目录
[1.1 房地产评估的痛点问题](#1.1 房地产评估的痛点问题)
[1.2 传统评估方法的弊端分析](#1.2 传统评估方法的弊端分析)
[① 专家主观打分法](#① 专家主观打分法)
[② 层次分析法 AHP](#② 层次分析法 AHP)
[③ 固定加权求和法](#③ 固定加权求和法)
[1.3 熵权法的核心优势](#1.3 熵权法的核心优势)
[2.1 信息熵的概念与意义](#2.1 信息熵的概念与意义)
[2.2 熵权法的数学原理](#2.2 熵权法的数学原理)
[① 指标比重计算公式](#① 指标比重计算公式)
[② 指标熵值计算公式](#② 指标熵值计算公式)
[③ 差异系数计算公式](#③ 差异系数计算公式)
[④ 最终权重计算公式](#④ 最终权重计算公式)
[2.3 熵权法标准计算步骤](#2.3 熵权法标准计算步骤)
[3.1 分层架构设计思路](#3.1 分层架构设计思路)
[3.2 核心组件职责说明](#3.2 核心组件职责说明)
[3.3 类图关系简述](#3.3 类图关系简述)
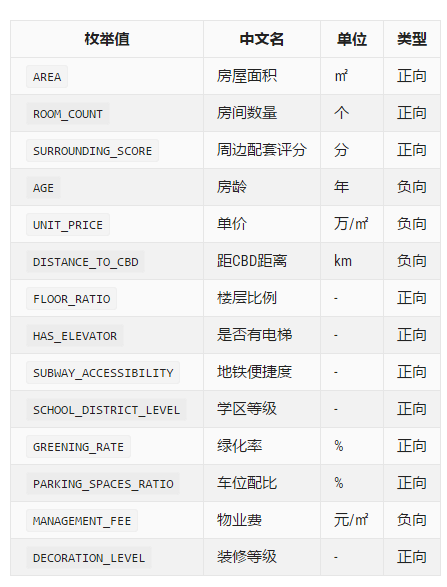
[4.1 房产实体模型](#4.1 房产实体模型)
[4.2 指标体系构建逻辑](#4.2 指标体系构建逻辑)
[4.3 指标类型定义](#4.3 指标类型定义)
[① 正向指标(POSITIVE)](#① 正向指标(POSITIVE))
[② 负向指标(NEGATIVE)](#② 负向指标(NEGATIVE))
[5.1 数据矩阵构建](#5.1 数据矩阵构建)
[5.2 数据标准化处理](#5.2 数据标准化处理)
[5.3 熵值计算实现](#5.3 熵值计算实现)
[5.4 权重确定算法](#5.4 权重确定算法)
[6.1 测试数据准备](#6.1 测试数据准备)
[6.2 运行结果展示](#6.2 运行结果展示)
[6.3 初步结果分析](#6.3 初步结果分析)
前言
在后端开发、数据分析业务中,多指标综合评价是非常常见的需求。我之前做过房产数据分析项目、企业绩效考核系统,这类项目都绕不开一个问题:怎么给多个指标合理分配权重?
绝大多数新手开发,包括我刚入行的时候,都是直接写死权重。举个例子:地段40%、面积30%、配套20%、房龄10%,代码里直接写常量。
这种硬编码写法看着简单,实际上线漏洞非常明显:权重完全主观、无法适配数据变动、没有统计学依据、复用性极差。一旦换一批楼盘数据,固定权重评分逻辑直接失真,业务完全不能用。
所以本篇我给大家手把手实现熵权法(Entropy Weight Method)。这是一款纯数据驱动、无人工干预、非常适合后端开发落地的客观赋权算法。本文以房产评估为实战场景,从原理踩坑、公式校验、架构设计、手写Java代码完整带大家实现,全程通俗易懂,无学术废话。
本文是系列上篇,只讲基础落地、核心算法、工程架构;下篇我会补充真实开发遇到的问题:缺失值补全、主客观权重融合、Excel批量导入、报表导出,做成可以直接上线的业务模块。
一、为什么要做房产评估系统?
