目录
- 整体架构:前后端模块化分离
- 前端三件套:HTML、CSS、JavaScript
- 模块化设计思想
- [HTML 布局核心概念](#HTML 布局核心概念)
-
- 盒子的概念
- [CSS 布局系统](#CSS 布局系统)
- 使用AI提示词的帮助
- [语义化 HTML](#语义化 HTML)
- [HTML 文档与 HTTP 协议](#HTML 文档与 HTTP 协议)
-
- 文档类型
- [HTTP 传输](#HTTP 传输)
- [DOM 编程------ JS操控HTML](#DOM 编程—— JS操控HTML)
-
- [什么是 DOM?](#什么是 DOM?)
- [DOM 树结构](#DOM 树结构)
- [常用 DOM 操作](#常用 DOM 操作)
- [为什么不直接改 HTML,而是用 innerHTML?](#为什么不直接改 HTML,而是用 innerHTML?)
- [后端准备:npm + json-server](#后端准备:npm + json-server)
-
- [JS 的通天能力](#JS 的通天能力)
- [npm 是什么?](#npm 是什么?)
- 初始化后端项目
- 总结:从零到全栈的开发脉络
整体架构:前后端模块化分离
在全栈开发中,核心思想是将前端与后端彻底分开。这种分离带来三大好处:维护更方便、扩展更灵活、优化更精准。
目录结构划分
项目根目录下通常包含两个主文件夹:
fe 目录(前端专注)
- 存放所有与用户界面相关的代码
- 包括 HTML、CSS、JavaScript 文件
- 负责页面的展示和交互逻辑
backend 目录(后端专注)
- 存放所有与数据处理相关的代码
- 包括服务器逻辑、数据库操作、API 接口
- 负责数据的存储、处理和提供
这种划分让前端工程师和后端工程师可以并行工作,互不干扰。
前端三件套:HTML、CSS、JavaScript
过去前端开发被称为"三件套",这三者各司其职,协同工作。
- HTML:结构负责
使用标签来搭建页面的骨架
每一个标签都是一个盒子
负责告诉浏览器"这里应该放什么"
- CSS:样式负责
在 HTML 的头部通过 标签引入
控制颜色、大小、位置、动画等视觉效果
可以使用 CSS 库(如 Twitter 的 Bootstrap 框架)快速搭建美观页面
最佳实践:让 HTML 和 CSS 尽早结合,这样页面能更快地呈现给用户,减少白屏时间。
- JavaScript:行为负责
通过 < script > 标签引入,常用文件名为 common.js
< script > 通常放在html 的body 的最下面,目的是先让页面html全部加载完毕,避免找不到DOM元素报错
(浏览器从上往下解析,先执行 JS,后渲染 HTML,JS 执行时目标标签还不存在,会获取到 null 。)
负责用户交互、数据请求、动态修改页面
让页面"活"起来
模块化设计思想
把所有的代码、功能都塞进一个文件或少数几个文件里,会带来三大痛点:
- 不好维护:修改一处可能影响全局,找 Bug 如同大海捞针
- 不好扩展:想加新功能时,代码互相缠绕,牵一发而动全身
- 不好优化:性能瓶颈难以定位,代码复用率极低
模块化的解决方案
核心原则:每个文件夹有明确的职责划分,每个文件只做一件事(最好是一个类或一个功能模块)。
具体做法:
按功能拆分:header.js、footer.js、sidebar.js
按页面拆分:home.js、profile.js、settings.js
按业务拆分:user.js、product.js、order.js
这样做的好处是:代码清晰、易于调试、多人协作时冲突少。
HTML 布局核心概念
- 默认两类标签
-
块级元素 做盒子
默认占据一行
常见标签:< div>、< p>、< h1>~< h6>、< header>、< footer>
-
行内元素 装内容
可以一行内摆在一起
主要用来装内容(文字、图片、按钮)
常见标签:< span>、< a>、< img>、< strong>
-
盒子的概念
先写盒子,再写内容:这是布局的基本顺序
每个 HTML 元素本质上都是一个矩形盒子
盒子嵌套盒子,形成页面结构
但是!不能滥用盒子,要根据语义写页面结构
语义 化标签
div 可以用来做盒子, 但是一个网页不能一直用div(结构混乱,得不到搜索引擎的推荐)
用header footer aside main来划分一个页面,比div逻辑更强,且比div 更有语义
CSS 布局系统
Container(容器)
作用:中间内容宽度固定,左右自动留白
来源:PC 时代为了适配不同尺寸设备的布局方案
使用AI提示词的帮助
- 想把网页做得美观精致,让AI 用 Bootstrap 现成 CSS 框架就行,不用从零写样式,省事还好看。
- 通过准确的标签描述让网页代码结构规整清晰,用上规范的语义标签,可以让搜索引擎更容易识别收录页面内容,网站曝光和排名也会更有优势。
语义化 HTML
为什么要避免 div 满天飞?
