机器学习20
- ImageNet介绍
-
- [一、ImageNet 核心定位与起源](#一、ImageNet 核心定位与起源)
-
- [1. 核心定义](#1. 核心定义)
- [2. 起源背景](#2. 起源背景)
- [二、ImageNet 核心特征(数据集亮点)](#二、ImageNet 核心特征(数据集亮点))
-
- [1. 规模与类别](#1. 规模与类别)
- [2. 标注质量与结构](#2. 标注质量与结构)
- [3. 数据来源与多样性](#3. 数据来源与多样性)
- [三、ImageNet 的核心历史意义(改变AI发展轨迹)](#三、ImageNet 的核心历史意义(改变AI发展轨迹))
-
- [1. 打破"数据瓶颈",支撑深层CNN训练](#1. 打破“数据瓶颈”,支撑深层CNN训练)
- [2. 2012年:引爆深度学习革命](#2. 2012年:引爆深度学习革命)
- [3. 成为技术迭代的"竞技场"(2010-2017)](#3. 成为技术迭代的“竞技场”(2010-2017))
- [4. 建立"统一评估标准",加速技术积累](#4. 建立“统一评估标准”,加速技术积累)
- [四、ImageNet 的现实影响(从实验室到生活)](#四、ImageNet 的现实影响(从实验室到生活))
- 五、争议与后续发展
-
- [1. 争议点](#1. 争议点)
- [2. 后续发展](#2. 后续发展)
- 总结
- [RNN(循环神经网络) 介绍](#RNN(循环神经网络) 介绍)
-
- 什么叫序列数据?
- [RNN 最核心特点:**拥有记忆**](#RNN 最核心特点:拥有记忆)
- [RNN 结构(最容易理解的版本)](#RNN 结构(最容易理解的版本))
-
- [1. 简化结构](#1. 简化结构)
- [2. 展开后长这样(时间展开)](#2. 展开后长这样(时间展开))
- RNN的公式与两种类型
- RNN结构与梯度消失
- [RNN 能做什么?(应用场景)](#RNN 能做什么?(应用场景))
-
- [1. 文字相关](#1. 文字相关)
- [2. 时序预测](#2. 时序预测)
- [3. 语音相关](#3. 语音相关)
- [4. 视频](#4. 视频)
- [RNN 的致命问题(必须知道)](#RNN 的致命问题(必须知道))
-
- [**梯度消失 / 梯度爆炸**](#梯度消失 / 梯度爆炸)
- [为了解决 RNN 缺点,诞生了两个升级版](#为了解决 RNN 缺点,诞生了两个升级版)
-
- [1. LSTM(长短期记忆网络)](#1. LSTM(长短期记忆网络))
-
- LSTM的基本结构和原理
- LSTM中的门控机制
- LSTM的工作机制
- LSTM的应用示例
- [LSTM的变体:Peephole LSTM 与FC LSTM](#LSTM的变体:Peephole LSTM 与FC LSTM)
- LSTM的应用效果与优势
- [2. GRU(门控循环单元)](#2. GRU(门控循环单元))
- 双向RNN
- [RNN vs CNN 区别](#RNN vs CNN 区别)
- [最简单总结(4 句就够)](#最简单总结(4 句就够))
ImageNet介绍
ImageNet 是计算机视觉领域的"奠基性数据集",由斯坦福大学李飞飞教授团队发起构建,是推动深度学习在视觉领域爆发的核心"燃料"。它不仅是一个大规模图像库,更重新定义了 AI 视觉技术的发展路径,直接催生了 AlexNet、ResNet 等经典模型,开启了现代深度学习时代。
一、ImageNet 核心定位与起源
1. 核心定义
ImageNet 是一个大规模、高质量、层级化的图像分类数据集,核心目标是为计算机视觉模型提供"视觉教科书",让机器通过学习海量带标注图像,掌握像人类一样的物体识别能力。
2. 起源背景
- 提出时间:2006年李飞飞教授提出构想,2007年正式启动项目,2009年在CVPR会议首次发布。
- 核心痛点:2000年代末,计算机视觉陷入"数据荒漠"------传统数据集(如MNIST仅6万张手写数字、CIFAR-10仅6万张小图)规模小、类别少,无法支撑深层模型训练,导致技术难以落地。
- 灵感来源:模仿人类通过"看数百万样本"学习识别物体的逻辑,参考WordNet(语义网络)构建层级分类体系,目标打造覆盖万级类别、千万级图像的"视觉百科全书"。
二、ImageNet 核心特征(数据集亮点)
1. 规模与类别
- 总规模:包含超过1400万张手工标注图像,覆盖2万+类别,每个类别平均含数百至数千张图像(部分类别超1万张)。
- 核心子集(ILSVRC):最常用的是"ImageNet大规模视觉识别挑战赛"子集,包含135万张图像(120万训练图+15万验证/测试图),聚焦1000个常见物体类别(如猫、狗、汽车、水果等),成为图像分类的"标准测试基准"。
- 存储需求:完整数据集占用150-200GB硬盘空间,ILSVRC子集体积更小,适配多数研究与开发场景。
2. 标注质量与结构
- 标注方式:通过亚马逊Mechanical Turk众包平台,由167个国家的49000名工作者耗时3年完成标注,每张图像至少经过3次人工验证,准确率超95%。
- 标注类型 :
- 图像级标注:明确图像中包含的物体类别(如"金毛寻回犬""咖啡杯");
