所有的深度学习计算机视觉判别模型,无论目标检测、图像分割还是视频动作识别等任务,其架构都可以抽象为以下三部分:
1)Backbone(骨干网络):负责对输入进行特征提取,任务是精准提取出当前输入具有的特征、有别于其它输入的特征、服务于最终任务的有效特征,类似于传统计算机视觉方法中的SIFT、HOG等特征提取方法,只不过SIFT等方法是通过人工设计的,而Backbone是利用深度学习模型自动从数据中学习的
2)Neck:负责对Backbone提取到的特征进行融合、增强等处理,任务是过滤和最终任务无关的特征、增强有效的特征
3)Head:根据具体任务类型(如目标检测、关键点检测、图像分类等),将融合后的特征,映射为任务所需的最终输出,比如分类概率(图像分类)、坐标框(目标框)等
这篇文章会详细梳理从1998年到至今为止比较典型、工业落地较多的Backbone网络,整体分为"卷积时代"和"Transformer时代"进行介绍,文章会很长。
一 卷积时代(1998~2022)
第一个问题:什么是卷积?
首先要明确卷积并不是计算机视觉单独提出来的一种操作,在计算机视觉领域使用之前,卷积操作就已经在信号处理等领域广泛使用了。简单理解"卷积"操作,可以将卷积看做是一个搜索过程,其用工具在指定对象中搜索我们感兴趣的东西,"工具"在卷积操作中称为卷积核,"对象"可以是一段波形信号、一幅图片等。卷积通过在数据上滑动卷积核,寻找我们感兴趣的东西,因为卷积核尺寸大小固定,所以我们会说卷积操作具有"局部归纳偏置",它只会在某个局部区域范围内进行操作,缺少全局视野,但是这种特点对于本身就具有局部相关性的数据,比如图像、声音,反倒是一种性能增强,因为图像中的物体肯定是集中在某个局部区域范围内的,不会弥散到整张图像,所以用卷积操作处理图像才会获得较好的效果。
第二个问题:为什么卷积操作能够通过卷积核找到我们感兴趣的东西?
传统卷积操作中的卷积核是由人工精心设计的,它根据我们要找的东西的特点,去反向构建对应的卷积核。拿图像处理中的边缘检测为例,一幅图像可以看作是由某个函数生成的,每个(x,y)处的像素值就对应这个函数的函数值f(x,y),那么在这种观点下,图像的导数可以通过差分来定义:
