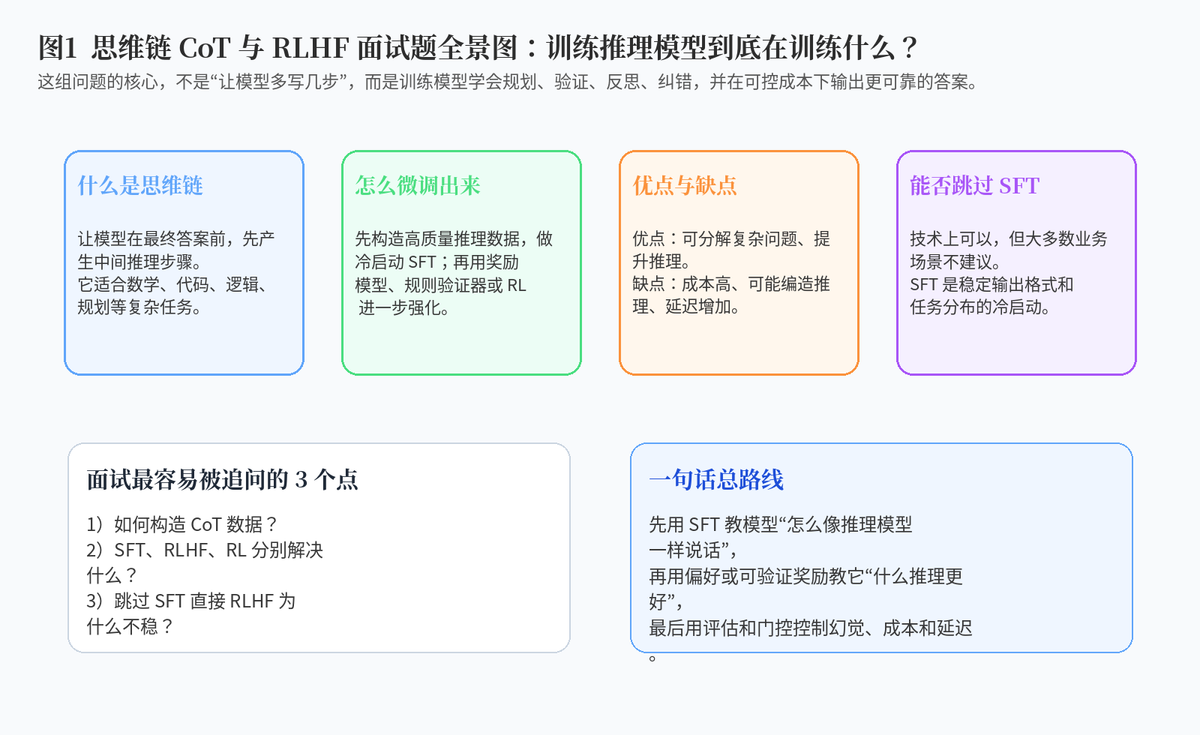
1. 什么是思维链 CoT?为什么它会成为推理模型的核心能力?
1.1 思维链不是"多说废话",而是把复杂问题拆开
思维链,也就是 Chain-of-Thought,通俗理解就是:模型在给出最终答案之前,先把中间推理步骤写出来。对于简单事实问答,思维链未必必要;但对于数学题、代码题、逻辑题、规划题、多约束决策题,它能帮助模型把问题拆成若干个小步骤,再逐步求解。
真正的关键不在于"写得长",而在于"推理过程有结构"。一个好的思维链,通常会包含问题拆解、条件整理、步骤推导、关键检查和最终结论。
1.2 为什么 CoT 能提升复杂任务表现?
