怎么用rag构建企业级知识库
以前企业中的知识库,就是用来保存企业中各个部门的资料
这么多文档 企业会作为一个知识库系统,统一的保存起来,但是保存完毕之后怎么做更好的检索 这是一个问题
随着技术的发展,有了es,但是es只能根据关键字进行检索
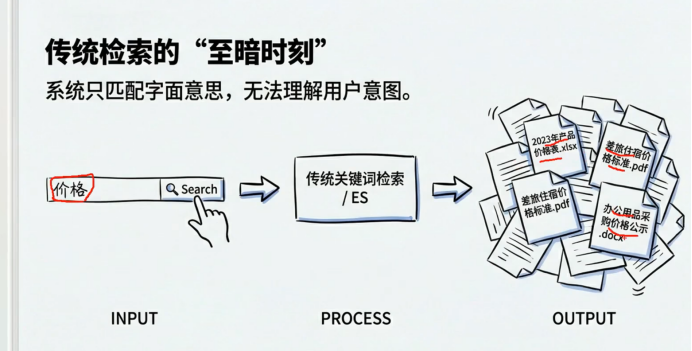
比如说 搜索价格 搜索出来一堆文档
呢我现在比如说 用户嫌弃价格贵 我搜索价格,我要查出这些文档, 我才可以用一个合理的理由解释用户嫌贵的问题
现在我们引入了ai 所谓的检索增强
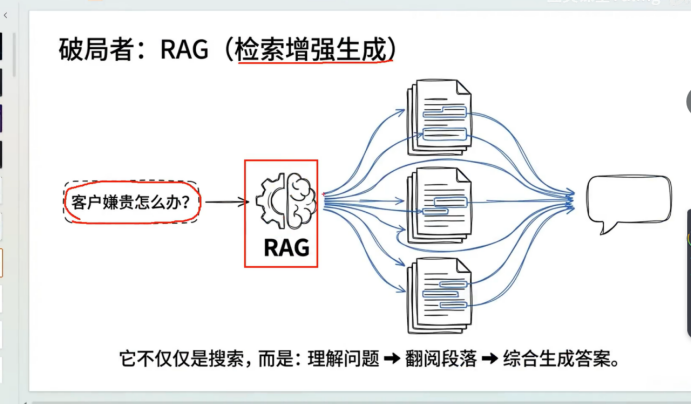
我作为一个销售 我希望ai 帮我们理解这个问题 帮我们检索这些相关文档
最终根据 文档中相似的信息给我生成一个满意的答案
######################>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
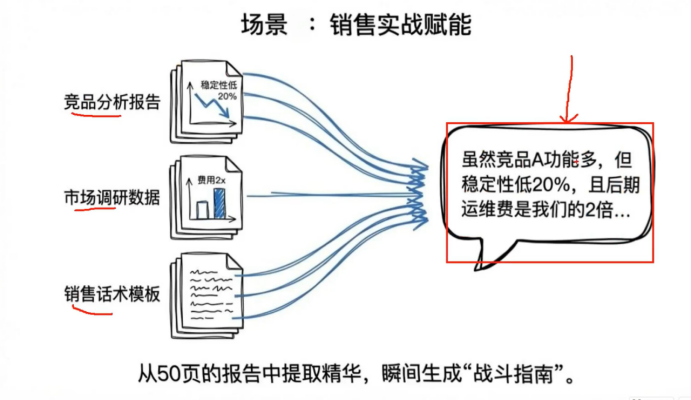
我是一个销售 我根据这些文档总结一个话术 呢他能够可以提供高我的工作效率
并且我们作为开发 如果我接手一个项目 我们如果对这个项目需求不熟悉的话会焦头烂额的
怎么去更改
如果有rag 知识库系统 我们可以根据这个rag去问 比如说xxx系统以前是怎样的 规则是怎样的
通过这些资料 帮我们提供对应的说明
我作为一个新手开发 我就可以通过rag知识库快速的 了解项目的相关东西, 可以说rag 是任何一个公司的ai应用场景
########>>>
比如说用户觉得xxx太贵 rag 是怎么检索到这些相似信息的
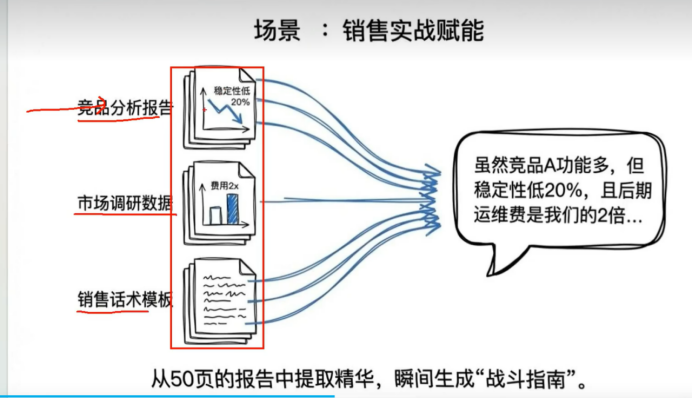
