我刚学Git那会,一直有个超级大的疑惑憋在心里:为什么保存代码非要分 git add 和 git commit 两步?
当时网上教程清一色直接甩命令,我照着敲了无数次,只会机械复制粘贴,完全不懂底层逻辑。自己本地瞎写代码还好,一到多人协作项目,立马翻车:要么文件没提交上,要么版本乱套,要么改了一堆东西,回头想撤回根本无从下手。
直到我沉下心,从零梳理了Git的基础设计逻辑,跑完一遍完整流程、踩完所有新手坑,才算真正搞懂------这两步命令根本不是多余的,是Git最核心的设计精髓。
今天就用我自己的学习复盘,把这套最基础、但最重要的Git工作流掰碎了讲清楚。
先说说:没有Git之前,我们写代码有多狼狈
大家可以回想一下,初学写代码的时候,没有版本控制工具,我们都是怎么存代码的?
我以前最经典的操作:项目文件夹复制粘贴,重命名「项目v1」「项目v2」「修复bug最终版」「最终版绝对不改了」......
说实话,这种纯本地存文件的方式,就是单机版本管理,漏洞多到离谱:
第一,风险极高,电脑硬盘一坏、文件夹误删,所有代码直接清零,找不到任何历史修改记录;
第二,完全没法团队协作,几个人同时改一个项目,传文件、发压缩包,代码重复、覆盖、丢失是常态;
第三,极其不工程化,你改了什么、什么时候改的、为什么改,完全没有记录,后续复盘、迭代根本无从谈起。
而Git的出现,就是为了解决这些问题。它最核心的身份是分布式版本控制系统。
这里用个大白话类比:传统单机代码,相当于每个人手里只有一份专属草稿;而Git分布式,是团队每个人的电脑上,都存着一整套完整的项目仓库,同时还有GitHub/Gitee这类远程中央仓库做同步,所有人的修改都能有序汇总、追溯,再也不会乱套。
Git最核心的概念:版本快照
很多新手搞不懂版本控制,本质是没理解「版本」是什么。
我之前一直以为:版本就是记录每一行代码的改动差异。后来才发现我完全理解错了!
Git的版本,是项目某一时刻的完整快照。
就像你手机拍照,按下快门的一瞬间,定格了画面所有内容。每一次 commit 提交,就是给我们的整个项目拍了一张完整的快照,Git会把这张快照保存下来,后续不管是回退、对比、查看历史,都是基于这一张张快照来操作的。
从零搭建本地Git仓库,实操走一遍
想要让普通文件夹拥有版本控制能力,第一步永远是 git init,这也是我学Git敲的第一个正经命令。
1. git init:普通文件夹变身代码仓库
在你的项目根目录打开Git Bash,执行初始化命令:
csharp
git init执行完你会发现,目录里多了一个 .git 隐藏文件夹。
新手最大的坑:绝对不要手动修改/删除.git文件夹!
这个文件夹是整个仓库的核心,所有版本记录、修改日志、关联远程仓库的信息全在这里。我之前手贱点开改了个配置,直接把整个仓库搞废,所有版本记录全部丢失,血的教训。
这个命令的本质就是:把当前普通项目目录,升级为拥有完整版本控制能力的Git本地仓库。
如果想看隐藏的.git文件夹,可以执行:
bash
ls -all
2. git add:把改动放进暂存区
项目写完文件后,第一步不是直接提交,而是执行 git add。
比如我新建了一个 readme.md 文档,想要纳入版本控制,就执行:
csharp
git add readme.md
很多人包括我当初都疑惑:为什么不能直接提交,非要多一步暂存?
后来实操多了才懂,暂存区(stage)是Git超人性化的设计!
