发 | 配置只停留在个人机器 |
| LSP | 符号级代码导航 | 配置后可用 | 定义、引用、类型关系搜索 | 以为它会自动启用 |
| MCP Servers | 连接外部工具和数据 | 配置后可用 | 内部平台、CI/CD、知识库 | 基础配置没做好就先接 MCP |
| Subagents | 独立 Claude 实例 | 被调用时 | 探索和编辑分离、并行工作 | 在同一会话里混跑探索和修改 |
这里最重要的不是"组件越多越好",而是按优先级构建。没有 CLAUDE.md 的项目,Claude 只能靠猜;没有 Hooks,很多重复校验会依赖人工提醒;没有 LSP,搜索经常停留在关键字层面。
三、CLAUDE.md:让 Claude 自动获得上下文地图
CLAUDE.md 是 Claude Code 每次会话都会读取的上下文文件。它应该告诉 Claude:
- 项目的整体架构是什么;
- 关键目录分别负责什么;
- 哪些地方容易踩坑;
- 修改代码时必须遵守哪些约定;
- 搜索、测试、构建应该从哪里开始。
视频强调一个很关键的做法:CLAUDE.md 可以分层放置,而不是只在根目录写一份巨大的文档。
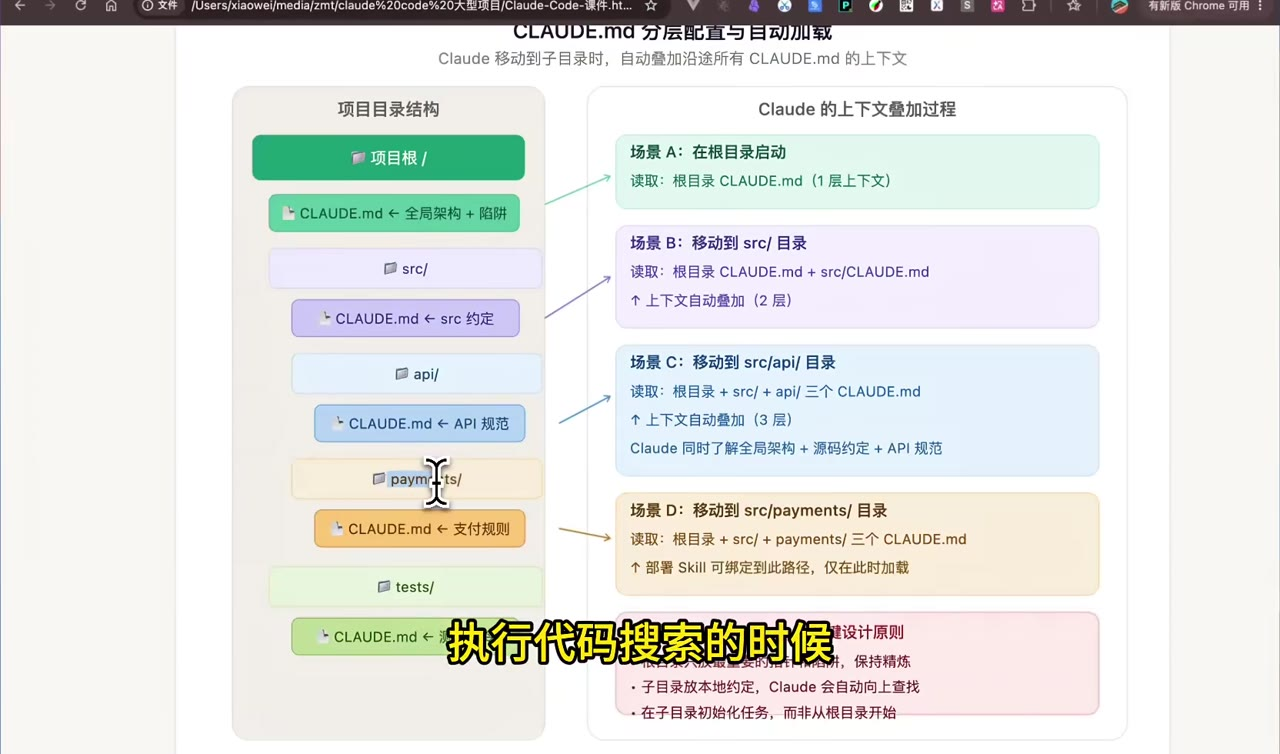
推荐结构:
text
project-root/
CLAUDE.md # 全局架构、通用约定、关键陷阱
CODE_MAP.md # 模块地图:去哪个目录找业务
src/
CLAUDE.md # src 目录约定
api/