##########<>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
bash
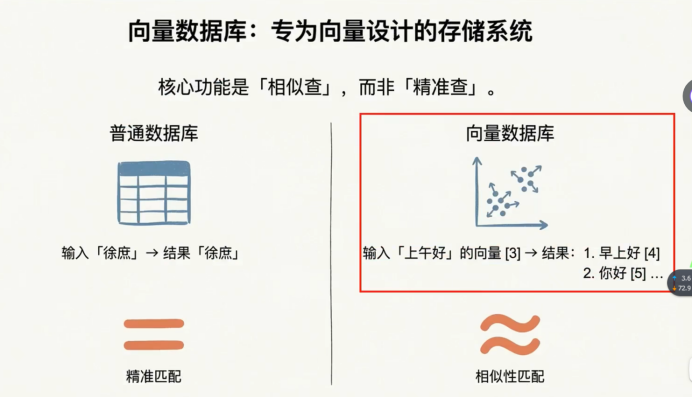
可以使用向量数据库 这里面涉及一个关键的问题,叫做向量数据库
他不像我们关系型数据库一样 用来做精确匹配的
向量数据库是用来做相似度匹配的, 只要语义相似,就可以检索出来
前提是你的要把这些文档信息提前存储在向量数据库中
并不是像以前的关系型数据库一样存储的文本
他存储的是向量
什么是向量, 比如说我存储 早上好 你好这些向量 我就可以通过上午好的向量检索到跟他语义相似的文本
向量就是用来检索相似性
比如说你好, 我通过向量化就可以得到对应的数值坐标
你好--------->5 通过什么才可以将文本编程向量
(向量模型)
这个向量模型和我们LLM 不同, 我们的LLM 是做智能对话的
=============================>>>>>>>>>>>>>>>>>>>>>>>>>>>>
x向量模型 是用来 第一理解文本的语义的,然后把他生成一个向量的数值
向量模型很多 比如说阿里的千问
通过向量模型,我们就可以让他去理解 文本,从而生成一个坐标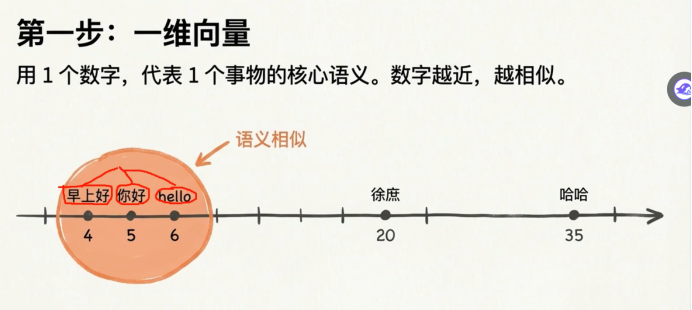
比如说hello 你好,这些从语义上来说是相近的,所以我必须从语义上去理解这些相似的文本
从而去生成一个对应的数值
相似语义的文本, 他们的坐标,就会比较近一些
而语义相似比较大的话,他们的坐标就会比较远一些
我们就的根据向量来检索跟他坐标哎的比较近的, 也就是语义比较近的文本信息