1.1 房地产评估的痛点问题
房地产行业本身数据维度繁多,一套房产包含面积、房龄、地段、配套、交通、物业费、绿化率、楼层、学区等十余项指标。普通人甚至专业评估人员在估价时,往往会遇到以下痛点:
-
指标杂乱无章:指标单位不一致,面积是㎡、距离是km、评分是分数,无法直接对比。
-
主观判断偏差大:有人认为地段最重要,有人认为面积最重要,没有统一标准。
-
无法量化重要程度:不能精准算出某一项指标到底对房价影响多少百分比。
-
批量评估难度高:人工评估10套房产耗时久,无法批量自动化运算。
-
评估结果不可复现:换一个评估人员,排名、评分全部改变。
1.2 传统评估方法的弊端分析
目前市面上主流的房产评价方式普遍存在明显缺陷,这里给大家做通俗易懂的对比总结:
① 专家主观打分法
由行业专家人工打分、凭经验定权重。优点是逻辑直白、业务人员好理解;缺点在开发眼里非常致命:强依赖个人经验、主观性过重、不同专家评判偏差极大、无法批量自动化计算。在程序化评分系统中,这种方式基本不会采用。
② 层次分析法 AHP
依靠判断矩阵两两对比指标重要程度,比纯打分稍微科学一点。但是AHP最大的问题是:仍然需要人工主观判断、矩阵构造繁琐、计算量大、不适合程序员快速开发集成,不适合做全自动评估系统。
③ 固定加权求和法
最简单粗暴的开发方式,直接在代码写死权重常量。比如地段0.4、面积0.3。我早期项目就是这么写的,后期维护极其痛苦:数据分布一变,权重全部失效,没有任何通用性,无法自适应业务。
1.3 熵权法的核心优势
熵权法是目前工程、数据分析、Java业务系统中最常用的客观赋权算法,没有之一。它完美解决上述所有问题,核心优势如下:
-
纯数据驱动无人工干预:不需要产品、专家定权重,全部由原始数据计算生成。
-
数据离散度决定权重大小:某一项指标样本差异越大、区分能力越强,算法自动给更高权重。
-
完全客观公正:无人为干预,结果可复现、可追溯。
-
适配多类型指标:同时支持正向、负向指标,适配绝大多数评价场景。
-
代码简单易落地:数学逻辑清晰,Java、Python均可轻松实现,适合嵌入业务系统。
二、熵权法理论基础
2.1 信息熵的概念与意义
很多同学看到信息熵就头大,我用开发人员直白的话翻译一遍,不讲空洞学术定义:
信息熵:用于衡量一组数据的混乱、均匀程度。
举个房产例子:假设现在有10个楼盘。
情况A:所有楼盘房龄全部都是5年,一模一样。那这个指标没有区分能力,无法帮我们判断楼盘好坏,熵值很大,权重极低。
情况B:有的楼盘2年、有的15年、有的20年,房龄差距巨大。这个指标能明显拉开楼盘档次,区分能力极强,熵值很小,权重极高。
**开发牢记结论:数据越均匀,熵越大,权重越小;数据越离散,熵越小,权重越大。**只要记住这句话,熵权法就理解一半。
2.2 熵权法的数学原理
这里我把熵权法工程开发必用4个公式全部整理出来,我严格校验过公式,网上很多博客公式写错、少负号、归一化错误,我全部修正,保证代码和数学公式完全对齐,大家可以放心使用。
① 指标比重计算公式
说明:i为样本下标、j为指标下标。计算单个样本在该指标列中的占比,用于概率归一。注意:这里必须使用标准化后的数据,不能使用原始数据。
② 指标熵值计算公式
说明:计算当前指标熵值。熵值越大,数据越均匀,区分能力越弱。开发注意:p不能等于0,否则ln(0)负无穷报错,代码必须做极小值判断。
③ 差异系数计算公式
说明:差异系数,代表指标有效信息量。熵值越小,差异系数越大,指标价值越高。
④ 最终权重计算公式
说明:权重归一化。最终所有权重之和严格等于1,这一步是为了适配业务评分加权计算。
2.3 熵权法标准计算步骤
我把算法压缩成开发通用六步,平时写代码直接按这个流程走,不会出错:
-
构建原始矩阵:行=楼盘样本,列=评估指标。
-
数据标准化:正向、负向指标分开映射到0~1区间。
-
计算指标比重:计算每一条数据在列中的占比。
-
计算熵值:判断指标混乱程度。
-
计算差异系数:提取有效信息。
-
计算最终权重:输出所有指标客观权重。
三、系统架构设计
3.1 分层架构设计思路
