一、Logistic回归(二分类)
1、模型原理
Logistic 回归用于二分类问题 ,将线性函数的输出通过 Logistic 函数(Sigmoid 函数)映射到 (0,1) 区间,作为类别 1的条件概率:
非线性函数Logistic :
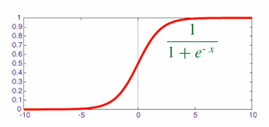
Logistic 回归 :
2、学习准则:交叉熵损失
① 条件概率估计
模型预测 条件概率:
真实条件概率:对于一个样本(x,y*),有
、
目标:让模型预测的概率分布 尽可能接近真实分布
② 信息论基础
· 熵:衡量⼀个随机事件的不确定性。
熵越高,随机变量的不确定性越大,信息量越多;熵越低,随机变量的确定性越大,信息量越少
用分布q自身 规律设计编码,熵 就是该规则下能达到的最短平均编码长度 ,这类编码统称熵编码。
· 交叉熵 :按照概率分布 q 的最优编码对真实分布为 p的信息进行编码的平均长度。
在给定 𝑞 的情况下,如果 p 和 𝑞 越接近,交叉熵越小;如果 p 和 𝑞 越远,交叉熵就越⼤
· KL散度 :用概率分布 q 来近似 p 时造成的信息损失量 ,等于交叉熵减去真实分布的熵。
③ 交叉熵损失函数推导 (单个样本的交叉熵损失)
最小化真实分布 和预测分布
之间的 KL 散度
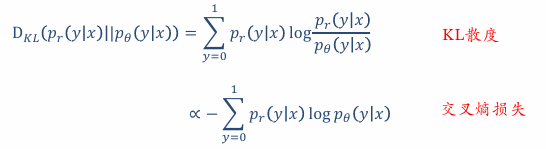
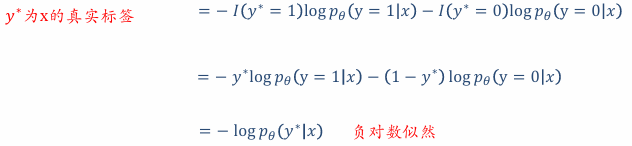
整个训练集的**平均损失(风险函数)**为:
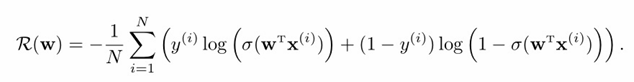
3、参数学习:梯度下降
梯度下降法最小化风险函数 R(w),计算损失对权重 w 的梯度

梯度的方向是损失函数上升最快的方向,沿着梯度的反方向更新权重
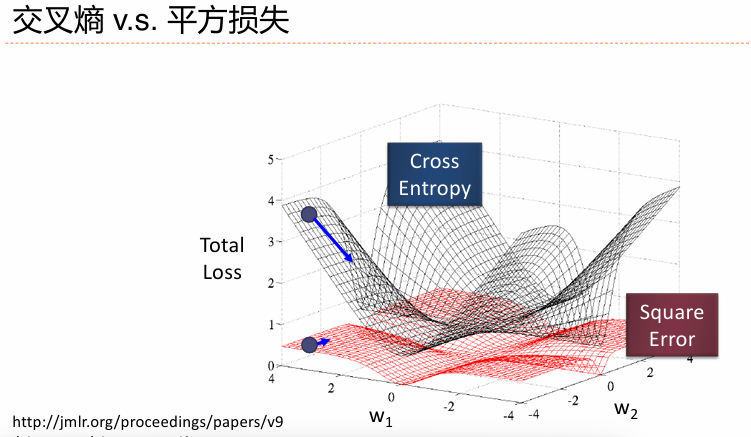
4、交叉熵损失与平方损失的讨论


