作为常年在一线与海量数据打交道的后端开发者,在复杂的业务系统开发中,处理重复数据是我们绕不开的命题。为了保证输出数据的唯一性,我们经常在 SQL 中使用 DISTINCT 关键字,或者利用全字段 GROUP BY 来实现语义上的去重。
然而,随着业务数据的指数级增长,这类去重操作屡屡成为拖垮系统查询性能的"隐形杀手"。最近,团队在进行底层基础软件的迁移与性能攻坚,我们将核心业务线迁移至了电科金仓数据库Kingbase。在深度剖析慢查询日志与底层执行计划时,我发现现代数据库的优化器早已跨越了单纯比对物理代价的阶段,进化出了基于编译逻辑推理的高级智能内核。
今天,我们就结合具体的 SQL 实操和极端场景下的底层执行计划对比,硬核拆解现代数据库是如何通过"常值推导"等语义重写手段,优雅且彻底地消灭去重性能瓶颈的。 
@toc
一、 传统执行引擎的痛点:物理层面的"暴力去重"
要理解优化的精妙,我们首先要明白传统数据库在处理去重时有多么"死板"。在传统的执行引擎眼中,无论是 DISTINCT 还是 GROUP BY 去重,底层的物理实现逻辑基本都是一套标准流程:全表或索引扫描过滤目标数据 -> 将数据送入内存构建哈希表或进行排序 -> 逐行分组比对剔除重复项。
为了直观展示这种性能浪费,我们在数据库中构建了一个包含海量冗余数据的测试表 s1,并模拟了一个需要对常量条件进行去重的查询场景:
sql
-- 传统的去重查询写法(使用 GROUP BY 替代 DISTINCT 实现语义去重)
EXPLAIN ANALYZE SELECT a, b FROM s1 WHERE a=1 AND b=1 GROUP BY a, b;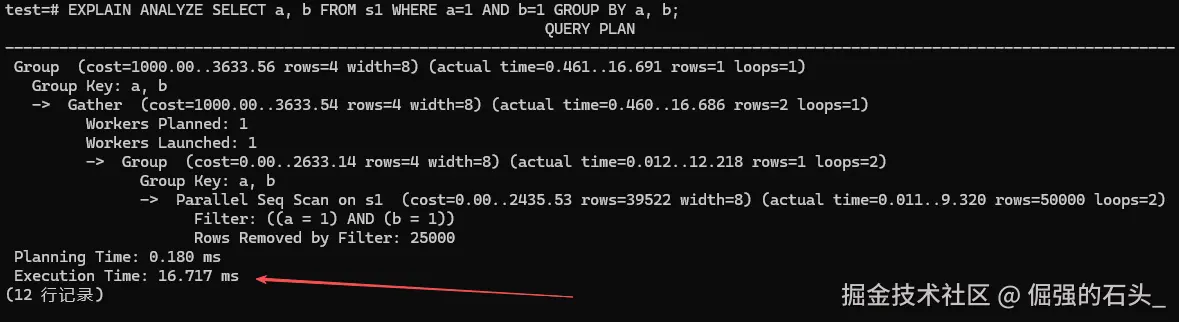
性能灾难分析: 如上图的执行计划所示,数据库极其"老实"地执行了并行全表扫描(Parallel Seq Scan),把满足条件的冗余数据全部捞了出来。接着,启动了 Group 算子,在内存中为这些长得一模一样 的数据进行毫无意义的分组比对。整个过程白白消耗了 16.717 毫秒。不仅浪费 CPU,还极大地占用了内存空间。
二、 破局之道:常值推导与 LIMIT 1 的降维打击
真正的技术突破,发生在于 SQL 解析阶段之后的逻辑优化环节。Kingbase的核心思路是:在进入物理执行之前,先在抽象语法树层面审视这条 SQL 的语义。 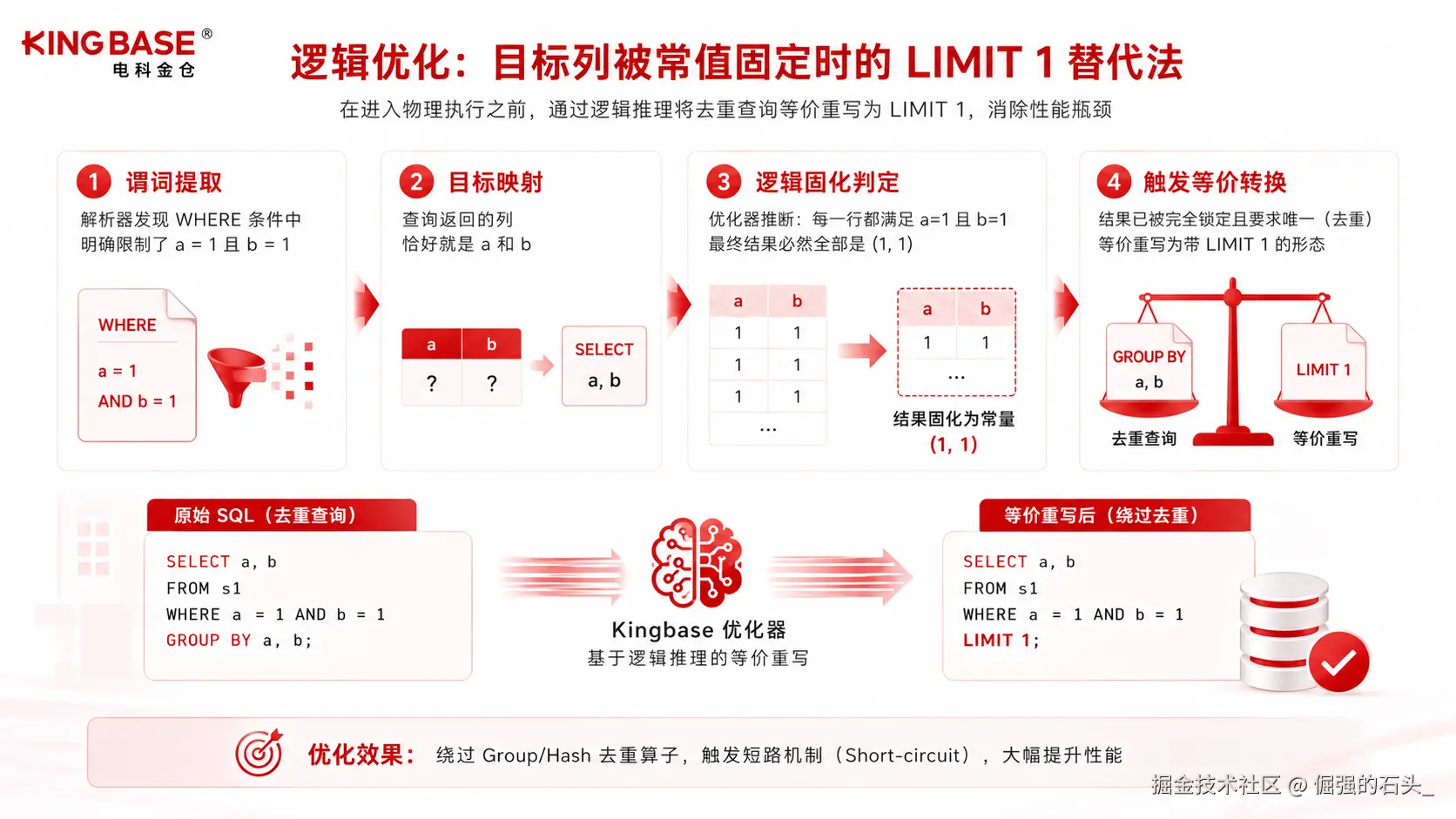
具备高级智能的数据库内核在这里引入了一项堪称"降维打击"的优化策略:目标列被常值固定时的 LIMIT 1 替代法。
它的底层逻辑推理链条非常严密:
- 谓词提取 :解析器发现
WHERE条件中明确限制了a = 1且b = 1。 - 目标映射 :查询返回的列恰好就是
a和b。 - 逻辑固化判定 :优化器推断出,既然结果集里的每一行都必须满足这两个字段等于固定常量,那么最终查出来的所有行,必然全部是
(1, 1)。 - 触发等价转换 :既然结果的样貌已被完全锁定,且业务明确要求结果唯一(去重)。此时优化器会在底层直接把原始语句等价重写为带有
LIMIT 1的形态,直接绕过底层的去重算子。
为了验证这个理论,我们手动将 SQL 改写为 LIMIT 1 模式来观测极限性能:
sql
-- 验证 LIMIT 1 带来的短路效应
EXPLAIN ANALYZE SELECT a, b FROM s1 WHERE a=1 AND b=1 LIMIT 1;
实操见证奇迹: 执行时间从 16.717 毫秒,断崖式暴降到了惊人的 0.048 毫秒 ! 原因就在于顶层的 Limit 算子。底层的扫描器只要碰巧扫到了第一条符合要求的数据,就会立刻触发"短路机制(Short-circuit)",直接向客户端返回结果,并强行终止底层后续的无数次扫描。沉重的去重操作被瞬间消解。
三、 深入无人区:复杂多表 JOIN 下的去重灾难
单表的常值推导固然惊艳,但真实的企业级应用充斥着复杂的表关联。在多表 INNER JOIN 的环境下,传统数据库的去重机制会引发多大的灾难?
我们引入表 s2,构造一个更复杂的关联去重场景。请注意,接下来的数据会非常震撼。
sql
-- 复杂多表关联场景下的去重查询
EXPLAIN ANALYZE
SELECT s1.a, s2.b
FROM s1
INNER JOIN s2 ON s1.a = s2.b
WHERE s1.a = 5
GROUP BY s1.a, s2.b; 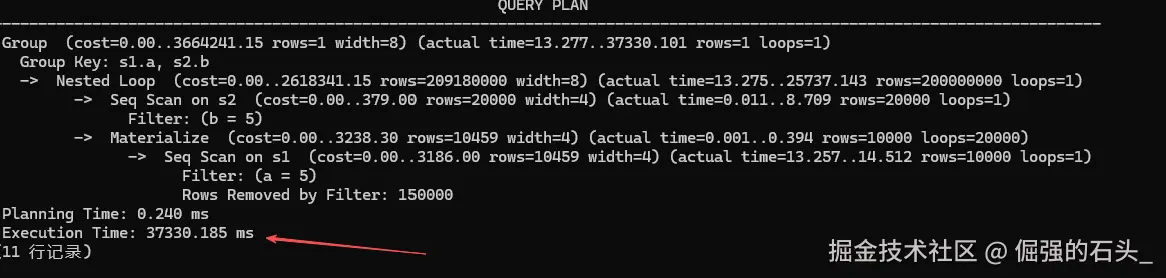
史诗级的性能灾难: 仔细剖析这条 SQL,存在一个隐蔽的逻辑陷阱:查询目标列是 s1.a 和 s2.b。但在 WHERE 条件中,开发者只写了 s1.a = 5,并没有直接说明 s2.b 等于几。
对于传统的低阶优化器来说,它在这里就停止思考了。从执行计划中我们可以看到恐怖的一幕:底层的 Nested Loop(嵌套循环连接)疯狂地执行了 2亿次 (loops=200000000)!最终导致这条查询耗时飙升到了令人窒息的 37330.185 毫秒(近 37 秒)!
四、 词间等值推导:将 37 秒化为 12 毫秒的神奇魔法
面对上述灾难,具备高阶推导能力的现代优化器是如何破局的呢?它会在内核中构建一张等值传递网络:
- 已知明确条件 :
s1.a = 5。 - 已知关联条件 :
s1.a = s2.b。 - 高阶推导 :既然 A=5 且 A=B,那么必然得出 B=5。即隐藏的常量条件
s2.b = 5绝对成立! - 此时回头检查查询的目标列
s1.a和s2.b,发现它们的值已经在逻辑上被完全固化为常量!
一旦推导成功,高级内核即可触发等价重写规则,将外层的去重操作直接替换为 LIMIT 1。我们再次手动模拟内核重写后的形态,进行性能验证:
sql
-- 模拟高阶优化器通过等值推导重写后的 SQL
EXPLAIN ANALYZE
SELECT s1.a, s2.b
FROM s1
INNER JOIN s2 ON s1.a = s2.b
WHERE s1.a = 5
LIMIT 1; 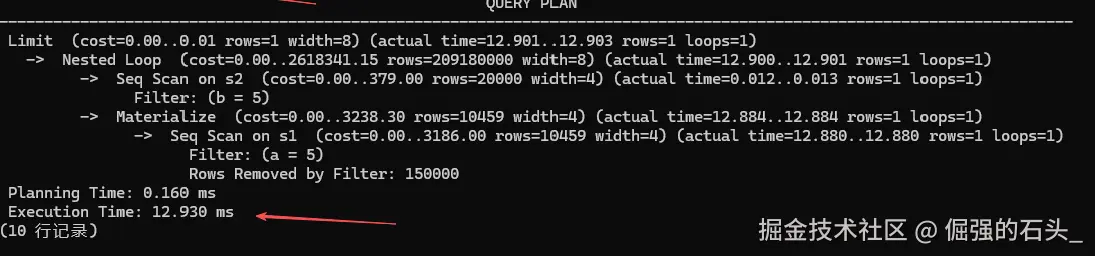
执行计划结果令人振奋:顶层的 Limit 算子如同定海神针。虽然底层扫描定位第一条符合 s1.a=5 的数据花了十几毫秒,但关键在于,那个原本疯狂循环 2 亿次的 Nested Loop,在探测到第一组匹配的数据后被瞬间截断(loops=1)!
原本耗时近 37 秒 的关联去重慢查询,最终耗时仅仅定格在 12.930 毫秒。性能提升了近 3000 倍!
五、 写在最后
刚才咱们把这些藏在数据库最底层的执行机制给捋了一遍,其实看完之后,我自己也在琢磨平时大家写业务代码的习惯。也就是说,要是遇到慢查询的情况,除了砸钱去加服务器硬件配置这种笨办法之外,其实利用底层的编译逻辑去把 SQL 重新处理一遍,才是现在这些底层软件最关键的技术点。
那么,这些东西对咱们平时做开发的同学来说,其实有这么几个挺实在的建议:
- 顺着引擎的思路去写:通常来说,我们在写那种很复杂的好几张表互相连表的情况的话,你的常量过滤条件尽量能写多全就写多全。哪怕它只是个间接的条件,也给它加上。为什么呢?因为这样一来的话,就能帮优化器省下很多事,它就能更容易地去把那个等值传递的链路给顺畅地串起来。
- 自己把控好逻辑 :如果说在写业务代码的时候,你心里非常清楚查出来的结果肯定就只有这一条的话。接着你干脆老老实实就在 SQL 语句的最后面加上个
LIMIT 1。这种做法,往往仅仅只是多敲了几个字母,但真的比你完全指望着数据库底层自己去帮你做分组和去重要稳当得多。 - 多去了解底层的变化:其实像电科金仓这种国产数据库,现在他们确实在引擎最底层的那块(比如像是用 GUC 参数去控制的那些自动改写功能)做了很多很实在的改动。平时要是能多花点时间去弄明白这些底层到底是怎么去做逻辑推理的,那么以后咱们自己去搞架构设计,或者说系统卡了需要去调优的时候,心里就有底了,不至于两眼一抹黑到处乱试。