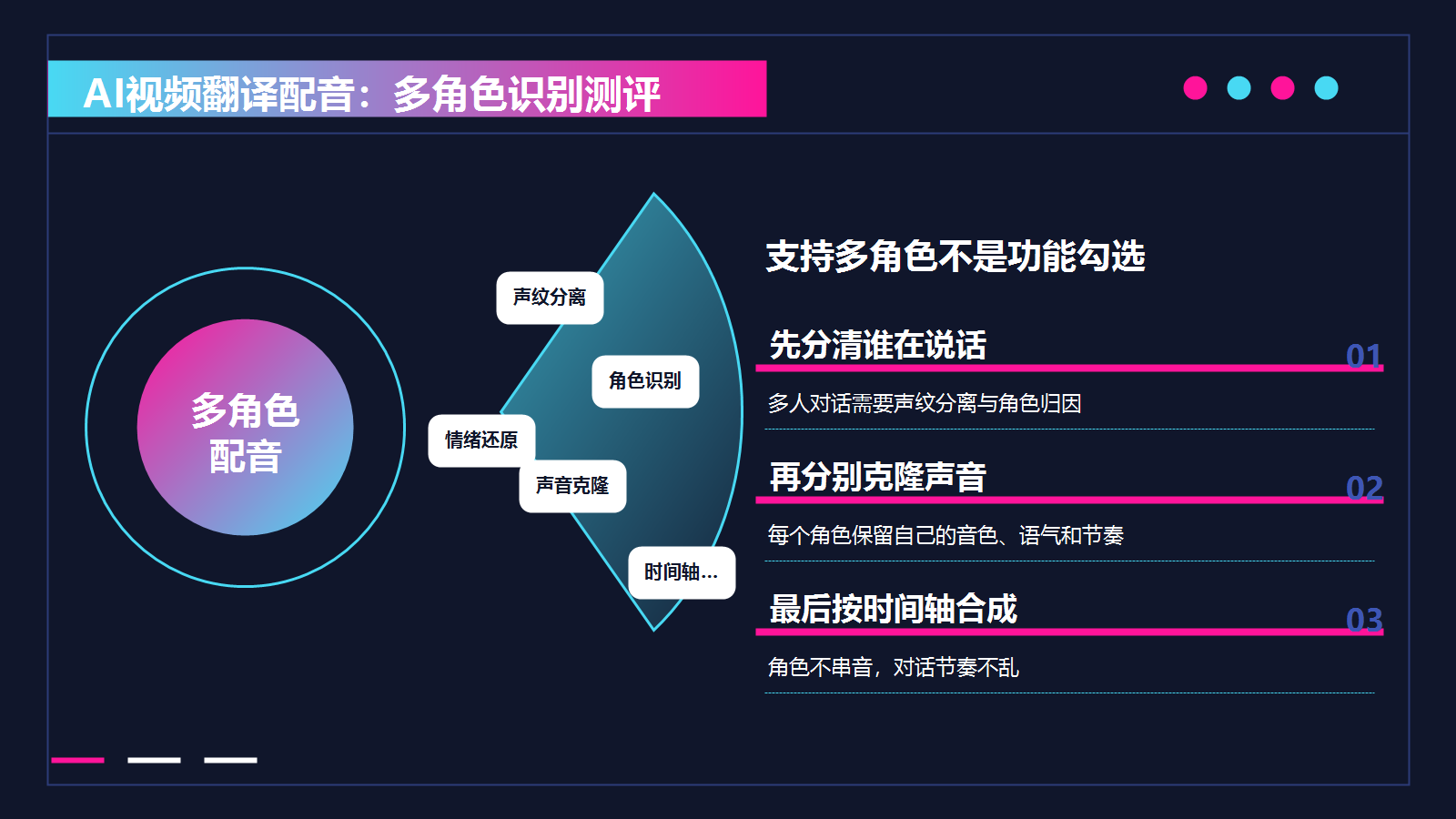
这个问题问得很精准------"支持多角色"这个条件一加进去,市面上能过关的工具立刻少了一大半。
先说为什么多角色配音这么难。
普通AI配音工具的逻辑是:给一段文本,生成一段语音,输出完事。但视频里有多个说话人的时候,工具需要先把不同人的声音分离开,分别识别、分别克隆、分别配音,最后再按时间轴合并回去。