前言
最近有球友问了我一个问题:Druid和HikariCP,到底哪个更好?
你在做技术选型的时候,是不是经常在两个优秀的开源组件之间纠结?
Druid和HikariCP就是典型的例子。
一个是阿里巴巴开源的"全能型选手",一个是Spring Boot默认集成的"性能怪兽"。
很多小伙伴在工作中肯定遇到过类似的问题:项目到底该用哪一个?
网上众说纷纭,有人说HikariCP快,有人说Druid功能强。
今天这篇文章就专门跟大家一起聊聊这个话题,希望对你会有所帮助。
更多项目实战在我的技术网站:susan.net.cn/project
一、先来聊聊数据库连接池是干啥的
要搞清楚哪个更好,我们得先弄明白连接池到底在解决什么问题。
说来惭愧,刚入行那会儿,我写的数据库代码是这样的:
java
// 错误示例:每次请求都创建新连接
public void getData() {
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
// ...
rs.close();
stmt.close();
conn.close();
}这样写有什么问题?
大家可以想象一下:一个高并发的系统,每秒有成百上千个请求访问数据库,每个请求都要建立一个数据库连接------三次握手、账号验证、建立Session,用完立马关掉。
数据库的CPU光伺候这些连接的建立和销毁就要累死了。
连接池本质上就是个"资源池":在程序启动的时候预先创建一批数据库连接,存在池子里。
请求来了,从池子里"借"一个连接;请求处理完了,把连接"还"回去,而不是关闭。
这样就省去了反复创建和销毁连接的开销。原理其实很简单,就像下面这张图画的:
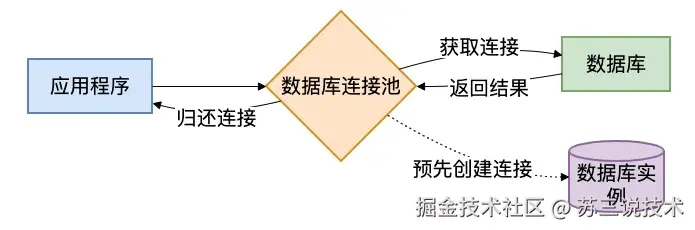
目前Java界用得最广的两个连接池就是HikariCP和Druid。
Spring Boot 2.x/3.x默认集成了HikariCP,而Druid是阿里巴巴出品的老牌劲旅。
二、HikariCP到底有多快?
2.1 一个简单的性能测试
我们先通过一个简单的测试来看HikariCP到底有多快。
在100并发下,连接获取延迟的差距就很明显了:
java
// 模拟高并发获取连接
public class ConnectionPoolBenchmark {
@Test
public void testHikari() throws Exception {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/test");
config.setUsername("root");
config.setPassword("123456");
config.setMaximumPoolSize(20);
// 开启泄漏检测(后面会讲到)
config.setLeakDetectionThreshold(5000);
HikariDataSource ds = new HikariDataSource(config);
// 100个线程并发获取连接
ExecutorService executor = Executors.newFixedThreadPool(100);
long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
try (Connection conn = ds.getConnection()) {
// 模拟业务操作
conn.isValid(1);
} catch (SQLException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
long end = System.currentTimeMillis();
System.out.println("总耗时: " + (end - start) + "ms");
}
}实测数据显示:HikariCP在高并发下的表现确实非常抢眼,连接获取延迟极低,内存占用控制得也很好。
在TechEmpower基准测试中,HikariCP能支撑15万+的TPS,而Druid大约在8万-12万之间。
连接获取延迟方面,HikariCP通常小于5ms,Druid在10-25ms之间。
内存占用差异也很大:HikariCP核心代码只有约130KB,而Druid的功能模块比较多,大约2MB左右。
2.2 揭开HikariCP性能的秘密
很多小伙伴可能会问:凭什么HikariCP这么快?它到底用了什么黑科技?
我花了几个晚上读它的源码,总结出最核心的两点。
第一点:ConcurrentBag------无锁化的设计
HikariCP的核心是一个叫ConcurrentBag的类,这是它管理连接池的最重要的核心类,也是它性能甩开其他连接池十条街的秘密所在。
ConcurrentBag是一个lock-free的并发集合,依赖了CopyOnWriteArrayList、ThreadLocal、AtomicInteger等JDK的并发类实现。
咱们来看看它的核心逻辑:
java
public class ConcurrentBag<T> {
// sharedList保存了所有的连接
private final CopyOnWriteArrayList<T> sharedList;
// threadList保存当前线程用过连接的引用
private final ThreadLocal<List<Object>> threadList;
// 等待获取连接的线程数
private final AtomicInteger waiters;
/**
* 从连接池中获取连接的核心方法
*/
public T borrow(long timeout, final TimeUnit timeUnit)
throws InterruptedException {
// ① 先尝试从ThreadLocal中拿------这一步完全无锁!