从外部表现看,思维链让模型不再急着直接猜答案,而是先把中间过程展开。这样一来,复杂问题被拆成多个简单子问题,模型更容易在每一步保持一致。尤其是需要多步计算、多轮推理和多条件约束时,直接输出答案往往容易出错,而分步骤推理会更稳。
不过要注意:思维链文本并不等于模型内部真实思考的完全还原。它更像一种可观察的推理轨迹,可以帮助模型生成更好的答案,也方便人类或系统检查,但不能把它当成绝对真实的"脑内过程"。
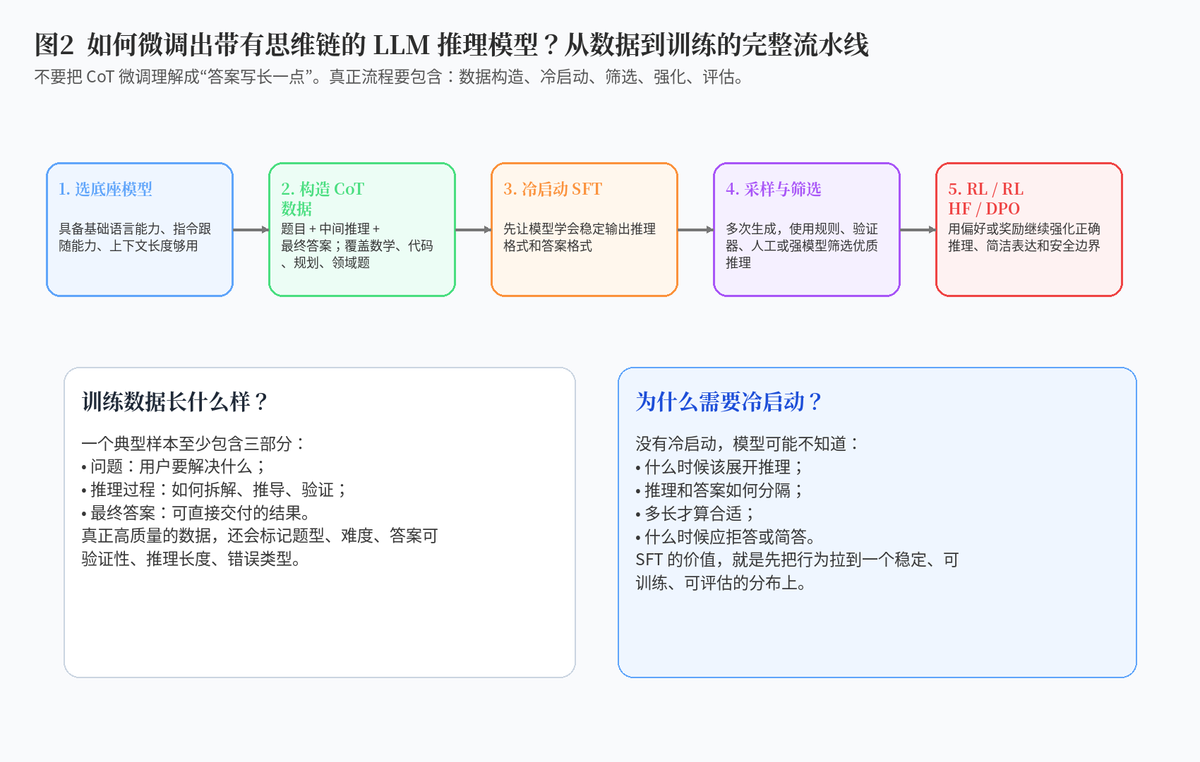
图2 带有思维链的推理模型训练流水线
2. 如何微调出带有思维链的 LLM 推理模型?
