"猫"与向量的关系与衍生
这里我们以猫引出词向量,再引出向星数据库的概念,通过这一个小小的演示,大家就能快速掌握词向量与向量数据库。
平时有养猫或者熟悉猫的小伙伴对于下面这一张猫的品类图,很快就能区分出它们的品种,之所以能做到这点,是因为我们会从不同的角度来观察这些猫的特征,如下:

如果我们使用一个水平轴来表示体型大小这个特征,这些不同品种的猫将落在不同的坐标点上,这样就可以通过体型的大小区分出一些品种,如下:
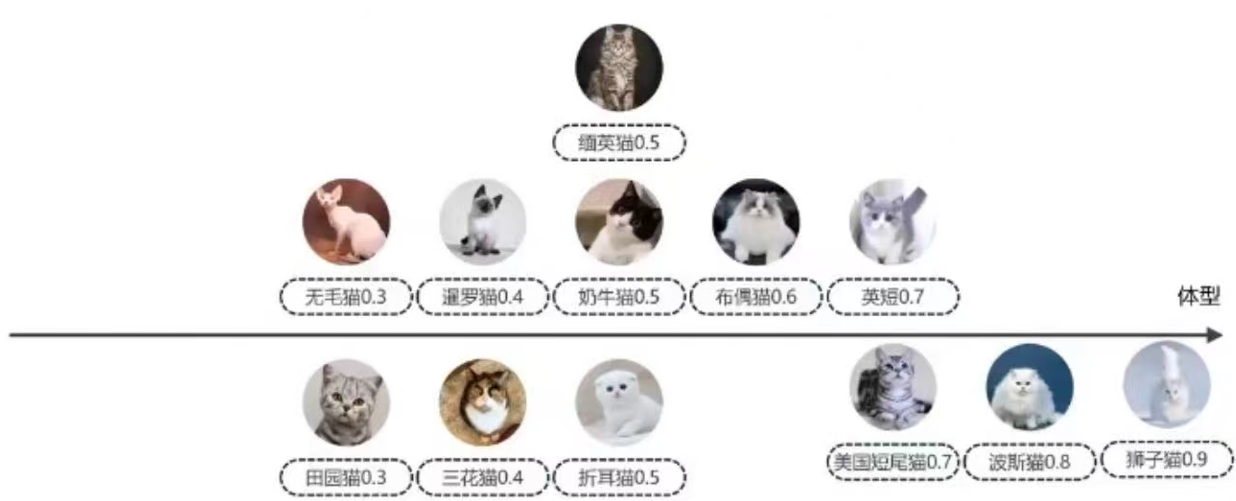
然而,如果仅仅靠体型一个特征,依旧会有很多品种的猫特征相近,比如缅英猫、奶牛猫和折耳猫就非常接近,所以我们继续添加多一个特征,比如毛发的长短,继续建立一个毛发的垂直轴,这样子就可以区分出更多品种。
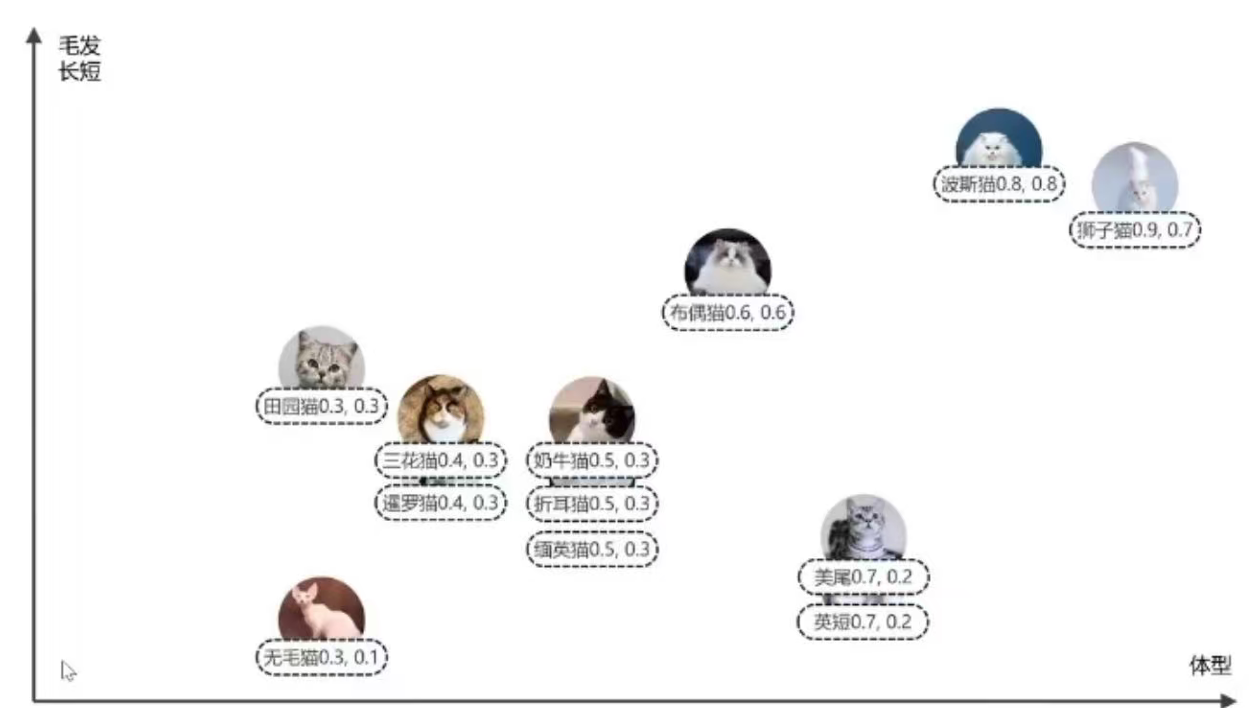
现在每个品种的猫就可以表示为一个二维的坐标点,但是哪怕有两个特征,仍然会有吊种无法区分。
所以我们需要从更多的角度来观察,例如腿的长短,这个时候在建立一个腿的长短的z轴,又有更多的品种被区分出来,现在每个品种的猫就可以表示为一个三维的坐标点,如下:
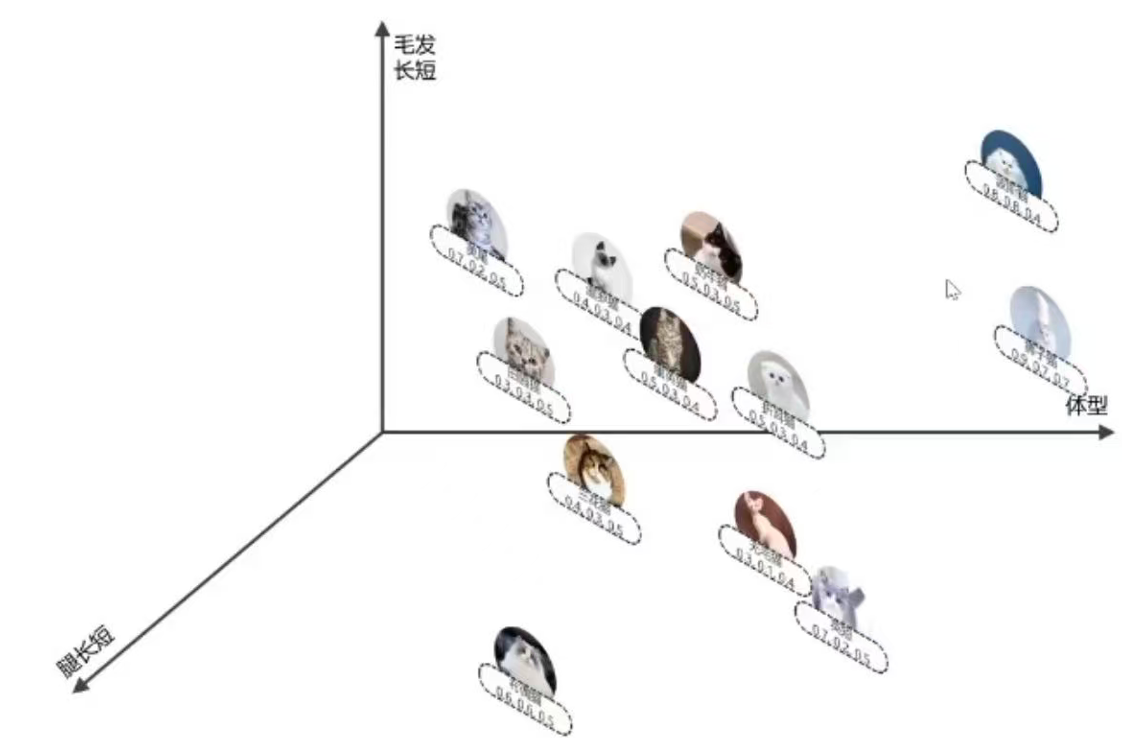
如果这个时候还想引入更多的特征进行区分,比如:眼晴大小、尾巴长短、毛发颜色、声音大小、耳朵形状等等,虽然在坐标图上没法展示出来,但是我们却可以很轻松地将这些特征使用数值的方式展示出来,例如下方:
python
1.遥罗猫:(0.4,0.3,0.4,0.5,0.3,0.4,0.5,...)
2.英国短毛猫:(0.7,0.2,0.5, 0.5,0.5,0.5,0.5,...)
3.间猫:(0.5, 0.3, 0.4, 0.5, 0.3, 0.4, 0.5, ...)
4.波斯猫:(0.8,0.8,0.4,0.8,0.7,0.4,0.6, ...)
5.布偶猫:(0.7, 0.6, 0.5, 0.8, 0.5, 0.4, 0.5, ...)
6.无毛猫:(0.6, 0.1, 0.4, 0.5, 0.3, 0.4, 0.5, ...)
7.中华田园猫:(0.5, 0.3, 0.5, 0.5, 0.5, 0.4, 0.5, ...)
8.折耳猫:(0.6, 0.3, 0.4, 0.5, 0.3, 0.4, 0.7, ...)
9.三花猫:(0.5, 0.3, 0.5, 0.5, 0.5, 0.5, 0.5, ...)
10.美国短毛猫:(0.7, 0.2, 0.5, 0.5, 0.5, 0.5, 0.5, ...)
11.狮子猫:(0.9, 0.7, 0.7, 0.8, 0.7, 0.8, 0.5, ...)
12.奶牛猫:(0.6, 0.3, 0.5, 0.5, 0.5, 0.4, 0.5, ...)当记录的特征足够大,维度足够大时,区分的程度也会越高,当看到一只猫,只需要将它转换成对应的多维坐标数据 / 向量,就可以很轻松地找到这只猫的分类归属,而且不仅仅是猫,几乎所有的事物都可以使用这一套方式进行表达。
所以一个字、一个词、一句话、一篇文本、甚至一张图片都可以用这样一个多维坐标数据,亦或者说 向量 记录对应的特征,而将文本转换为记录特征的向量就可以被称为词向量。
向量数据库概念与用途
向量数据库就是一种专门用于存储和处理向量数据的数据库系统,传统的关系型数据库通常不擅长处理向量数据,因为它们需要将数据映射为结构化的表格形式,而向量数据的维度较高、结构复杂,导致传统数据库存储和查询效率低下,所以向量数据库应运而生。
由于高维的向量我们在三维空间没法绘图,这里我们以二维向量的形式扩展到多维,来一起看下向量的神通广大之处!
