千行代码,一步步搭出一个现代 LLM 推理引擎,吃透大模型推理的每一项关键技术。
本阶段目标 --- 最简推理实现
用最朴素的方式把端到端推理跑通:先搭起整体框架,再逐个模块替换为完整实现。整个阶段共 5 篇短文:
| 序号 | 主题 |
|---|---|
| 1 | 序章:LLM 推理引擎到底在做什么(本篇) |
| 2 | 核心数据结构:Req 与 SamplingParams |
| 3 | 一个可运行的 Decoder Layer(一次性版本) |
| 4 | Naive KV Cache |
| 5 | 单 GPU Engine v0 与 greedy 生成 |
本篇你将学到
- 一句话能说清"LLM 推理引擎在做什么";
- 理解 prefill 与 decode 为何要分两步,KV cache 为何是核心;
- 看到推理引擎 4 类进程的全景图,作为后续阶段展开的起点;
- 获得一张系列阅读路线表,可按自己关心的方向选择性阅读。
本篇不涉及实现,只界定问题与目标。
1. LLM 推理引擎到底在做什么
一句话定义:给定一段 prompt,逐 token 生成续写,直到遇到停止条件。把这一过程包装成能以"请求"形式被外部高效调用的服务系统,便是 LLM 推理引擎。
与训练框架的区别
很多人第一次接触 LLM 推理时,会以为"加载模型然后调用 model.generate() 即可"。这在演示场景下尚可成立,但在生产场景下远远不够。
| 维度 | 训练框架(HF transformers / Megatron) | 推理引擎(SGLang / vLLM) |
|---|---|---|
| 输入 | 固定长度的 batch | 任意长度、随时到达的请求流 |
| forward 次数 | 每个 batch 一次 | 每个请求 N 次(N = 输出长度) |
| 显存关注点 | 激活值 + 梯度 | KV cache(梯度根本不存在) |
| 时间预算 | 多分钟一个 step 可以接受 | 单 token 的 P99 延迟以毫秒计 |
| 并发模型 | 数据并行+模型并行 | 上面这些 + 请求级调度 |
它要解决的真问题
吞吐量(每秒处理多少请求)、延迟(首 token 多快出、token 间隔多稳)、显存利用率(KV cache 不爆)、公平性(长请求不能饿死短请求)。
怎么解决
把"一次 forward 跑模型"拆成 prefill 与 decode 两个阶段、引入 KV cache、把请求打包成 batch、用 scheduler 决定每一步谁能上、用分页显存避免碎片、用 CUDA Graph 消除 launch 开销------这正是本系列后续 8 个阶段要逐一构建的东西。
本篇不展开任何一个机制,只把问题边界画清楚。
2. Prefill 与 Decode:为什么必须分两步
一个朴素假设
初次接触推理时常会产生这样的疑问:既然 transformer 是一次 forward,为何不能在 prompt 后拼接 N 个待生成的 PAD 一并送入,一次性输出 N 个 token?
