一、两种数字人的交互质感,一眼就能区分
我最近在对比多款数字人产品,发现一个很有意思的现象:很多数字人看着都能说话、有 3D 形象,但真正上手体验,交互质感天差地别。为什么同样是数字人,有的因为高延迟只能机械滞后播报,有的凭借低延迟做到实时共情沟通,今天我就以魔珐星云为例,聊聊两种数字人底层的本质区别。
交互核心差异
| 对比维度 | 传统数字人(云端集中渲染) | 魔珐星云具身数字人(端侧实时渲染) |
|---|---|---|
| 表达形式 | 语音 + 云端渲染形象,动作表情预制固化 | 语音 + 表情 + 眼神 + 肢体实时联动,随语境动态变化 |
| 交互节奏 | 被动延迟交互,无法实时打断,对话节奏僵硬 | 双向实时互动,支持随时打断,贴合真人对话节奏 |
| 情绪传递 | 语气标准化,无实时情绪共情 | 神态随语义动态变化,具备情感表达与共情 |
| 响应延迟 | 1.5‑3 秒,云端链路延迟高 | ≤500ms,端到端毫秒级响应 |
| 落地能力 | 云端 GPU 依赖、成本高、并发弱、老旧终端无法适配 | 低成本、千万级高并发、全终端兼容、轻量化部署 |
| 用户感知 | 工具式被动应答,距离感强 | 具象交互伙伴,真实沉浸感强 |
简单来说,传统云端数字人可完成标准化语音形象交互 ;魔珐星云具身数字人实现实时共情、双向动态交互,二者在交互深度、实时性、落地能力上存在代际差距。
二、表象相似,底层逻辑天差地别
传统数字人采用云端集中渲染架构,语音、动作、表情依赖预制模板生成,云端渲染链路长、响应延迟高,音画同步差,无法实时适配对话情绪变化。
魔珐星云具身数字人核心为端侧实时驱动引擎,云端下发音频、动作、表情四类轻量级驱动指令,终端本地完成 3D 实时渲染,端到端响应仅 500ms,表情、动作、语音精准同步。
