1、C++的第一个程序
C++兼容C语言的绝大数语法,所以C语言实现的hello world依旧可以运行,C++中只需要把文件定义成后缀为cpp就可以了,下面我们把C和C++版本的程序拿出来对比一下
C语言版本
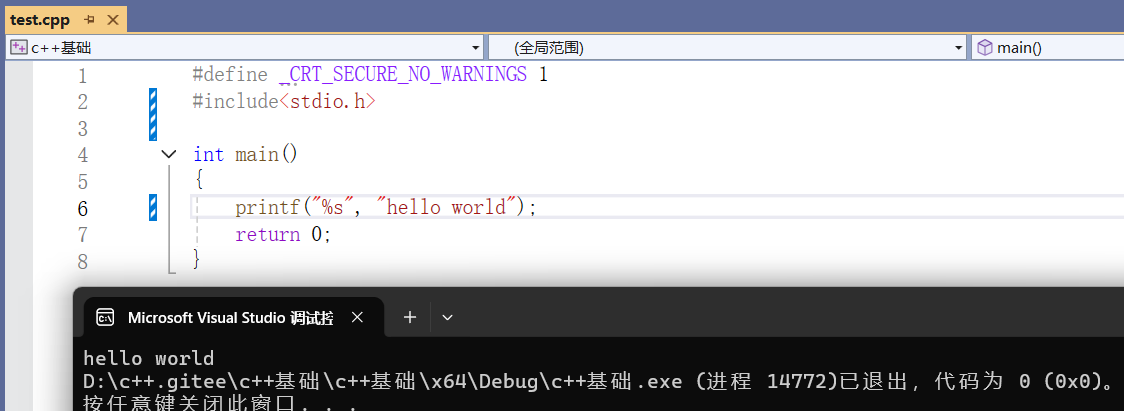 C++版本
C++版本
C++有一套自己的输入输出,看不明白不用着急,下面我们会讲解C++的基本语法,这里只是让大家看一下C和C++版本的程序的不同之处。
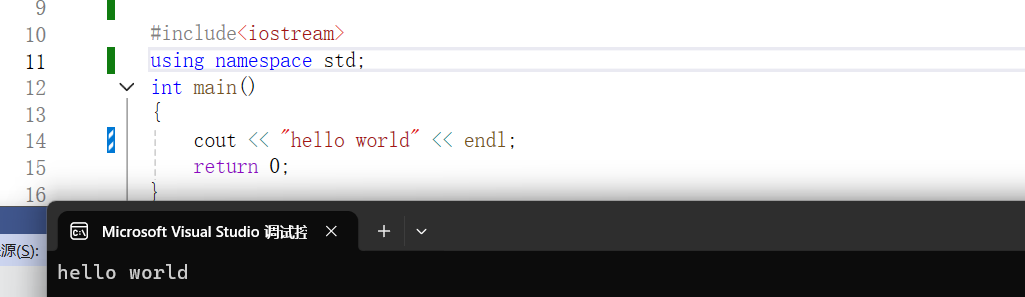 2、解读上面C++程序
2、解读上面C++程序
2.1C++头文件#include<iostream>
这里的头文件就相当于C语言中的#include<stdio.h>,它的作用是提供cout(输出),cin(输入),这些控制台交互功能的定义,没有这个头文件,你写的cout和cin就会报错,会说你没有定义。
所以,这里的作用就跟C语言当中的#include<stdio.h>与printf和scanf这些输入输出相互照应,头文件当中定义了这些函数,这里需要注意的是在C++的头文件当中,它的后缀没有.h.这里是因为C++之父为了区别C和C++而改变的。
2.2::(作用域解析运算符)