CLAUDE.md # API 层规则
payments/
CLAUDE.md # 支付模块规则
tests/
CLAUDE.md # 测试约定当 Claude 进入更深层目录时,会自动叠加沿途的 CLAUDE.md。例如:
- 在根目录启动:读取根目录
CLAUDE.md; - 进入
src/:读取根目录 +src/CLAUDE.md; - 进入
src/api/:读取根目录 +src/CLAUDE.md+src/api/CLAUDE.md; - 进入
src/payments/:额外获得支付模块的业务规则。
这样做的好处是:根目录保持精炼,子目录维护本地约束。Claude 不需要一开始就吞下所有细节,而是在到达相关模块时自动获得更精确的上下文。
四、Hooks:把重复动作自动化
Hooks 是在关键事件发生时自动运行的脚本,适合处理"每次都应该做"的机械动作。
常见 Hook 场景:
- 会话结束:把本次经验沉淀到经验文件;
- 文件写入前:自动运行 lint 或 format 检查;
- 文件写入后:更新相关文档或生成变更日志;
- 提交前:跑测试、检查敏感信息、校验格式。
不要把 Hooks 当成"提示词系统"。提示词、规则和项目知识应该放在 CLAUDE.md 或 Skill 中;Hooks 更适合做确定性的自动化。
五、Skills:按需加载专业知识
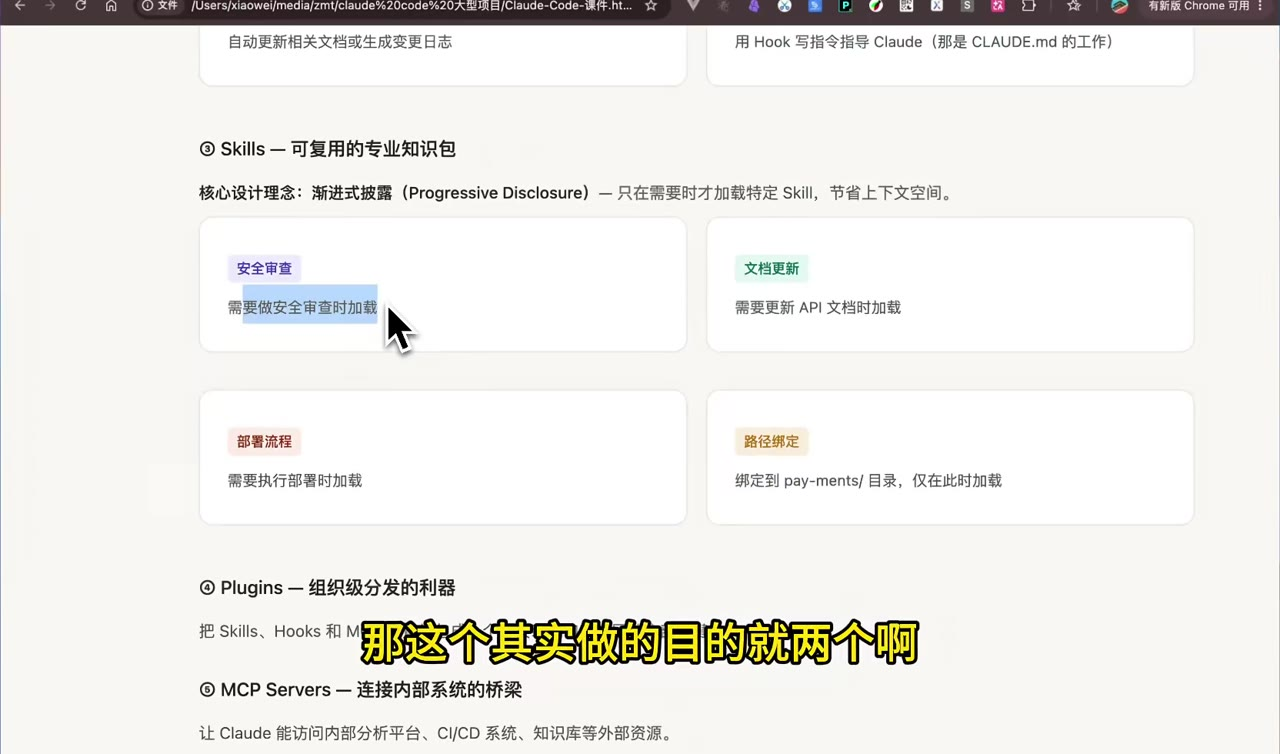
Skills 的核心设计理念是"渐进式披露":只有在任务需要时,才加载对应专业知识,避免长期占用上下文空间。
