引言:从一次展厅 Agent 项目谈起
最近接了一个有点意思的项目:某科技馆希望在展厅入口部署一块竖屏,作为 AI 讲解员,接管原本由真人讲解员承担的导览、问答、引路工作。
需求看起来不复杂------LLM、RAG、Function Calling 这些我们都熟。我快速搭了个原型:接入大模型,把展厅的展项介绍文档做成向量库,用户问什么,模型基于检索到的内容回答。命令行下测了几轮,效果挺好,基本可以稳定回答"这个展品什么原理"、"今天哪些展项是亮点"、"洗手间在哪"这种问题。
直到客户问了一句:"那它怎么显示在大屏上?要有个'人'在和观众说话吧?"
这一刻,整个项目卡住了。
我尝试了几种思路:
- 方案一:把 LLM 的输出接到 TTS,加一个静态的卡通头像。结果是观众听到一段平淡的合成语音,看着一张不动的脸------这哪里是 AI 讲解员,这是博物馆的语音导览器,2010 年的产品形态。
- 方案二:接一个市面上的传统交互数字人服务。这类方案的工作模式是先把 LLM 输出的完整回答在云端完成渲染,再下发到终端呈现。问题是用户问完问题要等 5-8 秒才看到数字人开口,而且每段回答都得占用一次云端算力,展厅这种 24 小时在岗的场景成本根本扛不住。
- 方案三:自己用 Unreal 写一个实时渲染的数字人。然后我意识到,我们团队总共两个人,光是把 Live Link 链路调通就够花一个月。
折腾了一周,我得出一个让我自己都有点意外的结论:我们这个行业,把 Agent 的"大脑"做得越来越强,但似乎一直没人认真做它的"身体"。
LLM 越来越聪明,Agent 框架越来越完善,工具调用、多智能体协作、Computer Use 这些方向都在飞速演进。但当 Agent 真的要走出聊天框,以一个"虚拟的人"的形态出现在屏幕上,与用户在物理空间里共处的时候,几乎所有团队都会卡在同一个地方------表达层。
今天我想讨论的就是这件事。是我从这次项目踩坑出发,对 Agent 表达层这个工程问题的完整思考、对端到端参数流架构的技术拆解,以及基于魔珐星云 SDK 落地一个具身智能体的全流程实战。
如果你也在做 Agent,尤其是想把 Agent 部署到任何一块"屏幕"上(展厅、商场、车机、机器人前面板、健身镜......),希望这篇文章对你有用。
一、Agent 技术栈的四层结构与表达层的工程缺位
1.1 重新审视 Agent 的完整架构
回过头看,我之前对 Agent 的理解,其实是有缺失的。
我和大多数开发者一样,把 Agent 默认理解为"LLM + 工具调用 + 一些记忆"。这个理解在 Chatbot 形态下完全够用------用户在聊天框里发消息,Agent 文本回复,顶多调几个工具,世界上一切都很美好。
但当我真的要把 Agent 部署到一块屏幕上、一个机器人身上、一个车机系统里时,这个理解开始崩塌。我意识到一个完整的 Agent 实际上有四层结构:

- 感知层 (Perception):Agent 怎么"看到"和"听到"世界。这一层包含 RAG、多模态输入、Computer Use 的截屏感知、传感器数据接入等。这是 Agent 与环境的输入接口。
- 理解层(Cognition):Agent 怎么"想"。LLM、CoT、ReAct、多 Agent 协作都属于这一层。这是 Agent 的大脑,也是过去两年所有人卷的重点。
- 执行层(Action):Agent 怎么"做事"。Function Calling、Tool Use、MCP 协议是这一层的代表。2025 年下半年到 2026 年,这是 Agent 赛道最火的方向。
- 表达层(Expression):Agent 怎么"呈现自己"。它是怎么"说"的,怎么"看起来"的,怎么和用户在同一个物理空间里共处的。
1.2 行业关注度严重不均衡
如果你打开 arXiv、GitHub Trending、各大技术社区的 Agent 相关内容,会发现一个特别明显的不均衡:
- 感知层:RAG 的优化方法层出不穷,从 GraphRAG 到 Agentic RAG,论文每周都在刷新
- 理解层:LLM、推理模型、多 Agent 协作框架,这是绝对的 C 位
- 执行层:MCP 协议在 2025 年下半年彻底引爆了 Agent 工具生态
- 表达层:几乎没有声音
我做了个粗略的统计,GitHub 上以 "agent" 为关键词的高 star 项目,前 50 个里讨论"Agent 怎么说话"、"Agent 怎么呈现自己"的,占比不到 5%。绝大多数 Agent 项目对"表达"的处理,就是 print(response) 或者最多接一个 TTS。
这不是个 bug,这是行业的盲点。
1.3 为什么 Chatbot 时代不需要表达层
之前没问题,是因为 Chatbot 形态把表达层"省略"了。
聊天框这个交互形态,本身就是一个低保真的表达层------文本就是表达的全部。用户对 ChatGPT 没有"它应该长什么样"的期待,因为它就是一个网页里的对话气泡。表达层被简化到极致,因此可以忽略。
但当 Agent 需要走出聊天框,出现在以下任何一种形态里:
- 展厅大屏上的虚拟讲解员
- 商场入口的 AI 导购
- 4S 店里的车机助手
- 银行网点的智能柜员
- 医院的导诊机器人
- 机器人前面板上的"脸"
------这些场景里,表达层不再是可选项,它成了 Agent 能否落地的决定性因素。
观众不会和一段没有形象的文字对话。商场顾客不会向一个静态头像问路。患者不会信任一个机械合成音的导诊系统。对于 C 端用户来说,Agent 没有"身体",就等于不存在。
1.4 当下行业动态印证了这个判断
回看 2025 年下半年到 2026 年的几个标志性事件:
- Claude 的 Computer Use 让 Agent 学会了"看屏幕",感知层进入新阶段
- Manus 引爆了通用 Agent 概念,推理层和执行层的拼接开始大众化
- MCP 协议在多个主流 IDE 和工具中落地,执行层基础设施成熟
- 各家智能终端厂商(车机、家电、机器人)都在喊"AI 化"
但仔细看这些产品形态,会发现一个共同点:它们的"AI"还停留在"会回答问题"的阶段,几乎没有一个产品在表达层做到了让用户产生"在和一个数字生命对话"的感觉。
这是一个真实存在的真空地带。也是一个真实存在的工程机会。
二、传统表达层方案的技术瓶颈分析
在选型阶段,我把市面上所有看起来沾边的方案都过了一遍。最后发现,目前业内做 Agent 表达层的主流路径,本质上只有三种,每一种都有难以绕过的硬伤。
2.1 路径一:文本 + TTS + 静态头像
这是最常见的方案,也是大部分 Agent 项目的默认配置。
架构很简单:LLM 输出文本 → 调用 TTS 服务合成音频 → 前端播放音频,配一张静态头像或简单动效。
它的硬伤在延迟的串行累加。我做过一组实测,用一个标准的"用户提问 → Agent 回答"流程:
|------------------|--------------|
| 阶段 | 典型耗时 |
| LLM 首 token 时延 | 400-800ms |
| LLM 完整回答生成(50 字) | 1-2s |
| TTS 整句合成 | 800ms-1.5s |
| 音频传输与首帧播放 | 200ms |
| 端到端首响应延迟 | 2.4-4.5s |
这个延迟在聊天框里能接受,因为用户预期就是"等一下"。但在屏幕前真人对话的场景下,3 秒以上的等待会让用户彻底出戏------观众会以为系统卡了,会重复提问,会走开。
更要命的是,即便你用流式 TTS,把延迟压到 1.5s 以内,口型对不上仍然是个问题。TTS 输出的音频和静态头像之间没有任何关联,头像不会"动嘴"。这种割裂感比延迟更让人难受。
2.2 路径二:预录视频数字人
这一类方案在 2023-2024 年特别火,也是很多客户最先想到的方案。