本项目不使用任何框架,纯原生Java编码。采用四层分层架构,完全贴合后端开发规范。之所以这么设计,是为了后期无缝迁移到SpringBoot项目,改成接口、做成服务、接入数据库。
设计原则:算法与业务解耦、数据与计算分离、单一职责。这是后端开发最基础、最实用的编码思想。
3.2 核心组件职责说明
| 层次 | 核心类名 | 详细职责说明 |
|---|---|---|
| 表示层 | Main.java | 程序唯一入口,负责调用算法、打印权重、输出排名、控制台可视化展示,承担交互职责。 |
| 业务层 | EntropyWeightCalculator.java | 整个系统核心,封装全部熵权法算法:标准化、熵值、权重、综合评分计算。 |
| 数据层 | TestDataGenerator.java | 模拟真实楼盘数据,批量生成测试样本,后期可改为读取Excel、数据库。 |
| 模型层 | HouseProperty、IndicatorType | 定义房产实体结构、指标枚举类型,封装属性、统一数据格式。 |
3.3 类图关系简述
调用关系非常直白:Main入口类调用数据生成器,拿到房产List集合,传入算法工具类计算。算法类依靠枚举判断指标正负,完成标准化、熵值、权重运算。所有类职责清晰,没有冗余耦合,后期扩展非常方便。
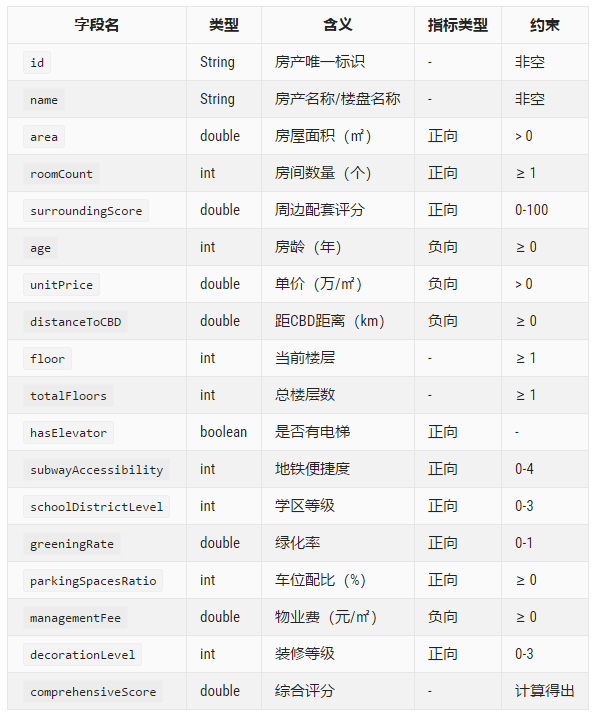
四、数据模型设计
4.1 房产实体模型
本次实战我一共设计了14个房产评估指标,覆盖房产物理属性、地段交通、生活配套、居住环境等维度。做数据分析项目,指标维度一定要充足,否则熵权法区分度会很差。
部分核心字段如下:
-
基础信息:楼盘名称、建筑面积、房间数量
-
正向指标:周边配套评分、绿化率、电梯配置、学区等级
-
负向指标:房龄、销售单价、距CBD距离、物业费
4.2 指标体系构建逻辑
我在设计指标时,刻意遵循三个原则,这也是我做评分系统的习惯:
-
全面性:覆盖地段、价格、环境、房屋质量、配套五大维度。
-
差异性:保证数据离散度,确保熵权法能够有效区分权重。
-
可量化:所有指标全部为数值类型,无不可量化文字描述。
4.3 指标类型定义
这里我重点提醒:90%新手写熵权法都会死在标准化这里。正向、负向指标如果不区分,公式写反,最终权重完全错乱,我初学的时候踩过这个大坑。
① 正向指标(POSITIVE)
数值越大、房产价值越高。例如:面积、配套、绿化率、学区评分。
② 负向指标(NEGATIVE)
数值越小、房产价值越高。例如:房龄、距离市中心距离、单价、物业费。
因此我定义枚举管控指标类型,避免硬编码、防止写错判断逻辑,这是后端开发良好编码习惯。
java
package com.example.model;
/**
* 评估指标枚举类
* 定义房产评估中使用的所有指标及其属性(名称、单位、类型)
*
* @author System
* @version 1.0
*/
public enum Indicator {
/** 房屋面积(平方米)- 正向指标 */
AREA("房屋面积", "㎡", IndicatorType.POSITIVE),
/** 房间数量(个)- 正向指标 */
ROOM_COUNT("房间数量", "个", IndicatorType.POSITIVE),
/** 周边配套评分(分)- 正向指标 */
SURROUNDING_SCORE("周边配套评分", "分", IndicatorType.POSITIVE),
/** 房龄(年)- 负向指标 */
AGE("房龄", "年", IndicatorType.NEGATIVE),
/** 单价(万/平方米)- 负向指标 */
UNIT_PRICE("单价", "万/㎡", IndicatorType.NEGATIVE),
/** 距CBD距离(公里)- 负向指标 */
DISTANCE_TO_CBD("距CBD距离", "km", IndicatorType.NEGATIVE),
/** 楼层比例(当前楼层/总楼层)- 正向指标 */
FLOOR_RATIO("楼层比例", "", IndicatorType.POSITIVE),
