热议 Agent 能力升级时,多数人陷入典型表象化认知误区:
把带 3D 数字人形象的基础对话交互 ,等同于具备深度实时认知交互能力 ,忽略 Agent 核心价值是实时认知响应、动态理解、双向共情,外在虚拟形象只是交互载体,而非能力本身。
为 Agent 赋予数字人形象,是打造自然交互的直观形式,但市面上大量 "数字人 Agent",仅实现形象可视化展示,并未搭建完整的实时认知交互链路,本质只是形象化的文字对话工具,并非能实时感知、动态应答、深度共情的具身认知主体。
Agent 认知盲区:表象化设计的认知局限
先说清楚,我不是在无脑黑。传统数字人方案在特定场景下确实有价值。但如果你要的是「实时交互」,那它的问题就暴露无遗了。
盲区一:云端渲染导致认知响应滞后,丧失实时感知能力
绝大多数数字人产品的技术路线是这样的:
用户输入 → 云端处理 → 云端渲染画面 → 结果下发至终端 → 预制式输出整套流程依赖云端集中渲染,并非端侧实时联动认知响应,只能被动执行预设流程,无法根据用户实时反馈动态调整。核心痛点:
-
延迟高:云端渲染 + 网络传输,端到端延迟 2‑5 秒,Agent 思考与应答节奏脱节;
-
不可实时打断:无法承接追问、插话,对话生硬机械;
-
强依赖网络 + 算力成本极高:云端 GPU 算力消耗巨大,弱网环境体验崩盘,规模化落地成本爆炸。
盲区二:认知链路碎片化,Agent 语义与数字人表达割裂
传统方案的另一个问题是技术栈是拼凑的:
ASR(语音识别) → LLM(大模型) → TTS(语音合成) → 渲染(数字人画面)各模块独立调用、API 串联,直接造成三大问题:
-
延迟层层叠加,整体响应难以低于 1 秒;
-
语音、口型、表情动作不同步,Agent 语义无法精准传递;
-
多环节算力叠加,云端渲染成本持续飙升,商用落地性价比极低。
盲区三:混淆形象载体与认知主体,伪交互泛滥
行业普遍将两类产品混为一谈:
-
展示型数字人:侧重形象美观,脚本化单向播报,无真实交互;
-
交互型数字人 Agent:需要实时问答、动态共情、高频服务,适配客服、导购、企业助手等场景。
大量厂商把展示型云端数字人包装成交互 Agent ,导致企业落地后发现:Agent 空有形象,对话僵硬、响应滞后,完全达不到服务标准。根源并非大模型认知能力不足,而是云端渲染的交互链路,锁死了 Agent 的实时交互上限。
市场上传统交互数字人,与魔珐星云具身 Agent存在底层代差:
-
传统云端方案:云端集中渲染,单向输出、延迟卡顿、成本高昂,本质是被动念稿;
-
魔珐星云:自研AI 端渲 + 端侧解算 ,文本、语音、表情、动作全链路实时生成,500ms 毫秒级响应、支持随时打断,真正实现真人式双向认知交互。