体验层面:传统数字人应答延迟数秒、动作语音脱节;魔珐星云随问随答、实时共情,复刻面对面自然交流。
三、从演示到落地,两种数字的门槛完全不同
传统数字人虽可实现演示级语音形象交互,但云端架构导致落地门槛极高:形象定制、动画制作、服务器部署周期长达数月,GPU 算力成本高昂,并发承载弱、老旧终端无法运行,仅适用于高端定制场景,无法规模化下沉。
魔珐星云具身数字人主打轻量化、普惠式落地:海量现成形象免建模、无需高端 GPU,百元级芯片即可运行;具备低成本、千万级高并发、全终端兼容优势,几行代码快速接入,半天即可完成部署,适配政务、门店、车机、基层服务等多元真实场景。
二者看似同为数字人,一个是高成本演示型产品,一个是可规模化商用的实时交互智能体,落地能力差距悬殊。
四、实操体验:从文字朗读到具象对话
魔珐星云------可实时交互的AI智能具身数字人
我们先打开魔珐星云官网:https://xingyun3d.com
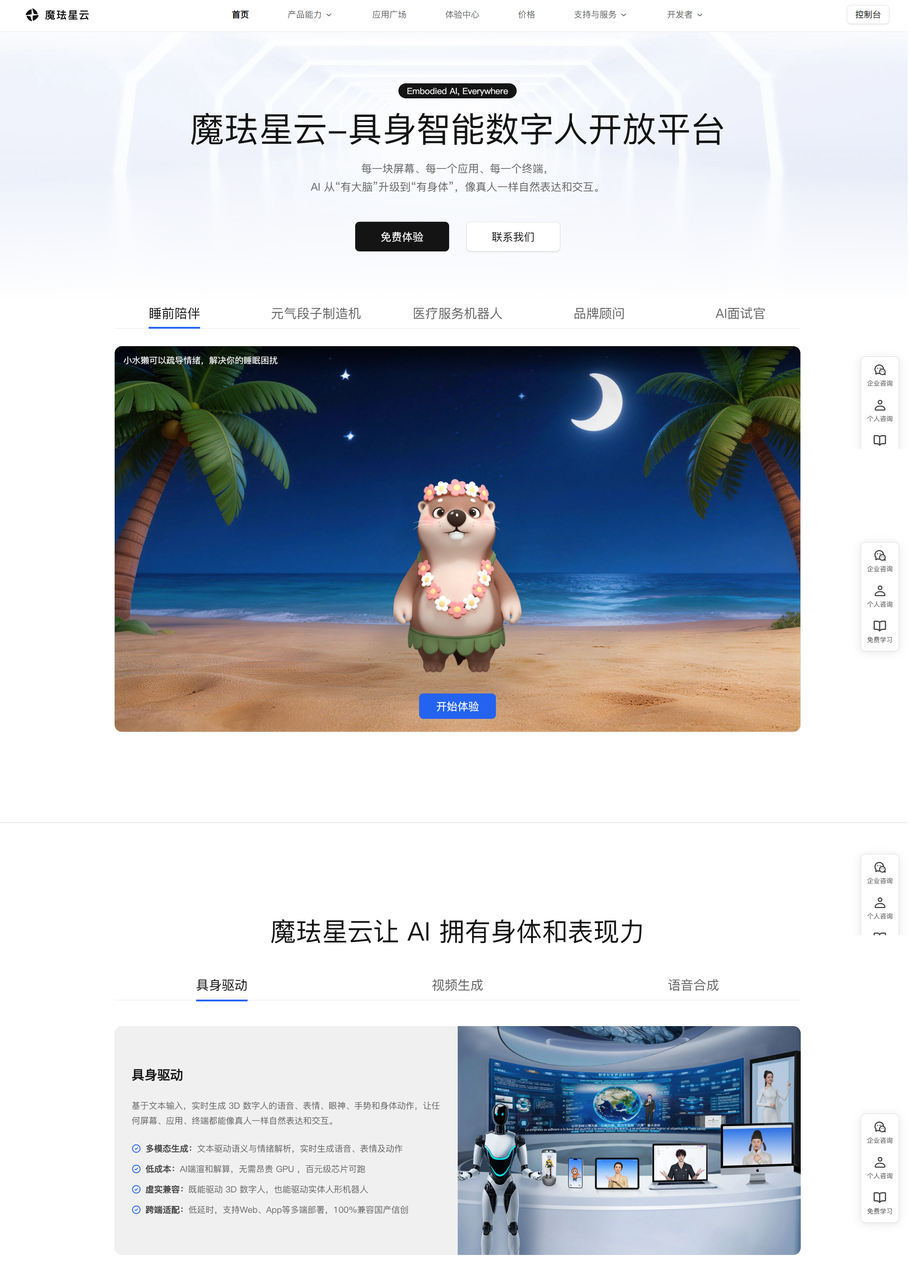
不是单纯让数字人念稿,也不是做一段虚拟人视频就结束。首页下面放的睡前陪伴、医疗服务机器人、品牌顾问、AI 面试官这些场景,都有一个共同点------需要实时回应,而不是单向播放。
所以后面我看的重点也变了。
我不再只关心数字人好不好看,而是开始看它能不能被实时驱动。能不能接文本 Agent,能不能根据回答生成语音、表情和动作,能不能让 AI 从屏幕里的回复框变成屏幕里的交互对象。
这也是我这次真正要展开的地方。
进入魔珐星云控制台:它不是在生成视频,而是在驱动角色