答案藏在 causal mask 里。Transformer 的自注意力中,第 k 个位置只能看到前 k-1 个位置,这是因果性的硬约束------你必须先生成第 k 个 token,才能为第 k+1 个 token 提供 K/V。换句话说,生成阶段的 token 之间存在数据依赖,串行无法绕开。
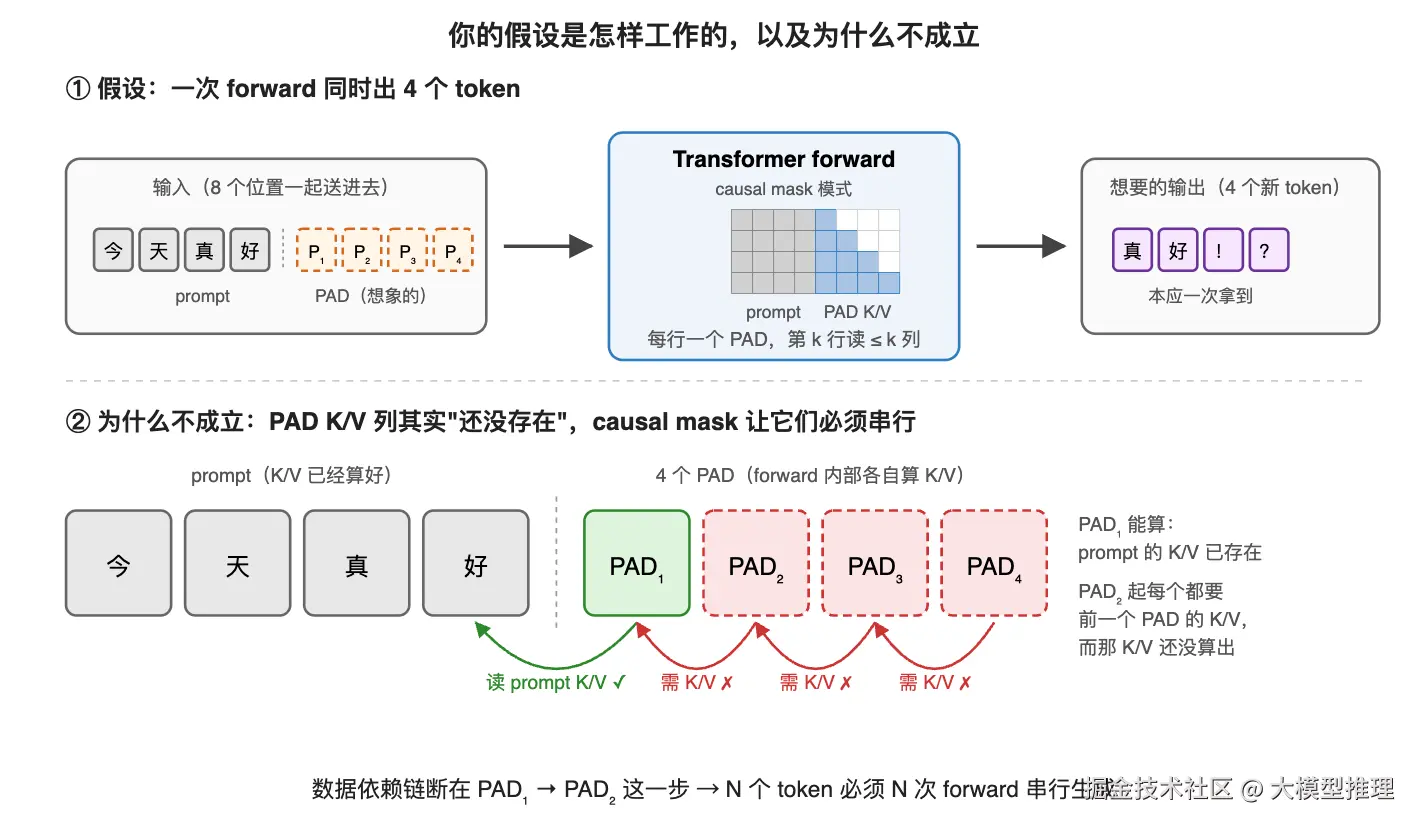
因此自然分为两个阶段
Prefill :把整个 prompt 一次性送入模型。所有 prompt token 之间没有"未来依赖"问题(它们是已知输入),可以并行算 attention。并行度 = prompt 长度,通常几十到几千,算力密集。
Decode :每一步只生成 1 个新 token。新 token 需要对全部历史 KV 算 attention,但自己只有一个 query。并行度 = batch 内同时在 decode 的请求数,通常 16~256,显存带宽密集。
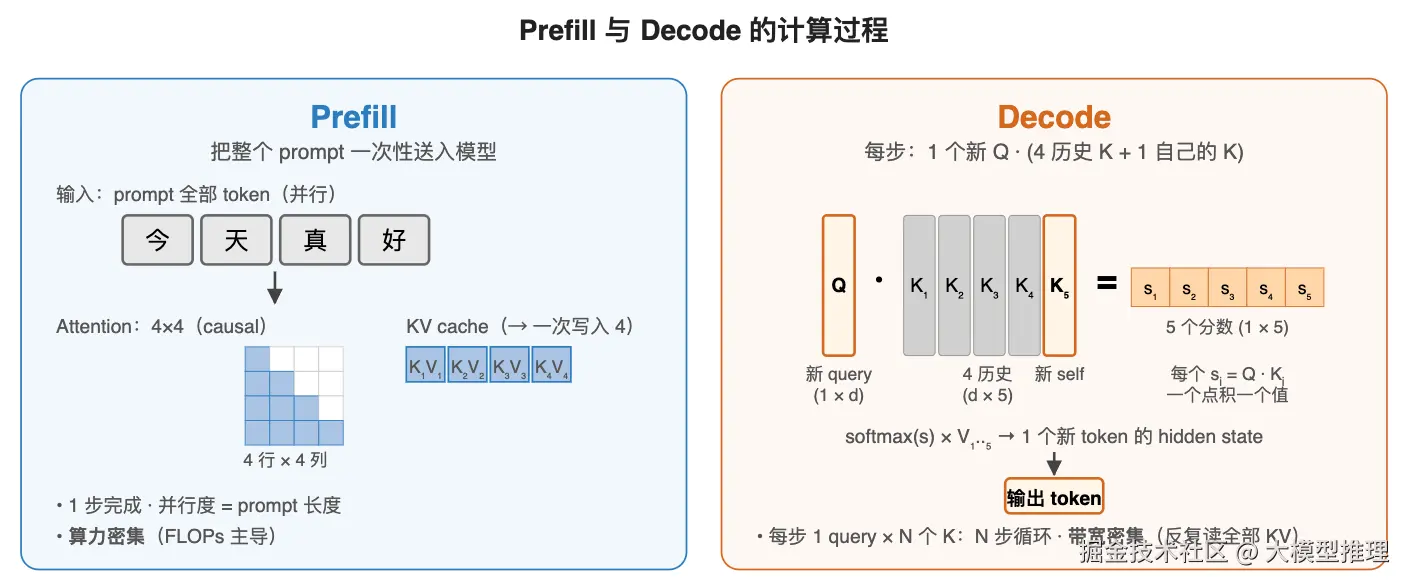
工程上的连锁后果
两个阶段在硬件瓶颈、kernel 实现、调度策略上几乎完全不同,这是这套引擎后续所有复杂度的根源:
- kernel 选择不同 :prefill 用
flash_attn_varlen_func(变长拼一起算),decode 用flash_attn_with_kvcache(带 cache 的特殊路径)。后文会展开。 - 调度策略不同:prefill 的约束在于避免显存溢出(token budget),decode 的约束在于避免 batch 过小(带宽利用率)。后文会展开。
- 优化重点不同:prefill 阶段 7PU 一般已经满载,性能上限是算力;decode 阶段 7PU 经常空转,性能上限是 CPU launch 开销。这也是后续引入 CUDA Graph 和 overlap scheduling 的原因。
拓展:PD 分离
既然 prefill 和 decode 在硬件瓶颈、kernel 选型、调度策略上都不同,能不能把它们放到不同机器上 ?这就是 PD 分离(Prefill-Decode Disaggregation,Splitwise / DistServe / MoonCake 等近期工作的核心思想):
- prefill 池:算力密集,用 H100/H200 这类高 FLOPs 卡;算完 prompt 把 KV cache 通过 RDMA / NVLink 传给 decode 池
- decode 池:带宽密集,用显存大、带宽高但 FLOPs 不必那么强的卡;只做 token 逐个生成
好处主要有四个:
- 干扰彻底消除:prefill 的"算力大锤"不再卡住 decode 的"毫秒级 token 流",TTFT(首 token 延迟)和 ITL(token 间间隔)可以分别优化