工作模式是:LLM 输出完整文本 → 服务端用文本驱动一个预训练的"数字人模型" → 合成一段口型对齐的视频 → 推到前端播放。
它解决了口型问题,但引入了三个新问题:
第一是实时性丧失。视频合成必须等 LLM 输出完整内容,无法做流式响应。用户问完问题,要等 LLM 生成 + 视频合成两个阶段串行完成,首响应延迟普遍在 5-10 秒。
第二是合成成本。每一段回答都要调用一次视频合成,而视频合成本质上是一次端到端的深度学习推理,GPU 占用极高。展厅这种 24 小时在岗的场景,如果每天 1000 次问答,云端算力账单是天文数字。
第三是并发瓶颈。视频合成无法做高并发------每路并发都要独占 GPU。如果一个连锁品牌想在全国 1000 家门店部署,这个方案在架构上就走不通。
视频数字人本质上是"录播"思维,它把一个本应是实时交互的过程,降级成了"生成视频再播放"。这与 Agent 实时对话的需求是背道而驰的。
2.3 路径三:云端实时渲染
这是最"重"的方案,主要由几家做实时 3D 渲染的厂商推动。
工作模式是:云端跑一个实时渲染引擎(通常是 UE 或 Unity),LLM 输出驱动 3D 角色实时表演,然后把渲染结果作为视频流推到端侧。
它的好处是真正实现了"边说边动",理论上口型、表情、肢体都能做到自然。但它的问题在于:
第一,视频流传输本身就是延迟和带宽的双重瓶颈。无论是 RTMP 还是 WebRTC,从云端编码、网络传输到端侧解码,这条链路至少叠加 200-500ms 的延迟,而且对带宽极不友好。展厅 4K 屏部署一路 60fps 视频流,带宽占用相当可观。
第二,云端 GPU 成本不可接受。每一路实时渲染都要独占至少一张消费级 GPU。如果要部署 1000 块屏幕,云端就需要 1000 张 GPU 持续运行------这个 TCO 完全不具备商业可行性。
第三,弱网或网络抖动时直接失效。视频流对网络状况极度敏感,一旦带宽不够,立刻出现卡顿、花屏、马赛克。展厅、商场这些场景的 WiFi 环境,经常是不可控的。
2.4 表达层的"不可能三角"
把这三种路径放在一起看,你会发现一个有意思的现象------表达层存在一个工程上的不可能三角:
低延迟
/\
/ \
/ \
/ \
/________\
高质量 低成本- 文本 + TTS:低成本 ,但质量低(无口型)
- 预录视频:高质量 ,但延迟高 + 成本高
- 云端实时渲染:高质量 + 低延迟 ,但成本极高
任何一个方案,最多能取其中两项。这不是产品力的问题,是架构设计的问题------这条链路一直被设计成一条串行的"内容生产管线",而不是一条可并行的"信号驱动通路"。
2.5 这是架构问题,不是模型问题
我必须强调这一点,因为很多人会把表达层做不好的原因,归结于"模型不够好"或者"算力不够强"。
不是的。
把 GPT-5、Sora、最强的 TTS 全部塞进上面任何一种方案里,问题依然存在。因为问题不在节点上,在节点之间的数据形态 和串行结构上:
- 视频帧作为传输介质,天然意味着大带宽和编解码延迟
- 串行的 "LLM → TTS → 渲染" 管线,意味着每一步必须等上一步完成
- 表达内容作为已合成的像素,意味着无法做细粒度的实时控制
要解决这些问题,必须从架构层面重新设计------这就是参数流架构要解决的事情。
三、端到端参数流架构:魔珐星云的工程选型分析
在做完上面的方案对比后,我开始系统性地调研业内有没有团队在架构层面尝试破局。这个过程中,我注意到魔珐科技的星云在工程选型上做了一个有意思的选择------端到端的参数流架构。
下面我会从开发者视角拆解这个架构,重点不是介绍这个产品,而是分析"为什么这条路能走通"。
3.1 三层架构的整体设计
魔珐星云对外宣称的是一个"感知---理解---表达"的三层架构。从工程视角看,这三层的关键不在于"分了三层",而在于把"表达层"作为一个独立的基础设施抽出来。
这个设计选择本身就有意思。在传统数字人方案里,"表达"是被切碎塞在管线各处的------TTS 厂商管音频,渲染厂商管画面,Agent 厂商管文本,没有人统一负责"Agent 怎么呈现自己"。
而星云的做法是:把表达层从感知层、理解层中解耦出来,作为一个独立的模块,接收来自任意 LLM 或 Agent 框架的输入,统一负责"把内容变成可感知的具身表达"。
这个解耦带来的直接好处是:开发者可以自由选择 LLM、自由设计 Agent 逻辑,只需要把最终输出对接到表达层 SDK 即可。这对于已经有自己 Agent 技术栈的团队尤其友好。
3.2 参数流 vs 视频流:数据形态的根本差异
参数流架构最核心的工程选择,是把"传什么"从"视频帧"换成"驱动参数"。
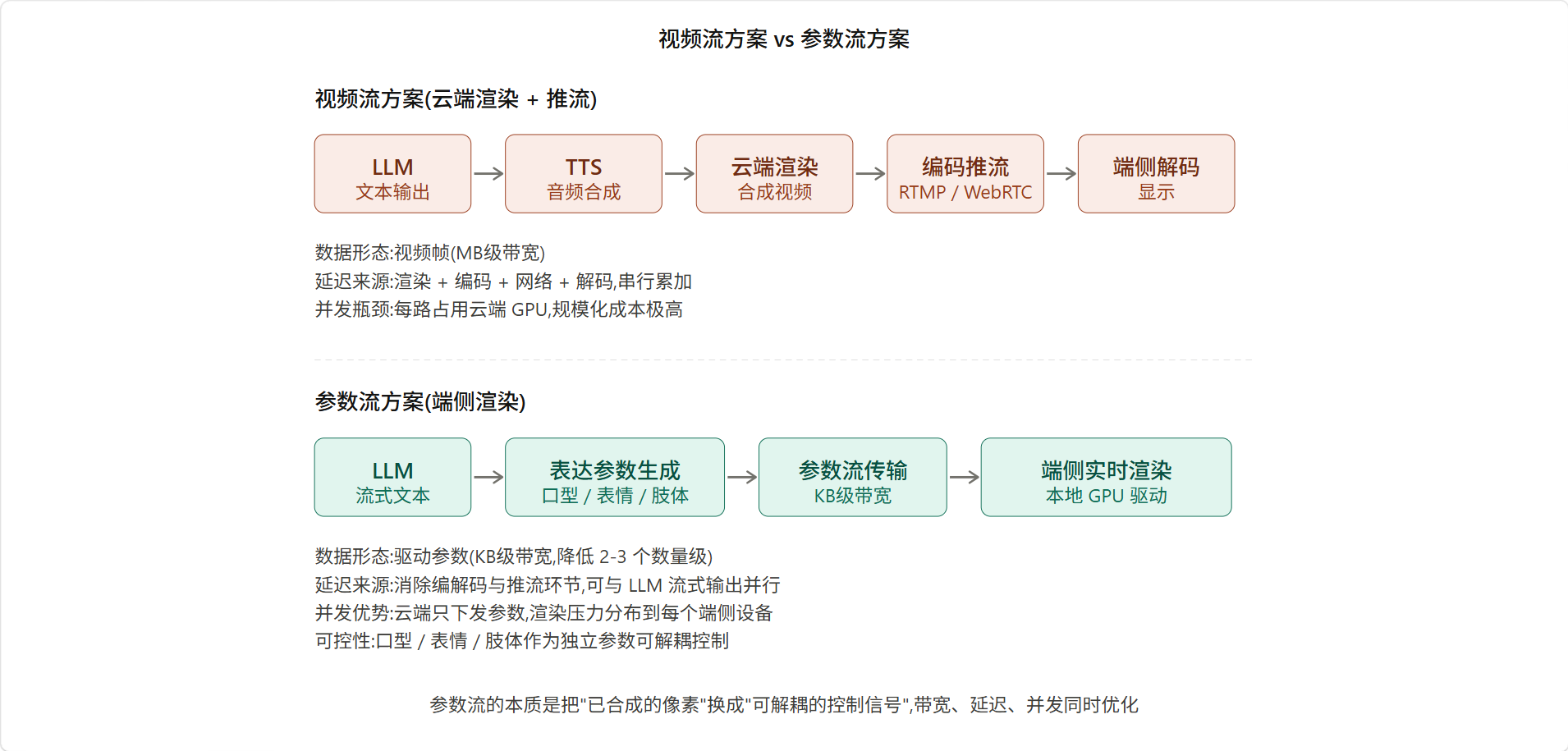
这个变化乍看不起眼,实际上彻底改变了整条链路的工程特性。我们逐项对比:
带宽:视频流要传输每一帧的像素数据,即便高效编码后,1080p 30fps 也要 2-4Mbps。参数流传的是骨骼/表情/口型的浮点数参数,数据量在 KB 级别------比视频流低 2-3 个数量级。
延迟构成 :视频流的延迟链路是"渲染 → 编码 → 传输 → 解码 → 显示";参数流是"参数生成 → 传输 → 端侧渲染 → 显示"。参数流消除了编解码这个最重的环节,而且因为数据量小,传输延迟也大幅降低。
并发能力:视频流的瓶颈在云端 GPU(每路独占),参数流的瓶颈在云端的参数生成(纯 CPU/小模型推理)和端侧 GPU(分布式)。同样的云端资源,参数流能撑的并发数是视频流的几十倍。
可控性:视频流是"已合成的像素",到了端侧只能播放,无法二次控制。参数流是"独立可解耦的控制信号",到了端侧仍然可以叠加二次控制------比如根据观众位置调整视线方向、根据时间调整光照、根据品牌调整服装。
3.3 端侧渲染:把压力从云端转移到终端
参数流架构能成立的前提,是端侧具备实时渲染的能力。
这件事在 2020 年之前是不成立的------那时消费级芯片的 GPU 性能不足以实时渲染高质量的数字人。但到了 2025-2026 年,情况已经完全变了:
- 主流商显屏幕的内置 SoC,GPU 性能已经能跑 1080p 30fps 的实时数字人渲染
- 国产芯片(瑞芯微、全志、晶晨等)百元级方案就能支撑端侧渲染
- 移动端芯片(高通、联发科)的中端型号也完全够用
这意味着我们终于可以做一件之前做不到的事情:让云端只负责"想"和"发参数",让每一台终端自己负责"演"。
这种架构的工程价值是:云端成本从" GPU × 路数"变成"小模型推理 × 路数",对大规模部署是质变性的优化。如果是 1000 块屏幕的连锁部署,云端 GPU 成本基本可以从天文数字降到一个普通服务器的水平。
3.4 表达参数的解耦:为什么"边说边动"成为可能
参数流的另一个关键设计,是把表达内容拆成独立的参数维度:
- 口型参数:由 LLM 输出的文本/音素直接驱动,与音频严格同步
- 表情参数:由情绪标记或文本语义驱动,可独立控制
- 肢体参数:由动作意图或预设动作库驱动
- 视线参数:可由感知层(摄像头检测观众位置)实时驱动
这些参数在端侧独立合成最终的渲染结果。它的好处是:
第一,流式驱动成为可能。LLM 出一个 token,口型参数就生成一段,端侧立刻就能渲染。不需要等整句话完成,首响应延迟可以压到 1.5s 以内。
第二,多源驱动可以并发。当 LLM 还在说话(口型/表情),感知层可以同时驱动视线(看向新走来的观众),动作模块可以触发指向手势------这三套参数互不阻塞。
第三,扩展性强。如果未来要增加新的表达维度(比如配合 AR 眼镜的空间感知),只需要新增一路参数,不需要重构整条管线。
3.5 不可能三角的破解逻辑
回看上一章提到的"低延迟、高质量、低成本"不可能三角,参数流架构破解它的方式很清楚:
|--------|------------------------------|
| 维度 | 破解逻辑 |
| 低延迟 | 参数流低带宽 + 端侧并行渲染,消除编解码与推流瓶颈 |
| 高质量 | 端侧实时渲染保证表情/口型/肢体细节,参数解耦保证可控性 |
| 低成本 | 云端只发参数,端侧分摊渲染压力,避免云端 GPU 堆叠 |
这个架构选择,本质上是用现代消费芯片的 GPU 性能,换云端规模化部署的成本。这条路在 2020 年是走不通的(端侧算力不够),在 2025-2026 年是刚刚开始走通(端侧算力刚刚够)。
魔珐星云在这个时间点把这套架构做出来,从工程节奏上看是对的。
理论分析到这里就够了。下一章进入实战------我们用魔珐星云 SDK 把这个展厅 Agent 真正搭起来。
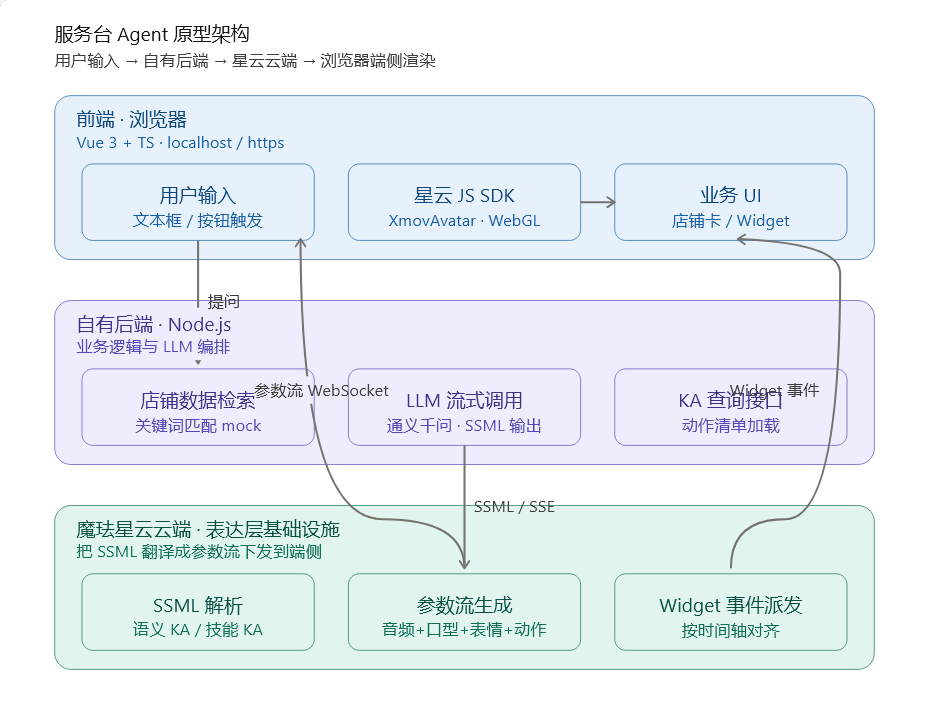
四、基于魔珐星云 JS SDK 的服务台 Agent 实战
展厅项目踩完坑、形成方法论之后,我又接了一个新项目------某商业地产方想在他们旗下购物中心的中央服务台部署一块竖屏,做"AI 服务员"。能力要求不复杂:问路引导(品牌店铺、洗手间、出入口)、活动咨询(当前在做的促销、会员日)、餐饮推荐(根据顾客描述推荐楼层和店家)。
这个项目我现在还在搭原型阶段------客户还没拍板部署形态,我也在等他们最终选屏。但表达层这条主链路必须先用原型跑通,才能拿去和客户谈。这一章我就把这个原型的搭建过程完整还原一遍:技术选型怎么定、平台后台怎么配、SDK 怎么接、流式驱动怎么写、踩了哪些坑、最后跑出来的体感如何。
4.1 原型范围与技术选型
要先把原型范围限定清楚------这个阶段不追求覆盖所有功能,只验证"表达层这条主链路能不能稳定跑通"。所以我把原型砍到最小可验证集合:
- ✅ 数字人能初始化、显示、待机、说话(SDK 主流程)
- ✅ 接 LLM 流式输出,数字人能边收边说(流式驱动)
- ✅ 数字人说话时配合表情和动作(KA 指令系统)
- ✅ 讲到具体店铺时,屏幕侧边弹出店铺信息卡(Widget 事件)
- ✅ 一轮完整问答闭环(状态机)
砍掉的:ASR 语音输入(用文本框替代)、知识库检索(店铺数据用 mock)、生产部署相关(预热、监控、容灾)。这些都放到第五章作为"下一步要做的事"讨论。
为什么选 Web 端而不是 Android
我最早其实想过 Android,因为商显屏内置 Android 系统是行业默认。但翻了一遍官方文档之后改了主意:
第一,官方提供了完整的 JS SDK Demo 工程(Vue 3 + TypeScript + Vite),拉下来 pnpm i && pnpm run dev 就能跑,迭代周期极短。原型阶段"能不能快速验证"比"是不是最优部署"重要得多。
第二,主流商显屏的内置 SoC 普遍能跑现代 Chromium,即便最终部署形态是商显屏,直接全屏 Chrome 启动 Web 应用也是一条可走的路径。
第三,官方 JS SDK 文档明确写出了浏览器版本要求、硬件加速参数、错误码体系、 兼容性测试 矩阵------这种文档完备度本身就在告诉你哪条路是被踩熟的。Android SDK 文档目前只覆盖 RK3588/RK3566 几款主控,适配面更窄,先在 Web 端把链路打磨成熟再说。
技术栈
|--------|------------------------------------|-------------------|
| 模块 | 选型 | 备注 |
| 前端框架 | Vue 3 + TS + Vite | 与官方 Demo 一致 |
| 表达层 | 魔珐星云 JS SDK (xmovAvatar@latest.js) | 端侧 WebGL 渲染 + 参数流 |
| LLM | 通义千问(走 OpenAI 兼容 API) | 任意流式模型都行 |
| 后端 | Node.js + Express | 仅作为 LLM 流式代理 |
| 店铺数据 | 本地 JSON mock | 原型阶段不接真实数据库 |
架构关键点:Agent 业务逻辑放在自己的后端,星云 SDK 跑在前端浏览器里,两者通过 Server-Sent Events (SSE) 把 LLM 的 token 流传到前端,前端拿到 token 后直接喂给 SDK 的 **speak()**方法。 这个设计的好处是:LLM、业务数据都掌握在自己手里,星云只做"表达层"这一件事------这正是前文反复强调的"表达层应该是独立的基础设施"。
4.2 在魔珐星云后台创建你的具身应用
写代码之前,先要在魔珐星云的平台后台把"数字人"配出来------选好形象、音色、表演风格,拿到 appId 和 appSecret,SDK 才有东西可以驱动。这一步官方文档里只用一句话带过("登录魔珐星云,在应用中心创建驱动应用"),但实际操作里有几个值得细说的选型决策。
Step 1:注册账号
打开 xingyun3d.com,点右上角"登录注册"。
Step 2:进入体验中心 → 具身驱动
登录之后第一件事不是急着创建应用,先去体验中心 → 具身驱动那一页玩一玩。
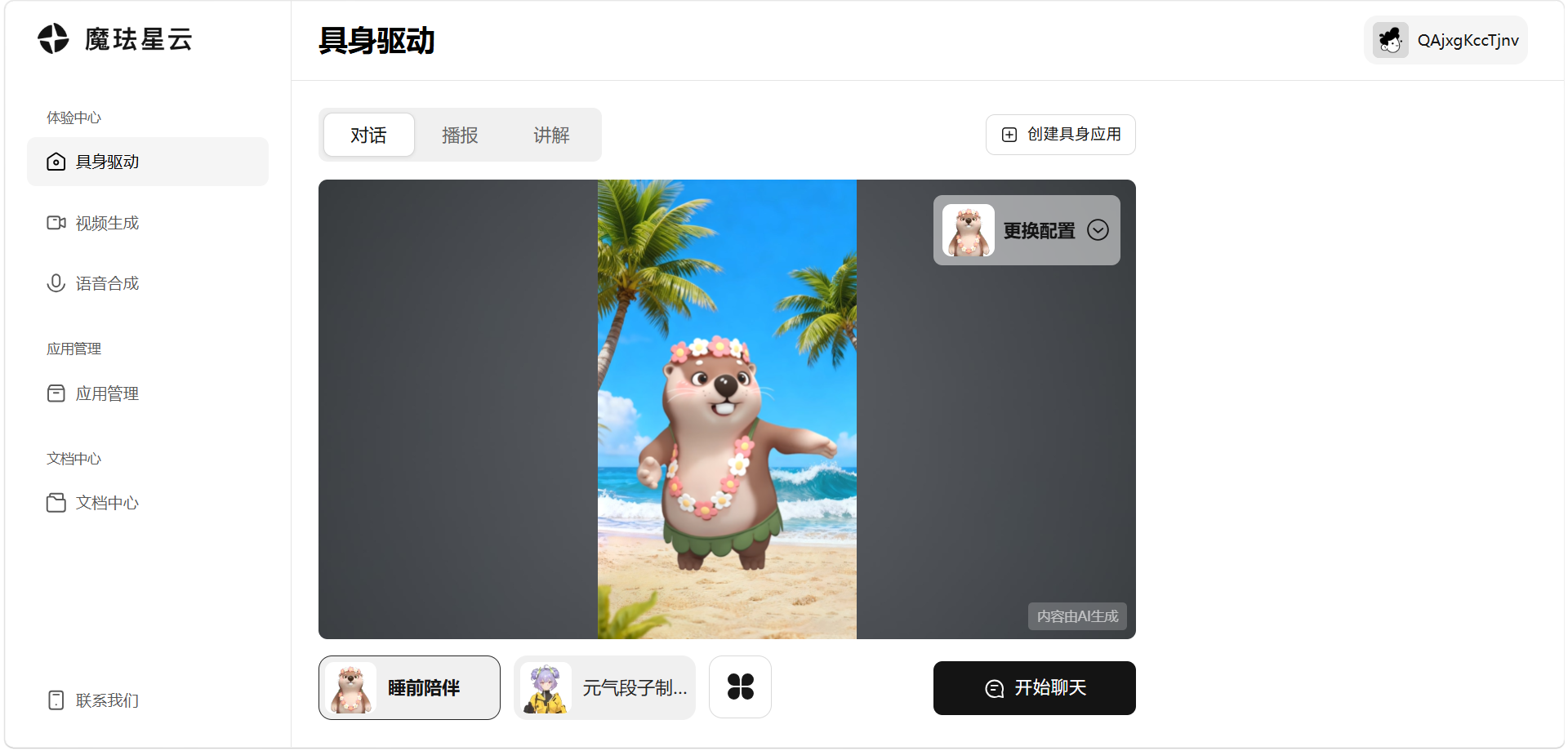
这个页面是星云的"试驾区",你能直接在浏览器里和内置数字人对话------我看到的有"睡前陪伴"(萌萌的水獭形象,海滩主题)、"元气段子手"、"AI 男友"等几个内置形象。直接点底部任意一个,然后右下角"开始聊天",就能和它说话。
Step 3:点击"创建具身应用"
体验完之后,右上角"创建具身应用"按钮就是我们的目的地。点进去会让你做几个关键选择:
选择形象
这是最影响最终用户体验的一步。星云的形象库分几个风格档位:超写实、美型、卡通、二次元。服务台场景的形象选型逻辑:
- 不要选超写实------商场环境光线复杂,超写实形象在弱光或强光下容易出现"恐怖谷"。除非你的部署场景光线极度可控(比如展厅射灯),否则避开
- 美型/卡通是首选------既有人形识别度,又有"我是数字人"的合理预期,不会让顾客产生"对方是不是真人"的错位感
- 二次元谨慎选------除非是动漫主题商场或者目标客群是 Z 世代,普通商场用二次元会显得不正式
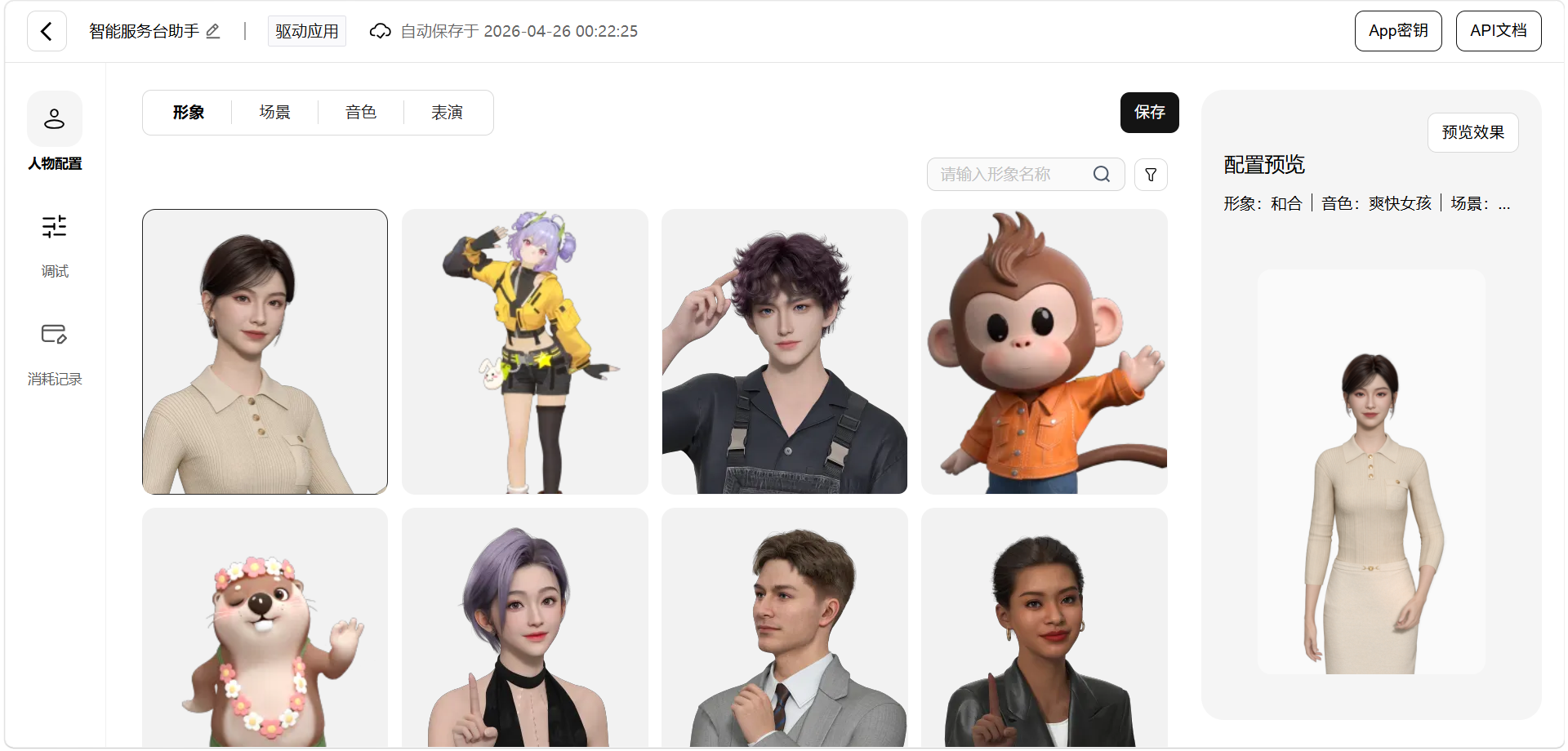
我最终选了一个偏成熟的女性卡通形象,30 岁左右,职业装感------既亲切又有"服务员"该有的专业感。
选择音色
音色库我快速试听了一遍,大致分:亲切女声 / 专业女声 / 活泼少女音 / 中年男声 / 商务男声。
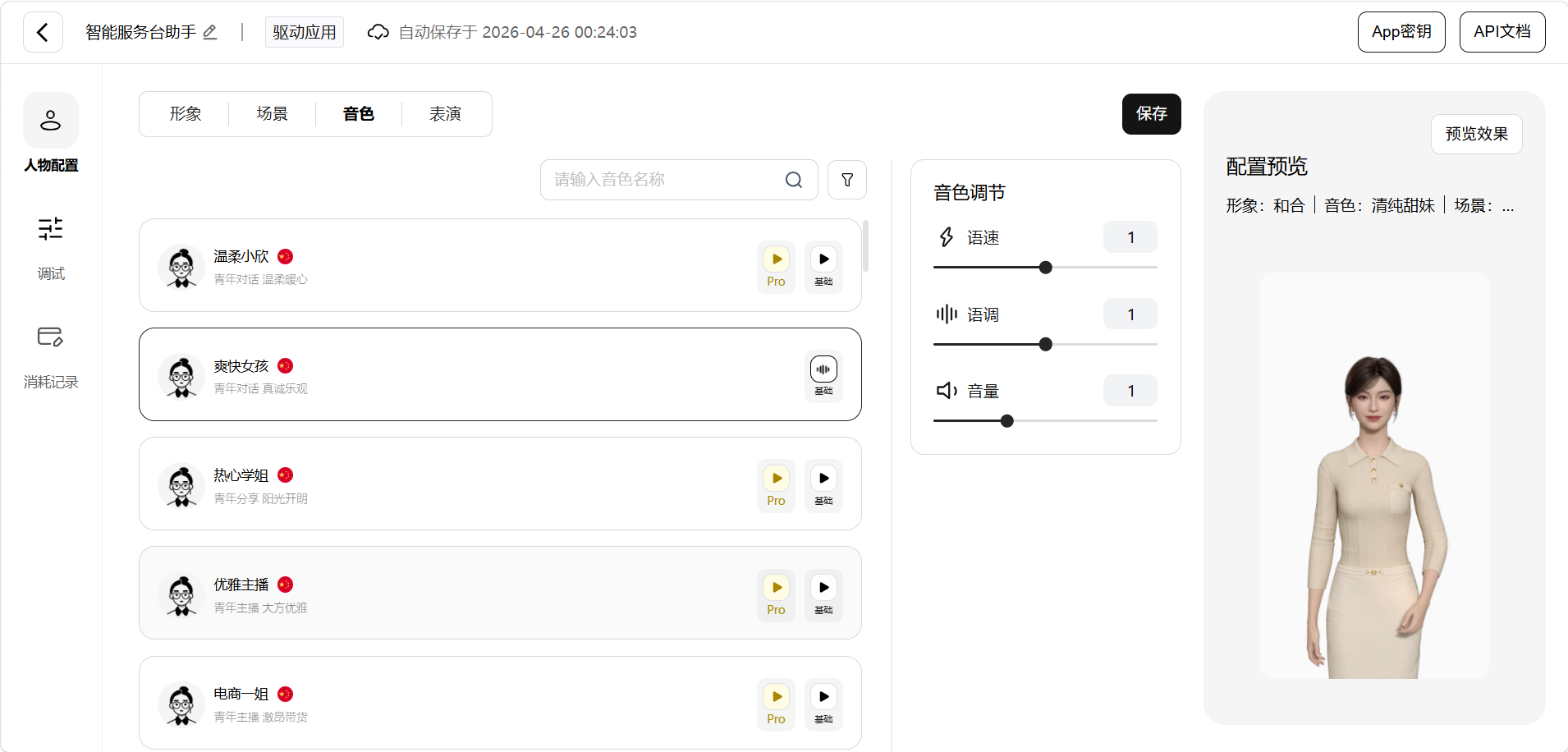
服务台场景我选的是亲切但不娃娃音的女声------太活泼会显得不专业,太成熟会显得有距离感。这一步建议你听一遍每一个音色再选,文字描述很难还原音色的实际气质。
选择表演风格
这个我理解是数字人的"基础节奏"------平稳/活泼/专业。服务台选"专业",讲解类场景可以选"活泼"。
Step 4:进入"应用管理",拿到 appId / appSecret
应用创建完之后,左侧菜单"应用管理"页面里能看到刚才创建的应用,点进去 → 查看密钥,就能拿到 appId 和 appSecret。这两个就是后面所有 SDK 代码里要用的凭证。
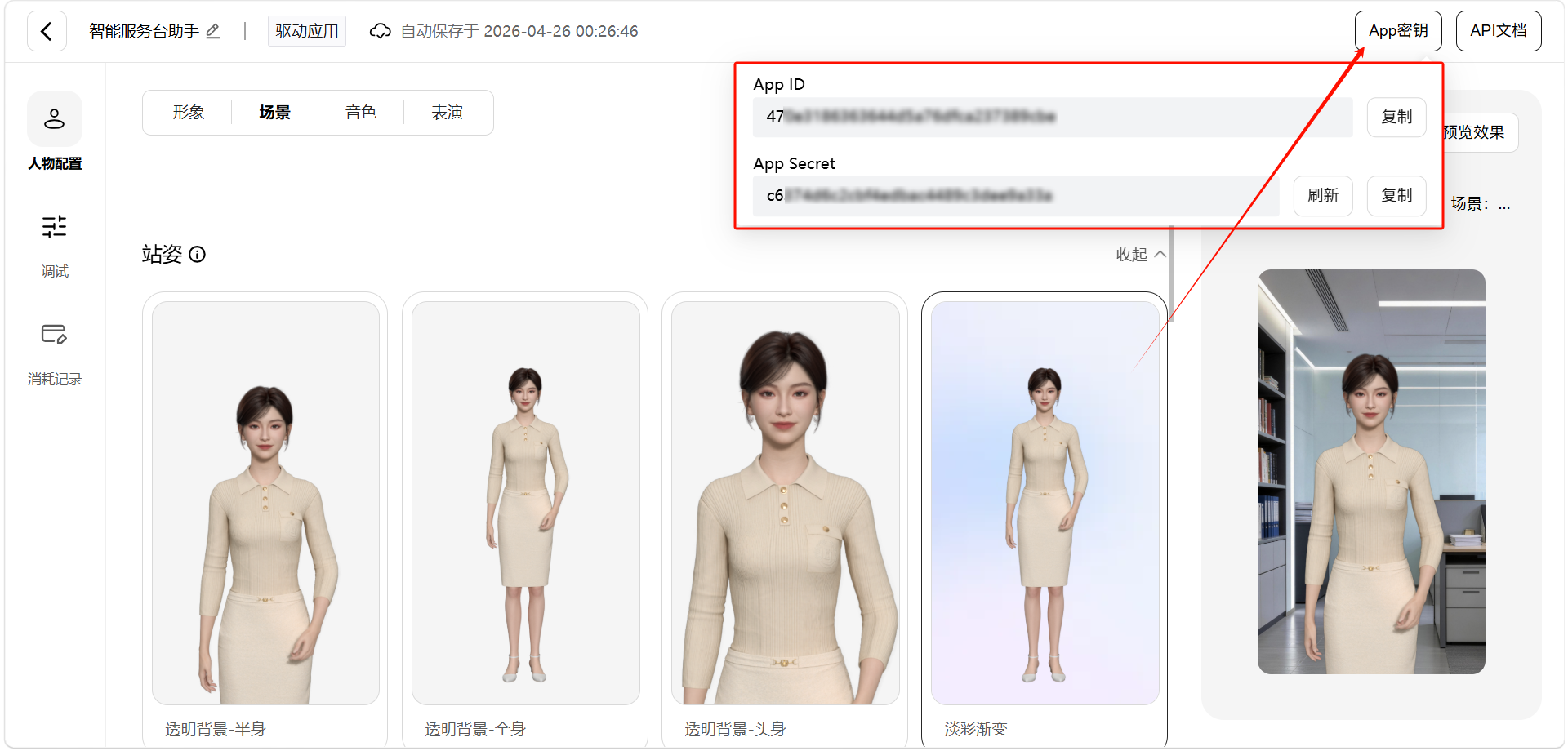
到这一步,准备工作就完成了。下面进入代码部分。
4.3 SDK 接入:从 Hello World 开始
先把最小可运行的数字人页面跑起来。在 Vite 项目的 index.html 里直接引入 SDK:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<title>服务台 Agent 原型</title>