虽然 < div> 是最常用的块级盒子,但如果整个网页全是 < div>,会出现两个问题:
- 结构混乱:看代码的人分不清哪个是头部、哪个是主体、哪个是底部
- SEO 不友好:搜索引擎爬虫无法理解页面结构,降低推荐权重
语义化标签列表
比 < div> 更具语义的标签:
< header>:页面或区块的头部
< footer>:页面或区块的底部
< main>:页面主体内容(一个页面只有一个)
< aside>:侧边栏内容
< nav>:导航链接区域
< article>:独立的文章内容
< section>:文档中的章节
main 里面包含aside 侧边栏 和 article 文章内容
一个页面由上到下:header->nav->main->footer
表格的语义化
表格不仅仅是 < table> 加一堆 < td>,正确的语义化写法是:
bash
<table class="table table-bordered">
<!-- 表格头部:放标题 -->
<thead>
<tr>
<td>序号</td>
<td>姓名</td>
</tr>
</thead>
<!-- 表格身体:放真实数据 -->
<tbody>
<tr>
<td>1</td>
<td>张三</td>
</tr>
<tr>
<td>2</td>
<td>李四</td>
</tr>
<tr>
<td>3</td>
<td>王五</td>
</tr>
</tbody>
</table>table ------ 表格容器标签
thead ------ 定义表格的头部内容 里面有一行
tbody ------ 定义表格的主体内容
tr ------ 行标签 一行里面有n个 td
td ------ 单元格标签
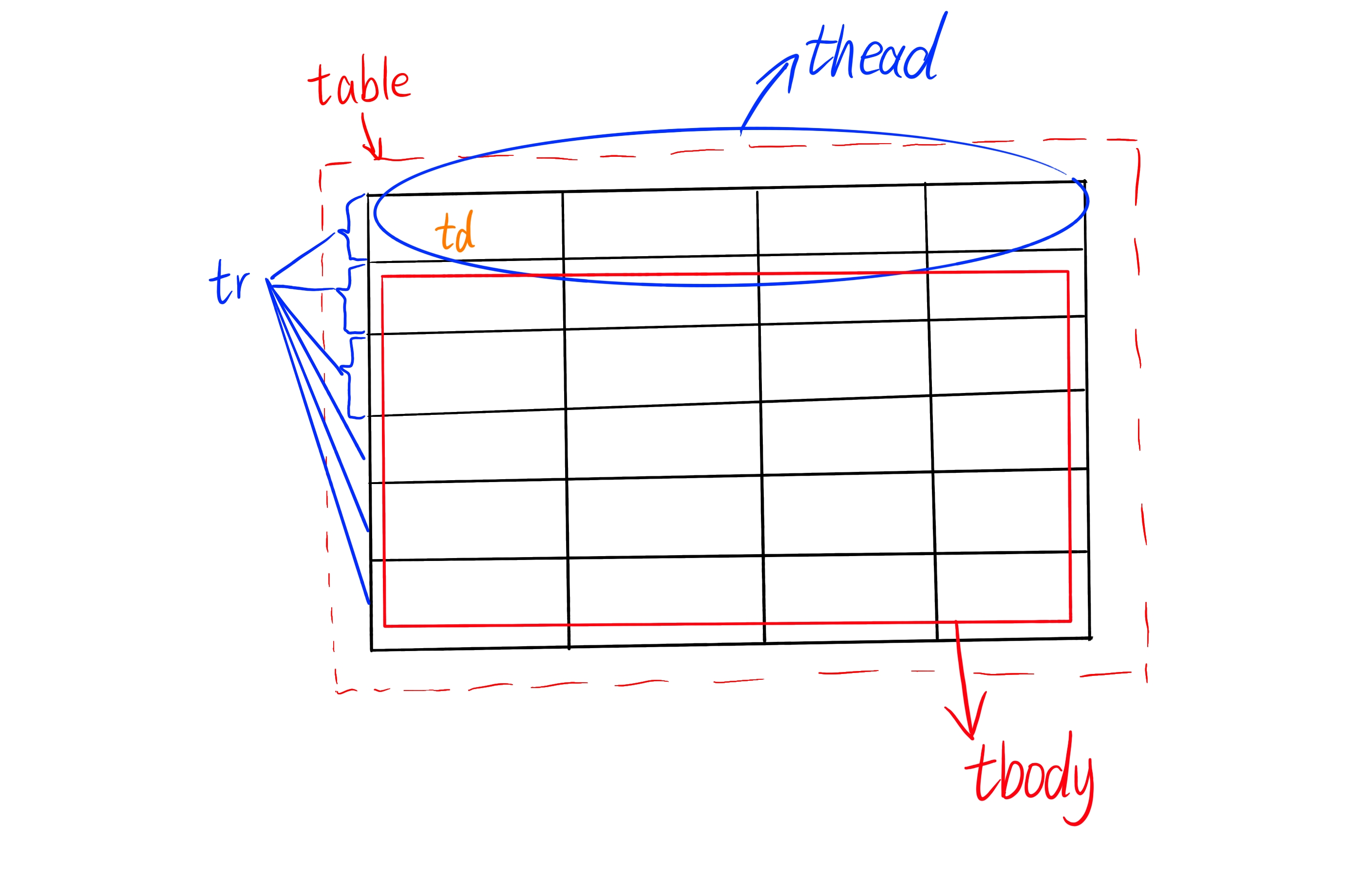
为什么要区分 thead 和 tbody?
