Hugging Face:AI 时代的开源基础设施
如果说 GitHub 改变了软件开发者协作写代码的方式,那么 Hugging Face 正在改变 AI 开发者使用、分享、训练和部署模型的方式。
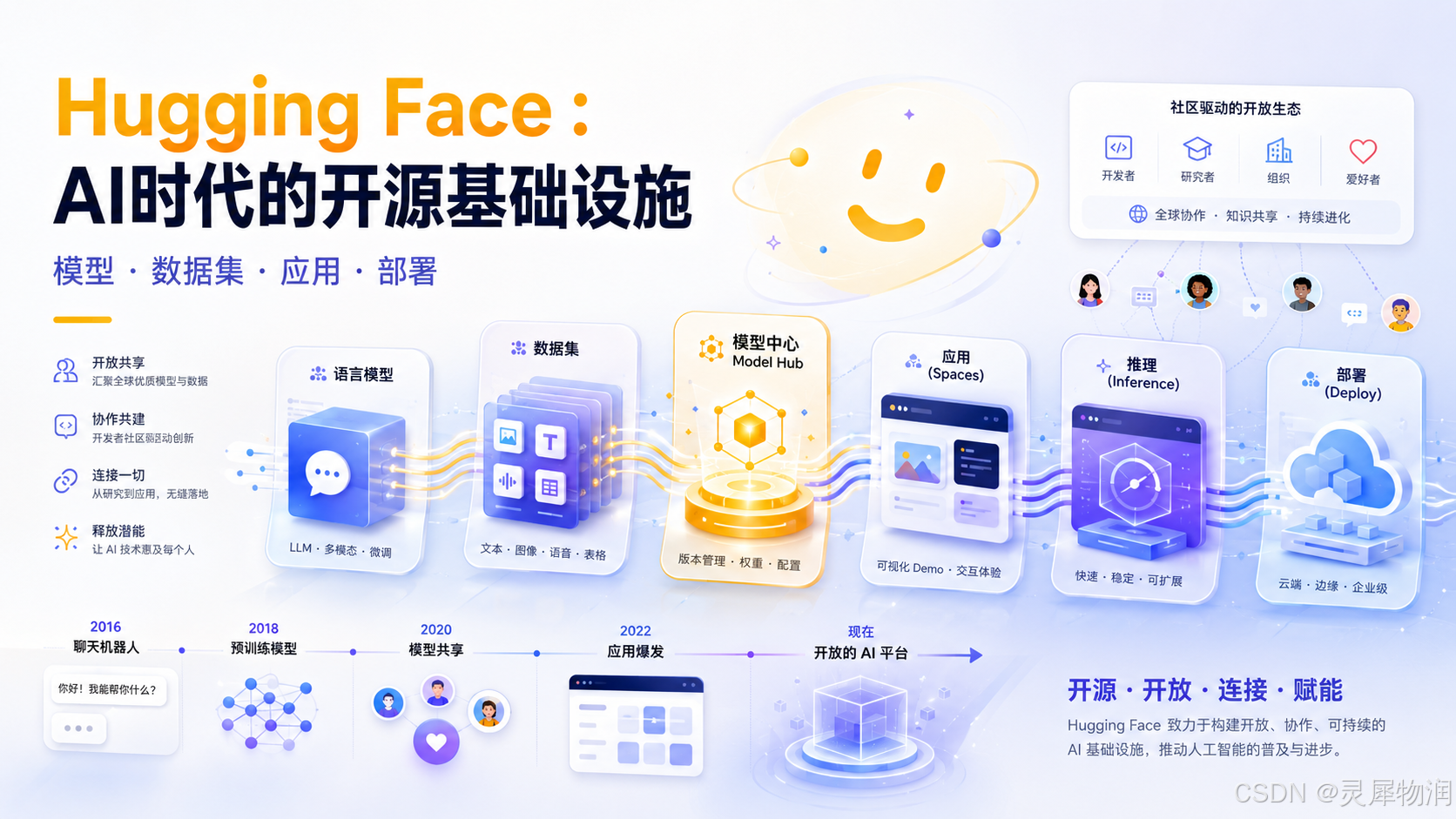
很多人第一次听到 Hugging Face,会以为它只是一个下载大模型的网站。实际上,它已经远远不只是"模型仓库"。今天的 Hugging Face 更像是一个围绕人工智能模型建立起来的综合平台:它既是模型市场,也是数据集仓库;既是开源工具生态,也是 AI Demo 展示平台;既服务个人开发者,也服务企业级 AI 应用落地。
截至目前,Hugging Face Hub 官方文档显示,它托管了超过 200 万个模型、150 万个数据集和 150 万个 AI 应用 Spaces,是开放机器学习领域最重要的平台之一。
一、Hugging Face 到底是什么?
