Yao Wang ⋆ ^\star ⋆,Xin Wu ⋆ ^\star ⋆,Lianming Xu † ^\dagger †,Na Liu ⋆ ^\star ⋆,Li Wang ⋆ ^\star ⋆
⋆ ^\star ⋆ 北京邮电大学计算机学院(国家示范性软件学院),中国北京 100876
† ^\dagger † 北京邮电大学电子工程学院,中国北京 100876
文章目录
摘要
无线电地图能够丰富无线电传播和频谱占用信息,为无线通信系统的运行和优化提供基础支撑。传统无线电地图主要依靠大量人工信道测量获得,这种方式耗时且效率较低。为降低信道测量复杂度,近年来出现了基于新型人工智能技术的无线电地图估计(radio map estimation, RME)方法,用于从稀疏测量或少量观测中获得更高分辨率的无线电地图。然而,学习式方法存在黑盒问题并强依赖训练数据,因此可解释性较弱;而模型式方法虽具有较强理论基础,但性能通常弱于学习式方法。本文提出一种用于无线电地图估计的深度展开低秩张量补全网络(deep unrolled low-rank tensor completion network, DULRTC-RME),通过把繁琐的低秩张量补全优化过程展开为深度网络,将理论可解释性与学习能力结合起来。这是算法展开技术首次用于 RME 领域。实验结果表明,DULRTC-RME 优于现有 RME 方法。
**索引词:**无线电地图估计,信道建模,低秩张量补全,深度展开网络
I. 引言
作为无线通信系统的基础工具,无线电地图通常揭示通信环境在多个域(例如空间和频率)中的重要信息,并通过几何信号功率谱密度(power spectral density, PSD)等信道建模参数刻画通信环境 1。然而,稠密且完整的无线电地图通常无法直接获得,一般需要根据目标区域中传感器人工采集的稀疏观测进行估计。这些观测在空间域和频率域中都可能是稀疏的。因此,无线电地图估计(RME)的主要任务,是从这些稀疏观测中恢复相对更高分辨率的无线电地图 2。
早期 RME 方法大体可分为两类:基于模型的方法和基于学习的方法。基于模型的方法通常假设特定的无线电传播模型。例如,3 使用对数距离路径损耗(log-distance path loss, LDPL)插值模型来估计 WiFi 无线电地图。然而,这些理论模型往往难以完全适应复杂真实场景,因为它们无法捕捉阴影、障碍物等复杂结构,导致 RME 精度受限。
与依赖预先指定的人工模型先验不同,基于学习的方法从稀疏观测中"学习",并利用深度神经网络(deep neural networks, DNNs)捕捉无线电数据中的复杂潜在结构 5-7。尽管这类方法在处理复杂无线电环境方面展现出潜力,但它们高度依赖训练样本的数量和质量;而真实场景中的训练样本通常有限且存在偏差。此外,DNN 架构通常依赖经验设计,使其行为和性能难以分析与预测。
为兼顾基于模型和基于学习方法的优点并克服各自缺陷,受物理启发的机器学习方法 2 被引入以改进 RME。其中一种重要方法称为算法展开(algorithm unrolling)9,它通过把优化算法的每一次迭代实现为 DNN 的一层,从而连接深度网络与传统模型。受此启发,本文提出一种基于低秩张量补全的深度展开网络(DULRTC)用于 RME,如图 1 所示。具体而言,本文考虑无线电传播衰落特性,把 RME 建模为低秩张量补全问题,并引入正则化函数来补偿分解假设中的不准确性。该优化问题以迭代方式求解。通过将迭代算法分解为多个模块,本文将其转化为等价的 DNN;由于其理论基础来自低秩张量补全,因此该网络保持了可解释性。尽管算法展开已广泛用于图像和视频处理,但据我们所知,RME 方向的相关研究仍然有限。在 BART-Lab Radiomap Dataset 上的实验表明,DULRTC-RME 在恢复更准确、更高质量的无线电地图方面,优于传统插值方法和纯深度学习方法。
II. 所提出的 DULRTC-RME 算法
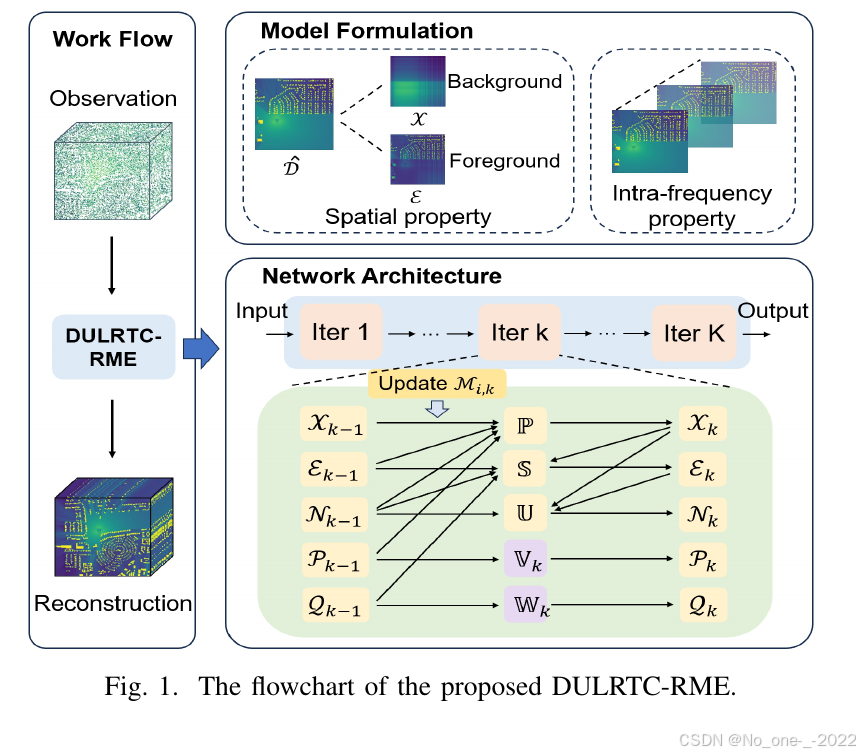
图 1. 所提出 DULRTC-RME 的流程图。
A. 数学预备知识
本文中,标量、向量、矩阵和张量分别用斜体小写字母(例如 x x x)、粗体小写字母(例如 x \mathbf{x} x)、斜体大写字母(例如 X X X)和粗体花体字母(例如 X \boldsymbol{\mathcal{X}} X)表示。 K K K 阶张量 X ∈ R I 1 × I 2 × ⋯ × I K \boldsymbol{\mathcal{X}}\in\mathbb{R}^{I_1\times I_2\times\cdots\times I_K} X∈RI1×I2×⋯×IK 在位置 ( i 1 , i 2 , ... , i K ) (i_1,i_2,\ldots,i_K) (i1,i2,...,iK) 处的元素记为 X ( i 1 , i 2 , ... , i K ) \boldsymbol{\mathcal{X}}(i_1,i_2,\ldots,i_K) X(i1,i2,...,iK)。对于三阶张量 X ∈ R n 1 × n 2 × n 3 \boldsymbol{\mathcal{X}}\in\mathbb{R}^{n_1\times n_2\times n_3} X∈Rn1×n2×n3,其第 i i i 个水平切片、侧向切片和正面切片分别表示为 X ( i , : , : ) \boldsymbol{\mathcal{X}}(i,:,:) X(i,:,:)、 X ( : , i , : ) \boldsymbol{\mathcal{X}}(:,i,:) X(:,i,:) 和 X ( : , : , i ) \boldsymbol{\mathcal{X}}(:,:,i) X(:,:,i)。两个张量 X , Y ∈ R n 1 × n 2 × ⋯ × n K \boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}\in\mathbb{R}^{n_1\times n_2\times\cdots\times n_K} X,Y∈Rn1×n2×⋯×nK 的内积定义为
⟨ X , Y ⟩ = ∑ i 1 , i 2 , ... , i K X ( i 1 , i 2 , ... , i K ) Y ( i 1 , i 2 , ... , i K ) . \langle\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}\rangle = \sum_{i_1,i_2,\ldots,i_K} \boldsymbol{\mathcal{X}}(i_1,i_2,\ldots,i_K) \boldsymbol{\mathcal{Y}}(i_1,i_2,\ldots,i_K). ⟨X,Y⟩=i1,i2,...,iK∑X(i1,i2,...,iK)Y(i1,i2,...,iK).