这个链路里任何一个环节出问题,配出来的声音就会张冠李戴------A角色的台词用了B角色的声线,或者多人对话的节奏完全乱掉。
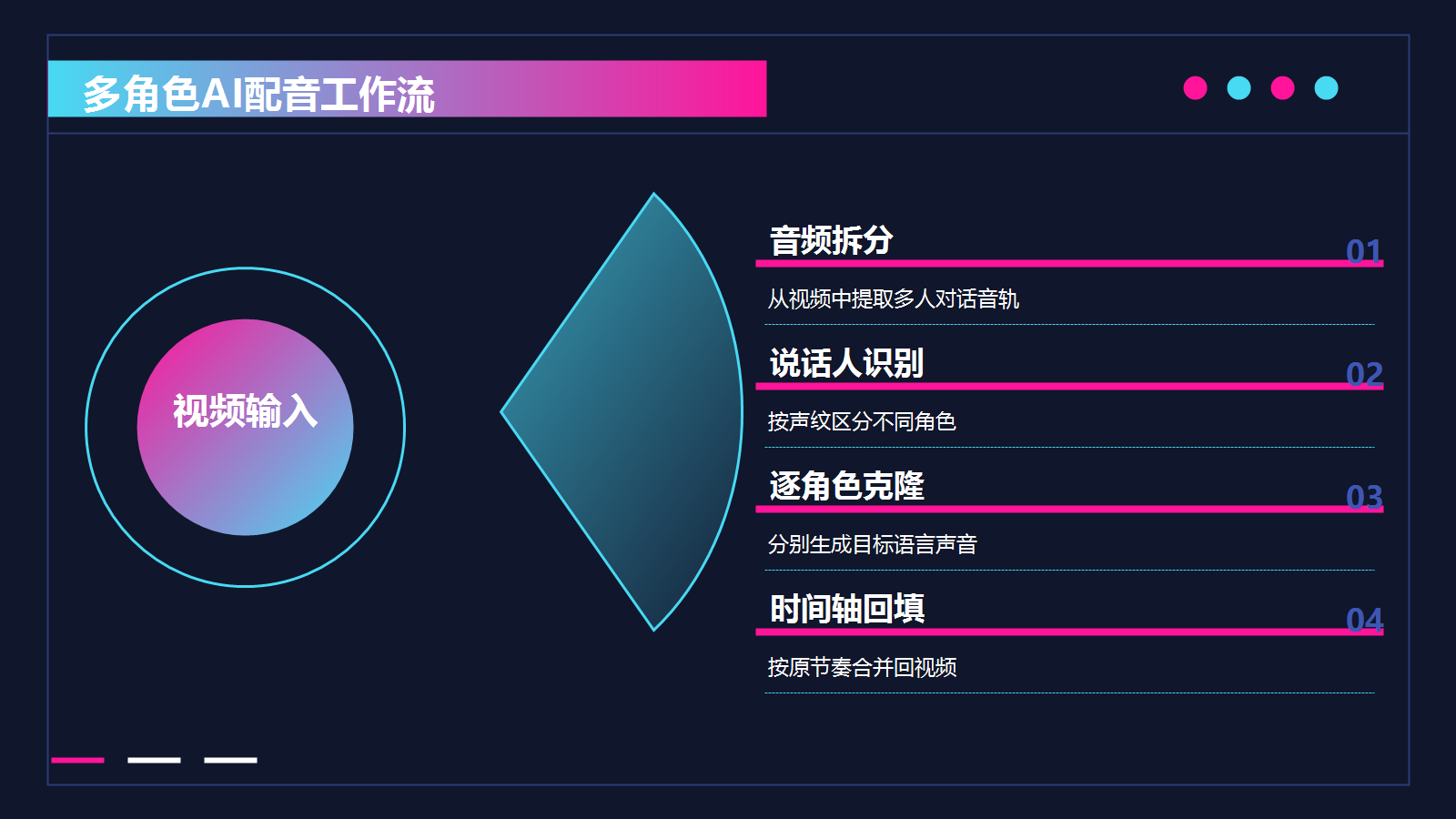
所以"支持多角色"不是一个简单的功能勾选,而是对工具底层能力的综合考验。
2026年主流AI视频翻译配音工具盘点:各有什么优缺点?