- 对象级标注:部分图像提供物体边界框(用于目标检测任务),标注物体在图像中的具体位置。
- 层级结构:基于WordNet构建树状语义体系(如"动物→哺乳动物→犬科→金毛寻回犬"),符合人类认知逻辑,帮助模型分层学习特征。
3. 数据来源与多样性
- 图像主要通过网络爬虫收集,涵盖真实世界的自然场景(如街景、家居、户外),避免了实验室数据的单一性;
- 数据多样性极强:同一类别包含不同角度、光照、背景的图像(如"猫"涵盖不同品种、姿态、环境),让模型学到更鲁棒的特征。
三、ImageNet 的核心历史意义(改变AI发展轨迹)
1. 打破"数据瓶颈",支撑深层CNN训练
传统浅层模型依赖人工设计特征(如边缘、纹理),而深层卷积神经网络(CNN)需要海量数据自动学习层级特征。ImageNet的1400万张真实图像,首次提供了足够的"训练土壤",让8层以上的深层网络(如AlexNet)得以有效训练,避免过拟合。
2. 2012年:引爆深度学习革命
- 关键事件:在ImageNet挑战赛(ILSVRC)中,多伦多大学的AlexNet模型以15.3%的Top-5错误率夺冠,远超传统算法的26.2%(错误率降低41%)。
- 革命意义 :
- 证明深度学习在视觉任务上的效果远超人工设计特征的传统方法;
- 推动GPU成为AI训练标配(AlexNet首次采用双GPU并行训练);
- 全球掀起深度学习热潮,计算机视觉从"算法为王"转向"数据驱动"范式。
3. 成为技术迭代的"竞技场"(2010-2017)
ILSVRC竞赛成为全球CV团队的"练兵场",推动模型架构快速进化:
- 2014年:GoogLeNet(Inception模块)、VGGNet(深度堆叠3×3卷积核),错误率降至6.67%;
- 2015年:微软ResNet(残差连接),错误率3.57%,首次超越人类视觉识别水平(约5%);
- 2017年:SENet等模型将错误率降至2.25%,逼近理论极限,竞赛使命完成并停止举办。
4. 建立"统一评估标准",加速技术积累
ImageNet提供了标准化的训练集、验证集和测试集,让不同团队的模型效果可直接对比,避免了"各说各话"的混乱局面。这种统一基准让技术进步可衡量、可积累,推动了CNN架构、激活函数(ReLU)、正则化(Dropout)等核心技术的快速普及。
四、ImageNet 的现实影响(从实验室到生活)
ImageNet的价值远超学术界,其训练的预训练模型成为计算机视觉的"基础组件",直接推动了众多产业应用:
- 消费电子:手机相册自动分类(人物、宠物、风景)、拍照识物、AR试妆;
- 自动驾驶:车辆、行人、交通标志的识别,依赖ImageNet预训练的特征提取器;
- 电商零售:淘宝"拍照找同款"、商品分类与质检;
- AI生成与内容创作:Stable Diffusion等生成模型的判别器常基于ImageNet微调;
- 医疗影像:病灶识别、医学图像分类的基础模型,多通过ImageNet迁移学习优化。
五、争议与后续发展
1. 争议点
- 数据偏见:部分类别图像存在地域、性别偏见(如特定职业的性别倾向);
- 版权问题:ImageNet仅提供图像标注和URL,不拥有原始图像版权,曾引发知识产权争议;
- 标注误差:少量图像存在标注错误,但整体准确率仍保持在95%以上。
2. 后续发展
- 竞赛停办后,研究焦点转向更复杂的任务(如细粒度识别、视频理解、多模态学习、自监督学习);
- ImageNet仍是"迁移学习"的核心基准:在小数据集场景(如工业缺陷检测、医疗影像),基于ImageNet预训练的模型微调,仍是最优方案之一;
- 衍生出COCO、KITTI等更复杂的数据集,但ImageNet奠定的"大规模标注数据+深层CNN"范式,仍是视觉AI的核心框架。
总结
ImageNet 不仅是一个数据集,更是现代计算机视觉的"奠基者"------它用1400万张图像,为深度学习提供了"燃料",用统一竞赛推动了技术爆发,用预训练模型支撑了产业落地。没有ImageNet,深度学习可能还要在黑暗中摸索多年,今天我们身边的AI视觉应用(从手机拍照到自动驾驶)也难以实现。它的核心启示是:对于AI而言,高质量的大规模数据,与优秀的算法同样重要。
RNN(循环神经网络) 介绍
RNN = Recurrent Neural Network(循环神经网络)
一句话总结:
RNN 是专门处理"序列数据"的神经网络,它有"记忆能力",能记住前面的信息,用来影响后面的输出。
提出时间: 1986年由Rumelhart等人提出,与BP网络同年诞生
核心特点: 专门处理序列数据(语音、文字、视频等),具有记忆功能
与传统网络区别:
卷积网络处理网格化数据(如图像)
RNN处理序列数据,前后数据存在关联性
序列数据特征: 前后元素相互影响(如语音中的上下文关系),而非独立事件
什么叫序列数据?
就是有先后顺序、有时间关系的数据:
- 文字(一句话)
- 语音(一段声音)
- 股票价格(时间序列)
- 视频帧(连续画面)
- 时序传感器数据
普通神经网络(全连接、CNN)没有记忆 ,只能处理一张图、一行数据;
RNN 能按顺序处理一串数据,并记住前面的内容。
RNN 最核心特点:拥有记忆
普通神经网络:
输入 → 计算 → 输出
前后无关
RNN:
输入1 → 输出1
输入2 → 结合输入1的记忆 → 输出2
输入3 → 结合输入1、2的记忆 → 输出3
......
