讲解视频:notebooklm.google.com/notebook/c2..._
Python 常用排序算法详解
这篇文章整理了Python中从内置工具 到面试高频手写算法的所有常用排序方法,每个算法都包含「核心思想、代码实现、过程讲解、复杂度分析」,新手也能看懂,面试/刷题直接用,这是本博客的第一篇文章,希望大家多多包涵
一、Python 内置排序(开发首选)
Python 提供了两个开箱即用的排序工具,底层是 Timsort(结合归并排序+插入排序的优化算法),是实际开发中最高效、最稳定的选择。
1. list.sort() 方法(原地排序)
核心特点
- 直接修改原列表,不返回新列表
- 支持升序/降序,支持自定义排序规则
- 稳定排序(相等元素的相对位置不变)
代码示例
python
# 1. 基础用法:默认升序
nums = [3, 1, 4, 1, 5, 9, 2, 6]
nums.sort()
print("升序结果:", nums) # [1, 1, 2, 3, 4, 5, 6, 9]
# 2. 降序排序
nums.sort(reverse=True)
print("降序结果:", nums) # [9, 6, 5, 4, 3, 2, 1, 1]
# 3. 自定义规则:按字符串长度排序
words = ["banana", "apple", "cherry", "date"]
words.sort(key=lambda x: len(x)) # key指定排序依据
print("按长度排序:", words) # ['date', 'apple', 'banana', 'cherry']复杂度分析
- 时间复杂度:平均 / 最好 / 最坏均为 O (n log n)(Timsort 优化后,几乎不会出现最坏情况)
- 空间复杂度:O (n)(Timsort 需要额外空间处理合并)
- 稳定性:稳定
2. sorted () 函数(返回新列表)
核心特点
- 不修改原列表,返回一个新的排序列表
- 可对任意可迭代对象排序(列表、元组、字符串、字典等)
- 用法和 sort () 类似,同样支持 key 和 reverse 参数
代码示例
python
# 1. 对列表排序(不修改原列表)
nums = [3, 1, 4, 1, 5]
new_nums = sorted(nums)
print("原列表:", nums) # [3, 1, 4, 1, 5](不变)
print("新列表:", new_nums) # [1, 1, 3, 4, 5]
# 2. 对字典按值排序
students = {"Alice": 85, "Bob": 78, "Charlie": 92}
