词向量含义
不要把词看成离散符号,而是映射到一个连续向量里,例如cat -> 0.2, 0.1, 0.01,... m是向量的维度,相似的词应该有相似向。可以这样理解,每个词都有自己的向量,词与词之间的相似性,在向量空间中,以距离近的形式表现出来。
论文理解
1、内容解析
训练集是w1,w2,w3w_1, w_2, w_3w1,w2,w3等这一串单词,这些单词都是词汇表V中,词汇表V很大,但是有限,例如w1=the,w2=cat,w3=isw_1 = the, w_2 = cat, w_3 =isw1=the,w2=cat,w3=is,目标是学习一个函数fff 用于估计 P(wt∣wt−1,...,wt−n+1)P(w_t|w_{t-1}, ..., w_{t-n+1})P(wt∣wt−1,...,wt−n+1),即,给定前面n-1个词,预测当前词出现的概率。模型会预测词汇表中每个词出现的概率,而这些概率之和为1。
论文中提到了整个语言模型理论基础
By the product of these conditional probabilities, one obtains a model of the joint probability of any sequence of words.
通过这些条件概率的乘积,可以得到任意词序列的联合概率模型。
这个是整个语言模型理论基础,因此只要能预测下一个词的概率,就能得到整个句子的概率。
论文中将P(wt∣wt−1,...,wt−n+1)P(w_t|w_{t-1}, ..., w_{t-n+1})P(wt∣wt−1,...,wt−n+1) 拆分为两个部分:
- 将词汇表中的词映射到实数向量空间中,它表示与词汇表中每个词相关的"分布式特征向量"。
- 利用词向量C构造概率函数P(wt∣context)P(w_t|context)P(wt∣context)。每个词都变成了词向量,怎么计算P(wt∣wt−1,...,wt−n+1)P(w_t|w_{t-1}, ..., w_{t-n+1})P(wt∣wt−1,...,wt−n+1)呢,定义一个函数ggg, 输入(C(wt−n,...,C(wt−1))(C(w_{t-n},...,C(w_{t-1}))(C(wt−n,...,C(wt−1)), 即上下文词向量,输出整个词表上的概率分布。
- 举个例子说明下,就是the cat is -> Embedding -> e1,e2,e3 -> MLP ->Vocabulary Softmax -> cat 0.01, dog 0.02, running 0.91, sleeping 0.03
- 数学形式 f(i,wt−1,...,wt−n)=g(i,C(wt1),...,C(wt−n))f(i, w_{t-1},...,w_{t-n}) = g(i,C(w_{t_1}),...,C(w_{t-n}))f(i,wt−1,...,wt−n)=g(i,C(wt1),...,C(wt−n)), g
这个过程可以用论文中的这个图来表示:
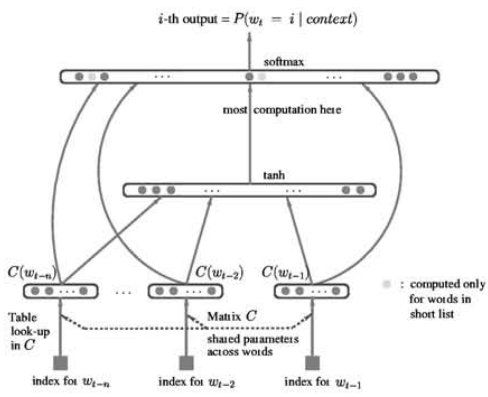
2、论文代码
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class BengioOriginalNNLM(nn.Module):
def __init__(
self,
vocab_size,
embedding_dim=30,
context_size=5,
hidden_dim=100
):
super().__init__()
self.embedding = nn.Embedding(
vocab_size,
embedding_dim
)
D = embedding_dim * context_size
self.H = nn.Linear(
D,
hidden_dim
)
self.U = nn.Linear(
hidden_dim,
vocab_size,
bias=False
)
self.W = nn.Linear(
D,
vocab_size,
bias=True
)
def forward(self, x):
x = self.embedding(x)
x = x.view(
x.size(0),
-1
)
hidden = torch.tanh(
self.H(x)
)
y = self.W(x) + self.U(hidden)
return y例如训练句子:I love deep learning very much
context_size = 3
构造训练样本:
I, love, deep -> learning
love, deep, learning -> very
deep, learning, very -> much
X =
\[I,love,deep\], \[love,deep,learning\], \[deep,learning,very
]
Y =
learning, very, much
3、深入理解
- 为什么可以词向量,因为词与词之间不是完全独立不相关的,如果都是完全独立不相关,那么每个词在向量空间里面都是基向量,但是从我们的认知来说,词cat 和 dog 之间是有联系的,它们具有某种意义的相似性,比如都是人类喜欢养的小动物,因此这两个词出现在很多相同的语言场景中,并且可以交换,很明显,cat 和 lion 这个单词的相似性就没有那么多,共同的语言场景不多。因此,词之间存在潜在连续结构,这种连续的结构,存在于我们的语言结构中,不是cat dog lion 天生带的,是训练数据潜在的关系。
- 上面已经说过了,对词进行向量化后,需要预测P(wt∣context)P(w_t|context)P(wt∣context)这个条件概率,为什么这里用到了MLP,不是因为MLP懂语言,而是MLP是一个强大的函数逼近器,当有足够大的神经网络时可以逼近任意连续函数。
- 为什么这个任务能够逼出有意义的语义空间,真正神奇的不是MLP,而是训练目标,是这个目标产生了语义
- 上面说到MLP是为了逼近条件概率这个函数,但是有一个问题,通用逼近定理说的是,如果MLP足够大,可以逼近任意函数,但是语言的真实条件概率极其复杂,单单几层MLP是不足以去逼近条件概率的,早期的NLP 有时候效果不好。
- 我觉得transformer的成功,就是替换MLP,极大地逼近条件概率P(wt∣wt−1,...,wt−n)