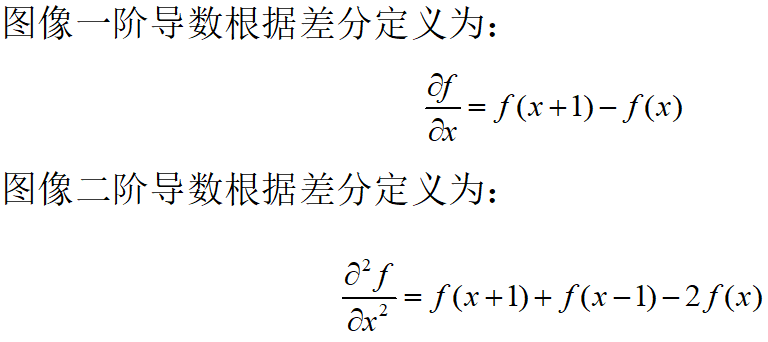
边缘是图像中灰度突变的像素集合,边缘检测的目的是通过某种方法找到这个像素集合并将这些像素进行有序连接,形成边缘。这个过程很明显就是一个搜索找东西的过程,我们可以定义一个卷积核,让这个卷积核和原图像的像素值进行卷积操作,从而得到那些灰度突变的像素集合,这样就找到了图像的边缘。
这个卷积核应该如何去定义,其实可以通过公式推导出来:
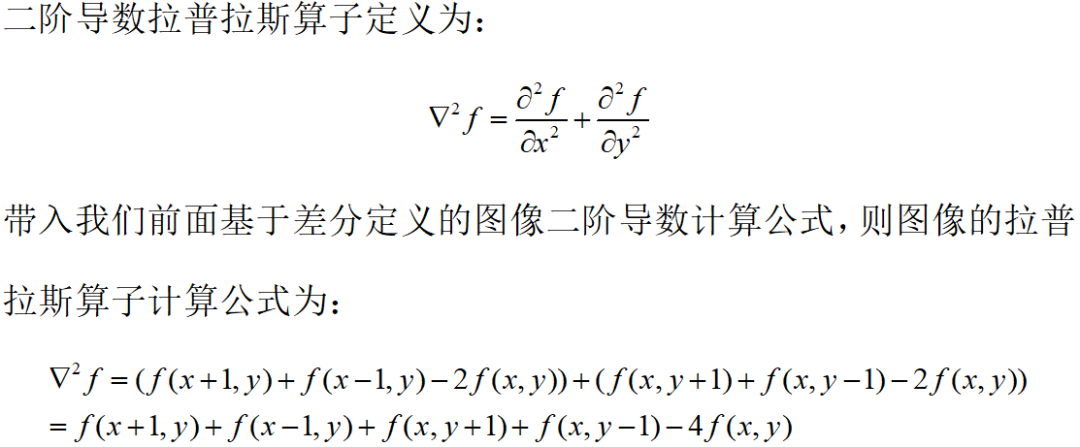
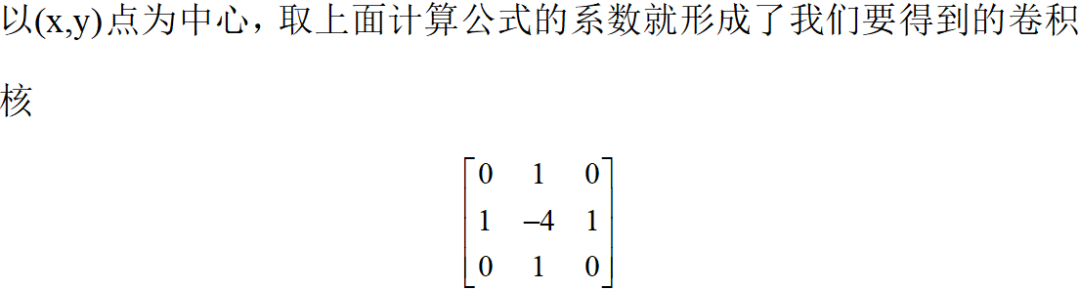
其中,卷积核的中心处是(x,y),对应公式中的-4f(x,y),所以对应位置处填-4,上面的(x-1,y)对应公式中的f(x-1,y),所以对应位置处填1,其它位置的数字同理,利用这个卷积核对图像进行卷积就得到了图像的二阶导数拉普拉斯结果,而这个结果也对应着图像像素突变幅度较大的边缘,这样我们就提取到了图像的边缘信息。
如果每个卷积核都像上面这样设计、计算会很麻烦,深度学习卷积神经网络要做的事,就是让网络自己从训练数据中学习出卷积核中的具体数值,这篇文章关注于计算机视觉Backbone,卷积更详细的介绍就不展开了,可以看:深度学习基础-3 卷积神经网络
卷积时代的Backbone都是基于这种卷积操作从输入中提取有效特征,因为将卷积过程看做是特征提取的过程,所以在深度学习中也称卷积运算得到的结果为"特征图(Feature map)"。卷积时代的Backbone是以"ResNet "作为分割节点的,在ResNet之前,大家在探索如何将卷积操作结合到深度学习中、如何构建更加有效的卷积神经网络结构,当时发现的一个事实是:更深层的卷积神经网络结构,特征提取会更加准确,但是如果盲目增大网络的层数,效果反而会下降。ResNet通过残差连接解决了这个问题,从而使训练更深层、更大规模的卷积神经网络成为可能。ResNet之后,大家对ResNet进行了不同层面的改进优化,比如更加准确、更加轻量等。