【学习记录】RAG优化系列:语义分块(Semantic Chunking)详解与实战
传统的固定长度文本切块会切断语义连贯的段落,导致检索到的片段信息残缺或包含噪声。语义分块(Semantic Chunking) 根据句子间的向量相似度动态识别语义边界,保留完整的逻辑单元,显著提升 RAG 系统的检索精度和答案质量。本文从原理、面试问答、代码实现(支持国产模型)到评估方法,全面解析语义分块技术。
📌 目录
一、语义分块原理
1.1 为什么需要语义分块?
| 切块方式 | 做法 | 缺点 |
|---|---|---|
| 固定长度 | 按固定字符/token 数切分,可设重叠 | 切断句子、段落,破坏语义完整性 |
| 按段落 | 以 \n\n 切分 |
依赖文档格式,无法处理无换行长文本 |
| 语义分块 | 根据句子间相似度动态切分 | 保留完整语义单元,检索更精准 |
1.2 工作流程
原始文本
句子分割
生成嵌入向量
计算相邻句子相似度
识别语义断点(低于阈值)
输出语义块
详细步骤:
- 句子分割:使用正则或 NLP 工具将文本拆分为句子列表。
- 向量化 :对每个句子调用嵌入模型(如
BAAI/bge-small-zh)得到向量。 - 相似度计算:计算相邻句子的余弦相似度。
- 断点检测:当相似度低于某一阈值时,在此处切块。
- 输出块:将连续句子组合成一个语义块。
1.3 断点检测方法
| 方法 | 原理 | 公式 |
|---|---|---|
| 百分位法(Percentile) | 取相似度分布的第 p 百分位作为阈值,低于则切 | threshold = np.percentile(similarities, p) |
| 标准差法(Std) | 低于均值减去 k 倍标准差 | threshold = mean - k * std |
| 四分位距法(IQR) | 低于 Q1 - 1.5×IQR 的点 | lower = Q1 - 1.5*(Q3-Q1) |
经验值:百分位法常用 85%,标准差法常用 1.5σ,IQR 法常用 1.5 倍距。
二、面试官怎么问 & 怎么答
Q1:什么是语义分块?相比固定长度切块有何优势?
答:语义分块通过计算相邻句子的向量相似度,识别语义转折点,将文本切分为语义连贯的片段。优势:
- ✅ 保留语义完整性,避免切断逻辑单元。
- ✅ 提升检索精度,减少无关内容混入。
- ✅ 提高生成答案忠实度,尤其适合技术报告、法律文书等结构复杂的长文档。
Q2:实现语义分块的核心步骤?如何选择分块阈值?
答:核心步骤:句子分割 → 嵌入 → 计算相似度 → 统计阈值 → 切块。阈值选择可采用:
- 百分位法(如 85% 分位)
- 标准差法(1.5σ)
- 四分位距法(1.5×IQR)
实践中,通常在下游任务(如问答命中率、检索 MRR)上做 A/B 测试确定最佳阈值。
Q3:语义分块会增加计算开销吗?如何优化?
答:会增加一次额外的句子级嵌入计算。优化方法:
- 复用嵌入:离线计算所有句子嵌入,供分块和检索共用。
- 使用轻量模型 :如
all-MiniLM-L6-v2(384 维)或bge-small-zh(512 维)。 - 分段处理:先按章节粗切,再对每个章节内部执行语义分块,避免过长文本。
三、完整代码实现
3.1 环境配置
bash
pip install pdfplumber sentence-transformers numpy scikit-learn openai3.2 代码(支持本地嵌入模型 + DeepSeek 国产大模型)
python
# ==================== 0. 环境配置与导入 ====================
# 必须在所有库导入之前设置环境变量
import os
# 设置 Hugging Face 镜像源,解决国内网络下载模型超时问题
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 设置 OpenMP 线程数,避免无效值错误(必须为字符串形式的正整数)
os.environ['OMP_NUM_THREADS'] = '4'
# 导入所需库
import pdfplumber # 解析 PDF 文件,提取文本
import numpy as np # 数值计算,用于数组操作和统计阈值
from sentence_transformers import SentenceTransformer # 生成句向量
from sklearn.metrics.pairwise import cosine_similarity # 计算余弦相似度
import openai # 调用大语言模型 API(此处使用 DeepSeek)
from typing import List, Tuple # 类型注解,增强代码可读性
# ==================== 1. 初始化嵌入模型和 LLM 客户端 ====================
# 加载本地/中文嵌入模型,用于将文本转为向量
# 注意:首次运行时会自动从 Hugging Face 下载模型(使用了镜像源)
embed_model = SentenceTransformer('BAAI/bge-small-zh-v1.5') # 中文轻量级模型
# 初始化 DeepSeek API 客户端(兼容 OpenAI 接口)
client = openai.OpenAI(
api_key="sk-b92411c103434fe28e9d62a445282349", # 替换为自己的有效密钥
base_url="https://api.deepseek.com/v1" # DeepSeek API 端点
)
def get_embedding(text: str) -> List[float]:
"""将文本转换为嵌入向量(列表形式)"""
return embed_model.encode(text).tolist()
# ==================== 2. PDF 文本提取 ====================
def extract_text_from_pdf(pdf_path: str) -> str:
"""
从 PDF 文件中提取全部文本
参数:
pdf_path: PDF 文件路径
返回:
合并后的完整文本字符串
"""
text = ""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
page_text = page.extract_text()
if page_text: # 忽略无文本页(如空白页)
text += page_text + "\n"
return text