- 硬件可以错配:prefill 节点配高算力卡、decode 节点配大显存卡,每一类各用所长,整体 $ / token 更优
- 独立扩缩容:长输出场景下 decode 工作量远大于 prefill,可以单独扩 decode pool 而不动 prefill
- SLO 解耦:两个池的指标互不干扰,prefill 池专注吞吐、decode 池专注尾延迟
代价:节点间要高速传 KV cache(依赖 RDMA / NVLink switch),调度系统要跨机 routing + 容灾,复杂度明显上升;小规模部署反而不划算。本系列只构建单机引擎,PD 分离不展开------但理解"为什么会出现这种架构"对后面读真实产线系统很有帮助。
下面这张图把两阶段的负载差异画出来,可作为后续讨论的原点。
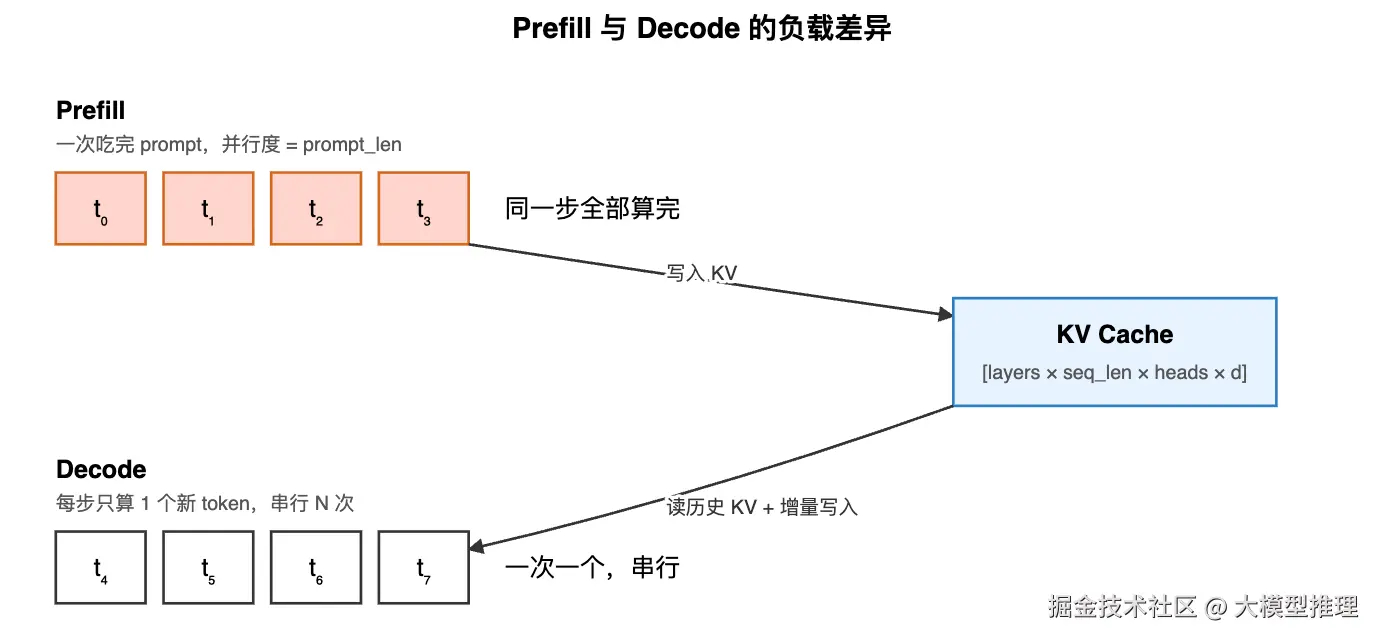
3. KV Cache:核心的核心
它存在的根本原因
回看 decode 的每一步:算 attention(Q_new, K_all, V_all)。其中 Q_new 是当前这个新 token 的 query,K_all、V_all 是从 prompt 第 1 个 token 到上一个生成 token 的全部 key 和 value。
关键观察:K_all 和 V_all 的前 n-1 项在上一步已经算过了,没有任何理由再算一次。把它们存下来、增量追加新一项即可------这就是 KV cache。
再深入一层:为什么位置 i 的 K_i、V_i 不会随时间变化? 因为它们都是 hidden state 的线性投影------K_i = W_k · h_i、V_i = W_v · h_i。而每一层 transformer 的 h_i 又来自 attention(Q_i, K_{0..i}, V_{0..i})------causal mask 让它只依赖位置 ≤ i,跟"未来生成的 token"完全无关。换句话说,一旦位置 i 的 K_i、V_i 写入 cache,后续无论生成多少新 token 都不会改它。这就是 KV cache 安全可重用的根本依据。
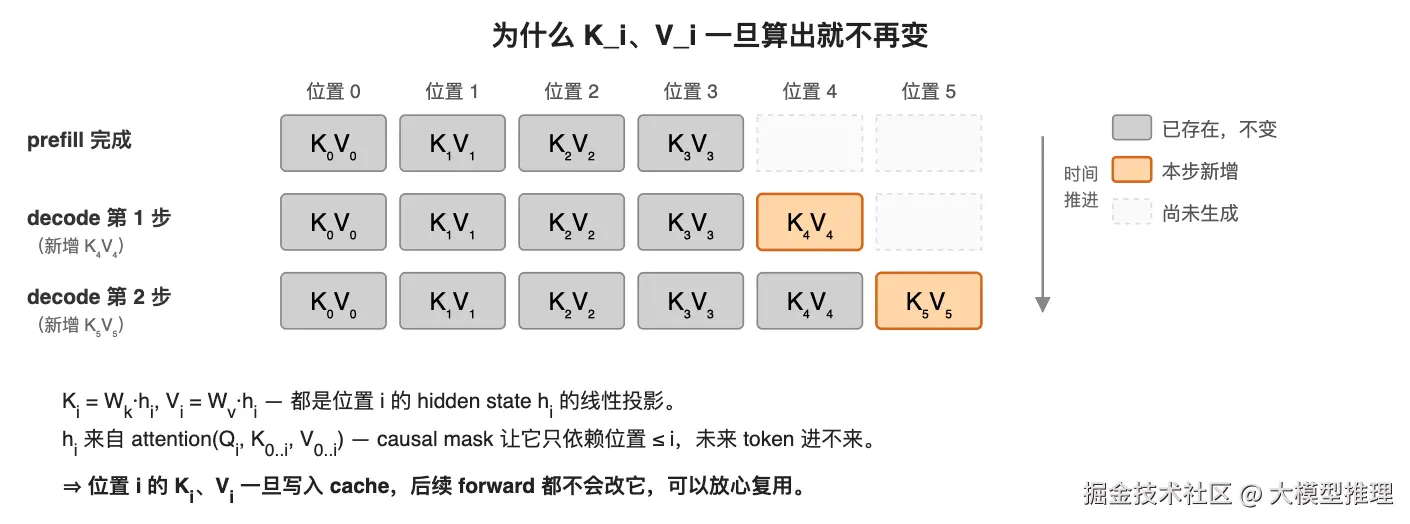
复杂度差异有多大
设隐藏维度为 d,生成第 k 个 token 时需要的计算量:
| 操作 | 不加 cache | 加 cache |
|---|---|---|
| Q 投影 | O(k · d²) | O(1 · d²) |
| K/V 投影 | O(k · d²) | O(1 · d²) 仅新 token |
| attention 矩阵 QKᵀ | O(k² · d) | O(k · d) |
| 输出投影 | O(k · d²) | O(1 · d²) |
| 单步总计 | O(k² · d) | O(k · d) |
| 生成 N 个 token 总计 | O(N³ · d) | O(N² · d) |