2.1 第一步:选择合适的底座模型
底座模型决定了训练的起点。如果底座模型本身语言能力弱、指令跟随差、上下文长度不够,那么后面再怎么做思维链微调,也很难得到稳定效果。更好的底座应该具备基本的知识覆盖、指令理解、长上下文处理和安全边界。
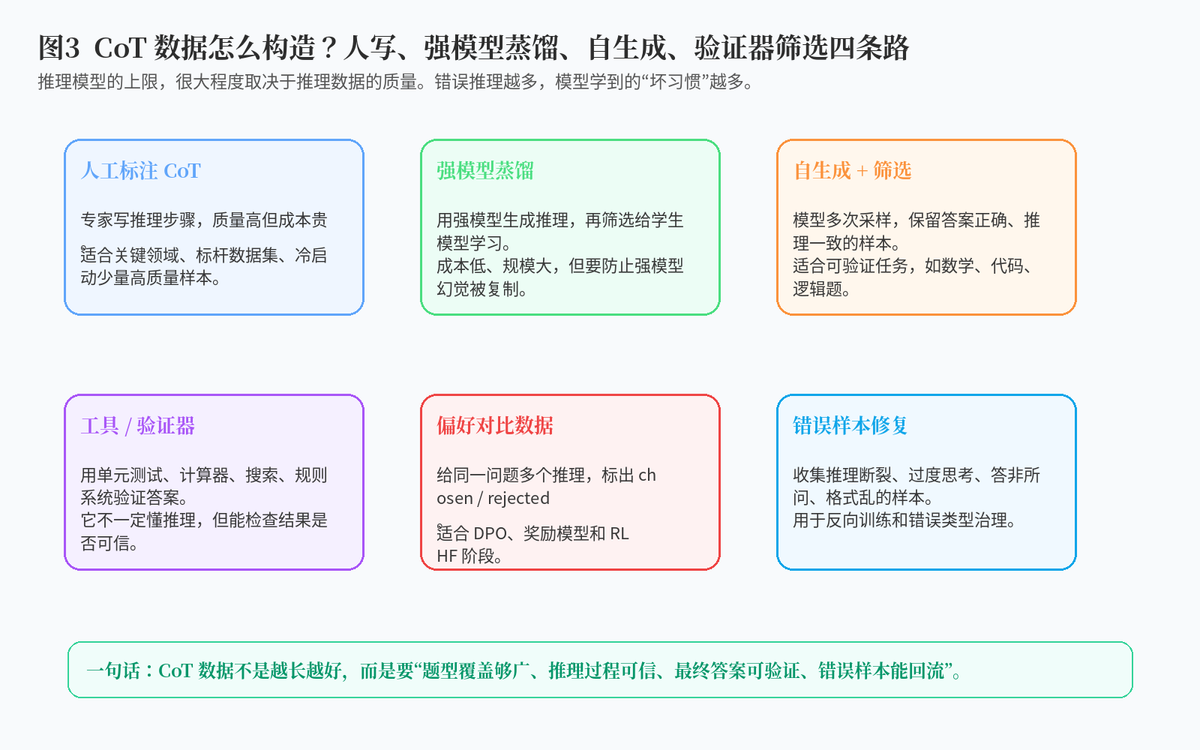
2.2 第二步:构造高质量 CoT 数据
CoT 训练数据不是简单地把答案写长,而是要形成"问题---推理过程---最终答案"的结构。一个高质量样本,通常要满足三点:问题真实,推理正确,最终答案可验证。
数据来源可以有几类:人工专家标注、强模型生成后筛选、模型自生成再用验证器过滤、从真实错误样本中修复。对于数学、代码、逻辑题,可以使用规则验证器、计算器、单元测试等方式检查最终答案;对于开放问答,则要结合人工标注、强模型评审和偏好排序。
2.3 第三步:做冷启动 SFT
SFT 的作用,是先让模型学会"像推理模型一样回答"。也就是说,它要知道什么时候应该展开推理、推理应该如何分段、最终答案应该放在哪里、遇到不确定问题要如何处理。
如果没有冷启动,模型直接进入强化学习阶段,很容易出现格式混乱、语言混杂、输出过长、答非所问等问题。SFT 相当于先把模型拉到一个稳定分布,让后续优化不至于从混乱状态开始。
2.4 第四步:采样、筛选和拒绝采样
SFT 后,可以让模型对同一批问题多次生成不同推理路径,再用验证器、规则、人工或更强模型筛选。正确答案且推理合理的样本,可以继续加入训练;错误样本可以进入错误分析库,用来定位模型容易在哪些题型上断链。