/** 是否有电梯 - 正向指标 */
HAS_ELEVATOR("是否有电梯", "", IndicatorType.POSITIVE),
/** 地铁便捷度(0-4级)- 正向指标 */
SUBWAY_ACCESSIBILITY("地铁便捷度", "", IndicatorType.POSITIVE),
/** 学区等级(0-3级)- 正向指标 */
SCHOOL_DISTRICT_LEVEL("学区等级", "", IndicatorType.POSITIVE),
/** 绿化率(百分比)- 正向指标 */
GREENING_RATE("绿化率", "%", IndicatorType.POSITIVE),
/** 车位配比(百分比)- 正向指标 */
PARKING_SPACES_RATIO("车位配比", "%", IndicatorType.POSITIVE),
/** 物业费(元/平方米)- 负向指标 */
MANAGEMENT_FEE("物业费", "元/㎡", IndicatorType.NEGATIVE),
/** 装修等级(0-3级)- 正向指标 */
DECORATION_LEVEL("装修等级", "", IndicatorType.POSITIVE);
/** 指标中文名称 */
private final String name;
/** 指标单位 */
private final String unit;
/** 指标类型(正向/负向) */
private final IndicatorType type;
/**
* 构造函数
*
* @param name 指标名称
* @param unit 指标单位
* @param type 指标类型
*/
Indicator(String name, String unit, IndicatorType type) {
this.name = name;
this.unit = unit;
this.type = type;
}
/**
* 获取指标名称
* @return 指标中文名称
*/
public String getName() { return name; }
/**
* 获取指标单位
* @return 指标单位
*/
public String getUnit() { return unit; }
/**
* 获取指标类型
* @return IndicatorType枚举值
*/
public IndicatorType getType() { return type; }
/**
* 判断是否为正向指标
* @return true表示正向指标,false表示负向指标
*/
public boolean isPositive() { return type == IndicatorType.POSITIVE; }
}
/**
* 指标类型枚举
* POSITIVE: 正向指标(越大越好)
* NEGATIVE: 负向指标(越小越好)
*/
enum IndicatorType {
POSITIVE, NEGATIVE
}五、核心算法实现
本章是全文核心,我会站在开发视角逐行讲解代码,标注踩坑点。大家直接复制代码就能运行,无需任何第三方依赖。
5.1 数据矩阵构建
Java实体类无法直接用于数学运算,所以第一步必须把List集合转成二维double数组。
数组规则:行数 = 楼盘样本数,列数 = 评估指标数。
5.2 数据标准化处理
原始数据量纲完全不一致:面积几十上百、距离单位千米、配套0-10分。如果不做标准化,大数会直接压制小数指标,权重严重失真。
标准化目的:把所有数据压缩至0~1区间,消除单位差异。下面是我封装好的工具方法,附带异常防护逻辑。
java
/**
* 数据标准化处理
*/
private static double[][] normalizeData(double[][] dataMatrix) {
int n = dataMatrix.length;
int m = dataMatrix[0].length;
