| 项目 | 内容 |
|---|---|
| summary | 基于 scikit-learn Digits 数据集,使用随机森林训练 10 分类手写数字识别模型,并将 Permutation Importance 映射为 8×8 像素热力图,直观展示模型「看」的是哪里。 |
| description | 本文基于 scikit-learn Digits 手写数字数据集,使用随机森林进行 0-9 多分类识别,涵盖混淆矩阵分析、像素级特征重要性热力图和误分类样本可视化,提供完整可复现代码。 |
本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/

Digits 手写数字识别:随机森林多分类 + 像素级特征热力图
前两个项目分别做了二分类和回归,这次试试多分类。多分类比二分类更复杂的地方在于:错误不再只是「对或错」,而是「把 A 错认成了 B」。哪些数字容易互相混淆?模型「看」的是图像的哪个区域?这些问题比单纯追求准确率更有意思。
这次用的是 scikit-learn 内置的 Digits 数据集------1,797 张 8×8 的手写数字图片,每张就是 64 个像素值。任务很简单:让模型认出这是 0-9 中的哪个数字。
完整代码:GitHub 仓库
核心结论:
- Accuracy:96.67%
- Macro F1:96.61%
- 误分类:12 / 360(3.33%)
- 最难认的数字:8(Recall 只有 0.86)
- 模型最关注的像素:第 21 号像素(8×8 网格中心偏上位置)
1. 数据集
Digits 数据集是 MNIST 的简化版。每张图只有 8×8 = 64 个像素,但已经足以区分 0-9 十个数字。
python
from sklearn.datasets import load_digits
digits = load_digits()
# digits.data: (1797, 64) --- 1797 张图,每张 64 个像素
# digits.target: (1797,) --- 0-9 的标签各类别分布:
| 数字 | 样本数 |
|---|---|
| 0 | 178 |
| 1 | 182 |
| 2 | 177 |
| 3 | 183 |
| 4 | 181 |
| 5 | 182 |
| 6 | 181 |
| 7 | 179 |
| 8 | 174 |
| 9 | 180 |
分布很均衡,不需要处理类别不均衡。训练集 1,437 张,测试集 360 张。
2. 环境准备
多了一个 seaborn 用于画更漂亮的混淆矩阵:
text
pandas
numpy
scikit-learn
matplotlib
seaborn
bash
git clone https://github.com/coderWang404/xingshuProjects.git
cd xingshuProjects/2026-06-08-digits-multiclass