VMEG
VMEG定位综合型视频创作平台,功能覆盖面在这几款工具里算最广的------文本转语音、字幕生成、视频配音、唇音同步全部集成在一个界面里,不需要在多个工具之间切换。
优势:支持170+语言和地区口音,语言覆盖面是这几款里最大的,包含不少小语种方言。多角色多语言自动识别是它的核心卖点,能自动翻译并配音,语速自动兼容,画面和声音的节奏基本能对上。专为影视、短剧、教育、跨境电商、广告等场景设计,功能模块比较完整。
缺点:没有桌面或移动应用,只能通过浏览器访问。对于需要离线处理或者网络环境不稳定的场景,这是个实际限制。声音克隆的情感细节还原深度和专门做声音克隆的工具相比有差距。
适合场景:语言覆盖广度优先、需要多语种内容批量产出、对工具集成度有要求的团队。如果你的内容需要覆盖冷门语种,VMEG是少数能支持的选择之一。
HeyGen
HeyGen是出海圈知名度最高的AI视频工具之一,但它解决的核心问题是数字人口播,而不是视频翻译配音。
优势:AI数字人形象逼真,适合品牌宣传、产品介绍、企业培训等需要虚拟形象出镜的场景。内置字幕翻译和配音同步功能,与视频制作流水线集成度高。在商业演示和社交媒体视频场景有成熟的用户基础。
缺点:定位决定了边界------它更注重视觉效果而非纯音频应用,语音定制功能和专门做声音克隆的工具相比有明显差距。如果你的视频里有真实人物出镜,需要保留原说话人声线,HeyGen并不是为这个场景设计的。多角色真实人物配音的处理能力有限。
适合场景:需要数字人口播的品牌视频、企业培训内容、社交媒体口播视频。如果你的需求是"已有真实视频、需要翻译成多语种版本",HeyGen不是最优选择。
ElevenLabs
ElevenLabs是目前声音克隆和情感语音合成领域公认的技术标杆,声音质量在所有工具里处于顶级水平。