上面这张表里每一项的复杂度都能从矩阵形状直接读出来------(m×p) × (p×n) 的乘法成本是 m · n · p:
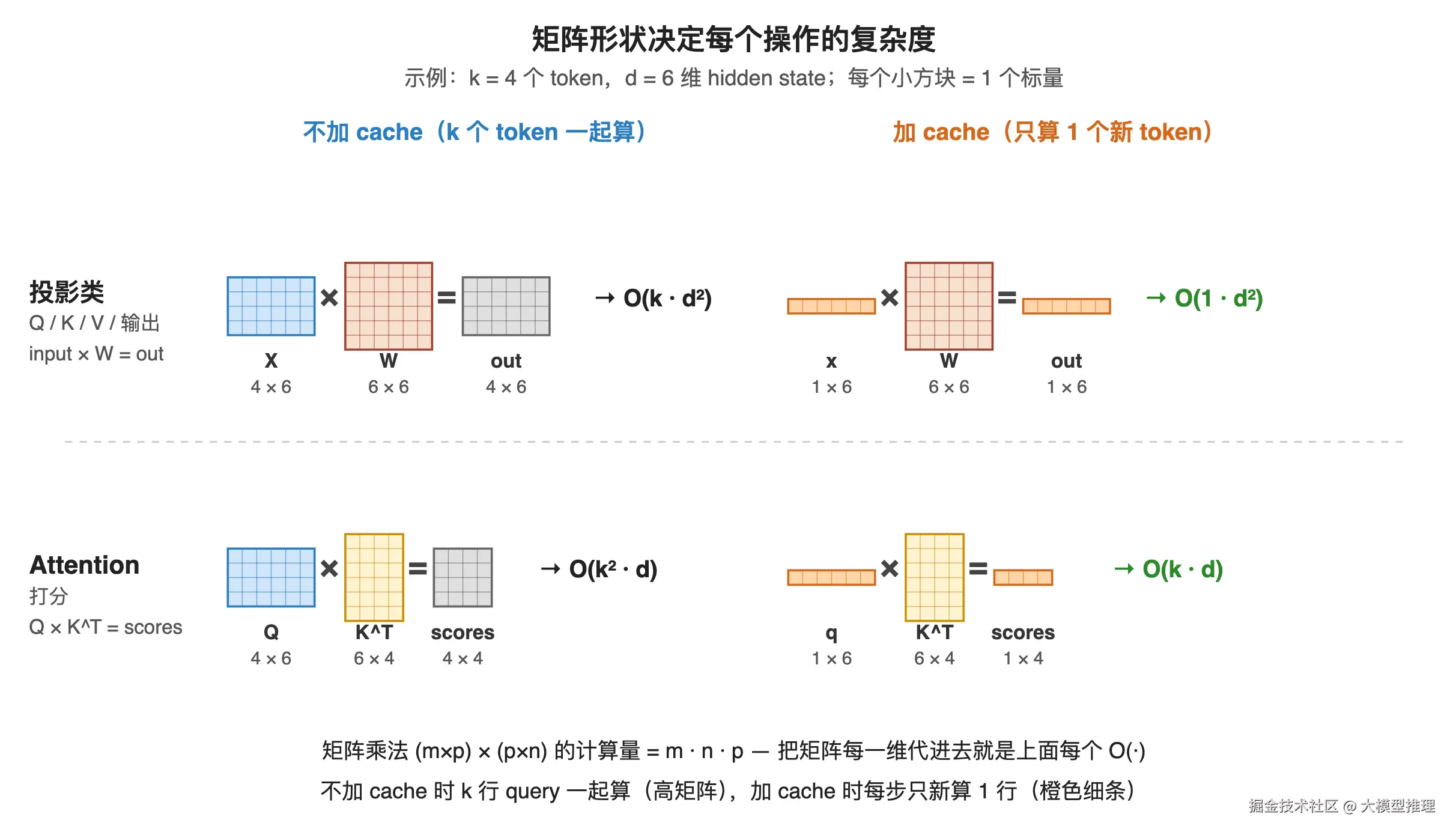
从 N³ 降至 N²。当 N=1000 时,差距达到 1000 倍。这并非一项普通优化,而是让 LLM 推理在工程上可行的前提。下文的示例代码将直观呈现这一差距。
它带来的新问题(伏笔)
KV cache 解决了一个根本瓶颈,但同时引入了两个新的工程问题,这两个问题贯穿后面几个阶段:
-
显存占用爆炸 :Llama-3 8B 在 4096 上下文下,单条请求的 KV cache ≈ 2 GB。100 个并发请求就吃掉 200 GB------而一块 H100 只有 80 GB 显存。这是后续引入 Paged KV Cache 的动机。
-
跨请求的浪费 :很多生产场景里,所有请求共享同一份 system prompt。这部分 KV 完全可以复用,而不是每条请求都从头算一遍。这是后续引入 Radix Cache 的动机。
本篇不展开这两个机制,只埋下伏笔------为后续的分页与 prefix tree 留好动机。
python
"""
示例:不加 cache 与加 cache 的复杂度对比
用一个 2 层、hidden=4096、vocab=100 的简化 GPT 跑两种生成方式:
A) naive --- 每生成 1 个 token 都重新跑整段序列
B) cached --- prefill 一次后,decode 每步只算 1 个新 token
观察 wall-time 差距随生成长度增长是否符合理论:
naive ∈ O(N³),cached ∈ O(N²)
"""
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(42)
# 有 GPU 就跑 GPU,没有就退回 CPU(示例模型的参数很小,非推理开销占比大,实测倍数可能远小于理论值)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
HIDDEN_DIM, NUM_HEADS, VOCAB_SIZE = 4096, 32, 100 # hidden=4096 接近真实 LLM 尺度
HEAD_DIM = HIDDEN_DIM // NUM_HEADS # = 128
class DemoAttn(nn.Module):
def __init__(self):
super().__init__()
self.qkv = nn.Linear(HIDDEN_DIM, 3 * HIDDEN_DIM, bias=False)
self.out_proj = nn.Linear(HIDDEN_DIM, HIDDEN_DIM, bias=False)
def forward(self, x, kv_cache=None):