例如:
- 做安全审查时,加载安全审查 Skill;
- 更新 API 文档时,加载文档更新 Skill;
- 执行部署任务时,加载部署流程 Skill;
- 进入
payments/目录时,加载支付相关规则或路径绑定 Skill。
这和 CLAUDE.md 的边界不同:
CLAUDE.md放项目长期有效、每次都需要知道的上下文;- Skill 放可复用、跨会话、按需启用的专业工作流;
- 不要把所有 Skill 内容复制进
CLAUDE.md,否则会污染上下文。
六、MCP、Plugins 与 Subagents:扩展能力,但不要跳过基础层
MCP Servers 让 Claude 能访问内部分析平台、CI/CD 系统、知识库等外部资源。Plugins 则可以把 Skills、Hooks 和 MCP 配置打包,方便团队内部一键分发。
但视频中特别提醒:不要在基础配置还没搭好之前就急着接 MCP。合理顺序是:
- 先写好
CLAUDE.md,让 Claude 知道代码库地图和规则; - 再用 Hooks 固化重复校验;
- 再把专业流程沉淀成 Skills;
- 团队需要复用时,用 Plugins 分发;
- 最后再接 MCP 和 Subagents 扩展能力。
Subagents 适合把探索和编辑拆开:一个 Agent 负责阅读和定位,另一个 Agent 负责实施修改。对于大型代码库,这可以减少主会话上下文压力,也能避免"边找边改"带来的误判。
七、Claude Code 的 5 步工作流