</head>
<body>
<div id="app"></div>
<!-- 关注 latest 版本以获取最新效果 -->
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script type="module" src="/src/main.ts"></script>
</body>
</html>第一个坑(也是文档 FAQ 第一条):必须 localhost 或 https 。 我一开始把 Vite 的 dev server 配成了 host: '0.0.0.0',然后用局域网 IP 在另一台机器上访问,直接报 VideoDecoder is not defined。SDK 的部分方法依赖 WebCodecs API,这个 API 只在 secure context 下可用。本地开发要么 localhost,要么给 Vite 配 @vitejs/plugin-basic-ssl 启 https。这个坑官方 Demo 工程的 FAQ 第一条就警告了,但我还是没绕过去。
数字人组件 Avatar.vue:
<template>
<div ref="containerRef" class="avatar-container"></div>
</template>
<script setup lang="ts">
import { ref, onMounted, onBeforeUnmount } from 'vue'
declare const XmovAvatar: any // SDK 通过 <script> 引入,作为全局变量
const containerRef = ref<HTMLDivElement>()
let sdk: any = null
const props = defineProps<{
appId: string
appSecret: string
}>()
const emit = defineEmits<{
(e: 'ready'): void
(e: 'voice-state', state: string): void
(e: 'error', code: number, message: string): void
(e: 'widget', type: string, data: any): void
}>()
onMounted(async () => {
if (!containerRef.value) return
containerRef.value.id = 'xmov-sdk-container'
sdk = new XmovAvatar({
containerId: '#xmov-sdk-container',
appId: props.appId,
appSecret: props.appSecret,
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
hardwareAcceleration: 'prefer-hardware', // 笔记本调试时务必开启硬解
enableLogger: true, // 调试期开,生产期关
onMessage(msg: any) {
// SDK 抛出的消息(包含错误码),错误码 >= 10000 都是异常
if (msg.code >= 10000) {
emit('error', msg.code, msg.message)
}
},
onStateChange(state: string) {
console.log('[SDK] state →', state)
},
onVoiceStateChange(status: string) {
// voice_start: 数字人开始讲话
// voice_end: 数字人讲话结束
emit('voice-state', status)
},
onNetworkInfo(info: { rtt: number; downlink: number }) {
if (info.rtt > 300) console.warn('[Network] RTT 偏高:', info.rtt)
},
// 自定义 widget 事件代理(讲到店铺时弹出店铺卡)
proxyWidget: {
'widget_shop_card': (data: any) => emit('widget', 'shop_card', data),
},
})
// 关键:必须监听下载进度,首次加载会拉模型/表情/视频资源
await sdk.init({
onDownloadProgress: (progress: number) => {
console.log(`[SDK] 资源加载 ${progress}%`)
},
initModel: 'normal',
})
emit('ready')
})
onBeforeUnmount(() => {
// 一定要 destroy,否则 socket 连接和 worker 不会被回收
if (sdk) {
sdk.destroy()
sdk = null
}
})
// 暴露给父组件调用
defineExpose({
speak: (ssml: string, isStart: boolean, isEnd: boolean) =>
sdk?.speak(ssml, isStart, isEnd),
idle: () => sdk?.idle(),
listen: () => sdk?.listen(),
think: () => sdk?.think(),
interactiveIdle: () => sdk?.interactiveidle(),
})
</script>
第二个坑:首屏黑屏。 我第一次跑起来的时候,浏览器画面里 SDK 容器持续黑屏了大概十几秒,我一度以为 SDK 挂了。看 console 才发现 onDownloadProgress 在持续 log------首次连接时要下载数字人模型、表情数据(face bin)、动作视频资源,加起来挺大一坨。官方文档明确说明:首次连接 bin 资源或首个视频资源加载失败时,进度不会到 100,且 SDK 会内部调用 stopSession------所以不监听 onDownloadProgress 的话,你根本不知道是还在加载、还是已经失败了。我现在的写法是把进度同步到 UI 上做一个加载条,体验好很多。
4.4 后端:LLM 流式代理 + SSML 协议设计
后端做的事情非常简单------接收前端问题,塞 system prompt,流式调 LLM,SSE 推回前端。关键不在代码,在 system prompt 怎么设计。
// server/agent.ts
import express from 'express'
import OpenAI from 'openai'
import shops from './data/shops.json' // mock 店铺数据
const app = express()
app.use(express.json())
const llm = new OpenAI({
apiKey: process.env.LLM_API_KEY,
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
})
const SYSTEM_PROMPT = `你是 XX 购物中心的 AI 服务员"小喵"。
回答要求:
1. 控制在 60 字以内,顾客没耐心听长篇大论
2. 必须基于"参考店铺数据"回答,不要编造未提供的店铺、楼层、活动
3. 输出严格符合下面的 SSML 格式,在合适的位置嵌入控制指令
可用控制指令(直接嵌入在 SSML 里):