# 按分数升序排序,返回元组列表
sorted_students = sorted(students.items(), key=lambda x: x[1])
print("按分数排序:", sorted_students) # [('Bob', 78), ('Alice', 85), ('Charlie', 92)]复杂度分析
和 list.sort() 完全一致,仅返回新列表,空间上会多占用一份原列表的空间。
二、基础交换类排序(入门必学)
这类算法是排序的基础,逻辑简单易理解,适合新手入门,也是面试中常考的手写题。
1. 冒泡排序(Bubble Sort)
核心思想
像水里的气泡一样,相邻元素两两比较,大的慢慢 "冒" 到后面,每一轮都会把当前最大的元素放到正确位置。 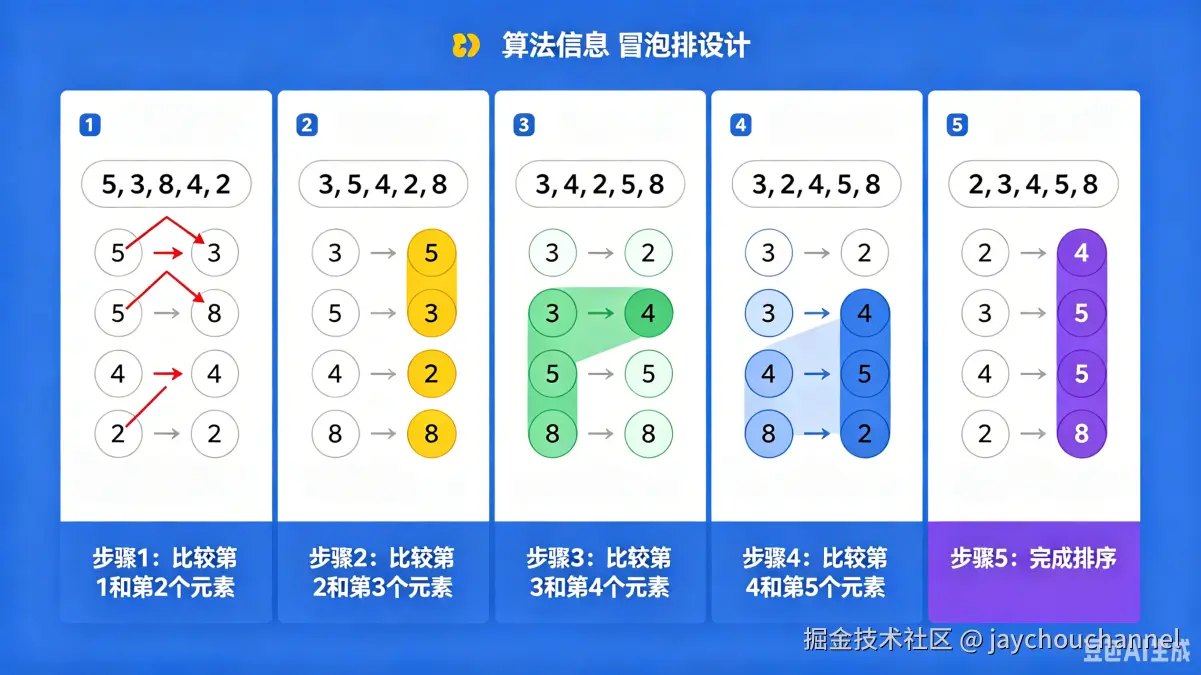
过程讲解
- 从第一个元素开始,和下一个元素比较,若前者大于后者则交换
- 每一轮结束后,当前最大的元素会被移到末尾
- 重复 n-1 轮(n 为列表长度),直到所有元素有序
- 优化:如果某一轮没有发生任何交换,说明列表已经有序,可以直接退出
代码实现
python
def bubble_sort(arr):
n = len(arr)
# 外层循环:控制轮数,每轮确定一个最大元素的位置
for i in range(n):
swapped = False # 标记本轮是否发生交换
# 内层循环:比较相邻元素,注意每轮结束后末尾i个元素已经有序,无需再比较
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
# 交换两个元素
arr[j], arr[j + 1] = arr[j + 1], arr[j]
swapped = True
# 如果本轮没有交换,说明已经有序,直接退出
if not swapped:
break
return arr
# 测试
print(bubble_sort([64, 34, 25, 12, 22, 11, 90])) # [11, 12, 22, 25, 34, 64, 90]复杂度分析
- 时间复杂度: 平均情况:O(n²)
- 空间复杂度:O(1) (原地排序,仅用了几个变量)
2. 选择排序(Selection Sort)
核心思想
每一轮在未排序部分找到最小的元素,放到已排序部分的末尾,就像打扑克时,每次从剩下的牌里挑最小的放到前面。 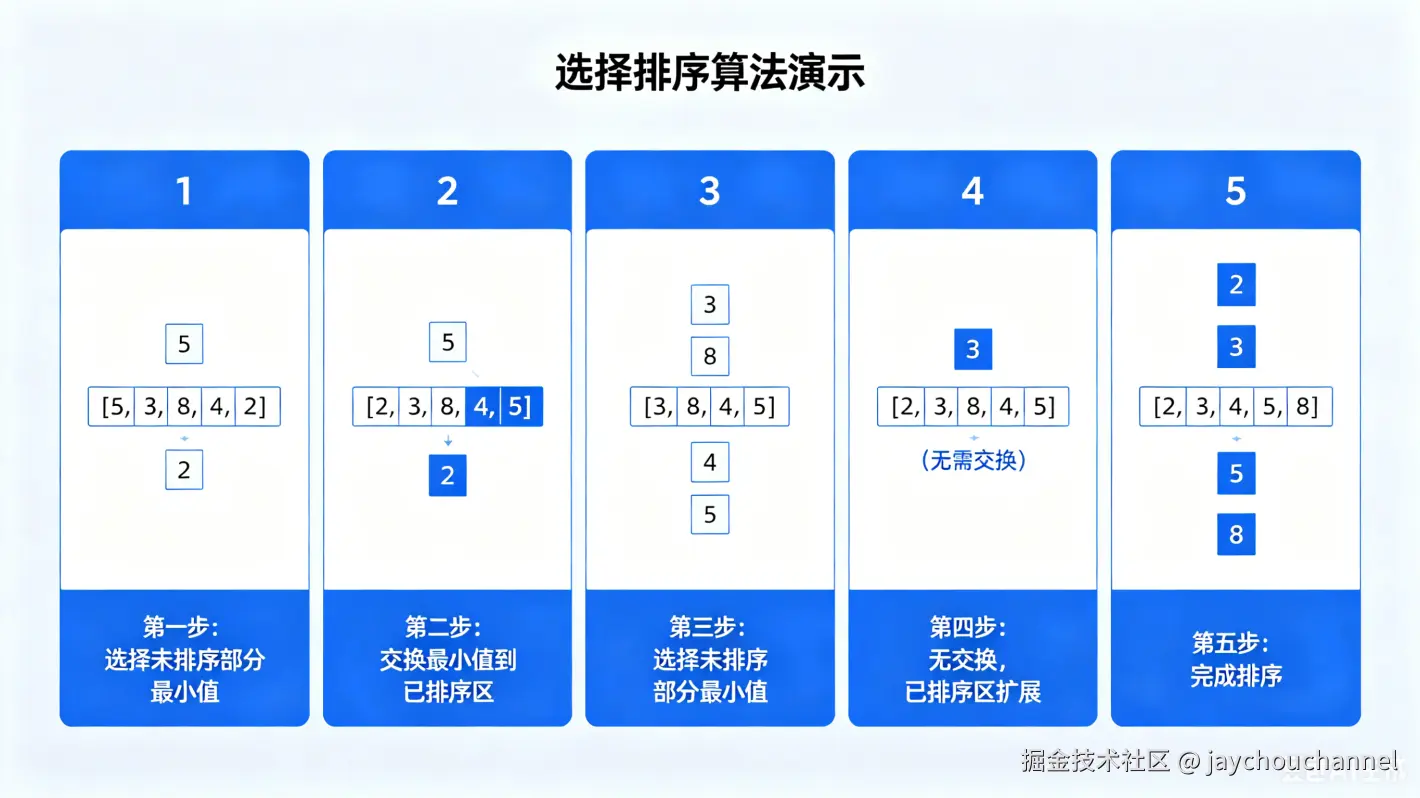
过程讲解
- 将列表分为「已排序部分」和「未排序部分」,初始时已排序部分为空