# x 形状: [batch, seq, hidden];kv_cache=None 表 prefill,否则 decode (seq=1)
batch, seq, _ = x.shape
q, k, v = self.qkv(x).chunk(3, dim=-1)
# 拆头:[batch, seq, hidden] → [batch, heads, seq, head_dim]
q = q.view(batch, seq, NUM_HEADS, HEAD_DIM).transpose(1, 2)
k = k.view(batch, seq, NUM_HEADS, HEAD_DIM).transpose(1, 2)
v = v.view(batch, seq, NUM_HEADS, HEAD_DIM).transpose(1, 2)
# 关键:decode 时把新 K/V 追加到历史 cache 上------这就是 cache 复用的本质
if kv_cache is not None:
cached_k, cached_v = kv_cache
k = torch.cat([cached_k, k], dim=2)
v = torch.cat([cached_v, v], dim=2)
new_kv_cache = (k, v)
attn_out = F.scaled_dot_product_attention(q, k, v, is_causal=(kv_cache is None))
attn_out = attn_out.transpose(1, 2).reshape(batch, seq, HIDDEN_DIM)
return self.out_proj(attn_out), new_kv_cache
class DemoGPT(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(VOCAB_SIZE, HIDDEN_DIM)
self.layers = nn.ModuleList([DemoAttn() for _ in range(2)])
self.lm_head = nn.Linear(HIDDEN_DIM, VOCAB_SIZE, bias=False)
def forward(self, token_ids, kv_caches=None):
x = self.embedding(token_ids)
new_kv_caches = []
for i, layer in enumerate(self.layers):
x, layer_cache = layer(x, None if kv_caches is None else kv_caches[i])
new_kv_caches.append(layer_cache)
return self.lm_head(x), new_kv_caches