我点进平台里的具身驱动体验页,直接就看到了中间的数字人角色,还可以切换不同角色,比如睡前陪伴、AI 男友、金融客服、傲娇女友。还能看到角色类型、语种、人物介绍、音色、AI 动作生成开关、ASR 模型和大语言模型选项。
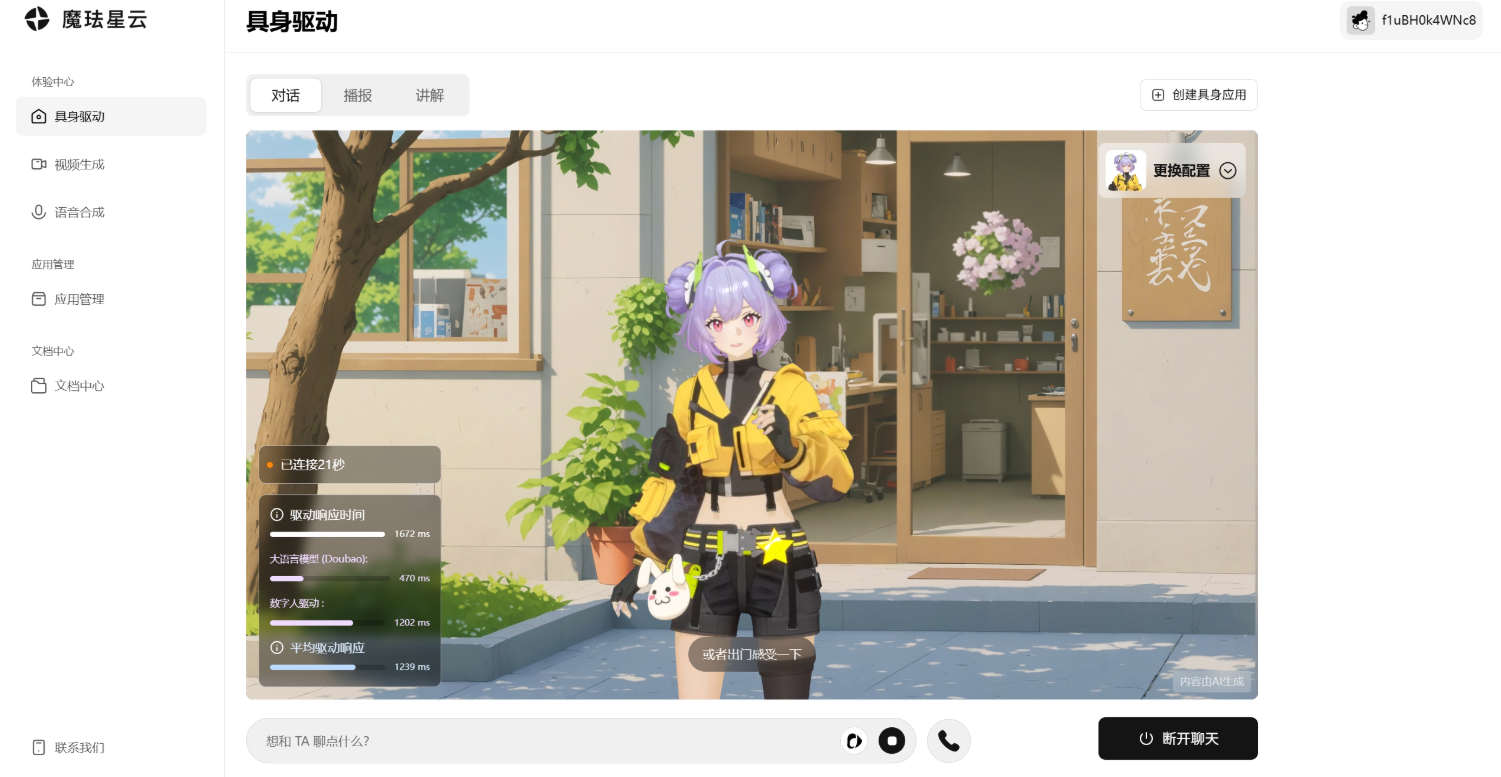
我选了元气段子手试了一下,这个角色有点二次元,也有点夸张,但它至少不是空白框。你还没输入,它已经站在那里了。哪怕它还没说话,屏幕中心已经被一个二次元占住了。
一个输入框是在等你使用,一个数字人是在等你交流。
文档里真正关键的词:实时驱动
官方文档我主要看了两块:一个是 具身驱动 SDK 接入说明,另一个是 具身驱动 KA 查询接口使用说明。前者更偏前端接入,后者更偏接口鉴权和服务调用。
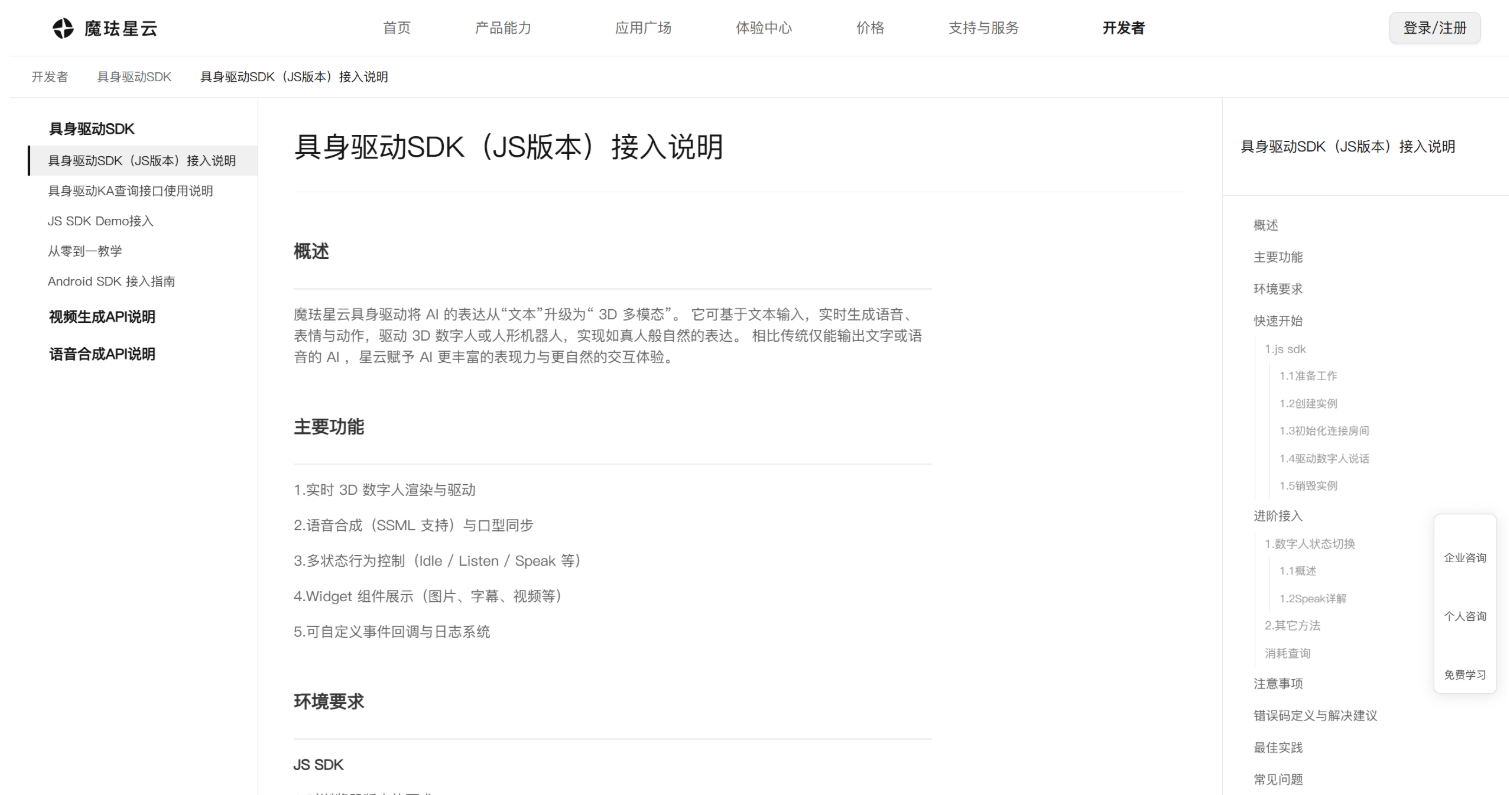
我觉得这里最重要的词不是数字人,而是驱动。文档里写到它可以做实时 3D 数字人渲染与驱动、语音合成和口型同步,还支持 Idle / Listen / Speak 这类状态控制。这说明它不是单纯生成一段数字人视频,而是让数字人能根据输入进入不同状态:等待、倾听、思考、说话。
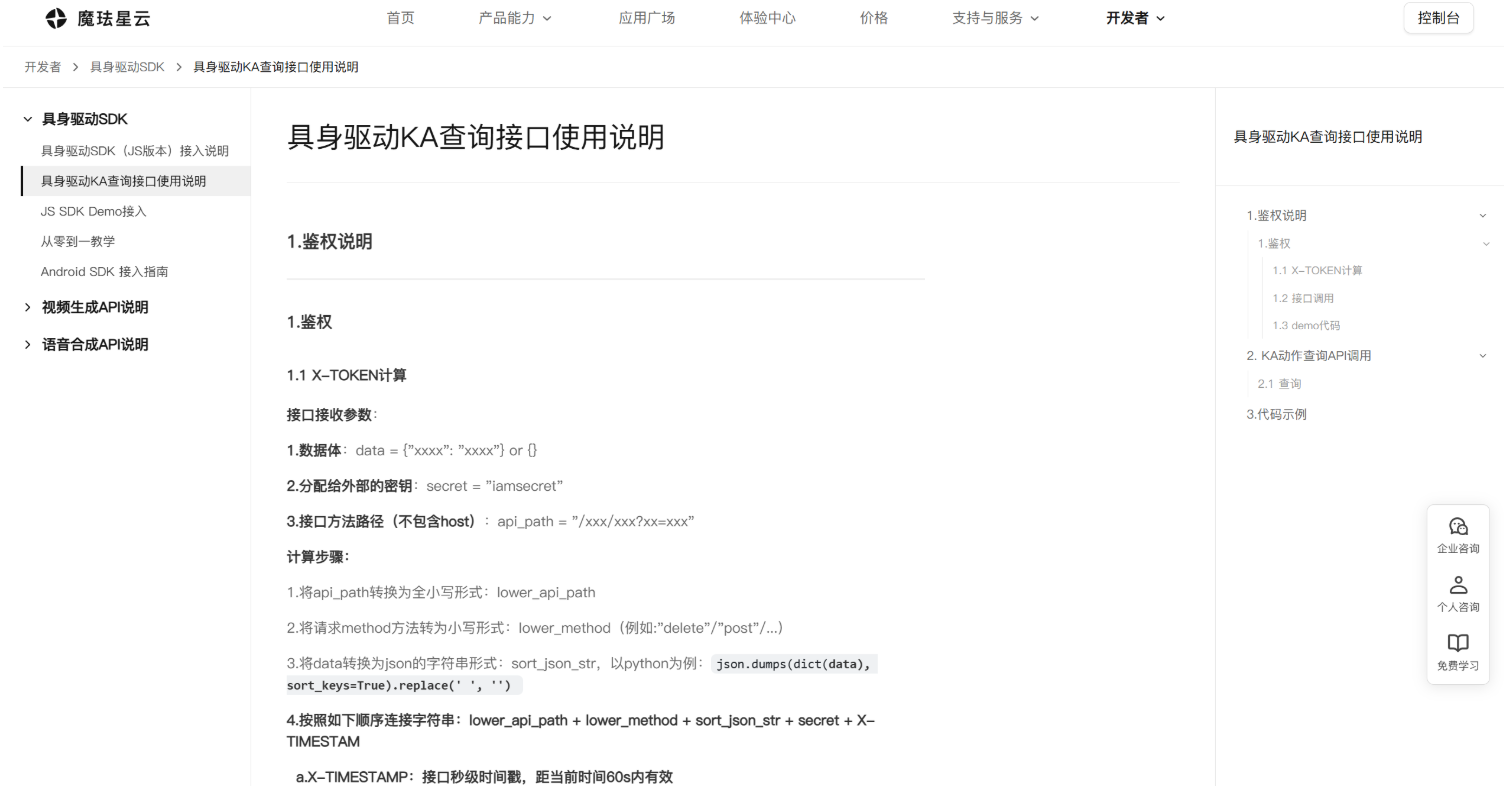
另一个 KA 查询接口文档则更偏工程化,里面有鉴权说明、X-TOKEN 计算、接口调用和 Demo 代码。这个部分和前面的 SDK 放在一起看,基本能看出接入思路,前端负责数字人的展示和状态驱动,接口侧负责查询、鉴权和业务能力调用。
所以我后面判断它是不是适合做具身 Agent,主要看这三点:能不能实时驱动、口型和语音能不能同步、状态能不能控制。如果只是 TTS + 一个数字人形象,很多工具都能做;但如果能把文本回答变成语音、口型、表情、动作和状态切换,那它就更接近一个可以被实时控制、可落地实现的具身智能 Agent,而不是一段被动播放的内容。