例如下图,在二维坐标上,概念上更接近的点,在图表上也更聚集,而那些概念上不同的点则一般距离比较远。
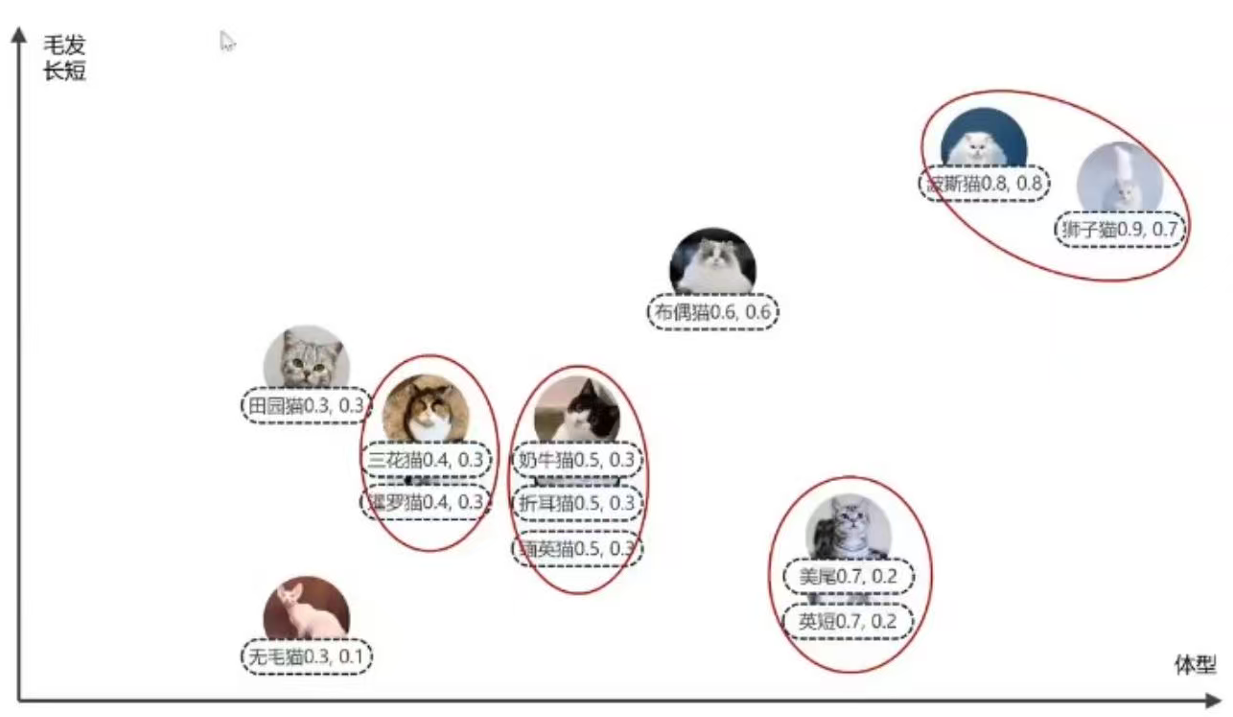
如果将两个点之间作差,得到一条新的向量,甚至我们可以使用这条结果向量来表示两个点之间的关联(越短表示关联越大),相比传统的数据库,向量数据库针对向量距离/相似度计算进行了特定的优化,如下:
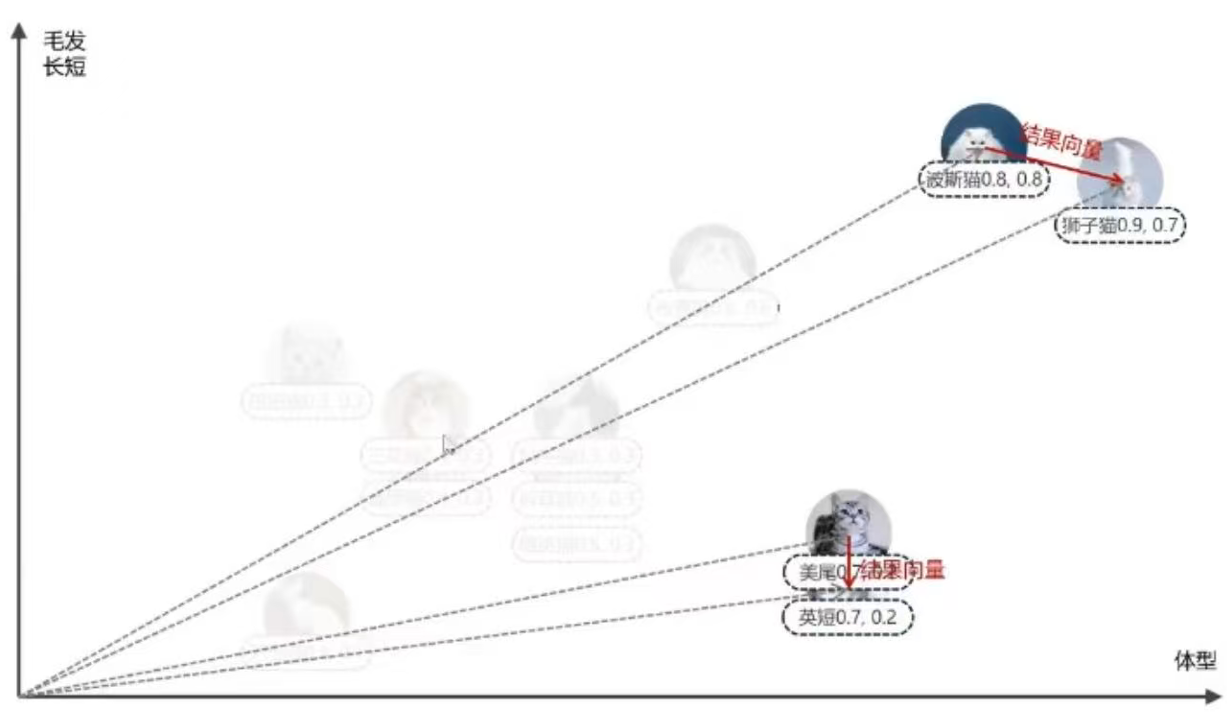
所以最常见的应用就是人脸识别,将不同的人脸归一化(固定大小)后生成对应的向量,然后将千千万万张人脸的向量进行存储。进行人脸识别时,只需要将这张人脸按照统一的标准归一化并转换成向量,接下来在向量数据库中搜索与这个向量最接近的向量,就可以巧妙实现人脸识别。
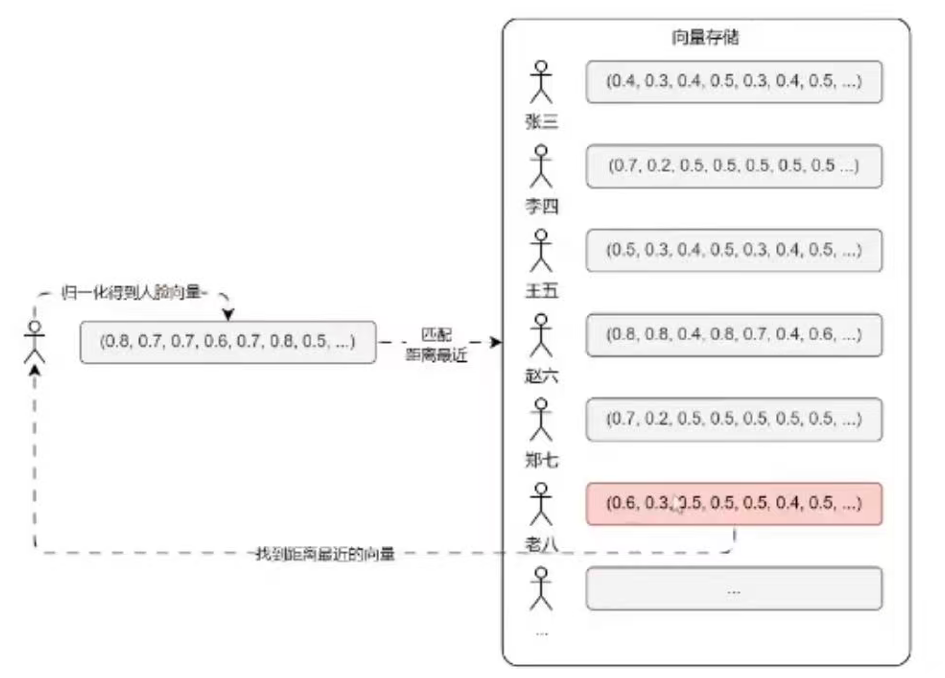
这也是向量数据库的最常使用场景:人脸识别、图像搜索、音频识别、智能推荐系统等。
而在RAG中,我们将对应的知识文档按照特定的规则拆分成合适的大小,再转换成向量存储到向量数据库中,当人类提问时,将人类提问query转换成向量并进行搜索,找到在特征上更接近的文本块,这些文本块就可以看成和query具有强关联或者说有因果关系。
这样就可以将这些文本块作为这次提问的额外补充知识,让LLM基于补充知识+提问生成对应的内容,从而实现知识库问答。
传统数据库与向量数据库的使用差异
两种数据库的差异
搜索方式差异
传统数据库,比如关系型数据库,擅长处理结构化数据,如存储在表格中的文本和数字等。它们通过预定义的查询语言(如SQL)来进行精确匹配或条件搜索。这种方式在处理银行交易、客户信息等数据时效果显著,但在处理复杂的模式识别问题时就显得力不从心。
例如,通过 sELECT + wHERE 可以精准查询到id为e0d13c78-870b-46df-b2f5-693ae9d5d727 的用户.
php
SELECT * FROM account WHERE id='e0d13c78-870bT46df-b2f5-693ae9d5d727'但是想通过SQL来查询和我喜欢打篮球游泳与编程这句话语义相近的内容,就无能力为了。
相比之下,向量数据库不是通过匹配确切的数值,而是通过一种称为相似性搜素的方法来工作。它们可以快速找到与查询向量最相似的数据点(目前绝大部分向量数据库都支持在相似性搜索的基础上添加筛选条件),即使这些数据点在数值上并不完全相同。
例如,在一个向量数据库中,即使没有完全相同的照片,我们仍然可以找到风格相似的图片。通过这种方式,向量数据库打破了传统数据库的局限,为处理和分析大规模、复杂的数据提供了更灵活和强大的解决方案。
数据处理与存储差异
传统数据库采用基于行的存储方式,传统数据库将数据存储为行记录,每一行包含多个字段,并且每个字段都有固定的列。传统数据库通常使用索引来提高查询性能,例如下方就是一个典型的传统数据库表格:
| 电影ID | 电影名称 | 导演 | 类型 | 评分 |
|---|---|---|---|---|
| 1 | 阿凡达 | 詹姆斯-卡梅隆 | 科幻/冒险 | 8.8 |
| 2 | 飞屋环游记 | 皮特-道格特 | 动画/冒险 | 8.2 |
| 3 | 泰塔尼克号 | 詹姆斯-卡梅隆 | 爱情/剧情 | 7.8 |
这种方式在处理结构化数据时非常高效,但在处理非结构化或半结构化数据时效率低下。
向量数据库将数据以列形式存储,即每个列都有一个独立的存储空间,这使得向量数据库可以更加灵活地处理复杂的数据结构。向量数据库还可以进行列压缩(稀疏矩阵),以减少存储空间和提高数据的访问速度。
并且在向量数据库中,将数据表示为高维向量,其中每个向量对应于数据点。这些向量之间的距离表示它们之间的相似性。这种方式使得非结构化或半结构化数据的存储和检索变得更加高效。
以电影数据库为例,我们可以将每部电影表示为一个特征向量。假设我们使用四个特征来描述每部电影:动作、冒险、爱情、科幻。每个特征都可以在0到1的范围内进行标准化,表示该电影在该特征上的强度。
例如,电影"阿凡达"的向量表示可以是0.9,0.8,0.2,0.9,其中数字分别表示动作、冒险、爱情、科幻的特征强度。其他电影也可以用类似的方式表示。这些向量可以存储在向量数据库中,如下所示:
| 电影ID | 特征向量 |
|---|---|
| 1 | 0.9,0.8,0.2,0.9 |
| 2 | 0.7,0.9,0.1,0.2 |
| 3 | 0.2,0.1,0.9,0.1 |
现在,如果我们想要查找与电影"阿凡达"相似的电影,我们可以计算向量之间的距离,找到最接近的向量,从而实现相似性匹配,而无需复杂的SQL查询。这就像使用地图找到两个地点之间的最短路径一样简单。
优缺点横向对比
尽管向量数据库在处理高维度数据和实现快速检索方面有着显著优势,但它并不是一种"一刀切"的解决方案。在某些应用场景中,其他类型得到数据库可能更合适,而且向量数据库与传统关系数据库协同发展,相互补充。
| 对比项 | 传统的关系型数据库 | 向量数据库 |
|---|---|---|
| 数据类型 | 数值、字符串、时间等传统数据类型 | 新的数据类型:向量数据 不存储原始数据(有的也支持) |
| 数据规模 | 小,1亿条数据对于关系型数据库来说规模很大 | 大,最少千亿数据是底线 |
| 数据组织方式 | 基于表格,按照行和列组织 | 基于向量,按照向量维度组织 |
| 查找方式 | 精确查找:点查/范围查 查询结果要么符合条件要么不符合条件 | 近似查找 查询结果是与输入条件最相似的,近似计算能力要求较高 |
| 低延时,高并发 | 否 | 是 |
| 上层应用 | 较弱 | 对外提供统一的API,更适合大规模AI应用程序的部署和使用 |
| 下游应用场景 | 央企、国企。央企国企工作因工作内容要求 容错率低,传统数据库能够提供更为准确 的搜索结果。 | 互联网公司。向量数据库的结果正确率相对较低, 成本低,互联网公司的场景容错率较高, 能够包容这一缺陷。 |
相似性搜索算法
余弦相似度与欧式距离
在向量数据库中,支持通过多种方式来计算两个向量的相似度,例如:余弦相似度、欧式距离、曼哈顿距离、闵可夫斯基距离、汉明距离、Jaccard 相似度等多种。其中最常见的就是 余弦相似度 和 欧式距离。
例如下图,左侧就是欧式距离,右侧就是余弦相似度。
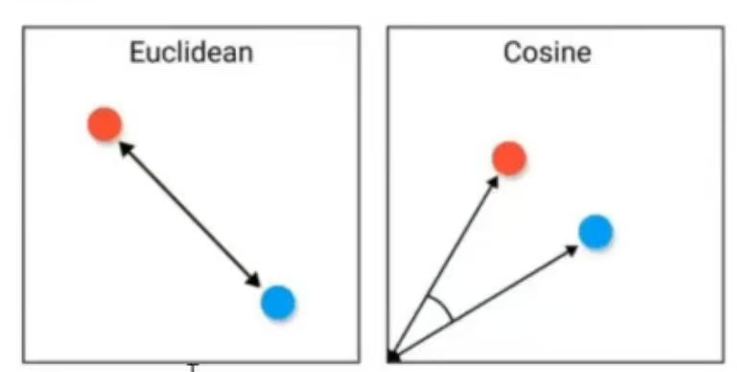
① 余弦相似度主要用于衡量向量在方向上的相似性,特别适用于文本、图像和高维空间中的向量。它不受向量长度的影响,只考虑方向的相似程度,余弦相似度的计算公式如下(计算两个向量夹角的余弦值,取值范围为 -1, 1):
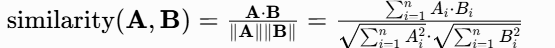
② 欧式距离衡量向量之间的直线距离,得到的值可能很大,最小为 0,通常用于低维空间或需要考虑向量各个维度之间差异的情况。欧氏距离较小的向量被认为更相似,欧式距离的计算公式如下:
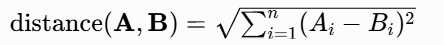
相似性搜索加速计算
在向量数据库中,数据按列进行存储,通常会将多个向量组织成一个MxN的矩阵,其中M是向量的维度(特征数),N是向量的数量数据库中的条目数),这个矩阵可以是稠密或者稀疏的,取决于向量的稀疏性和具体的存储优化策略。
这样计算相似性搜索时,本质上就变成了向量与MxN矩阵的每一行进行相似度计算,这里可以用到大量成熟的加速算法:
- 矩阵分解方法:
- SVD(奇异值分解):可以通过奇异值分解将原始矩阵转换为更低秩的矩阵表示,从而减少计算量。