def generate_naive(model, prompt, max_new_tokens):
# 每一步把整段 token_ids 重新过一遍模型------完全不复用历史 K/V
seq = prompt
for _ in range(max_new_tokens):
logits, _ = model(seq)
seq = torch.cat([seq, logits[:, -1:].argmax(-1)], dim=1)
return seq
def generate_cached(model, prompt, max_new_tokens):
# prefill 一次性写入 cache;之后 decode 每步只把新 token 喂进去
logits, kv_caches = model(prompt)
last_token = logits[:, -1:].argmax(-1)
output_pieces = [prompt, last_token]
for _ in range(max_new_tokens - 1):
logits, kv_caches = model(last_token, kv_caches=kv_caches)
last_token = logits[:, -1:].argmax(-1)
output_pieces.append(last_token)
return torch.cat(output_pieces, dim=1)
def sync():
# CUDA op 是异步的,timing 前要同步;CPU 上是空操作
if device.type == "cuda":
torch.cuda.synchronize()
model = DemoGPT().to(device).eval()
prompt = torch.randint(0, VOCAB_SIZE, (1, 32), device=device)
MAX_NEW_TOKENS = 64
with torch.no_grad():
# warmup:避开第一次 forward 的 kernel 编译 / cache 分配开销
generate_naive(model, prompt, 4)
generate_cached(model, prompt, 4)
sync()
t0 = time.perf_counter(); generate_naive(model, prompt, MAX_NEW_TOKENS); sync(); t1 = time.perf_counter()
t2 = time.perf_counter(); generate_cached(model, prompt, MAX_NEW_TOKENS); sync(); t3 = time.perf_counter()
print(f"device : {device}")
print(f"prompt_len=32, max_new_tokens={MAX_NEW_TOKENS}")
