Linux进程调度与优先级机制:从硬件上下文到O(1)调度算法完全详解
一、前言:本节目标与背景
在之前,我们已经学习了进程的基本概念、fork创建、进程状态(R、S、D、T、t、X、Z)以及僵尸进程与孤儿进程。今天我们要将进程从静态的数据结构推进到动态执行的层面,核心围绕三个目标:
- 进程优先级:彻底搞懂PRI与Nice值的关系、修改方法、取值范围及其限制。
- 进程切换:重点理解"硬件上下文"这一概念------寄存器中保存的临时数据如何被保存与恢复。
- 进程调度:掌握Linux内核真正使用的O(1)调度算法,包括其数据结构(运行队列、优先级数组、位图、活跃/过期队列)和完整调度逻辑,并理解分时系统与实时系统的区别。
这三个模块层层递进:优先级是调度的依据,调度引发切换,切换依赖硬件上下文。完成学习后,进程在你的大脑中将从一个PCB结构体,变成在CPU上不断流转的动态实体。
二、进程状态简要回顾
进程在Linux内核中有具体状态,对应ps命令的STAT列。我们上节课重点讨论了:
- R:运行态或就绪态(正在CPU上运行或等待运行)。
- S:可中断睡眠(阻塞状态,等待资源或事件)。
- D:不可中断睡眠(通常等待I/O,不响应信号)。
- T:停止状态(被作业控制信号暂停)。
- t:跟踪停止状态(如被调试器暂停)。
- X:死亡状态(进程终止,PCB被回收,肉眼不可见)。
- Z:僵尸状态(进程已终止但PCB未回收,等待父进程读取退出信息)。
这些状态中,S、D、T、t都可归为广义的阻塞态,X和Z是死亡态。另外还有前台与后台进程的概念:只有前台进程能够从键盘读取输入,且系统同时仅允许一个前台进程。父进程先于子进程退出时,子进程会被init(或systemd)领养,成为孤儿进程;而子进程退出后若父进程未回收资源,则成为僵尸进程,长期积累会导致内存泄漏。
以上是进程的静态属性,今天我们将进入动态层面。
三、进程优先级
3.1 优先级的本质
优先级是决定进程获得资源先后顺序的标尺 。在多任务系统中,CPU是核心资源,进程数量远超CPU核数,因此必须通过优先级来决定谁先被调度、谁后被执行。这种竞争与排序的现实世界类比包括:食堂排队、图书馆占座、高考录取排名。在操作系统层面,我们所讨论的优先级特指CPU调度优先级。
优先级与权限的区别
很多同学容易混淆这两个概念,我们对比一下:
| 概念 | 核心问题 | 例子 |
|---|---|---|
| 权限 | 能还是不能? | 普通用户不能修改系统关键文件;超级用户可以。 |
| 优先级 | 已经能了,谁先谁后? | 多个进程都能用 CPU,但必须排队决定先后。 |
· 权限:能不能访问资源。比如普通用户不能修改/etc/shadow。
· 优先级:已经能访问了,但谁先谁后。比如多个进程都要使用CPU,谁先上。
3.2 查看优先级:ps -al
使用 ps -al 可以查看进程的多个属性,其中包括与优先级相关的关键字段:
- UID :用户ID,标识进程由哪个用户启动。Linux内核通过数字UID识别用户,但通常命令会通过
/etc/passwd配置文件将UID映射为用户名显示(例如UID 1000显示为"john")。进程PCB中存储的是UID数字。 - PRI:进程当前优先级。
- NI:Nice值。
其他字段如PID(进程ID)、PPID(父进程ID)、TTY(终端)、TIME(累计CPU时间)、COMMAND(命令行)等不再赘述。
3.3 PRI与NI的关系
PRI是可见的优先级数值 ,范围60~99,数字越小优先级越高 (就像考试排名,第1名优于第100名)。但用户无法直接修改PRI,只能通过修改NI值(Nice值) 来间接改变优先级,因此Nice值被称为"优先级的修正数据"。
优先级的计算规则为:
PRI = PRI(old) + nice关键在于:PRI(old)是一个常数,默认为80。它不是"上一次计算后的优先级",而是一个固定基准。这样设计的目的是:每次修改优先级时无需查询当前值再叠加计算,直接从常数80出发加上新的Nice值即可得到新PRI,让设置更直接。
例如:
- Nice值设为0 → PRI = 80 + 0 = 80
- Nice值设为10 → PRI = 80 + 10 = 90 (优先级降低)
- Nice值设为-10 → PRI = 80 + (-10) = 70 (优先级升高)
3.4 修改优先级的方法
共有四种常用方式:
方法一:top命令交互修改
- 运行
top - 按
r键(代表renice) - 输入目标进程的PID
- 输入新的Nice值(范围-20~19)
- 按回车生效,退出top后用
ps -al验证。
注意:普通用户频繁修改优先级可能被拒绝(Permission denied),因为分时系统力求公平,不允许个人大幅干扰调度。此时可切换至root用户操作。
方法二:renice命令修改已运行进程
bash
renice <nice值> -p <PID>例如 renice -5 -p 26196 将PID为26196的进程Nice值改为-5。
方法三:nice命令启动时指定
bash
nice -n <nice值> <命令>例如 nice -n -10 ./myproc,该进程一启动便具有较高优先级(PRI=70)。
方法四:系统调用
在代码中使用 getpriority() 和 setpriority(),需包含 <sys/resource.h>。
3.5 Nice值的取值范围与优先级的40级
为防止用户无限提高或降低自身进程的优先级,破坏公平,Nice值的调整被限制在 -20 到 19 之间。尝试设为此范围之外的值会被内核强制截断(如设-100实际变为-20,设1000变为19)。
我们来计算一下共有多少级:
- 从-20到0(不包括0):-20, -19, ..., -1 共20个数字。
- 从0到19(包括0):0, 1, 2, ..., 19 共20个数字。
- 总计:20 + 20 = 40个级别。
由于PRI = 80 + nice,因此优先级的范围即为:
- 最低nice=-20 → PRI = 80 - 20 = 60
- 最高nice=19 → PRI = 80 + 19 = 99
- 范围:60~99,也是40个级别。计算数量:99 - 60 + 1 = 40。
这40级构成了分时调度的基础,后面调度的数据结构与此密切相关。
四、进程的四大特性与并发基础
4.1 竞争性
系统资源有限,多个进程天然存在竞争。为了决定谁胜出,进程必须拥有优先级。在源代码中,PCB一定会包含prio和nice字段来体现竞争排序。
4.2 独立性
每个进程拥有自己的PCB、独立的虚拟地址空间(代码和数据),即使父子进程也通过写时拷贝技术保持数据独立。一个进程崩溃不会影响其他进程,正如画图板挂掉不会导致音乐播放器退出。
4.3 并行与并发
- 并行:在多CPU或多核系统上,多个进程在同一时刻真正同时运行。
- 并发 :在单CPU系统上,通过进程快速切换,在一段时间内让多个进程的代码都得以推进,宏观上看起来同时执行。
4.4 时间片与切换速度
单CPU实现并发的核心机制是时间片 。每个进程被分配一小段CPU运行时间(通常1ms~10ms),时间片在PCB内部是一个计数器(早期内核字段可叫counter)。进程运行中时间片递减,减至0时该进程被剥离CPU,放入队列末尾,调度器选择下一个进程运行。
CPU切换速度极快(微秒级),远超人类感知(几十毫秒)。只要在足够短的时间内(如每隔50ms)进程能再次被调度,用户就觉得它一直在运行。但如果系统进程数量激增,一个进程的两次调度间隔可能拉长到秒级,用户就会感到卡顿。"卡顿"的本质是进程太多导致轮转周期变长。
五、进程切换与硬件上下文
5.1 寄存器保存进程临时数据
当进程在CPU上执行时,CPU内部的众多寄存器保存着该进程的临时数据。例如:
- 通用寄存器 EAX, EBX, ECX, EDX:保存变量值。
- 指令指针 EIP:保存当前执行到哪条指令。
- 栈指针 ESP:保存栈顶位置。
- 状态寄存器 EFLAGS:保存状态标志。
以C语言函数调用为例:
c
int add(int a, int b) {
int c = a + b;