- PCA(主成分分析):类似地,可以通过主成分分析将高维矩阵映射到低维空间,减少计算复杂度
- 索引结构和近似算法:
- LSH(局部敏感哈希):LSH可以在近似相似度匹配中加速计算,特别适用于高维稀疏向量的情况。
- ANN(近似最近邻)算法:ANN算法如KD-Tree、Bal-Tree等可以用来加速对最近邻搜索的计算,虽然主要用于向量空间,但也可以部分应用于相似度计算中。
- GPU加速:使用图形处理单元(GPU)进行并行计算可以显著提高相似度计算的速度,尤其是对于大规模数据和高维度向量。
- 分布式计算:由于行与行之间独立,所以可以很便捷地支持分布式计算每行与向量的相似度,从而加速整体计算过程。
向量数据库底层除了在算法层面上针对相似性搜索做了大量优化,在存储结构、索引肌制等方面均做了大量的优化,这才使得向量数据库
在处理高维数据和实现快速相似性搜索上展示出巨大的优势。
Embedding嵌入模型介绍与使用
什么是Embedding
要想使用向量数据库的相似性搜索,存储的数据必须是向量,那么如何将高维度的文字、图片、视频等非结构化数据转换成向量呢?这个时候就需要使用到Embedding嵌入模型了,例如下方就是Embedding嵌入模型的运行流程:
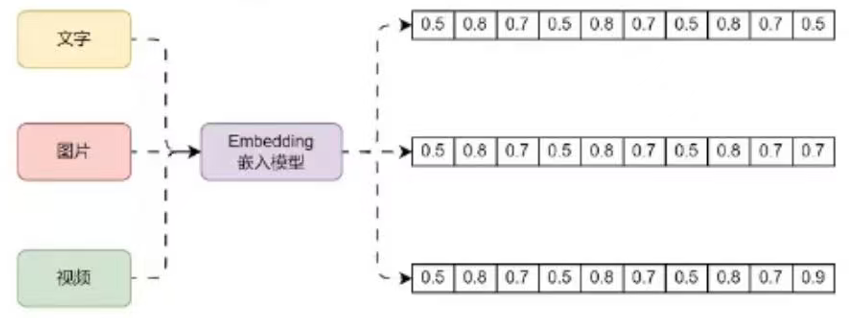
Embeding模型是一种在机器学习和自然语言处理中广泛应用的技术,它旨在将高纬度的数据(如文字、图片、视频)映射到低纬度的空间。Embedding向量是一个N维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。这种嵌入可以是一个词、一个类别特征(如商品、电影、物品等)或时间序列特征等。
而且通过学习,Embedding向量可以更准确地表示对应特征的内在含义,使几何距离相近的向量对应的物体有相近的含义,甚至对向量进行加减乘除算法都有意义!
一句话理解Embeding:一种模型生成方法,可以将非结构化的数据,例如文本/图片/视频等数据映射成有意义的向量数据。目前生成embedding
方法的模型有以下4类:
- Word2Vec(词嵌入模型):这个模型通过学习将单词转化为连续的向量表示,以便计算机更好地理解和处理文本。Word2Vec模型基于两种主要算法cBow和skip-gram
- Glove:一种用于自然语言处理的词嵌入模型,它与其他常见的词嵌入模型(如Word2Vec和FastText)类似,可以将单词转化为连续的向量表示。GloVe模型的原理是通过观察单词在语料库中的共现关系,学习得到单词之间的语义关系。具体来说,GloVe模型将共现概率矩阵表示为两个词向量之间的点积和偏差的关系,然后通过迭代优化来训练得到最佳的词向量表示。
GloVe模型的优点是它能够在大规模语料库上进行有损压缩,得到较小维度的词向量,同时保持了单词之间的语义关系。这些词向星可以被用于多种自然语言处理任务,如词义相似度计算、情感分析、文本分类等。 - FastText:一种基于词袋模型的词嵌入技术,与其他常见的词嵌入模型(如 Word2Vec和GloVe)不同之处在于,FastText考虑了单词的子词信息。其核心思想是将单词视为字符的n-grams的集合,在训练过程中,模型会同时学习单词级别和n-gram级别的表示。这样可以捕捉到单词内部的细粒度信息,从而更好地处理各种形态和变体的单词。
- 大模型Embeddings (重点):和大模型相关的嵌入模型,如OpenAI官方发布的第二代模型:text-embedding-ada-002。它最长的输入是8191个tokens,输出的维度是1536。
Embedding带来的价值
- 降维:在许多实际问题中,原始数据的维度往往非常高。例如,在自然语言处理中,如果使用 Token 词表编码来表示词汇,其维度等于词汇表的大小,可能达到数十万甚至更高。通过 Embedding,我们可以将这些高维数据映射到一个低维空间,大大减少了模型的复杂度。
- 捕捉语义信息:Embedding 不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。例如,在词嵌入中,语义上相近的词在向量空间中也会相近。这意味着 Embedding 可以保留并利用原始数据的一些重要信息。
- 适应性:与一些传统的特征提取方法相比,Embedding 是通过数据驱动的方式学习的。这意味着它能够自动适应数据的特性,而无需人工设计特征。
- 泛化能力:在实际问题中,我们经常需要处理一些在训练数据中没有出现过的数据。由于 Embedding 能够捕捉到数据的一些内在规律,因此对于这些未见过的数据,Embedding 仍然能够给出合理的表示。
- 可解释性:尽管Embedding是高维的,但我们可以通过一些可视化工具(如t-SNE)来观察和理解Embedding的结构。这对于理解模型的行为,以及发现数据的一些潜在规律是非常有用的。
Embedding的运算法则
通过对上文的理解,我们继续看看训练好的词向量实例(也被称为词嵌入),并探索他们的一些有趣属性(一个当成是玩笑的例子,主要用于帮助大家更好去理解 Embedding,该例子在其他 Embedding 模型下不一定能复现)。
这是一个 "king" 词的嵌入(使用 GloVe 方法生成的向量):
python
[0.50451, 0.68607, -0.59517, -0.022801, 0.60046, -0.13498, -0.08813, 0.47377, -0.61798, -0.31012, -0.076666,
1.493, -0.034189, -0.98173, 0.68229, 0.81722, -0.51874, -0.31503, -0.55809, 0.66421, 0.1961, -0.13495,
-0.11476, -0.30344, 0.41177, -2.223, -1.0756, -1.0783, -0.34354, 0.33505, 1.9927, -0.04234, -0.64319,
0.71125, 0.49159, 0.16754, 0.34344, -0.25663, -0.8523, 0.1661, 0.40102, 1.1685, -1.0137, -0.21585, -0.15155,
0.78321, -0.91241, -1.6106, -0.64426, -0.51042]这是一个 50 维的向量,通过数字我们很难观察其规律,但是我们可以将这个向量的每一个元素进行可视化颜色编码,由于范围是 -2, 2,越靠近 -2 则设置成蓝色,越靠近 2 则设置成红色,那么这一串向量就可以表示成这样:

我们忽略数字仅查看颜色,并且将 "King" 与其他单词进行比较(King 国王、Man 男人、Woman 女人):
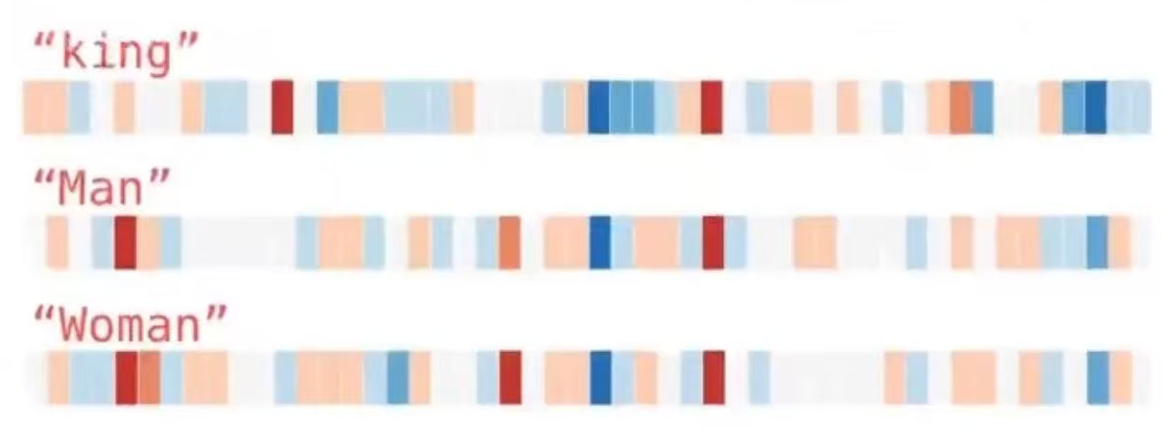
从色块分布图中,可以很容易的看出King、Man、Woman这三组向量的结构其实非常接近,色块颜色非常集中,这是否能意味着国王、男人、女人这三个词之间是具有强关联甚至是子集的因果关系。
接下来看下另外一个示例列表,这个示例展示了更多单词的向量分布的规律:
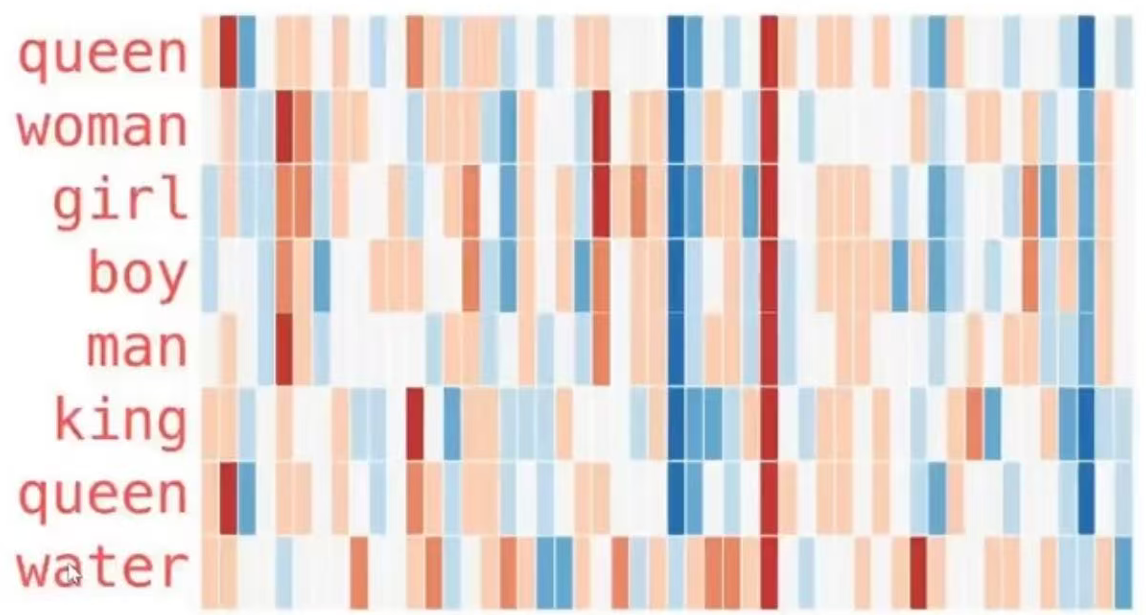
在这张分布图中也可以轻松看出一些信息:
- 这几个单词的词向量在中间都有一条直的红色列,代表它们在这个维度上是相似的,但是从数值来看我们看不出这个维度是什么。
- woman和girl在很多地方都是相似的,man和boy也一样。
- girl和boy也有一些彼此相似的地方,但这些和woman/girl不同,这些差异是否可以总结出"年龄"这个维度?