如果在张量中只保留一个自由度并固定其他所有维度,则可得到条带形式的纤维。为计算张量的 mode- m m m 展开,需要根据不同模式抽取纤维并重新排列组合。张量 X \boldsymbol{\mathcal{X}} X 的 mode- m m m 展开表示为 X ( m ) ∈ R n m × I m \boldsymbol{\mathcal{X}}{(m)}\in\mathbb{R}^{n_m\times I_m} X(m)∈Rnm×Im,其中 I m = ∏ k = 1 , k ≠ m N n k I_m=\prod{k=1,k\ne m}^{N}n_k Im=∏k=1,k=mNnk。张量元素 ( i 1 , i 2 , ... , i K ) (i_1,i_2,\ldots,i_K) (i1,i2,...,iK) 映射到矩阵元素 ( i m , j ) (i_m,j) (im,j),其中
j = 1 + ∑ k = 1 , k ≠ m N ( i k − 1 ) J k , J k = ∏ l = 1 , l ≠ m k − 1 n l . j=1+\sum_{k=1,k\ne m}^{N}(i_k-1)J_k,\qquad J_k=\prod_{l=1,l\ne m}^{k-1}n_l. j=1+k=1,k=m∑N(ik−1)Jk,Jk=l=1,l=m∏k−1nl.
B. 问题建模
假设目标地理区域的网格大小为 H × W H\times W H×W,其中包含若干个工作在特定 K K K 个频带上的发射机。稀疏测量表示为三阶张量 D ∈ R H × W × K \boldsymbol{\mathcal{D}}\in\mathbb{R}^{H\times W\times K} D∈RH×W×K。给定传感器在特定位置集合 Ω \Omega Ω 处采集 PSD 值,重构无线电地图记为 D ^ ∈ R H × W × K \widehat{\boldsymbol{\mathcal{D}}}\in\mathbb{R}^{H\times W\times K} D ∈RH×W×K,则有 P Ω ( D ) = P Ω ( D ^ ) \mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}})=\mathcal{P}{\Omega}(\widehat{\boldsymbol{\mathcal{D}}}) PΩ(D)=PΩ(D )。
基于无线电信号传播的复杂衰落特性,期望的无线电地图 D ^ \widehat{\boldsymbol{\mathcal{D}}} D 可以分解为两个部分:均匀背景 X \boldsymbol{\mathcal{X}} X 和稀疏前景 E \boldsymbol{\mathcal{E}} E。在空间域中,当信号在收发机之间长距离传播时,会发生大尺度衰落,形成主要取决于传播路径的路径损耗,因此呈现出规则且均匀的模式。在频率域中,同一空间场景内不同频率的无线电地图之间存在线性相关。因此, X \boldsymbol{\mathcal{X}} X 在空间域和频率域中都呈现低秩性。与此同时, E \boldsymbol{\mathcal{E}} E 保持稀疏,因为由反射、散射和绕射引起的小尺度衰落与地理空间建筑特征共同作用,使无线电地图中的大多数值为零。因此,多频 RME 问题可表述为
min X , E ∑ i = 1 3 α i ∥ X ( i ) ∥ ∗ + λ ∥ E ∥ 1 , s . t . P Ω ( X + E ) = P Ω ( D ) . (1) \begin{aligned} \min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{E}}}\quad &\sum_{i=1}^{3}\alpha_i\left\|\boldsymbol{\mathcal{X}}{(i)}\right\|* +\lambda\left\|\boldsymbol{\mathcal{E}}\right\|1,\\ \mathrm{s.t.}\quad &\mathcal{P}{\Omega}(\boldsymbol{\mathcal{X}}+\boldsymbol{\mathcal{E}}) = \mathcal{P}_{\Omega}(\boldsymbol{\mathcal{D}}). \end{aligned} \tag{1} X,Emins.t.i=1∑3αi X(i) ∗+λ∥E∥1,PΩ(X+E)=PΩ(D).(1)
注:
- 式 (1) 中的 ∥ X ( i ) ∥ ∗ \left\|\boldsymbol{\mathcal{X}}{(i)}\right\|* X(i) ∗ 不是普通绝对值;下标 ∗ * ∗ 表示核范数(nuclear norm),即第 i i i 个模展开矩阵 X ( i ) \boldsymbol{\mathcal{X}}_{(i)} X(i) 的奇异值之和。
- 因为 X ∈ R H × W × K \boldsymbol{\mathcal{X}}\in\mathbb{R}^{H\times W\times K} X∈RH×W×K 是三阶张量,论文不是直接最小化一个张量 rank,而是把它按三个 mode 展开为矩阵,并用 ∑ i = 1 3 α i ∥ X ( i ) ∥ ∗ \sum_{i=1}^{3}\alpha_i\left\|\boldsymbol{\mathcal{X}}{(i)}\right\|* ∑i=13αi X(i) ∗ 近似约束这些展开矩阵低秩。
- 直观上, X \boldsymbol{\mathcal{X}} X 表示由大尺度路径损耗和频率相关性形成的平滑背景,因此应具有低秩结构; E \boldsymbol{\mathcal{E}} E 表示由遮挡、散射、建筑物等造成的局部异常,因此用 ∥ E ∥ 1 \left\|\boldsymbol{\mathcal{E}}\right\|_1 ∥E∥1 约束其稀疏性。
由于张量秩难以直接求解,本文使用不同模式下张量展开矩阵核范数之和作为张量秩的凸近似。上述基于特定假设的模型可能无法准确表示真实场景中的所有特征。为解决这一限制,本文遵循 13 的方法,加入正则化函数 f : R H × W × K → R f:\mathbb{R}^{H\times W\times K}\to\mathbb{R} f:RH×W×K→R 和 g : R H × W × K → R g:\mathbb{R}^{H\times W\times K}\to\mathbb{R} g:RH×W×K→R,以补偿建模误差。此外,为考虑真实情况下的噪声,本文引入松弛变量 N \boldsymbol{\mathcal{N}} N,并最终将优化问题重新表述为
min X , E ∑ i = 1 3 α i ∥ X ( i ) ∥ ∗ + λ ∥ E ∥ 1 + f ( X ) + g ( E ) , s . t . X + E + N = P Ω ( D ) , ∥ P Ω ( N ) ∥ F ≤ δ , (2) \begin{aligned} \min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{E}}}\quad &\sum_{i=1}^{3}\alpha_i\left\|\boldsymbol{\mathcal{X}}{(i)}\right\|* +\lambda\left\|\boldsymbol{\mathcal{E}}\right\|1 +f(\boldsymbol{\mathcal{X}}) +g(\boldsymbol{\mathcal{E}}),\\ \mathrm{s.t.}\quad &\boldsymbol{\mathcal{X}}+\boldsymbol{\mathcal{E}}+\boldsymbol{\mathcal{N}} = \mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}}),\\ &\left\|\mathcal{P}_{\Omega}(\boldsymbol{\mathcal{N}})\right\|_F\le \delta, \end{aligned} \tag{2} X,Emins.t.i=1∑3αi X(i) ∗+λ∥E∥1+f(X)+g(E),X+E+N=PΩ(D),∥PΩ(N)∥F≤δ,(2)