Hugging Face 可以用一句话概括:
Hugging Face 是面向 AI 模型、数据集、应用和工具链的开放协作平台。
在传统软件开发中,开发者会把代码上传到 GitHub,别人可以查看、复制、修改、提交 Pull Request。而在 AI 开发中,除了代码之外,还需要模型权重、训练数据、模型说明、推理接口、Demo 页面、评测结果和部署环境。Hugging Face 正是为这些 AI 资产提供统一管理和协作的平台。
它最核心的组成部分包括:
- Hugging Face Hub:模型、数据集和 AI 应用的托管平台;
- Transformers:最著名的模型调用和训练库;
- Datasets:数据集加载、处理和分享工具;
- Spaces:AI 应用 Demo 展示平台;
- Diffusers:图像、视频、音频等生成式模型工具库;
- Inference Providers / Inference Endpoints:模型推理和部署服务;
- 企业协作能力:私有模型仓库、权限管理、团队协作和生产部署。
所以,Hugging Face 的真正价值不只是"有很多模型",而是它把 AI 开发过程中最关键的环节串联了起来。
二、Hugging Face 解决了什么问题?
AI 开发的难点并不只是"写代码"。在大模型时代,一个 AI 项目往往会遇到这些问题:
第一,去哪里找合适的模型?
第二,模型权重如何下载和管理?
第三,模型支持什么任务、什么语言、什么 License?
第四,如何加载模型并进行推理?
第五,如何找到训练或微调需要的数据集?
第六,如何快速做一个 Demo 给别人测试?
第七,如何把模型部署到生产环境?
Hugging Face 的作用,就是把这些原本分散、复杂、门槛很高的工作,变成相对标准化、工程化、可复用的流程。
三、Hugging Face Hub:AI 模型世界的"集散中心"
Hugging Face Hub 是整个平台的核心。开发者可以在上面搜索模型、下载模型、查看模型说明、比较模型能力,也可以上传自己的模型和数据集。官方文档把 Hub 定义为开放机器学习的参考平台,同时也支持企业内部和私有团队协作。
在 Hugging Face Hub 上,一个模型通常不只是一个文件夹。它通常包含:
- 模型权重;
- 配置文件;
- Tokenizer;
- README / Model Card;
- 使用示例;
- 许可证信息;
- 训练数据说明;
- 适用任务标签;
- 在线推理入口或关联 Demo。
其中 Model Card 非常重要。Hugging Face 官方文档说明,Model Card 通常以 README.md 的形式存在,用来提供模型相关信息,并帮助模型被发现、复现和分享。
这对于企业和研究人员尤其重要。因为模型不是普通代码,一个模型能不能用于商业场景,是否有数据风险,是否适合某种语言或行业,都需要清晰说明。
四、Transformers:让大模型真正进入开发者工作流
Hugging Face 最有影响力的开源项目是 Transformers。
Transformer 架构是现代大语言模型和许多多模态模型的基础,但直接使用这些模型并不简单。开发者需要处理模型结构、权重加载、Tokenizer、推理流程、GPU 加速、微调脚本等大量细节。
Transformers 的价值就在于:它用相对统一的 API,把 BERT、GPT、T5、Llama、Qwen、Mistral、Gemma 等不同模型接入到同一个开发体验中。Hugging Face 官方文档显示,Transformers 支持文本、计算机视觉、音频、视频和多模态任务,并且 Hub 上有超过 100 万个 Transformers 模型检查点可用。
对普通开发者来说,这意味着你不需要从零实现模型架构,也不需要自己处理大量底层细节。你可以直接加载预训练模型,完成文本分类、问答、摘要、翻译、生成、语音识别、图像理解等任务。
例如,使用 Transformers 做情感分析,只需要非常少的代码:
python
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("Hugging Face makes AI development easier.")