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt3. 运行实验
bash
python experiments/digits-multiclass/run_experiment.py4. 建模思路
随机森林天然适合这种结构化特征(64 个像素值就是 64 个数值特征)。参数:
python
model = RandomForestClassifier(
n_estimators=200,
max_depth=12,
min_samples_leaf=2,
random_state=42,
n_jobs=-1,
)min_samples_leaf=2 设得很小,因为单张图片的特征空间很紧凑(只有 64 维),稍微深一点的树也不会过拟合。max_depth=12 对于 64 维数据来说绰绰有余------随机森林不需要像神经网络那样几十层。
5. 结果:Accuracy 96.67%,但数字 8 是「困难户」
测试集 360 张图片,只错了 12 张。核心指标:
| 指标 | 数值 |
|---|---|
| Accuracy | 0.9667 |
| Macro Precision | 0.9674 |
| Macro Recall | 0.9662 |
| Macro F1 | 0.9661 |
按数字拆开看:
| 数字 | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| 0 | 0.97 | 0.97 | 0.97 | 36 |
| 1 | 0.92 | 0.97 | 0.95 | 36 |
| 2 | 1.00 | 0.97 | 0.99 | 35 |
| 3 | 0.97 | 1.00 | 0.99 | 37 |
| 4 | 0.97 | 1.00 | 0.99 | 36 |
| 5 | 0.97 | 1.00 | 0.99 | 37 |
| 6 | 1.00 | 0.97 | 0.99 | 36 |
| 7 | 0.92 | 1.00 | 0.96 | 36 |
| 8 | 0.94 | 0.86 | 0.90 | 35 |
| 9 | 1.00 | 0.92 | 0.96 | 36 |
数字 8 是唯一的「困难户」------Recall 只有 0.86,意味着 35 张 8 里面有 5 张被认错了。看混淆矩阵会更清楚:
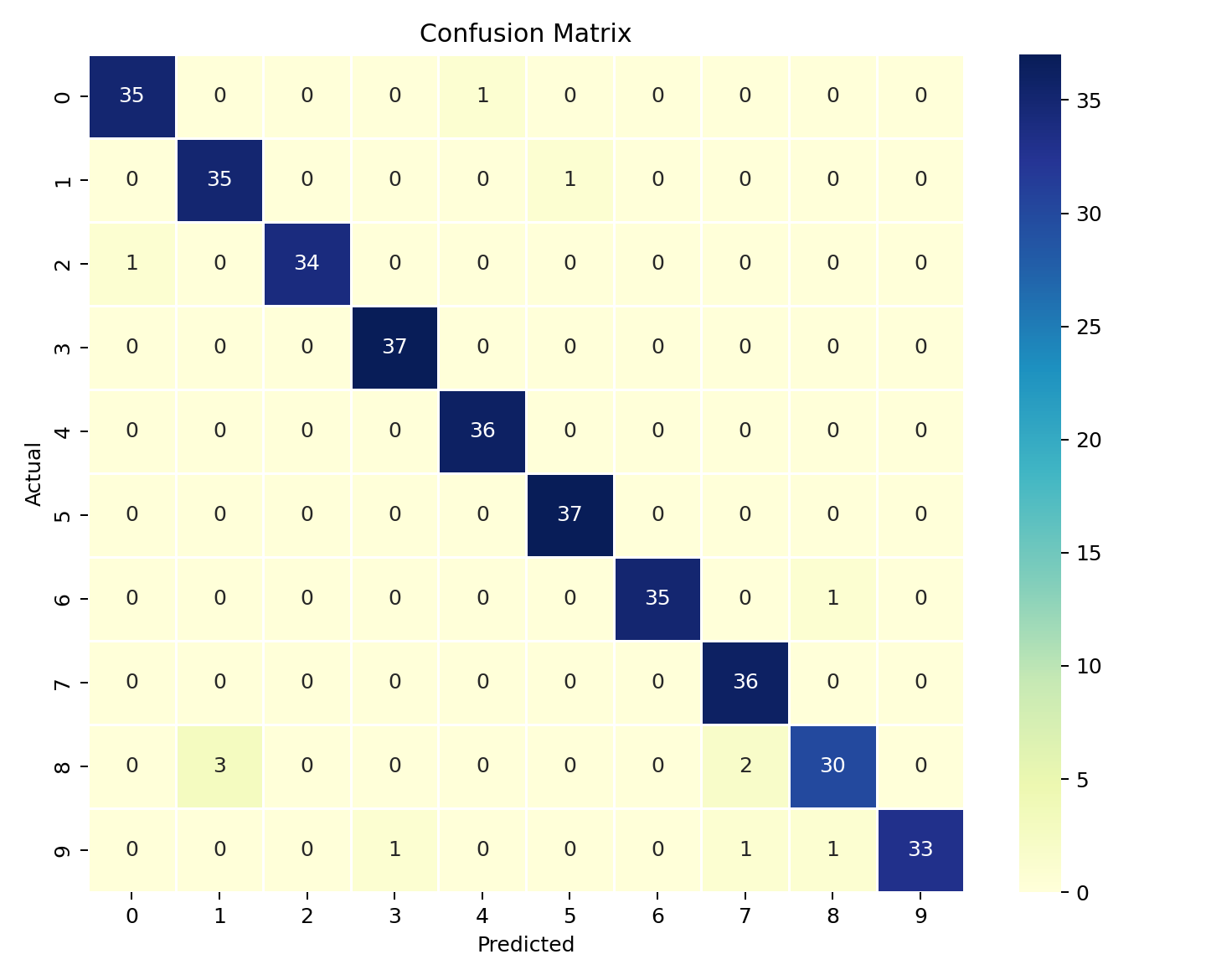
从图里能读出几个有趣的模式:
- 8 最容易被错认成 1(3 次)。其实不难理解:8×8 的分辨率下,一个写得瘦长的 8 确实容易看起来像 1。
- 8 还会被错认成 7(2 次)。8 的上半圈和 7 的横折在低分辨率下很容易混淆。
- 9 的 Recall 也不高(0.92),有 2 张被错认成 7 和 8。
- 数字 2、3、4、5、6 几乎没有错误------它们在 8×8 分辨率下的特征非常鲜明。

上面是部分错误案例的实拍。肉眼也能看出:有些 8 确实写得太像 1 或 7 了,别说是模型,人眼也得仔细看才能分清楚。