其中 δ \delta δ 为噪声阈值。
C. 优化问题的解法
式 (2) 是一个含不可微项且参数相互关联的凸问题。因此,本文引入辅助变量 P \boldsymbol{\mathcal{P}} P 和 Q \boldsymbol{\mathcal{Q}} Q,并采用交替方向乘子法(ADMM)14,把优化问题分别拆分为 X \boldsymbol{\mathcal{X}} X、 E \boldsymbol{\mathcal{E}} E、 N \boldsymbol{\mathcal{N}} N、 P \boldsymbol{\mathcal{P}} P、 Q \boldsymbol{\mathcal{Q}} Q 子问题。增广拉格朗日函数写为
L ( X , E , N , P , Q , Λ , Γ , Φ ) = ∑ i = 1 3 α i ∥ X ( i ) ∥ ∗ + λ ∥ E ∥ 1 + ⟨ Λ , P Ω ( D ) − X − E − N ⟩ + μ 2 ∥ P Ω ( D ) − X − E − N ∥ F 2 + f ( P ) + ⟨ Γ , X − P ⟩ + θ 2 ∥ X − P ∥ F 2 + g ( Q ) + ⟨ Φ , E − Q ⟩ + β 2 ∥ E − Q ∥ F 2 , (3) \begin{aligned} \mathcal{L}( \boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{E}},\boldsymbol{\mathcal{N}}, \boldsymbol{\mathcal{P}},\boldsymbol{\mathcal{Q}}, \boldsymbol{\Lambda},\boldsymbol{\Gamma},\boldsymbol{\Phi}) =& \sum_{i=1}^{3}\alpha_i\left\|\boldsymbol{\mathcal{X}}{(i)}\right\|* +\lambda\left\|\boldsymbol{\mathcal{E}}\right\|1\\ &+\left\langle \boldsymbol{\Lambda}, \mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}}) -\boldsymbol{\mathcal{X}}-\boldsymbol{\mathcal{E}}-\boldsymbol{\mathcal{N}} \right\rangle\\ &+\frac{\mu}{2} \left\| \mathcal{P}_{\Omega}(\boldsymbol{\mathcal{D}}) -\boldsymbol{\mathcal{X}}-\boldsymbol{\mathcal{E}}-\boldsymbol{\mathcal{N}} \right\|_F^2\\ &+f(\boldsymbol{\mathcal{P}}) +\left\langle \boldsymbol{\Gamma},\boldsymbol{\mathcal{X}}-\boldsymbol{\mathcal{P}} \right\rangle +\frac{\theta}{2}\left\|\boldsymbol{\mathcal{X}}-\boldsymbol{\mathcal{P}}\right\|_F^2\\ &+g(\boldsymbol{\mathcal{Q}}) +\left\langle \boldsymbol{\Phi},\boldsymbol{\mathcal{E}}-\boldsymbol{\mathcal{Q}} \right\rangle +\frac{\beta}{2}\left\|\boldsymbol{\mathcal{E}}-\boldsymbol{\mathcal{Q}}\right\|_F^2, \end{aligned} \tag{3} L(X,E,N,P,Q,Λ,Γ,Φ)=i=1∑3αi X(i) ∗+λ∥E∥1+⟨Λ,PΩ(D)−X−E−N⟩+2μ∥PΩ(D)−X−E−N∥F2+f(P)+⟨Γ,X−P⟩+2θ∥X−P∥F2+g(Q)+⟨Φ,E−Q⟩+2β∥E−Q∥F2,(3)
其中 μ , θ , β > 0 \mu,\theta,\beta>0 μ,θ,β>0,惩罚项 Λ , Γ , Φ ∈ R H × W × K \boldsymbol{\Lambda},\boldsymbol{\Gamma},\boldsymbol{\Phi}\in\mathbb{R}^{H\times W\times K} Λ,Γ,Φ∈RH×W×K 为拉格朗日乘子张量。
** X \boldsymbol{\mathcal{X}} X 子问题:**通过对 L \mathcal{L} L 关于 X \boldsymbol{\mathcal{X}} X 求偏导, X \boldsymbol{\mathcal{X}} X 的更新为
X k + 1 = arg min X 1 μ k + θ k ∑ i = 1 3 α i , k ∥ X ( i ) ∥ ∗ + 1 2 ∥ X − Ψ X , k ∥ F 2 , (4) \boldsymbol{\mathcal{X}}{k+1} = \arg\min{\boldsymbol{\mathcal{X}}} \frac{1}{\mu_k+\theta_k} \sum_{i=1}^{3} \alpha_{i,k}\left\|\boldsymbol{\mathcal{X}}{(i)}\right\|* +\frac{1}{2} \left\| \boldsymbol{\mathcal{X}}-\boldsymbol{\Psi}_{\boldsymbol{\mathcal{X}},k} \right\|_F^2, \tag{4} Xk+1=argXminμk+θk1i=1∑3αi,k X(i) ∗+21∥X−ΨX,k∥F2,(4)
其中
Ψ X , k = 1 μ k + θ k ( Λ k + μ k P Ω ( D ) − μ k E k − μ k N k + θ k P k − Γ k ) . \boldsymbol{\Psi}_{\boldsymbol{\mathcal{X}},k} = \frac{1}{\mu_k+\theta_k} \left( \boldsymbol{\Lambda}k +\mu_k\mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}}) -\mu_k\boldsymbol{\mathcal{E}}_k -\mu_k\boldsymbol{\mathcal{N}}_k +\theta_k\boldsymbol{\mathcal{P}}_k -\boldsymbol{\Gamma}_k \right). ΨX,k=μk+θk1(Λk+μkPΩ(D)−μkEk−μkNk+θkPk−Γk).
