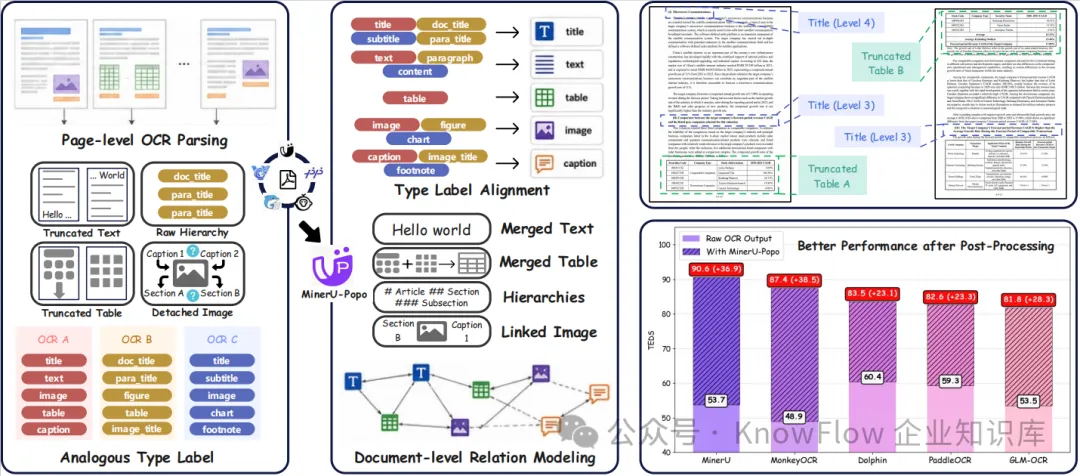
MinerU-Popo
OCR 解决的是"看见文字"的问题。
在文档智能场景里,这一步很重要,但还不够。一个 PDF 被 OCR 之后,通常会得到一组页面级的结果:文本块、标题块、表格块、图片块、坐标、页码,以及一些模型识别出来的版面标签。它们能说明"这一页上有什么",却不一定能说明"整篇文档在讲什么、这些内容之间是什么关系"。
这就是很多 RAG 系统在处理复杂 PDF 时容易遇到的问题。
一份年报里,表格可能从上一页延续到下一页;图的标题在图上方,脚注在下一段下面;目录页能看到章节名称,但正文页里标题层级并不总是稳定;同一节内容可能跨页、跨栏、跨多个文本框。OCR 把这些内容都识别出来了,但文档结构没有自动恢复。
后续进入检索、分块、引用和问答时,系统看到的就不是一篇结构化文档,而是一串被页面切开的内容片段。
MinerU-Popo 关注的正是这个断点:在 OCR/Layout 之后,把页面级解析结果进一步整理成文档级结构。
OCR 的下游缺口
传统 OCR 或版面分析模型通常以页面为基本单位工作。它们擅长回答几个问题:
-
• 这段文字在哪里
-
• 这个区域是不是表格
-
• 这张图的位置是什么
-
• 当前文本块属于标题、正文还是列表
-
• 表格能不能还原成 HTML
但真实文档还有另一层信息:
-
• 哪些标题是一级、二级、三级
-
• 哪些正文属于同一个章节
-
• 当前段落是不是上一页内容的延续
-
• 两个相邻页面上的表格是不是同一张表
-
• 图片、图注、表注、脚注应该挂在哪个章节下
-
• 长章节应该如何拆成可检索的小节点,同时保留父级上下文
这些信息不是单个页面能稳定判断的。它们依赖跨页顺序、标题样式、块之间的相对位置、文本连续性,以及整篇文档的上下文。
如果缺少这一层,RAG 系统会出现一些很具体的问题。
比如用户问"公司在水资源管理上的目标和完成情况是什么",检索可能只命中表格中的一行,却丢掉表格标题和所属章节;用户问"这张图说明了哪项环保措施",系统可能检索到图片说明,却不知道图片属于哪个案例;用户要求引用来源时,只能给出页码,不能给出更接近人类阅读习惯的章节路径。
这类问题不是单纯换一个 embedding 模型就能解决的。因为问题出在文档进入索引之前,结构已经损失了。
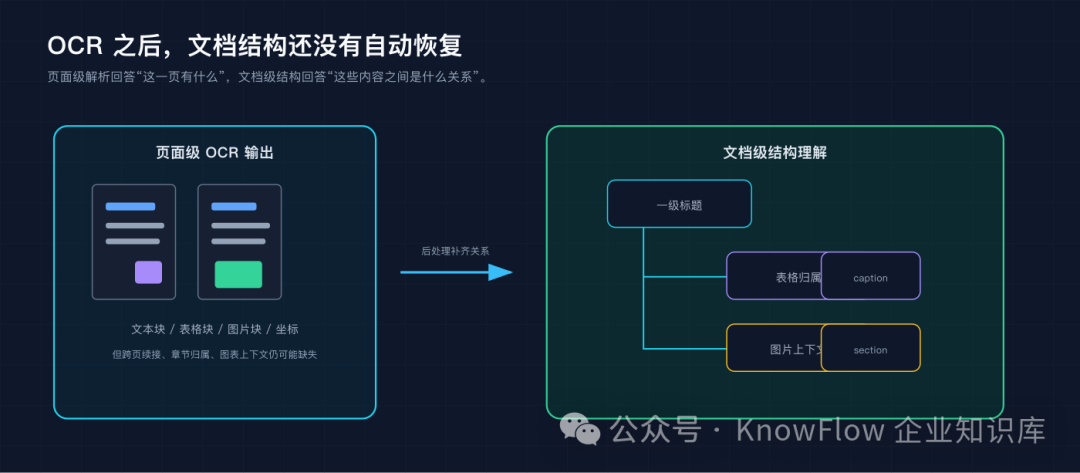
OCR 的下游缺口
MinerU-Popo 做了什么
MinerU-Popo 可以理解为一个 OCR 输出后的结构化后处理框架。它不替代前面的 OCR/Layout 模型,而是读取这些模型已经产生的页面级结果,再补上文档级关系。
从项目实现看,它的主流程可以拆成四类判断。
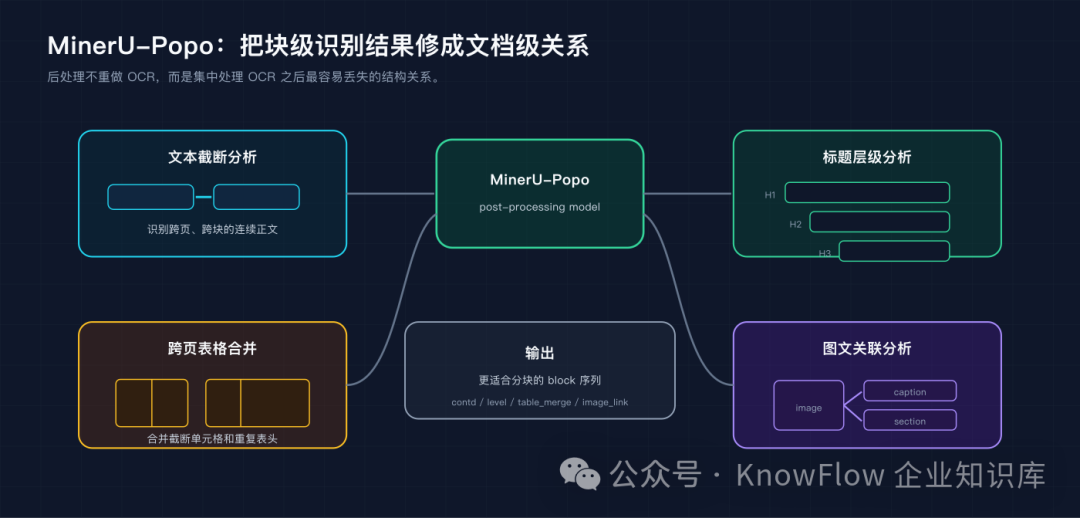