List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final T bagEntry = (T) list.remove(i);
// CAS操作,无锁更新连接状态
if (bagEntry != null &&
bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// ② ThreadLocal中没有,再从sharedList中拿
// 等待timeout时间,通过synchronizer进行线程间同步
// ...
}
}这里的巧妙之处在于:先用ThreadLocal缓存当前线程使用过的连接,还回去的连接也会放到线程本地的ThreadLocal中。
这样一来,大部分情况下获取连接根本就不需要加锁,性能自然就上去了。
而Druid在获取连接、归还连接时都有锁控制,因为连接池资源是多线程共享的,不可避免会有锁竞争。
第二点:字节码精简优化
HikariCP在编译期进行了大量的字节码优化,比如用自定义的FastList替代ArrayList,减少了各种边界检查的开销。
这些优化细节加起来,才有了"性能怪兽"的美誉。
2.3 连接池大小的黄金法则
很多新手设置连接池的时候有个误区:觉得maximumPoolSize越大越好,一上来就设成1000。
但是告诉大家,连接池真不是越大越好!
大家可以想一下:数据库服务器的CPU是有限的,假设只有4核,那同一时刻它真的只能做4件事。
给你1000个连接,996个都在排队,而且CPU还要花费大量时间在这些线程之间切来切去,得不偿失。
PostgreSQL官方和HikariCP的作者给出了一个广受认可的黄金公式:
最优连接数 = (CPU核心数 × 2) + 有效磁盘数
按照这个公式,4核CPU的数据库服务器,最优连接数只有9个!即使是生产环境,10-20个连接往往就能支撑几千并发了。
这听起来有点反直觉,但道理其实很简单------瓶颈通常在于磁盘I/O,而不是连接数不够。
另外还需要注意一个非常重要的配置:minimumIdle应该和maximumPoolSize保持一致。
否则连接池会随着流量波动不断扩容和缩容,反而造成了不必要的开销。
HikariCP的几个核心参数,大家可以记一下:
yaml
# HikariCP推荐配置(生产环境)
spring:
datasource:
hikari:
maximum-pool-size: 20 # 最大连接数,根据黄金公式设置
minimum-idle: 20 # 建议等于maximumPoolSize,固定大小
connection-timeout: 3000 # 连接超时,建议调小到3秒
idle-timeout: 600000 # 空闲超时10分钟
max-lifetime: 1800000 # 最大存活30分钟,必须小于数据库wait_timeout
leak-detection-threshold: 60000 # 连接泄漏检测,60秒未归还就报警
validation-timeout: 5000 # 连接校验超时5秒max-lifetime必须小于数据库服务端的wait_timeout,不然拿到的是已经断开的连接,会报"Pipe broken"错误。leak-detection-threshold这个开关非常重要,设置后如果连接超过阈值未被归还,会在日志中精准输出堆栈快照,直接定位到getConnection()的调用位置。
三、Druid凭什么还能占据半壁江山?