由于计算核范数时 X ( i ) \boldsymbol{\mathcal{X}}_{(i)} X(i) 之间相互依赖,本文引入新的辅助参数 M i = X , i = 1 , 2 , 3 \boldsymbol{\mathcal{M}}_i=\boldsymbol{\mathcal{X}},\ i=1,2,3 Mi=X, i=1,2,3 以及对应的拉格朗日乘子 Y i \boldsymbol{\mathcal{Y}}_i Yi。该问题分别拆分为 M i \boldsymbol{\mathcal{M}}_i Mi 子问题和 X \boldsymbol{\mathcal{X}} X 子问题。以下解法参考 HaLRTC 算法 10:
M i , k + 1 = fold D α i ρ ( X k , ( i ) + 1 ρ ( Y i , k ) ( i ) ) , (5) \boldsymbol{\mathcal{M}}_{i,k+1} = \operatorname{fold}\left \\mathcal{D}_{\\frac{\\alpha_i}{\\rho}} \\left( \\boldsymbol{\\mathcal{X}}_{k,(i)} +\\frac{1}{\\rho} \\left(\\boldsymbol{\\mathcal{Y}}_{i,k}\\right)_{(i)} \\right) \\right, \tag{5} Mi,k+1=foldDραi(Xk,(i)+ρ1(Yi,k)(i)),(5)
X k + 1 = ρ ∑ i = 1 3 ( M i , k + 1 − 1 ρ Y i , k ) + ( μ k + θ k ) Ψ X , k 3 ρ + μ k + θ k . (6) \boldsymbol{\mathcal{X}}{k+1} = \frac{ \rho\sum{i=1}^{3} \left(\boldsymbol{\mathcal{M}}{i,k+1} -\frac{1}{\rho}\boldsymbol{\mathcal{Y}}{i,k}\right) +(\mu_k+\theta_k)\boldsymbol{\Psi}_{\boldsymbol{\mathcal{X}},k} }{ 3\rho+\mu_k+\theta_k }. \tag{6} Xk+1=3ρ+μk+θkρ∑i=13(Mi,k+1−ρ1Yi,k)+(μk+θk)ΨX,k.(6)
** E \boldsymbol{\mathcal{E}} E 子问题:**接着,通过求解以下问题估计 E \boldsymbol{\mathcal{E}} E:
E k + 1 = arg min E λ k μ k + β k ∥ E ∥ 1 + 1 2 ∥ E − Ψ E , k ∥ F 2 , (7) \boldsymbol{\mathcal{E}}{k+1} = \arg\min{\boldsymbol{\mathcal{E}}} \frac{\lambda_k}{\mu_k+\beta_k} \left\|\boldsymbol{\mathcal{E}}\right\|1 +\frac{1}{2} \left\| \boldsymbol{\mathcal{E}}-\boldsymbol{\Psi}{\boldsymbol{\mathcal{E}},k} \right\|_F^2, \tag{7} Ek+1=argEminμk+βkλk∥E∥1+21∥E−ΨE,k∥F2,(7)
其中
Ψ E , k = 1 μ k + β k ( Λ k + μ k P Ω ( D ) − μ k X k + 1 − μ k N k + β k Q k − Φ k ) . \boldsymbol{\Psi}{\boldsymbol{\mathcal{E}},k} = \frac{1}{\mu_k+\beta_k} \left( \boldsymbol{\Lambda}k +\mu_k\mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}}) -\mu_k\boldsymbol{\mathcal{X}}{k+1} -\mu_k\boldsymbol{\mathcal{N}}_k +\beta_k\boldsymbol{\mathcal{Q}}_k -\boldsymbol{\Phi}_k \right). ΨE,k=μk+βk1(Λk+μkPΩ(D)−μkXk+1−μkNk+βkQk−Φk).
应用 SVT 算法后,可得到
E k + 1 = D λ k μ k + β k ( Ψ E , k ) . (8) \boldsymbol{\mathcal{E}}{k+1} = \mathcal{D}{\frac{\lambda_k}{\mu_k+\beta_k}} \left( \boldsymbol{\Psi}_{\boldsymbol{\mathcal{E}},k} \right). \tag{8} Ek+1=Dμk+βkλk(ΨE,k).(8)
** N \boldsymbol{\mathcal{N}} N 子问题:**令 lim N = ∥ P Ω ( N ) ∥ F ≤ δ k \lim_{\boldsymbol{\mathcal{N}}}=\left\|\mathcal{P}_{\Omega}(\boldsymbol{\mathcal{N}})\right\|_F\le\delta_k limN=∥PΩ(N)∥F≤δk,可通过求解以下方程估计 N \boldsymbol{\mathcal{N}} N:
N k + 1 = arg min lim N ∥ N − Ψ N , k ∥ F 2 , (9) \boldsymbol{\mathcal{N}}{k+1} = \arg\min{\lim_{\boldsymbol{\mathcal{N}}}} \left\| \boldsymbol{\mathcal{N}}-\boldsymbol{\Psi}_{\boldsymbol{\mathcal{N}},k} \right\|_F^2, \tag{9} Nk+1=arglimNmin∥N−ΨN,k∥F2,(9)
其中
Ψ N , k = P Ω ( D ) − X k + 1 − E k + 1 + 1 μ k Λ k . \boldsymbol{\Psi}{\boldsymbol{\mathcal{N}},k} = \mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}}) -\boldsymbol{\mathcal{X}}{k+1} -\boldsymbol{\mathcal{E}}{k+1} +\frac{1}{\mu_k}\boldsymbol{\Lambda}_k. ΨN,k=PΩ(D)−Xk+1−Ek+1+μk1Λk.
