#易语言 #OCR #文字识别 #API接口 #批量识别 #RPA #自动化
💡 说明 :本文API示例以石榴智能OCR接口为例。如需体验,可访问"石榴智能文字识别在线工具"免费测试识别效果,确认满意后再接入API。
易语言调用OCR API实现批量图片文字识别:从接口对接到多文件处理(附完整源码)
一、写在前面
易语言作为国产可视化编程语言,在Windows桌面应用开发、自动化脚本、RPA工具等领域有着广泛的用户基础。很多易语言开发者在做项目时,会遇到这样的需求:
-
批量处理文件夹里的图片,提取其中的文字信息
-
做一个截图OCR工具,按一个键就识别屏幕上的文字
-
把身份证识别、发票识别功能嵌入到已有系统中
这时,一个稳定的OCR API就派上了用场。
本篇文章将带你从零开始,用易语言完成OCR API的完整对接,并实现批量识别文件夹中所有图片的功能。
二、为什么选择OCR API而非本地OCR方案?
在易语言开发中,实现OCR主要有三种方式:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 本地Tesseract | 免费、可离线 | 中文字库依赖、识别率较低、环境配置复杂 |
| 大漠插件找字 | 识别速度快 | 需要做字库、通用性差 |
| OCR API | ✅易接入、✅识别率99%以上、✅支持多种卡证票据、✅毫秒级响应 | 需要联网、API需要付费 |
对于大多数项目和开发场景,OCR API是性价比最高、落地最快的方案。更重要的是,API天然支持批量处理,只需在代码外层套一个循环即可。
📌 还不确定选哪种方案的读者,建议先阅读同系列文章:《在线 OCR 识别 vs OCR API 接口怎么选?》
三、准备工作
3.1 注册获取API凭证
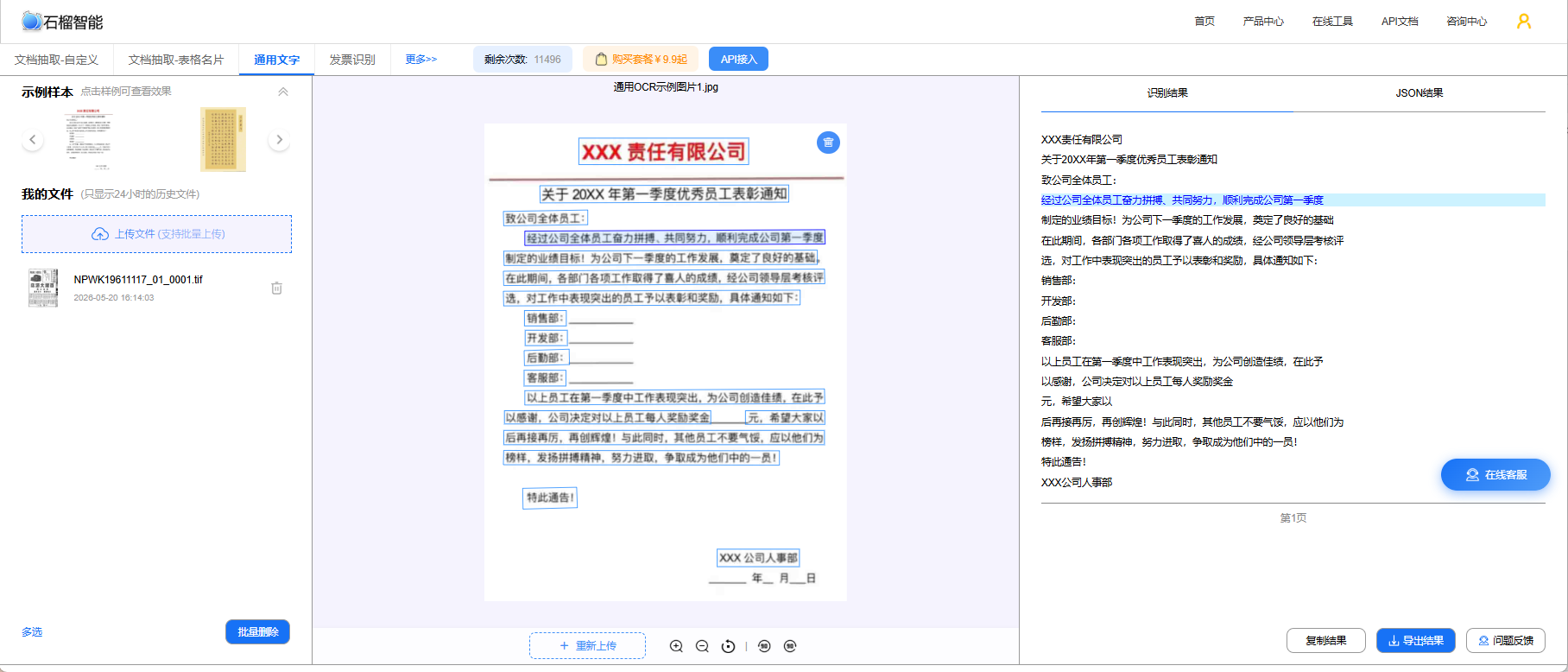
以石榴智能OCR通用文字识别接口为例:
-
访问石榴智能API市场注册账号
-
在后台获取
AppCode(API调用凭证)
首次注册通常赠送免费测试额度,可以先验证效果再决定是否付费接入。支持免费在线体验,API文档清晰,提供多种接入语言示例(如python、js、C#、java、php等),以及自动化脚本语言(如天诺、懒人精灵、按键精灵、易语言、EasyClick、触动精灵等)
3.2 准备精易模块
易语言中推荐使用精易模块 ,它提供了 网页_访问S 和 编码_BASE64编码 等函数,可以极大简化HTTP请求和编码的工作量。下载模块后在易语言中引入即可使用。
四、OCR API接口说明
本文以通用文字识别接口为例(支持中英文混合识别、印刷体):
| 项目 | 说明 |
|---|---|
| 请求方式 | POST |
| 请求头 | Authorization: APPCODE [您的AppCode] Content-Type: application/json |
| 请求参数 | image_base64(图片Base64编码)或 image_url(图片URL)或PDF |
| 返回格式 | JSON |
接口支持批量并发调用,单张图片响应时间通常在毫秒级。
API调用时序参考下图:
📖 如需身份证专用识别接口(自动提取姓名、身份证号等结构化字段),可查阅身份证OCR识别API文档。
五、核心步骤拆解
OCR API调用的完整流程分为4步:
-
读取图片文件:将本地图片读入内存
-
Base64编码:将图片数据转为Base64字符串(API只认这个格式)
-
发送HTTP请求:向API服务器提交JSON格式的请求
-
解析返回结果:从JSON中提取识别到的文字
六、完整代码示例
6.1 单张图片识别
以下是一个完整的易语言OCR识别函数,可直接复制使用:
// ==============================================================================
// 免费在线体验:https://market.shiliuai.com/tools/ocr/general-text