一句话总结:传统数字人 Agent 是形象化念稿 ,魔珐星云是可深度共情的具身智能体。
Agent 认知升级:从表象呈现,到端侧实时认知交互
破解行业痛点的核心,不是在云端方案上迭代修补,而是重构底层技术范式。
魔珐星云 摒弃传统云端集中渲染,以端侧实时渲染为核心,打通 Agent 认知 --- 语音 --- 形象全链路,把数字人从单纯的形象载体,升级为具备实时感知、动态应答、深度共情的商用级具身智能 Agent,真正适配线下多场景规模化落地。
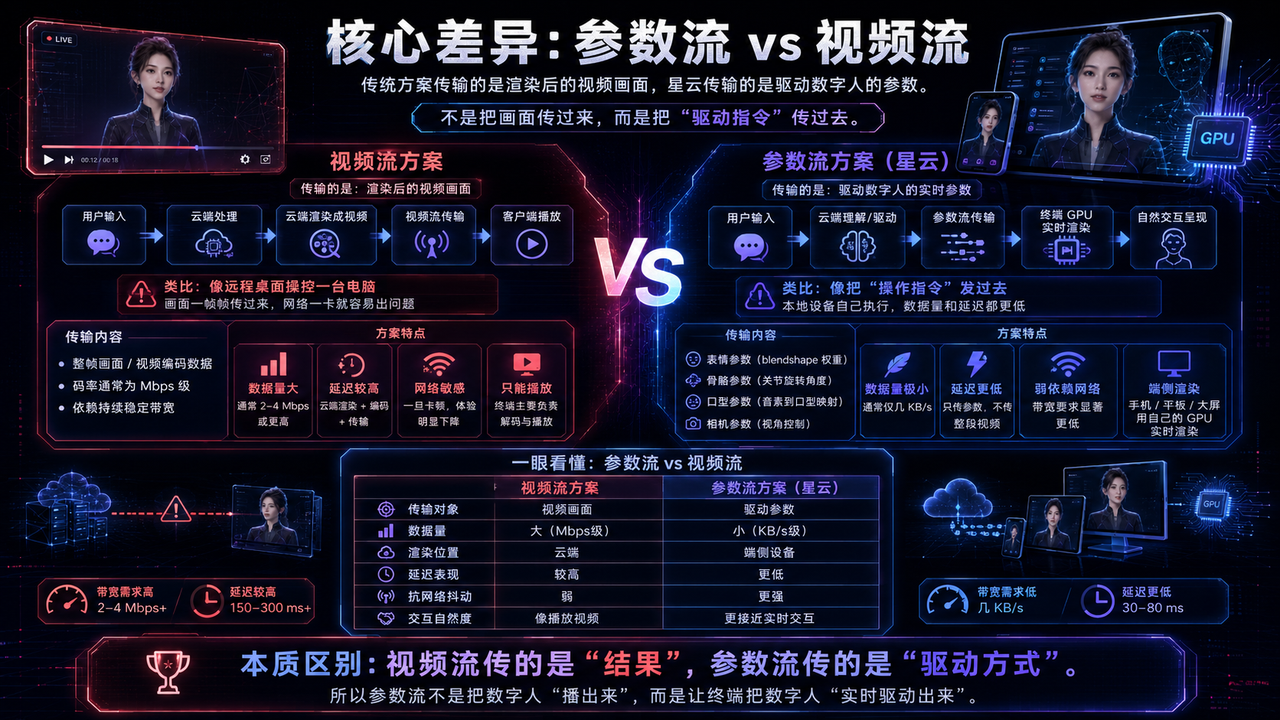
核心差异:AI 端渲与端侧解算 vs 云端集中渲染
传统方案传输的是渲染后的视频画面 ,星云传输的是轻量级驱动指令。
什么意思?打个比方:
-
云端集中渲染方案:相当于你远程桌面操控一台电脑,画面一帧帧传过来,网络一卡就完蛋。
-
AI 端渲与端侧解算方案:相当于你把「操作指令」发过去,本地电脑自己执行。传输的数据量小几个数量级,延迟也低几个数量级。
具体来说,星云的轻量级驱动指令传输的是:
-
表情参数(blendshape 权重)
-
骨骼参数(关节旋转角度)
-
口型参数(音素到口型的映射)
-
相机参数(视角控制)
这些参数的数据量极小(通常只有几 KB/s),而渲染在端侧完成------也就是说,手机、平板、大屏这些终端设备用自己的 GPU 实时渲染。
端到端打通:不是拼积木,是一体化
星云的另一个关键优势是端到端整合。
多模态感知层(ASR + 视觉理解)
↓
大模型 + 智能体认知层(LLM + Agent 编排)
↓
多模态具身表达层(TTS + 表情/动作/口型参数生成)
↓
端侧实时渲染这不是四个独立服务的串联,而是一体化设计。最大的好处在于:
-
TTS 和表情/口型参数是联合生成的,不是先出音频再驱动表情,而是同步产出,口型同步精度从根本上就更高。
-
延迟是系统优化的,不是环节叠加的。从用户说话到数字人回应,全链路可以压到毫秒级,端到端响应约 500ms。
-
Agent 的「思考」和「表达」是一体的。LLM 生成回复的同时就在生成对应的表达参数,不存在「想好了再说」的割裂感。
这种架构让数字人从单向展示的形象变成了「能对话的智能体」。
落地实战:企业级中的数字株洲
光说技术不够直观,我来分享一个实际场景。
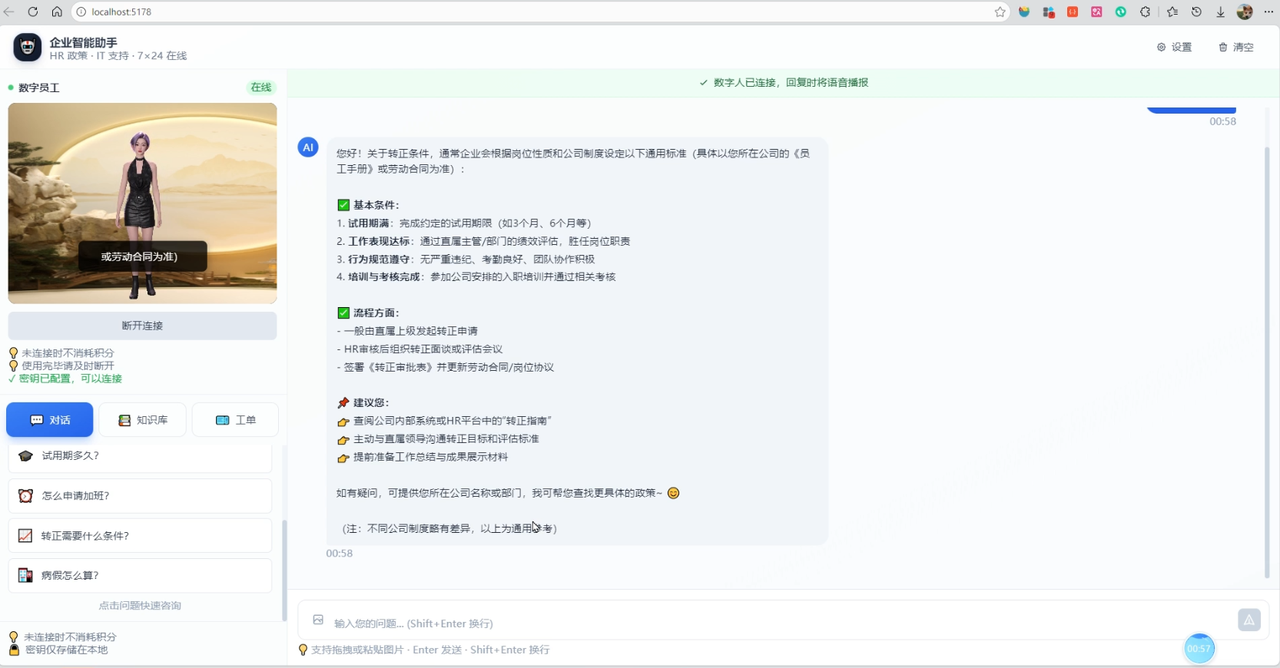
痛点
某银行在网点部署了智能柜员机,原本用平板 + 文字交互的方式引导客户办理业务。问题很明显:
-
老年客户不会用:文字交互界面复杂,字体小,操作步骤多。