它会把前一时刻的信息保存下来,传给下一时刻。
这就是"循环"的含义。
RNN 结构(最容易理解的版本)
1. 简化结构
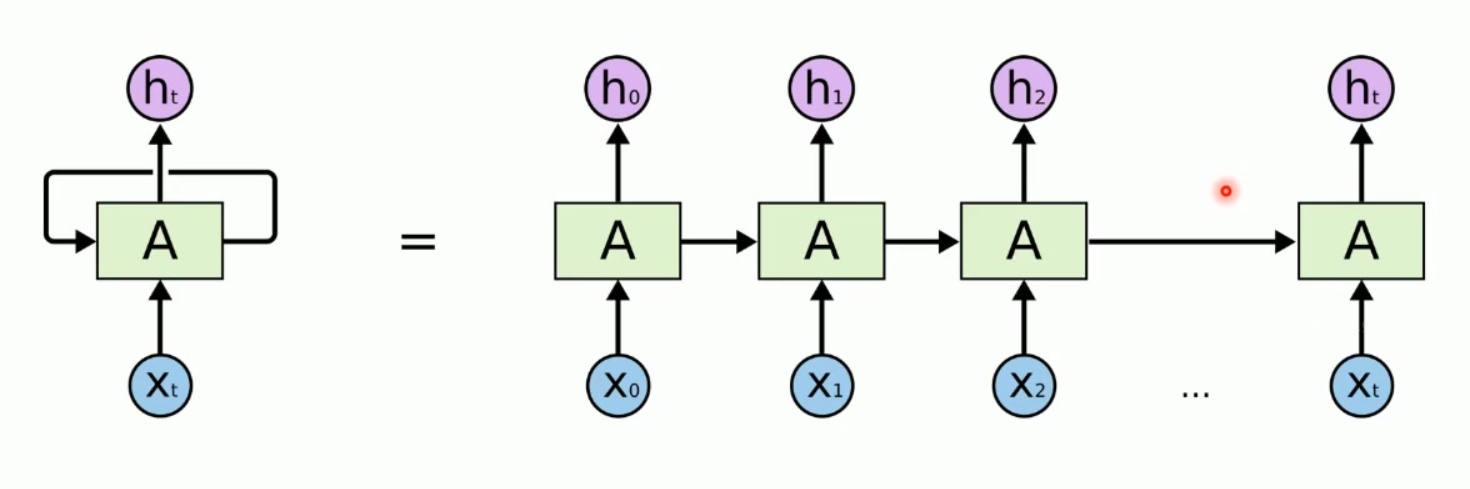
时间展开原理: 将循环连接展开为时间步序列
信息传递机制:
当前隐藏状态受当前输入和前一状态共同影响
实现上下文信息传递(如分词中前字影响后字标注)
应用示例: 在分词任务中,每个字的标注决策会参考前面字的特征
输入 x(t)
↓
隐藏层 h(t) ←←← 记忆 h(t-1)
↓
输出 y(t)每一步都会:
- 接收当前输入
x(t) - 接收上一步的记忆
h(t-1) - 生成当前输出
y(t) - 生成新的记忆
h(t)传给下一步
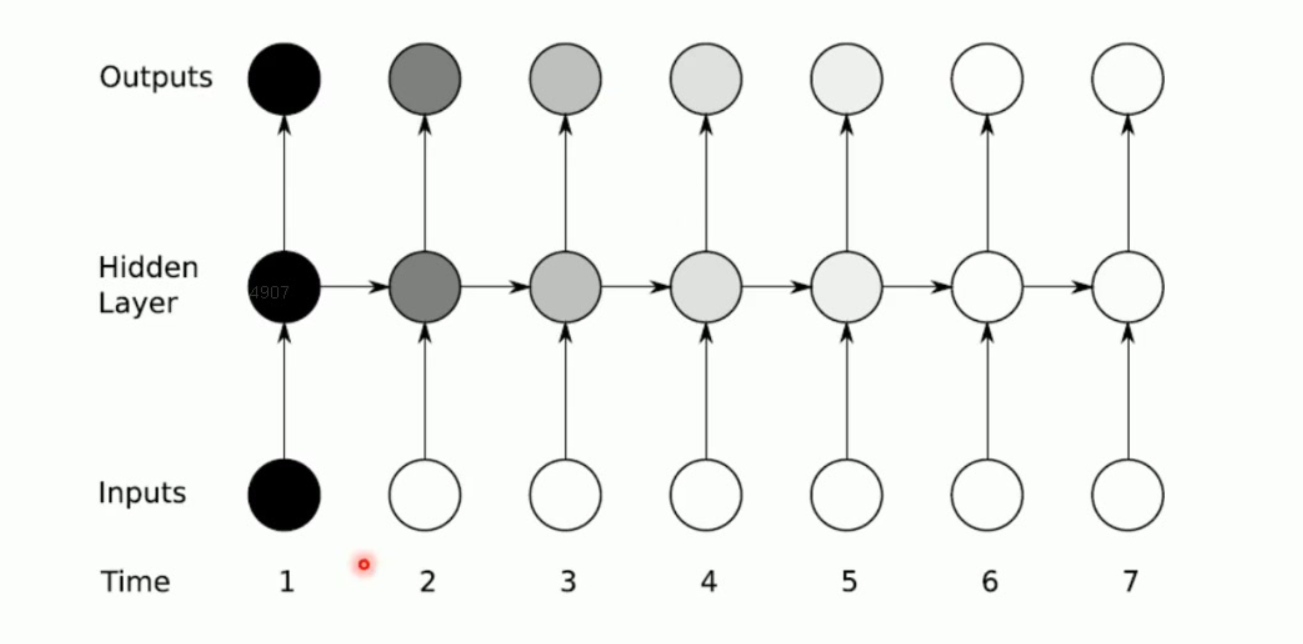
2. 展开后长这样(时间展开)
x1 → h1 → y1
↓
x2 → h2 → y2
↓
x3 → h3 → y3所有时刻共享同一组权重 → 这是 RNN 非常重要的特性。
RNN的公式与两种类型
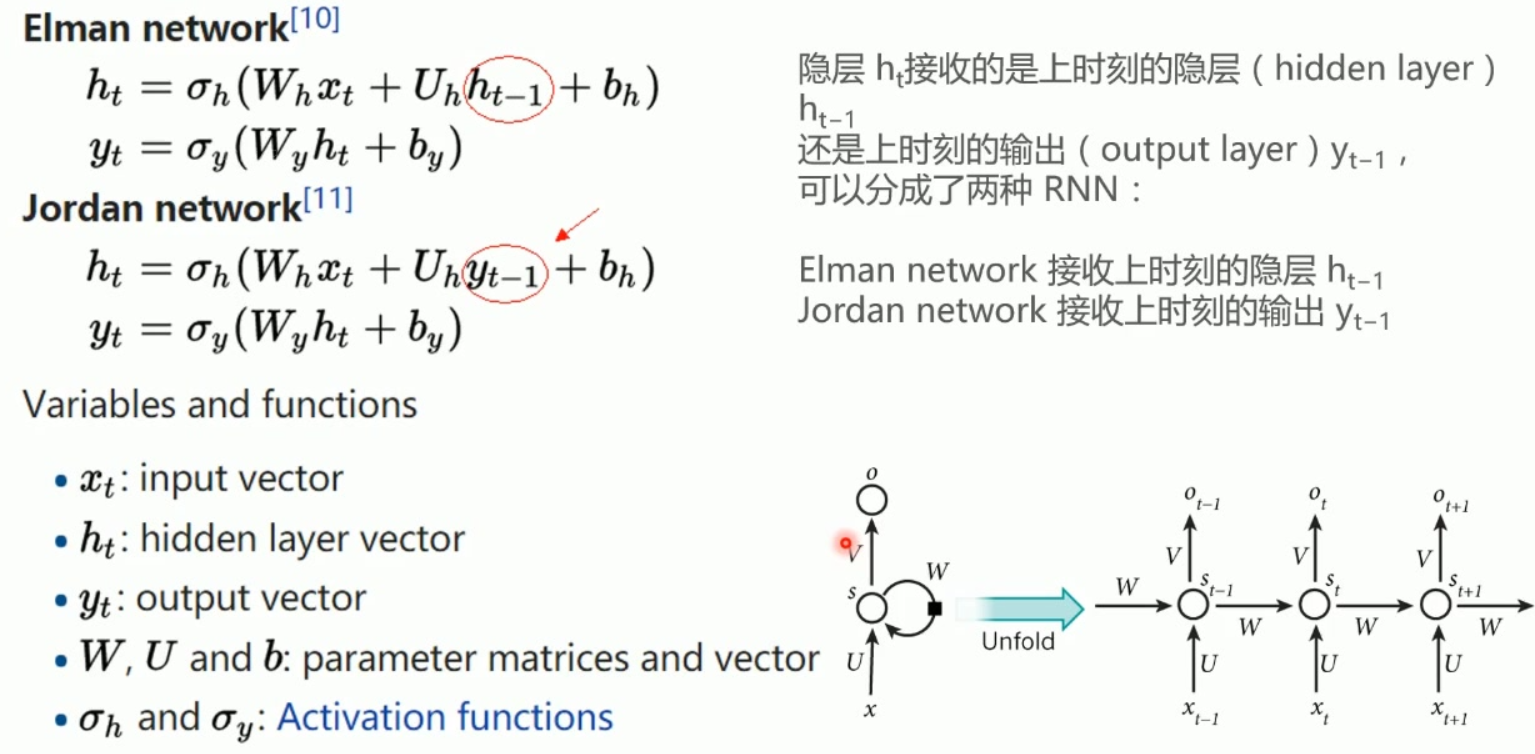
通用公式结构:
隐藏层: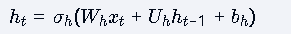
输出层: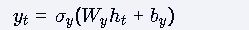
两种类型区别:
Elman网络:接收前一时刻隐藏层
Jordan网络:接收前一时刻输出层
参数说明:
W,U,b:权重矩阵和偏置向量
σ:激活函数
若去掉循环项(即退化为BP网络
核心功能: 通过历史信息决策当前问题,类似电影情节理解需要上下文
典型应用:
填空预测:根据前文预测缺失内容