// API文档完整开发文档和代码示例:https://market.shiliuai.com/doc/advanced-general-ocr
// 支持免费在线体验
// API文档清晰,提供多种接入语言示例(如python、js、C#、java、php等),以及自动化脚本语言(如天诺、懒人精灵、按键精灵、易语言、EasyClick、触动精灵等)
// ==============================================================================
版本 2
.支持库 spec
.支持库 dp1
.子程序 通用OCR_简单认证
.局部变量 局_网址, 文本型
.局部变量 局_提交数据, 文本型
.局部变量 局_提交协议头, 文本型
.局部变量 局_结果, 字节集
.局部变量 局_返回, 文本型
.局部变量 图片数据, 字节集
.局部变量 base64图片, 文本型
图片数据 = 读入文件 ("你的文件路径")
base64图片 = 编码_BASE64编码 (图片数据)
局_提交数据 = "{" + #引号 + "file_base64" + #引号 + ":" + #引号 + base64图片 + #引号 + "}"
局_网址 = "https://ocr-api.shiliuai.com/api/advanced_general_ocr/v1"
局_提交协议头 = "Authorization: APPCODE 你的AppCode" + #换行符 + "Content-Type: application/json"
局_结果 = 网页_访问_对象 (局_网址, 1, 局_提交数据, , , 局_提交协议头, , , , , , , , , , , , , )
局_返回 = 到文本 (编码_编码转换对象 (局_结果, , , ))
返回 (局_返回)
API文档完整开发文档和代码示例:https://market.shiliuai.com/doc/advanced-general-ocr
💡 小提示 :建议先用"在线OCR工具"免费测试图片识别效果,确认API能准确识别后再接入代码。
6.2 批量识别(遍历文件夹)
e
.版本 2
.支持库 shell
.子程序 OCR_批量识别文件夹, 整数型
.参数 文件夹路径, 文本型
.参数 请求地址, 文本型
.参数 AppCode, 文本型
.局部变量 局_文件数组, 文本型, , "0"
.局部变量 局_成功数, 整数型
.局部变量 局_失败数, 整数型
.局部变量 局_计次, 整数型
.局部变量 局_文件名, 文本型
.局部变量 局_识别结果, 文本型
.局部变量 局_保存路径, 文本型
' 1. 获取所有图片文件(支持常见图片格式)
局_文件数组 = 文件_枚举 (文件夹路径, "*.jpg;*.jpeg;*.png;*.bmp", , 真, 真)
如果 (取数组成员数 (局_文件数组) = 0)
信息框 ("未找到任何图片文件", 0, , )
返回 (0)
否则
信息框 ("找到 " + 到文本 (取数组成员数 (局_文件数组)) + " 个图片文件,开始识别...", 0, , )
如果结束
' 2. 创建保存结果目录
局_保存路径 = 文件夹路径 + "\OCR_结果\"
创建目录 (局_保存路径)
' 3. 循环识别每张图片
局_成功数 = 0
局_失败数 = 0
计次循环首 (取数组成员数 (局_文件数组), 局_计次)
局_文件名 = 文件_取文件名 (局_文件数组 [局_计次], 真)
调试输出 ("正在识别第 " + 到文本 (局_计次) + " / " + 到文本 (取数组成员数 (局_文件数组)) + " 张:" + 局_文件名)
' 调用单图识别函数
局_识别结果 = OCR_单图识别 (局_文件数组 [局_计次], 请求地址, AppCode)
如果 (取文本左边 (局_识别结果, 4) ≠ "识别失败")
局_成功数 = 局_成功数 + 1
' 将识别结果保存到对应文件
写到文件 (局_保存路径 + 局_文件名 + ".txt", 到字节集 (局_识别结果))
否则
局_失败数 = 局_失败数 + 1