从零到一接入:先让数字人出现
接入前需要先在控制台创建应用,拿到 AppID 和 AppSecret,再配置数字人形象、场景、音色、表演等信息。这个流程和接其他云服务差不多:创建应用,拿密钥,初始化 SDK。
1.创建应用,并进行一些形象、场景、音色、表演的配置
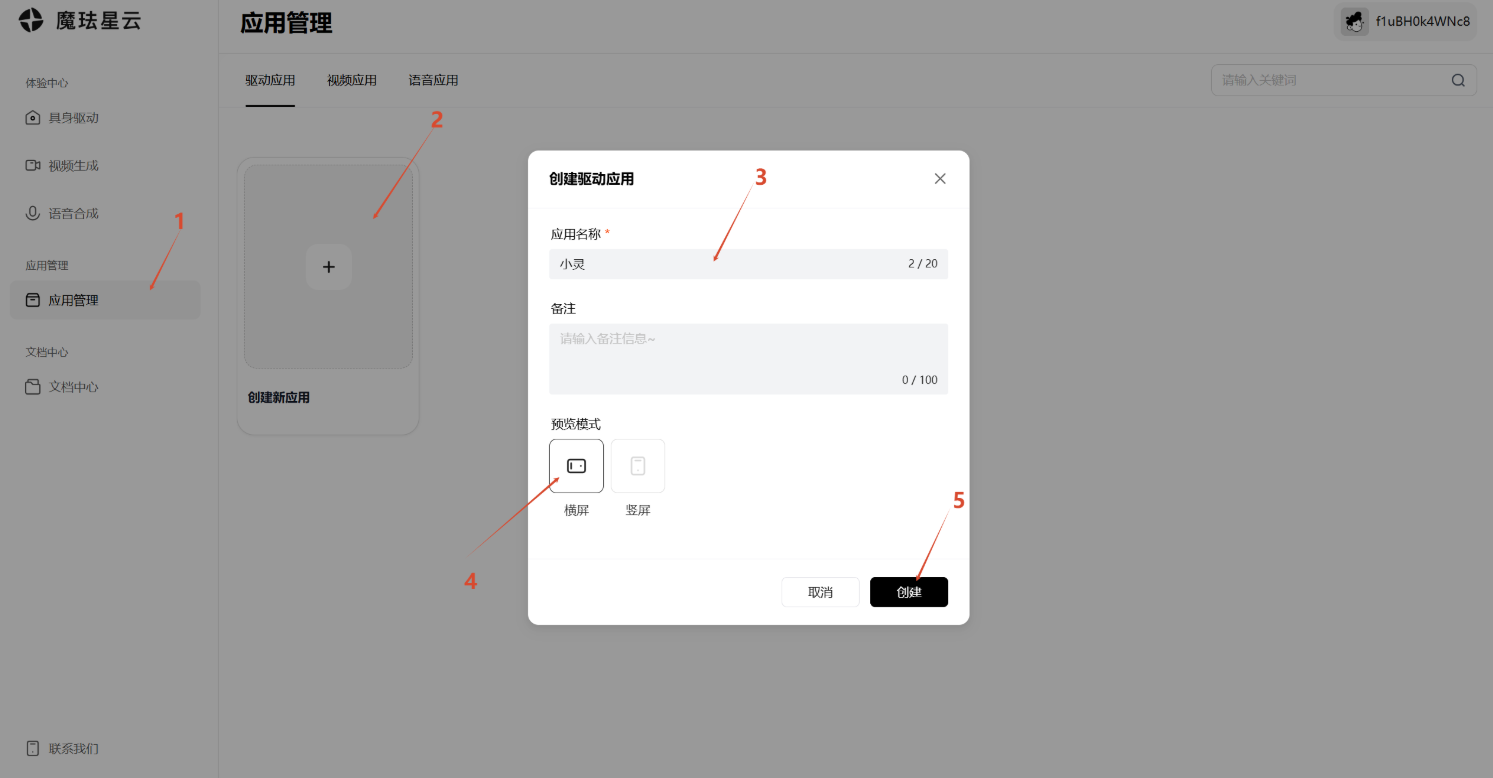
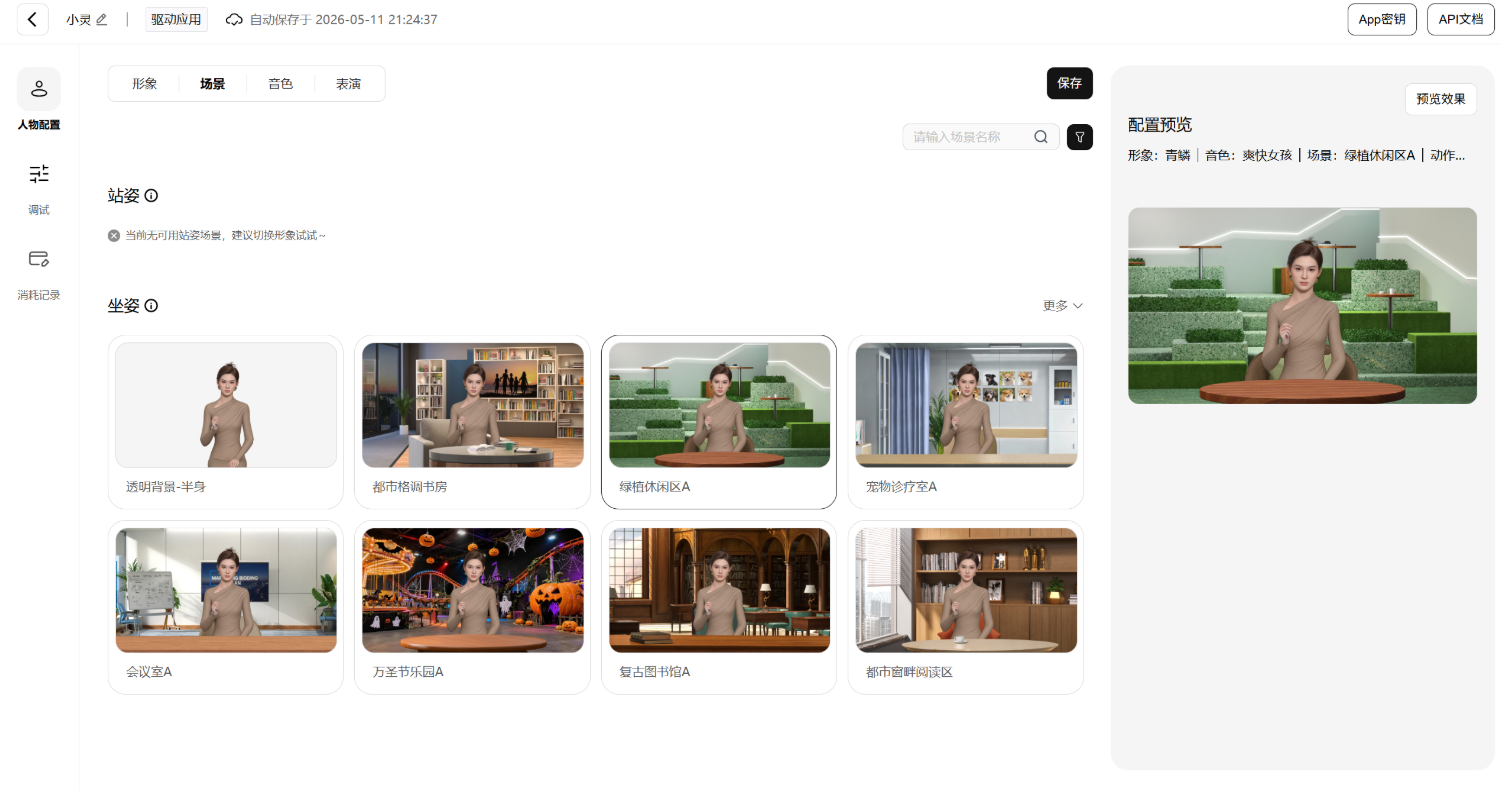
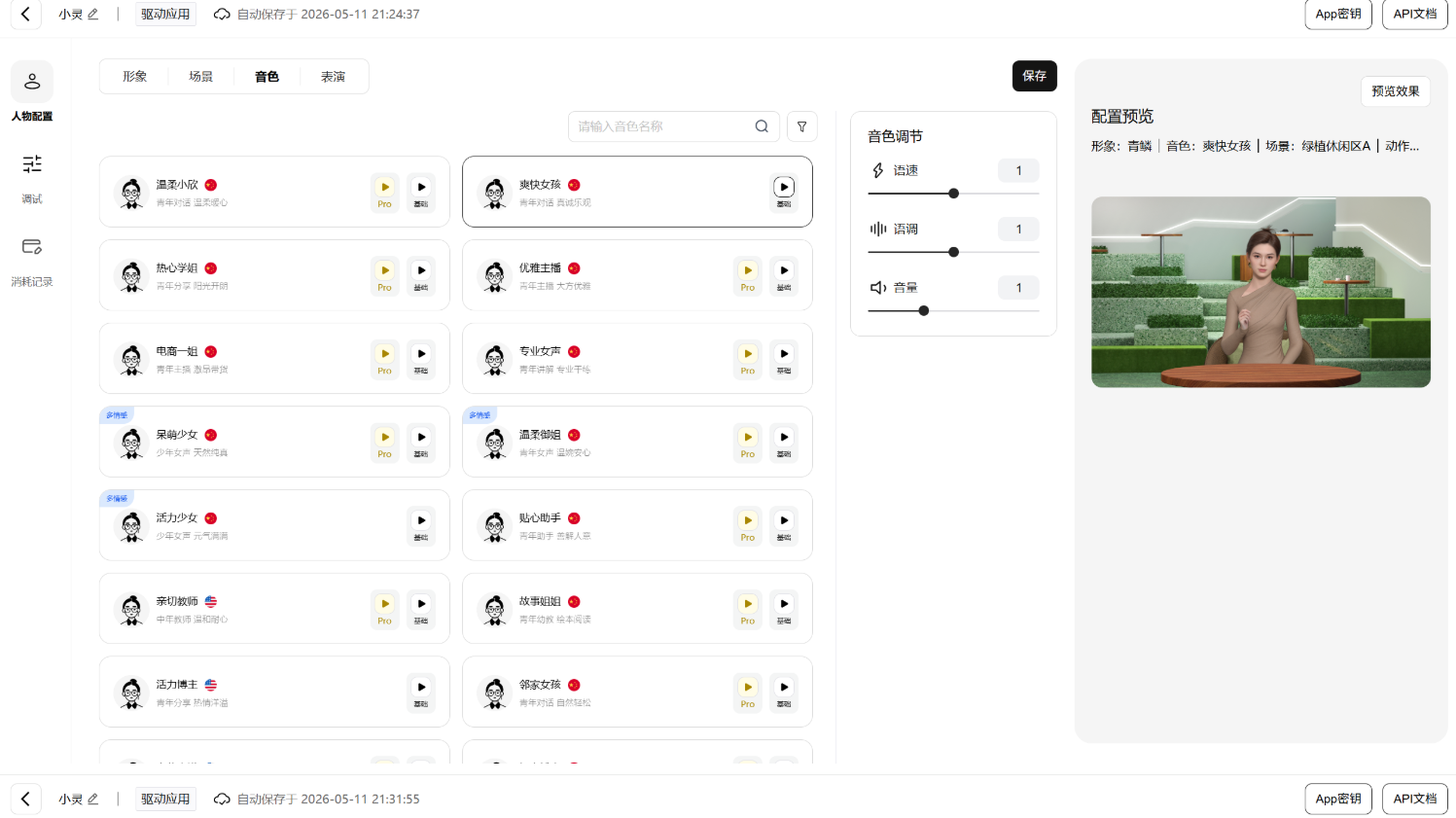
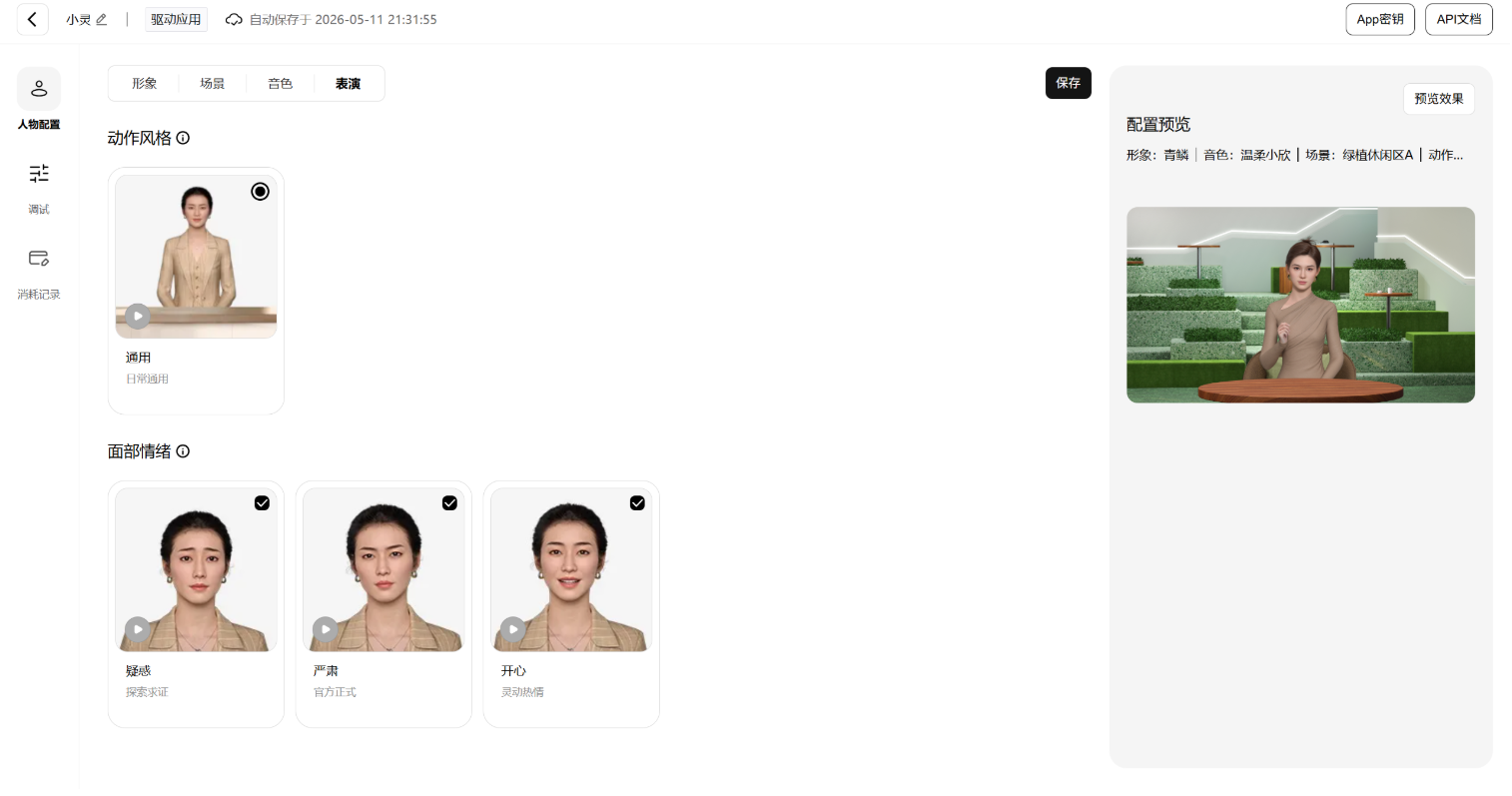
2.完成之后,退出能看到你的App ID和App Secret
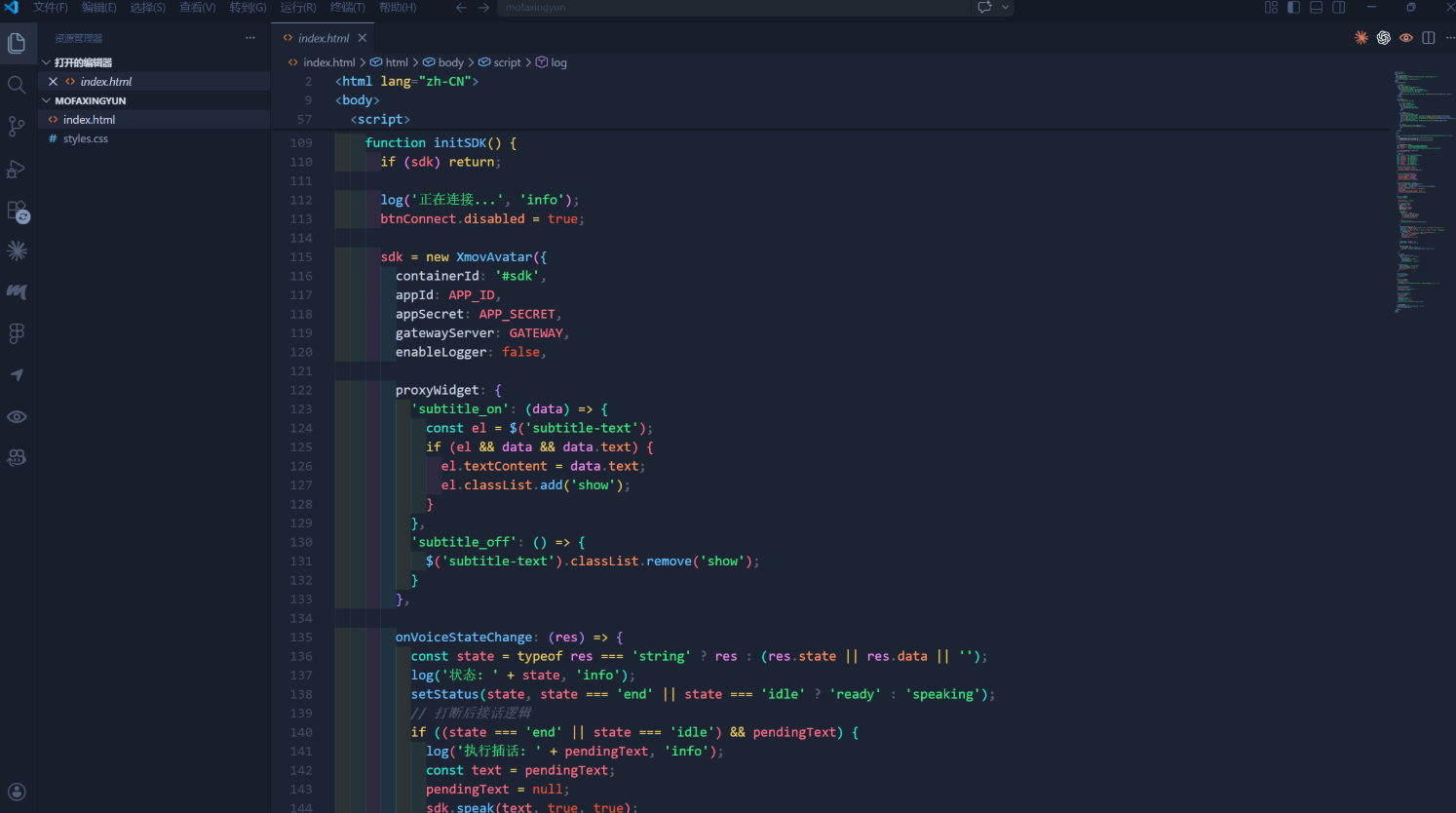
页面准备一个数字人容器,引入 JS SDK,然后创建 XmovAvatar 实例,配置 containerId、appId、appSecret、gatewayServer 等参数。下面是示意代码,真实项目按官方文档和自己的密钥来写,密钥别公开。
plain
sdk = new XmovAvatar({
containerId: '#sdk',
appId: APP_ID,
appSecret: APP_SECRET,
gatewayServer: GATEWAY,
enableLogger: false,
proxyWidget: {
'subtitle_on': (data) => {