语言建模:基于上下文生成合理文本
1. 填空预测示例
示例1:"有一朵云飘在()"
训练后模型可能输出"天空"、"空中"等合理词汇
成功原因:上下文简单,短期依赖关系明确
示例2:"我从小生长在美国。。。我可以说一口流利的()"
可能错误输出"中文"而非"英语"
失败原因:长距离依赖导致记忆丢失
RNN结构与梯度消失
信息传递机制:
隐藏层状态随时间步传递
早期输入对后期输出的影响呈指数衰减
典型影响范围:5-6个时间步后影响力趋近于零
- 梯度消失问题
根本原因:
误差反向传播时需经过多个时间步
梯度连乘导致数值快速衰减(类似传统BP网络)
具体表现:
长序列中远端信息无法有效影响当前决策
参数更新时早期层几乎得不到有效梯度
RNN 能做什么?(应用场景)
RNN 是NLP(自然语言处理)、语音、时序预测的基石模型。
1. 文字相关
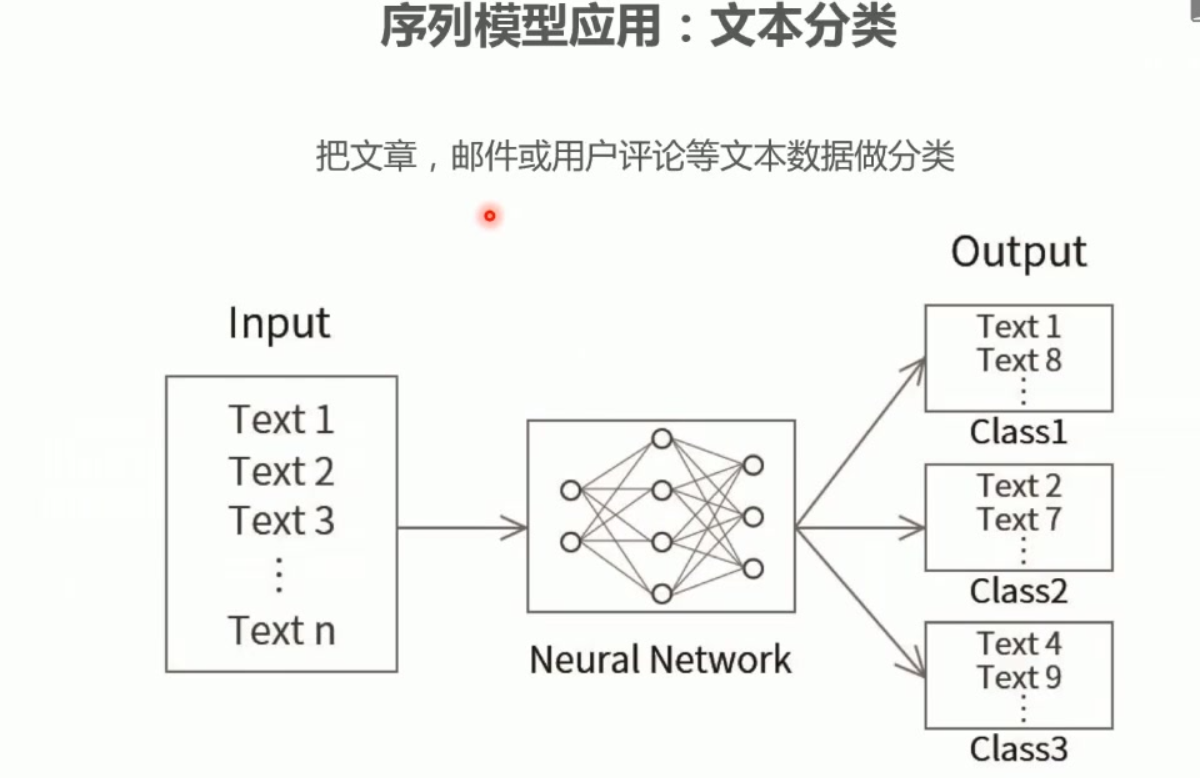
- 文本生成(写小说、写文案)
- 机器翻译
- 语音转文字
- 情感分析
- 聊天机器人
- 分词标注
使用BMES标注法:
B:词起始位置
M:词中间位置
E:词结束位置
S:单字词
示例分析:"人/B们/E常/S说/S生/B活/E是/S一/S部/S教/B科/M书/E"
2. 时序预测
- 股票预测
- 天气预测
- 工业传感器异常检测
- 行为识别
3. 语音相关
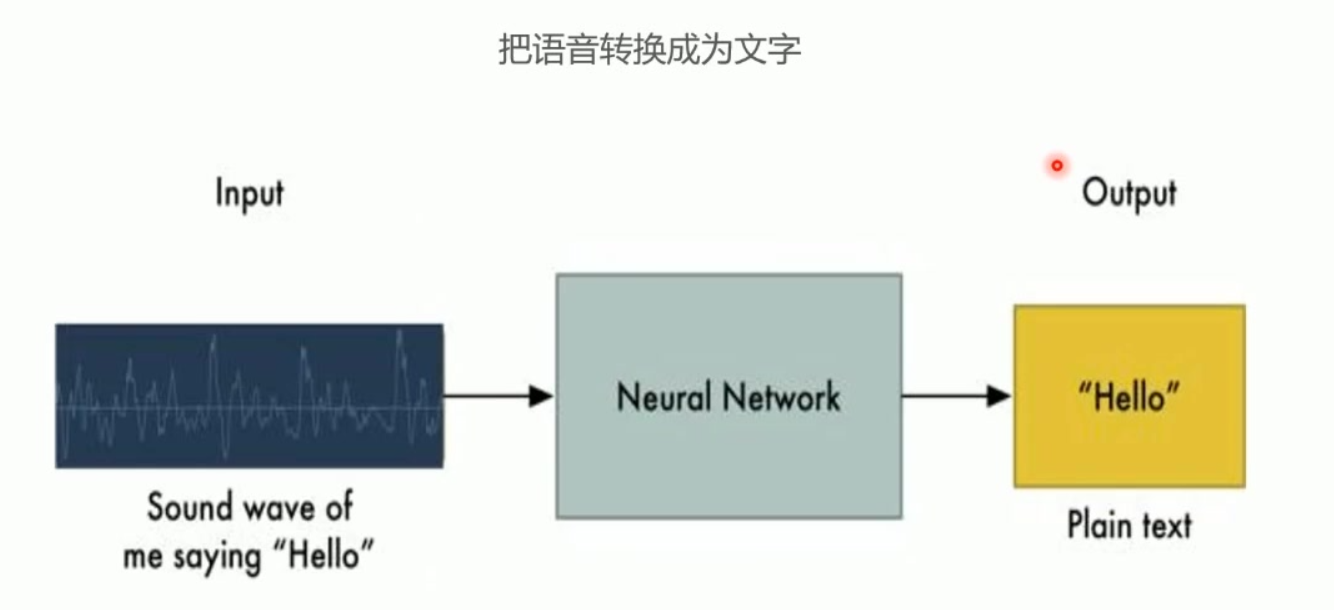
- 语音合成
- 语音识别
- 声纹识别
4. 视频
- 行为识别
- 视频帧预测
- 目标跟踪
RNN 的致命问题(必须知道)
梯度消失 / 梯度爆炸
RNN 理论上能记住很久之前的信息,但实际上记不住。