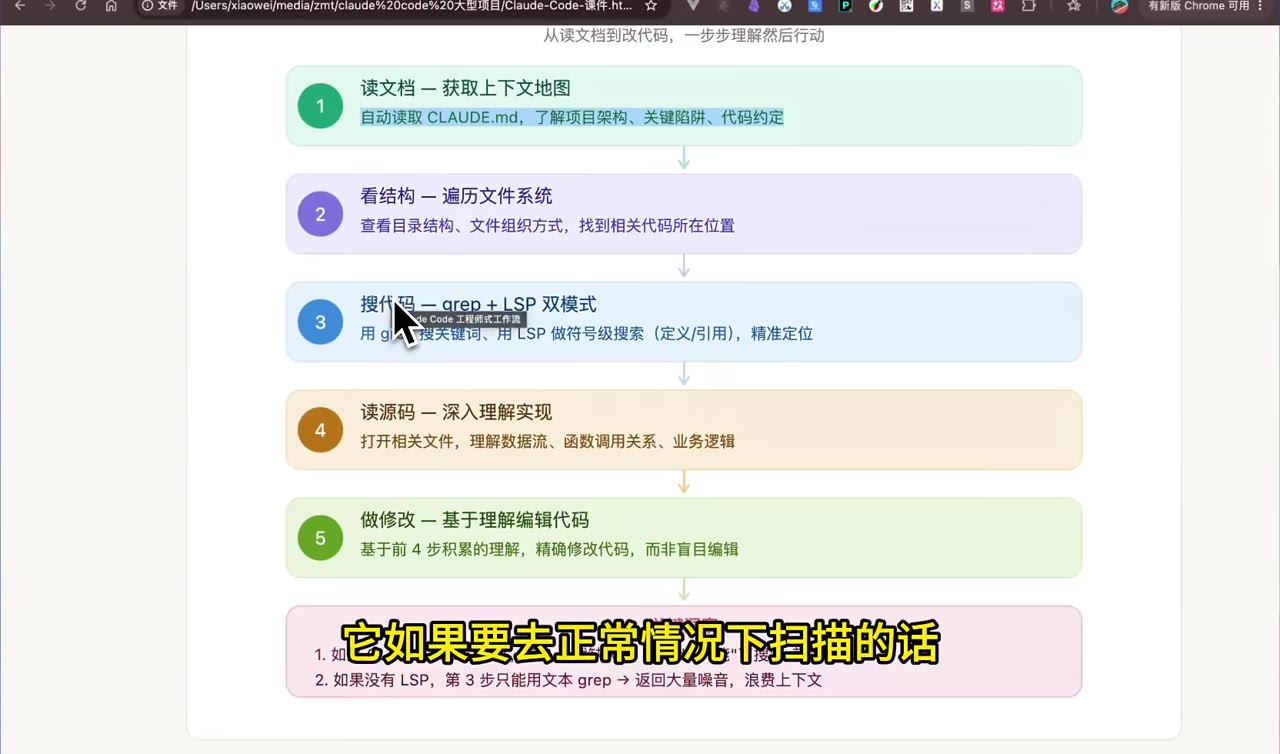
视频把 Claude Code 在大型代码库中的理想工作方式总结成 5 步:
- 读文档:自动读取
CLAUDE.md,获得项目结构、关键陷阱和代码约定; - 看结构:遍历文件系统,理解目录组织方式,找到相关代码位置;
- 搜代码:用 grep 搜关键字,用 LSP 做符号级搜索,定位定义和引用;
- 读源码:打开相关文件,理解数据流、函数调用关系和业务逻辑;
- 做修改:基于前 4 步的理解精确编辑代码,而不是盲目改。
这里的关键点是:Claude Code 应该像工程师一样"先理解,再行动"。如果没有 LSP,第三步只能靠文本搜索,返回结果会有大量噪声;如果没有上下文地图,前两步也会消耗大量时间。
八、CODE_MAP.md:给 Claude 一张业务模块地图
大型项目里,仅靠目录名不一定能判断业务边界。视频建议在根目录增加 CODE_MAP.md,专门回答一个问题:
遇到某类业务问题,应该去哪个模块?
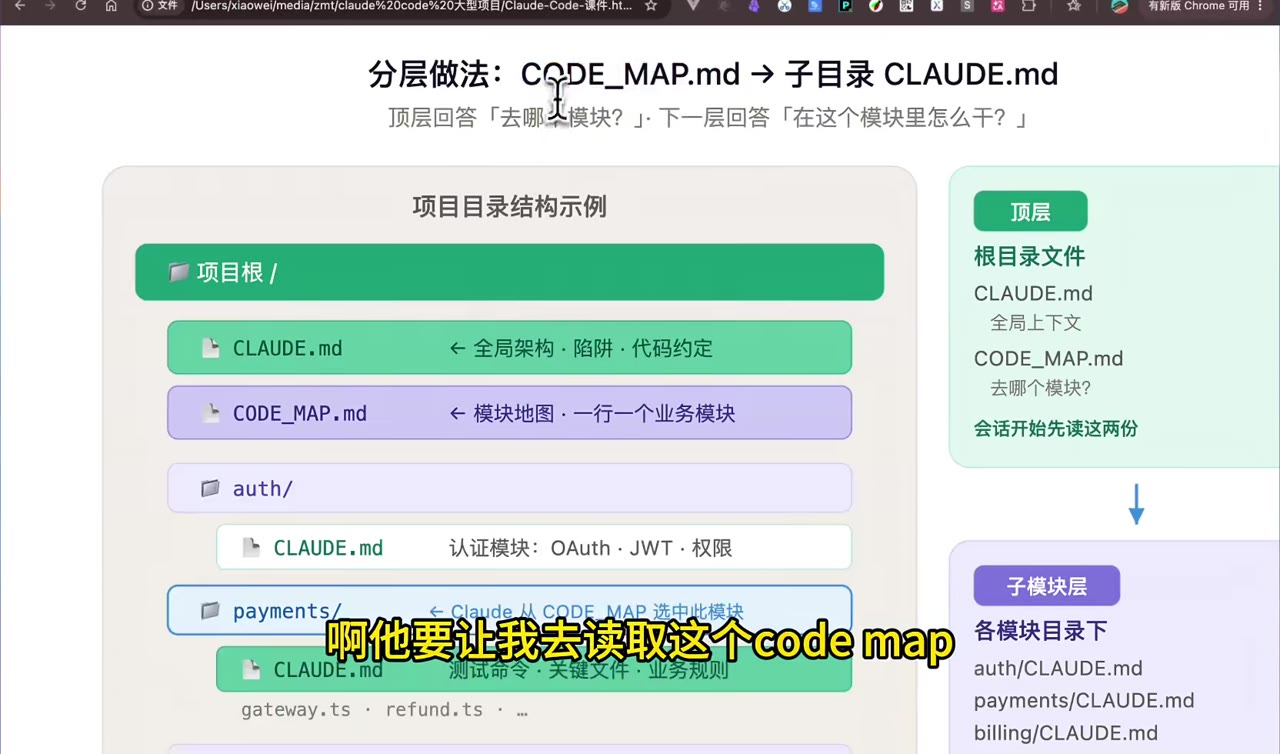
一个简化版 CODE_MAP.md 可以这样写:
md
# Code Map - 业务模块一览
- auth/:认证与授权,OAuth、JWT、权限控制
- payments/:支付处理,网关、退款、对账
- billing/:账单与订阅,周期计费、发票
- orders/:订单生命周期,下单、取消、履约
- notifications/:消息通知,邮件、推送、Webhook