const el = $('subtitle-text');
if (el && data && data.text) {
el.textContent = data.text;
el.classList.add('show');
}
},
'subtitle_off': () => {
$('subtitle-text').classList.remove('show');
}
},
我第一次跑的时候,最先遇到的问题不是 SDK,而是容器比例。随手写了个 div,数字人出来之后有点挤。这也说明具身 Agent 的体验不只看模型,前端容器、画面比例、字幕位置、角色大小,都会影响像不像一个正在服务你的人。
让它开口:最难的不是 API,是别让它像 PPT
数字人显示出来以后,下一步就是让它说话。官方文档里有 interactiveidle()、speak() 这类方法,用来切换状态和控制实时表达。技术上不算难,真正难的是内容。
我第一次把 LLM 的回答直接传给数字人,体验很糟。不是不能播,是太像 PPT。
用户问:"这个东西适合什么场景?"
LLM 很自然地答:"该产品适用于展厅接待、智能导购、教育培训、客服售后等多个业务场景......"
文字看着没问题。但数字人一本正经地念出来,像发布会主持人在背稿。这个瞬间我大概明白了:文本 Agent 的回答,不能原封不动交给具身 Agent。
给人看的文本,和给数字人说出来的话,不是一回事。
所以我改了 Prompt。重点不是让它更完整,而是让它更像人说话。
plain
你是一名 AI 产品顾问,负责用口语向用户介绍产品。
要求:
1. 不要写成说明书。
2. 每次回答控制在 80 字以内。
3. 少用"首先、其次、综上"。
4. 可以有轻微停顿感。