原因:
- 序列太长(比如 100 个字)
- 梯度反向传播时会不断相乘
- 梯度越来越小 → 消失
- 或者越来越大 → 爆炸
结果:
RNN 只能记住最近几步,无法记住长距离依赖。
比如:
- 我昨天去__,那里的风景很美。
RNN 能预测"哪里"。
但:
- 我小时候住在北京,后来去上海,长大后去深圳工作,我最喜欢的城市是__。
RNN 记不住前面的"北京"。
为了解决 RNN 缺点,诞生了两个升级版
1. LSTM(长短期记忆网络)
梯度消失问题:传统RNN在处理长序列时会出现梯度消失问题,导致预测结果不准确
LSTM的发明:1997年科学家发明了LSTM网络,专门用于处理长序列问题
名称由来:LSTM全称为Long Short Term Memory(长短时记忆网络)
LSTM的基本结构和原理
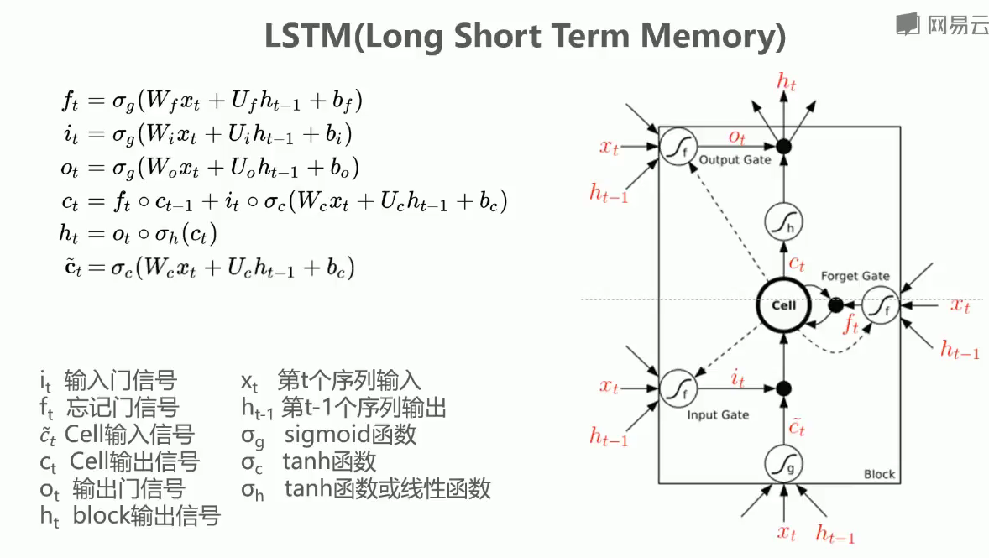
整体结构: LSTM将隐藏层的神经元替换为复杂的block结构
信号流向:
- 底部为输入层(表示第t个序列输入)
- 顶部为输出层(表示block输出信号)
- 中间为包含记忆单元的隐藏层
LSTM中的门控机制
输入门:
计算公式: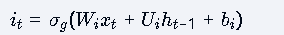
功能:控制新信息的输入比例(0-1之间)
遗忘门:
计算公式: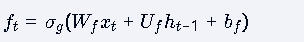
功能:决定保留或遗忘多少之前的信息
输出门:
计算公式: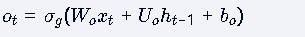
功能:控制当前状态的输出比例
记忆单元更新:
计算公式: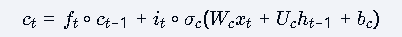
功能:结合遗忘门和输入门更新记忆单元
输出计算:
计算公式: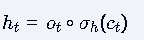
功能:基于当前记忆单元和输出门产生最终输出
LSTM的工作机制
信息保留:LSTM可以自主决定哪些信息需要长期保留
门控优势:
输入门控制新信息流入
遗忘门控制旧信息保留
输出门控制信息输出
训练结果:经过训练后,LSTM能自动判断信息处理策略
LSTM的应用示例
序列预测:如预测"我从小生长在美国...我可以说一口流利的()"
信息保留:LSTM可以记住"美国"这个关键信息来影响后续预测
自主决策:网络自动决定何时使用保留的信息
LSTM的变体:Peephole LSTM 与FC LSTM
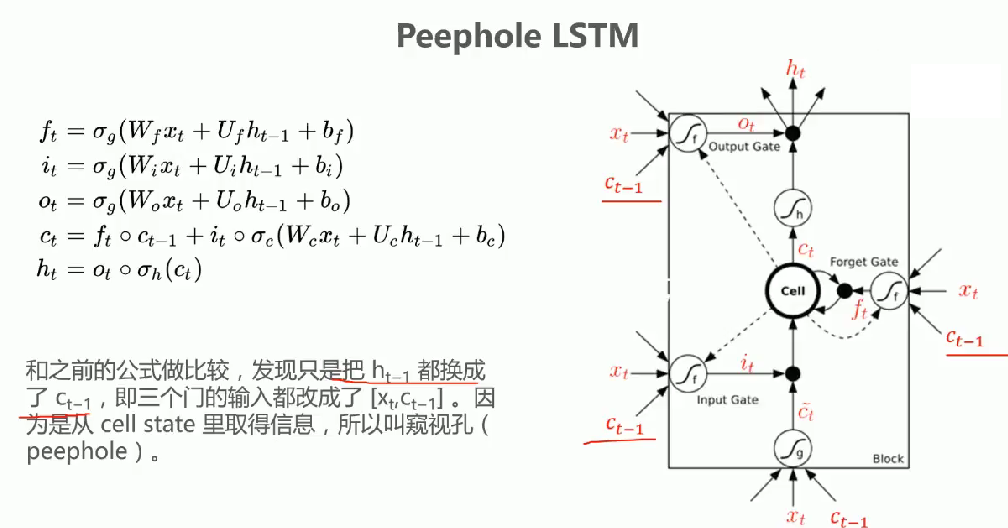
核心修改:将标准LSTM中三个门控单元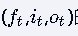
的输入h t-1全部替换为Ct-1,即门控输入变为的组合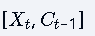
结构特点:
窥视机制:直接从cell state获取历史信息,形成"peephole"连接
公式变化:
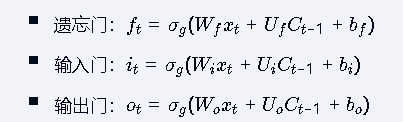
**设计原理:**通过cell state直接传递长期记忆信息,避免通过hidden state间接传递造成的信息衰减
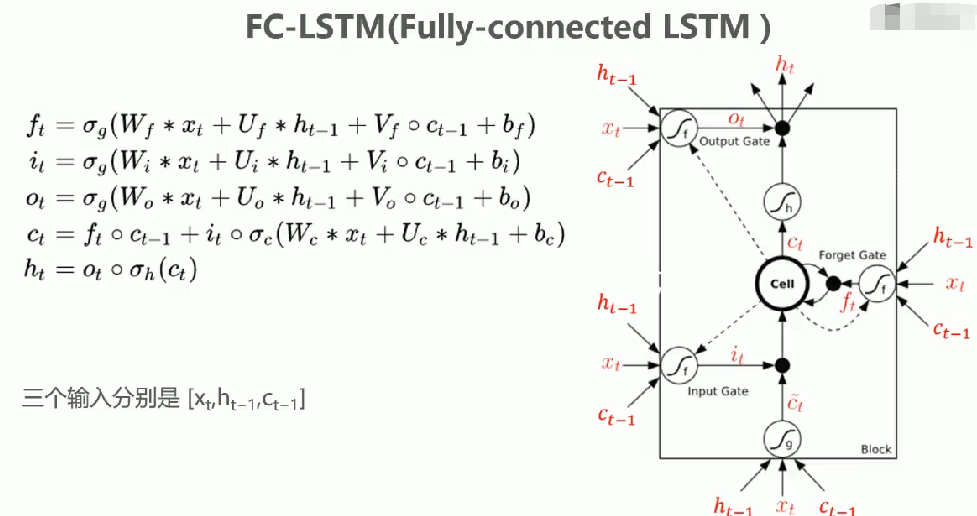