- infra/:基础设施,K8s、CI/CD、监控然后在各模块目录下继续维护自己的 CLAUDE.md:
text
payments/
CLAUDE.md # 支付模块规则、测试命令、关键文件、业务陷阱
gateway.ts
refund.ts推荐读取顺序:
text
根目录 CLAUDE.md -> CODE_MAP.md 选择模块 -> 子目录 CLAUDE.md 读取细节这样顶层只回答"去哪个模块",下一层再回答"在这个模块里怎么干"。这比把所有模块细节都堆在根目录更可维护。
九、配置也有生命周期:旧规则要及时清理
视频中还提到一个容易被忽略的问题:AI 编程配置不是一次性文档,它会随着模型能力、团队规范和项目架构变化而演进。
比如:
- 新模型发布后,某些过度细碎的约束可能不再需要;
- 目录结构调整后,
CODE_MAP.md要同步更新; - 某些 Hook 从"强制检查"变成"工具链默认行为"后,可以删掉;
- 子目录
CLAUDE.md中过期的业务规则必须清理,否则会误导 Claude。
建议把 CLAUDE.md、CODE_MAP.md、Hooks、Skills 都当成工程资产维护,和代码一起 review。
十、Harness构建优先级金字塔
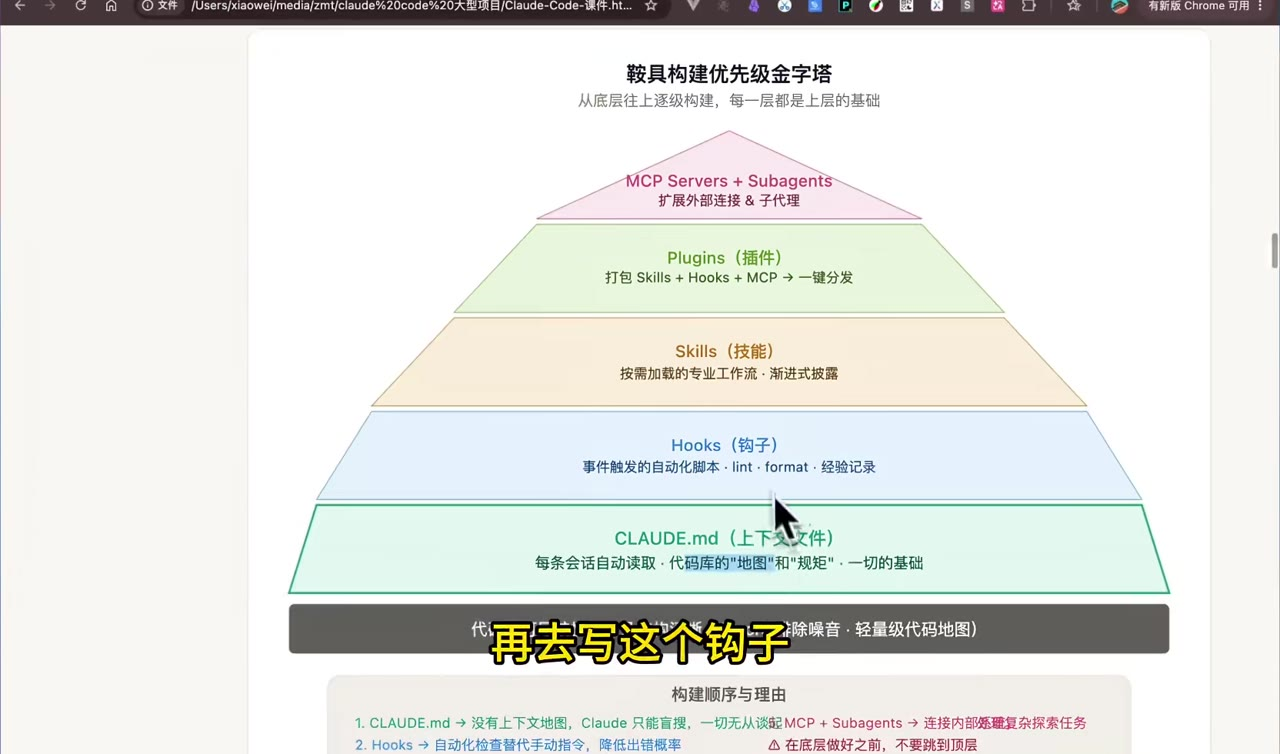
视频最后用金字塔总结了构建优先级:
text
MCP Servers + Subagents # 外部连接与多 Agent 协作
Plugins # 团队级打包分发