5. 如果用户问题很宽泛,先给一个方向,再引导用户继续问。
改完后,同一个问题可以变成,我觉得最适合三类地方:展厅、门店,还有培训屏。因为这些地方不只是展示信息,还需要有人解释、引导。
这句话不华丽,但数字人说出来顺很多。
这里还有一个小细节:语速。稍快一点像播报,稍慢一点像卡住。数字人比普通 TTS 更敏感,因为它多了脸、嘴型和动作。一个普通语音助手念得奇怪,你可能还能忍;一个数字人带着表情念得奇怪,尴尬感会被放大。
具身 Agent 的输出,不应该只有 text
做到这里,我发现原来的 Agent 输出结构不够用了。以前只要返回一段 answer 就行,现在最好能返回一组适合表达的参数:文本、情绪、动作、语气、字幕、是否展示图片,甚至是否需要追问。
比如这样:
plain
{
"text": "这个方案,我觉得更适合门店导购。",
"emotion": "friendly",
"action": "explain",
"subtitle": true,
"is_start": true,
"is_end": true
}前端再把这组信息交给 SDK:
plain
async function avatarSpeak(block) {
if (!sdk) return
sdk.interactiveidle()
await sdk.speak(
block.text,
block.is_start ?? true,
block.is_end ?? true
)
}这个地方能看出具身 Agent 和文本 ChatBot 的分水岭。文本 ChatBot 追求回答准确、完整、逻辑顺;具身 Agent 还要考虑怎么说、什么时候说、配什么动作、能不能被打断、字幕怎么出现、用户下一步怎么接。