-
咨询效率低:客户需要排队等人工柜员解答简单问题("怎么查余额?""跨行转账怎么收手续费?"),浪费人力。
-
体验冷冰冰:纯文字/简单语音的交互方式,客户感受不到「服务」。
方案:接入星云数字人
技术架构:
客户语音输入
↓
星云多模态感知(ASR + 意图识别)
↓
星云 Agent 认知层(金融知识库 + LLM 对话)
↓
星云具身表达层(TTS + 表情/动作参数生成)
↓
端侧 SDK 实时渲染数字人柜员
↓
客户看到数字人微笑着回答:"您的余额是 xxx 元~"以下代码来自本黑客松项目的真实接入(health-assistant 项目),已跑通验证:
// AvatarController.ts - 核心SDK控制器(已跑通)
export class AvatarController {
private sdk: any = null;
// 1. 动态加载星云SDK
private loadSDK(): Promise<void> {
return new Promise((resolve, reject) => {
const script = document.createElement('script');
script.src = 'https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js';
script.onload = () => resolve();
script.onerror = () => reject(new Error('Failed to load SDK'));
document.head.appendChild(script);
});
}
// 2. 创建SDK实例并连接
async connect(): Promise<void> {
await this.loadSDK();
const XmovAvatar = (window as any).XmovAvatar;
this.sdk = new XmovAvatar({
containerId: '#avatar-container',
appId: 'your-app-id',
appSecret: 'your-app-secret',
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
onStateChange: (state: string) => { /* 数字人状态变化 */ },
onVoiceStateChange: (status: string) => { /* 语音开始/结束 */ },