也就是通过向量模型 他会理解语义的意思 然后转化成一个坐标
#########################>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
我们只是举例了一些一维度的坐标
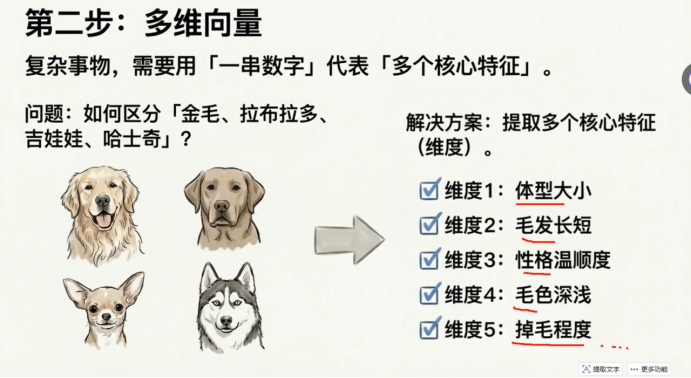
第二步 多维向量
bash
特征越多 相似性检索的精度就会越高 代表检索的精确性越高(多代表多维度) 我们要拆分维度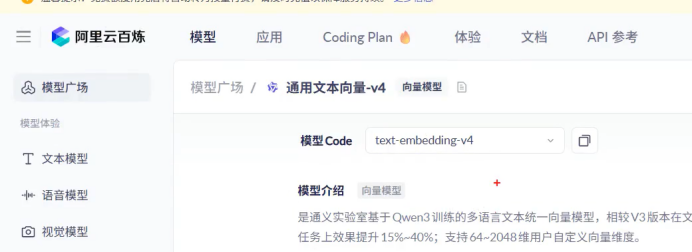
bash
所以我们在选择向量模型的时候 呢种维度太少的模型 不要用
因为性能比较差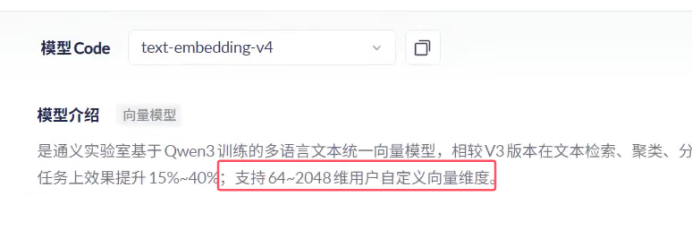
bash
对于一个物品 我们需要维度来提取他的坐标 不管他是多少维
基于这些维度 他是怎么检索到相似性文本的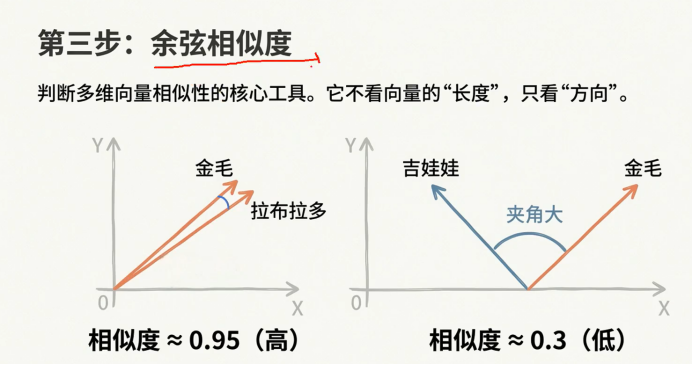
bash
可以进行余弦相似度 这是进行相似度检索的一个算法
比如说两个狗的夹角 夹角越小 代表相似度越高
夹角越大,代表相似度越小
自然这个相似度不需要我们去记忆
向量数据库已经帮我们完成了, 我们只需要放一个向量进去就可以了
他内部会根据各种算法(比如说余弦相似度) 从而检索出来
所以我们需要进行相似度检索,需要3个关键东西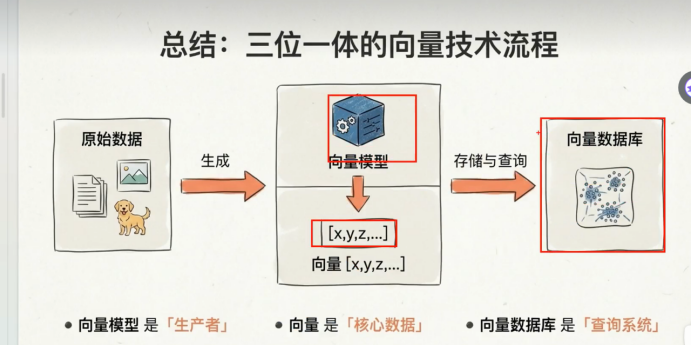
bash
1.向量 2. 向量模型 3, 向量数据库
########################>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>..