可以理解为一个作用域解析运算符专门用来指定:我要使用的这个名字,属于那个范围。
比如下面我们上面写的std::cout
::表示"我要访问std里面的东西"
cout是std里面的对象
所以std::cout完整的意思是:"我要用cout",是std这个命名空间里的cout,不是别的地方的。
2.3namespace命名空间
我们在C语言的学习过程中,难免会遇到定义一个变量或者函数名会和库里面的名字重复,导致程序发生报错,为了解决这种问题,namespace命名空间就能很好的解决这个问题,最核心的目的就是防止变量、函数、类名重名冲突。
为啥会冲突呢?C++自带很多标准库(输入输出、数学、字符串等),库里面已经写好了大量函数、变量名。
如果你自己写代码,不小心取了和库里面一模一样的名字,编译器就分不清你写的还是系统库里面自带的,直接报错。
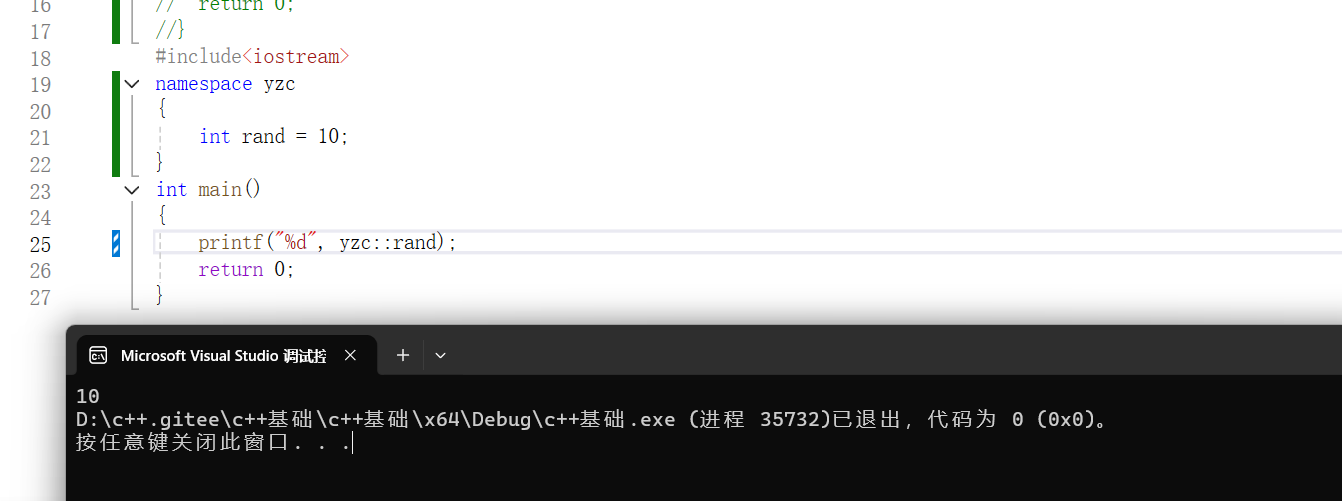
为什么要写namespace,我们以代码进行实操

这里显示了报错,说rand重定义了,因为在这个头文件当中rand是一个函数,而我们在这里定义的是一个整形变量,所以编译器就进行了报错。C++为了解决这个问题,就要使用namespace,namespace就相当于一个盒子,把这个我们自己定义的变量名字进行包装起来,当我们想使用的时候就把它展开,下面我们看一下如何写