return c;
}
int main() {
int result = add(10, 20);
}a和b的值被加载到寄存器中,计算结果30往往放在EAX中。函数返回时,虽然局部变量c在栈上被释放,但EAX中的30通过mov指令写入result变量。寄存器的内容就是进程当前运行状态的快照。
严格区分:寄存器是硬件存储空间,寄存器内保存的数据才是"硬件上下文" 。就像变量int a是存储空间,a=10中的10是数据。
5.2 硬件上下文的类比:大学生参军档案
一个学生(进程)被征兵(时间片到,切换)时,不能直接离校,必须让导员将其学籍、成绩、专业、宿舍等信息整理成档案(硬件上下文)并封存。当兵两年后回来,凭档案恢复所有信息,继续学业。
这个过程中,保存是为了恢复。如果直接走人,回来时早已被退学(数据丢失);如果回来不恢复档案,就无法回到原来的学习状态。
5.3 进程切换的保存与恢复
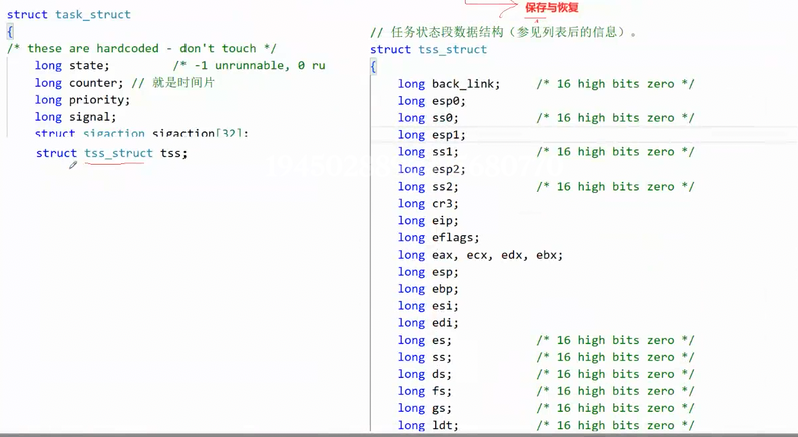
当进程A的时间片用完,切换至进程B时:
- 保存 :将CPU所有寄存器中属于进程A的数据(硬件上下文),全部拷贝到进程A的PCB内。在早期Linux内核中,PCB(
task_struct)中有一个成员struct tss_struct tss,TSS全称 Task State Segment(任务状态段),正是用来存储这些寄存器值的结构体。 - 恢复:从进程B的PCB的TSS中,将其之前保存的寄存器数据,重新加载到CPU的物理寄存器中。
- 继续执行:CPU的EIP指向进程B上次停止的位置,进程B无缝运行。
此后进程B也可能被切走,同样保存自己的硬件上下文。当进程A再次被调度时,再把它的TSS内容恢复到寄存器,如此循环。
现代内核由于task_struct体积过大,TSS已不再直接内嵌,而是通过指针独立管理,但概念完全相同:硬件上下文保存于进程对应的内核数据结构中。
进程B_PCB
进程A_PCB
CPU芯片
进程A运行时
切换时保存
恢复时加载
寄存器 1
寄存器 2
寄存器 ...
进程A的
硬件上下文
进程B的
硬件上下文
寄存器内容 = 进程A的临时数据
六、Linux O(1)调度算法
切换之后,CPU应选择哪个进程执行?这就是调度算法的工作。Linux 2.6内核引入的O(1)调度算法,完美平衡了效率与公平。
6.1 运行队列 runqueue
每个CPU拥有一个运行队列,称为 runqueue(或rq)。所有就绪态进程都挂载在这个队列中。但它绝不是简单的FIFO链表,其内部结构极其精巧。
6.2 优先级数组:140个队列
在runqueue中有一个核心结构:包含140个元素的数组 。每个元素是一个 list_head,即链表的头节点,因此每个元素代表一个队列,该队列存放具有相同优先级的进程。
这140个元素的下标范围0~139,被划分为两段:
- 0~99(100个队列) :提供给实时进程使用。
- 100~139(40个队列) :提供给分时进程(常规进程)使用。
进程的PRI范围为60~99,我们通过简单的映射公式将优先级转换为数组下标:
数组下标 = PRI + 40- PRI=60 → 下标100(最高优先级分时队列)
- PRI=99 → 下标139(最低优先级分时队列)
这正是为什么优先级恰好有40个级别的原因------数据结构本身就预留了40个队列。相同优先级的进程被链入同一下标对应的队列,队列内部遵循FIFO 。这实际上就是一个哈希表,键是优先级,值是进程链表。
6.3 位图 bitmap:O(1)查找的关键
虽然有40个队列,但如果逐个遍历检查是否为空,最坏需要40步,虽然不多但仍有优化空间。为此引入位图。
位图是一个包含5个unsigned int的数组:
c
unsigned int bitmap[5];unsigned int在32位系统中占32个比特位,5个元素共160位。用这160位中的前140位,一一对应140个队列:
- 位的位置(从0开始):对应数组下标。
- 位的值:1表示该队列不空,0表示为空。
如何通过位图快速定位?