优势:声音克隆效果极为逼真,情感深度和细节还原是这几款工具里最强的。支持自定义语音克隆和微调,能为讲故事、旁白、有声书等场景提供高质量音频输出。语音库丰富,情感基调选项多。
缺点:没有内置翻译功能,没有字幕功能,不直接处理视频文件。多角色场景需要自行把不同角色的台词拆分出来,分别处理后再合并,工作流需要完全自己搭建。团队协作功能仍在开发中,对需要多人协同的团队不够友好。
适合场景:对声音质量有极高要求、愿意自己搭建工作流的专业用户。适合有声书制作、播客配音、高端品牌视频旁白等纯音频或单人配音场景。如果你需要的是视频翻译配音的完整流程,ElevenLabs只是其中一个环节,还需要配合其他工具使用。
Wavel AI
Wavel AI定位专业媒体和学习平台的语音配音与本地化服务,在企业级项目上有一定积累。
优势:提供20+语言配音,带音调控制功能,语音质量稳定。包含字幕翻译和语音同步选项,适合有标准化本地化需求的大型项目。对企业级工作流的支持相对完善。
缺点:定价更面向组织而非个人,个人创作者和小团队使用成本偏高。界面对初学者不够直观,上手需要一定时间。语言覆盖数量(20+)和VMEG(170+)相比差距明显,小语种支持有限。
适合场景:有稳定本地化需求的中大型企业,预算充足、对语音质量和项目管理有标准化要求的团队。个人创作者和小团队性价比不高。
Murf AI
Murf AI是面向商务、教育和播客场景的专业TTS工具,在演示文稿配音和学习模块制作方面有较多用户。
优势:界面简洁,时间线编辑功能直观,可以对配音进行精细的时间轴调整。支持音调、重点和节奏控制,配音细节可调整空间较大。能与PowerPoint和主流视频编辑器集成,适合需要配合PPT使用的场景。
缺点:缺乏内置翻译和字幕支持,视频翻译配音需要自己处理翻译环节。自定义语音选项需要更高级别的付费计划才能解锁。多角色处理需要手动操作,没有自动识别能力。