这一步的核心价值,是把"模型可能会的东西"转化成"模型应该学的东西"。
2.5 第五步:RLHF、RL 或 DPO 继续强化
当模型已经能稳定输出推理格式后,就可以通过偏好数据、奖励模型或可验证奖励继续优化。例如:两个回答都能给出答案,但一个推理简洁、步骤正确、结论清晰,另一个冗长、绕路、甚至中间自相矛盾,这时就可以把前者作为 chosen,后者作为 rejected,用偏好优化方法继续训练。
对于答案可以自动验证的任务,比如代码、数学和部分逻辑题,也可以使用结果奖励:答案正确给高分,错误给低分,再配合长度、格式、安全等约束奖励。
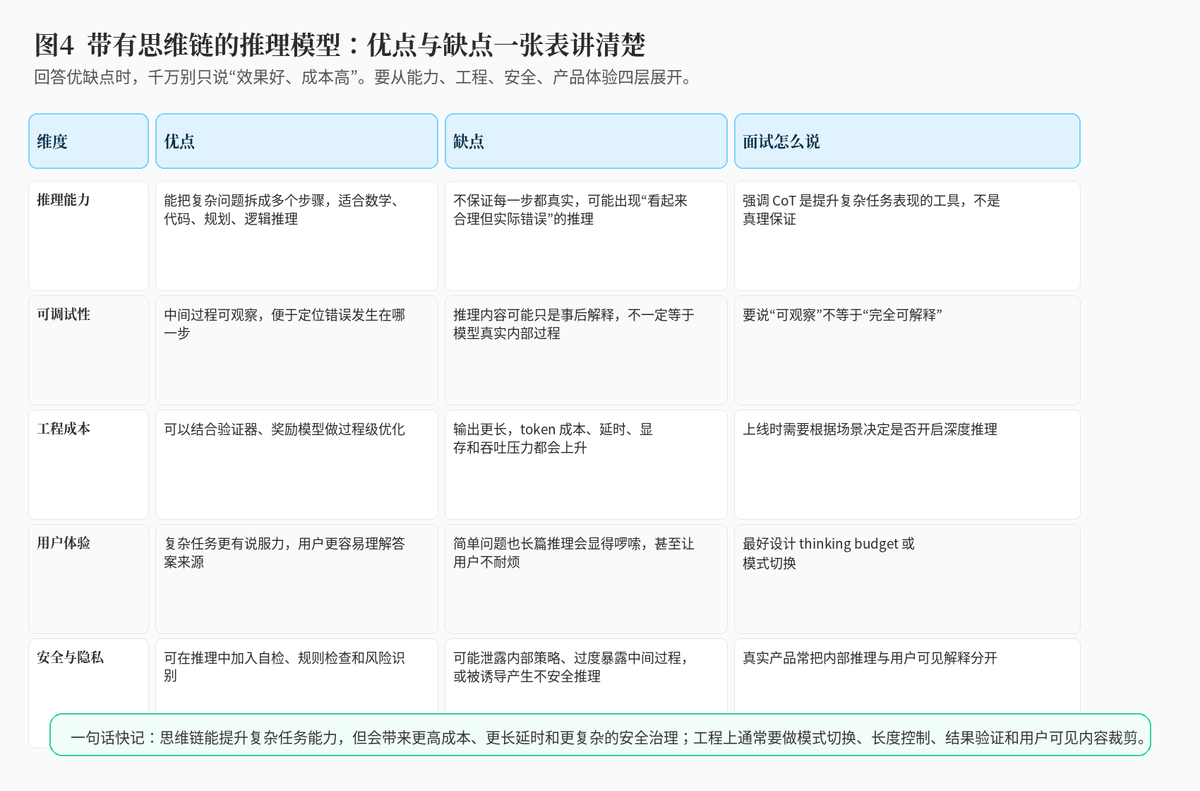
3. 带有思维链的推理模型有什么优点?
3.1 复杂问题更容易拆解
思维链最大的优势,是让模型把复杂任务拆成多个小步骤。面对数学推理、代码调试、复杂规划、多约束分析时,模型如果直接输出最终答案,很容易跳步;而 CoT 能让它先整理条件,再逐步推进。
3.2 更容易做过程检查和错误定位
当模型只给一个最终答案时,系统很难知道它错在哪里。可如果模型输出了中间过程,我们就能发现是理解题意错了、计算错了、假设错了,还是最后归纳错了。
3.3 更适合和验证器、工具、奖励模型结合
思维链把推理过程显式化后,很多工程手段就可以介入,比如让工具检查计算,让代码单元测试检查程序,让规则系统检查格式,让奖励模型判断哪条推理更清晰、更可靠。
4. 带有思维链的推理模型有什么缺点?