进入2020年,随着Transformer架构正式进入计算机视觉领域,其表现出来的通用性、泛化性远超基于卷积架构的Backbone,大家的目光开始聚集于Transformer架构的Backbone,甚至出现了抛弃卷积操作的呼声,ConvNeXt在卷积操作的基础上,融入Transformer的优点,以卷积结构达到了比肩Transformer架构的性能,作为卷积结构Backbone的最后一舞,但是历史的发展无法阻挡,Backbone还是转向到了以Transformer架构为主的时代。
1.1 早期探索:ResNet之前(1998~2015)
1998-LeNet
《Gradient-Based Learning Applied to Document Recognition》
Yann LeCun在1998年提出LeNet,用于解决手写体图片识别问题,是深度学习计算机视觉的开端,Yann LeCun也因为对深度学习的贡献获得了图灵奖。
LeNet网络结构如下:
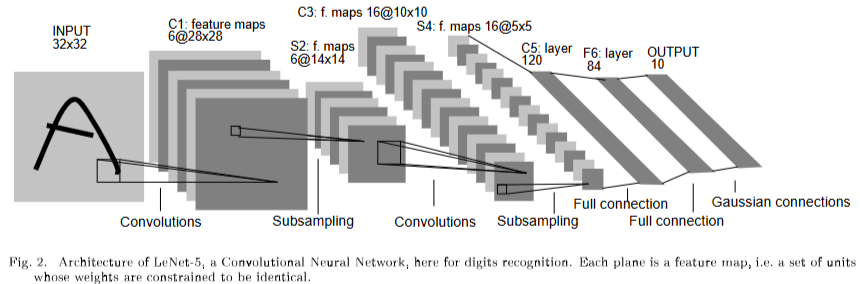
输入图片->卷积->池化->卷积->池化->全连接层分类,最终得到输入图片中包含的手写字符类别。
LeNet确立了延续至今的卷积神经网络结构设计准则:
1)利用卷积层对输入图像进行卷积操作,得到特征图(feature map)
2)利用非线性激活函数对特征图进行激活,增强网络的非线性特征提取能力
3)利用池化层对特征图进行特征池化,剔除冗余特征、保留有效特征
通过重复堆叠这些"卷积+池化"结构,从输入图像中进行特征提取。
2012-AlexNet
《ImageNet Classification with Deep Convolutional Neural Networks》
LeNet指出了深度学习计算机视觉这条道路可行,AlexNet以当时的计算条件证明了这条道路是未来最优。AlexNet在当年的ILSVRC-2012计算机视觉比赛中获得了冠军,相关指标远超第二名传统计算机视觉方法10%~20%,证明了大规模图像训练数据+深度学习卷积神经网络的可行性,网络整体结构如下:
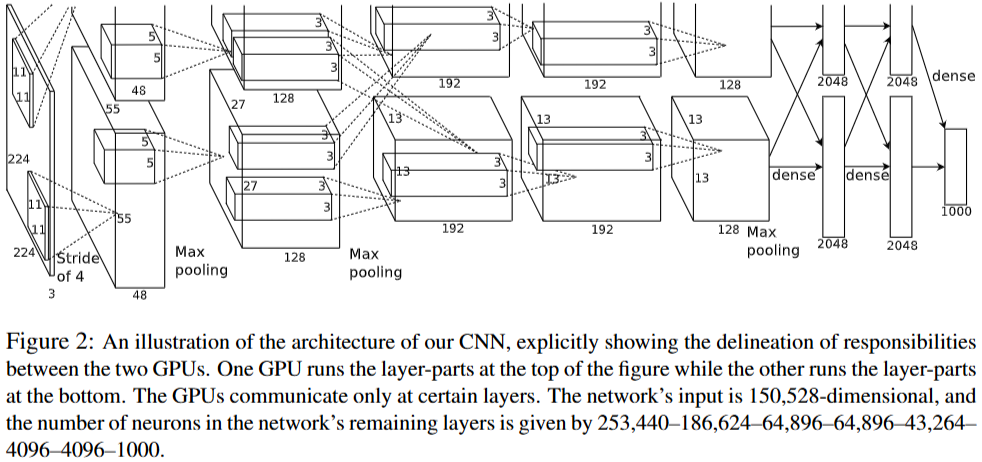
整体还是采用卷积+池化的架构,但是受限于当时的GPU计算资源条件,必须切分网络在两个GPU上进行训练,所以图中会出现平行的两部分,其实这些是一个整体,AlexNet做出了以下改进:


其中ReLU激活函数、局部相应归一化、重叠池化是为了让AlexNet特征提取更加准确,数据增强和Dropout是为了缓解AlexNet参数量过大,出现过拟合的风险。
值得一提的是论文的三个作者:

都是后来人工智能方向的大牛,感兴趣的可以自己搜索相关信息。
2015-VGG
《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
VGG验证了加深卷积神经网络的层数,会获得更好的特征提取效果,最终结果会更加准确。
为了加深卷积神经网络层数的同时,不增加网络的参数量,VGG做了以下改进:
①使用3*3的小卷积核替代以往常使用的7*7、11*11大尺寸卷积核:
VGG作者通过实验发现通过堆叠两个3*3卷积核可以得到5*5卷积核的感受野,堆叠三个就可以获得7*7卷积核的感受野,也就是2个3*3卷积核的效果等价于1个7*7卷积核的效果,这种替换在大幅减少计算量的同时,还没有损失原有卷积层的效果,论文通过大量实验验证了这种小尺寸卷积核替换是可行的:

②统一使用2*2尺寸的池化层
③通过改变不同网络层的尺寸大小,提出了多个版本的VGG模型,具体如下:
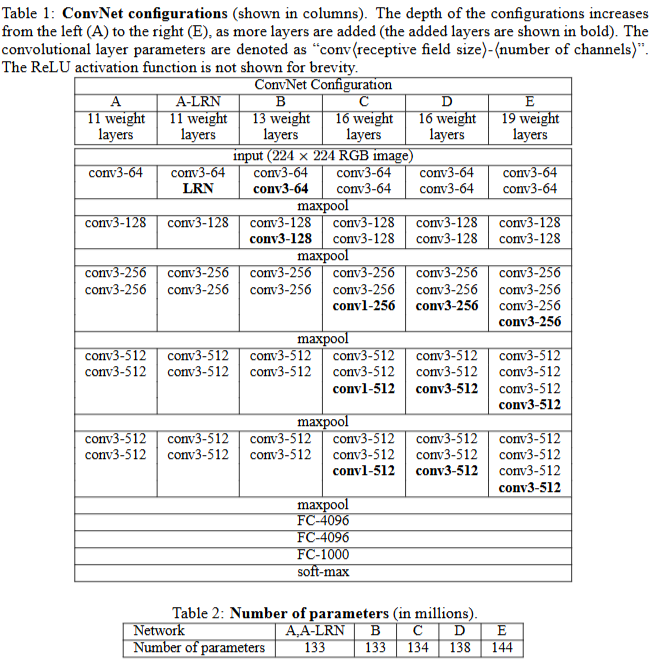
以往的卷积神经网络一般是遵循固定的结构,VGG指出了另外一条卷积神经网络设计路线:可以结合具体任务自行设计卷积层、池化层的结构、网络的深度,强调了卷积神经网络设计中的"自主性"。
2015-GoogLeNet
《Going deeper with convolutions》
VGG验证了加深卷积神经网络的可行性,GoogLeNet验证了加宽卷积神经网络的可行性。
以往卷积神经网络的卷积层都是单一、固定尺寸的卷积核,GoogLeNet提出了一种Inception结构替换以往卷积神经网络中的卷积层:
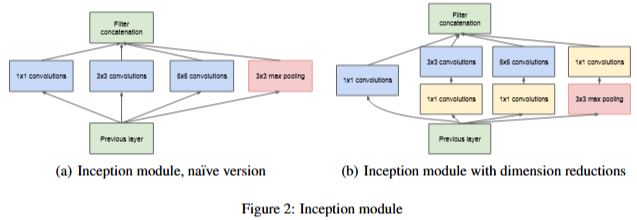
Inception结构包含多个并行的、不同尺寸大小的卷积核,用于提取输入中不同尺度大小的特征,为了避免多卷积核输出的结果过大,导致最终整体卷积神经网络参数量过大,使用1*1卷积进行输出通道数压缩,在增加网络深度、宽度的同时,不增加网络的参数规模。
为了避免整体卷积神经网络过深导致过拟合,GoogLeNet在网络的中间层外接了辅助分类器,增加梯度回传路径,保证低层网络的训练稳定,同时用平均池化层替代了以往卷积神经网络常使用的全连接层,在减少参数量的同时,提升了网络的准确率,总的来说,GoogLeNet做出了以下改进:
1)Inception结构替换以往固定尺寸大小的卷积层,可同时提取不同尺度大小的特征,提升特征提取的准确性
2)辅助分类器:为避免网络过深,低层网络得不到充分训练,在中间网络层插入辅助分类器,增加梯度回传路径,保证低层网络得到训练
3)平均池化层代替全连接层:整体网络结构全部采取卷积操作,移除对全连接层的依赖,减少参数量,让卷积神经网络结构更纯粹
2015-BN
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
BN(批归一化)是一种网络正则化方法,用于避免过深的神经网络出现过拟合的问题,是辅助Backbone的一个集成组件,作为一个独立网络层插入到Backbone中,现代的卷积神经网络一般都会默认插入BN层,其重要性不言而喻,一道经典的面试题就是"请解释BN的原理和作用,一般用于什么场景,它和LN(层归一化)有什么区别与联系",可以自行搜索答案。
BN的提出源自于这样一个问题:在神经网络训练过程中,由于前一网络层参数的更新,后面网络层输入的分布会不断变化,这使得神经网络的每一层都需要不断适应新的数据分布,从而极大减慢了训练速度与稳定性,并且会使模型极易陷入饱和区(尤其是使用Sigmoid等激活函数时)。
BN 的核心思想是在训练时,将归一化操作作为模型架构的一部分,对每一层的输入进行归一化,让它们的分布稳定在均值为0、方差为1的状态,保证输入数据分布的稳定性,同时通过可学习参数对归一化后的输入进行线性变换,恢复模型的表达能力,具体过程如下:


整体BN网络层的训练、推理伪代码如下:

训练完成后,因为推理时没有 "批量" 的概念,无法再计算当前批次的均值和方差,因此需要将训练时的 BN 层转换为固定的线性变换,合并到网络中:

1.2 卷积时代巅峰:ResNet(2015)
《Deep Residual Learning for Image Recognition》
更深的卷积神经网络具备更高的准确率,但是如果一直增加网络深度,模型不仅难以训练,还会出现一种反直觉的现象:随着网络层数变深,训练准确率会达到饱和然后迅速退化,这种退化不是由过拟合引起的(过拟合通常表现为训练集表现好而测试集表现差),而是更深层的网络反而产生了更高的训练误差,虽然有BN、Dropout这些正则化方法,但还是没有从根源上解决这个问题。
针对这个问题,何恺明等人提出了ResNet网络,从根源上解决了无法训练更深层卷积神经网络的问题。ResNet是卷积时代的巅峰之作,获得了2016年CVPR最佳论文奖,目前论文被引量超25万,所提出的残差连接思想已经渗透到人工智能各个领域深度学习网络结构的设计之中,无论是计算机视觉,还是目前的语言大模型,都有残差连接的影子。


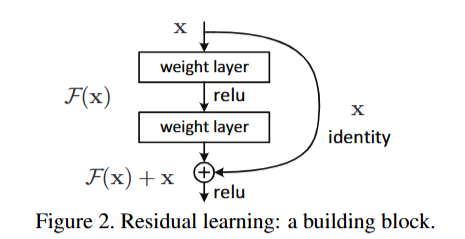
从字面意义来理解"残差连接":为什么更深层的网络训练会退化、不稳定?反过来想,怎么才能让深层网络训练稳定?如果我们新添加的网络层是恒等映射,那么你随便添加多少层,网络肯定不会退化,因为1*自身还是自身,如何将这种想法体现在网络结构设计上呢?就是残差连接,可以通过网络层旁侧的恒等映射路径直接进行前向传递,这也是上图中右侧"identity"的意义。
从梯度的角度来理解"残差连接":残差连接相当于在网络中人为构建了梯度回传的"高速通路",让不同网络层可以充分得到监督信号进行自身迭代,从而避免了退化的问题。
1.3 全方位进化:ResNet之后(2016~2022)
2017-Wide-ResNet-宽度进化
《Wide Residual Networks》
ResNet虽然能够扩展到数千层并持续提升性能,但是这种盲目增加网络深度的方式存在以下问题:
1)特征复用递减:每提升极小比例的准确率几乎需要将网络层数翻倍,导致网络极深。在训练极深的残差网络时,梯度很容易直接通过恒等映射进行传播,而不经过残差块,导致只有少数残差块学到了有用的特征表示,很多残差块对最终任务目标的贡献极小,也就是大部分网络层都是"冗余"的,资源浪费
2)训练极其缓慢:极深且极窄的网络结构由于大量的串行计算,训练效率低下,耗时极长
Wide-ResNet证明了ResNet的主要威力在于残差块,而不是极端的深度,通过适当加宽残差块,可以用极少的网络层数达到上千层ResNet的效果,在大幅提升精度的同时缩短训练时间。