我们开发一个功能,往往会改很多文件:index.html页面、common.css样式、common.js脚本。如果没有暂存区,改一个文件就要提交一次,版本会碎得一塌糊涂。
而有了暂存区,我们可以:
csharp
# 多次add,汇总所有功能修改
git add index.html
git add common.css
git add common.js多次add的操作,只会把文件暂时放到暂存区,不会生成新的版本。相当于你先把所有修改的零件,全部放到一个临时篮子里,等一个功能完整开发完,再统一打包。
而且这个阶段还能「后悔」,如果某个文件改废了,还能从暂存区撤下来,不会影响仓库版本。
如果您只是想把文件从暂存区取出,保留文件中的代码修改(以便重新编辑),请使用:
bash
git reset HEAD index.html如果您误将不该追踪的文件(如编译生成的文件、日志等)加入暂存区,且希望 Git 彻底忽略 它: 文件变为 untracked 状态。这仅解除版本追踪,不会删除本地硬盘上的物理文件。
bash
git rm --cached readme.md如果你已经 git add 了文件,但想把它从暂存区拿出来(即笔记中提到的"提前后悔一下"),但不想丢弃代码修改:
css
git restore --staged index.html
3. git commit:打包生成正式版本快照
等所有相关文件都add到暂存区,功能开发完成,就可以执行提交命令,生成正式版本:
sql
git commit -m '完成首页页面整体功能'这里重点说下 -m 备注参数,我新手期最敷衍,经常写「修改bug」「更新代码」这种废话。
后来参与团队项目才知道,commit备注是团队协作的核心!leader复盘代码、同事追溯修改、自己后续回退版本,全靠这段备注。备注一定要精准描述本次改动内容,绝对不能乱写。
执行成功后,控制台会提示类似 2 insertions 的信息,代表本次提交新增了2行代码,这就是Git严谨的版本记录。

误 Commit 后的补救
如果已经将文件 commit 到了本地仓库才发现错误:撤销最近一次提交,将文件状态回退到暂存区,供您重新整理。
css
git reset --soft HEAD~1进阶------推送到远程仓库
前置工作:创建一个git远程仓库
执行三条命令,让本地连接远程仓库
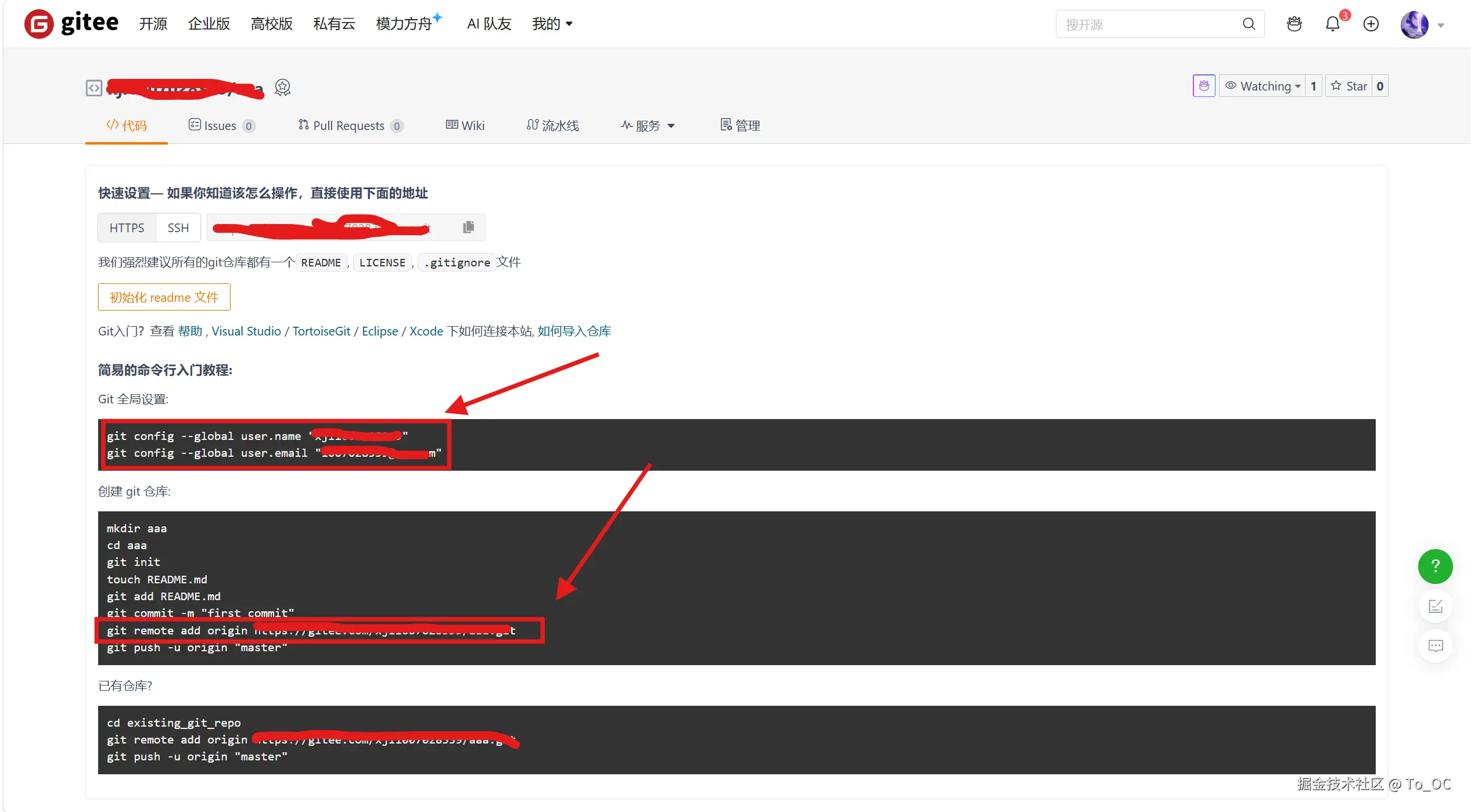
git push:推送到远程
提交之后就可以推送到远程了,和团队的其他队友一起协作
perl
git push -u origin "master"我最常用的保命命令:git status
这里必须安利一个新手一定要养成的习惯:任何关键操作前,先敲 git status。
lua
git status这个命令就是帮你看清当前仓库的所有状态,杜绝盲目操作。我之前很多报错,都是因为不看仓库状态,瞎add、瞎commit导致的。