- 上面的单词中,除了water其他的都和人相关,并且向量的倒数第三个元素是一个蓝色的色块,来到water这里却消失了。
- king和queen非常接近,但是存在一些比较明显的差异,这部分差异是否能体现出"性别"这个维度?除了单个词的向量能展示出一些有意思的信息,对向量进行加减乘除也能得到一些有意思的结果。在NLP界有一个非常著名的公式:
python
Queen = King - Man + Woman女王=国王-男人+女人对这几个向量进行运算后,同样可视化出来,结果如下:
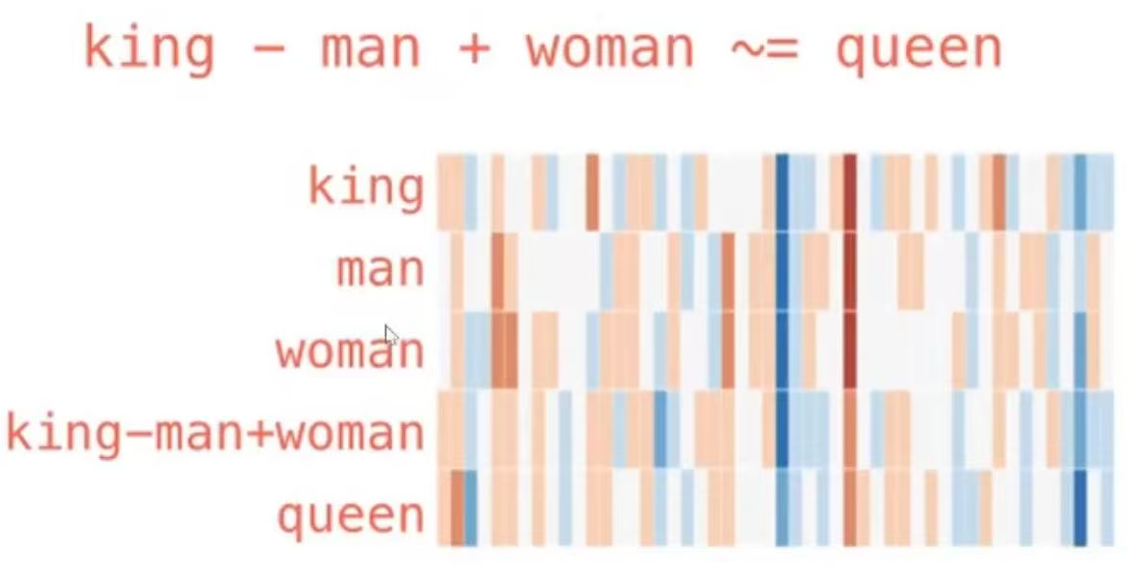
你会发现 king-man+woman和queen 的向量特征分布非常接近,也是GloVe集合中40w 个字嵌入中最接近它的词。
这一个示例虽然不一定是一个正确的思路,但是从这个示例中仍然可以看到将对应的词转换成Embeding向量后,嵌入模型能够捕捉到数据的语义信息,并且语义上相近的词在向量空间中也会相近,这也为语义搜索提供了一个可能。
OpenAI Embedding接口使用实践测试
OpenAI Embedding嵌入模型
OpenAI 服务提供商提供了线上的 Embeddings 服务,涵盖了 3 种模型,信息对比如下:
| 模型 | 1美元支持嵌入文档数 单文档800Token | 性能评估 | 最大输入 | 向量维度 |
|---|---|---|---|---|
| text-embedding-3-small | 62500 | 62.3% | 8191 | 1536(可修改) |
| text-embedding-3-large | 9615 | 64.6% | 8191 | 3072(可修改) |
| text-embedding-ada-002 | 12500 | 61.0% | 8191 | 1536 |
OpenAI 的 Embeddings 嵌入模型虽然是市面上效果最好的嵌入模型,虽然价格非常低廉,不过由于没有本地版本,而且接口响应速度相对较慢,在需要对大量文档进行嵌入时,效率非常低,所以国内使用得并不多(国内一般会使用对应的本地或者本地服务提供商的嵌入模型)。
OpenAI Embeddings 官网文档:https://platform.openai.com/docs/guides/embeddings
Embedding 组件使用
在 LangChain 中,Embeddings 类是一个专为与文本嵌入模型交互而设计的类,这个类为许多嵌入模型提供商(如 OpenAI、Cohere、Hugging Face 等)提供一个标准的接口。
LangChain 中 Embeddings 类提供了两种方法:
- embed_documents:用于嵌入文档列表,传入一个文档列表,得到这个文档列表对应的向量列表。
- embed_query:用于嵌入单个查询,传入一个字符串,得到这个字符串对应的向量。
并且Embeddings类并不是一个Runnable组件,所有并不能直接接入到Runnable序列链中,需要额外的RunnableLambda函数进行转换,核心基类代码也非常简单:
python
class Embeddings(ABC):
"""Interface for embedding models."""
@abstractmethod
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Embed search docs."""
@abstractmethod
def embed_query(self, text: str) -> List[float]:
"""Embed query text."""
async def aembed_documents(self, texts: List[str]) -> List[List[float]]:
"""Asynchronous Embed search docs."""
return await run_in_executor(None, self.embed_documents, texts)
async def aembed_query(self, text: str) -> List[float]:
"""Asynchronous Embed query text."""
return await run_in_executor(None, self.embed_query, text)如果如果想对接自定义的 Embedding 嵌入模型,其实非常简单,只需实现 embed_documents 和 embed_query 这两个方法即可。
LangChain 使用 OpenAI Embeddings 嵌入模型示例:
python
import dotenv
from langchain_openai import OpenAIEmbeddings
import numpy as np
from numpy.linalg import norm
dotenv.load_dotenv()
def consine_similarity(vec1, vec2) -> float:
"""计算传入两个向量的余弦相似度"""
# 1. 计算两个向量的点积
dot_product = np.dot(vec1, vec2)
# 2. 计算向量的长度
vec1_norm = norm(vec1)
vec2_norm = norm(vec2)
# 3. 计算余弦相似度
return dot_product / (vec1_norm * vec2_norm)
# 1. 创建文本嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 2. 嵌入文本
query_vector = embeddings.embed_query("我叫幕小课,我喜欢打篮球")
print(query_vector)
print(len(query_vector))
# 3.嵌入文档列表/字符串列表
documents_vector = embeddings.embed_documents([
"我叫幕小课,我喜欢打篮球",
"这个喜欢打篮球的人叫幕小课",
"求知若渴,虚心若愚"
])
print(len(documents_vector))
# 计算相似度
print("向量1与向量2的相似度", consine_similarity(documents_vector[0], documents_vector[1]))
print("向量1与向量3的相似度", consine_similarity(documents_vector[0], documents_vector[2]))CacheBackEmbedding使用与场景与注意事项
CacheBackEmbedding使用与场景
通过嵌入模型计算传递数据的向量需要昂贵的算力,对于重复的内容,Embeddings 计算的结果肯定是一致的,如果数据重复仍然二次计算,会导致效率非常低,而且增加无用功。
所以在 LangChain 中提供了一个叫 cacheBackEmbedding 的包装类,一般通过类方法 from_bytes_store 进行实例化,它接受以下参数:
- underlying_embedder:用于嵌入的嵌入模型。
- document_embedding_cache:用于缓存文档嵌入的任何存储库(ByteStore)。
- batch_size:可选参数,默认为 None,在存储更新之间要嵌入的文档数量。
- namespace:可选参数,默认为 "",用于文档缓存的命名空间。此命名空间用于避免与其他缓存发生冲突。例如,将其设置为所使用的嵌入模型的名称。
- query_embedding_cache:可选,默认为 None 或者不缓存,用于缓存查询 / 文本嵌入的 ByteStore,或设置为 True 以使用与document_embedding_cache 相同的存储。
注意事项:CacheBackEmbedding 默认不缓存 embed_query 生成的向量,如果要缓存,需要设置 query_embedding_cache 的值,另外请尽可能设置 namespace,以避免使用不同嵌入模型嵌入的相同文本发生冲突。
使用示例:
python
import dotenv
from langchain.storage import LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
from langchain_openai import OpenAIEmbeddings
import numpy as np
from numpy.linalg import norm
dotenv.load_dotenv()
def consine_similarity(vec1, vec2) -> float:
"""计算传入两个向量的余弦相似度"""
# 1. 计算两个向量的点积
dot_product = np.dot(vec1, vec2)
# 2. 计算向量的长度
vec1_norm = norm(vec1)
vec2_norm = norm(vec2)
# 3. 计算余弦相似度
return dot_product / (vec1_norm * vec2_norm)
# 1. 创建文本嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
embeddings_with_cache = CacheBackedEmbeddings.from_bytes_store(
embeddings,
LocalFileStore('./cache/'),
namespace=embeddings.model,
query_embedding_cache=True
)
# 2. 嵌入文本
query_vector = embeddings_with_cache.embed_query("我叫幕小课,我喜欢打篮球")
print(query_vector)
print(len(query_vector))
# 3.嵌入文档列表/字符串列表
documents_vector = embeddings_with_cache.embed_documents([
"我叫幕小课,我喜欢打篮球",
"这个喜欢打篮球的人叫幕小课",
"求知若渴,虚心若愚"
])
print(len(documents_vector))
# 计算相似度
print("向量1与向量2的相似度", consine_similarity(documents_vector[0], documents_vector[1]))
print("向量1与向量3的相似度", consine_similarity(documents_vector[0], documents_vector[2]))CacheBackEmbedding运行流程
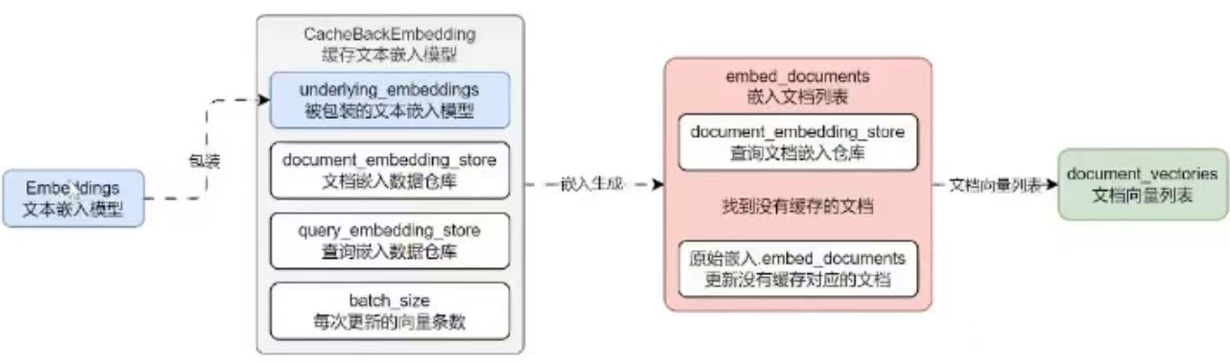
CacheBackEmbedding 底层的运行流程非常简单,本质上就是封装了一个持久化存储的数据存储仓库,在每次进行数据嵌入前,会从前数据存储仓库中检索对应的向量,然后逐个匹配对应的数据是否相等,找到缓存中没有的文本,然后将这些文本调用嵌入生成向量,最后将生成的新向量存储到数据仓库中,从而完成对数据的存储。
运行流程如下:
其他Embedding嵌入模型的配置与使用
Hugging Face文本嵌入模型
在某些对数据保密要求极高的场合下,数据不允许传递到外网,这个时候就可以考虑使用本地的文本嵌入模型 ------Hugging Face 本地嵌入模型,配置的技巧也非常简单,安装 langchain-huggingface 与 sentence-transformers 包,命令如下:
python
pip install -U langchain-huggingface sentence-transformers其中 langchain-huggingface 是 langchain 团队基于 huggingface 封装的第三方社区包,sentence-transformers 是一个用于生成和使用预训练的文本嵌入,基于 transformer 架构,也是目前使用量最大的本地文本嵌入模型。
配置好后,就可以像正常的文本嵌入模型一样使用了,示例:
python
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
query_vector = embeddings.embed_query("你好,我是慕小课,我喜欢打篮球")
print(query_vector)
print(len(query_vector))sentence-transformers 模型加载时,会将模型从本地加载到内存中,首次加载相对会慢,后续调用速度即可恢复正常。
除此之外,使用 Hugging Face 文本嵌入还可以加载任意本地的文本嵌入模型,传递 model_name 与 cache_folder 参数即可,示例:
python
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L12-v2",
cache_folder="./embeddings/"
)
query_vector = embeddings.embed_query("你好,我是慕小课,我喜欢打篮球")
print(query_vector)
print(len(query_vector))HuggingFace 远程嵌入模型
部分模型的文件比较大,如果只是短期内调试,可以考虑使用 HuggingFace 提供的远程嵌入模型,首先安装对应的依赖:
bash
pip install huggingface_hub然后在 Hugging Face 官网(https://huggingface.co/)的 setting 中添加对应的访问秘钥,并配置到 .env 文件中:
bash
HUGGINGFACEHUB_API_TOKEN=xxx接下来就可以使用 Hugging Face 提供的推理服务,这样在本地服务器上就无需配置对应的文本嵌入模型了。
python
import dotenv