6. 像素级特征重要性:模型「看」的是哪里
这是这次实验最有意思的部分。我把 Permutation Importance 映射回了 8×8 的像素网格:
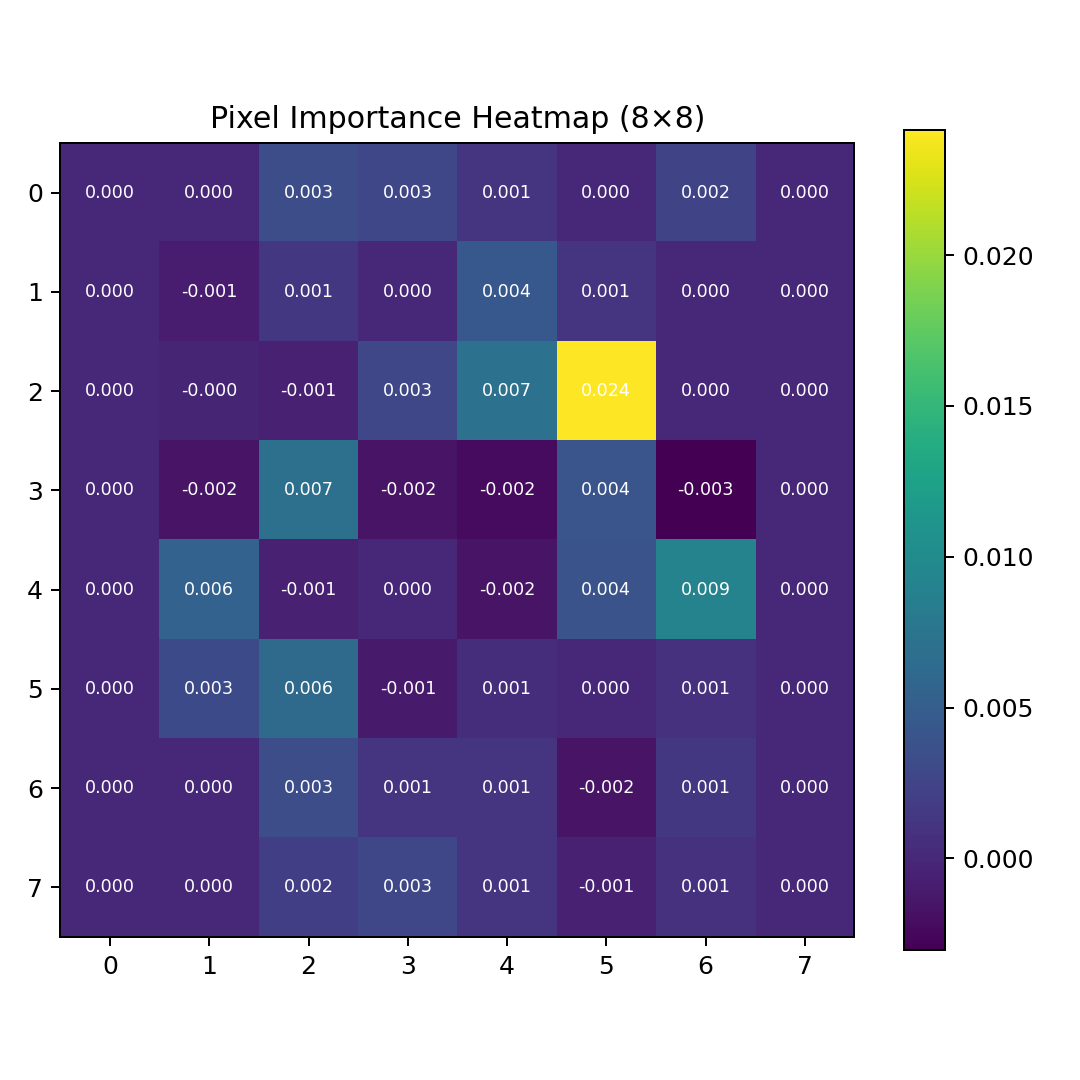
颜色越亮(黄绿色),说明这个像素对模型判断越重要。能看出非常明显的规律:
模型最关注的是图像的中心区域。第 21 号像素(第 2 行第 5 列,中心偏上)的重要性高达 0.024,是第二名的 2.6 倍。这个数字区域恰好是大多数手写数字的「笔画交汇点」------0 的中心空洞、8 的上下连接处、6 的圆环中心都落在这个区域。
边缘像素(最外一圈)的重要性普遍很低。这也符合直觉:手写数字的有效笔画很少延伸到最边缘。
但有一个反直觉的发现:角上的像素(比如第 0、7、56、63 号)虽然重要性低,但几乎没有为零的。这说明即使是边缘,模型也会用到------比如 1 的竖线可能偏左或偏右,7 的横折可能偏上。随机森林通过组合这些「弱信号」来做出最终判断。
7. 输出文件
运行后 experiments/digits-multiclass/outputs/ 会生成:
text
metrics.json # 完整指标 JSON
classification_report.txt # 每类分类报告
dataset_profile.csv # 像素值统计
feature_importance.csv # 全部像素重要性
class_distribution.png # 类别分布图
confusion_matrix.png # 混淆矩阵热图
feature_importance.png # Top 20 像素条形图
pixel_importance_heatmap.png # 8×8 像素热力图 ⭐
misclassified_samples.png # 错误案例实拍
summary.md # 实验摘要8. 总结
这个实验让我对「多分类」和「图像特征的模型解释」有了更直观的理解:
- Accuracy 96.67% 在多分类里已经很高了,但拆到每类就会发现 8 是明显的短板。
- 混淆矩阵比 Accuracy 更有信息量------它告诉你模型到底在「哪里犯错」,而不是简单告诉你「对了多少」。
- 像素热力图是最有 insight 的可视化------它把抽象的「特征重要性」变成了肉眼可见的「模型在看哪里」。
- 低分辨率图像(8×8)对随机森林已经很友好了。如果换成 28×28 的 MNIST,特征数会变成 784,随机森林的性能会下降,这时候就该 CNN 出场了。
如果想拿它当学习模板,建议试试这几个改动:
- 把
max_depth从 12 改成 5 或 20,观察 Accuracy 和混淆矩阵的变化 - 用 Support Vector Machine(SVM)跑一遍同样的数据,对比两种模型的错误模式
- 把 8×8 图像可视化出来,对比模型认为「重要」的像素和实际笔画的重合度
完整代码与实验脚本:GitHub 仓库