- 遍历未排序部分,找到最小元素的索引
- 将最小元素和未排序部分的第一个元素交换,该元素加入已排序部分
- 重复 n-1 轮,直到所有元素有序
代码实现
python
def selection_sort(arr):
n = len(arr)
# 外层循环:控制已排序部分的末尾位置
for i in range(n):
min_idx = i # 假设当前i位置是未排序部分的最小值
# 内层循环:遍历未排序部分,找到真正的最小值索引
for j in range(i + 1, n):
if arr[j] < arr[min_idx]:
min_idx = j
# 将最小值和当前i位置交换
arr[i], arr[min_idx] = arr[min_idx], arr[i]
return arr
# 测试
print(selection_sort([64, 25, 12, 22, 11])) # [11, 12, 22, 25, 64]复杂度分析
- 时间复杂度: 最好 / 最坏 / 平均情况:均为 O(n²)(无论列表是否有序,都要遍历找最小值)
- 空间复杂度:O(1)(原地排序)
- 稳定性:不稳定(交换操作可能破坏相等元素的相对位置,例如 2, 2, 1 排序后两个 2 的位置会改变)
三、进阶高效排序(面试高频)
这类算法的时间复杂度是 O (n log n),效率远高于基础排序,是面试中手写算法的重点。
1. 快速排序(Quick Sort)
核心思想
分治思想的经典实现:选一个基准元素,将列表分为「比基准小的左半部分」和「比基准大的右半部分」,再递归对左右两部分进行快速排序,直到子列表长度为 1(自然有序)。 
过程讲解
- 选一个基准元素(pivot,通常选第一个、最后一个或中间元素,优化时可随机选)
- 定义左右指针,左指针从左往右找比 pivot 大的元素,右指针从右往左找比 pivot 小的元素
- 交换左右指针找到的元素,直到两指针相遇,将基准元素放到相遇位置(此时左边都比 pivot 小,右边都比 pivot 大)
- 递归处理左半部分和右半部分,直到子列表长度≤1
代码实现
python
def quick_sort(arr, low=0, high=None):
# 初始化high为列表末尾索引
if high is None:
high = len(arr) - 1
# 递归终止条件:low >= high,说明子列表长度≤1,已有序
if low >= high:
return arr
# 1. 分区操作:将列表分为左右两部分,返回基准元素的最终位置
pivot_index = partition(arr, low, high)