让浏览器和搜索引擎知道:thead 里的内容是列标题,tbody 里才是数据
便于实现复杂功能:如固定表头、滚动表体、分页处理等
HTML 文档与 HTTP 协议
文档类型
HTML 文档本质上是文本,但有不同的文本类型:
text/plain:纯文本,浏览器直接显示字符
text/html:HTML 标签文本,浏览器会解析成网页
DOCTYPE 声明:
xml
< !DOCTYPE html>! 表示这是 HTML5 最新版本,区别于旧版本(如 HTML4),让浏览器用标准模式渲染**
HTTP 传输
HTML 文档通过 HTTP (超文本传输协议)从服务器传输到浏览器 ,浏览器将其解析成 Document 对象。
DOM 编程------ JS操控HTML
什么是 DOM?
DOM(Document Object Model,文档对象模型)是浏览器把 HTML 页面转换成的对象树。
核心理解:
HTML 的每一个标签,在 JS 里都变成一个对象JS 可以通过这棵树访问、修改页面上的任何元素
这就是"从静态页面到动态交互"的桥梁
DOM 树结构
xml
document(根对象)
└── document.documentElement(html 标签)
└── document.body(body 标签)
├── header(对象)
├── main(对象)
└── footer(对象)例如一个HTML标签
bash
<html>
<body>
<div id="box">hello</div>
</body>
</html>转换成DOM树:
bash
document(根)
└─ html
└─ body
└─ div (id="box", 内容是"hello")常用 DOM 操作
- 选中元素
使用 CSS 选择器来定位页面中的元素。
javascript
// 通过 id 选择单个元素
let box = document.querySelector('#box');
// 通过 class 选择所有匹配的元素(返回 NodeList)
let btns = document.querySelectorAll('.btn');
// 通过标签名选择第一个匹配的元素
let firstP = document.querySelector('p');- 修改内容(核心技能)
通过innerHTML和innerText属性可以动态更新元素内容。
javascript
let box = document.querySelector('#box');
// innerHTML:可以解析并渲染 HTML 标签
box.innerHTML = '<strong>加粗的文字</strong>';
// innerText:仅处理纯文本,标签会被当作普通字符显示
box.innerText = '<strong>会原样显示标签符号</strong>';- 修改样式
通过style属性可以直接修改元素的 CSS 样式。
javascript
box.style.color = 'red';
box.style.backgroundColor = 'black'; // 注意:CSS 属性名使用驼峰命名
box.style.fontSize = '20px';- 添加/删除类名
通过classList可以方便地操作元素的 CSS 类。
javascript
box.classList.add('active'); // 添加一个类
box.classList.remove('hidden'); // 删除一个类
box.classList.toggle('open'); // 切换类(有则删除,无则添加)选择器:document.querySelector()
作用:从 document 对象出发,用选择器查找页面中的 HTML 元素。
语法:
xml
document.querySelector("选择器")选择器规则(与 CSS 完全一致):
- 选 class:.类名(如 .box)
- 选 id:#id名(如 #header)
- 选标签:div、p、button
注意事项:
- 只返回第一个匹配的元素
- 如果页面有多个符合条件的元素,也只拿第一个
- 要拿全部,用 document.querySelectorAll()
修改内容:.innerHTML
作用:获取或修改一个标签内部的所有 HTML 内容(包括文字和子标签)。
获取内容:
bash
let box = document.querySelector('#box');
console.log(box.innerHTML);修改内容(可以写 HTML 标签):
bash
box.innerHTML = '<h1>我是标题</h1>';为什么不直接改 HTML,而是用 innerHTML?