【欢迎/招呼】
<ue4event><type>ka_intent</type><data><ka_intent>Welcome</ka_intent></data></ue4event>
【推荐/赞许】
<ue4event><type>ka_intent</type><data><ka_intent>ThumbUp</ka_intent></data></ue4event>
【思考】
<ue4event><type>ka_intent</type><data><ka_intent>Thinking</ka_intent></data></ue4event>
【弹出店铺卡】(讲到具体店铺时使用,SHOP_ID 替换为店铺数据里的 id)
<ue4event><type>widget_shop_card</type><data><id>SHOP_ID</id></data></ue4event>
输出模板:
<speak>
{欢迎指令(可选)}
你说的话{在合适位置嵌入店铺卡指令}
</speak>
注意:每次回答最多嵌入 1 个店铺卡指令,讲到核心推荐的店铺时弹出。`
app.post('/api/chat', async (req, res) => {
const { question } = req.body
// 原型阶段:简单关键词过滤店铺数据,生产应换成向量检索
const candidates = shops.filter(s =>
question.includes(s.category) ||
question.includes(s.floor) ||
s.tags.some((t: string) => question.includes(t))
).slice(0, 5)
const ctx = candidates.length > 0
? candidates.map(s => `- ${s.id} | ${s.name}(${s.category},${s.floor})`).join('\n')
: '(无相关店铺,请引导顾客提供更多信息)'
res.setHeader('Content-Type', 'text/event-stream')
res.setHeader('Cache-Control', 'no-cache')
res.setHeader('Connection', 'keep-alive')
const stream = await llm.chat.completions.create({
model: 'qwen-plus',
stream: true,
messages: [
{ role: 'system', content: SYSTEM_PROMPT },
{ role: 'user', content: `参考店铺数据:\n${ctx}\n\n顾客问题:${question}` },
],
})
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta?.content ?? ''
if (delta) {
res.write(`data: ${JSON.stringify({ token: delta })}\n\n`)
}
}
res.write(`data: ${JSON.stringify({ done: true })}\n\n`)
res.end()
})
app.listen(3001)关于 system prompt 的核心设计
我想强调一件事:把 SSML 协议作为 LLM 的输出格式,而不是事后用代码解析"加表情"。
这件事我前一个展厅项目的时候是绕了弯路的------当时让 LLM 输出纯文本,业务侧用关键词匹配触发表情。后来发现这种"事后解析"问题非常多:LLM 出"恭喜你!"这种短语时,我没想到要加规则,数字人就一脸严肃地说"恭喜你"。规则枚举不完。
LLM 自己最清楚这句话的情绪和上下文。把表情和动作的决策权交给 LLM,只要在 prompt 里把可用 指令 清单列清楚就行。 星云的 SSML 设计天然支持这种用法------你给 LLM 一份指令清单,它会在合适的位置自己嵌入。
我用通义千问试下来,这件事做得相当稳定。要注意的是国产 LLM 的指令遵循度有差异,通义偶尔会把 <ue4event> 写漏一个标签,或者把 <ka_intent> 写成中文标点 <ka_intent>,所以前端在 feed 给 SDK 之前必须做容错------不合法的 SSML 直接当纯文本送出去,不要让 SDK 报错中断对话。
4.5 流式驱动:把 LLM token 流喂给 SDK
这一节是整个原型最关键的代码,也是我踩坑最多的地方。先看最终稳定版本,再讲我一开始为什么写错了。
// src/composables/useStreamSpeak.ts
import { ref, type Ref } from 'vue'
interface AvatarRef {
speak: (ssml: string, isStart: boolean, isEnd: boolean) => void
interactiveIdle: () => void
think: () => void
}
export function useStreamSpeak(avatarRef: Ref<AvatarRef | null>) {
const isStreaming = ref(false)
let buffer = ''
let isFirst = true
const FIRST_FLUSH_THRESHOLD = 20 // 首次累积阈值,见下文"踩坑 3"
function start() {
avatarRef.value?.think() // 先切到 think,LLM 推理时数字人做思考动作
buffer = ''
isFirst = true
isStreaming.value = true
}
function feed(token: string) {
buffer += token
// 首次必须积攒一段再发,否则数字人说话速度会追上 LLM 输出
if (isFirst && buffer.length < FIRST_FLUSH_THRESHOLD) return
// 后续按"完整句子"为单位 flush(避免 SSML 标签被切断)
if (!isFirst && !endsAtSafeBoundary(buffer)) return
flush(false)
}
function flush(isEnd: boolean) {
if (!buffer && !isEnd) return
// 把累积的 buffer 包成 SSML
const ssml = `<speak>${buffer}</speak>`
avatarRef.value?.speak(ssml, isFirst, isEnd)
buffer = ''
isFirst = false
}
function finish() {
flush(true)
isStreaming.value = false
// 关键:is_end=true 之后必须切状态,否则下一次 speak 不会生效
setTimeout(() => avatarRef.value?.interactiveIdle(), 100)
}
// 判断 buffer 是否在"安全边界"上(标签闭合 + 句末标点)
function endsAtSafeBoundary(s: string): boolean {
// buffer 末尾是不完整标签时,等待
if (/<[^>]*$/.test(s)) return false
// 末尾是句末标点(中英文)时,可以 flush