2017-DenseNet-连接进化
《Densely Connected Convolutional Networks》
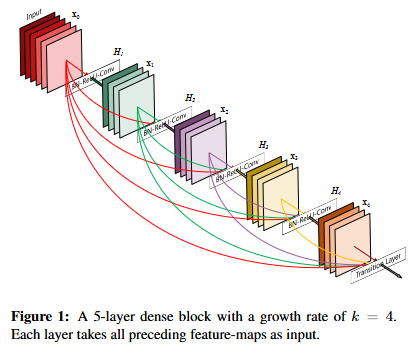
DenseNet拓展了残差网络"高速梯度通道"的思想,为了确保网络层之间的最大信息流动,其将所有网络层彼此进行直连,也就是在L层的网络中,传统卷积神经网络有L个连接,但是DenseNet有L*(L+1)/2个连接。
与ResNet直接进行残差分支输出和短路分支输出求和进行特征输出的方式不同,DenseNet通过特征拼接的方式进行特征输出,第L个模块会以之前所有模块的特征输出作为输入,然后将这些特征进行通道缩减、卷积、拼接,作为当前层的特征输出,通道缩减通过1*1卷积实现,目的是避免整体网络参数量过大。因为不同网络层输出的特征维度不同,无法直接进行拼接处理,所以在DenseNet中,不同DenseBlock之间会插入维度变换层进行特征维度变换,保证维度统一,具体是使用平均池化层进行实现的。
DenseNet通过拼接不同网络层的特征输出达到特征复用的效果,但只需要很少的卷积核,整体上,DenseNet只使用ResNet一半的参数量就可以达到相同的效果,但是DenseNet的特征拼接操作会占用大量显存。
模型轻量化
2016 SqueezeNet
《SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE》
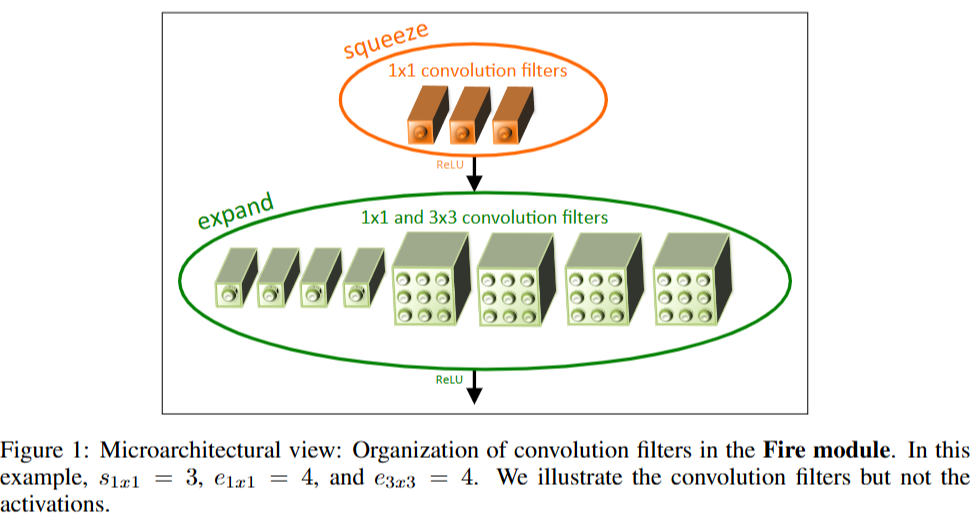
SqueezeNet提出Fire模块对以往的卷积层进行压缩替换。



2017~2018 MobileNet系列
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
以往的卷积神经网络虽然准确率很高,但是无法真正落地到资源受限的设备上,往往都是理论上能达到最优,但是无法工程落地。MobileNet的目标是设计嵌入式、移动式设备上真正可用的卷积神经网络。
MobileNet的设计思想是采取矩阵分解的方法,将以往的3*3卷积操作,分解为逐通道深度卷积+逐空间位置的1*1卷积,也就是现在常说的深度可分离卷积

MobileNet V2发现V1版本存在以下问题:
1)ReLU激活函数会使MobileNet大部分输出特征都是0,降低了模型的性能
2)输入特征通道数较少时,深度可分离卷积准确性较差
针对以上问题,MobileNet V2提出"带有线性瓶颈的倒残差结构"替换以往的卷积层。

