e2b-local 是一个跑在本机的 E2B 兼容网关。应用侧还是接 E2B SDK,只需要把 API 地址指到本地;Sandbox.create()、commands.run()、filesystem、PTY 这些调用方式都不变。变化发生在后面:原本会创建到云端的 sandbox,现在会落到本机 Docker 容器,或者 OrbStack 的 Linux VM 里。
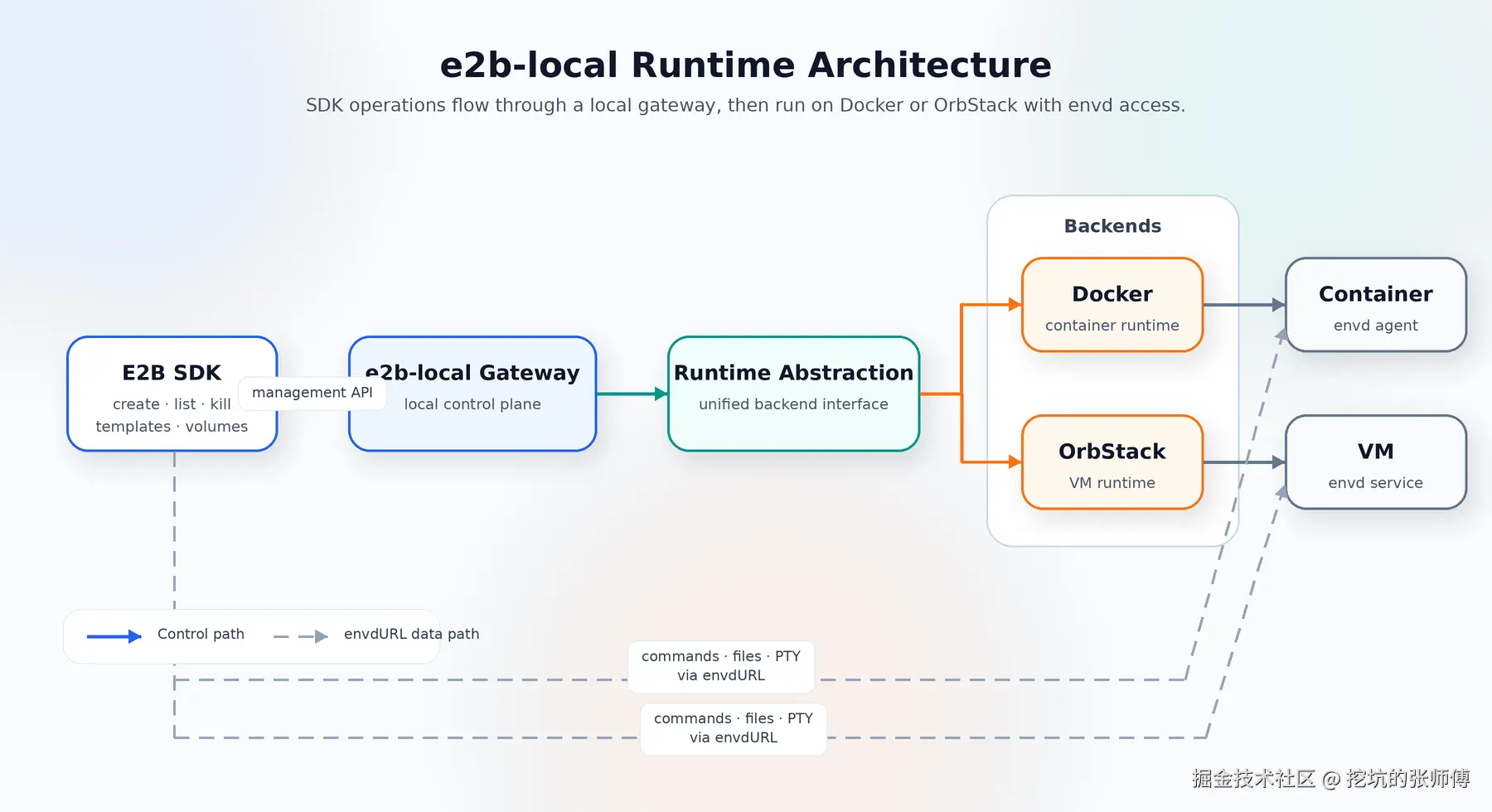
它更像是把 E2B 控制面接到本地 runtime 的一层适配器。上面尽量保持 SDK 的调用方式,下面负责把 template、volume、envd 和 sandbox 生命周期翻译成 Docker / OrbStack 的操作:Docker 模式把本机 image 当 template;OrbStack 模式把已有 machine 当 template,再 clone 出一个新的 sandbox VM。
我做它的起点不是想复刻 E2B,也不是觉得云端 sandbox 不好用。真正卡住我的,是开发 template 时那条很长的反馈链路。
一个 template 还没稳定的时候,经常只是改了一行系统依赖、换了一个启动命令、调了一下 ready check,或者临时加一个 debug 工具。按正常云端流程,每一次改动都要重新 build、上传、发布,再创建 sandbox 验证。单次看起来还好,但连续调几轮以后,人的注意力会被等待切碎。
另一个更现实的问题是本地网络。很多时候 sandbox 里要访问的服务还在我的开发机上:本地 API server、mock server、临时数据库、还没部署的内部服务。远端 sandbox 当然可以通过各种办法绕回来,但这件事本身就已经偏离了"我只是想验证一下 template 能不能跑"的初衷。
所以这个项目想解决的是开发阶段的那一截路:SDK 仍然用 E2B 的方式调用,但真正的 sandbox 跑在本机 Docker 容器或 OrbStack Linux VM 里。它不是云端 E2B 的替代品,更像是把 template 调试这件事拉回开发机,让修改、启动、观察日志、再修改形成一个短很多的闭环。
先把边界想清楚
刚开始想做本地版 sandbox 时,很容易把问题想成"本地启动一个容器,然后把 SDK 接过去"。但真正看一遍 E2B 的调用链,会发现这里面其实有两条很不一样的路径。
一条是控制面:创建 sandbox、删除 sandbox、列 template、管理 volume、看 logs 和 metrics。这些请求适合由一个本地 gateway 接住,然后翻译成本地 runtime 操作。
另一条是数据面:执行命令、读写文件、开 PTY、处理 streaming。这些能力真正落在 sandbox 内部的 envd 上。也就是说,gateway 不应该假装自己能处理所有事情;它更像调度器,负责把一个 sandbox 创建出来,然后把这个 sandbox 自己的 envdURL 返回给 SDK。后续 command、filesystem、PTY 调用,SDK 直接访问 envd。
这个拆分是整个项目里最重要的判断之一。它决定了 e2b-local 不需要重写 envd 协议,也不需要把所有数据流量都绕回 gateway。
HTTP 层使用 Gin,E2B API 的 request/response DTO 从 OpenAPI schema 通过 oapi-codegen 生成到 internal/e2bapi。这里我不太想手写一套"看起来差不多"的结构体,因为 SDK 兼容是这个项目最核心的边界。字段名、枚举、返回结构只要偏一点,最后都会变成调用方很难理解的小问题。
SDK 侧的配置保持很轻:
bash
export E2B_API_URL="http://127.0.0.1:3000"
export E2B_API_KEY="local"
unset E2B_SANDBOX_URLE2B_API_KEY 在这里主要是为了满足 SDK 的调用习惯,本地 gateway 不依赖真实的云端 key。
Docker 是最短的第一步
如果只看 template 调试,Docker 是最自然的起点。E2B 的自定义 template 本来就和 Docker image 有很深的关系;云上最终跑的是 Firecracker microVM,但用户构建 template 时,入口通常还是 Dockerfile 和 linux/amd64 镜像。
所以 Docker backend 的思路很直接:把本机已有的 Docker images 当成 templates。开发者在本机 build/tag 一个 image,e2b-local 从这个 image 创建 sandbox。验证通过以后,同一套 Dockerfile 或 image 构建逻辑再接到云上的 E2B template 流程里。
例如本地先构建一个 amd64 image:
bash
docker buildx build \
--platform linux/amd64 \
-t e2b-local/code-interpreter:latest \
--load .然后 SDK 里创建 code-interpreter,本地 gateway 会把它解析到对应的 Docker image。
这里我刻意没有调用 docker run、docker ps 这些命令,而是直接走 Docker Engine API。原因和后面 OrbStack 的选择是一脉相承的:gateway 是一个常驻服务,它更适合持有结构化 client,而不是不断 fork CLI 进程再解析 stdout/stderr。
Docker host 的解析顺序也尽量贴近开发环境:先尊重用户显式设置的 DOCKER_HOST;如果当前用户有 OrbStack 的 Docker socket,就使用 ~/.orbstack/run/docker.sock;否则回到常见的 unix:///var/run/docker.sock。后面的 image inspect、container create/start/stop/remove、logs、stats、volume 操作都走同一个 Docker SDK client。
template 映射也尽量不引入额外 registry。本机有 tag 的 image 就是候选 template,dangling image 会被忽略,带 e2b.local.snapshot=true 的 snapshot image 也不会混进列表。默认 template ID 来自 image reference 的最后一段:
text
e2b-local/code-interpreter:latest -> code-interpreter
python:3.11 -> python
ghcr.io/acme/my-template:v1 -> my-template如果 image 是通过 e2b-local 的 template build API 构建出来的,gateway 会写入 e2b.local.template_id、template names、build ID、start command、ready command 等 labels。之后再列 templates 时,这些 labels 会覆盖默认推导。这样简单 image 可以零配置使用,复杂 template 又能保留更明确的 metadata。
Docker 容器启动时还有一个关键点:e2b-local 不修改用户镜像,也不重新 build 一层 image。它会根据 image 架构选择仓库里的 envd 二进制:
text
linux/amd64 -> envd-bin/envd-linux-amd64
linux/arm64 -> envd-bin/envd-linux-arm64然后在创建容器时把它只读挂载进去:
text
host: envd-bin/envd-linux-amd64
container: /usr/local/bin/envd
readonly: true容器 entrypoint 被覆盖成 /usr/local/bin/envd。envd 默认在容器内监听 49983/tcp,宿主机端口由 Docker 自动分配,并且只绑定到 127.0.0.1。gateway 在容器启动后 inspect 端口映射,拿到类似 http://127.0.0.1:随机端口 的地址,把它作为 envdURL 返回给 SDK。
如果 template label 里记录了 start command,gateway 会把它作为 envd 的 -cmd 参数传进去;如果有 ready command,就等 envd health check 通过后再执行 ready command。失败时,刚创建的容器会被清理掉,错误里会尽量带上容器日志。这个细节很重要,因为本地开发最怕的是"创建失败了,但不知道里面发生了什么"。
OrbStack 是另一种形态的本地 sandbox
Docker 很适合轻量环境,但不是所有 template 都天然适合容器。有些东西更像一台完整 Linux 机器:需要 systemd,需要更接近真实主机的进程模型,需要在一个长期存在的 base machine 上慢慢调整系统状态。
这就是 OrbStack backend 出现的原因。
在 macOS 上,OrbStack 的 VM 启动很快,文件系统体验也好,同时它本身就提供 Docker 兼容能力和 Linux machine 能力。对 e2b-local 来说,已有的 OrbStack machine 可以很自然地被看成 template:创建 sandbox 时 clone 这台 template machine,启动 clone 出来的 sandbox VM,把 envd 放进去,安装 systemd service,然后等待 envd 起来。
最开始我确实先想过直接调用 orb 命令。这个方案能很快跑通原型,而且命令也很直观:
text
orb clone <template-vm> <sandbox-vm>
orb start <sandbox-vm>
orb stop <sandbox-vm>
orb delete --force <sandbox-vm>
orb info --format json <vm>
orb list --format json
orb config set machine.<vm>.isolated true
orb config add machine.<vm>.mounts <host-path>:<vm-path>但往下做一点,就会发现这不是我想长期留下来的接口。
CLI 当然适合人用,却不一定适合一个 gateway 当作内部控制协议。每次生命周期操作都 fork 一个 orb 进程,启动成本是一方面,更麻烦的是超时、取消、stderr 解析和错误分类。即使 orb info --format json 能给出结构化结果,错误路径也经常还是人类可读的文本。最后这些文本再被包装成 SDK 错误,对调用方其实不够友好。
还有一个更深的原因:OrbStack VM 初始化不只是 clone/start。e2b-local 还要把 envd 写进 VM 的 /usr/local/bin,写 systemd unit,写 sandbox metadata,创建 volume symlink,再执行 systemctl daemon-reload && systemctl restart envd。如果全靠 orb run 或 orb push,实现会被绑在一层更大的 CLI 语义上,而不是清楚地分成"控制 VM 生命周期"和"进入 VM 做文件/systemd 操作"。
到这里,思路就变了:不要把 orb 当成唯一接口,而是看看它自己到底怎么和 OrbStack daemon 通信。CLI 最终也要和本机 daemon 说话,如果我们能直接接入背后的 Unix domain socket,就可以少绕一层。
我是怎么确认 OrbStack UDS 协议的
这一步不是拍脑袋猜协议,而是两边交叉验证:一边逆向 Go 客户端,一边抓真实 socket 流量。
OrbStack 的 orb/orbctl 在 macOS 上本质是 Go 程序。对 Go 二进制,go version -m 和 strings 很有用。它们能暴露 module path、依赖库,以及一些没被完全抹掉的方法名。分析下来可以看到一些非常关键的线索:
text
github.com/creachadair/jrpc2
ContainerStart
ContainerStop
ContainerDelete
ContainerClone
ContainerSetConfig
ListContainers
MachineConfig
MachineMount
sconrpc.sock
sconssh.sock这些名字基本把方向指清楚了:控制面大概率是 JSON-RPC,VM 生命周期对应的是一组 Container* RPC method;另有一条 sconssh.sock 用来进入 machine。
拿 ListContainers 举个例子,会更容易理解这里所谓"直接和 OrbStack daemon 通信"到底是什么意思。它不是一个新的 HTTP 服务,也不是监听在 TCP 端口上的 API,而是跑在 Unix domain socket 上的一次 JSON-RPC 调用。用 curl 就能直接试:
bash
curl --unix-socket "$HOME/.orbstack/run/sconrpc.sock" \
-H 'Content-Type: application/json' \
-X POST http://sconrpc \
--data '{"jsonrpc":"2.0","id":1,"method":"ListContainers"}'这里的 http://sconrpc 不是一个真实的网络地址。curl --unix-socket 仍然需要一个 URL 来组 HTTP request,host 部分只是占位,真正的连接走的是 $HOME/.orbstack/run/sconrpc.sock。
返回结果大概是这样的,实际机器上的 id、IP 和磁盘大小会不同:
json
{
"jsonrpc": "2.0",
"id": 1,
"result": [
{
"record": {
"id": "01GQQVF6C60000000000DOCKER",
"name": "docker",
"image": {
"distro": "docker",
"version": "latest",
"arch": "arm64",
"variant": "default"
},
"config": {
"isolated": false,
"forward_ssh_agent": true,
"isolate_network": false,
"default_username": "root",
"http_port": 0,
"https_port": 0
},
"builtin": true,
"state": "running"
},
"disk_size": 2634473472,
"ip4": "192.168.139.2",
"ip6": "fd07:b51a:cc66::2"
},
{
"record": {
"id": "01KTK0Z32XA8Y4R8MVY2F4TZKN",
"name": "ubuntu-2404",
"image": {
"distro": "ubuntu",
"version": "noble",
"arch": "arm64",
"variant": "cloud"
},
"config": {
"isolated": false,
"forward_ssh_agent": true,
"isolate_network": false,
"default_username": "arthur",
"http_port": 0,
"https_port": 0
},
"builtin": false,
"state": "running"
},
"disk_size": 1155293184,
"ip4": "192.168.139.198",
"ip6": "fd07:b51a:cc66:0:18cb:1bff:fe4a:2ea0"
}
]
}这个响应一眼就能看出它比 orb list 的人类输出更适合程序使用。record.name 是 machine 名称,record.image 能告诉我们它来自哪个发行版和架构,record.state 能判断 running/stopped,record.config.isolated 正好对应后面要设置的隔离配置。builtin: true 的 docker machine 也能被识别出来,避免把 OrbStack 内置环境误当成用户 template。
对 e2b-local 来说,这个 method 基本就覆盖了 "list/info" 这类入口能力:列出当前机器,过滤出可用 template,判断 sandbox VM 是否已经存在,读取它当前的状态和网络地址。后面的 clone/start/stop/delete/config 也只是沿着同一条 JSON-RPC 通道继续调用不同 method。也正是从这个例子开始,orb list --format json 就没有必要再留在 gateway 里了。
光看字符串还不够,因为你仍然不知道真实 payload 长什么样、socket 路径有没有版本差异、CLI 到底在什么场景调用哪些 method。所以我又用 socat 做了一次 Unix socket 中间人。方法是把真正的 socket 文件临时改名,然后在原路径上放一个新的监听 socket;这个监听 socket 一边转发到真实 socket,一边把双向流量 dump 出来。
先找 socket。现在常见路径在 ~/.orbstack/run 下:
bash
ls -la ~/.orbstack/run
ls -la ~/.orbstack/run/vmcontrol.sock
ls -la ~/.orbstack/run/sconrpc.sock如果版本不同,也可以扩大搜索:
bash
find ~/.orbstack /Applications/OrbStack.app \
\( -name "vmcontrol.sock" -o -name "sconrpc.sock" \) 2>/dev/null安装 socat:
bash
brew install socat然后以 vmcontrol.sock 为例做中间人:
bash
SOCK="$HOME/.orbstack/run/vmcontrol.sock"
mv "$SOCK" "$SOCK.real"
socat -v \
"UNIX-LISTEN:$SOCK,fork" \
"UNIX-CONNECT:$SOCK.real" \
2>&1 | tee /tmp/vmcontrol-dump.log接着运行几次 orb list、orb info,或者在 OrbStack UI 里操作 machine。对于 JSON-RPC 这类明文协议,dump 里通常能直接看到 method、params 和 id。抓完以后记得恢复:
bash
rm -f "$SOCK"
mv "$SOCK.real" "$SOCK"有些旧版本或特殊安装路径可能会把 socket 放在 app bundle 里,这时同样的办法也能用,只是需要 sudo:
bash
sudo mv /Applications/OrbStack.app/Contents/MacOS/vmcontrol.sock \
/Applications/OrbStack.app/Contents/MacOS/vmcontrol.sock.real
sudo socat -v \
UNIX-LISTEN:/Applications/OrbStack.app/Contents/MacOS/vmcontrol.sock,fork \
UNIX-CONNECT:/Applications/OrbStack.app/Contents/MacOS/vmcontrol.sock.real \
2>&1 | tee /tmp/vmcontrol-dump.log这个过程的目的不是"占有"OrbStack 的所有内部协议,而是确认当前项目真正需要的边界:list/info/clone/start/stop/delete/config 走 sconrpc.sock 上的 JSON-RPC;进入 VM 写文件、装 systemd service 走 sconssh.sock 上的 SSH。至于 orb run --machine <vm> /bin/sh -lc <script>,最后发现并不是必需能力,因为 VM 内操作可以直接通过 SSH 完成。
于是代码里落下来的形态很薄:internal/orbctl 负责通过 Unix socket 发 JSON-RPC HTTP request,封装 ListContainers、ContainerClone、ContainerStart、ContainerStop、ContainerDelete、ContainerSetConfig;OrbStack backend 需要写 root 文件或执行 systemd 命令时,用 Go SSH client 连 ~/.orbstack/run/sconssh.sock,不再 fork 系统 ssh,也不再 fork orb。
这样以后,Docker 和 OrbStack 两个 backend 在风格上终于统一了:Docker 不 shell out 到 docker,OrbStack 也不 shell out 到 orb。gateway 直接和本地 daemon/socket 通信,拿结构化结果,自己控制超时和错误。
volume metadata 这个小问题
OrbStack volume 的实现里还有一个很小但挺典型的取舍:本地目录应该怎么命名,metadata 又应该放在哪里。
Docker backend 可以直接用 Docker native named volume。但 OrbStack VM 的 volume 更适合映射成本机目录,默认放在:
text
~/.e2b-local/volumes创建 sandbox 时,backend 通过 OrbStack selective mount 把对应目录挂进 VM,再在 VM 里 symlink 到 SDK 请求的路径。如果开启 orbstack.isolated: true,sandbox VM 不会看到完整 macOS 文件系统,只能看到显式挂载的 volume。
一开始最简单的目录名是 volume ID,比如:
text
~/.e2b-local/volumes/vol_01HX...这样查找很方便,但人打开目录时完全不知道每个 volume 是干什么的。换成用户给的 volume name 又舒服很多:
text
~/.e2b-local/volumes/data
~/.e2b-local/volumes/cache问题是 name 不是稳定主键,可能重名,也可能以后想改显示名。E2B API 里真正稳定的是 volume ID。
最后的设计是把这两个概念拆开:目录名尽量保持可读,比如 data、cache、data-2;稳定身份写进目录自己的 extended attribute。现在使用的 xattr key 是:
text
com.e2b.local.volume-meta内容是一个很小的 JSON:
json
{"VolumeID":"vol-123","Name":"data"}我选择 xattr,而不是在 volume 目录里放 .e2b-meta.json,主要是因为这个目录会被挂进 VM,里面应该尽量只出现用户数据。额外的元数据文件很容易被用户看到、误改或者删除;xattr 更像这个目录在宿主机侧的外部属性,不会混进 sandbox 的业务文件列表。
迁移上也留了口子。早期版本可能已经有旧 xattr key com.e2b.volume-meta,或者旧的 .e2b-meta.json。读取 metadata 时,代码会按新 xattr、旧 xattr、旧文件的顺序尝试;如果读到旧格式,就写回新的 com.e2b.local.volume-meta,并清理旧 key 或旧文件。旧 payload 里的历史 Token 字段也会被丢掉,当前 metadata 只保留 VolumeID 和 Name。
这不是 OrbStack 本身要求的格式,而是 e2b-local 在 macOS + OrbStack 场景下管理本地 volume 的方式:API 身份稳定,文件夹名字对人可读,控制面 metadata 不混进 sandbox 数据面。
envd 不能依赖我的机器
还有一个发布前必须处理的问题是 envd 二进制的位置。
早期调试时,很容易把 envd 路径写成自己机器上的绝对路径。这种写法能让原型先跑起来,但项目一旦给别人用就会立刻坏掉,因为那条路径只存在于我的电脑上。
现在仓库里直接带了 Linux 版 envd:
text
envd-bin/envd-linux-amd64
envd-bin/envd-linux-arm64这些 envd 不是 e2b-local 重新实现的协议服务,而是从 E2B 源码构建出来的二进制。这样 SDK 数据面的 commands、filesystem、PTY、streaming 行为可以尽量贴近真实 E2B sandbox。
Docker backend 会把对应架构的 envd bind-mount 到容器内 /usr/local/bin/envd;OrbStack backend 会把 envd 复制进 VM,再安装成 systemd service。配置里仍然可以写相对路径,但解析会按配置文件所在目录来做,避免把某台开发机上的私有路径带进项目。
SDK 调用方最好感觉不到这些选择
做完这些底层工作以后,SDK 调用方看到的东西应该尽量简单。
TypeScript 里仍然可以这样写:
ts
import { Sandbox } from 'e2b'
const sandbox = await Sandbox.create('code-interpreter')
const result = await sandbox.commands.run('echo "hello from e2b-local"')
console.log(result.stdout)
await sandbox.kill()Go 里也可以通过 superduck-ai/e2b-go-sdk 调:
go
sandbox, err := e2b.Create(ctx, "code-interpreter", nil)
if err != nil {
panic(err)
}
defer sandbox.Kill(ctx, nil)
result, err := sandbox.Commands.Run(ctx, `echo "hello from e2b-local"`, nil)
if err != nil {
panic(err)
}
fmt.Println(result.(*e2b.CommandResult).Stdout)调用方真正需要知道的差异很少:Docker runtime 的 template 来自本机 Docker image;OrbStack runtime 的 template 来自已有 OrbStack machine;Docker volume 是 native named volume;OrbStack volume 是 orbstack.volume_host_path 下的本地目录。除此之外,SDK 仍然按 E2B 的方式创建 sandbox、执行命令、读写文件和销毁环境。
现在它适合放在哪个位置
它适合本地开发和 template 调试,尤其适合这些场景:快速验证 Docker image 能不能作为 E2B template 工作;调启动命令、环境变量、ready check 和系统依赖;让 sandbox 访问本机开发服务;在 macOS 上用 OrbStack VM 模拟更完整的 Linux 主机环境。
它不打算替代云端 E2B 的多租户生产隔离,也不想把本地机器包装成一个生产 sandbox 平台。它更像开发阶段的一层适配器:把反馈链路缩短,把问题提前暴露,把 SDK 调用方式保持住。
回头看,最关键的几个决定其实都来自同一个出发点:gateway 应该直接接本地 runtime 的结构化接口,而不是把 CLI 当成长期依赖。Docker 走 Engine API,OrbStack 走 UDS 上的 JSON-RPC 和 SSH,envd 继续负责数据面。这样实现更轻,错误更可控,也更接近一个本地常驻服务应该有的形态。
这也是为什么我最后没有继续沿用 orb 命令,而是花时间去分析 OrbStack 的 socket 通信。不是为了炫技,也不是为了追求"更底层",只是因为对 e2b-local 这种 gateway 来说,少 fork 一层进程、少解析一层人类输出,很多后续问题都会简单不少。
我还没实现的部分
现在这套实现优先覆盖的是本地开发最常用的链路:创建 sandbox、启动 envd、跑 commands/filesystem/PTY、管理 template 和 volume,以及用 Docker 或 OrbStack 快速验证环境。换句话说,我先把"能不能把一个 template 在本地快速跑起来"这件事做顺,而不是一开始就把 E2B 云端的所有 API 语义都补齐。
还没完整实现的部分,最典型的是 snapshot 这一类能力。云端 E2B 里的 snapshot 不只是"把当前环境存一下"这么简单,它还会牵涉到 template 生命周期、命名空间、权限、长期存储、从 snapshot 再创建 sandbox、以及和构建系统之间的关系。e2b-local 目前更关注本地调试闭环,所以即使有些 runtime 可以做非常薄的一层本地快照映射,我也不想把它包装成已经完整兼容云端 snapshot 语义。
类似的还有一些偏平台侧的能力:更完整的 metrics/logs 语义、network policy、access token / API key 管理、团队和权限模型、配额、审计、跨机器调度、长期资源治理等。这些能力在云端平台里很重要,但对本地 template 开发来说不是第一优先级。e2b-local 现在更适合作为开发工具,而不是生产控制面。
小结
e2b-local 做的事情并不复杂:让 E2B SDK 的使用方式尽量不变,把 template 开发时最慢的那段反馈链路搬回本机。Docker 负责轻量、直接的 image 调试;OrbStack VM 负责更接近完整 Linux 主机的场景;而绕开 docker / orb 这类 CLI,直接接本地 runtime 的结构化接口,是让这个 gateway 更轻、更稳定的关键。
欢迎 star:github.com/superduck-a...