from langchain_huggingface import HuggingFaceEndpointEmbeddings
dotenv.load_dotenv()
embeddings = HuggingFaceEndpointEmbeddings(model="sentence-transformers/all-MiniLM-L12-v2")
query_vector = embeddings.embed_query("你好,我是慕小课,我喜欢打篮球")
print(query_vector)
print(len(query_vector))相关资料信息:
Hugging Face 官网: https://huggingface.co/
HuggingFace 嵌入文档: https://python.langchain.com/v0.2/docs/integrations/text_embedding/sentence-transformers/
HuggingFace 嵌入翻译文档: http://imooc-langchain.shortvar.com/docs/integrations/text_embedding/sentence_transformers/
百度千帆文本嵌入模型
如果想对接国内的文本嵌入模型提供商,可以考虑百度千帆,是目前国内生态最好,支持的模型最多(Embedding-V1、bge-large-zh、bge-large-en、tao-8k),速度最快的 AI 应用开发平台。
由于目前百度千帆并没有单独封装到独立的包,可以直接从 langchain_community 中导入,使用示例如下:
python
import dotenv
from langchain_community.embeddings.baidu_qianfan_endpoint import QianfanEmbeddingsEndpoint
dotenv.load_dotenv()
embeddings = QianfanEmbeddingsEndpoint()
query_vector = embeddings.embed_query("我叫慕小课,我喜欢打篮球游泳")
print(query_vector)
print(len(query_vector))相关资料信息:
百度千帆预设模型列表:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vwu
百度千帆嵌入文档:https://python.langchain.com/v0.2/docs/integrations/text_embedding/baidu_qianfan_endpoint/
百度千帆嵌入翻译文档:http://imooc-langchain.shortvar.com/docs/integrations/text_embedding/baidu_qianfan_endpoint/
Faiss向量数据库的配置与使用
目前关于向量数据库的技术进展非常迅速,所以不同服务商提供的向量数据库使用差异非常大,数据的存储结构、支持的相似性检索方式、集合、条件筛选等功能差异也比较大,在 LangChain 中对于向量数据库基类只做了通用性的封装,减轻了部分迁移成本,在使用向量数据库时一定要综合衡量下各个向量数据库的差异。
按照部署方式和提供的服务类型进行划分,向量数据库可以划分成几种:
- 本地文件向量数据库:用户将向量数据存储到本地文件系统中,通过数据库查询的接口来检索向量数据,例如:Faiss。
- 本地部署 API 向量数据库:这类数据库不仅允许本地部署,而且提供了方便的 API 接口,使用户可以通过网络请求来访问和查询向量数据,这类数据库通常提供了更复杂的功能和管理选项,例如:Milvus、Annoy、Weaviate 等。
- 云端 API 向量数据库:将向量数据存储在云端,通过 API 提供向量数据的访问和管理功能,例如:TCVectorDB、Pinecone 等。
要想快速上手向量数据库的使用,只需要把向量数据库看成是 Excel 电子表格使用即可,按照使用办公软件的流程:安装、写入数据、查找数据、删除数据、更新数据、保存数据等相同的流程去学习 + 使用向量数据库即可。
而且向量数据库没有 SQL 数据库这么多复杂的查询功能,也没有事务,学习起来其实比绝大部分传统数据库都要容易上手。
Faiss向量数据库简介
Faiss 是 Facebook 团队开源的向量检索工具,针对高维空间的海量数据,提供高效可靠的相似性检索方式,被广泛用于推荐系统、图片和视频搜索等业务。Faiss 支持 Linux、macOS 和 Windows 操作系统,在百万级向量的相似性检索表现中,Faiss 能实现 < 10ms 的响应(需牺牲搜索准确度)。
- Faiss 官网:https://faiss.ai/
- Faiss 仓库:https://github.com/facebookresearch/faiss
Faiss 使用 C++ 开发,提供了 Python 接口,可以通过 pip 安装 Faiss 库:
bash
# CPU环境下使用
pip install faiss-cpu
# GPU环境下使用并且已经安装了CUDA,则可以使用GPU版本
pip install faiss-gpu目前绝大部分向量数据库都支持多种对数据的操作方法:新增数据、检索数据、带得分的数据检索、带筛选条件的数据检索、删除数据等,但是几乎都不支持修改数据,这是因为向量数据库通常使用特定的索引结构(如向量索引树或近似最近邻搜索算法),这些结构需要在数据插入后进行构建和优化,如果允许修改数据,索引结构可能需要频繁更新,这会显著增加系统的复杂性和开销,所以一般是删除后再新增。
Faiss 也类似,不过由于 Faiss 是本地文件向量数据库,还额外支持了将向量数据持久化到本地、从本地文件夹加载向量数据库等操作。
Faiss向量数据库使用技巧
数据的导入与相似性搜索
在 LangChain 中,提供了 from_texts 和 from_documents 两个通用方法,这两个方法可以快捷从文本和文档中导入数据到向量数据库中,由于向量数据库存储的向量,所以需要传入文本嵌入模型,让向量数据库自动将传入的文本转换成向量。
示例如下:
python
import dotenv
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = FAISS.from_texts([
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
], embedding)
print(db.index.ntotal)完成数据的填充后,即可在向量数据库中进行对应的检索,LangChain 为所有的向量数据库都设计封装了一致的搜索接口,最常用的有以下 4 种:
- similarity_search():基础相似度搜索,传递 query(搜索语句)、k(返回条数)、filter(过滤器)、fetch_k(富余条数)等。
- similarity_search_with_score():携带得分的相似性搜索,参数和 similarity_search() 函数保持一致,只是会返回得分,这里的得分并不是相似性得分,而是欧几里得距离。
- similarity_search_with_relevance_scores():携带相关性得分的相似性搜索,得分范围是 0-1。
- as_retriever():将向量数据库转换成检索器,检索器是 Runnable 可运行组件。
在向量数据库中进行检索并携带得分(这里的得分并不是相似性得分,默认是欧几里得距离),效果如下:
python
print(db.similarity_search_with_score("我养了一只猫,叫笨笨"))输出内容:
python
10
[
(Document(page_content='笨笨是一只很喜欢睡觉的猫咪'), 0.11375141),
(Document(page_content='猫咪在窗台上打盹,看起来非常可爱。'), 1.0895041),
(Document(page_content='我的狗喜欢追逐球,看起来非常开心。'), 1.3836973),
(Document(page_content='我的手机突然关机了,让我有些焦虑。'), 1.5533546)
]由于不同文本嵌入模型生成向量的范围不一致,LangChain 封装的 Faiss 计算相关性得分的时候,可能会出现 bug(比如出现负数)。
python
print(db.similarity_search_with_relevance_scores("我养了一只猫,叫笨笨"))输出:
python
[
(
Document(page_content='笨笨是一只很喜欢睡觉的猫咪', metadata={'page': 1}),
0.4592331743070337
),
(
Document(page_content='猫咪在窗台上打盹,看起来非常可爱。', metadata={'page': 3}),
0.22960424668403867
),
(
Document(page_content='我的狗喜欢追逐球,看起来非常开心。', metadata={'page': 10}),
0.02157827632118159
),
(
Document(page_content='我的手机突然关机了,让我有些焦虑。', metadata={'page': 7}),
-0.09838758604956
)
]Faiss 计算相关性得分的核心代码如下(默认使用欧几里得距离计算相关性):
python
# langchain_community/vectorstores/faiss.py -> FAISS
def _euclidean_relevance_score_fn(distance: float) -> float:
return 1.0 - distance / math.sqrt(2)这个公式计算正确的前提是向量只有 2 维,并且向量的每个值范围是 0, 1,这个公式的几何意义如下:
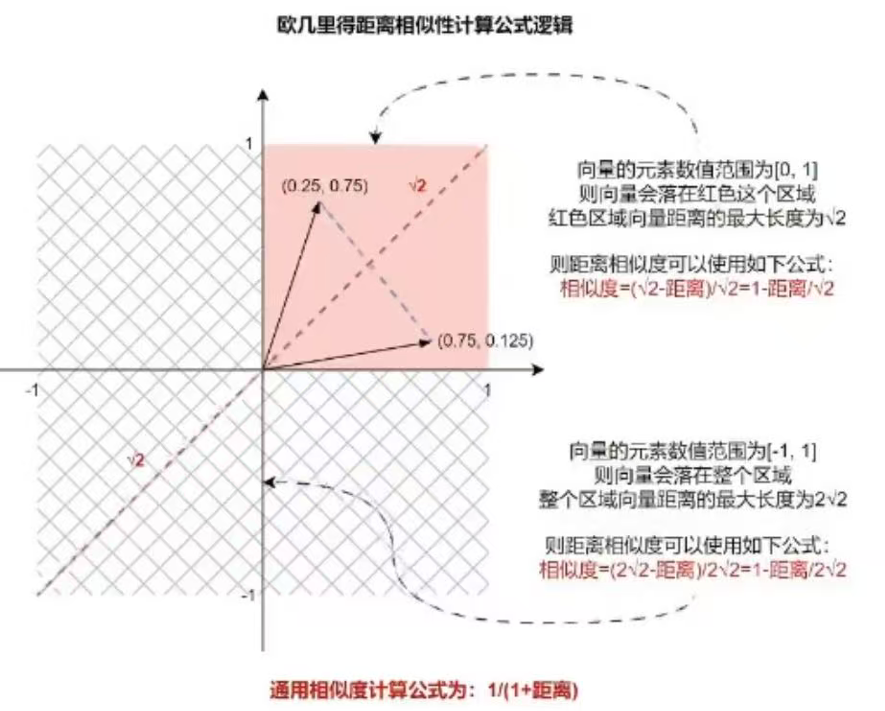
扩展到三维向量空间中(向量的范围是 0, 1),两个向量 / 点之间最大距离为 √3,并不是 √2,所以直接套用公式,可能会出现负值得分,在 N 维向量空间下,两点的最大距离是 √N,所以出现负数的概率大大增加。
可以修改成以下方式进行修正:
python
def _euclidean_relevance_score_fn(distance: float) -> float:
return 1.0 / (1.0 + distance)在使用 LangChain 封装的向量数据库时,一定要注意测试和校验下文本嵌入模型生成向量的数值范围,避免出现明显的错误。由于向量数据库目前更新太快,而且 LangChain 封装了太多的第三方组件(数百个),在很多场合下,LangChain 可能没有对每一种情况进行测试,有可能会出现一些莫名其妙的计算结果。
带过滤的相似性搜索
在绝大部分向量数据库中,除了存储向量数据,还支持存储对应的元数据,这里的元数据可以是文本原文、扩展信息、页码、归属文档 id、作者、创建时间等等任何自定义信息,一般在向量数据库中,会通过元数据来实现对数据的检索。
php
向量数据库记录 = 向量 (vector) + 元数据 (metadata) + id比较遗憾的是 Faiss 原生并不支持过滤,所以在 LangChain 封装的 FAISS 中对过滤功能进行了相应的处理。首先获取比 k 更多的结果 fetch_k(默认为 20 条),然后先进行搜索,接下来再搜索得到的 fetch_k 条结果上进行过滤,得到 k 条结果,从而实现带过滤的相似性搜索。
而且 Faiss 的搜索都是针对元数据的,在 Faiss 中执行带过滤的相似性搜索非常简单,只需要在搜索时传递 filter 参数即可,filter 可以传递一个元数据字典,也可以接收一个函数(函数的参数为元数据字典,返回值为布尔值)。
例如下方的代码只会对 page>5 的文档进行检索,代码如下:
python
import dotenv
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
texts: list = [
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
]
metadatas: list = [
{"page": 1},
{"page": 2},
{"page": 3},
{"page": 4},
{"page": 5},
{"page": 6},
{"page": 7},
{"page": 8},
{"page": 9},
{"page": 10},
]
db = FAISS.from_texts(texts, embedding, metadatas)
print(db.index_to_docstore_id)
print(db.similarity_search_with_score("我养了一只猫,叫笨笨", filter=lambda x: x['page'] >5))输出结果:
python
{0: '452f290d-3afa-4989-a168-2d222a92093e', 1: '71bc9dcf-751c-4e65-9b61-5003c43c8474', 2: '66a7bc83-df40-4036-b7c3-1b747ca4ee98', 3: '829e5148-139b-4185-95c1-341681d6ca5a', 4: '24038a82-a083-4ec5-99cd-adaf81036f98', 5: 'b0f16e08-8cf3-4f08-87fb-d635604dee82', 6: '668e6593-5f2c-4f86-95ff-93cf679e05a7', 7: '9c6359ae-42c4-438e-bcf0-d35037c857e4', 8: '7f2c926e-d390-46f8-8485-6685c898bc45', 9: 'b347b82e-ec1a-4583-baa8-61d5f68e92a0'}
[