将Peephole LSTM与标准LSTM相结合,三个门控单元同时接收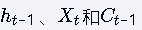
三种输入信号

LSTM的应用效果与优势
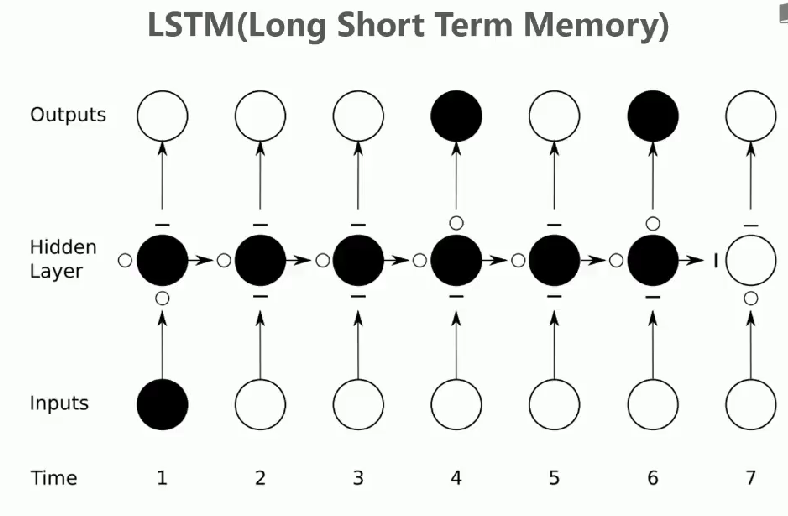
记忆机制:
选择性记忆:通过门控机制自动判断信息重要性,重要信息可长期保存在Ct中
可控遗忘:遗忘门实现记忆的渐进式更新而非直接清除
时序处理优势:
长程依赖:cell state形成的信息高速公路,有效缓解梯度消失问题
动态输出:输出门控制记忆内容的适时释放,如示例中Ct可在多个时间步影响输出
结构创新:
神经单元改造:将传统RNN神经元替换为包含门控机制的memory block
三阶段控制:输入门筛选、遗忘门更新、输出门发布的协同工作机制
2. GRU(门控循环单元)
出现时间: 2014年提出的新型循环神经网络结构
核心优势: 与LSTM效果相当但参数更少,计算效率更高
结构简化: 将LSTM的遗忘门和输入门合并为单一的更新门
应用现状: 当前使用频率较高,因其在保持性能的同时减少了计算量


设计原理:
公式结构是经过大量实验验证的最优方案
参数共享和门控机制实现了信息的高效流动
相比LSTM减少了参数数量但保持了相近性能
LSTM与GRU都属于 RNN 的改进版 ,解决了长序列记忆问题。
现在工业界、学术界基本不用原始 RNN,都用 LSTM 或 GRU。
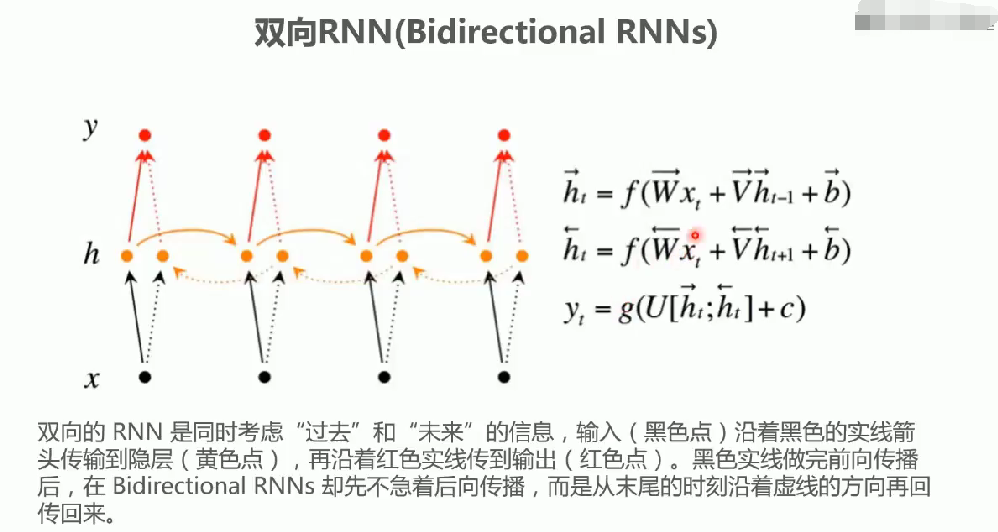
双向RNN
设计理念: 同时考虑序列数据的正向和反向信息
应用场景: 适用于需要全局上下文理解的任务(如自然语言处理)
核心价值: 通过双向处理捕获更完整的序列特征
典型结构: 包含正向和反向两个独立的RNN处理流
堆叠双向RNN
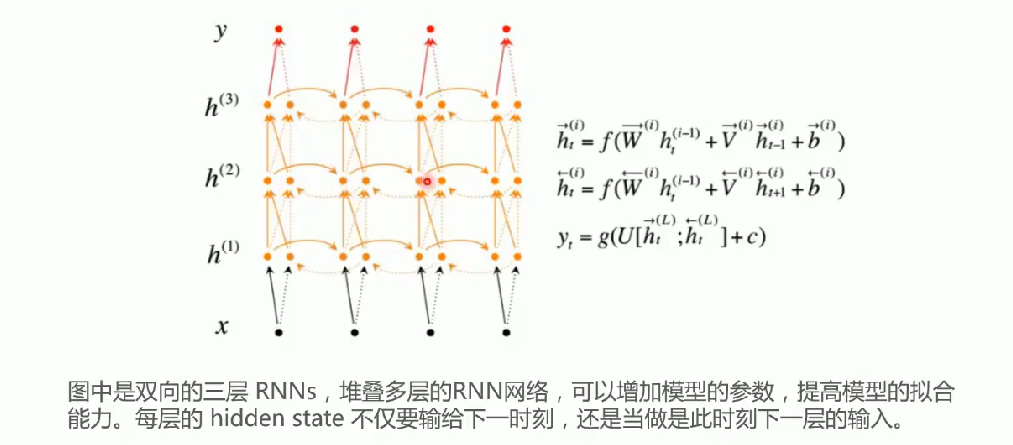
核心概念:通过堆叠多层RNN网络增加模型参数,提高模型拟合能力。图中展示的是双向三层RNN结构。
双向性体现:同时包含前向传播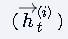
和后向传播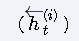
的隐藏状态计算。
层级传递:每层hidden state需同时传递给:
同层的下一时序(时间维度传播)
当前时序的下一层(深度维度传播)
参数说明:
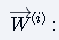
第i层前向传播的权重矩阵
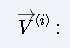
第i层时序传播的权重矩阵
网络类型兼容性:堆叠结构可适用于标准RNN、LSTM或GRU等循环网络变体
RNN vs CNN 区别
| 特点 | CNN | RNN |
|---|---|---|
| 处理数据 | 图像(空间结构) | 序列(时间/顺序结构) |
| 记忆能力 | 无 | 有 |
| 核心能力 | 提取空间特征 | 提取时序依赖 |
| 擅长 | 图片分类、检测 | 文本、语音、时序 |
| 结构 | 卷积、池化 | 循环、隐藏状态 |
简单记:
CNN 看空间,RNN 看时间。
最简单总结(4 句就够)
- RNN 是处理序列数据(文字、语音、时序)的神经网络
- 它有记忆,能记住前面的信息
- 原始 RNN 有梯度消失问题,记不住长序列
- 现在都用 LSTM / GRU 替代 RNN