# 2. 递归排序左半部分(基准左边)
quick_sort(arr, low, pivot_index - 1)
# 3. 递归排序右半部分(基准右边)
quick_sort(arr, pivot_index + 1, high)
return arr
def partition(arr, low, high):
# 优化:随机选基准,避免最坏情况
import random
pivot_idx = random.randint(low, high)
arr[pivot_idx], arr[high] = arr[high], arr[pivot_idx] # 把基准放到末尾,方便处理
pivot = arr[high] # 基准元素
i = low - 1 # 小于基准的元素的边界索引
# 遍历low到high-1的元素
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
# 把基准放到正确位置(i+1)
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
# 测试
print(quick_sort([10, 7, 8, 9, 1, 5])) # [1, 5, 7, 8, 9, 10]最简快速排序
代码实现
python
def quick_sort(arr):
# 递归终止条件:列表长度≤1,直接返回
if len(arr) <= 1:
return arr
# 选择第一个元素作为基准
pivot = arr[0]
# 拆分:左=小于基准,中=等于基准,右=大于基准
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
# 递归拼接结果
return quick_sort(left) + middle + quick_sort(right)
# 测试
print(quick_sort([3, 6, 8, 10, 1, 2, 1])) # [1, 1, 2, 3, 6, 8, 10]复杂度分析
- 时间复杂度: 最好 / 最坏 / 平均情况:均为 O(n log n)(无论列表是否有序,都要分 log n 层,每层合并 n 个元素)
- 空间复杂度:O(n)(需要额外的辅助列表存储合并结果,递归栈深度为 log n,可忽略)
- 稳定性:稳定(合并时相等元素会按原顺序放入结果列表,相对位置不变)
- 适用场景:大数据量、要求稳定排序的场景(如外排序、链表排序),Timsort 底层就用到了归并排序的优化
2.归并排序
核心思想