(Document(page_content='我的狗喜欢追逐球,看起来非常开心。', metadata={'page': 10}), 1.3836973),
(Document(page_content='我的手机突然关机了,让我有些焦虑。', metadata={'page': 7}), 1.5533546),
(Document(page_content='阅读是我每天都会做的事情,我觉得很充实。', metadata={'page': 8}), 1.5989475),
(Document(page_content='他们一起计划了一次周末的野餐,希望天气能好。', metadata={'page': 9}), 1.7179501)
]删除指定数据
在 Faiss 中,支持删除向量数据库中特定的数据,目前仅支持传入数据条目 id 进行删除,并不支持条件筛选(但是可以通过条件筛选找到符合的数据,然后提取 id 列表,再批量删除)。
代码实例:
python
print("删除前数量:", db.index.ntotal)
# 获取向量数据库的索引id列表信息
db.delete([db.index_to_docstore_id[0]])
print("删除后数量:", db.index.ntotal)输出结果:
python
删除前数量: 10
删除后数量: 9保存和加载本地数据
除了从文本和文档列表中加载数据到向量数据库,Faiss 还支持将整个数据库持久化到本地文件,亦或者从本地文件一键加载数据,这样就不需要在每次使用向量数据库的时候重新创建,可以极大提升向量数据库的使用效率,两个方法如下:
- save_local():将向量数据库持久化到本地,传递 folder_path 和 index 分别代表文件夹路径与索引名字。
- load_local():将本地的数据加载到向量数据库,传递 folder_path、embeddings 和 index 分别代表文件夹路径、嵌入模型、索引名字。
示例:
python
db.save_local("faiss_index")
new_db = FAISS.load_local("faiss_index", embeddings)
docs = new_db.similarity_search("我养了一只猫,叫笨笨")输出结果:
python
[
Document(page_content='笨笨是一只很喜欢睡觉的猫咪', metadata={'page': 1}),
Document(page_content='猫咪在窗台上打盹,看起来非常可爱。', metadata={'page': 3}),
Document(page_content='我的狗喜欢追逐球,看起来非常开心。', metadata={'page': 10}),
Document(page_content='我的手机突然关机了,让我有些焦虑。', metadata={'page': 7})
]PineCone向量数据库的配置与使用
PineCone向量数据库简介
Pinecone 是一个托管的、云原生的向量数据库,具有极简的 API,并且无需在本地部署即可快速使用,Pinecone 服务提供商还为每个账户设置了足够的免费空间,在开发阶段,可以快速基于 Pinecone 快速开发 AI 应用。
相关资料:
Pinecone 官网: https://www.pinecone.io/
Pinecone 翻译文档: https://www.pinecone-io.com/
langchain-pinecone 翻译文档: http://imooc-langchain.shortvar.com/docs/integrations/vectorstores/pinecone/
Pinecone 向量数据库的设计架构与 Faiss 差异较大,Pinecone 由于是一个面向商业端的向量数据库,在功能和概念上会更加丰富,有几个核心概念 + 架构图如下:
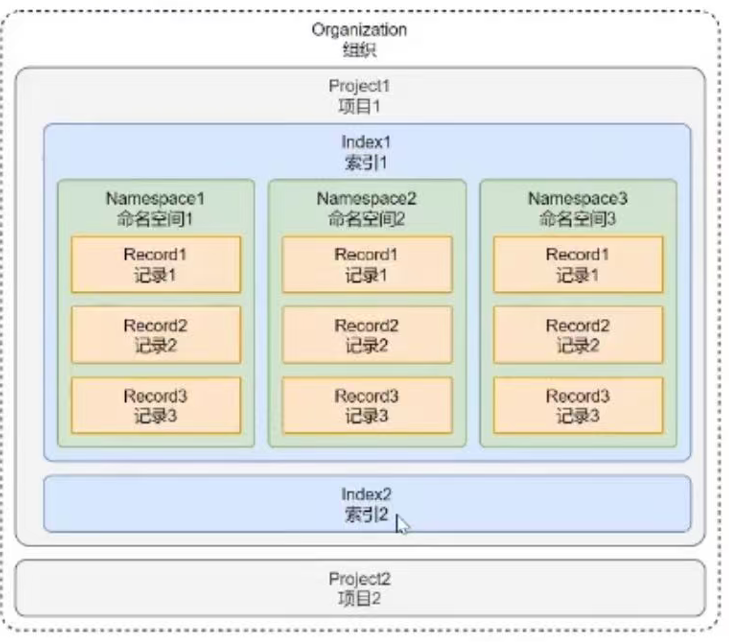
概念的解释如下:
- 组织:组织是使用相同结算方式的一个或者多个项目的集合,例如个人账号、公司账号等都算是一个组织。
- 项目:项目是用来管理向量数据库、索引、硬件资源等内容的整合,可以将不同的项目数据进行区分。
- 索引:索引是 Pinecone 中数据的最高组织单位,在索引中需要定义向量的存储维度、查询时使用的相似性指标,并且在 Pinecone 中支持两种类型的索引:无服务器索引(根据数据大小自动扩容)和 Pod 索引(预设空间 / 硬件)。
- 命名空间:命名空间是索引内的分区,用于将索引中的数据区分成不同的组,以便于在不同的组内存储不同的数据,例如知识库、记忆的数据可以存储到不同的组中,类似 Excel 中的 sheet 表。
- 记录:记录是数据的基本单位,一条记录涵盖了 ID、向量 (values)、元数据 (metadata) 等。
所以在 Pinecone 中使用向量数据库,要确保组织、项目、索引、命名空间、记录等内容均配置好才可以使用,并且由于 Pinecone 是云端向量数据库,使用时还需配置对应的 API 秘钥(可在注册好 Pinecone 后管理页面的 API Key 中设置)。
对于 Pinecone,LangChain 团队也封装了响应的包,安装命令:
python
pip install -U langchain-pinecone然后在 .env 文件中配置对应的 API 秘钥,如下:
python
# Pinecone向量数据库
PINECONE_API_KEY=xxx接下来就可以像 Faiss 一样去使用 LangChain 封装好的向量数据库了(会有稍许差异,这是不同向量数据库之间的一些差异)。
PineCone向量数据库使用技巧
数据的导入
Pinecone 和 Faiss 一样拥有 from_texts 和 from_documents 方法,支持快捷从文本列表和文档列表中构建向量数据库,也支持通过构造函数实例化 Pinecone 向量数据库后,通过 add_texts 的方式添加数据。
在配置好 index(llmops)、namespace(dataset)、api_key 后,可执行以下代码完成向量数据库数据的添加:
python
import dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = PineconeVectorStore(index_name="llmops", embedding=embedding, namespace="dataset")
db.add_texts([
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
], [
{"page": 1},
{"page": 2},
{"page": 3},
{"page": 4},
{"page": 5},
{"page": 6},
{"page": 7},
{"page": 8},
{"page": 9},
{"page": 10},
], namespace="dataset")
print(db.similarity_search_with_relevance_scores("我养了一只猫,叫笨笨"))输出内容:
python
[
(Document(page_content='笨笨是一只很喜欢睡觉的猫咪', metadata={'page': 1.0}), 0.8095565),
(Document(page_content='猫咪在窗台上打盹,看起来非常可爱。', metadata={'page': 3.0}), 0.7276270835),
(Document(page_content='我的狗喜欢追逐球,看起来非常开心。', metadata={'page': 10.0}), 0.6540447475),
(Document(page_content='我的手机突然关机了,让我有些焦虑。', metadata={'page': 7.0}), 0.611671284)
]带过滤的相似性搜索
和 Faiss 不同,Pinecone 支持原生的带过滤的相似性检索功能(元数据筛选),使用元数据过滤器会精确检索与过滤器匹配的最近结果数,在 Pinecone 中,过滤器格式为 JSON,其中 键 是元数据字段对应字符串,值 是字符串、数字、布尔值、列表、JSON 中的一种。
例如下方是精确筛选的过滤器:
python
{
"genre": "action",
"year": 2020,
"length_hrs": 1.5
}
{
"color": "blue",
"fit": "straight",
"price": 29.99,
"is_jeans": true
}除此之外,筛选器的值还可以传递json数据,用于支持更加复杂的条件搜索,而且还可以和AND/OR配合
| 筛选条件 | 描述 | 支持的类型 |
|---|---|---|
$eq |
将元数据值等于指定值的向量进行匹配 | 数字、字符串、布尔值 |
$ne |
匹配元数据值不等于指定值的向量 | 数字、字符串、布尔值 |
$gt |
匹配元数据值大于指定值的向量 | 数字 |
$gte |
匹配元数据值大于或等于指定值的向量 | 数字 |
$lt |
匹配元数据值小于指定值的向量 | 数字 |
$lte |
匹配元数据值小于或等于指定值的向量 | 数字 |
$in |
将向量与指定数组中的元数据值进行匹配 | 字符串, 数字 |
$nin |
与不在指定数组中的元数据值的向量匹配 | 字符串, 数字 |
$exists |
与存在/不存在特定元数据值的向量匹配 | 布尔值 |
$and |
多个条件同时符合 | - |
$or |
多个条件只需要满足一个 | - |
例如检索页数小于等于 5 页的数据,代码示例:
python
import dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = PineconeVectorStore(index_name="llmops", embedding=embedding, namespace="dataset")
resp = db.similarity_search_with_relevance_scores(
"我养了一只猫叫笨笨",
filter={"page": {"$lte": 5}}
)输出内容:
python
[
(Document(page_content='笨笨是一只很喜欢睡觉的猫咪', metadata={'page': 1.0}), 0.8121996819999999),
(Document(page_content='猫咪在窗台上打盹,看起来非常可爱。', metadata={'page': 3.0}), 0.7371905),
(Document(page_content='我喜欢在夜晚听音乐,这让我感到放松。', metadata={'page': 2.0}), 0.5996375455),
(Document(page_content='我最喜欢的食物是意大利面,尤其是番茄酱的那种。', metadata={'page': 5.0}), 0.5745788215000001)
]列入下方,在page=5并且account_id=1的向量数据里进行相似性检索:
python
resp=db.similarity_search_with_relevance_scores(
"我养了一只猫叫笨笨",
filter={"$and":[{"page": 5},{"account_id": 1}]}
)
# 输出,没有符号条件的数据
[]改成$or则为符合其中一个条件即可:
python
resp = db.similarity_search_with_relevance_scores(
"我养了一只猫叫笨笨",
filter={"$or": [{"page": 5}, {"account_id": 1}]}
)
# 输出
[
(Document(page_content='我最喜欢的食物是意大利面,尤其是番茄酱的那种。', metadata={'page': 5.0}), 0.574801199),
(Document(page_content='昨晚我做了一个奇怪的梦,梦见自己在太空飞行。', metadata={'account_id': 1.0, 'page': 6.0}), 0.5700240435)
]关于 Pinecone 更详细的筛选用法文档: https://docs.pinecone.io/guides/data/filter-with-metadata
删除指定数据
Pinecone 向量数据库中同样支持删除数据,并且支持按照 id 列表、按照命名空间删除全部数据、条件删除 等多种策略,delete() 函数参数如下:
- ids: 需要删除的 id 列表,非必填参数。
- delete_all: 是否删除全部数据,一般结合 namespace 一起使用,代表删除命名空间内的所有数据,非必填参数。
- namespace: 需要删除的命名空间数据,非必填参数。
- filter: 过滤器,格式为 json/dict,删除符合条件的所有数据,在无服务器索引的情况下,不支持通过元数据筛选器删除对应的数据,只在 Pod 索引下支持,检索器的用法和相似性搜索一模一样。
例如,删除 id=21c694f3-1e12-47b5-af9d-c93de29ad093 对应的向量数据,如下:
python
db.delete(["21c694f3-1e12-47b5-af9d-c93de29ad093"])关于 Pinecone 删除数据的用法文档: https://docs.pinecone.io/guides/data/delete-data
获取原始实例
如果 LangChain 封装的 VectorStore 对应的方法并不能满足相应的需求,一般情况下,还可以获取到向量数据库的原始实例,例如 Pinecone 提供了 update 方法,但是在 LangChain 封装的 PineconeVectorStore 并没有提供这个方法,所以可以考虑从原始实例上调⽤该方法。
可以通过 .get_pinecone_index() 函数来获取对应的 Index,从而进行相应的操作:
python
llmops_index = db.get_pinecone_index("llmops")
llmops_index.update(id="xxx", values=[xxx], namespace="dataset")关于原始实例操作数据的相关文档: https://docs.pinecone.io/guides/data/upsert
TCVectorDB向量数据库的配置与使用
TCVectorDB向量数据库简介
虽然目前绝大部分开源向量数据库都是海外的,配置起来也非常简单,性能也很高,但是因为网络的原因,如果将向量数据库部署到海外,而产品面向国内,网络延迟是一个必要考虑的问题,所以考虑国内服务商的云向量数据库往往是最佳的选择。
腾讯云向量数据库(TCVectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据,该数据库支持多种索引类型和相似度计算方法,索引支持千亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。而且目前认证过的腾讯云账号可以免费使用
TCVectorDB 一个月时间,相关文档:
- TCVectorDB 产品链接: https://cloud.tencent.com/product/vdb
- TCVectorDB 产品文档: https://cloud.tencent.com/document/product/1709
- LangChain TCVectorDB 翻译文档: http://imooc-langchain.shortvar.com/docs/integrations/vectorstores/tencentvectordb/
TCVectorDB 和 Pinecone 的设计理念非常接近,在腾讯云向量数据库中也有对应的 数据库、集合、记录 等概念:
- 数据库: 分为普通向量数据库和 AI 数据库,其中 AI 数据库无需外部配置文本分割、Embedding、文档解析等功能,底层全部有腾讯云实现,而普通向量数据库则需要外部程序处理,它只能接收传递的数据,并没有处理功能,但是功能更加可定制化。
- 集合: 集合是数据库的下一个单位,类似与传统数据库中的 表,在集合中,需要设置集合名称、分片数、索引等信息。
- 记录: 集合的每一条数据就是记录。
TCVectorDB 默认只能在内网中链接使用,在生产环境中,也尽可能不将数据库暴露到外网中,但是在开发中,则需要配置并开启外网访问功能,配置好外网访问功能、API 秘钥后,需要在项目中导入对应的环境变量。
php
TC_VECTOR_DB_URL=xxx
TC_VECTOR_DB_USERNAME=root
TC_VECTOR_DB_KEY=xxx
TC_VECTOR_DB_DATABASE=llmops
TC_VECTOR_DB_TIMEOUT=30接下来安装对应的 Python 包,命令如下:
bash
pip install tcvectordb接下来就可以像Faiss、Pinecone一样正常使用即可,整体功能和Pinecone几乎一摸一样,只是filter、namespace等概念的操作有些许差异
TCVectorDB向量数据库使用技巧
内置Embedding导入数据与查询
TCVectorDB向量数据库内置了Embedding模型,并支持5种嵌入方式,如下:
| 模型名 | 适用语言类型 | 维度 | 最大 Token 数量 | 分类得分 | 聚类得分 | 检索得分 |
|---|---|---|---|---|---|---|
| bge-base-zh(推荐) | 中文 | 768 | 512 | 67.06 | 47.64 | 69.53 |
| m3e-base | 中文 | 768 | 512 | 67.52 | 47.68 | 56.91 |
| text2vec-large-chinese | 中文 | 1024 | 512 | 60.66 | 30.02 | 41.94 |
| e5-large-v2 | 英文 | 1024 | 512 | 75.24 | 44.49 | 50.56 |
| multilingual-e5-base | 多语言 | 768 | 514 | 63.35 | 40.68 | 40.68 |
使用内置的 Embedding 模型速度会更快(而且目前 LangChain 封装的 TCVectorDB 使用内置 Embedding 没有 bug),不过限制也比较多,迁移数据库时,所有的文本全部需要重新生成。
内置 Embedding 模型文档说明 & 计费: https://cloud.tencent.com/document/product/1709/98014
示例:
python
import os
import dotenv
from langchain_community.vectorstores import TencentVectorDB
from langchain_community.vectorstores.tencentvectordb import (
ConnectionParams,
)
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = TencentVectorDB(
embedding=None,
connection_params=ConnectionParams(
url=os.environ.get("TC_VECTOR_DB_URL"),
username=os.environ.get("TC_VECTOR_DB_USERNAME"),
key=os.environ.get("TC_VECTOR_DB_KEY"),
timeout=int(os.environ.get("TC_VECTOR_DB_TIMEOUT")),
),
database_name=os.environ.get("TC_VECTOR_DB_DATABASE"),
collection_name="dataset-builtin",
)
texts = [
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
]
ids = db.add_texts(texts)
print("添加文档id列表:", ids)
print(db.similarity_search_with_score("我养了一只猫,叫笨笨"))输出示例:
python
添加文档id列表: ['1721204162283324200-8452797147690134545-0', '1721204162283324200-4748609318240602995-1',
'1721204162283324200-5687737768520280782-2', '1721204162283324200--327905253905429573-3',
'1721204162283324200--4217514370195306218-4', '1721204162283324200-5510932568003309936-5',
'1721204162283324200-7945499047074485108-6', '1721204162283324200-8077162730065074156-7',
'1721204162283324200-36196153077512649-8', '1721204162283324200-3472252428185052217-9']
[(Document(page_content='笨笨是一只很喜欢睡觉的猫咪'), 0.874507), (Document(page_content='我的狗喜欢追逐球,看起来非常开心。'), 0.757709), (Document(page_content='猫咪在窗台上打盹,看起来非常可爱。'), 0.748665),
(Document(page_content='昨晚我做了一个奇怪的梦,梦见自己在太空飞行。'), 0.735823)]外部Embedding导入数据与查询
除了使用内置的 Embedding 模型,TCVectorDB 也支持传递自定义的文本嵌入模型,但是在 LangChain 中封装的 TencentVectorDB 存在一个 bug,当传递外部 Embedding 模型时,必须配置 meta_fields 属性,并且指定字段名称为 text,然后将 metadatas 中的数据添加上 text 这个字段,向量数据库才会记录原文信息。
meta_fields 的字段是告知 TCVectorDB 需要存储 metadata 中的哪些字段,如果没有设置,metadata 中的所有字段均不会被保存。
如果没有记录原文信息,在进行检索操作时,会因为找不到原文,从而没法创建 Document 文档,引发报错。
出现 bug 的源码:
python
# langchain_community/vectorstores/tencentvectordb.py->TencentvectorDs::add_texts
def add_texts(
self,
texts: Iterable[str]metadatas: optional[List[dict]] = None,
timeout:optional[int]= None,
batch_size: int = 1000,
ids: optional[List[str]] = None,
*kwargs: Any,
) -> List[str]:
...
if embedding
doc_attrs["vector"] = embeddings[id]
else:
doc_attrs["text"] = texts[id]
...修复示例:
python
import os
import dotenv
from langchain_community.vectorstores import TencentVectorDB
from langchain_community.vectorstores.tencentvectordb import (
ConnectionParams,
MetaField,
META_FIELD_TYPE_STRING
)
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = TencentVectorDB(
embedding=None,
connection_params=ConnectionParams(
url=os.environ.get("TC_VECTOR_DB_URL"),
username=os.environ.get("TC_VECTOR_DB_USERNAME"),
key=os.environ.get("TC_VECTOR_DB_KEY"),
timeout=int(os.environ.get("TC_VECTOR_DB_TIMEOUT")),
),
database_name=os.environ.get("TC_VECTOR_DB_DATABASE"),
collection_name="dataset-external",
meta_fields=[
MetaField(name="text", data_type=META_FIELD_TYPE_STRING),
]
)
texts = [
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
]
metadatas = [{"text": text, "page": index} for index, text in enumerate(texts)]
ids = db.add_texts(texts, metadatas)
print("添加文档id列表:", ids)
print(db.similarity_search_with_score("我养了一只猫,叫笨笨"))输出内容:
python
添加文档id表:['1721204290046443100--7979142186803955240-0', '1721204290046443100--2991801275249710134-1','1721204290046443100-722901721204290046443100-6820010242590464795-3'1721204290046443100-17611721204290046443100-38561721204290046443100-5925
1721204290046443100-7105227574091896456-5'
川已暂停
721204290046443100-2611196434988287836-7'
1721204290046443100--5880598133876375674-9']
-content='笨笨是一只很喜欢睡觉的猪咪',metadata=['text':[Document(page'笨笨是一只很喜欢睡觉的猫咪'})Document(page_content='猫咪在窗台上打盹,看起来非常可爱.',metadata=【'text':'猫咪在窗台上打吨,看起来非常可爱。'}),metadata=【text':'我的狗喜欢迫逐球,看起来非常开心。'}),Document(page_content='我的狗喜欢迫逐球,看起来非常开心。"Document(page_content='我的手机突然关机了,让我有些焦虑。,metadata=【text':'我的手机突然关机了,让我有些焦虑。'})]TCVectorDB带过滤的相似性搜索
TCVectorDB也支持为相似性搜索添加过滤器,表达式的格式为<field_name>,多个表达式之间支持and(与)、or(或)、not (非)关系。其中:
- <field_name>:表示要过滤的字段名。
- :要使用的运算符。
- string:匹配单个字符串值(=)、排除单个字符串值(1=)、匹配任意一个字符串值(in)、排除所有字符串值(notin)。其
对应的Value必须使用英文双引号括起来。 - uint64:大于(>)、大于等于(>=)、等于(=)、小于(<)、小于等于(<=)、不等于(1=).