根据 11,其解为
N k + 1 = P Ω C ( Ψ N , k ) + min { δ k ∥ P Ω ( Ψ N , k ) ∥ F , 1 } P Ω ( Ψ N , k ) . (10) \boldsymbol{\mathcal{N}}{k+1} = \mathcal{P}{\Omega^C} \left( \boldsymbol{\Psi}{\boldsymbol{\mathcal{N}},k} \right) + \min\left\{ \frac{\delta_k} {\left\| \mathcal{P}{\Omega} \left( \boldsymbol{\Psi}{\boldsymbol{\mathcal{N}},k} \right) \right\|F}, 1 \right\} \mathcal{P}{\Omega} \left( \boldsymbol{\Psi}{\boldsymbol{\mathcal{N}},k} \right). \tag{10} Nk+1=PΩC(ΨN,k)+min{∥PΩ(ΨN,k)∥Fδk,1}PΩ(ΨN,k).(10)
** P \boldsymbol{\mathcal{P}} P 和 Q \boldsymbol{\mathcal{Q}} Q 子问题:**第 k + 1 k+1 k+1 次迭代中的参数 P \boldsymbol{\mathcal{P}} P 和 Q \boldsymbol{\mathcal{Q}} Q 可表示为
P k + 1 = arg min P f ( P ) + θ k 2 ∥ P − ( X k + 1 + 1 θ k Γ k ) ∥ F 2 = prox f ( X k + 1 + 1 θ k Γ k ) , (11) \begin{aligned} \boldsymbol{\mathcal{P}}{k+1} &= \arg\min{\boldsymbol{\mathcal{P}}} f(\boldsymbol{\mathcal{P}}) +\frac{\theta_k}{2} \left\| \boldsymbol{\mathcal{P}} -\left( \boldsymbol{\mathcal{X}}_{k+1} +\frac{1}{\theta_k}\boldsymbol{\Gamma}_k \right) \right\|_F^2\\ &= \operatorname{prox}f \left( \boldsymbol{\mathcal{X}}{k+1} +\frac{1}{\theta_k}\boldsymbol{\Gamma}_k \right), \end{aligned} \tag{11} Pk+1=argPminf(P)+2θk P−(Xk+1+θk1Γk) F2=proxf(Xk+1+θk1Γk),(11)
Q k + 1 = arg min Q g ( Q ) + β k 2 ∥ Q − ( E k + 1 + 1 β k Φ k ) ∥ F 2 = prox g ( E k + 1 + 1 β k Φ k ) , (12) \begin{aligned} \boldsymbol{\mathcal{Q}}{k+1} &= \arg\min{\boldsymbol{\mathcal{Q}}} g(\boldsymbol{\mathcal{Q}}) +\frac{\beta_k}{2} \left\| \boldsymbol{\mathcal{Q}} -\left( \boldsymbol{\mathcal{E}}_{k+1} +\frac{1}{\beta_k}\boldsymbol{\Phi}_k \right) \right\|_F^2\\ &= \operatorname{prox}g \left( \boldsymbol{\mathcal{E}}{k+1} +\frac{1}{\beta_k}\boldsymbol{\Phi}_k \right), \end{aligned} \tag{12} Qk+1=argQming(Q)+2βk Q−(Ek+1+βk1Φk) F2=proxg(Ek+1+βk1Φk),(12)
其中 prox f ( ⋅ ) \operatorname{prox}_f(\cdot) proxf(⋅) 和 prox g ( ⋅ ) \operatorname{prox}_g(\cdot) proxg(⋅) 分别表示正则化函数 f ( ⋅ ) f(\cdot) f(⋅) 和 g ( ⋅ ) g(\cdot) g(⋅) 的近端算子。
注:
- 在标准 ADMM 中, f f f 和 g g g 一般是人为设计的正则项或先验项,用来表达希望变量满足的结构。基本原则是:相信变量具有什么性质,就给它添加对应的正则项;同时还要保证对应的近端算子 prox f ( ⋅ ) \operatorname{prox}_f(\cdot) proxf(⋅)、 prox g ( ⋅ ) \operatorname{prox}_g(\cdot) proxg(⋅) 尽量容易计算,否则每一步 ADMM 更新会变得很重。
变量 常见先验 常见正则项或约束 近端/更新直觉 平滑背景 X \boldsymbol{\mathcal{X}} X 空间平滑、低频变化、结构连续、跨频相关 TV 正则、Tikhonov 正则、图拉普拉斯正则、非局部相似性、低秩约束 去除局部噪声和不规则扰动,保留整体传播趋势和跨频结构 稀疏异常 E \boldsymbol{\mathcal{E}} E 局部遮挡、散射、异常点、建筑物影响较稀疏 l 1 l_1 l1 正则、变换域稀疏正则、梯度稀疏正则 通过阈值/收缩操作保留显著异常,压制小幅扰动 噪声 N \boldsymbol{\mathcal{N}} N 能量有限、观测误差较小 Frobenius 范数约束或二范数约束 把噪声限制在允许半径内,避免噪声项吸收真实结构
- 在普通手工 ADMM 设计中,通常是先明确写出 f , g f,g f,g 的解析形式,再推导或调用对应的近端算子:
手工设计 f , g ⟹ 手工推导 prox f , prox g . \text{手工设计 } f,g \quad\Longrightarrow\quad \text{手工推导 } \operatorname{prox}_f,\operatorname{prox}_g. 手工设计 f,g⟹手工推导 proxf,proxg.
例如 l 1 l_1 l1 正则的近端算子是 soft-thresholding;TV 正则也有成熟求解器。选择这些正则项的一个重要原因,就是它们对应的近端更新相对容易实现。
这篇论文的区别是:作者没有显式写出 f ( X ) f(\boldsymbol{\mathcal{X}}) f(X) 和 g ( E ) g(\boldsymbol{\mathcal{E}}) g(E) 的具体函数形式。它们在式 (2) 中只是作为额外正则项出现,用来补偿"低秩背景 X \boldsymbol{\mathcal{X}} X + 稀疏前景 E \boldsymbol{\mathcal{E}} E"这一理想模型对真实无线电地图刻画不足的问题。
通过引入辅助变量 P \boldsymbol{\mathcal{P}} P 和 Q \boldsymbol{\mathcal{Q}} Q,ADMM 把 f f f 和 g g g 分离到式 (11)、(12) 的近端更新中:
P k + 1 = prox f ( X k + 1 + 1 θ k Γ k ) , Q k + 1 = prox g ( E k + 1 + 1 β k Φ k ) . \boldsymbol{\mathcal{P}}_{k+1} = \operatorname{prox}f \left( \boldsymbol{\mathcal{X}}{k+1} + \frac{1}{\theta_k}\boldsymbol{\Gamma}k \right), \qquad \boldsymbol{\mathcal{Q}}{k+1} = \operatorname{prox}g \left( \boldsymbol{\mathcal{E}}{k+1} + \frac{1}{\beta_k}\boldsymbol{\Phi}_k \right). Pk+1=proxf(Xk+1+θk1Γk),Qk+1=proxg(Ek+1+βk1Φk).
- 深度展开后的 DULRTC-RME 保留 ADMM 的主体结构,但不再手工指定 prox f \operatorname{prox}_f proxf 和 prox g \operatorname{prox}_g proxg。作者用第 k k k 层的 CNN 模块 V k \mathbb{V}_k Vk 和 W k \mathbb{W}_k Wk 来学习这两个近端映射:
P k + 1 = V k ( X k + 1 + 1 θ k Γ k ) , Q k + 1 = W k ( E k + 1 + 1 β k Φ k ) . \boldsymbol{\mathcal{P}}_{k+1} = \mathbb{V}k \left( \boldsymbol{\mathcal{X}}{k+1} + \frac{1}{\theta_k}\boldsymbol{\Gamma}k \right), \qquad \boldsymbol{\mathcal{Q}}{k+1} = \mathbb{W}k \left( \boldsymbol{\mathcal{E}}{k+1} + \frac{1}{\beta_k}\boldsymbol{\Phi}_k \right). Pk+1=Vk(Xk+1+θk1Γk),Qk+1=Wk(Ek+1+βk1Φk).