呢如果我们要落地到我们的实现 具体要怎么去做
比如说我们现在问 迟到扣多少钱 基础大模型LLM 肯定不知道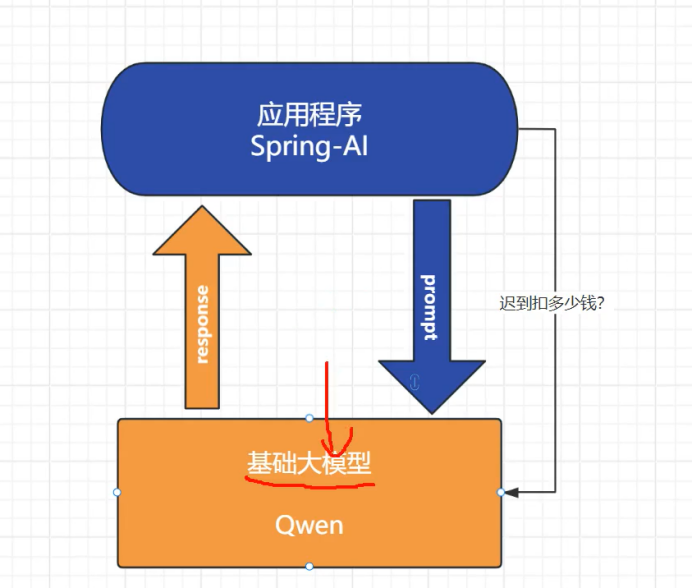
bash
我们现在想要根据我企业中垂直的信息去回答
这个我们就要用到RAG 的相似性检索
所以我们现在要先进性embeding 的数据嵌入阶段, 把我们的资料保存到向量数据库中
比如说有什么 人事手册 企业规章 怎么去保存
我们通常不会把我们的pdf 直接保存到我们的向量数据库中
- 文档可能token 过大
2 .比如说这个文档会有几兆 如果把这个文件通过向量模型转换成数值(向量维度是有限的)
在有限的向量 去转换很大的文件,他这个文本的数据就会被稀释
文件大 会产生的坐标(维度会很大)
bash
我们现在想要根据我企业中垂直的信息去回答
这个我们就要用到RAG 的相似性检索
所以我们现在要先进性embeding 的数据嵌入阶段, 把我们的资料保存到向量数据库中
比如说有什么 人事手册 企业规章 怎么去保存
我们通常不会把我们的pdf 直接保存到我们的向量数据库中
在RAG 流程中,你检索出的 PDF 片段(chunks)会被拼接到 Prompt 里,作为 输入上下文 一并送给 LLM,因此:
输入 token 数量 = 系统指令 + 用户问题 + 检索到的所有 chunks 的文本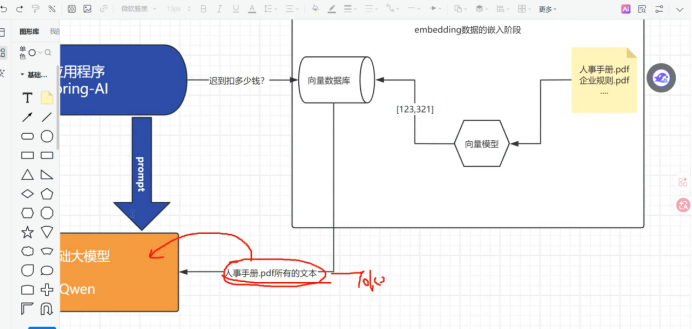
bash
所以 token 如果过大 费用高 推理时间就会边长 用户的延迟就会边长
所以我们不建议直接把一个大的文本直接存储在向量数据库中
我们一般会对我们的数据 文件进行分片处理
从而我们就会把这些一个个的片段去进行向量化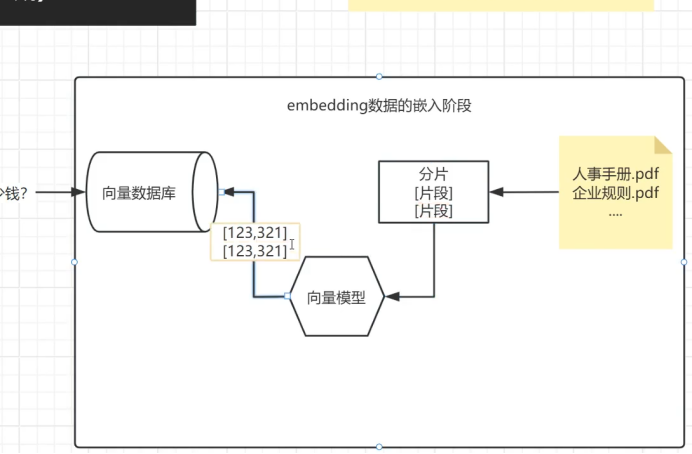
bash
存储到我们向量数据库中
之前我们叫做embe 嵌入