通过git status,我们能清晰看到文件的三种核心状态,这也是Git的基础核心:
- untracked 未跟踪:新建的文件,Git还没接管,不受版本控制
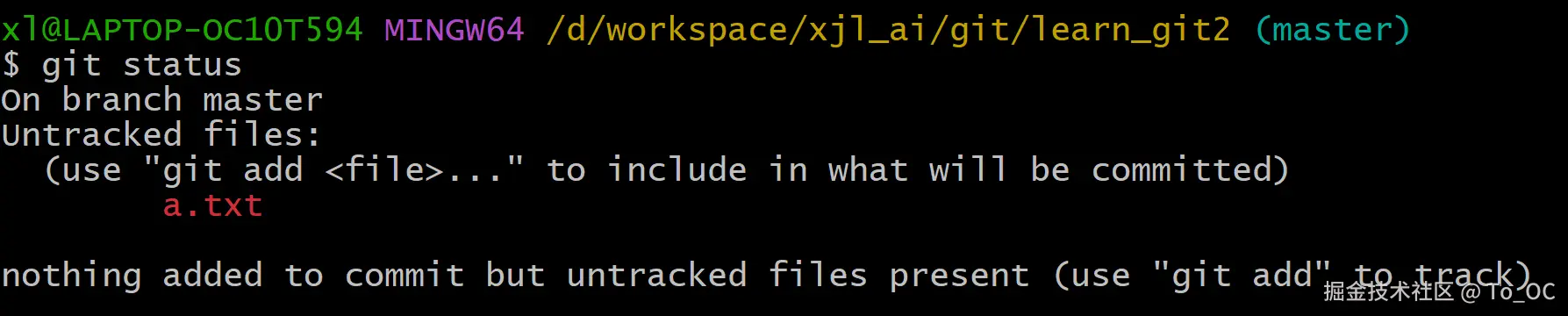
- to be committed 待提交:已经执行add,文件在暂存区,等待commit生成版本

- 已提交:完成commit,成功存入本地仓库,生成正式快照
正规的开发逻辑一定是:多次add汇总修改,一次commit完成一个开发任务,全程保证最终仓库是干净、整洁的,没有残留的暂存文件、未跟踪文件。
新手高频踩坑总结(我全中过)
梳理完完整流程,复盘下我初学的时候踩的所有低级坑,大家直接避开就行:
坑1:手动修改.git隐藏文件夹
以为是普通配置文件,随便改动,直接导致仓库损坏,版本记录丢失。
正确姿势:永远不要手动操作.git文件夹,所有修改全部用Git命令完成。
坑2:commit备注敷衍乱写
无意义的备注,后续根本分不清每一次版本改了什么,项目迭代越久越乱。
正确姿势:备注精准对应功能改动,做到见字知意。
坑3:不看git status盲目操作
不知道文件处于什么状态,重复add、重复提交,导致仓库冗余杂乱。
正确姿势:每次add、commit前后,都用status确认状态。
坑4:一个文件一次commit
不会用暂存区汇总修改,把一个完整功能拆成无数个小版本,版本日志极其混乱。
最后聊聊分支:团队协作的基础
基础流程跑通后,就不得不提git branch 分支命令,这是多人协作的入门关键。
git branch执行这个命令可以查看当前项目的所有分支。简单来说,分支就是给项目开一条「独立开发线」,大家在各自的分支上开发功能,互不干扰,开发完成后再合并到主分支。
如果说前面的add/commit是单人开发的基础,那分支管理就是团队协作的核心,后续我再单独出一篇分支实战和合并踩坑的复盘。
我的三点核心学习收获
折腾完这一遍,彻底摆脱了「只会敲命令不懂原理」的状态,总结三个最关键的心得:
-
Git两步命令是分工明确的:add是汇总修改(临时存放),commit是固化版本(永久存档),暂存区的设计是为了让版本迭代更规整。
-
版本的本质是快照,不是代码差异,这也是Git回退、合并功能能精准实现的根本原因。
-
规范比会敲命令更重要:干净的仓库状态、清晰的commit备注,是后续团队协作、项目维护的关键。
另外也说句实话,Git基础工作流不是万能的,简单的个人小项目、一次性Demo,完全没必要上Git,反而多此一举。但只要是需要迭代、需要多人协作、需要长期维护的项目,Git就是必备技能,没有替代方案。
这次先把最基础的本地工作流捋清楚了,下一篇再讲远程仓库关联、分支合并、冲突解决这些高频场景。
如果你之前也一直死记Git命令、不懂底层逻辑,看完这篇有没有豁然开朗?欢迎评论区聊聊你初学Git踩过的坑,互相避坑!