print(f"naive : {t1 - t0:.3f} s")
print(f"cached : {t3 - t2:.3f} s ({(t1 - t0) / (t3 - t2):.1f}x faster)")
kotlin
/opt/miniconda3/lib/python3.12/site-packages/torch/cuda/__init__.py:61: FutureWarning: The pynvml package is deprecated. Please install nvidia-ml-py instead. If you did not install pynvml directly, please report this to the maintainers of the package that installed pynvml for you.
import pynvml # type: ignore[import]
device : cpu
prompt_len=32, max_new_tokens=64
naive : 4.900 s
cached : 3.152 s (1.6x faster)4. 推理引擎的核心模块
到此为止,单条请求内部发生的事情已经讲完。但工程上面对的从来都不是单条请求,而是并发的请求流。
单进程为何不够
理论上可以,但实际上不可行,原因有三:
- Python GIL(Global Interpreter Lock):CPython 同一时刻只允许一个线程执行 Python 字节码。tokenizer / Detokenizer / HTTP 处理都是 CPU 密集的纯 Python 代码,一旦它们抢到 GIL,Scheduler 主循环就只能等------GPU 因此空转。
- GPU 调度需要独占主循环:Scheduler 必须在每个 step 之后立刻决定下一个 batch 怎么组------任何阻塞都会让 GPU 空转。
- 故障隔离:tokenizer 抛异常不应该让整个引擎挂掉。
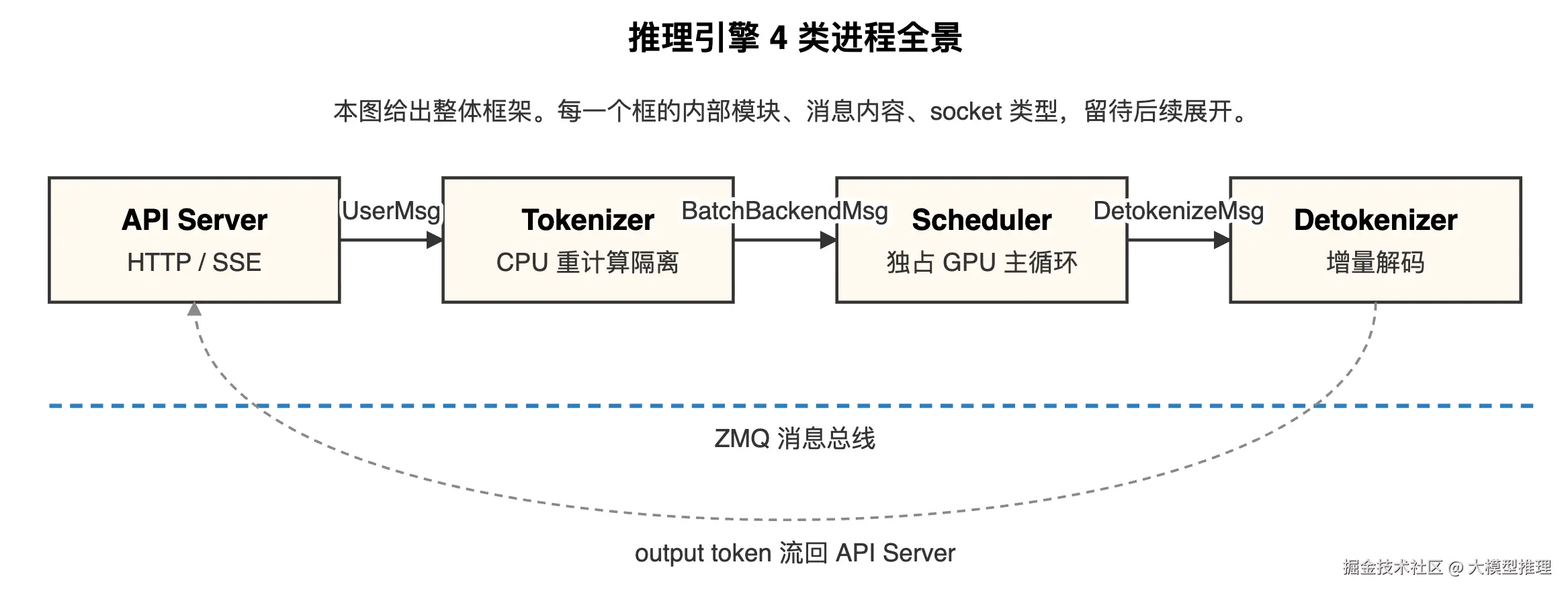
因此自然分成 4 类进程
我们要构建的推理引擎把整个系统拆成 4 个相互独立的 Python 进程,靠 ZMQ 消息总线相互连接:
- API Server:接 HTTP 请求、对接 OpenAI 兼容接口、维护 SSE 流式连接(SSE = Server-Sent Events,单向的 HTTP 推送,让客户端能边收 token 边显示);
- Tokenizer Worker:把文本切成 token id(CPU 密集,独立进程不阻塞 GPU 调度);
- Scheduler:拥有 GPU。维护请求队列、KV cache 池、Engine 实例;每一步决定哪些请求进入 batch;