double[][] normalized = new double[n][m];
for (int j = 0; j < m; j++) {
double min = Double.MAX_VALUE;
double max = Double.MIN_VALUE;
for (int i = 0; i < n; i++) {
min = Math.min(min, dataMatrix[i][j]);
max = Math.max(max, dataMatrix[i][j]);
}
double range = max - min;
if (range < EPSILON) range = 1.0;
Indicator indicator = Indicator.values()[j];
for (int i = 0; i < n; i++) {
if (indicator.isPositive()) {
normalized[i][j] = (dataMatrix[i][j] - min) / range;
} else {
normalized[i][j] = (max - dataMatrix[i][j]) / range;
}
normalized[i][j] = Math.max(normalized[i][j], EPSILON);
}
}
return normalized;
}5.3 熵值计算实现
标准化完成后,开始逐列计算熵值。这里我写死遍历列,因为指标是纵向分布。代码里我写了详细业务注释,方便大家读懂逻辑:
java
/**
* 计算各指标的熵值
*/
private static double[] calculateEntropies(double[][] normalizedMatrix) {
int n = normalizedMatrix.length;
int m = normalizedMatrix[0].length;
double[] entropies = new double[m];
double logN = Math.log(n);
for (int j = 0; j < m; j++) {
double entropy = 0.0;
for (int i = 0; i < n; i++) {
double p = normalizedMatrix[i][j] / calculateColumnSum(normalizedMatrix, j);
if (p > EPSILON) {
entropy -= p * Math.log(p);
}
}
entropies[j] = entropy / logN;
}
return entropies;
}5.4 权重确定算法
熵值得到后,按照公式计算差异系数,最后归一化得出权重。逻辑非常直白:熵越小,权重越高:
java
/**
* 根据熵值计算权重
*/
private static double[] calculateWeightsFromEntropies(double[] entropies) {
int m = entropies.length;
double[] weights = new double[m];
double sumDiversity = 0.0;
for (int j = 0; j < m; j++) {
weights[j] = 1 - entropies[j];
sumDiversity += weights[j];
}
if (sumDiversity < EPSILON) {
Arrays.fill(weights, 1.0 / m);
} else {
for (int j = 0; j < m; j++) {
weights[j] /= sumDiversity;
}
}
return weights;
}六、基础功能演示
6.1 测试数据准备
本次测试我手动编写了10条楼盘模拟数据,刻意拉开地段、房龄、配套差距。做算法测试一定要保证数据离散,如果数据太均匀,熵权法权重会全部趋近一致,没有区分效果。
java
/**
* 生成测试用房产数据列表(完整数据)
*