官方 SDK 文档里也提到 Widget 组件展示、自定义事件回调等能力。放到具身 Agent 里,这些不是简单 UI 功能,而是表达的一部分。数字人在解释产品时,旁边弹出图卡;讲步骤时出现 PPT;回答问题时显示字幕。这些东西一起工作,才像一个完整的交互界面。

为什么 LLM + TTS + 渲染拼起来,还是不像人?
很多人做数字人 Agent,会自然想到三段式:LLM 负责回答,TTS 负责说话,渲染引擎负责让人物动起来。听起来合理,但真正测下来,问题就出在拼。
LLM 说得太书面,TTS 像播音腔,口型跟不上,动作和语义没关系,表情一直微笑。每个模块单独看都没错,合在一起就很假。像几个部门在同一个屏幕上轮流上班。
所以我觉得,具身 Agent 的关键不只是多一个数字人形象,而是把认知和表达之间的链路打通。自研文生 3D 多模态大模型、AI 端渲、语音、表情、动作联动,最后都是为了让 AI 的回答变成一个可感知的表达过程。
当然,具身 Agent 做不好会更尴尬。文字回答差一点,用户可能只是觉得啰嗦;数字人动作假一点、嘴型慢一点、语音腔重一点,用户会直接出戏。但这也说明,它进入的是更接近真实交互的区域。
我选的测试场景:门店 / 展厅导购
为了不泛泛而谈,我把测试场景定成了AI 产品顾问,更具体一点,就是门店或展厅里的导购讲解员。这个场景刚好适合对比文本 Agent 和具身 Agent,因为它不是单纯查资料,也不是闲聊,而是需要引导用户继续往下走。
纯文本 Agent 在这里的问题很明显:它等用户问。用户如果不知道问什么,就结束了。
具身 Agent 的优势也很明显:它可以先开口。
比如:
"你可以先告诉我,你更关注价格、效果,还是接入难度?"
