目录
[1. 数组的定义](#1. 数组的定义)
[2. 数组的存储原理](#2. 数组的存储原理)
[3. 获取数组首地址(基址)](#3. 获取数组首地址(基址))
[4. 数组寻址公式与比例因子(Scale Factor)](#4. 数组寻址公式与比例因子(Scale Factor))
[5. 数组访问与操作示例](#5. 数组访问与操作示例)
[6. 数组遍历的常见模式](#6. 数组遍历的常见模式)
[7. 注意事项与常见技巧](#7. 注意事项与常见技巧)
[rep 重复执行前缀](#rep 重复执行前缀)

数组
汇编语言中的数组:定义、存储与访问详解
- 在计算机编程中,数组 是一种将多个相同类型的元素存储在连续内存块中的数据结构。
- 它能高效组织和访问批量数据。在汇编语言(MASM)中,数组通常定义在
.data段,通过伪指令直接分配内存。
1. 数组的定义
使用 dd、db、dw 等伪指令定义数组,并可配合 dup 操作符初始化。
示例:
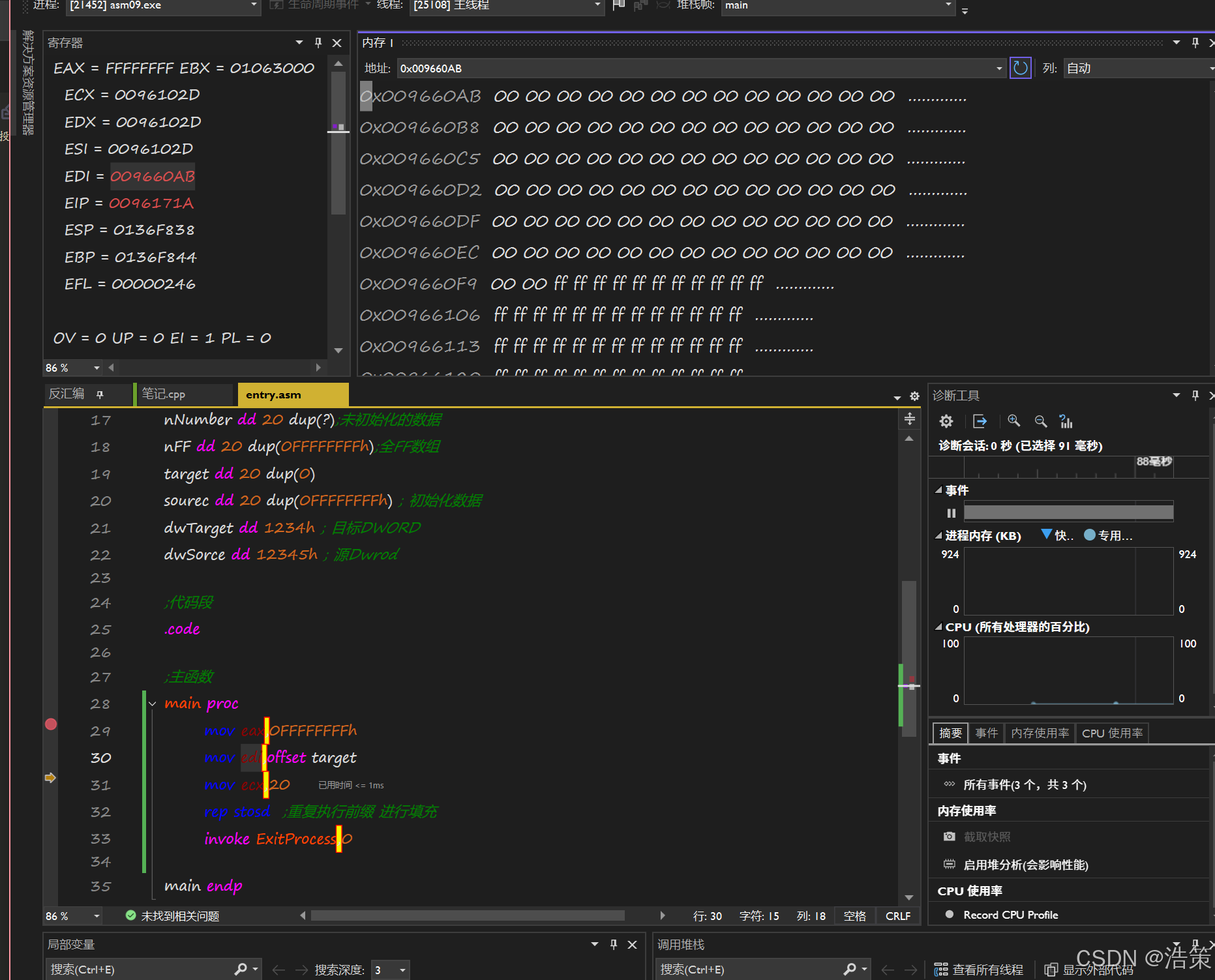
.data
nArray dd 10 dup(0) ; 10个DWORD元素,全部初始化为0
nNumber dd 20 dup(?) ; 20个DWORD,未初始化
nFF dd 20 dup(0FFFFFFFFh) ; 20个DWORD,全部初始化为0xFFFFFFFF
szHello db 'HelloWorld', 0 ; 字符串(本质是字节数组)说明:
-
dd:定义 DWORD(32位/4字节)数据。 -
dup(n):重复初始化n次。 -
?:表示不初始化(保留未初始化内存)。 -
db:定义字节(相当于C语言的char),常用于字符串。
重要 :任意基础数据类型(BYTE、WORD、DWORD、QWORD 等)都可以声明为数组。
2. 数组的存储原理
数组元素在内存中连续线性存储,每个元素占用固定字节数。
-
DWORD数组 :每个元素占 4字节。
-
BYTE数组 (如字符串):每个元素占 1字节。
内存分布示例(nArray):
-
首地址(假设为
0x00401000)存放第0个元素。 -
第1个元素地址 =
0x00401000 + 4 -
第n个元素地址 = 基址 + n × 元素大小
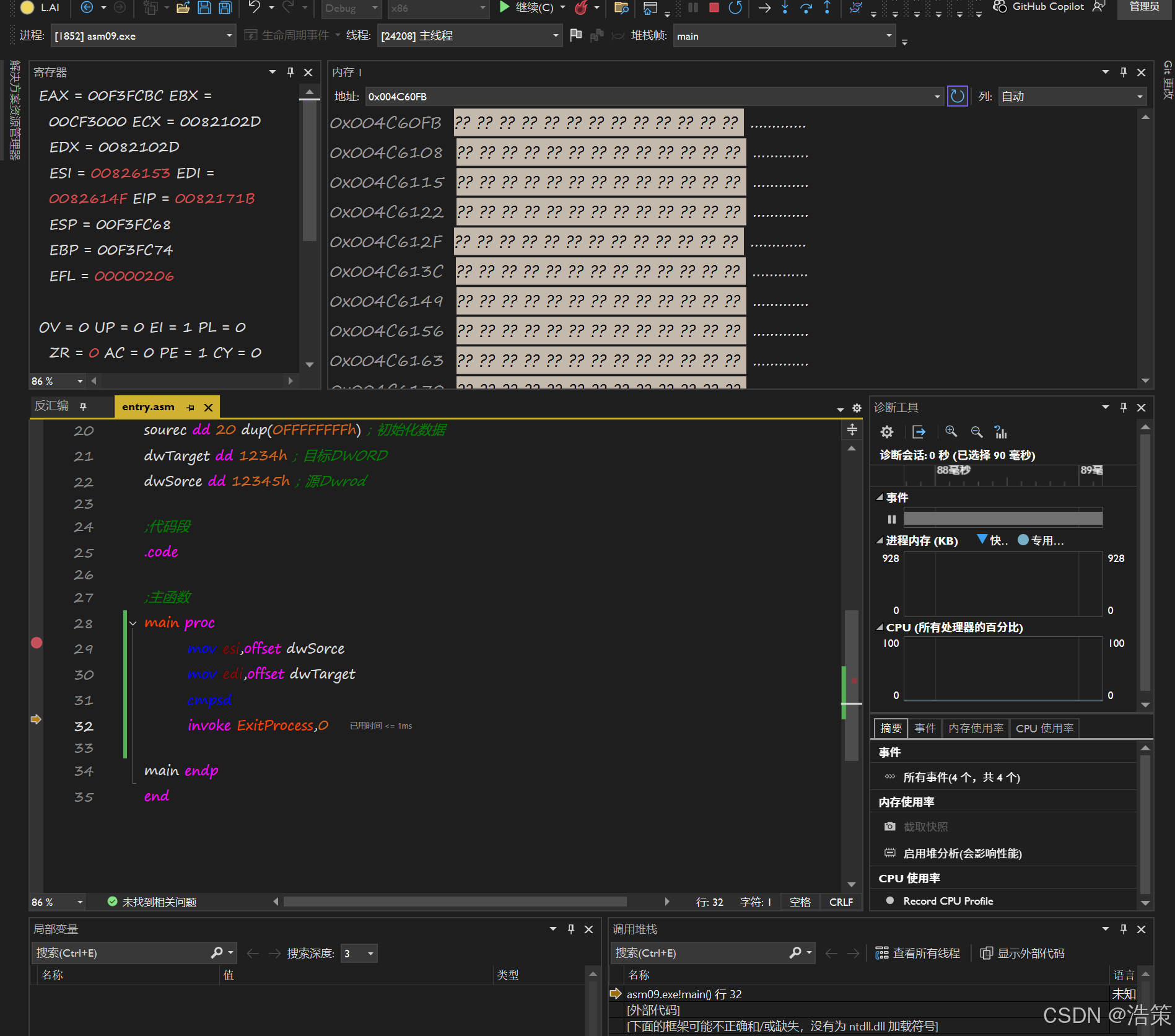
3. 获取数组首地址(基址)
常用三种方式(效果相同):
lea eax, nNumber ; 推荐:加载有效地址
mov eax, offset nNumber ; 使用offset伪指令eax 中保存的就是数组的起始内存地址(基址)。
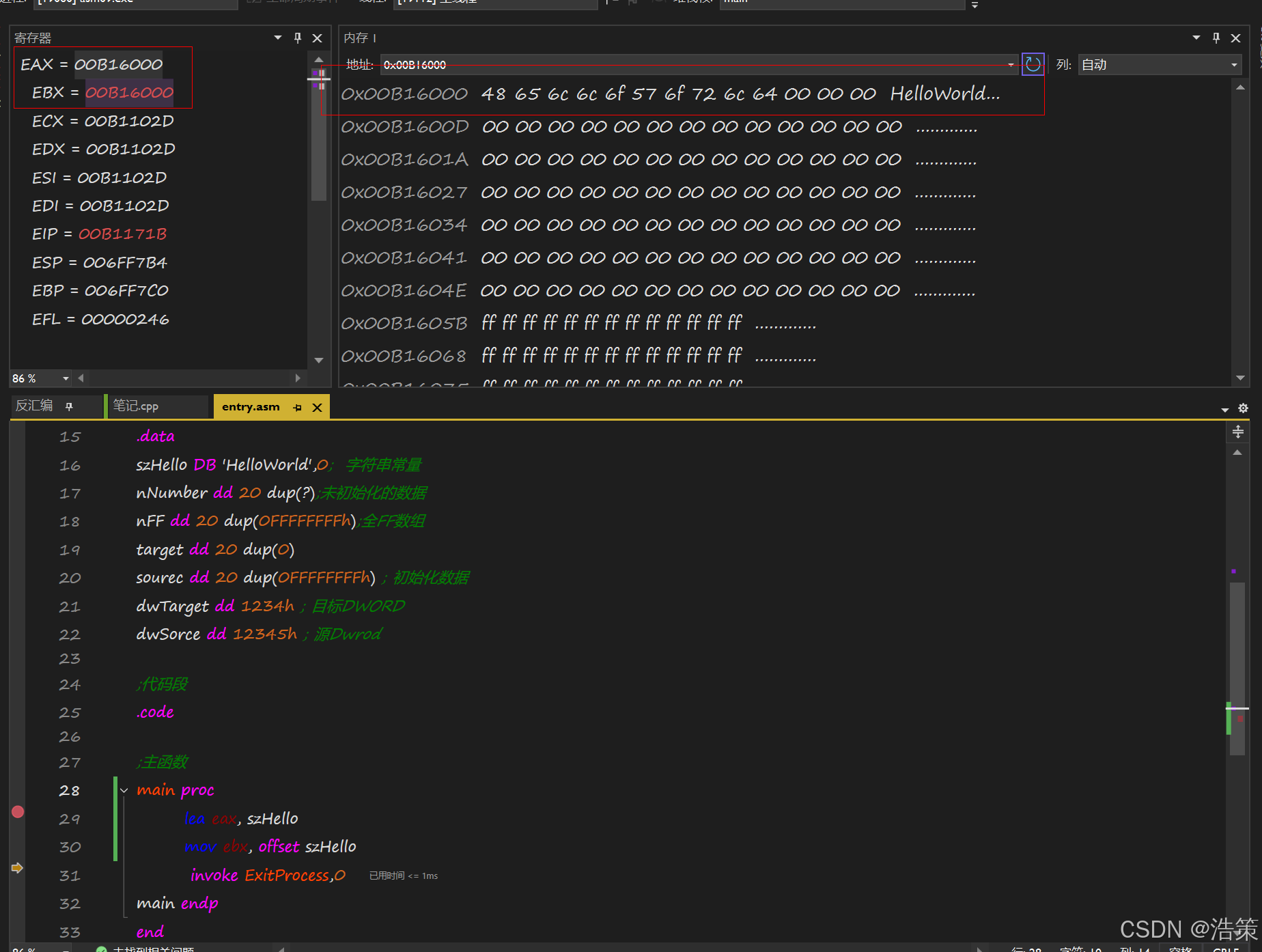
4. 数组寻址公式与比例因子(Scale Factor)
;主函数
main proc
xor edx,edx
mov eax,offset nNumber
mov ecx,20
flag:
mov[eax + edx * 4], ecx
inc edx
loop flag
invoke ExitProcess,0
main endp
end核心公式:
元素地址 = 基址 + 索引 × 元素大小(Type Size)
在汇编中,可直接使用带比例因子的间接寻址:
mov [eax + edx * 4], ecx ; eax=基址, edx=索引, 4=DWORD大小-
eax:基址寄存器 -
edx:索引寄存器(下标) -
4:比例因子(scale),对应元素字节数(BYTE=1, WORD=2, DWORD=4, QWORD=8)
这是CPU硬件直接支持的高效寻址方式,无需手动乘法指令。
5. 数组访问与操作示例
示例1:循环填充数组
.code
main proc
lea eax, nNumber ; 获取数组基址
xor edx, edx ; edx = 0(索引清零)
mov ecx, 20 ; ecx = 循环次数(20个元素)
flag:
mov [eax + edx * 4], ecx ; nNumber[edx] = ecx
inc edx ; 索引 +1
loop flag ; ecx--,若ecx !=0 则跳转到flag
invoke ExitProcess, 0
main endp
end循环机制说明:
-
ECX作为计数器 ,loop指令会自动ECX--,并在ECX != 0时跳转。 -
EDX作为索引,每次递增。
示例2:访问与处理数组元素
mov ecx, 10
mov edx, 0
loop_start:
mov eax, [nArray + edx * 4] ; 读取第edx个元素到eax
; ... 对eax进行处理 ...
inc edx
loop loop_start6. 数组遍历的常见模式
-
基址寄存器 (EAX/EBX)存放
offset。 -
索引寄存器(EDX/ECX)存放下标。
-
使用
loop/dec + jnz控制循环。 -
通过
[基址 + 索引 * scale]访问元素。
这种方式完全依赖寄存器和地址总线计算有效地址,不涉及堆栈操作,执行效率极高。
7. 注意事项与常见技巧
-
未初始化数组 (
dup(?)):内存值随机,使用前必须初始化。 -
字符串数组 :本质是
BYTE数组,以0结尾(C风格字符串)。 -
比例因子必须匹配类型 :DWORD 用
*4,WORD 用*2,BYTE 用*1(或省略)。 -
索引从0开始:符合C语言习惯。
-
越界风险:汇编不做边界检查,需程序员手动控制循环次数。
总结
-
定义 :在
.data段用dd/dw/db + dup定义连续内存。 -
存储:元素连续存放,地址线性递增。
-
访问 :基址 + 索引 × 类型大小,通过带比例因子的间接寻址实现。
-
遍历 :常用
ECX做计数器 +loop指令,或手动inc+ 条件跳转。 -
优势:内存利用率高、访问速度快,是汇编处理批量数据的核心技术。
掌握数组寻址与循环,是从"写指令"到"写程序"的重要一步。它让你能高效处理表格、缓冲区、字符串等各种数据结构。
掌握要点 : 数组 = 连续内存 + 基址 + 索引 × scale 理解这个公式,你就真正理解了汇编中的数组。
串指令
- 串指令(String Instructions)是汇编语言中一组专门为高效处理内存中连续数据块(如字符串、数组)而设计的指令。
- 它们的核心思想是将"操作"和"地址更新"合并为一步,从而简化代码并提升性能。
什么是串指令?
- 简单来说,串指令可以自动完成以下两个步骤:
- 执行一个基本操作 :
- 例如,从内存读取数据、向内存写入数据、比较数据等。
- 自动更新地址指针 :
- 根据预设的方向,自动将源地址指针(SI/ESI/RSI)和/或目标地址指针(DI/EDI/RDI)指向下一个(或上一个)数据单元。
- 这种自动化机制使得处理大量连续数据时,无需手动编写循环来递增或递减指针,代码更简洁,执行效率也更高。
主要的串指令
串指令家族主要包括以下几类,它们通常都有字节(B)、字(W)、双字(D)等不同操作尺寸:
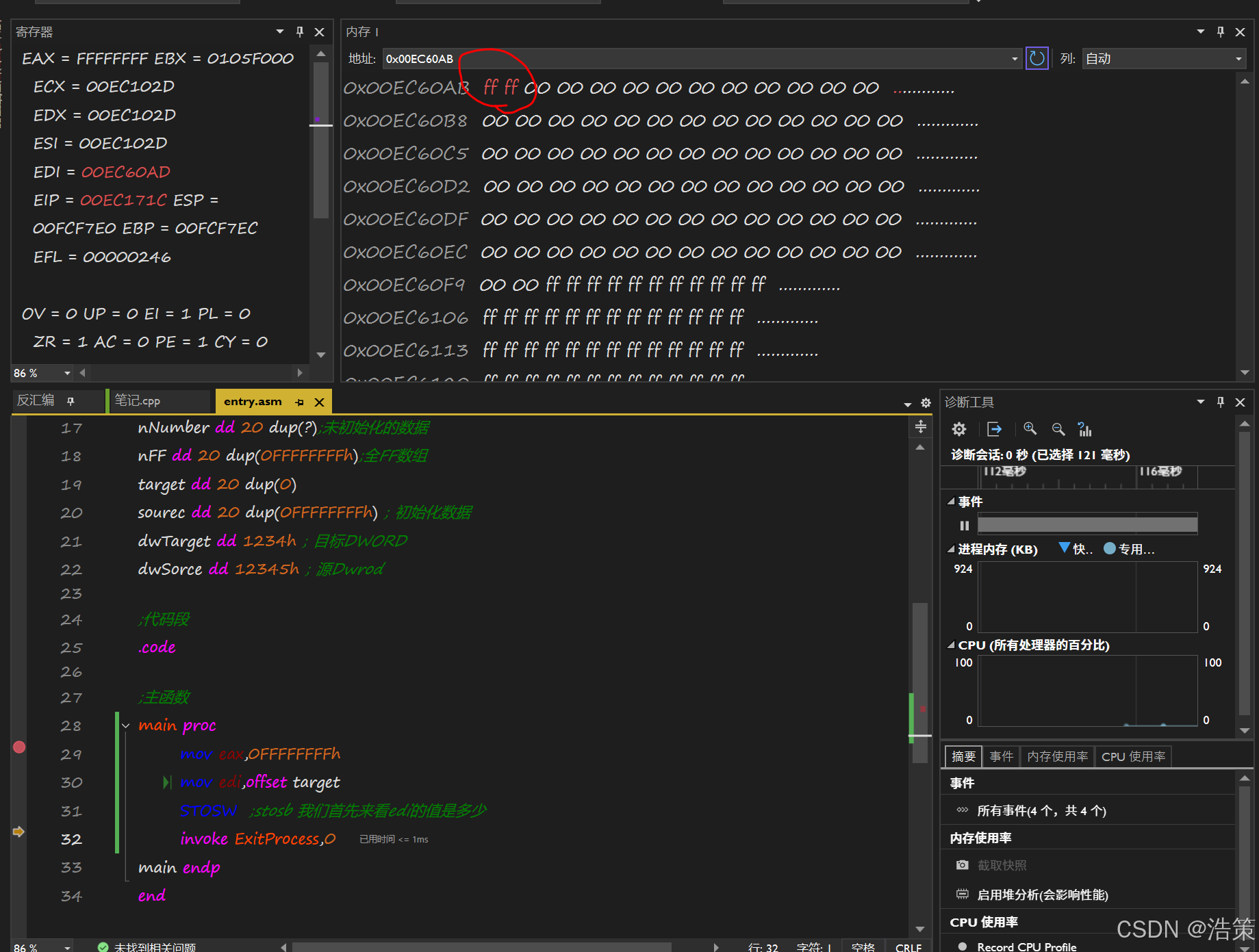
MOVS(Move String) : 串传送。将数据从源地址(DS:SI)复制到目标地址(ES:DI)。STOS(Store String) : 存串。将累加器(AL/AX/EAX)中的数据写入到目标地址(ES:DI),常用于内存填充。LODS(Load String) : 取串。从源地址(DS:SI)读取数据到累加器(AL/AX/EAX)。CMPS(Compare String) : 串比较。比较源地址(DS:SI)和目标地址(ES:DI)的数据,并根据结果设置标志位。SCAS(Scan String) : 串扫描。用累加器(AL/AX/EAX)中的数据与目标地址(ES:DI)的数据进行比较,用于在字符串中搜索特定值。
使用串指令的注意点
使用串指令时,有几个关键点必须提前设置好,否则可能导致错误的结果:
-
设置方向标志 (DF)
- 串操作的方向由方向标志位(DF)决定。
- 使用
CLD指令将 DF 清零(DF=0),地址指针会自动递增,实现从低地址到高地址的正向操作。 - 使用
STD指令将 DF 置一(DF=1),地址指针会自动递减,实现从高地址到低地址的反向操作。 - 在执行任何串指令前,务必明确设置 DF 的状态。
-
初始化地址指针 (SI/DI)
- 源串的地址由
SI(或ESI/RSI)寄存器指向,默认在数据段(DS)中。 - 目标串的地址由
DI(或EDI/RDI)寄存器指向,默认在附加段(ES)中。 - 在操作前,必须将源数据和目标缓冲区的起始地址正确地加载到这两个寄存器中。
- 源串的地址由
-
设置重复次数 (CX)
- 当与重复前缀(如
REP)配合使用时,需要操作的元素个数(长度)必须预先存入CX(或ECX/RCX)寄存器中。
- 当与重复前缀(如
-
初始化段寄存器 (DS/ES)
- 确保数据段寄存器(
DS)和附加段寄存器(ES)指向正确的内存段。如果源串和目标串在同一个段,也需要将ES设置为与DS相同的值。
- 确保数据段寄存器(
-
重复前缀不能单独使用
REP、REPE、REPNE等是前缀,不是独立的指令,必须紧跟在一条串指令前面才能生效。
什么时候使用串指令?
串指令在需要高效处理连续内存块的场景中非常有用:
- 内存复制 :使用
REP MOVSB或REP MOVSD可以快速地将一块内存数据复制到另一块内存区域,效率远高于手动循环。 - 内存初始化/填充 :使用
REP STOSB可以将一个值(如0)快速写入一大片内存区域,常用于将缓冲区清零。 - 字符串搜索 :使用
REPNE SCASB可以在一个字符串中快速查找某个特定字符(如字符串结束符\0)。 - 数据块比较 :使用
REPE CMPSB可以快速比较两个内存块的内容是否完全相同。
sto操作的方法
-
Sto stosb stosw stosd srosq
-
STOSB(Store String Byte)**:-
作用 : 将
AL寄存器中的一个**字节**数据存储到ES:DI(或EDI/RDI) 指向的内存地址,并根据方向标志 (DF) 自动递增或递减目标地址指针1。 -
简而言之 : 将
AL的内容写入内存,每次一个字节。
-
-
-
STOSW(Store String Word)**:-
作用 : 将
AX寄存器中的一个**字**(2字节)数据存储到ES:DI(或EDI/RDI) 指向的内存地址,并根据方向标志 (DF) 自动递增或递减目标地址指针2。 -
简而言之 : 将
AX的内容写入内存,每次两个字节。
-
-
STOSD(Store String Doubleword)**:-
作用 : 将
EAX寄存器中的一个**双字**(4字节)数据存储到ES:DI(或EDI/RDI) 指向的内存地址,并根据方向标志 (DF) 自动递增或递减目标地址指针4。 -
简而言之 : 将
EAX的内容写入内存,每次四个字节。
-
-
STOSQ(Store String Quadword)**:-
作用 : (仅在64位模式下可用) 将
RAX寄存器中的一个**四字**(8字节)数据存储到RDI指向的内存地址,并根据方向标志 (DF) 自动递增或递减目标地址指针8。 -
简而言之 : 将
RAX的内容写入内存,每次八个字节。
-
rep 重复执行前缀
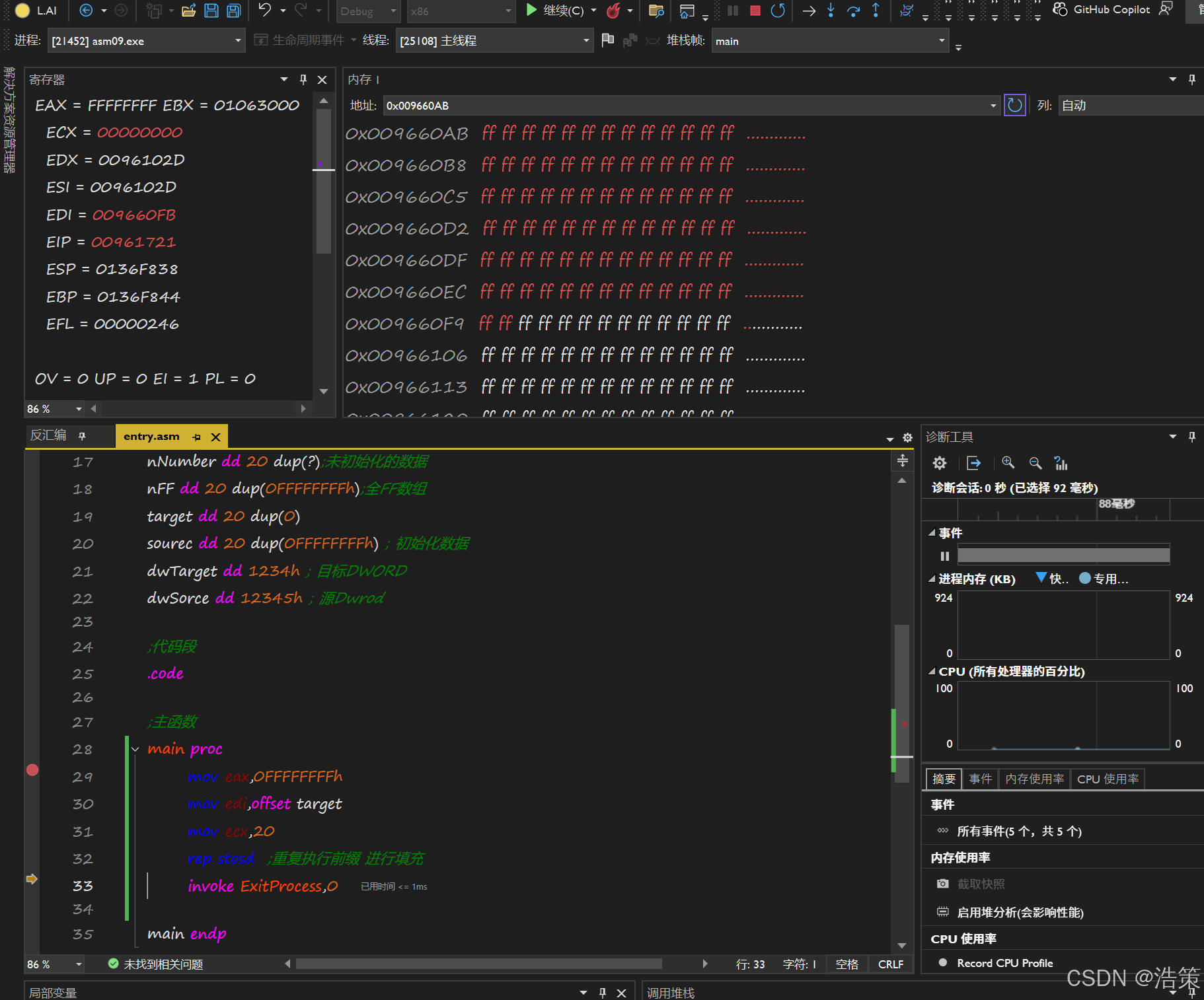
Load
-
lods lodsb lodsw lodsd lodsq
-
这些指令是x86汇编语言中用于字符串操作的指令,具体来说是"加载字符串"指令。
-
它们的作用是将内存地址中的数据加载到累加器寄存器,并根据方向标志(DF)自动更新源地址指针。
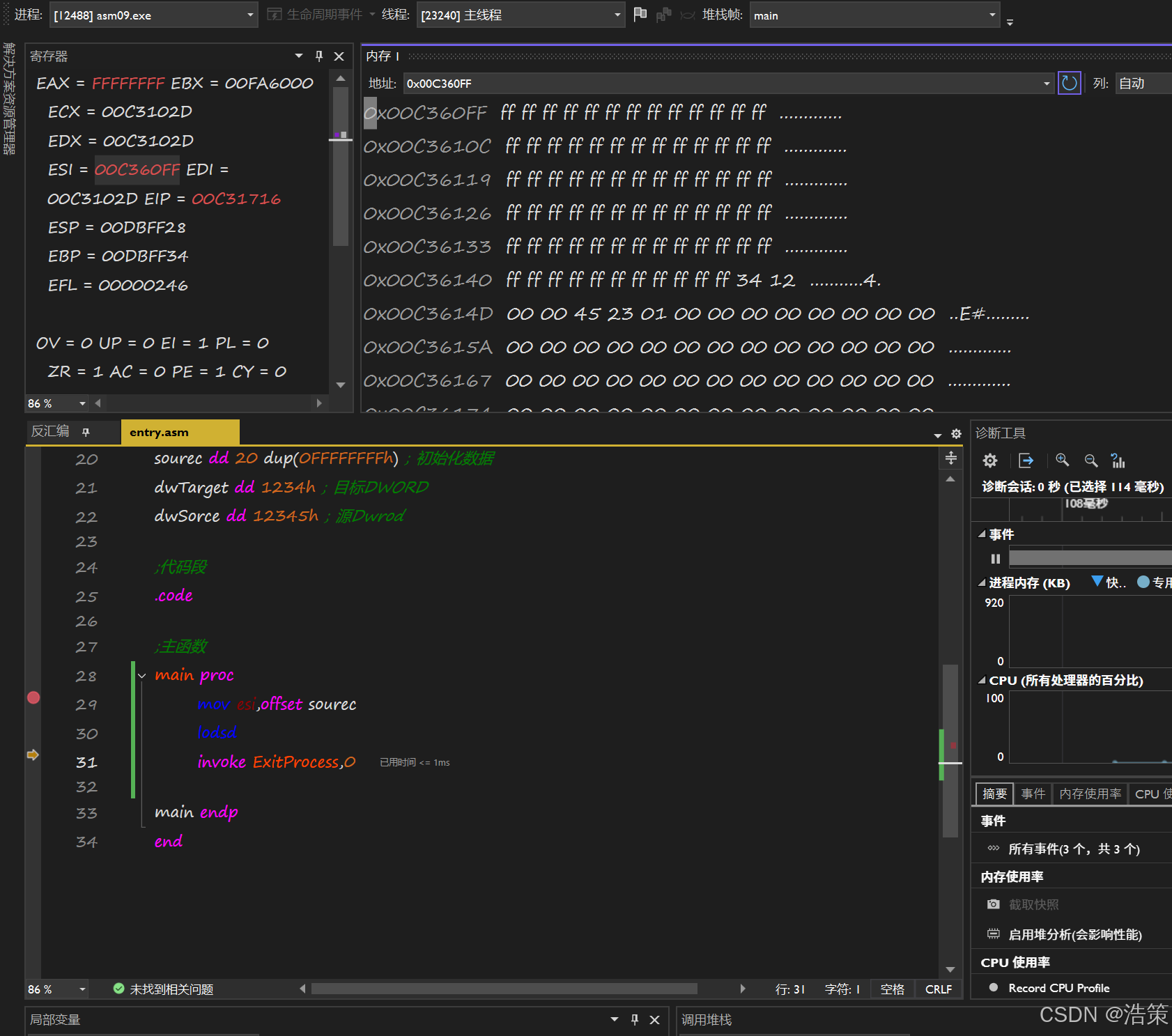
-
源地址寄存器:
-
在32位模式下,使用
ESI寄存器作为源地址。DS段寄存器通常被忽略或默认为数据段。 -
在64位模式下,使用
RSI寄存器作为源地址。DS段寄存器被忽略。
-
-
方向标志 (DF - Direction Flag):
-
如果
DF = 0(使用CLD指令设置),则SI/ESI/RSI在每次操作后会**增加**。 -
如果
DF = 1(使用STD指令设置),则SI/ESI/RSI在每次操作后会**减少**。
-
-
重复前缀 (REP):
-
LODS指令通常**不**与REP前缀直接结合使用,因为LODS每次操作只加载一个数据项到累加器 -
而
REP会重复执行指令直到计数器为零,这会覆盖累加器中的值 -
LODS更常用于在循环中手动处理每个加载的数据。
-
-
LODSB(Load String Byte)**:-
作用 : 从
DS:SI(或ESI/RSI) 指向的内存中加载一个**字节**到AL,并更新SI/ESI/RSI。 -
简而言之 : 每次一个字节地从内存读取数据到
AL。
-
-
LODSW(Load String Word)**:-
作用 : 从
DS:SI(或ESI/RSI) 指向的内存中加载一个**字**(2字节)到AX,并更新SI/ESI/RSI。 -
简而言之 : 每次两个字节地从内存读取数据到
AX。
-
-
LODSD(Load String Doubleword)**:-
作用 : 从
DS:SI(或ESI/RSI) 指向的内存中加载一个**双字**(4字节)到EAX,并更新SI/ESI/RSI。 -
简而言之 : 每次四个字节地从内存读取数据到
EAX。
-
-
LODSQ(Load String Quadword)**:-
作用 : (仅在64位模式下可用) 从
RSI指向的内存中加载一个**四字**(8字节)到RAX,并更新RSI。 -
简而言之 : 每次八个字节地从内存读取数据到
RAX。
-
movs
movs 系列指令用于在内存之间复制数据块。它们是字符串操作指令,通常与 rep 前缀结合使用以复制多个数据单元。
-
movs: 这是一个通用的字符串移动指令。它的具体操作大小取决于操作数大小前缀(例如,movsw移动字,movsd移动双字)。如果没有明确指定大小,汇编器会根据上下文推断,或者你需要使用特定大小的版本。 -
movsb: **Move String Byte**。将一个字节从DS:SI(或RSI)指向的内存位置复制到ES:DI(或RDI)指向的内存位置。复制后,SI和DI(或RSI和RDI)会根据方向标志(DF)自动递增或递减。 -
movsw: **Move String Word**。将一个字(2字节)从DS:SI(或RSI)指向的内存位置复制到ES:DI(或RDI)指向的内存位置。复制后,SI和DI(或RSI和RDI)会根据方向标志(DF)自动递增或递减2。 -
movsd: **Move String Doubleword**。将一个双字(4字节)从DS:SI(或RSI)指向的内存位置复制到ES:DI(或RDI)指向的内存位置。复制后,SI和DI(或RSI和RDI)会根据方向标志(DF)自动递增或递减4。 -
movsq: **Move String Quadword**。在64位模式下可用。将一个四字(8字节)从RSI指向的内存位置复制到RDI指向的内存位置。复制后,RSI和RDI会根据方向标志(DF)自动递增或递减8。
这些指令通常与 rep、repe、repne 等前缀一起使用,以重复执行复制操作,直到 CX(或 RCX)寄存器减为零。例如,rep movsb 会重复复制字节,直到 CX 为零。
cmps
cmps 系列指令用于在内存之间比较数据块。它们是字符串操作指令,通常与 rep 前缀结合使用以比较多个数据单元。
-
cmps: 这是一个通用的字符串比较指令。它的具体操作大小取决于操作数大小前缀(例如,cmpsw比较字,cmpsd比较双字)。如果没有明确指定大小,汇编器会根据上下文推断,或者你需要使用特定大小的版本。它通过从DS:SI(或RSI)指向的内存位置减去ES:DI(或RDI)指向的内存位置的数据来执行比较,并根据结果设置标志寄存器(如 ZF、CF、SF、OF、PF、AF),但**不存储结果**。 -
cmpsb: **Compare String Byte**。比较一个字节:从DS:SI(或RSI)指向的内存位置读取一个字节,并从ES:DI(或RDI)指向的内存位置读取一个字节,然后执行相减操作([DS:SI] - [ES:DI]),并根据结果设置标志寄存器。比较后,SI和DI(或RSI和RDI)会根据方向标志(DF)自动递增或递减。 -
cmpsw: **Compare String Word**。比较一个字(2字节):从DS:SI(或RSI)指向的内存位置读取一个字,并从ES:DI(或RDI)指向的内存位置读取一个字,然后执行相减操作,并根据结果设置标志寄存器。比较后,SI和DI(或RSI和RDI)会根据方向标志(DF)自动递增或递减2。 -
cmpsd: **Compare String Doubleword**。比较一个双字(4字节):从DS:SI(或RSI)指向的内存位置读取一个双字,并从ES:DI(或RDI)指向的内存位置读取一个双字,然后执行相减操作,并根据结果设置标志寄存器。比较后,SI和DI(或RSI和RDI)会根据方向标志(DF)自动递增或递减4。 -
cmpsq: **Compare String Quadword**。在64位模式下可用。比较一个四字(8字节):从RSI指向的内存位置读取一个四字,并从RDI指向的内存位置读取一个四字,然后执行相减操作,并根据结果设置标志寄存器。比较后,RSI和RDI会根据方向标志(DF)自动递增或递减8。
这些指令通常与 repe (Repeat while Equal) 或 repne (Repeat while Not Equal) 前缀一起使用。
-
repe cmpsb会重复比较字节,只要字节相等且CX(或RCX)不为零,就继续比较。一旦遇到不相等的字节或CX变为零,循环就会停止。 -
repne cmpsb会重复比较字节,只要字节不相等且CX(或RCX)不为零,就继续比较。一旦遇到相等的字节或CX变为零,循环就会停止。