return /[。!?,、,.!?]$/.test(s)
}
return { start, feed, finish, isStreaming }
}调用方式:
async function askAgent(question: string) {
const { start, feed, finish } = streamSpeak // 复用 useStreamSpeak 实例
start()
const resp = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ question }),
})
const reader = resp.body!.getReader()
const decoder = new TextDecoder()
while (true) {
const { done, value } = await reader.read()
if (done) break
const chunks = decoder.decode(value).split('\n\n').filter(Boolean)
for (const chunk of chunks) {
const data = JSON.parse(chunk.replace(/^data: /, ''))
if (data.token) feed(data.token)
if (data.done) finish()
}
}
}这套流程现在跑得稳定。但写到这一步之前,我连续踩了三个让我抓狂的坑,每一个都让我对官方文档的某个不起眼的小角落产生敬畏。
踩坑 1:LLM 的 SSML 输出会把标签拆散在多个 token 里
最早我写的版本是每收到一个 token 就调一次 speak:
function feed(token: string) {
avatarRef.value?.speak(`<speak>${token}</speak>`, isFirst, false)
isFirst = false
}跑起来数字人开始一字一字念"小尖括号 u e 4 event 大尖括号 type ..."------LLM 输出 <ue4event><type>ka_intent</type>... 这样的标签时,token 切分是不可控的,可能切成 <ue4、event>、<type> 这样的碎片。每一段单独包成 <speak> 都不是合法 SSML,SDK 直接把它当文本读了出来。
解决方案:积攒成完整的 SSML 片段再发。 buffer 累积到下一个完整的可断句单元(句号、逗号,或者一个完整的标签结束)时才 flush 一次。也就是上面 endsAtSafeBoundary 函数做的事。
踩坑 2:is_end=true 之后接续 speak 不生效
第一版能流式说话之后,我兴奋地测了第二轮对话------问完第一个问题、等数字人说完,再问第二个问题。结果第二轮数字人完全没反应,console 里 SDK 也没报错,就是哑了。
翻了好几遍代码没头绪,最后是在官方文档"Speak 详解"那段不起眼的注释里找到答案:
speak 不允许连续多次调用(即前一次 speak 调用中 is_end=true 之后,接续 speak),建议中间使用 interactive_idle 或者 listen 方法做一次数字人状态切换。
也就是说,is_end=true 之后,SDK 会把数字人状态锁在"说完了"的终态,你必须显式切一下状态 (interactiveIdle() / listen() / idle())才能再次进入可说话的状态。
这就是为什么上面 finish() 函数里有 setTimeout(() => avatarRef.value?.interactiveIdle(), 100) 这一行。延迟 100ms 是因为 is_end=true 那帧 SDK 内部还在收尾,立刻切状态偶尔会丢命令------这个延迟值是我多次尝试出来的经验值,你可以根据自己机器的表现调整。
踩坑 3:首段太短,数字人说话追上 LLM 输出导致断流
这个坑更隐蔽。第二个坑解决之后,流式说话整体能跑通了,但偶尔会出现一种现象:数字人说了前半句之后停顿一两秒,然后接着说后半句------明显的"卡顿感",体验很别扭。
排查了半天,最后从官方文档的"Speak 详解"里挖出来:
为了保证较好的数字人呈现,建议流式调用中的首次可以积攒一小段内容后调用,保证后续数字人说话速度(对于文本内容的消耗速度)低于 大模型 后续流式输出的速度。
翻译成大白话:数字人是边收边说的,如果你第一段只发了 5 个字,数字人 1 秒就念完了,但 LLM 下一段 token 还要 800ms 才到------这中间的 200ms 数字人就只能尴尬地停着。
解决方案:首段累积阈值 20 个字符 (可以根据 LLM 输出速度调整),保证数字人开始说的时候后面已经积压了足够长的"安全垫"。这就是 FIRST_FLUSH_THRESHOLD = 20 这一行的来历。
三个坑的共性
回过头看,这三个坑全部源于同一个误解------我把 **speak()**当成了一个"傻瓜的 print",以为塞什么进去它就播什么。但它实际上是一个有状态、有节奏、有协议约束的流式接口。
读懂这一点之前,代码再漂亮也跑不稳。这个心智模型的转变,是用星云 SDK 必须跨过的门槛。我把它写在这里,希望你不用再重复踩一遍。
4.6 用 KA 指令让数字人"会做动作"
到这一步,数字人已经能边说边动嘴了,但还是一动不动一副扑克脸。下面用 KA 系统让它"活过来"。
魔珐星云的动作系统有三种形态(官方文档术语):
- 语义 KA( ka_intent**)** :传入一个情绪/意图关键词,SDK 自动匹配合适的表情和动作。比如
<ka_intent>Welcome</ka_intent>会触发欢迎手势。 - 技能 KA ( ka**+** action_semantic**)**:显式指定某个具体动作。
- Speak KA:把动作和说话内容组合,先做动作再说话。
通过 KA 查询接口拉取所有可用动作
LLM 怎么知道哪些动作能用?通过官方提供的 KA 查询接口 (GET /user/v1/external/lite_ka_summary)拉到全量动作列表,然后塞进 system prompt 里:
// server/ka.ts
import crypto from 'crypto'
import axios from 'axios'
function signHeaders(appId: string, secret: string, method: string, path: string, data: object) {
const timestamp = Math.floor(Date.now() / 1000)
// 关键:JSON 必须 sort_keys 后去空格(否则签名通不过)
const sortedData = JSON.stringify(data, Object.keys(data).sort()).replace(/\s/g, '')
const sign = path.toLowerCase() + method.toLowerCase() + sortedData + secret + timestamp
const token = crypto.createHash('md5').update(sign, 'utf8').digest('hex')
return {
'X-APP-ID': appId,
'X-TOKEN': token,
'X-TIMESTAMP': String(timestamp),
}
}