因此,在本文中 f , g f,g f,g 更像是"隐式正则项":论文保留了优化模型中的 f , g f,g f,g 位置和 ADMM 更新逻辑,但实际效果由训练得到的 CNN 近端算子体现。 V k \mathbb{V}_k Vk 主要学习背景项 X \boldsymbol{\mathcal{X}} X 中的空间连续性、建筑阴影和跨频相关结构; W k \mathbb{W}_k Wk 主要学习前景/异常项 E \boldsymbol{\mathcal{E}} E 中由遮挡、散射、突变区域等造成的局部复杂扰动。
可以把标准 ADMM 与本文方法的区别概括为:
标准 ADMM:手工设计 f , g → 手工求 prox f , prox g \boxed{ \text{标准 ADMM:手工设计 } f,g \rightarrow \text{手工求 } \operatorname{prox}_f,\operatorname{prox}_g } 标准 ADMM:手工设计 f,g→手工求 proxf,proxg
DULRTC-RME:保留 ADMM 主体结构 + 用 CNN 学习 prox f , prox g \boxed{ \text{DULRTC-RME:保留 ADMM 主体结构} + \text{用 CNN 学习 } \operatorname{prox}_f,\operatorname{prox}_g } DULRTC-RME:保留 ADMM 主体结构+用 CNN 学习 proxf,proxg
D. 深度展开网络
本文将迭代式张量补全算法转换为深度网络中的一系列模块。图 1 的"Network Architecture"部分展示了 DULRTC-RME 的结构。初始时输入观测张量,其他所有变量均设为 0。网络由 K K K 个展开块组成,优化变量在其中迭代更新。在每个块中, X \boldsymbol{\mathcal{X}} X、 E \boldsymbol{\mathcal{E}} E 和 N \boldsymbol{\mathcal{N}} N 通过闭式解更新。具体而言,有 X k + 1 = P ( M i , k + 1 , Ψ X , k ) \boldsymbol{\mathcal{X}}{k+1}=\mathbb{P}(\boldsymbol{\mathcal{M}}{i,k+1},\boldsymbol{\Psi}{\boldsymbol{\mathcal{X}},k}) Xk+1=P(Mi,k+1,ΨX,k)、 E k + 1 = S ( Ψ E , k ) \boldsymbol{\mathcal{E}}{k+1}=\mathbb{S}(\boldsymbol{\Psi}{\boldsymbol{\mathcal{E}},k}) Ek+1=S(ΨE,k) 以及 N k + 1 = U ( Ψ N , k ) \boldsymbol{\mathcal{N}}{k+1}=\mathbb{U}(\boldsymbol{\Psi}_{\boldsymbol{\mathcal{N}},k}) Nk+1=U(ΨN,k)。
注:
- 这里的 P \mathbb{P} P、 S \mathbb{S} S、 U \mathbb{U} U 是算子形式的更新模块,不是新的独立物理模型;它们把前面 ADMM 推导出的闭式更新封装成可放入网络前向传播的层。
- P \mathbb{P} P 表示 X \boldsymbol{\mathcal{X}} X 更新模块,对应式 (5)、(6);严格来说它依赖 i = 1 , 2 , 3 i=1,2,3 i=1,2,3 的所有 M i , k + 1 \boldsymbol{\mathcal{M}}{i,k+1} Mi,k+1,可理解为 X k + 1 = P ( { M i , k + 1 } i = 1 3 , Ψ X , k ) \boldsymbol{\mathcal{X}}{k+1}=\mathbb{P}(\{\boldsymbol{\mathcal{M}}{i,k+1}\}{i=1}^{3},\boldsymbol{\Psi}_{\boldsymbol{\mathcal{X}},k}) Xk+1=P({Mi,k+1}i=13,ΨX,k)。
- S \mathbb{S} S 表示 E \boldsymbol{\mathcal{E}} E 的稀疏收缩/阈值更新模块,对应式 (7)、(8); U \mathbb{U} U 表示噪声松弛变量 N \boldsymbol{\mathcal{N}} N 的投影更新模块,对应式 (9)、(10)。
- 后面的 V k \mathbb{V}_k Vk 和 W k \mathbb{W}_k Wk 才是由 CNN 学习得到的近端算子模块,用来替代手工指定的正则项近端映射。
对于 P k + 1 \boldsymbol{\mathcal{P}}{k+1} Pk+1 和 Q k + 1 \boldsymbol{\mathcal{Q}}{k+1} Qk+1,传统上正则化函数需要根据具体应用确定,这可能不够准确,也限制了模型泛化能力。为解决手工设计正则项的约束,本文在算法展开框架下引入 CNN 来实现近端算子,使其能够从训练数据中学习,并有效重构复杂多样的视觉特征。记第 k k k 次迭代中的 CNN 为 V k \mathbb{V}_k Vk 和 W k \mathbb{W}_k Wk,则解为
P k + 1 = V k ( X k + 1 + 1 θ k Γ k ) , (13) \boldsymbol{\mathcal{P}}_{k+1} = \mathbb{V}k \left( \boldsymbol{\mathcal{X}}{k+1} +\frac{1}{\theta_k}\boldsymbol{\Gamma}_k \right), \tag{13} Pk+1=Vk(Xk+1+θk1Γk),(13)
Q k + 1 = W k ( E k + 1 + 1 β k Φ k ) . (14) \boldsymbol{\mathcal{Q}}_{k+1} = \mathbb{W}k \left( \boldsymbol{\mathcal{E}}{k+1} +\frac{1}{\beta_k}\boldsymbol{\Phi}_k \right). \tag{14} Qk+1=Wk(Ek+1+βk1Φk).(14)
训练过程中,网络参数根据输入张量 V k \mathbb{V}k Vk 和 W k \mathbb{W}k Wk 更新,以得到最优解 P k + 1 \boldsymbol{\mathcal{P}}{k+1} Pk+1 和 Q k + 1 \boldsymbol{\mathcal{Q}}{k+1} Qk+1。
深度展开网络的最终输出为估计的背景 X \boldsymbol{\mathcal{X}} X 和前景 E \boldsymbol{\mathcal{E}} E,二者合并得到期望结果 D ^ \widehat{\boldsymbol{\mathcal{D}}} D 。
除了 V k \mathbb{V}_k Vk 和 W k \mathbb{W}_k Wk 的网络参数,参数 μ k \mu_k μk、 θ k \theta_k θk、 β k \beta_k βk、 λ k \lambda_k λk 和 δ k \delta_k δk 也是可学习的,并在训练过程中通过反向传播更新。该结构严格遵循推导出的数学模型,从而保证完整的可解释性和分析能力。由于 V k \mathbb{V}_k Vk 和 W k \mathbb{W}_k Wk 是结构无关的非线性映射,因此它们可以采用任意 CNN 架构。
注:
- 在标准 ADMM/ALM 中, μ \mu μ、 θ \theta θ、 β \beta β 通常是人为设定的惩罚参数,可以固定,也可以按启发式规则随迭代调整;它们并不一定像 X \boldsymbol{\mathcal{X}} X、 E \boldsymbol{\mathcal{E}} E、 N \boldsymbol{\mathcal{N}} N 这类优化变量一样每步由闭式公式更新。
- 本文写成 μ k \mu_k μk、 θ k \theta_k θk、 β k \beta_k βk,是因为 deep unrolling 把第 k k k 次 ADMM 迭代变成第 k k k 个网络层;这些惩罚系数变成逐层可学习参数,在训练阶段通过反向传播学到,测试时通常作为已训练好的层参数使用。
- λ k \lambda_k λk 控制稀疏前景项 E \boldsymbol{\mathcal{E}} E 的 l 1 l_1 l1 正则强度, δ k \delta_k δk 控制噪声松弛变量 N \boldsymbol{\mathcal{N}} N 的容忍阈值;它们同样被设置为逐层可学习参数。
最后,拉格朗日乘子张量根据增广拉格朗日法(augmented Lagrangian method, ALM)策略更新:
Λ k + 1 = Λ k + μ k ( P Ω ( D ) − X k + 1 − E k + 1 − N k + 1 ) , (15) \boldsymbol{\Lambda}{k+1} = \boldsymbol{\Lambda}k +\mu_k \left( \mathcal{P}{\Omega}(\boldsymbol{\mathcal{D}}) -\boldsymbol{\mathcal{X}}{k+1} -\boldsymbol{\mathcal{E}}{k+1} -\boldsymbol{\mathcal{N}}{k+1} \right), \tag{15} Λk+1=Λk+μk(PΩ(D)−Xk+1−Ek+1−Nk+1),(15)
Γ k + 1 = Γ k + θ k ( X k + 1 − P k + 1 ) , (16) \boldsymbol{\Gamma}{k+1} = \boldsymbol{\Gamma}k +\theta_k \left( \boldsymbol{\mathcal{X}}{k+1} -\boldsymbol{\mathcal{P}}{k+1} \right), \tag{16} Γk+1=Γk+θk(Xk+1−Pk+1),(16)
Φ k + 1 = Φ k + β k ( E k + 1 − Q k + 1 ) , (17) \boldsymbol{\Phi}{k+1} = \boldsymbol{\Phi}k +\beta_k \left( \boldsymbol{\mathcal{E}}{k+1} -\boldsymbol{\mathcal{Q}}{k+1} \right), \tag{17} Φk+1=Φk+βk(Ek+1−Qk+1),(17)
Y i , k + 1 = Y i , k + ρ ( X k + 1 − M i , k + 1 ) . (18) \boldsymbol{\mathcal{Y}}{i,k+1} = \boldsymbol{\mathcal{Y}}{i,k} +\rho \left( \boldsymbol{\mathcal{X}}{k+1} -\boldsymbol{\mathcal{M}}{i,k+1} \right). \tag{18} Yi,k+1=Yi,k+ρ(Xk+1−Mi,k+1).(18)
在介绍完所提网络架构后,本文将损失函数定义为基线损失 L r e c o n \mathcal{L}{\mathrm{recon}} Lrecon 与物理信息损失 L p h y \mathcal{L}{\mathrm{phy}} Lphy 的组合,其中 ω \omega ω 控制二者贡献:
L t o t a l = ω L r e c o n + ( 1 − ω ) L p h y . \mathcal{L}{\mathrm{total}} = \omega\mathcal{L}{\mathrm{recon}} +(1-\omega)\mathcal{L}_{\mathrm{phy}}. Ltotal=ωLrecon+(1−ω)Lphy.
L r e c o n \mathcal{L}{\mathrm{recon}} Lrecon 是估计无线电地图与真实值之间的 l 1 l_1 l1 范数。物理信息损失 L p h y \mathcal{L}{\mathrm{phy}} Lphy 8 定义为基于无线电传播模型 LDPL 得到的插值无线电地图与估计无线电地图之间的均方误差(MSE)。
III. 实验结果
本文使用 BART-Lab Radiomap Dataset 1 ^1 1,该数据集包含跨 5 个频带(1750 MHz 至 5750 MHz)的 2000 幅粗分辨率无线电地图。为简化处理,本文选取 { 2750 , 3750 , 4750 } \{2750,3750,4750\} {2750,3750,4750} MHz 处的地图,并在基站附近随机裁剪大小为 256 × 256 256\times256 256×256 的块,得到 2000 个大小为 256 × 256 × 3 256\times256\times3 256×256×3 的张量用于训练和测试。
为评估所提出的 DULRTC-RME,本文将其与代表性张量补全方法 HaLRTC 10、基于 RBF 的插值方法 4、基于深度学习的 RadioUNet 5 以及先进的展开网络 FISTA-Net 12 进行比较。其中,HaLRTC 是用于张量补全的经典算法,广泛用于多维数据缺失值补全任务。
RBF 使用基于距离的径向函数估计未知 PSD 值。RadioUNet 是一种高效深度学习方法,用于估计发射机和接收机之间的传播路径损耗;FISTA-Net 则把 FISTA 与算法展开相结合,用于从压缩测量中重构视频帧,以服务于快照压缩成像。本文用 1200 组数据训练深度学习算法,剩余 800 组用于测试。训练采用 Adam 优化器,batch size 为 1,训练 25 个 epoch,并设置 K = 10 K=10 K=10 个展开迭代。
1 ^1 1 https://github.com/BRATLab-UCD/Radiomap-Data

图 2. 不同方法的可视化结果;红色方框中的细节子图被放大展示。
对于定量评估,本文将观测比例固定为 10%,并使用 PSNR 和 RMSE 评估重构保真度。表 I 的前两列显示,DULRTC-RME 优于基线方法,具有更高 PSNR 和更低 RMSE,说明其结果与真实值更接近。这一提升得益于同时利用无线电地图在空间域和频率域中的低秩性质,以及用于误差补偿的校正式正则化项。
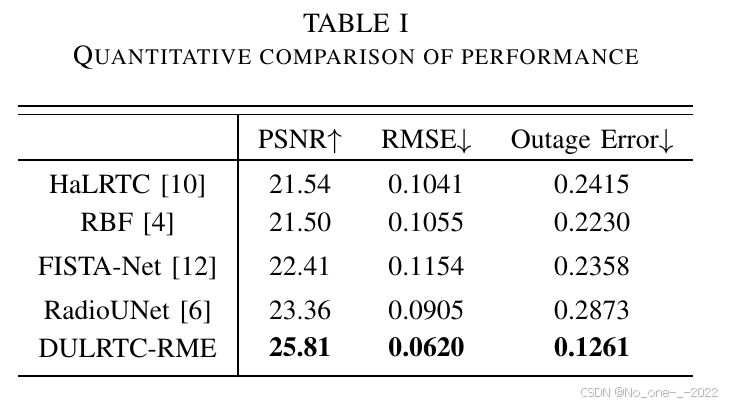
表 I. 性能定量比较。
在 outage detection 等应用中,通常只需要粗略的 PSD 分布,而不一定需要精确无线电地图。为评估 DULRTC-RME 在此类场景中的性能,本文参考 8 进行了 outage fault diagnosis。当某一位置的 PSD 值低于设定阈值时,将其定义为发生 outage。通过把无线电地图转换为包含正常区域和 outage 区域的二值 outage map,本文使用一个示例阈值评估重构 outage map 与真实 outage map 之间的误差。如表 I 第三列所示,DULRTC-RME 算法取得了更准确的结果,证明其对 outage detection 有效。
本文还给出了重构无线电地图的可视化结果。图 2 展示了一个测试图像上的比较。基于插值的 RBF 和基于张量补全的 HaLRTC 未能捕捉 PSD 值中的潜在结构,导致重构结果同质化且模糊。与 FISTA-Net 相比,DULRTC-RME 通过严格施加低秩约束,并使用学习到的正则化项进行误差补偿,生成了更准确的无线电地图。
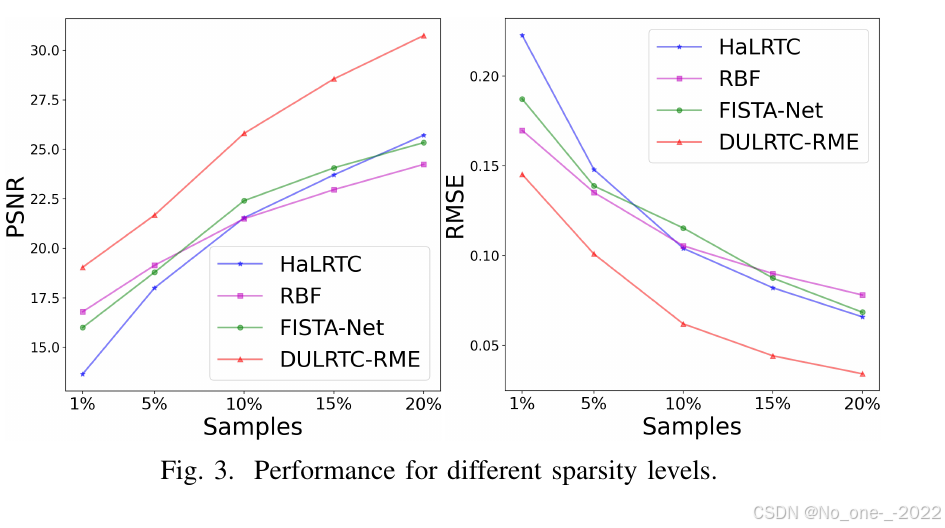
图 3. 不同稀疏程度下的性能。
图 3 比较了所有方法在不同测量稀疏程度下的表现。结果显示,DULRTC-RME 在 PSNR 和 RMSE 指标上始终优于三种基线方法。值得注意的是,即使在观测极少的稀疏水平(1%)下,DULRTC-RME 仍然取得了相对较强的重构性能。
IV. 结论
通过展开低秩张量补全算法,本文开发了 DULRTC-RME,用于从稀疏观测中估计无线电地图,并结合了基于模型和基于学习的方法。具体而言,无线电传输中的空间大尺度衰落和频间相关性被刻画为低秩性质。从稀疏观测进行无线电地图估计的问题,被表述为一个带可学习正则化项的低秩张量补全优化问题,以捕捉结构信息。为降低计算复杂度并自适应学习结构化无线电信息,ADMM 迭代优化过程通过把子问题展开为 DNN 模块来完成。在所提出的 DULRTC-RME 中,闭式解和可学习正则项通过训练网络进行迭代更新。实验结果表明,DULRTC-RME 在重构精度上优于现有算法。
参考文献
1 D. Romero and S.-J. Kim, "Radio Map Estimation: A data-driven approach to spectrum cartography," IEEE Signal Processing Magazine, vol. 39, no. 6, pp. 53-72, November 2022.
2 S. Zhang, B. Choi, F. Ouyang and Z. Ding, "Physics-Inspired Machine Learning for Radiomap Estimation: Integration of Radio Propagation Models and Artificial Intelligence," IEEE Communications Magazine, vol. 62, no. 8, pp. 155-161, August 2024.
3 M. Lee and D. Han, "Voronoi Tessellation Based Interpolation Method for Wi-Fi Radio Map Construction," IEEE Communications Letters, vol. 16, no. 3, pp. 404-407, March 2012.
4 D. Lazzaro and L. B. Montefusco, "Radial basis functions for the multivariate interpolation of large scattered data sets," Journal of Computational and Applied Mathematics, vol. 140, no. 1-2, pp. 521-536, 2002.
5 Y. Teganya and D. Romero, "Deep completion autoencoders for radio map estimation," IEEE Transactions on Wireless Communications, vol. 21, no. 3, pp. 1710-1724, June 2021.
6 R. Levie, Ç. Yapar, G. Kutyniok and G. Caire, "RadioUNet: Fast Radio Map Estimation With Convolutional Neural Networks," IEEE Transactions on Wireless Communications, vol. 20, no. 6, pp. 4001-4015, June 2021.
7 F. Li, Y. Deng, B. Zhou and Q. Wu, "Partial Convolutional Based-Radio Map Reconstruction for Urban Environments with Inaccessible Areas," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 2024, pp. 7585-7589.
8 S. Zhang, T. Yu and B. Choi, "Radiomap Inpainting for Restricted Areas based on Propagation Priority and Depth Map," IEEE Transactions on Wireless Communications, 2024.
9 V. Monga, Y. Li and Y. C. Eldar, "Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing," IEEE Signal Processing Magazine, vol. 38, no. 2, pp. 18-44, 2021.
10 J. Liu, P. Musialski, P. Wonka and J. Ye, "Tensor Completion for Estimating Missing Values in Visual Data," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 1, pp. 208-220, January 2013.
11 C. Lee and E. Y. Lam, "Computationally efficient truncated nuclear norm minimization for high dynamic range imaging," IEEE Transactions on Image Processing, vol. 25, no. 9, pp. 4145-4157, 2016.
12 X. Liu, Q. Huang, X. Han, B. Wu, L. Kong, A. Waild and X. Wang, "Real-Time Decoding of Snapshot Compressive Imaging Using Tensor FISTA-Net," IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 10, pp. 13312-13326, October 2024.
13 T. T. N. Mai, E. Y. Lam and C. Lee, "Deep Unrolled Low-Rank Tensor Completion for High Dynamic Range Imaging," IEEE Transactions on Image Processing, vol. 31, pp. 5774-5787, 2022.
14 S. Boyd, N. Parikh, E. Chu, B. Peleato and J. Eckstein, "Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers," Now Foundations and Trends, 2011.