写之前先说一下namespace怎么用
• 定义命名空间,需要使⽤到namespace关键字,后⾯跟命名空间的名字,然后接⼀对{}即可,{}中即为命名空间的成员。命名空间中可以定义变量/函数/类型等。
• namespace本质是定义出⼀个域,这个域跟全局域各⾃独⽴,不同的域可以定义同名变量,所以下⾯的rand不在冲突了。
• C++中域有函数局部域,全局域,命名空间域,类域;域影响的是编译时语法查找⼀个变量/函数/类型出处(声明或定义)的逻辑,所有有了域隔离,名字冲突就解决了。局部域和全局域除了会影响编译查找逻辑,还会影响变量的⽣命周期,命名空间域和类域不影响变量⽣命周期。
• namespace只能定义在全局,当然他还可以嵌套定义。• 项⽬⼯程中多⽂件中定义的同名namespace会认为是⼀个namespace,不会冲突。
• C++标准库都放在⼀个叫std(standard)的命名空间中。
也可以这样写:
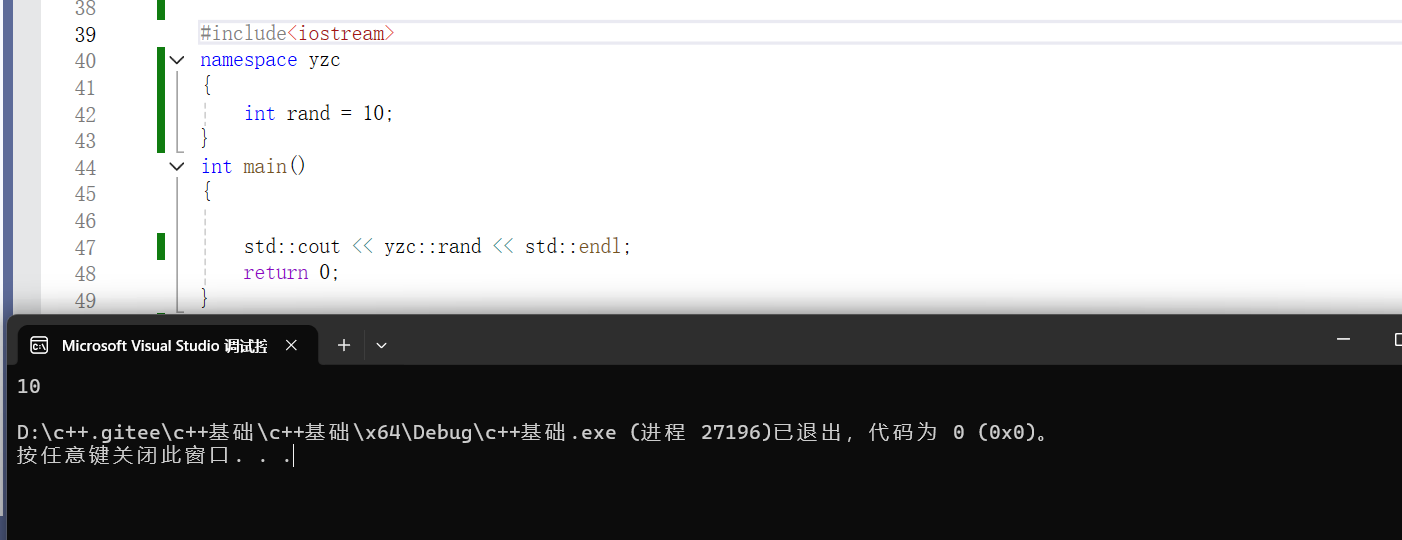
此时就不会显示重定义了,我们想要使用我们定义的变量,只需要+(重命名的名字::)就可以了。
namespace也可以进行嵌套

这里可以看到namespace的嵌套使用也是可以的。
2.4 std标准库