- :表示要匹配的值。
例:uint64_val > 30、game_tag="Detective"等。
并且在TCVectorDB使用非向量字段进行检索时,必须在构建col1ection 时添加上对应的索引,否则无法检索会报错。
详细文档: https://cloud.tencent.com/document/product/1222/98734#2e2e982a-a487-4a05-8410-58c6bda12180
python
import os
import dotenv
from langchain_community.vectorstores import TencentVectorDB
from langchain_community.vectorstores.tencentvectordb import (
ConnectionParams,
MetaField,
META_FIELD_TYPE_UINT64
)
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = TencentVectorDB(
embedding=None,
connection_params=ConnectionParams(
url=os.environ.get("TC_VECTOR_DB_URL"),
username=os.environ.get("TC_VECTOR_DB_USERNAME"),
key=os.environ.get("TC_VECTOR_DB_KEY"),
timeout=int(os.environ.get("TC_VECTOR_DB_TIMEOUT")),
),
database_name=os.environ.get("TC_VECTOR_DB_DATABASE"),
collection_name="dataset-filter",
meta_fields=[
MetaField(name="page", data_type=META_FIELD_TYPE_UINT64),
]
)
texts = [
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
]
metadatas = [
{"page": 1},
{"page": 2},
{"page": 3},
{"page": 4},
{"page": 5},
{"page": 6},
{"page": 7},
{"page": 8},
{"page": 9},
{"page": 10},
]
ids = db.add_texts(texts, metadatas)
print("添加文档id列表:", ids)
print(db.similarity_search_with_score("我养了一只猫,叫笨笨", expr="page>9"))Weaviate向量数据库的配置与使用
Weaviate 介绍
Weaviate 是完全使用 Go 语言构建的开源向量数据库,提供了强大的数据存储和检索功能。并且 Weaviate 提供了多种部署方式,以满足不同用户和用例的需求,部署方式如下:
- Weaviate 云:使用 Weaviate 官方提供的云服务,支持数据复制、零停机更新、无缝扩容等功能,适用于评估、开发和生产场景。
- Docker 部署:使用 Docker 容器部署 Weaviate 向量数据库,适用于评估和开发等场景。
- K8s 部署:在 K8s 上部署 Weaviate 向量数据库,适用于开发和生产场景。
- 嵌入式 Weaviate:基于本地文件的方式构建 Weaviate 向量数据库,适用于评估场景,不过嵌入式 Weaviate 只适用于 Linux、macOS 系统,在 Windows 下不支持。
Weaviate 和 Pinecone/TCVectorDB 一样,也存在着集合的概念,在 Weaviate 中集合类似传统关系型数据库中的表,负责管理一类数据 / 数据对象,要使用 Weaviate 的流程其实也非常简单:
- 创建部署 Weaviate 数据库(使用 Weaviate 云、Docker 部署)。
- 安装 Python 客户端 / LangChain 集成包。
- 连接 Weaviate(本地连接、云端连接)。
- 创建数据集 / 集合(代码创建、可视化管理界面创建),在 Weaviate 中,集合的名字必须以大写字母开头,并且只能包含字母、数字和下划线,否则创建的时候会出错,和 Python 的类名规范几乎一致。
- 添加数据 / 向量。
- 相似性搜索 / 带过滤器的相似性搜索。
参考资料
- Weaviate 官网:https://weaviate.io/
- Weaviate 快速上手指南:https://weaviate.io/developers/weaviate/quickstart
- LangChain Weaviate 集成包翻译文档:https://imooc-langchain.shortvar.com/docs/integrations/vectorstores/weaviate
Weaviate云服务
Weaviate官方为所有注册登录的账号提供了无限量的Weaviate云服务(免费账号每个实例使用时间最大为14天,付费账号不限),通过邮箱注册登录Weaviate后,找到后台管理系统的clusters(集群)即可快速创建Weaviate向量数据库实例
Weaviate后台管理面板:https://console.weaviate.cloud/dashboard
创建好 Weaviate 云服务器集群后,平台提供了 REST 和 gRPC 两种链接方式的地址与 API 秘钥,在客户端中即可快速连接到云服务。
Docker部署Weaviate向量数据库
在 Docker 上部署 Weaviate 向量数据库非常简单,如果使用默认值,则不需要 docker-compose.yml 文件来运行镜像(适用于开发场景),安装好 Docker 之后,执行如下命令:
bash
docker run -d --name weaviate-dev -p 8080:8080 -p 50051:50051
cr.weaviate.io/semitechnologies/weaviate:1.24.20上述的命令就会快速创建一个叫 weaviate-dev 的容器并在后台运行,该容器暴露了两个端口,8080 和 50051,其中 8080 端口为 REST 接口连接端口、50051 为 gRPC 服务连接端口。
除此之外,使用 Docker 部署的 Weaviate 向量数据库服务,还有以下几个常见命令:
python
# 启动 weaviate 服务
docker start weaviate
# 关闭 weaviate 服务
docker stop weaviate
# 移除 weaviate 容器
docker rm weaviate-dev
# 查看当前 docker 容器所有镜像
docker images
# 移除 weaviate 镜像
docker rmi cr.weaviate.io/semitechnologies/weaviate
# 查看当前运行的docker服务
docker ps
# 查看所有docker 容器(涵盖启动和未启动)
docker ps -aWeaviate向量数据库使用技巧
创建好 Weaviate 数据库服务后,接下来就可以安装 Python 客户端 / LangChain 集成包,命令如下:
python
pip install -Uqq langchain-weaviate下一步如果使用的是 Weaviate 云服务,可以直接从可视化界面创建 collection,亦或者在使用时 LangChain 自动检测对应的数据集是否存在,如果不存在则直接创建。
然后就可以考虑连接 Weaviate 服务了,Weaviate 框架针对不同的部署方式提供的不同的连接方法:
- weaviate.connect_to_local():连接到本地的部署服务,需配置连接 URL、端口号。
- weaviate.connect_to_wcs():连接到远程的 Weaviate 服务,需配置连接 URL、连接秘钥。
示例如下:
python
import weaviate
# 连接192.168.2.120:8080并创建weaviate客户端
client = weaviate.connect_to_local("192.168.2.120", "8080")连接到远程的Weaviate服务代码如下:
python
import weaviate
from weaviate.auth import AuthApiKey
client = weaviate.connect_to_wcs(
cluster_url="https://2j9jgyhprd2yej3c3rwog.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("BAn9bgzdzbdgcmuyfdegQoKFctyMmxaqdDFb")
)创建好客户端后,接下来可以基于客户端创建 LangChain 向量数据库实例,在实例化 LangChain VectorDB 时,需要传递 client(客户端)、index_name(集合名字)、text(原始文本的存储键)、embedding(文本嵌入模型),如下:
python
import dotenv
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
dotenv.load_dotenv()
# 1. 连接 weaviate 向量数据库
client = weaviate.connect_to_local("192.168.2.120", "8080")
# 2. 实例化 weaviateVectorStore
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = WeaviateVectorStore(client=client, index_name="DatasetTest", text_key="text", embedding=embedding)实例化 LangChain VectorDB 后,就可以像 Faiss、Pinecone、TCVectorDB 一样去使用了,例如执行新增数据后完成检索示例如下:
python
import dotenv
import weaviate
from weaviate.auth import AuthApiKey
from langchain_openai import OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
dotenv.load_dotenv()
# 原始文本数据与元数据
texts = [
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
]
metadatas = [
{"page": 1},
{"page": 2},
{"page": 3},
{"page": 4},
{"page": 5},
{"page": 6},
{"page": 7},
{"page": 8},
{"page": 9},
{"page": 10},
]
# 创建连接客户端
client = weaviate.connect_to_wcs(
cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud",
auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0"),
)
# 2. 实例化 weaviateVectorStore
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
db = WeaviateVectorStore(client=client, index_name="DatasetTest", text_key="text", embedding=embedding)
# 添加数据
ids = db.add_texts(texts, metadatas)
print(ids)
# 执行相似性搜索
print(db.similarity_search_with_score("笨笨"))输出内容:
python
[(Document(page_content='笨笨是一只很喜欢睡觉的猫咪'), 0.699999988079071), (Document(page_content='猫咪在窗台上打盹,看起来非常可爱。'), 0.2090398222208023), (Document(page_content='我的狗喜欢追逐球,看起来非常开心。'), 0.19787956774234772), (Document(page_content='我的手机突然关机了,让我有些焦虑。'), 0.11435992270708084)]在 Weaviate 中,也支持带过滤器的相似性筛选,并且 LangChain Weaviate 社区包并没有对筛选过滤器进行二次封装,所以直接传递原生的 weaviate 过滤器即可,参考文档: https://weaviate.io/developers/weaviate/search/filters
例如需要检索 page 属性大于等于 5 的所有数据,可以构建一个 filters 后传递给检索方法,如下:
python
from weaviate.classes.query import Filter
filters = Filter.by_property("page").greater_or_equal(5)
print(db.similarity_search_with_score("笨笨", filters=filters))输出结果如下:
python
[(Document(page_content='我的狗喜欢追逐球,看起来非常开心。', metadata={'page': 10.0, 'account_id': None}), 0.699999988079071),
(Document(page_content='我的手机突然关机了,让我有些焦虑。', metadata={'page': 7.0, 'account_id': None}), 0.4045487940311432),
(Document(page_content='昨晚我做了一个奇怪的梦,梦见自己在太空飞行。', metadata={'page': 6.0, 'account_id': 1.0}), 0.318904846906662),
(Document(page_content='我最喜欢的食物是意大利面,尤其是番茄酱的那种。', metadata={'page': 5.0, 'account_id': None}), 0.2671944797039032)]如果想获取 Weaviate 原始集合的实例,可以通过 db._collection 快速获得,从而去执行一些原始操作,例如:
python
from weaviate.classes.query import MetadataQuery
collection = db._collection
response = reviews.query.near_text(
query="a sweet German white wine",
limit=2,
target_vector="title_country", # Specify the target vector for named vector collections
return_metadata=MetadataQuery(distance=True)
)
for o in response.objects:
print(o.properties)
print(o.metadata.distance)对接自定义向量数据库的配置与使用
对接自定义向量数据库
向量数据库的发展非常迅猛,几乎间隔几天就有新的向量数据库发布,LangChain 不可能将所有向量数据库都进行集成,亦或者封装的包存在这一些 bug 或错误,这个时候就需要考虑创建自定义向量数据库,去实现特定的方法。
在 LangChain 实现自定义向量数据库的类有两种模式,一种是继承封装好的数据库类,一种是继承基类 VectorStore。前一种一般继承后重写部分方法进行扩展或者修复 bug,后面一种是对接新的向量数据库。
在 LangChain 中,继承 VectorStore 只需实现最基础的 3 个方法即可正常使用:
- add_texts: 将对应的数据添加到向量数据库中。
- similarity_search: 最基础的相似性搜索。
- from_texts: 从特定的文本列表、元数据列表中构建向量数据库。
其他方法因为使用频率并不高,VectorStore 并没有设置成虚拟方法,但是在没有实现的情况下,直接调用会报错,涵盖:
- delete(): 删除向量数据库中的数据。
- _select_relevance_score_fn(): 根据距离计算相似性得分函数。
- similarity_search_with_score(): 携带得分的相似性搜索函数。
- similarity_search_by_vector(): 传递向量进行相似性搜索。
- max_marginal_relevance_search(): 最大边界相似性搜索。
- max_marginal_relevance_search_by_vector(): 传递向量进行最大边界相关性搜索。
自定义VectorStore示例
要在 LangChain 中对接自定义向量数据,本质上就是将向量数据库提供的方法集成到 add_texts、similarity_search、from_texts 方法下,例如自建一个基于内存 + 欧几里得距离的 "向量数据库",示例如下:
python
from typing import Any, Iterable, Optional, List, Type
import dotenv
import numpy as np
from langchain_core.documents import Document
from langchain_core.embeddings import Embeddings
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import VectorStore, VST
import uuid
class MemoryVectorStore(VectorStore):
"""基于内存+欧几里得距离的向量数据库"""
store: dict = {} # 存储向量的临时变量
def __init__(self, embedding: Embeddings):
self._embedding = embedding
def add_text(self, texts: Iterable[str], metadatas: Optional[List[dict]] = None, **kwargs: Any) -> List[str]:
"""将数据添加到向量数据库中"""
# 1. 检测metadata的数据格式
if metadatas is not None and len(metadatas) != len(texts):
raise ValueError("metadatas格式错误")
# 2. 将数据转换成文本嵌入/嵌入和ids
mebeddings = self._embedding.embed_documents(texts)
ids = [str(uuid.uuid4()) for _ in texts]
# 3. 通过for循环组装数据记录
for idx, text in enumerate(texts):
self.store[ids[idx]] = {
"id": ids[idx],
"text": text,
"vector": mebeddings[idx],
"metadatas": metadatas[idx] if metadatas is not None else {},
}
return ids
def similarity_search(self, query: str, k: int = 4, **kwargs: Any) -> list[Document]:
"""传入对应的query执行相似搜索"""
# 1. 将query转换成向量
embeddings = self._embedding.embed_query(query)
# 2. 循环和store中的每一个向量进行比较,计算欧几里得距离
result = []
for key, record in self.store.items():
distance = self._euclidean_distance(embeddings, record["vector"])
result.append({"distance": distance, **record})
# 3. 排序,欧几里得距离越小越靠前
sorted_result = sorted(result, key=lambda x: x["distance"])
# 4. 取数据,取K条数据
result_k = sorted_result[:k]
return [Document(page_content=item['text'], metadatas={**item['metadata'],"score": item["distance"]}) for item in result_k]
@classmethod
def from_texts(cls: type["MemoryVectorStore"], texts: list[str], embedding: Embeddings, metadatas: list[dict] | None = None, *,
ids: list[str] | None = None, **kwargs: Any) -> VST:
"""从文本和元数据中去构建向量数据库"""
memory_vector_store = cls(embedding=embedding)
memory_vector_store.add_texts(texts, metadatas, **kwargs)
return memory_vector_store
@classmethod
def _euclidean_distance(cls, vec1: list, vec2: list) -> float:
"""计算两个向量的欧几里得距离"""
return np.linalg.norm(np.array(vec1) - np.array(vec2))
dotenv.load_dotenv()
# 创建初始数据与嵌入模型
texts = [
"笨笨是一只很喜欢睡觉的猫咪",
"我喜欢在夜晚听音乐,这让我感到放松。",
"猫咪在窗台上打盹,看起来非常可爱。",
"学习新技能是每个人都应该追求的目标。",
"我最喜欢的食物是意大利面,尤其是番茄酱的那种。",
"昨晚我做了一个奇怪的梦,梦见自己在太空飞行。",
"我的手机突然关机了,让我有些焦虑。",
"阅读是我每天都会做的事情,我觉得很充实。",
"他们一起计划了一次周末的野餐,希望天气能好。",
"我的狗喜欢追逐球,看起来非常开心。",
]
metadatas = [
{"page": 1},
{"page": 2},
{"page": 3},
{"page": 4},
{"page": 5},
{"page": 6},
{"page": 7},
{"page": 8},
{"page": 9},
{"page": 10},
]
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 构建自定义向量数据库
db = MemoryVectorStore(embedding=embeddings)
ids=db.add_texts(texts, metadatas)
print(ids)
# 执行检索
print(db.similarity_search("笨笨"))