MinerU-Popo 的四类后处理任务
第一类是文本截断分析。
OCR 输出中,正文经常被页面、栏位、图片或版面区域切开。两个相邻文本块在视觉上分开,但语义上可能属于同一句或同一段。MinerU-Popo 会先用规则筛出可能连续的文本对,例如前一个文本块没有完整结束符、后一个文本块不是列表起始项,再交给模型判断是否应该合并。最终在内容里标记出 <|txt_contd|> 和 <|txt_split|>,区分连续和自然分割。
第二类是标题层级分析。
OCR 能识别出"这是标题",但不一定能稳定识别"这是几级标题"。尤其是中文年报、论文、合同、招股书等文档里,标题样式经常混杂:字号、编号、缩进、粗细、页眉样式都会干扰判断。MinerU-Popo 会把候选标题及其页码、坐标、内容组织成输入,判断标题层级,再用栈结构构建章节树。
第三类是图文关联分析。
图片、图注、表注、脚注和正文之间的位置关系很复杂。图注可能在图下方,也可能在上方;表格标题可能和表格隔着一段说明;有些图表还嵌套在大图块里。MinerU-Popo 会把图片、表格、图注、表注、标题等视觉元素统一纳入关联判断,给图表找到对应的标题节点或父级视觉块。
第四类是跨页表格合并。
跨页表格是文档还原里的高频难点。项目里不仅判断相邻页的表格是否应该合并,还会解析 HTML 表格结构,比较表头、行列数、rowspan、colspan,并处理上一页最后一行与下一页第一行可能被截断的情况。合并后的表格不只是把两段 HTML 拼起来,而是尽量保持单元格结构的连续性。
这四类结果最后会进入构树阶段。
构树逻辑并不复杂,但很关键:文本节点按标题层级形成父子关系;表格、图片、图表、印章等特殊元素挂到对应章节;页眉、页脚、页码、旁注等补充信息单独保留;长文本节点还可以拆成 subnode,便于后续分块和索引。
最终得到的不是一段 Markdown,而是一棵带有类型、标题、内容、metadata、location、block_ids、children 的 JSON 文档树。
这棵树才是后续 RAG 更需要的输入。
对 Agentic RAG 的价值:让推理有路径
Agentic RAG 和普通问答式 RAG 的差别,在于它通常不会满足于一次向量检索。它会拆问题、查证据、补上下文、比较来源、做多步推理。
多步推理对文档结构非常敏感。
如果知识库只有扁平 chunk,Agent 能做的事主要是"找相似片段"。但很多问题需要沿结构走。
例如:
-
• 先定位"ESG 管理"
-
• 再进入"利益相关方沟通"
-
• 再读取该小节下的表格
-
• 再把表格内容和后续"管理成效"对照
-
• 最后给出回答和引用
如果文档树存在,这条路径是明确的。每个 chunk 不只是孤立文本,而是知道自己的父章节、兄弟节点、子节点、页码位置,以及关联的图表。
这会带来三个直接变化。
第一,检索可以从"命中文本"升级为"命中节点"。