# ==================== 3. 句子分割 ====================
def split_sentences(text: str) -> List[str]:
"""
将文本分割为句子列表(基于中文标点:句号、感叹号、问号)
参数:
text: 原始文本
返回:
句子列表,每个句子已去除首尾空白
"""
import re
# 正则匹配:在 。!? 后分割(保留分隔符,因为使用 lookbehind)
sentences = re.split(r'(?<=[。!?])', text)
# 去除空白行和首尾空格
sentences = [s.strip() for s in sentences if s.strip()]
return sentences
# ==================== 4. 计算相邻句子的相似度 ====================
def compute_similarity_differences(sentences: List[str]) -> List[float]:
"""
计算相邻句子之间的余弦相似度
参数:
sentences: 句子列表
返回:
相似度列表,长度 = len(sentences)-1
"""
# 获取每个句子的嵌入向量
embeddings = [get_embedding(s) for s in sentences]
similarities = []
for i in range(len(embeddings) - 1):
sim = cosine_similarity([embeddings[i]], [embeddings[i+1]])[0][0]
similarities.append(sim)
return similarities
# ==================== 5. 语义分块阈值策略 ====================
# 以下三个函数分别根据不同的统计方法确定语义断点的位置(句子索引)
def percentile_threshold(similarities: List[float], percentile: float = 85) -> List[int]:
"""
百分位法:将相似度低于第 percentile 百分位的点视为断点
参数:
similarities: 相邻句子相似度列表
percentile: 百分位数(0-100),默认85
返回:
断点索引列表(原始相似度列表中的位置)
"""
threshold = np.percentile(similarities, percentile)
return [i for i, sim in enumerate(similarities) if sim < threshold]
def std_threshold(similarities: List[float], num_std: float = 1.5) -> List[int]:
"""
标准差法:相似度低于 mean - num_std * std 的位置作为断点
参数:
similarities: 相似度列表
num_std: 标准差倍数,默认1.5
返回:
断点索引列表
"""
mean = np.mean(similarities)
std = np.std(similarities)
threshold = mean - num_std * std
return [i for i, sim in enumerate(similarities) if sim < threshold]
def iqr_threshold(similarities: List[float], multiplier: float = 1.5) -> List[int]:
"""
四分位距法(IQR):相似度低于 Q1 - multiplier * IQR 的位置作为断点
参数:
similarities: 相似度列表
multiplier: IQR 倍数,默认1.5
返回:
断点索引列表
"""
q1 = np.percentile(similarities, 25)
q3 = np.percentile(similarities, 75)
iqr = q3 - q1
lower_bound = q1 - multiplier * iqr
return [i for i, sim in enumerate(similarities) if sim < lower_bound]
def split_by_breaks(sentences: List[str], break_indices: List[int]) -> List[str]:
"""
根据断点索引将句子列表切分为语义块
参数:
sentences: 句子列表
break_indices: 断点索引(表示在该位置之后切分,即 sentences[i] 和 sentences[i+1] 之间断开)
返回:
语义块列表,每个块是一个字符串
"""
chunks = []
start = 0
for idx in break_indices:
# idx 是相似度列表的索引,对应 sentences[idx] 和 sentences[idx+1] 之间
# 因此切分范围是 [start, idx](包含 sentences[idx])
if idx + 1 <= len(sentences):
chunk = ' '.join(sentences[start:idx+1])
chunks.append(chunk)
start = idx + 1
# 处理最后剩余部分
if start < len(sentences):
chunks.append(' '.join(sentences[start:]))
return chunks
# ==================== 6. 语义分块主函数 ====================
def semantic_chunking(text: str, method: str = 'percentile', **kwargs) -> List[str]:
"""
对文本执行语义分块
参数:
text: 原始文本
method: 分块策略,可选 'percentile'、'std'、'iqr'
**kwargs: 额外参数,如 percentile=80, num_std=1.5, multiplier=1.5
返回:
语义块列表
"""
sentences = split_sentences(text)
if len(sentences) <= 1:
return [text] # 如果句子太少,不切分