分治思想的稳定实现:将列表不断二分,直到每个子列表只有一个元素(自然有序),再将有序的子列表两两合并,最终得到完整的有序列表。 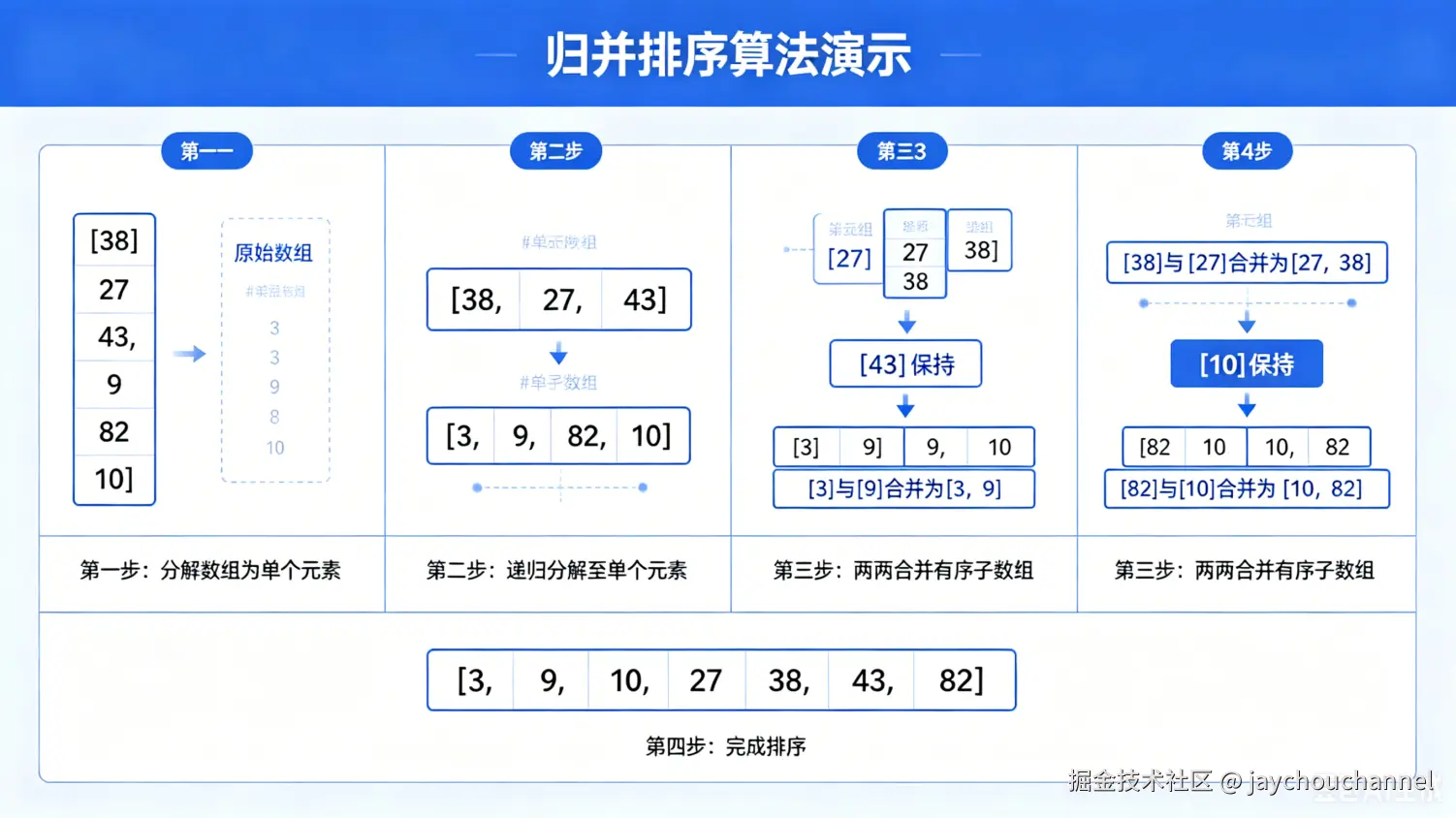
过程讲解
- 分:将列表从中间分为左右两个子列表,递归对左右子列表进行归并排序,直到子列表长度为 1
- 治(合并):将两个有序的子列表合并成一个新的有序列表 定义两个指针,分别指向左右子列表的开头 比较两个指针指向的元素,将较小的元素放入结果列表,对应指针后移 直到其中一个子列表遍历完,将另一个子列表的剩余元素直接追加到结果列表
代码实现
python
def merge_sort(arr):
# 递归终止条件:子列表长度≤1,已有序
if len(arr) <= 1:
return arr
# 1. 分:将列表从中间分为左右两部分
mid = len(arr) // 2
left = merge_sort(arr[:mid]) # 递归排序左半部分
right = merge_sort(arr[mid:]) # 递归排序右半部分
# 2. 治:合并两个有序列表
return merge(left, right)
def merge(left, right):
result = []
i = j = 0 # 左右子列表的指针
# 遍历两个子列表,按顺序合并
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# 追加剩余元素(如果有)
result.extend(left[i:])
result.extend(right[j:])
return result
# 测试
print(merge_sort([38, 27, 43, 3, 9, 82, 10])) # [3, 9, 10, 27, 38, 43, 82]四、排序算法对比总结
| 算法 | 时间复杂度(平均) | 时间复杂度(最坏) | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| Timsort(内置) | O(n log n) | O(n log n) | O(n) | 稳定 | 实际开发、所有场景 |
| 冒泡排序 | O(n²) | O(n²) | O(1) | 稳定 | 教学演示、数据量极小的场景 |
| 选择排序 | O(n²) | O(n²) | O(1) | 不稳定 | 教学演示、数据量极小的场景 |
| 快速排序 | O(n log n) | O(n²) | O(log n) | 不稳定 | 大数据量、内存有限的场景 |
| 归并排序 | O(n log n) | O(n log n) | O(n) | 稳定 | 大数据量、要求稳定排序的场景 |