用户的问题命中一个子节点后,系统可以把父节点标题、上级章节、相邻表格一起带入上下文。这样既不会把上下文拉得过大,也不会只给模型一段残缺内容。
第二,推理可以利用章节路径。
标题层级本身就是文档作者组织信息的方式。一级标题通常表达主题,二级标题表达问题域,三级标题表达措施、指标或案例。Agent 在做问题拆解时,可以把章节路径作为规划线索,而不是完全依赖文本相似度。
第三,证据组织更自然。
回答不只引用"第 17 页",还可以引用"水资源管理目标与完成情况"这一类结构位置。对于企业报告、技术文档、法规制度、招投标文件,这种引用粒度更接近人工审阅习惯。
当前项目里已经有父子分块检索逻辑:子块用于精确召回,父块用于补充回答上下文。MinerU-Popo 输出的文档树,正好可以作为更可靠的父子分块来源。标题节点可以成为父块,正文、表格、图片说明可以成为子块;命中子块后,再回填父章节和相关视觉元素。
这比单纯按 token 长度切分更稳定。
对高保真还原的价值:把文档重新装回去
文档解析的另一个目标是还原。
很多场景并不是只要回答问题,还需要把原文结构尽量完整地保存下来。例如:
-
• 把 PDF 转成可编辑的 Markdown 或 HTML
-
• 在知识库里展示原文目录树
-
• 检索结果中展示表格、图片和上下文
-
• 生成带来源的报告摘要
-
• 对比两个版本文档的章节差异
这些任务都需要高保真的结构信息。
标题层级决定了文档骨架。 没有层级,所有标题只是加粗文本;有了层级,才能恢复目录、章节折叠、段落归属和引用路径。
表格合并决定了数据完整性。 跨页表格如果被拆成两张表,检索和展示都会出错。用户看到的是两段不连续数据,模型看到的也是两个互不相干的 HTML 片段。MinerU-Popo 的跨页合并逻辑可以把表头重复、行列跨度、截断单元格等问题在后处理阶段修正掉。
图片上下文决定了视觉内容能不能被理解。单独保存图片没有太大意义,必须知道它的图注、脚注、所属章节,以及前后正文在讲什么。MinerU-Popo 把图片、图注、表注和章节挂接起来,后续无论是做多模态检索,还是做图文摘要,都有了结构锚点。
这对当前项目里的 OCR 后处理尤其重要。
DeepDOC、MinerU、PaddleOCR 等解析器可以负责把页面内容识别出来;MinerU-Popo 可以作为后处理层,接收统一后的 block 列表,进一步增强文档还原效果。重点增强的不是"识别更多文字",而是:
-
• 标题层级更稳定
-
• 正文跨页续接更准确
-
• 表格跨页合并更完整
-
• 图片、表格、图注、脚注的归属更清楚
-
• 长章节能拆成子节点,但仍保留父级结构
换句话说,OCR 负责把内容从页面里取出来,MinerU-Popo 负责把内容放回文档里。
对 KnowFlow 的借鉴意义
对 KnowFlow 这类产品来说,MinerU-Popo 的意义不在于重做一套 OCR,而是在现有 OCR 结果之后追加一层结构修正。