Skills # 按需加载的专业工作流
Hooks # 事件触发的自动化脚本
CLAUDE.md # 每次会话自动读取的上下文基础
轻量级代码地图 / 代码库索引 # 降噪、定位、理解边界我的理解是:越底层越应该先做,越上层越应该在团队真的需要时再引入。大型代码库里,最先要解决的不是"让 Claude 接更多系统",而是让它知道自己身处什么项目、应该遵守什么规则、应该去哪里找代码。
总结
这段视频最值得带走的实践是:
CLAUDE.md是基础,不是垃圾桶,只放每次会话都需要的上下文;- 子目录可以维护自己的
CLAUDE.md,让上下文随路径自动叠加; CODE_MAP.md负责业务模块导航,解决"问题该去哪一层找"的问题;- Hooks 做自动化,不负责提示词指挥;
- Skills 做按需专业知识加载,避免污染主上下文;
- LSP 让搜索从文本关键字升级到符号级导航;
- MCP、Plugins、Subagents 很有用,但应该建立在基础harness之上;
- 所有配置都需要生命周期管理,过期规则要及时清理。
如果要在自己的团队落地,建议先做三件事:
- 在根目录写一份精炼的
CLAUDE.md; - 新增
CODE_MAP.md,列清楚核心业务模块; - 给最复杂的 1 到 2 个子目录补充本地
CLAUDE.md。
等这三步稳定后,再逐步引入 Hooks、Skills、Plugins、MCP 和 Subagents。这样 Claude Code 才能在大型代码库里真正像一个熟悉项目的工程师一样工作。