这句话很普通,但它降低了用户开始互动的成本。很多转化就发生在这种小地方。用户愿不愿意停下来,愿不愿意问第一句,愿不愿意继续追问,愿不愿意留下联系方式,都不是靠一段完美答案决定的,而是靠整个交互过程决定的。
比方说,我文数字人哪家商品的质量更好,它就会给出合理的建议。

我的 Demo 结构大概是这样:
plain
页面左侧:数字人展示区
页面右侧:问题输入区 + 推荐问题
底部:当前状态 / 日志
后端:LLM 生成口语化回答
前端:调用星云 SDK 驱动数字人播报推荐问题可以设置成:
plain
1. 这个方案适合什么场景?
2. 和普通 ChatBot 有什么区别?
3. 开发者接入难吗?
4. 如果我要做一个门店导购,应该怎么设计?用户问"和普通 ChatBot 有什么区别?"我希望数字人不要回答成百科,而是说:
"ChatBot 更像输入框,你问它才答。具身 Agent 会主动出现在屏幕里,用语音、表情和动作解释问题。放在门店或展厅里,用户更容易开始第一轮互动。"
这段话不复杂,但更适合被说出来。
10|为什么同样业务场景,具身智能体可能转化更高?
这里不能简单说"有数字人,所以转化一定更高"。真实转化要看场景、内容、用户意图和产品本身。但从交互机制看,具身智能体确实更容易提高一些关键机会。
第一,它更容易吸引停留。一个会动、会说、会主动出现的角色,比一个输入框更容易让用户多看几秒。很多线下屏幕的第一步不是成交,是让人停下来。
第二,它更容易降低提问门槛。纯文本 Agent 要求用户组织语言,具身 Agent 可以先给选项、先引导方向、先抛出问题。用户不需要一开始就知道自己要问什么。
第三,它更容易建立信任感。用户不一定真的相信它是人,但语音、表情、节奏会让服务感更强。尤其是金融、医疗、教育、导购这些需要解释的场景,一段文字和一个"正在讲给你听"的角色,感受不一样。
第四,它更适合复杂产品讲解。文字堆多了没人看,宣传视频又不能互动。具身 Agent 可以边讲边根据用户反馈调整方向,这一点是它和传统视频的区别。
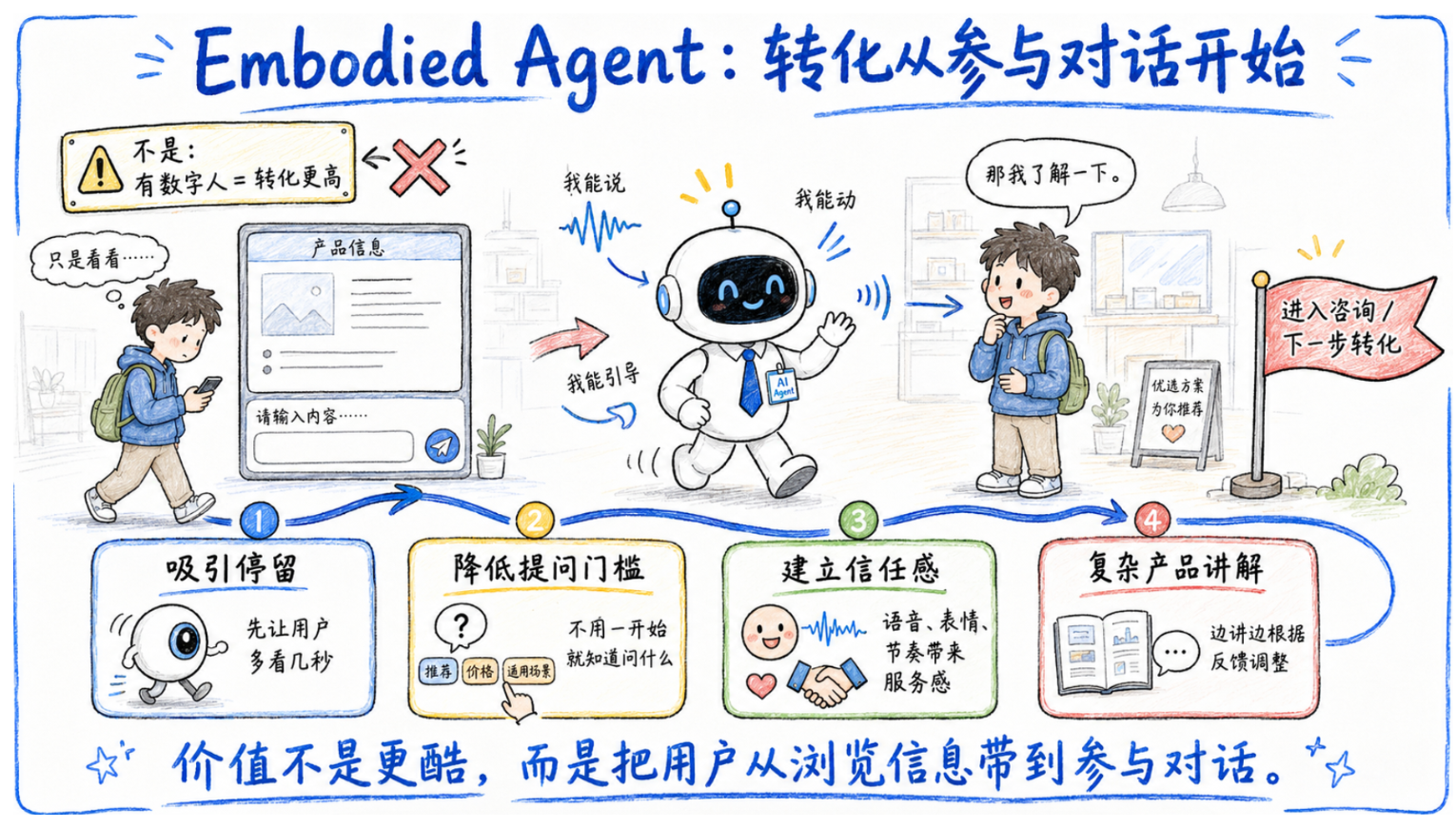
所以具身 Agent 的价值不是更酷,而是把用户从浏览信息带到参与对话。这一步如果发生了,后面的转化才有空间。
最后 Demo 跑起来的时候,我盯着屏幕看了一会儿。数字人站在那里,等我输入问题。它当然不是真的人,也没有真的理解我。但它已经不太像一个聊天框了。
下一次再看到屏幕正中间写着"请输入您的问题",我可能会有点不耐烦。
它明明可以先开口的。
魔珐星云官网:++https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc121++
文章出自:IvanCodes
原文链接:https://ivancodes.blog.csdn.net/article/details/160986904