调试输出 ("识别失败:" + 局_识别结果)
如果结束
计次循环尾 ()
信息框 ("批量识别完成!成功:" + 到文本 (局_成功数) + " 张,失败:" + 到文本 (局_失败数) + " 张", 0, , )
返回 (局_成功数)6.3 身份证专用识别(结构化字段提取)
如果你需要识别身份证(自动提取姓名、身份证号、住址等结构化字段),可以使用身份证专用接口,返回格式更规范:
// ==============================================================================
// 免费在线体验:https://market.shiliuai.com/tools/ocr/id-card
// API文档完整开发文档和代码示例:https://market.shiliuai.com/doc/id-card-ocr
// 支持免费在线体验
// API文档清晰,提供多种接入语言示例(如python、js、C#、java、php等),以及自动化脚本语言(如天诺、懒人精灵、按键精灵、易语言、EasyClick、触动精灵等)
// ==============================================================================
版本 2
.支持库 spec
.支持库 dp1
.子程序 身份证OCR识别_核心库版
.局部变量 局_网址, 文本型
.局部变量 局_方式, 整数型
.局部变量 局_提交数据, 文本型
.局部变量 局_提交协议头, 文本型
.局部变量 局_结果, 字节集
.局部变量 局_返回, 文本型
.局部变量 图片数据, 字节集
.局部变量 base64图片, 文本型
图片数据 = 读入文件 ("你的图片路径.jpg")
base64图片 = 编码_BASE64编码 (图片数据)
局_提交数据 = "{" + #引号 + "image_base64" + #引号 + ":" + #引号 + base64图片 + #引号 + "}"
局_网址 = "https://ocr-api.shiliuai.com/api/id_card_ocr/v2"
局_方式 = 1
局_提交协议头 = "Authorization: APPCODE 你的AppCode" + #换行符 + "Content-Type: application/json"
局_结果 = 网页_访问_对象 (局_网址, 局_方式, 局_提交数据, , , 局_提交协议头, , , , , , , , , , , , , )
局_返回 = 到文本 (编码_编码转换对象 (局_结果, , , ))
返回 (局_返回)📖 身份证OCR全字段说明和接入细节,详见:《身份证OCR识别API接入实战》
七、常见问题与避坑指南
❌ 问题1:Base64编码后内容为空
原因:图片路径错误或文件不存在。
解决方法 :调用前用 文件是否存在() 验证图片路径,确认无误后再读取。
❌ 问题2:请求返回 401 Unauthorized
原因:AppCode 配置错误或格式不正确。
解决方法 :确保请求头格式为 Authorization: APPCODE [你的AppCode],注意 APPCODE 后面有一个英文空格,AppCode前后不要有空格。
❌ 问题3:Base64编码过长导致提交失败
原因:大图片Base64编码后字符数太多,超过API限制(≤20MB)。
解决方法:
-
API要求图片<20MB,像素尺寸在15×15到8192×8192之间
-
可以在编码前将图片缩放到合适尺寸,或用
image_url参数上传图片URL代替Base64
❌ 问题4:返回 success=false 或识别不到文字
原因:图片质量差或格式不支持。
解决方法:
-
图片需要清晰、文字可辨认,API对旋转图片会
自动纠偏 -
支持jpg、png、bmp等常见图片格式
-
建议先用在线OCR工具测试图片是否能够成功识别
-
测试时注意确认图片中的文字不要过于潦草,印刷体识别率最高
八、相关文章推荐
本系列其他文章同样值得一看: