背景
Monknow 是一款新标签页插件,支持网站分组管理和数据云同步。使用一段时间后,我在其收藏夹中积累了相当数量的书签。最近出于备份考虑,我希望将这些数据导出为通用格式,以便本地存档或在需要时迁移到其他新标签页插件。
Monknow 本身没有提供导出功能。我曾尝试联系作者询问是否有可能在后续版本中加入此特性,但未收到回复。这促使我自行寻找技术方案。
之前的尝试
早期我写过一篇博客(Monknow新标签页数据导出),通过浏览器控制台执行 JavaScript 来提取数据。但是还是繁琐了一点。
因此这次主要改用 Python 实现,直接从浏览器本地存储读取数据,一键运行。同时保留了js的脚本。
源码已上传Github。
工具说明
Github:MonknowExporter https://github.com/i-bugmaker/MonknowExporter
包含两个脚本:
| 文件 | 说明 |
|---|---|
export-monknow.py |
Python 脚本,自动扫描浏览器数据目录,读取并导出书签 |
export-monknow.js |
浏览器控制台脚本,Python 不可用时的备选方案 |
Python 脚本无需安装第三方库,Python 3.6+ 即可运行。输出为标准 HTML 书签文件(Netscape Bookmark Format),可直接导入 Edge、Chrome、Firefox。
使用方法
bash
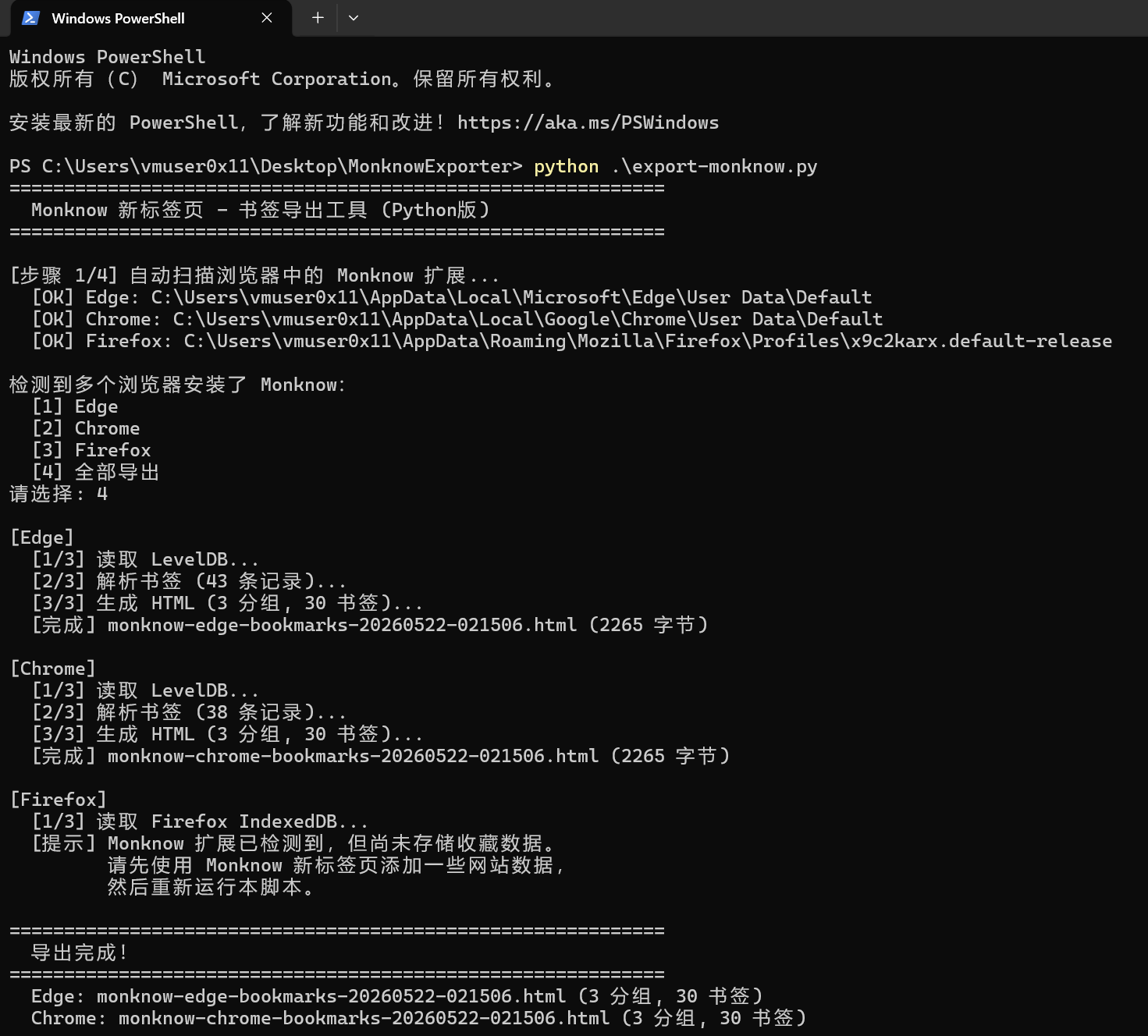
python export-monknow.py脚本会自动检测 Edge、Chrome、Firefox 的 Monknow 数据存储位置,解析书签并生成 HTML 文件。如果多个浏览器都检测到 Monknow,会提示选择导出哪一个或全部导出。
输出文件格式为 monknow-{browser}-bookmarks-{timestamp}.html,保留原来的分组目录结构。
当无法运行 Python 时,可使用 export-monknow.js,在 Monknow 新标签页的开发者工具控制台中执行,脚本会自动下载书签文件。
附上演示截图:
数据安全
- 所有数据仅从本地读取,不会上传到任何服务器
- 导出的 HTML 文件仅包含书签的 URL 和标题,不含密码或敏感信息
- 两个脚本均为只读操作,不会修改或删除 Monknow 的原始数据
导入到浏览器
生成的 HTML 文件可通过浏览器的书签管理功能导入:
- Edge :收藏夹 → 更多选项(
...) → 导入收藏夹 - Chrome:书签管理器 → 整理 → 导入书签
- Firefox :管理书签(
Ctrl+Shift+O) → 导入和备份 → 从 HTML 文件导入书签
总结
这个工具解决了一个比较具体的需求:将 Monknow 中的数据以标准格式导出。实现上涉及浏览器扩展底层存储的读取(Chrome/Edge 的 LevelDB 日志和 Firefox 的 IndexedDB/Snappy 压缩数据),但使用者只需执行一行命令。
如果你也有同样的需求,欢迎使用或参与改进。