});
await this.sdk.init({
onDownloadProgress: (progress: number) => { /* 下载进度 */ },
onError: (error: any) => { /* 错误处理 */ },
});
}
// 3. 让数字人流式说话(边接收AI回复边说)
async speakRealTimeStream(textStream: AsyncIterable<string>): Promise<void> {
let isFirst = true;
let buffer = '';
for await (const chunk of textStream) {
buffer += chunk;
if (buffer.length >= 15) {
this.sdk.speak(buffer, isFirst, false);
buffer = '';
isFirst = false;
}
}
if (buffer) this.sdk.speak(buffer, isFirst, true);
}
disconnect() { this.sdk?.destroy(); }
}效果
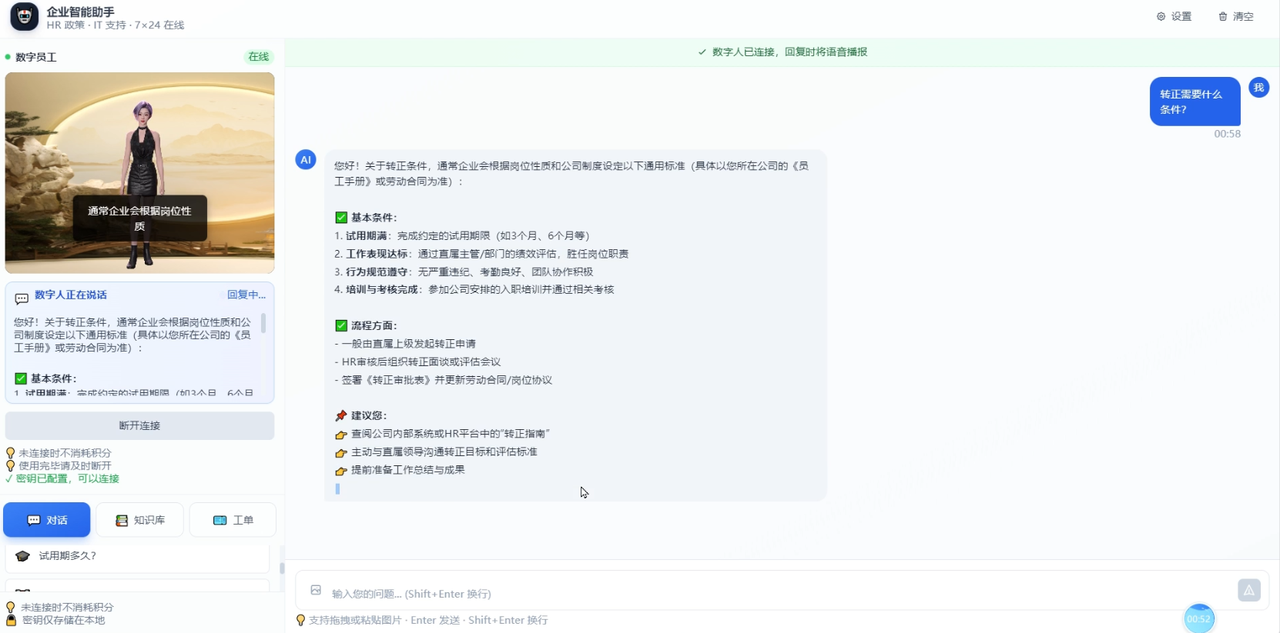
-
响应延迟:从原来文字界面的「无感」到数字人交互的毫秒级响应,客户几乎感受不到等待。
-
端侧渲染:柜员机自带 GPU,AI 端渲方案下渲染完全本地化,不依赖网点网络质量。
-
实时打断:客户可以随时插话、改问题,数字人自然切换话题,不会出现「等它说完」的尴尬。
-
部署成本:不需要云端 GPU 资源为每台柜员机分配渲染算力,AI 端渲方案下云端的计算开销极低。
据该银行反馈,部署数字人柜员后,简单咨询类问题的人工柜员转接率下降了 47% ,老年客户的自助业务办理完成率提升了 35%。
SDK 与 API:开发者视角的接入体验
作为开发者,我最关心的是接入成本。星云在这方面做得不错:
接入方式
星云提供三种接入层级,适配不同需求:
1. 低代码接入(最快上手)
-
通过星云控制台配置数字人形象、Agent 人设、知识库
-
获取嵌入代码,一行 iframe 搞定
-
适合快速验证和简单场景
2. SDK 接入(灵活定制)
-
Web SDK(JavaScript/TypeScript)
-
移动端 SDK(iOS / Android)
-
Unity / Unreal 插件
-
适合需要深度定制的应用
3. API 接入(完全自主)
-
RESTful API:数字人管理、知识库管理等
-
WebSocket API:实时对话通信