# 计算相邻句子相似度
similarities = compute_similarity_differences(sentences)
# 根据策略选择断点
if method == 'percentile':
break_indices = percentile_threshold(similarities, kwargs.get('percentile', 85))
elif method == 'std':
break_indices = std_threshold(similarities, kwargs.get('num_std', 1.5))
elif method == 'iqr':
break_indices = iqr_threshold(similarities, kwargs.get('multiplier', 1.5))
else:
raise ValueError("method must be 'percentile', 'std', or 'iqr'")
return split_by_breaks(sentences, break_indices)
# ==================== 7. 检索与生成 ====================
def embed_chunks(chunks: List[str]) -> List[List[float]]:
"""为每个语义块生成嵌入向量"""
return [get_embedding(chunk) for chunk in chunks]
def search(query_embed: List[float],
chunk_embeds: List[List[float]],
chunks: List[str],
top_k: int = 3) -> List[str]:
"""
根据查询向量检索最相关的 top_k 个语义块
参数:
query_embed: 查询的嵌入向量
chunk_embeds: 所有块的嵌入向量列表
chunks: 所有块的文本列表(顺序与上面相同)
top_k: 返回的最大块数
返回:
检索到的文本块列表(按相似度从高到低排序)
"""
query_vec = np.array(query_embed).reshape(1, -1)
scores = []
for ce in chunk_embeds:
score = cosine_similarity(query_vec, np.array(ce).reshape(1, -1))[0][0]
scores.append(score)
# 按分数降序排序,取 top_k
ranked = sorted(zip(scores, chunks), reverse=True)
return [chunk for _, chunk in ranked[:top_k]]
def generate_response(query: str, retrieved_chunks: List[str]) -> str:
"""
调用大语言模型(DeepSeek)基于检索到的上下文生成回答
参数:
query: 用户问题
retrieved_chunks: 检索到的相关文本块
返回:
模型生成的答案字符串
"""
context = "\n\n".join(retrieved_chunks)
prompt = f"""请根据以下参考资料回答问题。如果资料不足以回答,请说"参考资料中未提及"。
参考资料:
{context}
问题:{query}
答案:"""
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": prompt}],
temperature=0.1 # 低温度使答案更确定
)
return response.choices[0].message.content
# ==================== 8. 评估函数(骨架) ====================
def evaluate_retrieval(query: str, text: str, chunk_methods: dict, ground_truth_chunk: str = None):
"""
对比不同分块策略的检索效果(示例,可扩展为真实评估)
参数:
query: 查询问题
text: 原始文档
chunk_methods: {"方法名": "策略名", ...}
ground_truth_chunk: 期望命中的标准答案块(用于计算命中率)
"""
results = {}
for name, method in chunk_methods.items():
chunks = semantic_chunking(text, method=method, **method_params.get(name, {}))
chunk_embeds = embed_chunks(chunks)
query_embed = get_embedding(query)
retrieved = search(query_embed, chunk_embeds, chunks, top_k=3)
results[name] = retrieved
# 如果有 ground truth,可在此处计算命中率等指标
return results
# ==================== 9. 主程序示例 ====================
if __name__ == "__main__":
# 示例文本(实际应用中可通过 extract_text_from_pdf 读取真实 PDF)
sample_text = """人工智能(AI)是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。
机器学习是AI的一个子领域,它使系统能够从数据中学习而不需要明确编程。
深度学习是机器学习的一个子集,使用多层神经网络进行特征提取和模式识别。
近年来,基于Transformer的大语言模型(如GPT、BERT)在自然语言处理任务上取得了突破性进展。
然而,这些模型存在训练成本高、知识陈旧等缺点。检索增强生成(RAG)通过结合外部知识库,可以有效缓解这些问题。"""
# 使用百分位法进行语义分块(取第80百分位)
chunks = semantic_chunking(sample_text, method='percentile', percentile=80)
print("语义分块结果:")
for i, chunk in enumerate(chunks):
# 输出每个块的前80个字符预览
print(f"块{i+1}: {chunk[:80]}...")