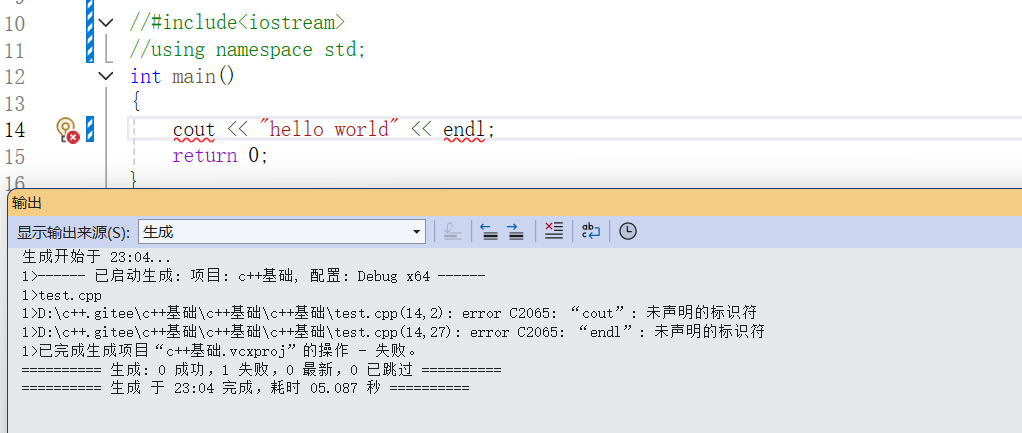
**为什么加了头文件还是报错?
因为 cout 和 endl 根本不是全局的名字,它们的完整身份是 std::cout 和 std::endl :
- 头文件 <iostream> 只是把它们的声明带进了你的代码里,但它们被放在了 std 这个命名空间里。**
- 不写 using namespace std; ,也不写 std:: ,编译器只会在全局空间里找 cout ,自然找不到。
std就是C++标准库的专属命名空间,全程standard,里面封装着所有的标准库的功能
比如输入输出:cout,cin
字符串 :string
容器:sort,find
为了防止库里面的这些名字和我们自己写的变量/函数重名冲突,C++把所有标准库的东西都"打包"进了std这个命名空间里。
这里的写法有两种:
第一种方法:
 第二种方法:
第二种方法: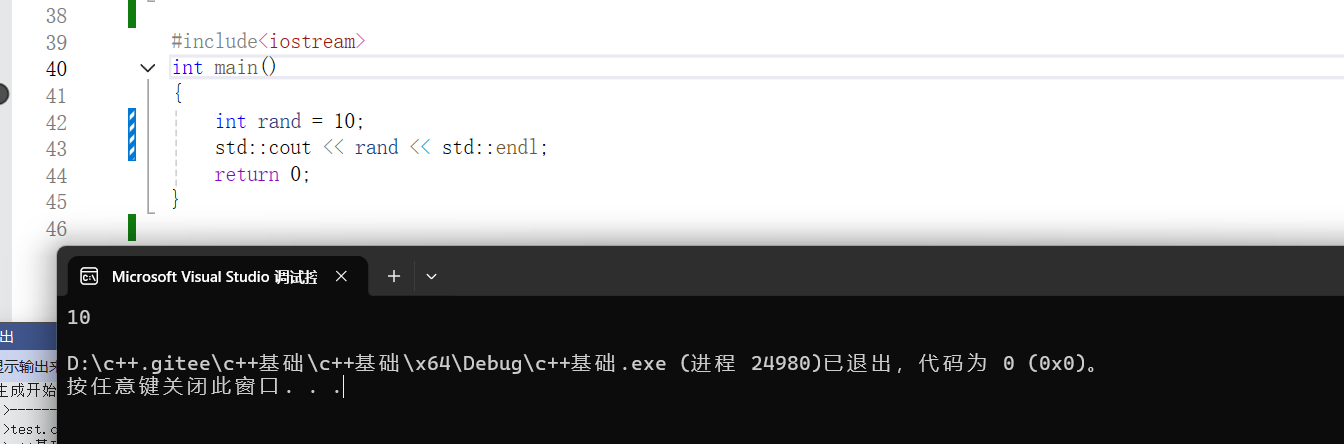
一般来说我们使用第二种方法较多。
2.5头文件和std的关系
最通俗易懂的来说
头文件:告诉编译器"有这个东西(cout/cin)";
std:告诉编译器"这个东西在哪(在std盒子里)"。
2.6 auto自动类型推导
- 什么是auto?