现在我们叫做检索##> 所以 rag 分为2个步骤
bash
我们这里讲的检索增强 拖过向量数据库实现rag 只是他落地实现的一种
并不是说rag 检索增强生成一定要用向量数据库
###########>>>>>>>>>>>>>>>>>>>>
bash
所以 我们利用向量数据库可以实现rag 以外 还有那些可以想到的rag场景
比如说联网检索 ,基础大模型LLM 是通过 网络的通用信息训练的 他的数据会有一些滞后
所以很多大模型 有一个联网搜索的功能
对比我对话之前 调用下百度的api 所以检索增强生成是一种思想 只不过通过向量数据库实现是一种方案
##################>>>>>>>>>>>>>>>>
我们具体到我们企业 又怎么去落地
我就可以进行问答的方式进行检索
所以看下对应的java相关的 springai 实现起来到底有多简单
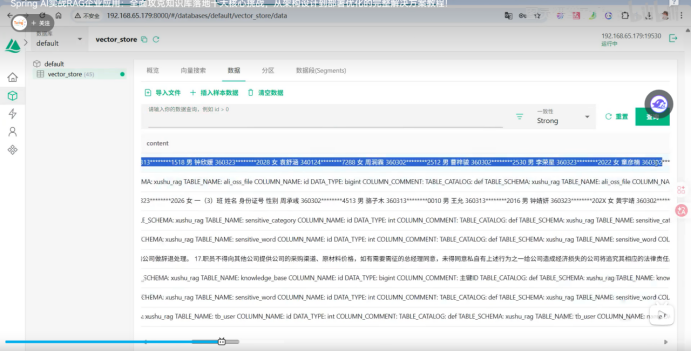
我向量数据库是有界面可以看到的
我经过存储之后就是一个一个的片段
里面会包含文本信息 和向量信息
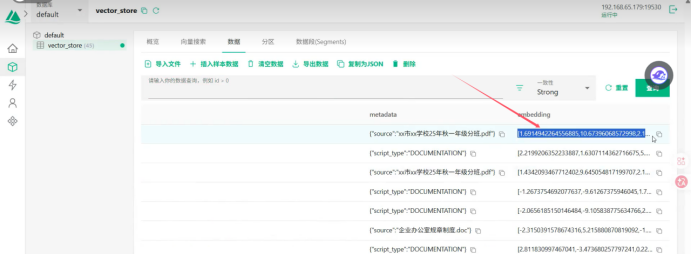
这就是他对应的向量 我就可以知道他这个是那个文件下的这样可以 追述
################>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.
我们可以基于元数据表达式去搜索
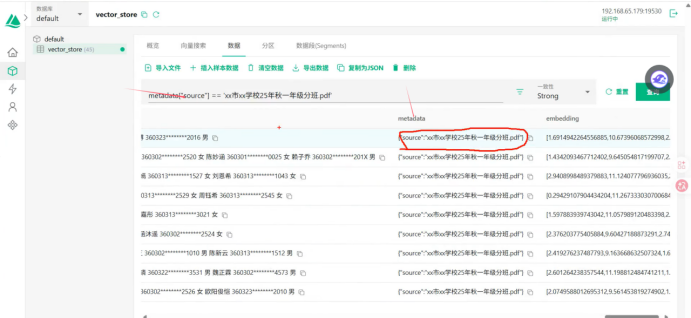
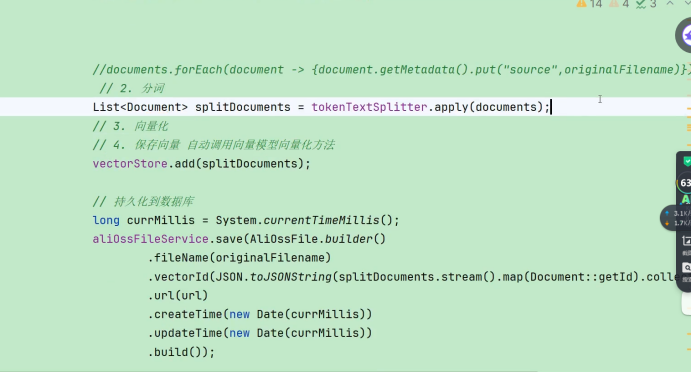
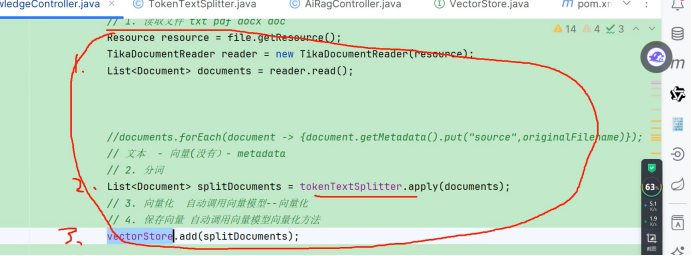
所以我们基于springAI
1.读取文件
分片
存储
#################################>>>>>>>>>>.