export async function fetchKaList(appId: string, appSecret: string) {
const path = '/user/v1/external/lite_ka_summary'
const headers = signHeaders(appId, appSecret, 'GET', path, {})
const resp = await axios.get(`https://nebula-agent.xingyun3d.com${path}`, { headers })
return resp.data.data // [{ name, cn_name, ka_type, ... }]
}签名算法严格按官方文档实现:接口路径转小写 + method 转小写 + JSON 排序后去空格 + secret + 时间戳 ,拼接后 MD5。这个签名顺序我第一次写错过------data 字段必须是 JSON.stringify(data, Object.keys(data).sort()) 而不是 JSON.stringify(data),否则签名通不过。
启动后端时把动作列表加载进 system prompt:
const kaList = await fetchKaList(APP_ID, APP_SECRET)
const actionDocs = kaList
.filter((k: any) => k.ka_type === 'gesture')
.map((k: any) => `- ${k.name}(${k.cn_name})`)
.join('\n')
const SYSTEM_PROMPT_WITH_KA = `${SYSTEM_PROMPT}
可用动作清单(在 SSML 中用 <action_semantic>动作名</action_semantic>):
${actionDocs}
`官方文档里有一个特别容易漏的细节 :返回的 name 字段是完整路径(如 M_CN03_show03__PointingSelf),但在 SSML 中只能用最后一段 (PointingSelf)。这一点文档示例里有提,但代码示例里没强调,我第一次跑出来 SDK 静默不响应,排查了半小时才意识到。生产代码里建议在加载 KA 列表时统一截断成最后一段,避免 LLM 用错。
4.7 用 Widget 事件做"屏幕侧边的店铺卡"
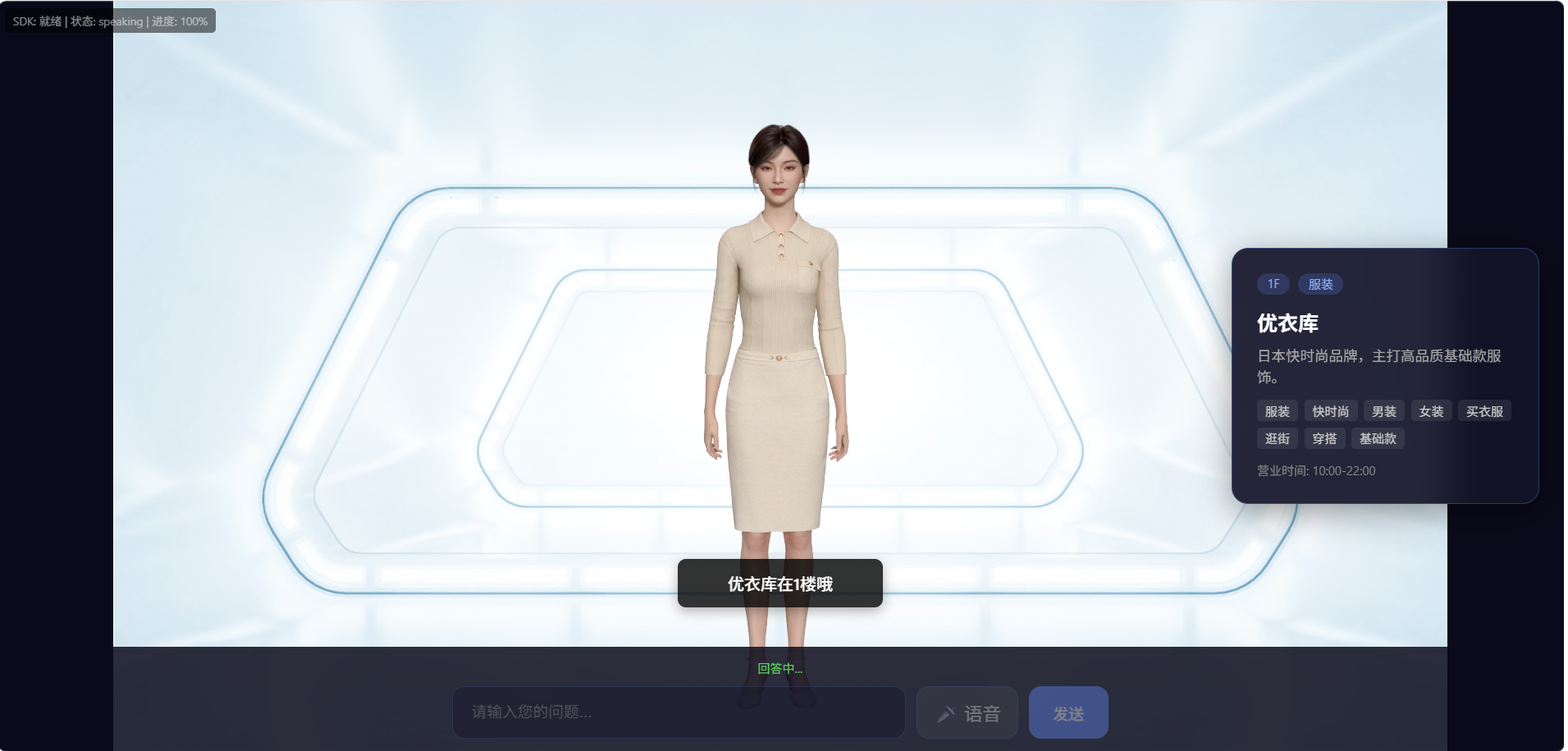
到这里数字人已经会说会动了,但还差一个对 服务台 场景特别关键的能力------讲到具体店铺时,屏幕侧边能弹出店铺图片、楼层、营业时间。
这就是星云 SDK 的 widget 事件系统。LLM 在 SSML 里嵌入 widget 指令,SDK 把指令通过 proxyWidget 回调转给前端业务代码,前端在画布旁边渲染对应的 UI。
LLM 输出示例:
<speak>
您找的咖啡店,我推荐三楼的"豆生活",
<ue4event>
<type>widget_shop_card</type>
<data><id>shop_3f_007</id></data>
</ue4event>
他们家的手冲特别出名,环境也很安静。
</speak>前端配置 proxyWidget(在 Avatar.vue 里已经写过了,这里看父组件怎么消费):
<!-- App.vue -->
<template>
<div class="screen">
<Avatar
ref="avatarRef"
:app-id="APP_ID"
:app-secret="APP_SECRET"
@widget="onWidget"
/>
<ShopCard v-if="currentShop" :shop="currentShop" />
</div>
</template>
<script setup lang="ts">
import { ref } from 'vue'
import shops from './data/shops.json'
const currentShop = ref<any>(null)
let hideTimer: number
function onWidget(type: string, data: any) {
if (type === 'shop_card') {
const shop = shops.find(s => s.id === data.id)
if (!shop) return
currentShop.value = shop
// 5 秒后自动收起
clearTimeout(hideTimer)
hideTimer = window.setTimeout(() => {
currentShop.value = null
}, 5000)
}
}
</script>proxyWidget 的优先级在官方文档里讲得很清楚:onWidgetEvent**>** proxyWidget**> 默认事件** 。如果你只想覆盖个别事件,用 proxyWidget;如果想全部接管,用 onWidgetEvent。我们这里用 proxyWidget 注册一个自定义的 widget_shop_card 事件------SDK 默认是不认识它的,完全由我们的业务代码处理。
这个 widget 系统为什么是关键能力
我想花一段时间专门讲这个,因为这是星云区别于其他数字人方案的杀手级特性,也是这次原型搭建过程中最让我惊艳的部分。
如果用传统的"视频数字人"或者"TTS + 静态头像"方案,要在屏幕侧边显示一张店铺卡,你得在前端写一套独立的状态机:监听 LLM 输出、用关键词匹配店铺、控制弹窗时机、和数字人说话进度做对齐------光对齐时机就够你调一周。因为视频数字人的画面和音频是已合成的整体,业务侧不知道"它讲到第几个字了",自然没法做精准对齐。
而星云的 widget 事件是 SDK 内部从参数流里直接派发的,事件触发的时机就是数字人说到那句话的时机,不需要业务侧做任何对齐工作 。这件事直接体现了第三章讲的"参数流架构 vs 视频流架构"的工程价值------因为 SDK 拿到的是结构化的参数流,而不是已合成的 像素,所以可以在恰当的时机精确派发业务事件。
4.8 完整状态机:让数字人"看起来活着"
最后把所有片段拼起来。原型阶段我做的简化版状态机------没有 ASR(用文本框替代语音输入),没有摄像头唤醒(用按钮触发欢迎),核心就这三个状态:
[打开页面]
▼
idle ───── 点击"开始服务" ─────► speak(欢迎语)
▲ │
│ ▼
└──── 30s 无交互 ──── interactive_idle ◄── 用户输入问题
│ │
▼ ▼
think ──────► speak(回答)
(LLM 中) │
│
┌────────────────┘
▼
interactive_idle (等下一轮)代码骨架:
// App.vue
type AgentState = 'idle' | 'greeting' | 'thinking' | 'speaking' | 'waiting'
const agentState = ref<AgentState>('idle')
function onStartService() {
if (agentState.value !== 'idle') return
agentState.value = 'greeting'
const greeting = `<speak>
<ue4event><type>ka_intent</type><data><ka_intent>Welcome</ka_intent></data></ue4event>
您好!欢迎光临,我是这里的服务员小喵,有什么可以帮您?