说完HikariCP,咱们再来看看Druid。既然HikariCP性能这么好,为什么还有那么多大厂在用Druid?答案很简单:Druid是"为监控而生"的连接池。
3.1 Druid最核心的优势------监控能力
很多小伙伴在工作中应该遇到过这样的场景:线上系统突然变慢了,大量请求超时。
排查了一圈,发现是数据库慢查询导致连接被占满。
但问题是,慢查询的SQL到底是谁写的?哪段代码调用了它?如果没有SQL监控,抓起来非常痛苦。
Druid内置了完善的监控系统,可以实时监控连接池的状态(活跃连接数、空闲数等)、SQL执行情况(执行时间、行数、慢SQL等),甚至还能关联Web请求与数据库的交互关系。
下面这个是Druid监控体系的结构图:
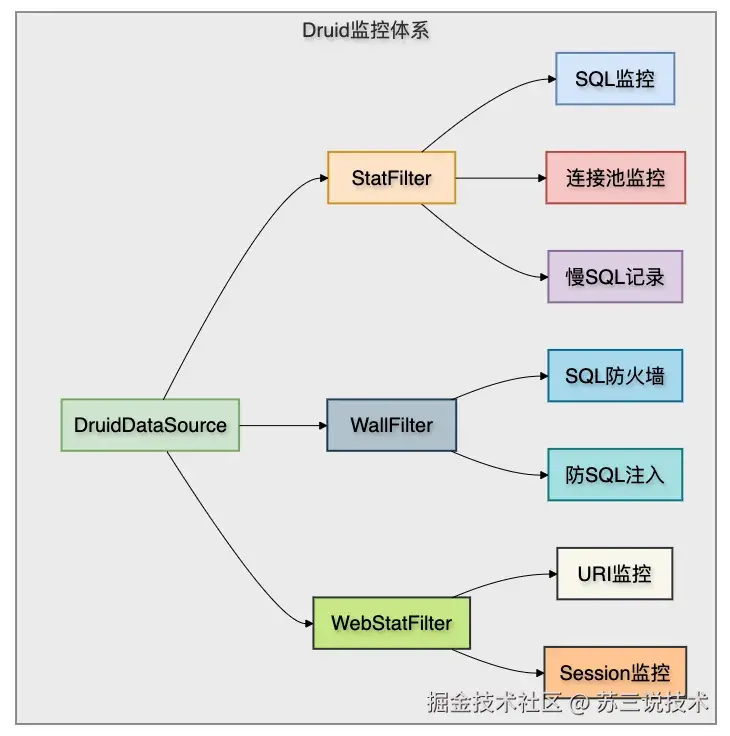
开启Druid的监控非常简单,几步就能搞定:
yaml
# application.yml
spring:
datasource:
druid:
# 监控页面配置
stat-view-servlet:
enabled: true
url-pattern: /druid/*
login-username: admin
login-password: 123456
reset-enable: false
# Web监控过滤器
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: "*.js,*.css,*.jpg,/druid/*"
session-stat-enable: true
# SQL监控配置
filter:
stat:
enabled: true
db-type: mysql
log-slow-sql: true
slow-sql-millis: 1000 # 超过1秒算慢查询
wall:
enabled: true # 开启防火墙
config:
delete-allow: false # 禁止全表删除
drop-table-allow: false # 禁止删表配置完成之后,访问 http://localhost:8080/druid 就能看到一个非常直观的监控页面,包含SQL监控、URL监控、Session监控等丰富的功能模块。
3.2 Druid的"杀手锏"
连接泄漏检测和生产环境故障排查。
Druid在连接泄漏检测方面做得非常到位。
电商大促、秒杀活动的时候,最容易出现的一个问题就是连接被拿走了却不归还,最终导致连接池耗尽。
Druid提供了三级防护体系:
java
@Configuration
public class DruidConfig {
@Bean
public DataSource druidDataSource() {
DruidDataSource ds = new DruidDataSource();
// 连接池基础配置
ds.setUrl("jdbc:mysql://localhost:3306/test");
ds.setUsername("root");
ds.setPassword("123456");
ds.setInitialSize(10);
ds.setMaxActive(100);
ds.setMinIdle(10);
// 🔥 核心防泄漏配置
ds.setRemoveAbandoned(true); // 开启泄漏连接自动回收
ds.setRemoveAbandonedTimeout(180); // 180秒未归还算泄漏
ds.setLogAbandoned(true); // 记录泄漏连接的堆栈信息
ds.setAbandonWhenOverflow(true); // 连接池满时立即回收泄漏连接
// 连接保活配置
ds.setValidationQuery("SELECT 1");
ds.setTestWhileIdle(true);
ds.setTimeBetweenEvictionRunsMillis(60000);
// 开启监控和防火墙
ds.setFilters("stat,wall");
return ds;
}
}这些参数配置之后,一旦发生连接泄漏,Druid会自动回收连接,并在日志中打印出泄漏连接的堆栈,直接帮你定位到是哪一行代码没关连接!