-
驱动指令 API:获取裸驱动指令数据,完全自主渲染
-
适合需要极致控制和已有渲染引擎的场景
核心概念
// 星云 SDK 的核心对象模型
const session = await agent.createSession({
mode: 'realtime', // 实时交互模式
input: ['audio', 'text'], // 支持语音和文字输入
output: ['audio', 'param'], // 输出语音和驱动指令
});
// 如果你想自己处理渲染,可以只拿参数
session.on('params', (frame) => {
// frame.blendshapes: 表情参数
// frame.skeleton: 骨骼参数
// frame.lipsync: 口型参数
// 自己的渲染引擎消费这些参数
myRenderer.update(frame);
});这种设计很聪明------你可以选择用星云的渲染管线,也可以只拿驱动指令自己渲染。对于有自研渲染引擎的团队来说,后者的灵活性价值巨大。
写在最后:一次亲身体验
说实话,在体验星云之前,我对「数字人」这个品类是持怀疑态度的。之前接触的数字人产品,无一例外都是「看起来很酷,用起来很蠢」------延迟高、对话假、交互生硬,更像是技术 demo 而非可用的产品。
星云让我改变了这个看法。
真正打动我的不是某个单一技术点,而是「端到端」带来的体验质变。 AI 端渲与端侧解算解决了延迟问题,一体化管线解决了口型同步问题,Agent 认知层解决了对话能力问题------当这些环节不再是拼凑的积木,而是一个整体时,交互体验产生了质的飞跃。
我在测试环境里用星云 SDK 跑了一个简单的客服 Agent,从注册到跑通第一个可交互数字人,不到 2 小时。数字人的表情自然度、口型同步精度、对话响应速度,都远超我之前体验过的同类产品。
如果非要用一句话总结:传统数字人是单向念稿,魔珐星云是真人式对话。
这不是修辞------前者是被动执行预设流程,后者是实时感知与响应。当你的数字人能实时感知你的情绪、即时回应你的问题、自然地打断和切换话题时,它就不再是一个形象展示工具,而是一个真正的具身智能体。
对开发者来说,这可能才是 AI Agent 时代最被低估的基础设施------不只是让 AI 能思考,更要让 AI 能自然地「与人交互」。
魔珐星云在这条路上走了一条不同的技术路线,而且从我的体验来看,这条路是对的。
体验魔珐星云++https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc135++