| 方式 | 特点 | 适用场景 |
|---|---|---|
| 静态 HTML | 写死内容,需要刷新页面才能更新 | 固定不变的页面 |
| innerHTML 动态渲染 | JS 实时修改,无需刷新 | 所有交互功能 |
实际应用:
- 点击按钮后显示新内容
- 下拉加载更多列表
- 表单提交后显示结果
- 所有你看到的动态变化,底层都是 DOM 操作
后端准备:npm + json-server
JS 的通天能力
JavaScript 已经不局限于前端:
前端:操作 DOM、处理交互、发送请求
后端:用 Node.js 运行在服务器上
AI:TensorFlow.js、机器学习库
npm 是什么?
npm(Node Package Manager)是 Node.js 的包管理器,可以将其理解为 JavaScript 生态的"应用商店",专门用于下载和管理代码库(包)。
npm 主要承担三个核心角色:
1. 下载工具
通过 npm install 包名(简写为 npm i 包名)命令,可以一键下载社区中他人编写好的代码库,无需手动查找和复制文件。
2. 项目管家
npm 会生成并维护 package.json 文件,该文件记录了项目所安装的所有依赖及其版本信息 。当团队协作或环境迁移时,只需运行 npm install 即可自动还原完整的开发环境,有效解决了"在我电脑上能运行,在你电脑上却不行"的环境依赖问题。
3. 脚本运行器
你可以在 package.json 中配置自定义脚本命令,例如:
npm run serve:启动开发服务器npm start:启动项目npm test:运行测试
通过简单的命令即可触发复杂的构建、测试或部署流程,极大提升了开发效率。
初始化后端项目
第一步:生成配置文件
在终端中执行以下命令:
bash
# 进入你的后端目录
cd backend
npm init -ynpm init:初始化一个 Node.js 项目,生成package.json文件(项目配置文件)。-y:全称为--yes,表示全部采用默认配置,跳过交互式问答。
第二步:安装 json-server
执行安装命令:
bash
npm i json-serveri是install的缩写。- 该命令会在当前项目中安装 json-server,这是一个用于快速搭建模拟后端服务器的工具。
第三步:创建模拟数据库
在项目根目录下创建一个名为 db.json 的文件,用于存储模拟数据。该文件遵循 JSON 格式,其结构决定了后端 API 的资源和路由。
json
{
"users": [
{ "id": 1, "name": "张三", "age": 25 },
{ "id": 2, "name": "李四", "age": 30 }
],
"posts": [
{ "id": 1, "title": "第一篇文章", "userId": 1 }
]
}第四步:配置并启动服务器
打开 package.json 文件,在 scripts 字段中添加一个启动命令:
json
{
"scripts": {
"start": "json-server --watch db.json --port 3000"
}
}--watch db.json:监听db.json文件的改动,数据变化时 API 会自动更新。--port 3000:指定服务器运行在 3000 端口。
配置完成后,在终端运行以下命令启动服务器:
bash
npm run start第五步:访问 API 接口
服务器启动成功后,打开浏览器,访问 http://localhost:3000/users,你将看到以下 JSON 格式的响应数据:
json
[
{ "id": 1, "name": "张三", "age": 25 },
{ "id": 2, "name": "李四", "age": 30 }
]至此,一个具备完整 RESTful API 功能的模拟后端服务就搭建完成了!
总结:从零到全栈的开发脉络
- 前后端分离 :
fe目录负责界面,backend目录处理数据。 - 前端三件套:HTML 搭建结构,CSS 美化样式,JavaScript 实现交互。
- 模块化设计:每个文件夹职责明确,每个文件功能单一。
- 布局核心:遵循"先盒子后内容"的原则,利用容器、行、列构建响应式布局。
- 语义化 HTML :使用
header、footer、main等语义标签替代泛滥的div,并用thead/tbody优化表格结构。 - DOM 编程 :浏览器将 HTML 转换为对象树(DOM),通过
querySelector选择元素,使用innerHTML动态修改内容。 - 后端环境:使用 npm 管理依赖,借助 json-server 快速搭建模拟 API 服务。
这条学习路径从构建静态页面开始,逐步深入到动态交互,最终实现后端数据服务,完整勾勒出了 AI 时代全栈开发的核心能力图谱。