- Detokenizer Worker:把生成的 token id 增量解码回文本(要处理多字节 UTF-8 的边界问题,独立成进程便于隔离)。
后续阶段都在拆这张图
本系列的大部分阶段,本质上都是在"展开其中某一个框":
- 后续大部分阶段都发生在 Scheduler 框内(KV cache、batch、调度、CUDA Graph、Radix、TP);
- 直到系列末段才把 API Server / Tokenizer / Detokenizer 三个框展开,讲它们怎么和 Scheduler 通信、SSE 怎么实现、
/v1/chat/completions怎么对齐 OpenAI 协议。
下方这张图给出整体地图,先把握其结构,内部细节后续逐一展开。
5. 系列阶段一览
整个系列分 9 个阶段(1~9),每个阶段以一个"可运行的里程碑"为终点:
| 阶段 | 主题 | 里程碑 |
|---|---|---|
| 1 | 最简推理实现 | 单卡 + greedy 输出 100 token |
| 2 | Batch 与 Attention 后端 | 单卡同时跑 16~32 条请求 |
| 3 | 模型层与权重加载 | 直接 load HF 模型(Llama / Qwen) |
| 4 | Scheduler 与连续 Batching | 完整引擎,接近 SGLang 基线吞吐 |
| 5 | CUDA Graph 与 Overlap | decode GPU 利用率拉到 90%+ |
| 6 | Radix Cache | 跨请求 prefix 复用,吞吐 2~10x |
| 7 | Tensor Parallelism | 4 卡跑 Qwen3-32B |
| 8 | 多进程架构与 OpenAI Server | 一行命令启动 OpenAI 兼容服务 |
| 9 | 进阶(MoE、kernel、benchmark) | 对标 SGLang 的能力清单 |
每个阶段末尾建议停下来,通读自己写完的代码,再进入下一阶段。
小结
用一句话回到开篇所立的定义:LLM 推理引擎就是把"prompt → 续写"这件事,包装成一个能并发服务、显存利用率高、延迟可控的系统。它的核心结构有三层:
- 算法层:prefill / decode 两阶段 + KV cache,把生成 N 个 token 的复杂度从 O(N³) 压到 O(N²);
- 调度层:batch、scheduler、paged cache、prefix tree,让多请求高效共享 GPU;
- 架构层:4 类进程 + ZMQ 消息总线,让 CPU、网络、调度互不阻塞。
接下来的每个阶段,都是在把这三层中的某一块"换成完整实现"。
下一篇预告
2 核心数据结构:Req 与 SamplingParams ------下一篇将引入用于表示一条请求的 Req 结构,看它如何用 cached_len / device_len 等几个长度字段同时支撑 prefill 和 decode 两阶段,并理解 greedy 快路径的判定条件。