print(result)这背后的意义很大:Hugging Face 把复杂的 AI 研究成果,变成了普通工程师可以直接调用的开发工具。
五、Datasets:模型之外,数据同样重要
在 AI 项目中,模型很重要,但数据同样重要,甚至很多时候更重要。
Hugging Face 的 Datasets 库提供了大量可直接使用的数据集,并且支持高效的数据加载、处理和分享。它覆盖自然语言处理、计算机视觉、语音等多种任务类型。Hugging Face 的 datasets 项目也将自己定位为面向 AI 模型的即用型数据集中心,并提供快速、易用、高效的数据处理工具。(GitHub4)
这对于模型训练、微调和评测非常关键。比如你想训练一个中文文本分类模型,或者微调一个英文问答模型,通常可以先在 Hugging Face 上寻找已有数据集,而不是从零开始收集数据。
Hugging Face 把模型和数据集放在同一个生态中,使 AI 项目的复现和协作变得更容易。
六、Spaces:让 AI Demo 更容易被看见
很多 AI 项目最大的问题不是模型没有价值,而是别人很难直观体验它。
Hugging Face Spaces 解决的就是这个问题。Spaces 是一个 AI 应用展示平台,开发者可以用 Gradio、Streamlit 等工具快速搭建网页 Demo,让用户直接在浏览器中体验模型效果。Hugging Face 的 Spaces 页面将其称为 "AI App Directory",覆盖图像生成、视频生成、文本生成、语言翻译、语音合成、3D 建模、目标检测等任务。
这对研究人员、学生、创业者和开源开发者都很有用。你不需要先买服务器、写复杂前端、配置后端服务,就可以把模型做成一个可交互页面,让别人直接测试。
从传播角度看,Spaces 让模型不再只是论文或代码仓库,而是变成了可以体验的产品原型。
七、从 NLP 到多模态:Hugging Face 的生态扩张
Hugging Face 最早因 NLP 和 Transformers 出名,但现在它已经不局限于文本模型。
在图像生成领域,Hugging Face 推出了 Diffusers。官方文档介绍,Diffusers 可以用于图像生成、模型微调和扩散模型相关应用;其 GitHub 项目也强调,它是用于图像、音频甚至分子 3D 结构生成的预训练扩散模型工具库。
在推理和部署方面,Hugging Face 也提供了 Inference Providers 和 Inference Endpoints。官方文档说明,Inference Providers 让开发者可以通过服务商访问数百个机器学习模型;Inference Endpoints 则面向生产环境,帮助用户把模型部署到专用、可扩展的托管基础设施上。
这意味着 Hugging Face 的定位正在从"开源模型社区"进一步扩展为"AI 工程化平台"。
八、Hugging Face 的发展历史
Hugging Face 成立于 2016 年,由 Clément Delangue、Julien Chaumond 和 Thomas Wolf 在纽约创立。它最早并不是一个模型平台,而是一个面向青少年的聊天机器人应用。后来,团队发现聊天机器人背后的模型和工具链更有价值,于是逐渐转向开源机器学习平台。
2018 到 2019 年前后,Hugging Face 开始因为 Transformers 库受到广泛关注。2019 年发布的 Transformers 论文明确提出,这个开源库的目标是把先进的 Transformer 架构和预训练模型开放给更广泛的机器学习社区,并提供统一 API。
2020 到 2021 年,Hugging Face 的重心从单一工具库扩展为平台。模型仓库、数据集、模型卡片、在线推理、社区协作等能力逐步形成,Hub 开始成为 AI 开发者寻找和发布模型的重要入口。
2022 年,Hugging Face 参与推动 BigScience 项目,并发布 BLOOM。BLOOM 是一个 176B 参数的开放多语言大模型,由数百名研究者协作完成,被视为开放大模型运动中的重要事件。
2023 年,Hugging Face 完成 2.35 亿美元融资,估值达到 45 亿美元,投资方包括 Salesforce、Google、Nvidia 等科技公司。这说明资本市场和大型科技公司已经把 Hugging Face 视为 AI 基础设施领域的重要公司。
2024 年以后,Hugging Face 继续向企业级 AI 落地扩张。Reuters 报道称,Hugging Face 推出了 HUGS,也就是 Hugging Face for Generative AI Services,目标是帮助企业更容易地把开源 AI 模型转换为可运行的应用,并降低构建 AI 系统的成本。
2025 年,Hugging Face 还收购了 Pollen Robotics,进入开源机器人方向。Hugging Face 官方博客表示,这次收购与其"让 AI 和机器人进入每个人手中"的目标一致。
从这个历史可以看出,Hugging Face 的发展路径大致是:
聊天机器人应用 → 开源 NLP 工具库 → Transformers 生态 → 模型和数据平台 → 开放大模型基础设施 → 企业 AI 平台 → 多模态与机器人生态。
九、为什么 Hugging Face 如此重要?
Hugging Face 的重要性,不在于它自己拥有某一个最强模型,而在于它掌握了 AI 时代非常关键的"分发、协作和标准化能力"。
AI 模型的发展速度非常快。每天都有新模型、新数据集、新评测结果、新微调方法出现。如果没有一个统一的平台,开发者很难发现、比较、复现和使用这些成果。
Hugging Face 做了三件非常关键的事情。
第一,它降低了 AI 使用门槛。
普通开发者不需要从零训练模型,也可以基于预训练模型完成应用开发。
第二,它提高了 AI 协作效率。
研究人员、企业和开源社区可以用统一格式发布模型、数据集和 Demo。
第三,它推动了开放 AI 生态。
在 OpenAI、Google、Anthropic 等公司提供封闭模型服务的同时,Hugging Face 为开源模型提供了重要的基础设施,使开发者和企业有机会掌握更多技术自主权。
对企业来说,这一点尤其重要。企业不一定希望所有 AI 能力都依赖第三方黑盒 API。对于金融、医疗、政府、制造业等行业,数据隐私、成本控制、模型可控性和私有化部署都非常关键。Hugging Face 的开源模型生态和部署工具,正好给企业提供了另一条路线。
十、普通开发者应该如何使用 Hugging Face?
如果你是刚接触 AI 的开发者,可以按照下面的路径学习 Hugging Face。
第一步,学会使用 Hub 搜索模型。
比如搜索文本生成、文本向量、图像生成、语音识别、翻译等任务,观察不同模型的下载量、License、Model Card 和示例代码。
第二步,学习 Transformers。
先从 pipeline 入门,完成文本分类、摘要、问答、翻译等简单任务,再进一步学习 AutoTokenizer、AutoModel、模型微调和推理优化。
第三步,学习 Datasets。
理解如何加载数据集、切分训练集和测试集、做数据清洗,以及如何把自己的数据集上传到 Hub。
第四步,尝试 Spaces。
把一个简单模型做成 Gradio 或 Streamlit Demo,让别人可以直接在网页上体验。
第五步,学习部署。
当 Demo 走向真实业务时,再研究 Inference Endpoints、Text Generation Inference、vLLM、Ollama、llama.cpp 等推理和部署方案。
对于软件工程师来说,Hugging Face 最好的学习方式不是只看概念,而是直接动手做一个小项目。比如:
- 用 BGE 或 E5 做一个文本向量检索 Demo;
- 用 Whisper 做一个语音转文字工具;
- 用 Qwen 或 Llama 做一个本地知识库问答系统;
- 用 Stable Diffusion 或 FLUX 做一个图像生成 Demo;
- 用 Spaces 发布一个可以在线体验的 AI 小工具。
十一、Hugging Face 的本质是 AI 时代的基础设施
Hugging Face 最值得关注的地方,不是它有没有某一个最强模型,而是它正在成为 AI 时代的重要基础设施。
它让模型可以被发现,让数据可以被共享,让 Demo 可以被体验,让研究成果可以被复现,让企业可以基于开源模型构建自己的 AI 系统。
在过去,AI 是少数大公司和研究机构才能深入参与的领域。Hugging Face 的出现,把大量工具、模型和数据开放给了普通开发者、创业者、学生和企业团队。
所以,如果你正在学习 AI,Hugging Face 几乎是绕不开的平台。
如果你正在做 AI 应用,Hugging Face 是寻找模型、验证想法和搭建原型的重要工具。
如果你正在为企业规划 AI 架构,Hugging Face 则代表了一条与闭源 API 不同的路线:更开放、更可控,也更接近工程自主。