我们就完成这个embeding 了
###################>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
之后 我们进入检索阶段
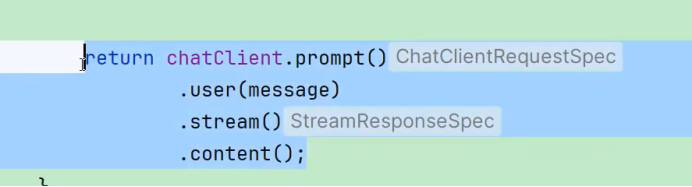
bash
这就是我们简单的智能体对话
我们这个只是进行一个大模型对话而已 我们没有进行检索增强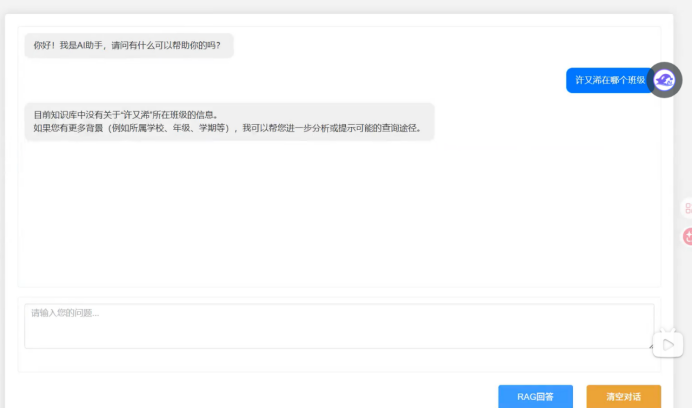
bash
我再问知识库 就没有了 因为此时没有做检索增强
所以我们在跟大模型对话之前进行检索对象生成
#########################>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
我们进行查询 他是进行相似性质查询 的 所以 他会有一个得分
所以他是根据得分来决定那个文本最相似
bash
那个片段最不相似 会有一个0-1的得分 1代表最相似
在向量数据库检索阶段进行一次过滤 而不至于把一些不太相似的检索出来
我们的基础大模型的token 是有限的 如果传递的文本太多 就会超出上线
比如说5个 我只会检索出最相似的前面5蓨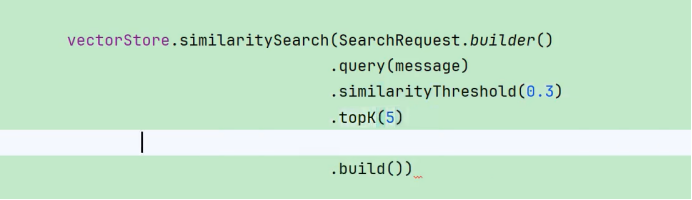
bash
这个时候我们的对话就会有对应的检索增强
除此以外我们会有上网搜索 调用搜索引擎的api 把搜索引擎搜索的东西也覆盖上去
springai 提供了一种更简单更友好的方式 叫做 a'dvisor
大模型的拦截器 他会跟我们在大模型对话之前和响应 进行一个增强
所以 我们用 rag 完成知识库系统 或者智能客服 是很简单的 单agent项目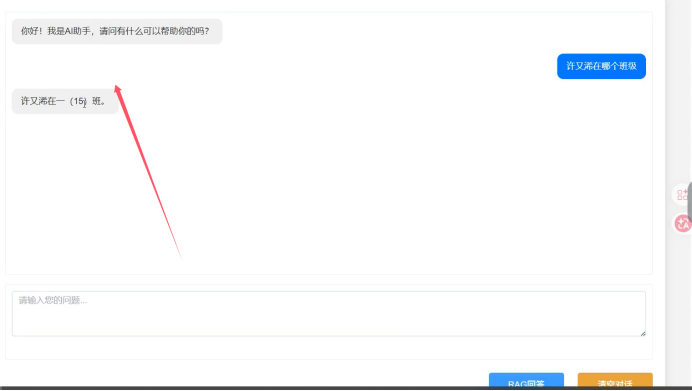