当前解析链路已经可以产出 middle_json、Markdown、坐标映射和语义块。这里面包含了文档还原所需的大部分原材料:文本内容、layout type、页码、bbox、表格 HTML、图片区域和块顺序。问题在于,这些信息仍然偏页面级,很多关系还没有被稳定地文档化。
因此,比较自然的方案是把 middle_json 作为 MinerU-Popo 的输入来源:先把不同解析器产出的结构归一化为 block schema,再通过 MinerU-Popo 判断标题层级、文本续接、图文关联和跨页表格合并,最后回写为增强后的文档树或增强版 middle_json。
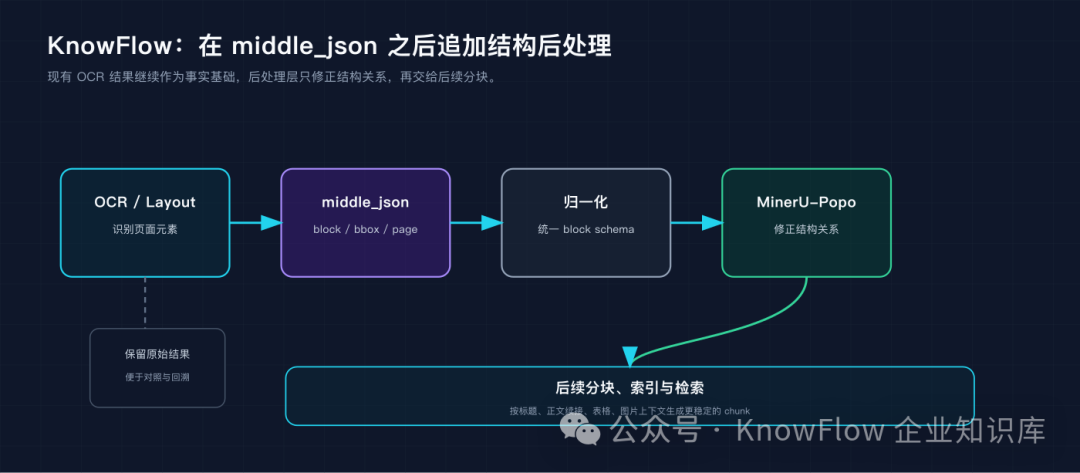
KnowFlow 中的后处理接入位置
这条路线的好处在于边界清楚。
原有 OCR 结果不被废弃,仍然作为事实基础;后处理层只负责修正结构关系。这样可以减少系统改造范围,也便于做灰度验证:同一份文档同时保留原始解析结果和后处理结果,逐项比较标题、表格、图片上下文的变化。
但这里有一个前提:修正结果必须可信。
结构后处理如果判断正确,会显著提升文档解析质量;如果判断错误,也可能把原本正确的 OCR 结果改坏。比如把两个独立表格误合并、把图注挂到错误章节、把三级标题识别成一级标题,都会影响后续检索和展示。
在这个前提成立后,后处理方案才适合进入 KnowFlow 的主解析链路,并稳定改善复杂文档的解析效果。
需要注意的边界
MinerU-Popo 不是万能的文档解析器。
它依赖前置 OCR/Layout 的质量。如果文字识别错误、表格 HTML 本身残缺、图片区域裁剪不准,后处理只能修复一部分结构关系,不能凭空恢复所有内容。
它也会带来额外推理成本。尤其是长文档,需要动态分块、跨块同步和模型调用。实际接入时应该优先处理高价值文档类型,例如年报、论文、合同、制度文件、技术手册、招投标文件,而不是对所有短文本都启用完整后处理。
另外,文档树并不意味着必须抛弃原有 chunk 策略。更合适的做法是让结构树成为 chunk 的来源和约束:该细分时仍然细分,但不要切断标题、表格、图片和正文之间的关系。
结语
OCR 把文档变成可读取的文本,文档结构理解把这些文本重新组织成可使用的知识。
对于 RAG 来说,这一步的价值不在于多识别几个字,而在于减少进入索引前的结构损失。标题层级、跨页续接、表格合并、图文归属,这些看起来像解析细节,实际会影响检索召回、上下文构造、引用定位和多步推理。
MinerU-Popo 提供了一种清晰的后处理思路:保留前置 OCR/Layout 的能力,把模型判断集中用在文档级关系上,再输出可索引、可展示、可溯源的文档树。
从这个角度看,文档解析链路的目标不只是"从 PDF 到文本",而是"从页面识别到结构理解"。这也是复杂文档进入 RAG 之前,最值得补上的一层。