</speak>`
avatarRef.value?.speak(greeting, true, true)
}
// 监听 SDK 的语音状态回调
function onVoiceState(status: string) {
if (status === 'voice_end') {
if (agentState.value === 'greeting' || agentState.value === 'speaking') {
avatarRef.value?.interactiveIdle()
agentState.value = 'waiting'
}
}
}
async function onSubmit(question: string) {
if (agentState.value !== 'waiting' && agentState.value !== 'greeting') return
agentState.value = 'thinking'
await askAgent(question) // 4.5 节的流式问答
// askAgent 内部调用 finish(),会自动切回 interactive_idle
agentState.value = 'speaking'
}
// 30s 无交互回到 idle
let idleTimer: number
function resetIdleTimer() {
clearTimeout(idleTimer)
idleTimer = window.setTimeout(() => {
avatarRef.value?.idle()
agentState.value = 'idle'
}, 30_000)
}这里有一个我观察到、但官方文档没明说的细节 :onVoiceStateChange 抛出的 voice_end 略早于 onStateChange 的 idle 状态切换(我观察是大约 100-200ms 的差异)。如果业务侧想"在数字人说完话的瞬间立刻进入下一轮等待",用 voice_end****比 **state == 'idle'**更准确。这个细节我在做轮次衔接的时候发现的------用 state 判断会导致每轮之间多一段尴尬的停顿。
4.9 跑下来的体感
不给精确数字了------我自己笔记本上的数据没有商业意义,任何"实测 1.55 秒"都是误导。但我可以给你主观体感:
- 首次资源加载 :第一次打开页面时,从 SDK 初始化开始到数字人画面出现,大约十几秒(笔记本 + 家庭宽带的体感)。生产环境必须做资源预热,这是不能绕过的工程项。
- 端到端首响应 :从我点击"提交问题"到数字人开口的第一帧,主观体感大约 1.5-2 秒之间。这个延迟在屏幕前对话场景已经基本可以接受------不会让人觉得"卡了"。
- 流式说话流畅度:数字人开口之后,说话节奏跟得上 LLM 输出速度,没有明显卡顿(这是踩坑 3 解决之后的状态------解决之前会一卡一卡的)。
- 口型同步:这是最让我意外的一点。参数流架构下,口型与音频是基于同一份输出同步生成的,两者天然对齐,没有传统视频数字人方案那种"音频已经到下一句、画面还在张嘴"的尴尬错位。
- 表情自然度 :LLM 输出的
ka_intent触发表情后,数字人在合适的时候微笑、点头、招手。这种"非语言表达"对建立"在和一个人对话"的感觉作用极大,主观感受上比口型对得齐还重要。
整个原型主链路代码,我大致估算了一下,核心业务逻辑大约 300 行 TS 代码------SDK 接入、流式驱动、KA 集成、Widget 事件、状态机加起来。对比展厅项目里调研过的几种方案(自研 UE 链路至少一个月、视频数字人需要等服务端合成、纯 TTS 方案做不出口型),工作量是数量级的差异。 而且这一版主链路真的能用,原型阶段就能立得住。
下一步我会把原型拿去和客户对齐部署形态------他们如果选 Web 全屏方案,这一套基本可以直接平移上线;如果选 Android 商显屏,主链路逻辑也能复用,只需要替换 SDK 接入层换成 Android SDK。表达层这条主链路一旦跑通,后面的事就是工程问题,不再是技术风险。
五、具身智能体的演进趋势与表达层基础设施的价值
写到最后,想跳出技术细节,聊一些方向性的判断。
5.1 Agent 正在从对话框走向实体终端
回顾 Agent 这几年的演进:
- 2022-2023:Chatbot 时代,Agent 活在聊天框里
- 2024-2025:工具调用时代,Agent 学会了操作软件、执行任务
- 2026:具身时代的开端,Agent 开始走向实体屏幕、机器人、终端
每一次形态升级,都需要新的基础设施:Chatbot 时代需要 LLM API,工具调用时代需要 MCP 协议,具身时代需要的就是表达层基础设施。
这是一个还没有"赢家"的新赛道。RAG 有 LangChain,工具调用有 MCP,表达层目前没有事实标准。谁能先把这层做成开发者用得顺手的基础设施,谁就有机会成为下一个 Agent 时代的关键基础设施提供方。
5.2 屏幕是具身 Agent 的第一站
很多人提到"具身智能"会立刻想到机器人。但从工程落地的优先级来看,屏幕一定是具身 Agent 的第一站:
- 屏幕已经无处不在(全国商显屏存量超过千万块)
- 屏幕的硬件成本远低于机器人
- 屏幕的部署门槛远低于机器人
- 屏幕的运维要求远低于机器人
把存量屏幕升级为"AI 智能体终端",是这两年最大的工程红利,也是把"具身智能"从概念变成商业现实的最快路径。机器人是更远期的事,屏幕是当下就能做的事。
5.3 给开发者的几个建议
如果你也想在这个方向上做点东西,我的几点建议:
第一,把表达层当作一个独立模块来设计。不要把 TTS、渲染、动作散落在你的 Agent 代码里,把它们抽出来作为一个独立的服务。这样无论后续你换 LLM、换渲染方案,业务逻辑不需要改。
第二,优先用流式接口。从 LLM 到 TTS 到渲染,整条链路如果有任何一段是非流式,首响应延迟就会被这一段卡住。屏幕前的对话场景对延迟极度敏感,流式不是优化项,是底线。
第三,把"非语言表达"当一等公民。表情、手势、视线这些,以前总被当作"加分项"。但实际体验下来,它们对"这是不是一个人"的感知,可能比语言内容本身还重要。LLM prompt 设计时就把情绪/动作标签考虑进去。
第四,关注端侧 算力 的演进。参数流架构能成立的基础是端侧算力够用。这两年消费级 SoC 性能提升很快,以前不能跑的方案现在能跑了。要持续关注硬件演进,把握架构选型的窗口。
5.4 资源链接
如果你想动手试试这套方案,以下是相关资源:
- 魔珐星云开发者文档与 SDK:https://xingyun3d.com/developers/52-183
- 魔珐星云 AI Coding 操作手册:https://rsjqcmnt5p.feishu.cn/wiki/ULNQwoiKwid2tVkTpAlcMb49nKg
- 魔珐星云官网:https://xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc50
写在最后
这次展厅 Agent 项目让我意识到一件事:在 Agent 这条路上,真正的瓶颈往往不在"模型够不够强",而在"工程链路够不够通"。
LLM 已经够强了,RAG 已经够成熟了,工具调用已经够丰富了。但当我们要把这些能力整合成一个"能站在屏幕里、与用户共处一室的 AI 智能体"时,缺的从来不是某一个组件,而是把感知、理解、表达完整串起来的端到端基础设施。
参数流架构是一个工程上的回答。它不一定是最终答案,但它确实指出了一个被长期忽略的真问题------表达层不应该是各家拼凑的副产品,它应该是一个独立的、可标准化的、为大规模具身 Agent 部署而设计的基础设施。
这条路才刚刚开始走。希望这篇文章能让更多开发者意识到这个方向,也希望未来能看到更多有意思的具身 Agent 项目落地。
如果你也在做类似的事,欢迎交流。