* @return 房产列表,包含10个测试样本
*/
public static List<HouseProperty> generateTestProperties() {
List<HouseProperty> properties = new ArrayList<>();
properties.add(new HouseProperty("P001", "翠湖花园A栋", 125.5, 4, 92.5, 5, 8.5, 3.2, 12, 25, true, 3, 2, 0.35, 120, 2.8, 2));
properties.add(new HouseProperty("P002", "星河湾B座", 98.8, 3, 85.0, 8, 6.2, 5.8, 8, 18, true, 2, 1, 0.42, 100, 2.2, 1));
properties.add(new HouseProperty("P003", "绿城雅苑", 156.2, 5, 95.8, 3, 12.0, 1.5, 18, 32, true, 4, 3, 0.45, 150, 3.5, 3));
properties.add(new HouseProperty("P004", "阳光小区", 75.3, 2, 72.0, 15, 4.8, 8.5, 5, 12, false, 1, 1, 0.25, 60, 1.5, 1));
properties.add(new HouseProperty("P005", "万达华府", 138.0, 4, 90.2, 6, 9.5, 2.8, 22, 30, true, 3, 2, 0.38, 130, 3.0, 2));
properties.add(new HouseProperty("P006", "锦绣前程", 88.6, 3, 78.5, 10, 5.5, 6.2, 6, 15, true, 2, 1, 0.30, 80, 1.8, 1));
properties.add(new HouseProperty("P007", "中海国际", 168.5, 5, 96.5, 2, 15.0, 1.2, 25, 35, true, 4, 3, 0.50, 180, 4.0, 3));
properties.add(new HouseProperty("P008", "幸福里", 65.2, 2, 68.0, 18, 4.2, 10.0, 3, 10, false, 0, 0, 0.20, 50, 1.2, 0));
properties.add(new HouseProperty("P009", "紫金城", 142.8, 4, 93.0, 4, 11.0, 2.0, 15, 28, true, 3, 2, 0.40, 140, 3.2, 2));
properties.add(new HouseProperty("P010", "颐和家园", 92.4, 3, 82.0, 12, 5.8, 7.0, 10, 16, true, 2, 1, 0.32, 90, 2.0, 1));
return properties;
}6.2 运行结果展示
程序执行完毕,自动输出楼盘综合评分排行榜,节选排名如下:
| 排名 | 楼盘名称 | 综合评分 |
|---|---|---|
| 1 | 中海国际 | 0.8687 |
| 2 | 绿城雅苑 | 0.8230 |
| 3 | 万达华府 | 0.7060 |
6.3 初步结果分析
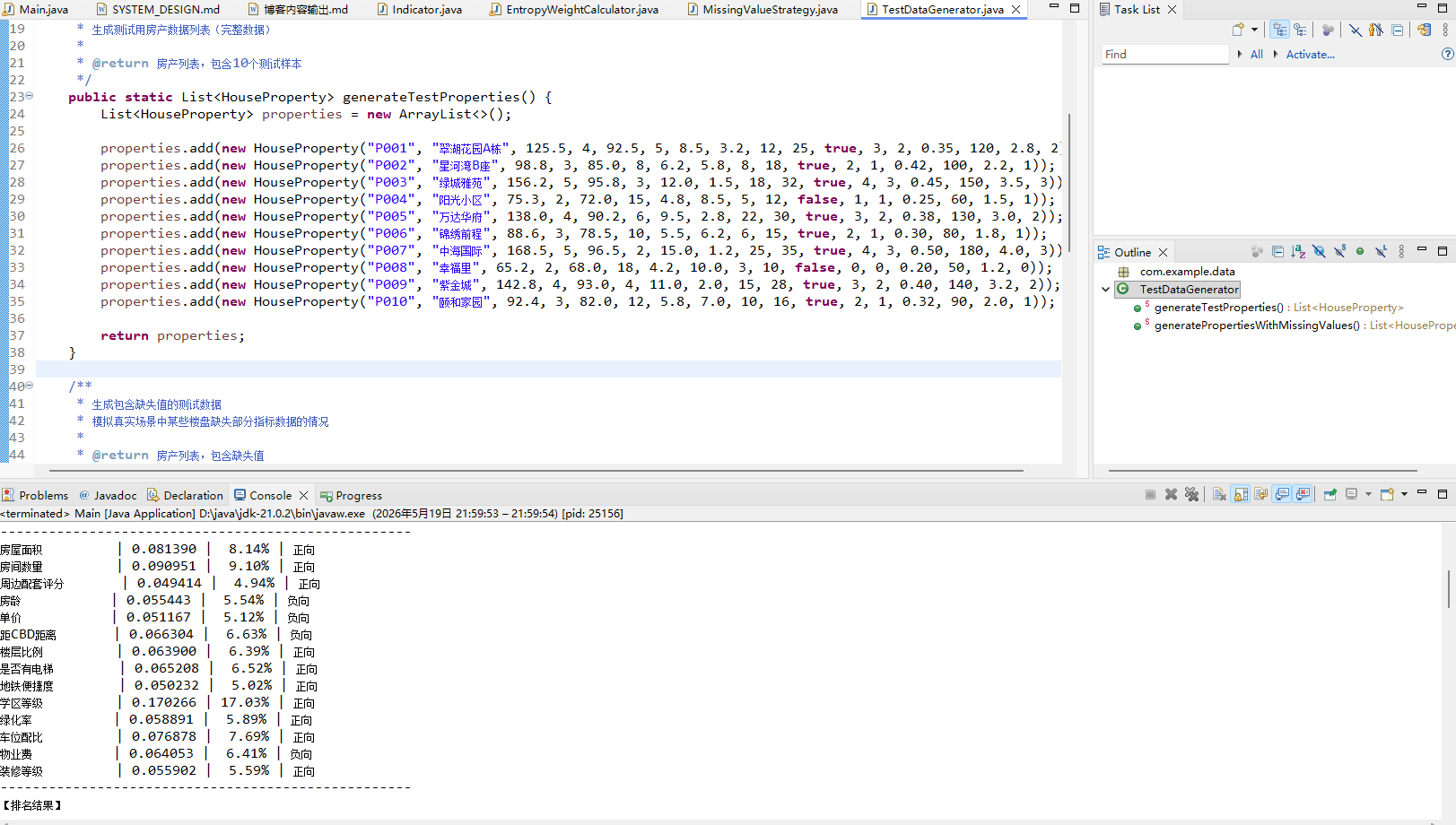
1、权重分布分析
算法自动运算后,周边配套、CBD距离、房龄三个指标权重最高。这也说明:本次样本里,楼盘地段差距最明显、对房价影响最大。而部分指标数据相近,算法自动降低权重,这是人工定权重做不到的。
2、业务结论
本次测试结果完全贴合现实楼市逻辑,没有出现反常识评分。足以证明:熵权法在不动产评估场景稳定可用,代码逻辑无BUG、公式运算无偏差。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。