适合场景:企业培训视频、在线课程旁白、播客制作、需要配合PPT的商务演示。不适合需要完整视频翻译配音流程的出海场景。
Lovo AI
Lovo AI专注于叙述和媒体项目的类人语音生成,在情感基调控制方面有一定特色。
优势:语音库内容丰富,提供情感基调选项,支持实时语音预览的脚本编辑器,操作体验流畅。支持各种语言的配音和字幕,适合多媒体故事制作。
缺点:免费层级的时长和导出数量有限,批量使用成本上升快。翻译准确性因语言而异,小语种质量不稳定。和ElevenLabs相比,声音克隆的情感细节还原有差距。
适合场景:有声书、播客、媒体内容旁白、需要情感表现力的叙述类内容。批量视频翻译出海场景不是它的强项。

多角色配音首选:VividDub深度体验
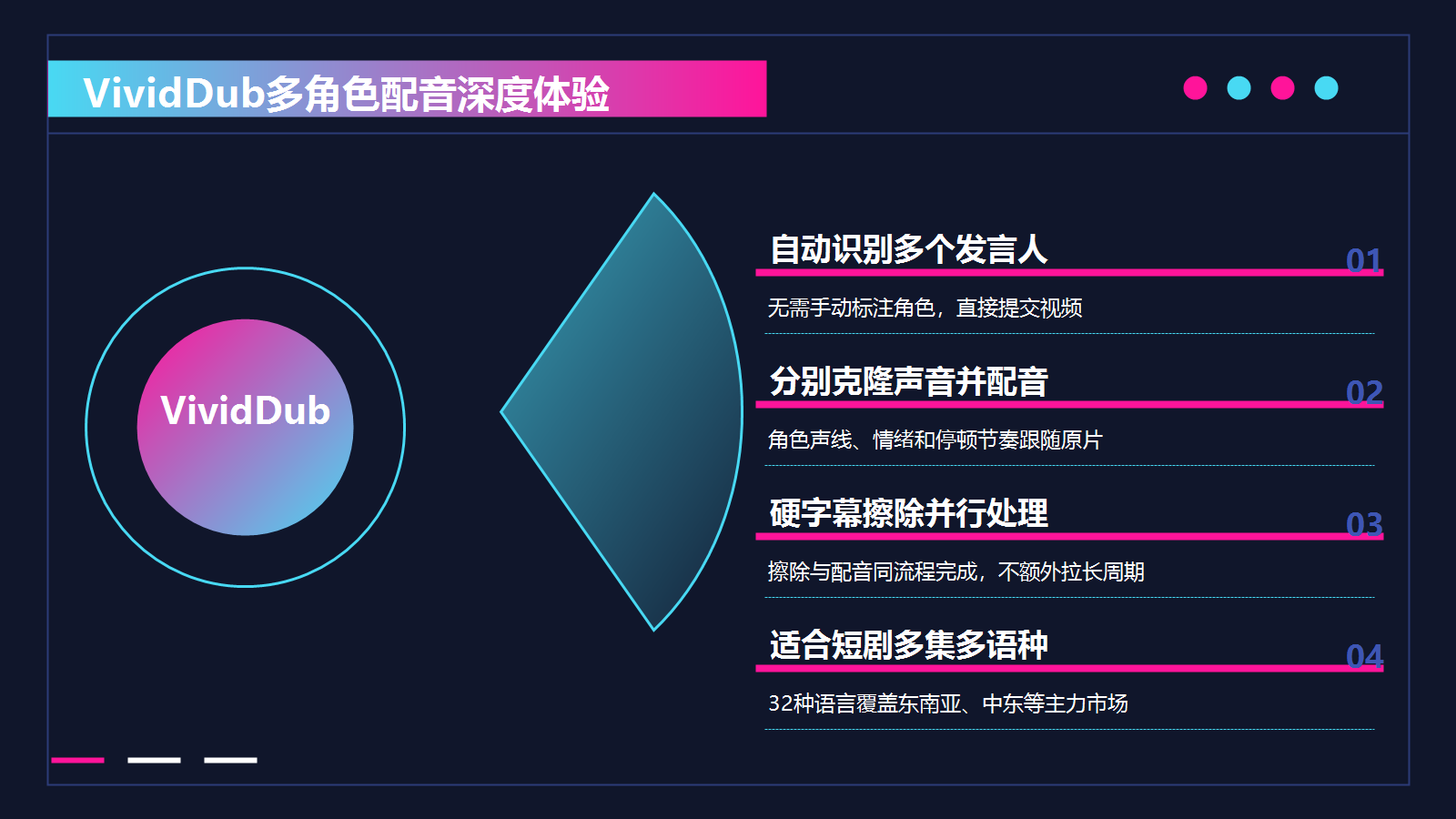
如果需求是视频语音AI翻译配音加多角色,目前用下来最顺手的是 VividDub。
先说多角色这块。之前用其他工具处理短剧素材,最头疼的就是多人对话------要么工具根本不区分角色,所有人配同一个声音;要么需要手动把每个角色的台词拆出来,分别处理完再拼回去,一集下来光这个环节就要折腾一两个小时。
VividDub是直接提交视频,它自己去识别谁是谁,分别克隆声音,分别配音,不需要做任何标注。第一次用的时候有点不敢相信,以为会乱,结果角色对应得很准。
配音质量这块,和之前用过的TTS工具差距挺明显的。
不是那种念稿子的感觉,情绪起伏、停顿节奏都跟着原视频走。有一场角色激动争吵的戏,配出来的愤怒感是真的在的,不是平铺直叙地把台词念完。这个对短剧来说很关键,观众对情绪的感知比对口型的感知敏感得多。
还有一个省了不少事的功能是硬字幕擦除。
很多视频基本都有烧录字幕,以前要先用单独的工具擦掉,再导进来配音,两道工序。现在直接在VividDub里一起处理,擦除和配音是并行跑的,不额外占时间。