bash
我们可以通过advisier就可以非常方便的实现 检索增强生成
这样 就可以直接实现了 自动根据 我们对话内容去检索向量db
然后把检索到的内容 自动给我们 进行附加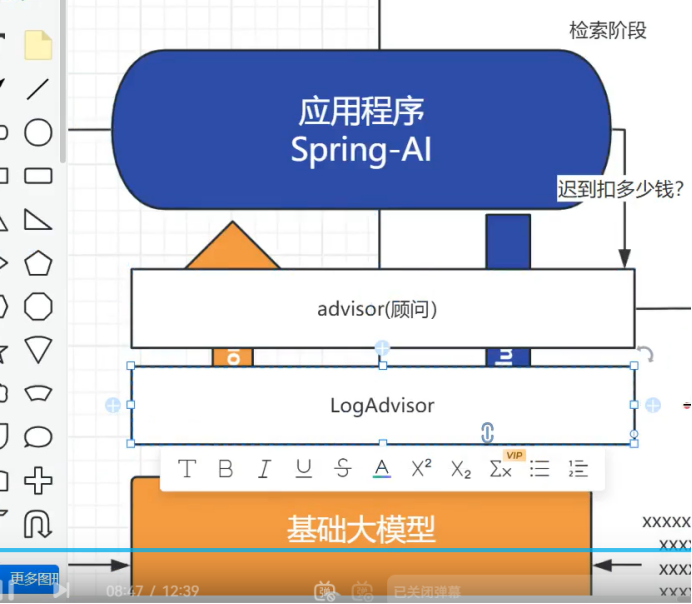
也会有对应的日志
bash
我们现在只是实现了 最基本的rag知识库的检索增强
但是我们真正完成一个企业级rag知识库 肯定会遇到很多问题
>1.1 企业中最佳的分片策略
他没有任何一个分片策略可以应对所有的文件结构
根据不同的文件结构 选择不同的分片策略
---------------->提供多种分片策略 供用户去选择
我们可以参考一下dify
所以分片是rag知识库中 决定他的检索精度中最重要的一环
只有分片片段语义是很合理 你的精度才可以提升 你提供给大模型的内容才会最相似
所以 到底用哪一个 最简单的
>按照固定文字大小去调整 这种造成语义割裂
>比如一些markdown 文档 我们可以进行一些 分片 比如说一级标题 二级标题这种
>我们还可以进行语义分片 比如说这对于我们的会议纪要,小说 新闻
语义分片从简单到难
我们可以按照段落分 /n/n为一个
开源自然语言的自然框架
##################>>>>>>>>>>>>>>>>>>>>
跨向量的聚合问题(统计求和 ) 怎么处理
1.视野受限 我们可以把topk 加大
从向量数据库里找出与用户问题最相似的前 K 个文档片段(chunks),然后只把这 K 个片段送入 LLM。
如果加大topk 我只能留下有价值的信息 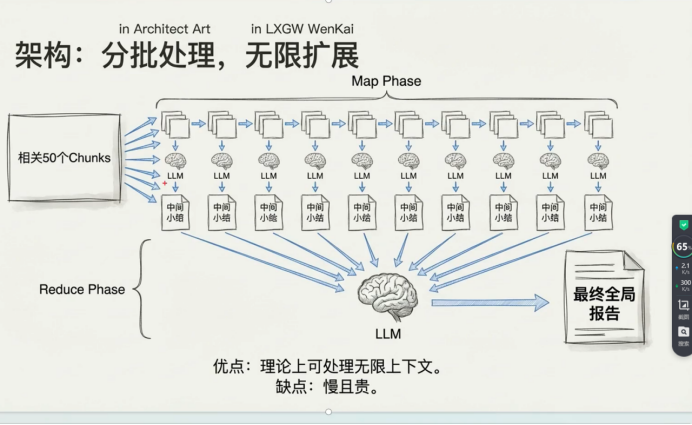
bash
性能成本很大
不太合理