4.1 成本和延迟明显增加
最直接的问题是:思维链会让输出变长。输出越长,token 成本越高,用户等待越久,系统吞吐下降越明显。因此,并不是所有问题都值得开启深度思考。对于简单问答,直接短答往往更好。
4.2 推理过程可能不真实,也可能会自圆其说
思维链文本看起来很像人类推理,但它并不保证每一步都真实可靠。有时候模型会先猜到答案,再生成一段看似合理的解释;也可能在中间步骤犯错,但最终答案碰巧正确。
4.3 可能引入安全和隐私风险
在真实产品中,完整内部推理不一定适合直接展示给用户。因为里面可能包含不该暴露的系统策略、安全判断、内部规则,甚至被诱导生成不安全内容。因此,很多系统会把"内部推理"和"用户可见解释"分开。
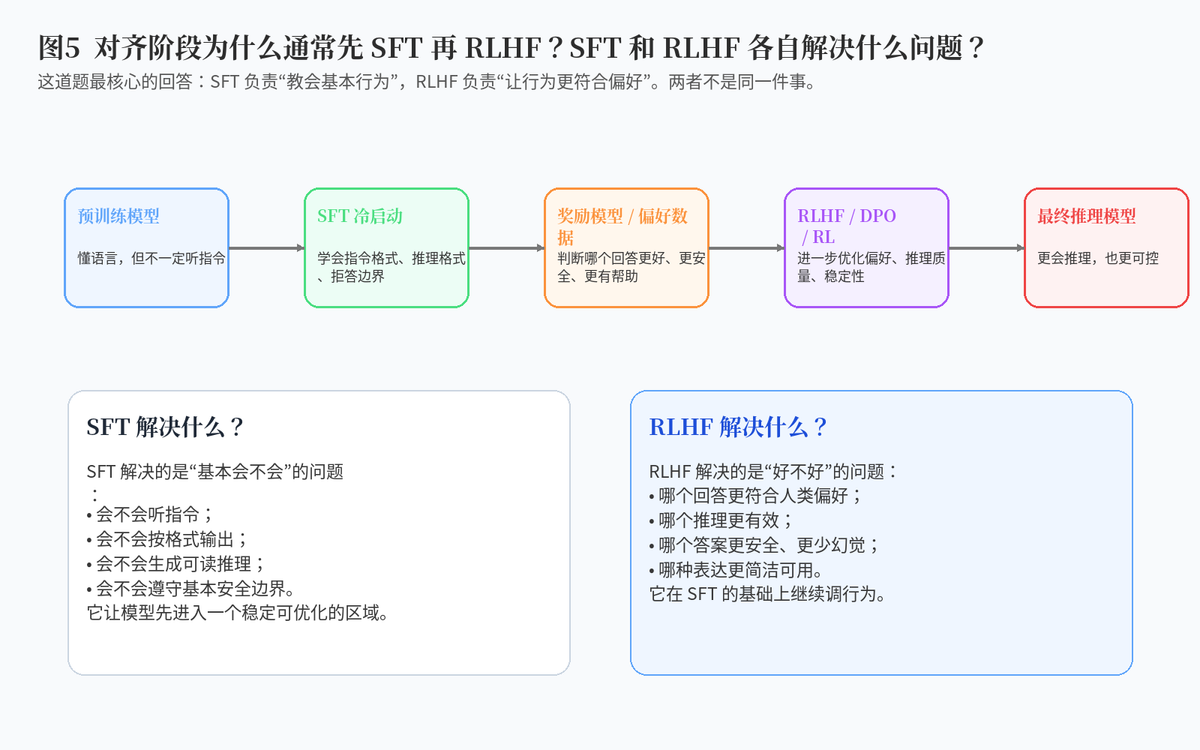
5. 现阶段 LLM 对齐阶段为什么通常分为 SFT 和 RLHF?
5.1 SFT 是"教会模型基本行为"
SFT,也就是监督微调,主要解决模型"会不会按要求回答"的问题。它通过高质量指令---回答样本,让模型学会指令跟随、输出格式、语气风格、安全边界和基本推理习惯。
如果把模型训练比作培养一个学生,SFT 就像先给它看标准答案和标准过程,让它知道什么样的输出是合格的。
5.2 RLHF 是"让模型更符合偏好"
RLHF 则进一步解决"好不好"的问题。它通过人类偏好、奖励模型或其他偏好优化方法,让模型倾向于生成更有帮助、更安全、更真实、更简洁的回答。
对于思维链模型来说,RLHF 不只是让模型更礼貌,还可以让它少绕路、少胡编、少过度思考,并在复杂任务中更愿意检查自己的中间步骤。
6. 可以跳过 SFT 阶段,直接进行 RLHF 吗?
6.1 标准答案:技术上可以探索,但大多数工程场景不建议
这个问题不能简单回答"能"或"不能"。更准确的说法是:如果底座模型非常强,任务答案可验证,奖励信号非常可靠,那么直接 RL 或类似 RLHF 的强化优化是可以探索的;但在大多数业务训练中,不建议跳过 SFT。
原因很简单:RLHF 优化的是偏好和奖励,而不是从零教会模型如何回答。如果模型还没有稳定的指令跟随、输出格式和安全边界,直接 RLHF 就像在一个还没学会走路的人身上训练跑步技巧,过程会非常不稳定。
6.2 为什么跳过 SFT 容易出问题?
第一,输出格式不稳定。模型可能不知道怎么区分推理和答案,也不知道什么时候应该长答,什么时候应该短答。
第二,奖励欺骗风险更高。模型可能学会钻奖励漏洞,而不是真正学会推理。比如它发现某些模板更容易拿高分,就反复套模板。
第三,训练波动更大。RL 需要大量采样和探索,如果初始策略太差,训练过程可能成本高、收敛慢、结果不可控。
第四,可读性和安全性容易变差。没有 SFT 冷启动约束,模型可能出现语言混杂、过度思考、输出冗长等问题。
6.3 那为什么还有人研究直接 RL?
因为对于可验证推理任务,直接 RL 有可能激发模型自我探索能力。尤其是在数学、代码、逻辑题等可以自动判定答案对错的任务中,模型可以通过奖励信号不断尝试不同推理路径。
但这更像研究探索路线,不代表所有业务都该这么做。真实落地通常会采用更稳的方案:先用少量高质量 CoT 数据做冷启动 SFT,再用 RL、RLHF 或偏好优化进一步增强。

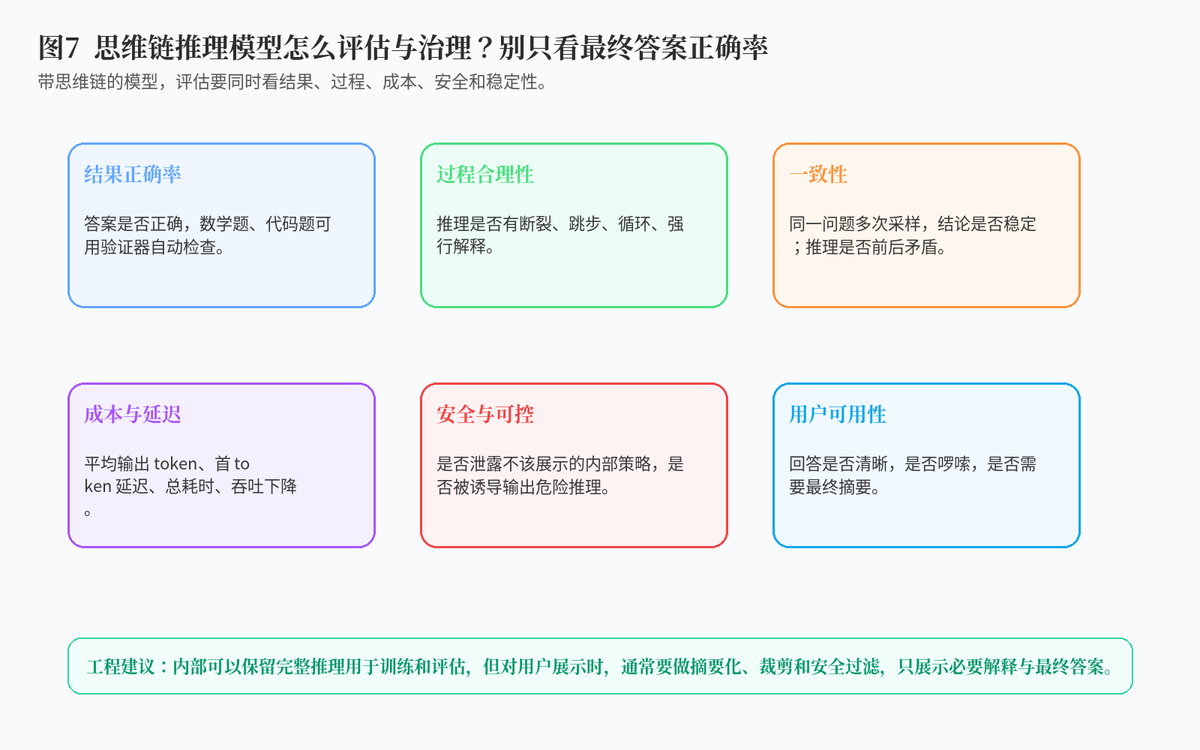
7. 思维链模型怎么评估和上线?
7.1 不只看最终答案正确率
普通模型评估可能只看最终答案对不对,但推理模型还要看过程。一个回答最终答案正确,但中间过程胡说八道,也不一定是好样本;一个回答过程清晰但最后算错,也说明模型还需要在验证阶段增强。
因此,推理模型评估一般要看结果正确率、过程合理性、一致性、输出长度、延迟、成本、安全性和用户可用性。
7.2 上线时要做模式切换
不是所有问题都需要深度推理。工程上可以设计两种模式:简单问题直接短答,复杂问题开启思维链或深度推理。也可以设置 thinking budget,让模型根据问题复杂度决定推理长度。
7.3 内部推理和用户解释最好分开
真实产品中,模型内部生成的长推理不一定全部展示给用户。更常见的做法是:内部保留完整推理用于训练、验证和调试;用户侧只展示简洁解释、关键依据和最终答案。
8. 面试高频追问,建议这样回答
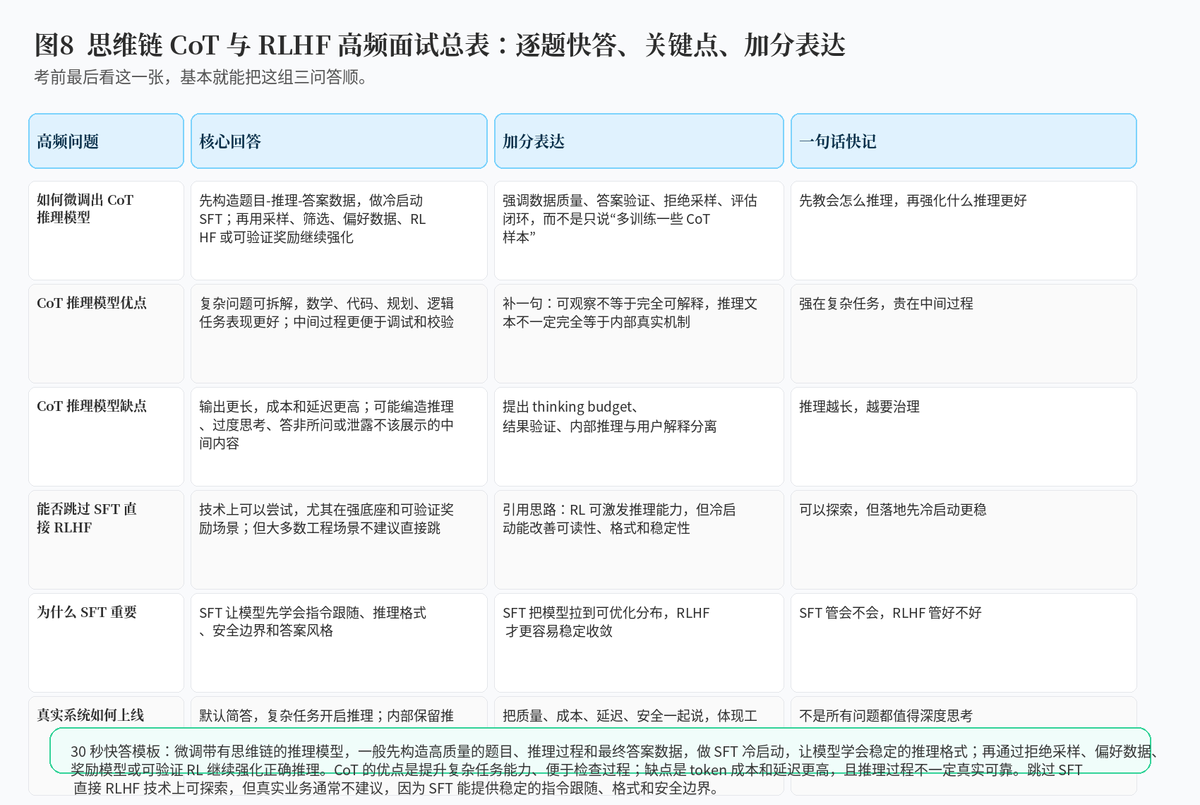
8.1 如何微调出带有思维链的 LLM 推理模型?
答:一般先构造高质量的"问题---推理过程---最终答案"数据,做 SFT 冷启动,让模型学会稳定的推理格式;然后通过多次采样、拒绝采样、验证器筛选、偏好数据、奖励模型或 RLHF / DPO 继续优化,让模型学会更正确、更简洁、更可靠的推理。
8.2 带有思维链的推理模型有什么优缺点?