这一点在生产环境中简直是救命稻草。
3.3 SQL防火墙------防注入的"守门员"
Druid内置了WallFilter,可以对SQL进行安全检查,拦截危险的SQL语句,比如DROP TABLE、DELETE without WHERE等。
这在金融、医疗等合规要求比较高的场景下非常重要。
java
// 开启WallFilter配置
ds.setFilters("stat,wall"); // stat=监控,wall=防火墙
// 高级配置:自定义拦截规则
Map<String, String> wallConfig = new HashMap<>();
wallConfig.put("deleteAllow", "false"); // 禁止DELETE操作
wallConfig.put("dropTableAllow", "false"); // 禁止DROP TABLE
wallConfig.put("createTableAllow", "false"); // 禁止CREATE TABLE
WallConfig config = new WallConfig(wallConfig);
WallFilter wallFilter = new WallFilter();
wallFilter.setConfig(config);
ds.setProxyFilters(Arrays.asList(wallFilter));四、两者对比
为了方便大家对比,我用一张表格把两者的差距列出来:
| 对比维度 | HikariCP | Druid |
|---|---|---|
| 设计理念 | 极简高性能,"跑车" | 功能全面可监控,"SUV" |
| 性能表现 | ⭐⭐⭐⭐⭐ 连接获取<5ms | ⭐⭐⭐ 连接获取10-25ms |
| 内存占用 | ~130KB,极度轻量 | ~2MB,功能丰富 |
| TPS峰值 | 15万+/秒 | 8万-12万/秒 |
| 监控能力 | 基础统计 | 可视化仪表盘 + SQL级别追踪 |
| SQL防火墙 | 不支持 | 支持(防注入、黑白名单) |
| 连接泄漏检测 | 日志输出堆栈 | 自动回收 + 堆栈定位 |
| SQL执行分析 | 需配合APM | 内置,实时查看 |
五、到底该怎么选?------实战选型指南
说到这里,大家心里可能已经有个数了。
没有绝对的"更好",只有"更适合"。
我跟大家分享一个决策框架,帮你快速做出选择:
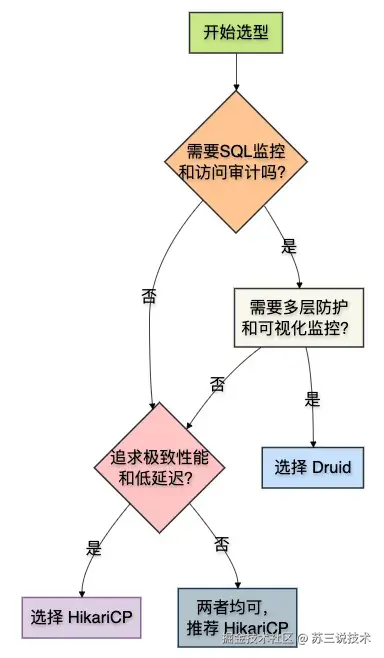
下面分场景来说:
5.1 选HikariCP的场景
- 微服务/云原生架构:对启动速度和内存占用非常敏感,HikariCP的轻量化是最合适的。
- 高并发交易系统:秒杀、抢购、支付场景下,每一毫秒都很关键,HikariCP延迟最低。
- Spring Boot新项目:Spring Boot 2.x+默认就是HikariCP,直接用就好,少一个依赖就少一点维护成本。
- 资源受限的环境:Docker容器内存分配很小的时候,HikariCP更友好。
5.2 选Druid的场景
- 企业级后台管理系统:需要做SQL审计、性能分析,监控功能不可或缺。
- 金融/医疗等合规领域:操作必须留痕,需要SQL防火墙防注入和操作审计。
- 旧系统改造/运维:线上问题多、难以排查,Druid的监控能极大提升排查效率。
- 团队规模较大、需要统一监控平台:Druid的可视化监控面板可以让DBA和开发人员共用。
5.3 给大家一个更详细的选型对比表
| 场景 | 推荐方案 | 核心原因 |
|---|---|---|
| 微服务/云原生 | HikariCP | 低内存开销,快速启动 |
| 高并发交易/秒杀 | HikariCP | 纳秒级连接获取延迟 |
| 大型电商平台 | Druid | 需要深度监控和问题诊断 |
| 金融/医疗系统 | Druid | SQL审计 + 安全防护能力 |
| 旧系统运维改造 | Druid | 可视化监控帮你找到问题 |
| 初创项目/快速原型 | HikariCP | 轻量、简单、够用 |
更多项目实战在我的技术网站:susan.net.cn/project
总结
写这篇文章是希望对还在纠结选哪个连接池的朋友们有所帮助。
不要为了"看起来很厉害"的技术而选型,要从自己的业务需求出发。
用一句话来概括的话:
如果追求极致性能,选HikariCP------"跑车"轻快,直道狂飙;如果需要深度监控和安全防护,选Druid------"SUV"稳重,山路不慌。
如果觉得这篇文章对你有帮助,欢迎转发、点赞、在看,让更多的朋友看到。