假设要检查下标100对应的位:
- 确定位于
bitmap数组的哪个元素:100 / 32 = 3(向下取整),即bitmap[3]。 - 确定在该元素的第几位:
100 % 32 = 4,即第4位(从0计数)。
反过来,调度器查找下一个可运行进程时:
- 从
bitmap[0]开始,若为0,则下标0~31队列全空,跳过。 - 发现第一个非零元素,如
bitmap[3]不为0,则下一个进程必然在32×3=96到127号下标之间。 - 利用CPU的位扫描指令(如
bsfl)找到该整数最低位1的位置,即确定了具体队列下标。 - 整个过程无需遍历链表,仅通过位图操作和一条CPU指令即可完成,时间复杂度常数级。
6.4 单队列的饥饿问题
如果只有这一个140队列,会出现严重的饥饿(starvation) :
假设有多个PRI=60的高优先级进程长期运行,它们时间片耗尽后会被重新放回该队列。调度器每次从下标100开始扫描,永远先找到PRI=60的进程,导致PRI=80、90的低优先级进程永远得不到CPU时间。这与分时系统"公平调度"的目标背道而驰。
6.5 双队列:活跃队列与过期队列
为解决饥饿,runqueue中实际包含两个优先级数组,分别称为:
- 活跃队列(active):CPU当前正在调度的进程集合。
- 过期队列(expired):存放时间片已耗尽的进程。
结构定义概念:
c
struct prio_array {
int nr_active; // 该数组中的进程总数
unsigned int bitmap[5]; // 位图
struct list_head queue[140]; // 140个链表头
};
struct runqueue {
// ...
struct prio_array arrays[2]; // 两个数组实体
struct prio_array *active; // 指向arrays[0]或[1]
struct prio_array *expired; // 指向另一个
// ...
};初始时,active指向arrays[0],expired指向arrays[1]。
调度与队列轮转流程:
-
调度器永远只从active队列中按优先级查找进程执行。
-
当一个进程的时间片用完,它不被放回active ,而是根据其优先级,被插入expired队列的对应优先级链表中。
-
随着调度进行,active队列中的进程逐渐减少,
nr_active递减;expired队列中的进程逐渐增多。 -
当active队列的
nr_active变为0(即全部进程时间片耗尽),触发指针交换 :cswap(active, expired);这一交换极其迅速,仅交换两个指针的指向。原来的expired瞬间成为新的active,新一轮调度开始;原来的active(现为空)成为新的expired,用于接收下一批耗尽时间片的进程。
效果分析:
- 宏观公平:在一个调度周期内(active从满到空),所有进程无论优先级高低都会被调度一次。因为高优先级进程时间片耗尽后也被移入expired,不再参与本轮竞争,从而给低优先级进程机会。
- 微观优先:在周期内,CPU始终优先选择高优先级进程,保证了重要任务的响应速度。
这样,饥饿问题被彻底解决。
6.6 O(1)调度的完整选择逻辑
综合上述结构,调度器选择一个进程的步骤为:
- 通过
active指针定位到当前活跃优先级数组。 - 检查
nr_active计数器;若为0,立即swap(active, expired)。 - 从
active的位图中找到第一个非空队列的下标(通过位图扫描指令)。 - 从该下标的链表头部取出一个进程,将其从链表移除,投入CPU运行。
- 整个过程中,位图扫描为常数时间,取链表头为常数时间,指针交换为常数时间。因此算法整体时间复杂度为 O(1)。
6.7 Nice值存在的深层原因:延迟优先级修改