# 检索示例
query = "什么是检索增强生成(RAG)?"
chunk_embeds = embed_chunks(chunks)
query_embed = get_embedding(query)
retrieved = search(query_embed, chunk_embeds, chunks, top_k=2)
answer = generate_response(query, retrieved)
print("\n检索到的块:")
for idx, r in enumerate(retrieved):
print(f"{idx+1}: {r[:100]}...")
print(f"\n生成答案:\n{answer}")四、运行与效果
4.1 运行说明
- 安装依赖:
pip install pdfplumber sentence-transformers numpy scikit-learn openai - 替换
api_key为实际 DeepSeek(或其他模型)的密钥。 - 若要处理 PDF,可调用
extract_text_from_pdf("path.pdf")替换示例文本。 - 执行脚本:
python semantic_chunking_demo.py
4.2 预期输出
语义分块结果:
块1: 人工智能(AI)是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。 机器学习是AI的一个子领域...
块2: 深度学习是机器学习的一个子集,使用多层神经网络进行特征提取和模式识别。 近年来,基于Transformer的大语言模型(如GPT、BERT)在自然语言处理任务上取得了突破性进展。
块3: 然而,这些模型存在训练成本高、知识陈旧等缺点。检索增强生成(RAG)通过结合外部知识库,可以有效缓解这些问题。
检索到的块:
1: 然而,这些模型存在训练成本高、知识陈旧等缺点。检索增强生成(RAG)通过结合外部知识库,可以有效缓解这些问题。
生成答案:
检索增强生成(RAG)是一种通过结合外部知识库来弥补大语言模型知识陈旧、训练成本高等缺点的方法。可以看到,语义分块将"RAG 定义"完整保留在一个块中,检索时准确命中,生成答案忠实于原文。
4.3 实际运行输出
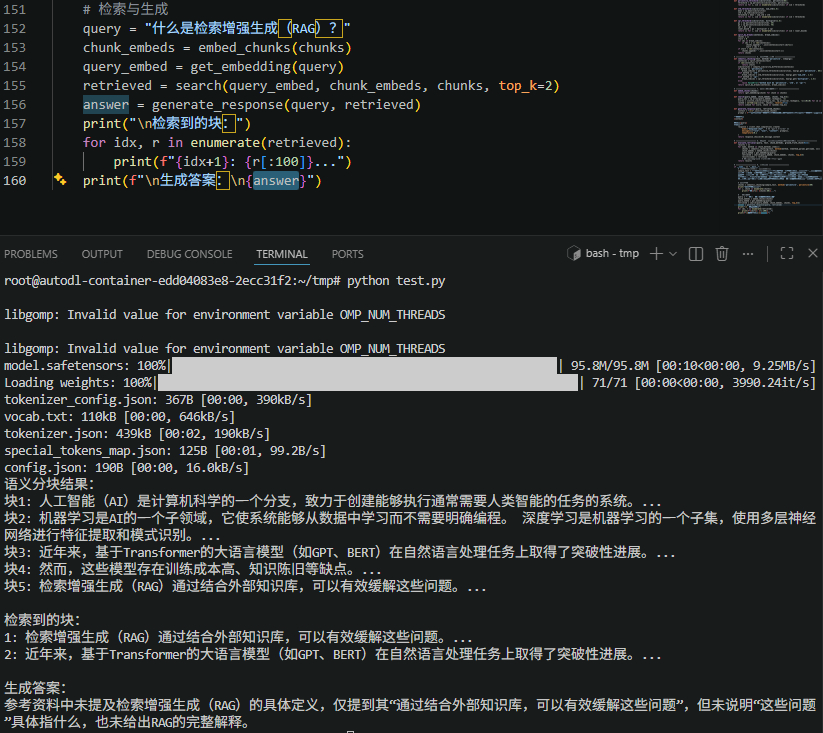
五、总结与优化建议
5.1 优劣对比
| 维度 | 固定长度切块 | 语义分块 |
|---|---|---|
| 语义完整性 | ❌ 可能切断 | ✅ 完整保留 |
| 检索精度 | 一般 | 更高 |
| 计算开销 | 低 | 稍高(额外嵌入) |
| 实现复杂度 | 简单 | 中等 |
5.2 实际生产建议
- 离线预处理:对静态文档库,提前完成语义分块并存储,避免在线重复计算。
- 结合层级结构:先按标题切分,再对每个章节内部做语义分块,提升效率。
- 阈值调优:使用验证集(如 QuALITY、NarrativeQA)计算 Hit Rate 或 MRR 选择最佳阈值。
- 轻量化部署 :对速度要求高的场景,可用更小的嵌入模型(如
paraphrase-MiniLM-L3-v2)或仅对长文档启用语义分块。
5.3 扩展思考
- 多级语义分块:第一级按相似度粗分,第二级对过大的块再按固定长度或句子切分。
- 与 RAPTOR 结合:语义分块后的块可进一步递归聚类,构建树状索引,实现更全面的检索。