答:优点是能提升复杂任务的推理能力,把问题拆成多步,便于过程检查和工具验证;缺点是输出更长,token 成本和延迟更高,且推理过程可能并不完全真实,也可能带来安全和隐私风险。
8.3 可以跳过 SFT 直接进行 RLHF 吗?
答:技术上可以探索,尤其是强底座模型和可验证奖励场景;但大多数工程场景不建议直接跳过 SFT。因为 SFT 能让模型先具备稳定的指令跟随、输出格式和安全边界,RLHF 才更容易稳定优化。如果直接 RLHF,可能出现格式混乱、奖励欺骗、训练不稳定和可读性差等问题。
9. 总结:思维链训练不是把答案写长,而是训练模型"更会解决复杂问题"
如果把整篇文章浓缩成一句话,那就是:带有思维链的推理模型,不是靠简单让模型多写几句就能得到的,而是需要高质量推理数据、冷启动 SFT、采样筛选、奖励或偏好优化、评估治理共同配合。
SFT 的价值,是把模型拉到一个稳定、可控、可优化的输出分布;RLHF 或 RL 的价值,是在此基础上进一步提升推理质量、偏好对齐和安全性。跳过 SFT 并非绝对不可能,但大多数真实业务场景中,先 SFT 再 RLHF 仍然是更稳妥、更可控的路线。
真正高质量的面试回答,不是背"CoT、SFT、RLHF"这些名词,而是能讲清它们各自在训练链路中解决什么问题、彼此如何衔接、工程上有哪些取舍。
附:30 秒快答模板
"微调带思维链的推理模型,通常先构造高质量的题目、推理过程和最终答案数据,做 SFT 冷启动,让模型学会稳定的推理格式;之后通过拒绝采样、验证器、偏好数据、奖励模型或 RLHF / DPO 进一步优化推理质量。CoT 的优点是提升复杂任务能力、便于过程检查;缺点是 token 成本和延迟更高,推理过程也不一定完全真实。至于能不能跳过 SFT 直接 RLHF,技术上可探索,但工程上通常不建议,因为 SFT 能提供稳定的指令跟随、输出格式和安全边界,让后续 RLHF 更容易稳定收敛。"