现在可以揭示为什么优先级不设计成一个可直接修改的整数,而要引入Nice值。假设进程正在运行,如果此时直接修改PRI,必须立即将该进程从当前优先级链表中移除,并插入新优先级链表。这种操作不仅涉及复杂的数据结构变更,还可能发生在调度过程中,需要额外的锁保护,严重影响效率。
通过Nice值,Linux实现了延迟修改:
- 在本调度周期内,进程的PRI保持不变(即使在运行中被
renice),数据结构完全不动。 - 当进程时间片用完,在移入expired队列之前 ,调度器重新计算其优先级:
PRI = 80 + nice。 - 然后根据新PRI将其插入expired队列的相应位置。
如此一来,优先级的修改被推迟到了自然的切换点,避免了运行时对调度数据结构的干扰。这种设计让调度路径保持简洁高效。据传开发者对此设计极为满意,直呼"Nice!",于是便以此命名。
七、分时系统与实时系统
7.1 两种调度模型
我们目前介绍的基于时间片、双队列公平轮转的调度,属于分时操作系统 (Time-Sharing System)。它追求公平,让所有进程都能获得CPU时间。日常的Linux、Windows、macOS均属此类。
但还有一种需求完全不同的系统------实时操作系统 (Real-Time System)。它追求严格的响应时间,要求高优先级任务必须立即执行且一次性完成,不能被轮转打断。典型场景是工业控制、汽车电子、航空航天等。(只使用一个队列)
特斯拉自动驾驶的例子:汽车传感器检测到前方障碍物,操作系统必须立即调度刹车逻辑。如果此时操作系统因为"音乐播放器的时间片还没用完"而延迟刹车,后果不堪设想。因此,实时系统必须保证:刹车任务一旦就绪,就要抢占CPU并执行到底。
7.2 Linux如何统一二者
Linux内核在一套框架中同时支持分时与实时。其秘密就在运行队列的140个优先级中:
- 0~99(100个优先级) :用于实时调度策略 (如
SCHED_FIFO,SCHED_RR)。这部分进程不使用时间片 ,也不参与活跃/过期轮转。当一个实时进程运行时,它只会在更高优先级的实时进程出现时被抢占,或者自己主动放弃CPU。因此单队列结构(不放回)天然实现了"必须执行完"的实时特性。 - 100~139(40个优先级) :用于分时调度策略 (
SCHED_OTHER),即我们前面详述的O(1)调度。
在我们的云服务器或桌面Linux上,默认所有进程都是分时调度,使用100139的优先级。但系统完全具备实时能力,只要通过`sched_setscheduler`系统调用将进程设置为实时策略,并赋予099的优先级,即可获得硬实时响应。
7.3 优先级抢占
现代Linux是抢占式内核。即使分时进程,也允许高优先级进程抢占低优先级进程。例如,PRI=60的进程正在运行,突然一个PRI=58的进程就绪,调度器可以立即挂起当前进程,切换至58的进程。实时模式下抢占更为严格,分时模式结合了抢占与时间片轮转。
八、总结:结构决定算法
今天,我们将进程管理的三个核心模块串联成完整的图景:
- 优先级:PRI = 80 + nice(-20 ~ 19),共40级(60 ~ 99),nice值限制确保了公平基础。
- 进程切换:本质是硬件上下文的保存与恢复,数据保存在进程TSS中,切换由时间片耗尽触发。
- O(1)调度算法 :
- 数据结构:运行队列包含两个140元素优先级数组(active/expired),每个数组配有一个位图。
- 公平调度:active队列耗尽后,与expired交换指针,实现所有进程轮转,杜绝饥饿。
- 效率:位图扫描和链表取头均为常数时间,整体调度O(1)。
- 精巧设计:Nice值延迟修改,避免运行时数据结构抖动。
最终理念:结构决定算法。 你看到什么样的数据结构,大体就能猜到背后的算法是如何运作的。Linux O(1)调度器正是通过精巧的双队列、哈希映射和位图结构,实现了高效且公平的进程调度。这种设计思想不仅限于操作系统,在任务调度、资源分配等广泛工程领域都有深刻的借鉴意义。
经过这次学习,进程不再是一个静态的PCB,而是一个在精密调度算法驱动下,在CPU上不断保存上下文、切换、运行、轮转的动态生命体。