ReLU6激活函数定义为y=min(max(0,x),6),也就是强制将ReLU的取值范围缩减到0,6,增强网络在低精度条件下的稳定性,同时MobileNet V2在瓶颈结构第二个1*1卷积之后不使用激活函数,降低ReLu激活造成的损失。
2017~2018 ShuffleNet系列
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
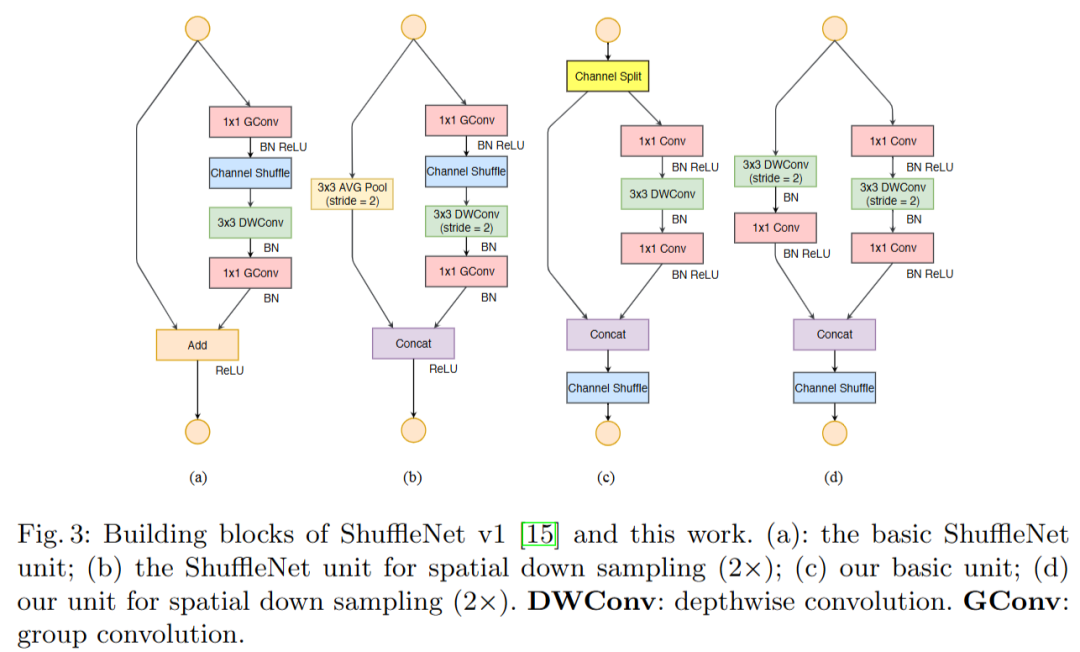
相比于MobileNet,ShuffleNet对1*1卷积也进行了分组,进一步提升网络计算速度,同时为了增强分组之间的信息交互,引入了混洗(Shuffle)操作:

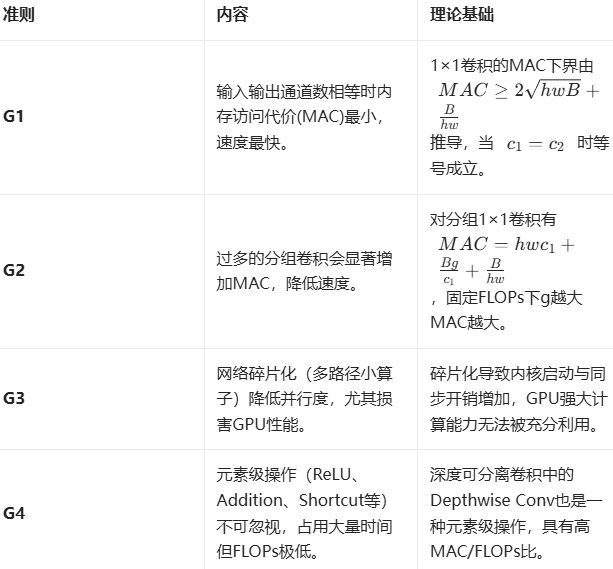
ShuffleNet V2通过实验归纳了以下高效卷积神经网络设计准则:
基于以上准则设计了ShuffleNet V2

2020-EfficientNet-NAS引入
到这个时间点,卷积神经网络的设计准则业界已经逐渐探索完成,主要有以下几种方式:

但是纯手工的方式进行网络设计,不好调节各个设计点,EfficientNet利用神经网络架构搜索(NAS)方法,自动寻找最优的卷积神经网络结构。
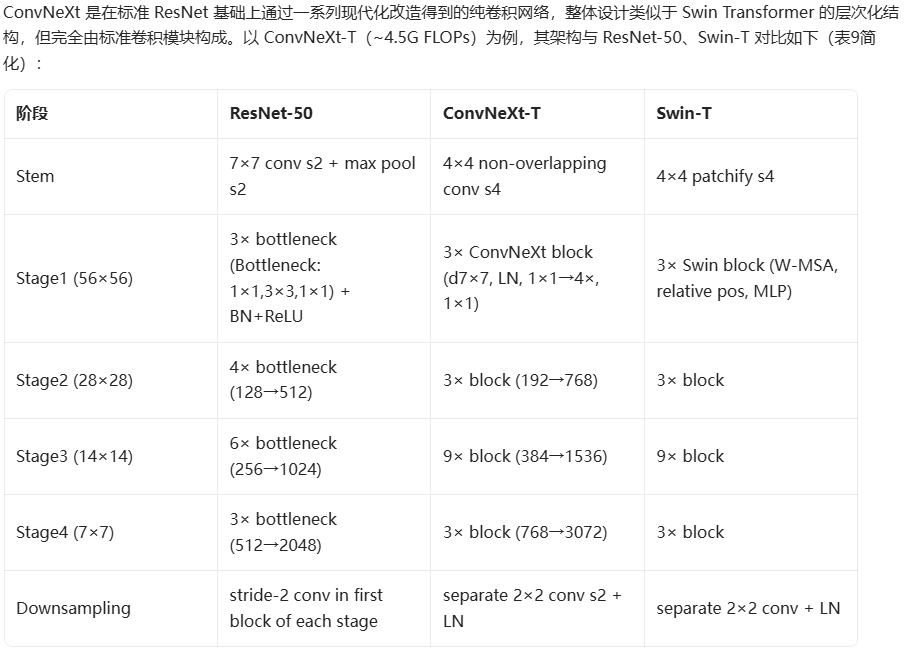
2022-ConvNeXt-卷积结构最后一舞
到了2022年,Transformer基本上已经证明了自己在计算机视觉任务上的潜力,相比于卷积架构更具备通用性、泛化性,大家也更多聚焦于Transformer架构的Backbone结构,甚至呼吁放弃卷积。
ConvNeXt详细对比、分析了为什么卷积架构不如Transforme架构,并以ResNet为基础,借鉴Transformer架构的优点,重新设计ResNet,达到了比肩Transformer架构Backbone的性能。


ViT Patch Embedding模仿:



利用类似MobileNet的深度可分离卷积模仿Transformer的注意力机制



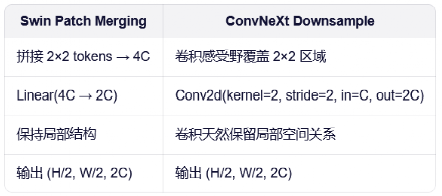
Patch Merge模仿:
1.4 卷积时代Backbone小结
1998年LeNet确定了深度学习卷积神经网络的架构模式:"卷积层+池化层",通过不断堆叠这些网络层,从输入图片中进行特征提取。当时是支持向量机(SVM)的浪潮,深度学习并没有受到太多重视,随着数据量的积累以及加速训练硬件GPU的出现,2012年AlexNet凭借卷积神经网络获得了计算机视觉大赛的冠军,效果远超第二名传统计算机视觉方法近10%~20%,证明了卷积神经网络才是计算机视觉的未来。2015年VGG、GoogLeNet、BN方法的提出,将人们的注意力带到如何设计卷积层、池化层、网络结构上,想通过这种精心设计,挖掘卷积神经网络的全部潜力,最终人们达成了共识:更深的卷积神经网络,具有更高的准确率,但是当盲目增加卷积神经网络层数时,会出现训练失败的问题。2016年ResNet的提出,将训练更深层卷积神经网络变成了现实,之后在"更深、更快、更准"目标的指引下,出现了对ResNet进一步的优化网络。Wide-ResNet首先证明了更宽的网络+残差连接足以媲美笨重的深层网络,DenseNet将残差连接的"高速梯度通道"思想发挥到了机制,SqueezeNet、MobileNet、ShuffleNet在人们追求更深、参数量更大网络的时候,目光转向到卷积神经网络的轻量化,借助卷积分解、通道混洗等操作,使卷积神经网络更快、更轻,能真正部署到嵌入式、移动式设备上。到此时,人们已经积累了大量卷积神经网络设计准则,EfficientNet借助NAS技术,根据这些设计准则,利用NAS自动构建出最优的卷积神经网络结构。2021年Transformer正式进入计算机视觉领域,表现出了卷积架构不具有的通用性、泛化性,在人们普遍怀疑卷积架构未来的时候,ConvNeXt通过对比、融合Transfromer架构特点到ResNet中,凭借卷积架构达到了比肩Transformer架构的性能,但是历史的发展不可阻挡,自2020年之后,Backbone转向到了以Transformer为核心的路线上。