二、Softmax回归(多分类)
1. 多分类问题的经典思路:
| 方式 | 模型数量 | 核心逻辑 | 优缺点 |
|---|---|---|---|
| 一对其余 | C | 一类对抗其余类 | 模型少,易冲突、样本失衡 |
| 一对一 | C(C-1)/2 | 两类两两对决 | 判定精准,数量膨胀算力高 |
| Argmax 打分 | C个判别函数 | 各类独立打分取最高 | 简洁高效,Softmax 底层形式 |
2. Softmax函数:将得分转换为概率
"argmax" 方式只能输出类别标签,无法给出预测的置信度(概率)。Softmax 函数的作用就是将 C 个类别的原始得分(任意实数)转换为合法的概率分布(所有类别概率之和为 1,且每个概率在 0 到 1 之间)。
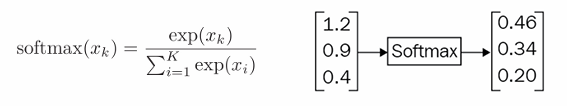
3. Softmax回归模型
将线性判别函数与 Softmax 函数结合,直接输出每个类别的条件概率
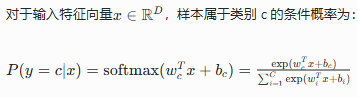
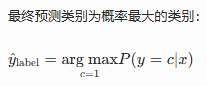
4. 学习准则:多分类交叉熵损失
真实分布与预测分布

交叉熵损失推导

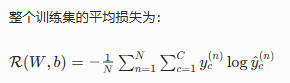
梯度下降:

三、感知器
1. 感知器模型原理
感知器模拟生物神经元的结构和功能,由输入层 、权重(突触) 、偏置(阈值) 和激活函数(细胞体)组成,输出为离散的 + 1 或 - 1。
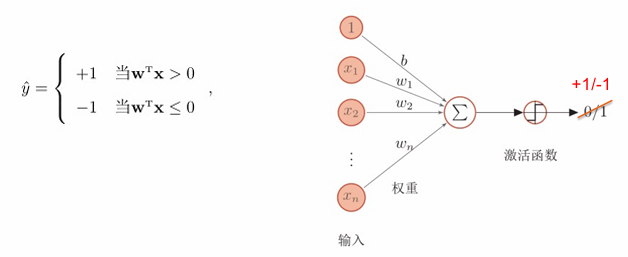
几何意义:D维特征空间中寻找一个线性超平面 ,将两类样本分开:
超平面上方()被判定为 +1 类
超平面下方()被判定为 -1 类
| 模型 | 标签取值 | 激活函数 | 输出 |
|---|---|---|---|
| 感知器 | +1, -1 | 符号函数 sgn | 离散类别 |
| Logistic 回归 | 0, 1 | Sigmoid 函数 | 连续概率值 |
2. 感知器学习算法
采用错误驱动的在线学习算法,最核心的特点:只有当样本被分类错误时,才会更新权重参数
算法核心思想
- 初始化权重向量为全零向量(
)
- 遍历训练集中的每个样本 (x,y)
- 如果样本被分类错误(
- 当
- 当
- 当
- 重复上述过程,直到所有样本都被正确分类或达到最大迭代次数
3. 感知器损失函数
感知器损失:
- 当分类正确时(
- 当分类错误时(
- "错误驱动" 的思想:只有错误的样本才会产生损失,才会参与参数更新
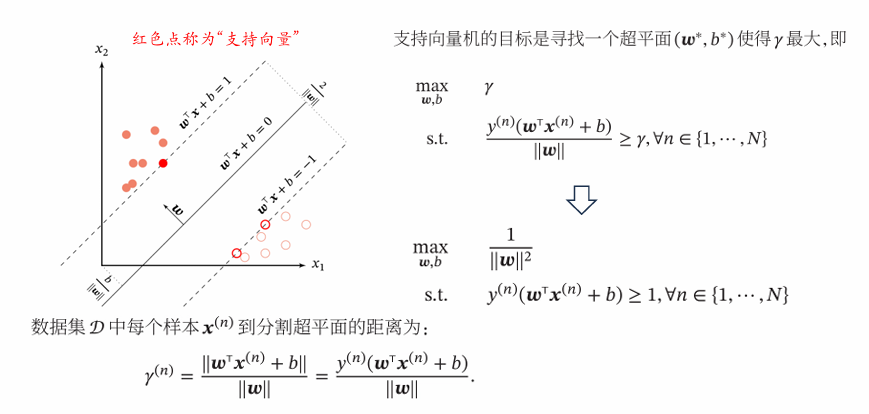
4. 支持向量机(SVM)