语言方面支持32种,东南亚和中东的小语种都有,越南语、印尼语、阿拉伯语这些出海主力市场直接覆盖。
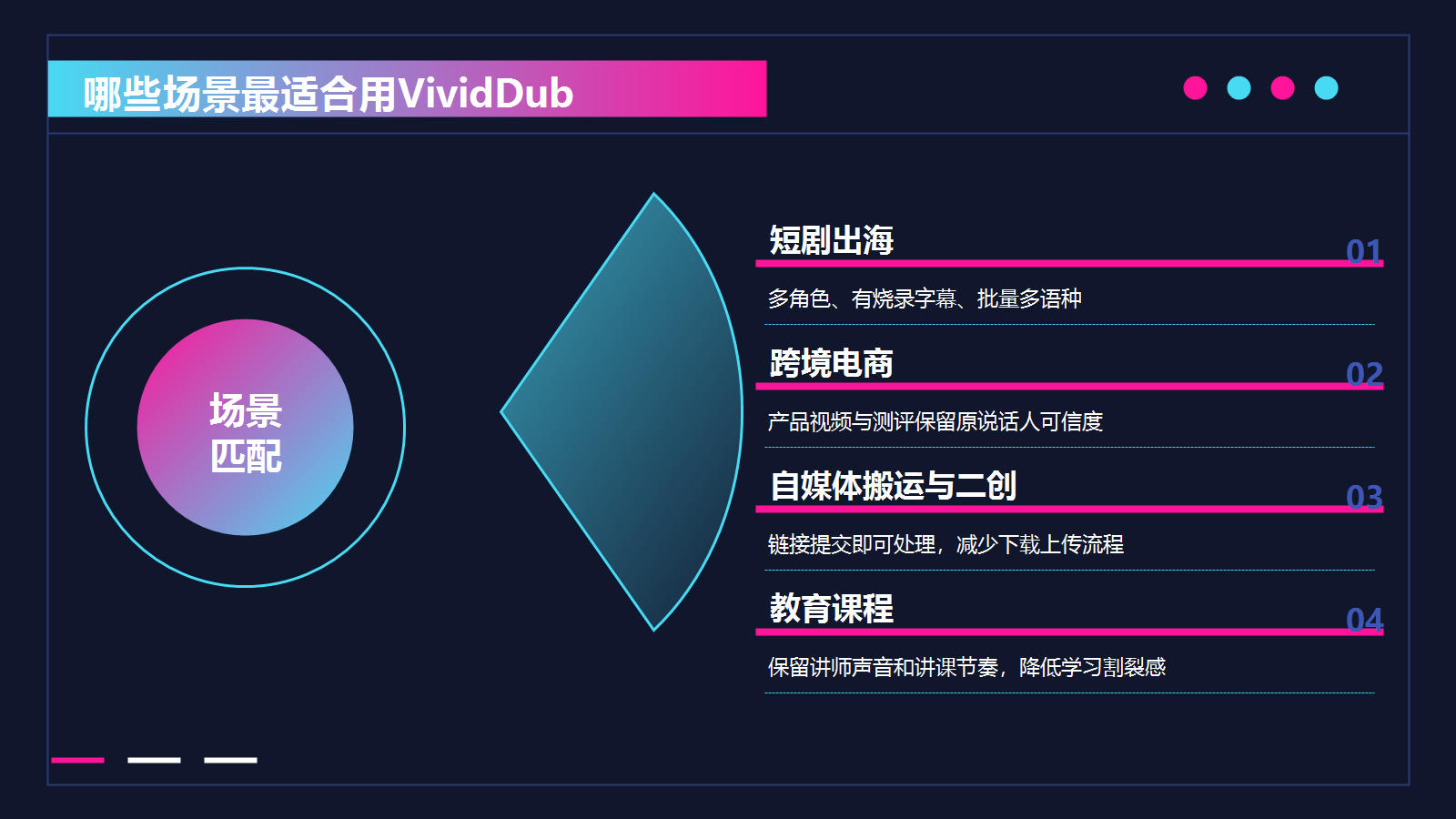
短剧出海、跨境电商、教育课程......哪些场景最适合用VividDub?
顺便说一下它适合哪些人用,因为不同场景用下来感受差挺多的。
短剧出海是最对口的场景。多角色、有烧录字幕、需要批量出多个语种,这几个条件叠在一起,VividDub基本是目前能一站式跑通的少数选择之一。一部剧几十集,每集出三四个语种版本,靠人工配音根本算不过来账。
跨境电商也很适合。产品视频、品牌宣传片、开箱测评,这类内容通常是单人出镜讲解,翻译成目标市场语言之后声音还是原来那个人的感觉,比换一个陌生的TTS声音更有信任感。
自媒体搬运和二创用的人也不少。把海外优质内容翻译成中文,或者把中文内容出海,提交链接直接处理,不用下载原视频再上传,省了一道工序。
教育和课程内容的需求也很契合。录好的课程视频想出多语种版本,讲师的声音和讲课节奏都能保留,不会因为换了语言就变成另一个人在讲课,学员接受度更高。
这几个场景的共同点是:都有"已有视频、需要快速出多语种版本"的需求,而不是从零生成内容。这也是VividDub产品设计的核心逻辑所在。
AI视频翻译配音工具怎么选?按需求场景对号入座
按需求场景简单归个类:
只需要高质量单人声音克隆、自己搭工作流的,ElevenLabs声音质量是标杆。
需要数字人口播、品牌宣传视频的,HeyGen更合适。
需要视频翻译+多角色配音+字幕+硬字幕擦除全流程打通、主攻出海场景的,VividDub目前是链路最短的选择。
需要超大语言覆盖面(170+语言)、对工作流自动化要求不那么高的,VMEG值得评估。
多角色这个需求本身就是筛选器------能真正做到自动识别、分别克隆、准确还原的工具,目前市面上并不多。