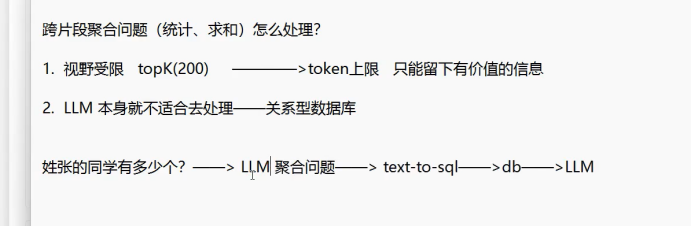
应该怎么合理 LLM 本身就不适合去处理
bash
我先通过大模型判断一下 是不是聚合问题
我们要让大模型去生成sql
项目启动 根据数据库 形成一个标--->将我们每一个表形成一个片段
存储到向量数据库
检索 出来
生成sql 执行sql 拿到结果返回给大模型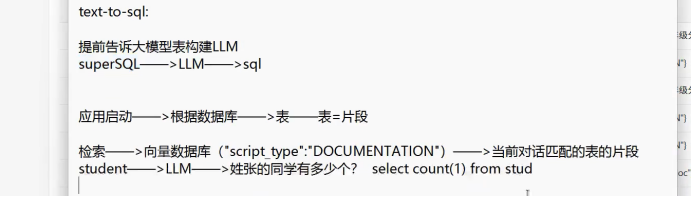
bash
知识库的文档如何更新
>1. 我这个文档信息错了 ---del(全链路删除 包括物理文件 向量 db) 事务
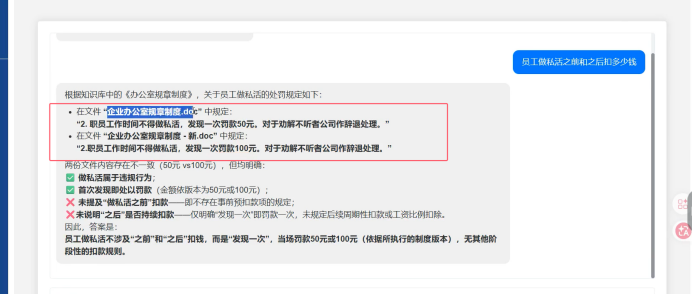
>2, 过期了--->(比如说之前迟到一次扣50 现在迟到一次扣100)
不建议删除 但是一定在文件名中体现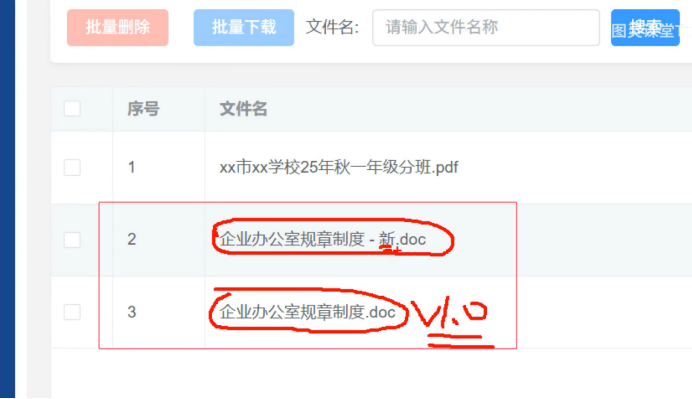
我们建议保留 并且告诉大模型 片段是属于那个文件 可能要 对比2次的不同
bash
我们如果涉及到了 比如说提升rag的检索精度 或者我们要解决rag的幻觉 应该怎么去做
比如说我们通过大模型检索 大模型给我胡说八道、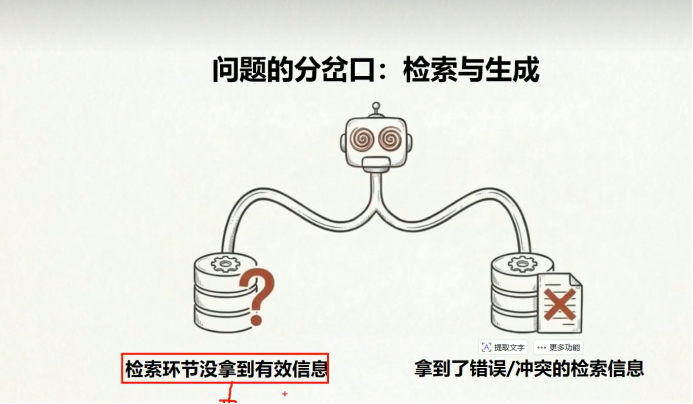
bash
没有检索到信息 他直接检索网络信息 没有价值
我们通过 提示词告诉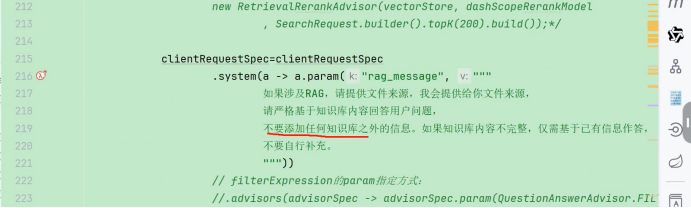
bash
提升他的检索精度 我们只有提升他的检索精度 才不会拿到错误的信息
我们可以在那些环节可以进行优化 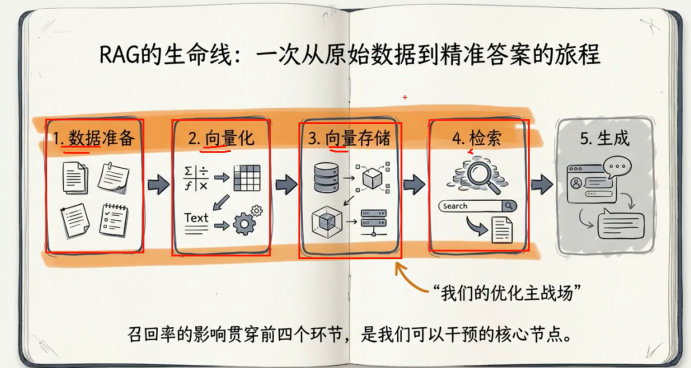
bash
数据准备 所以说分片是提升rag 的技术最重要的环节
向量模型的选择 要高纬度的向量模型