auto 是 C++11 开始支持的语法,编译器自动帮你识别变量类型,不用手动写 int 、 double 、 string 。

- 核心作用
-
简化代码,不用手动判断复杂类型
-
编译器在编译阶段自动推导,不影响运行速度
-
必须定义时直接赋值,否则推导不出来
2.7输入(cin)输出(cout)换行(endl)运算符
• <iostream> 是 Input Output Stream 的缩写,是标准的输⼊、输出流库,定义了标准的输⼊、输出对象。
• std::cin 是 istream 类的对象,它主要⾯向窄字符(narrow characters (of type char))的标准输⼊流。
• std::cout 是 ostream 类的对象,它主要⾯向窄字符的标准输出流。
• std::endl 是⼀个函数,流插⼊输出时,相当于插⼊⼀个换⾏字符加刷新缓冲区。
• <<是流插⼊运算符,>>是流提取运算符。(C语⾔还⽤这两个运算符做位运算左移/右移)
• 使⽤C++输⼊输出更⽅便,不需要像printf/scanf输⼊输出时那样,需要⼿动指定格式,C++的输⼊输出可以⾃动识别变量类型(本质是通过函数重载实现的,这个以后会讲到),其实最重要的是C++的流能更好的⽀持⾃定义类型对象的输⼊输出。
• IO流涉及类和对象,运算符重载、继承等很多⾯向对象的知识,这些知识我们还没有讲解,所以这⾥我们只能简单认识⼀下C++ IO流的⽤法,后⾯我们会有专⻔的⼀个章节来细节IO流库。
• cout/cin/endl等都属于C++标准库,C++标准库都放在⼀个叫std(standard)的命名空间中,所以要通过命名空间的使⽤⽅式去⽤他们。
• ⼀般⽇常练习中我们可以using namespace std,实际项⽬开发中不建议using namespace std。
• 这⾥我们没有包含<stdio.h>,也可以使⽤printf和scanf,在包含<iostream>间接包含了。vs系列编译器是这样的,其他编译器可能会报错。
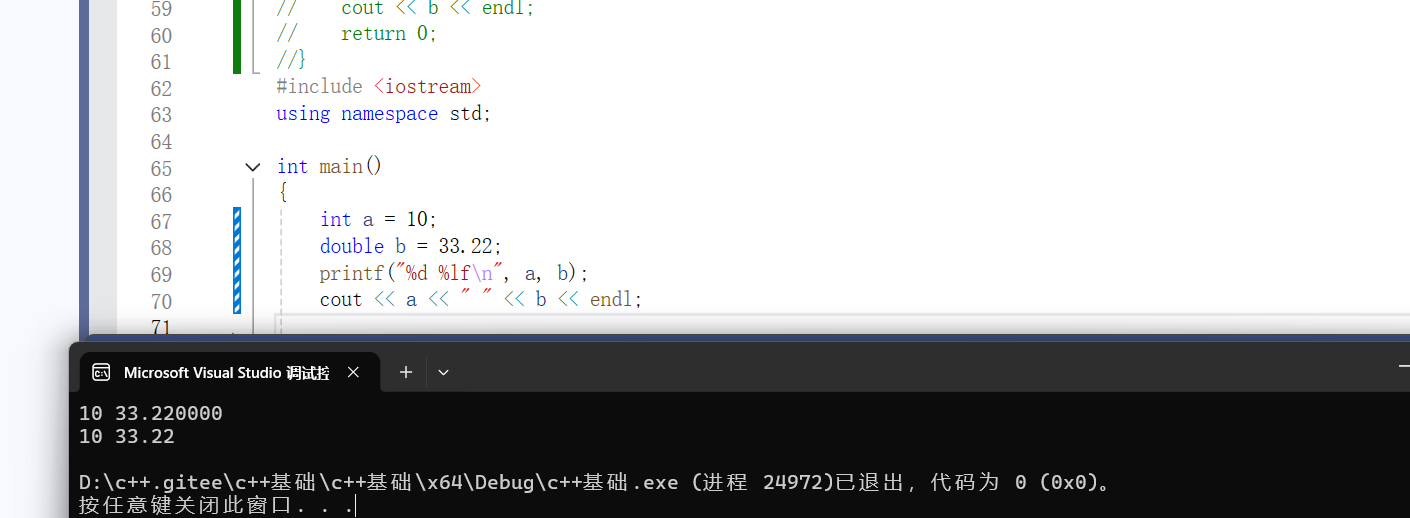 这里我们可以看到,C++中的输入输出运算符可以自动识别我们的类型,相较于C语言,减少了极大的麻烦。
这里我们可以看到,C++中的输入输出运算符可以自动识别我们的类型,相较于C语言,减少了极大的麻烦。
3、缺省函数
• 缺省参数是声明或定义函数时为函数的参数指定⼀个缺省值。在调⽤该函数时,如果没有指定实参则采⽤该形参的缺省值,否则使⽤指定的实参,缺省参数分为全缺省和半缺省参数。(有些地⽅把缺省参数也叫默认参数)
• 全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。
• 带缺省参数的函数调⽤,C++规定必须从左到右依次给实参,不能跳跃给实参。
• 函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
 3.1全缺省函数
3.1全缺省函数
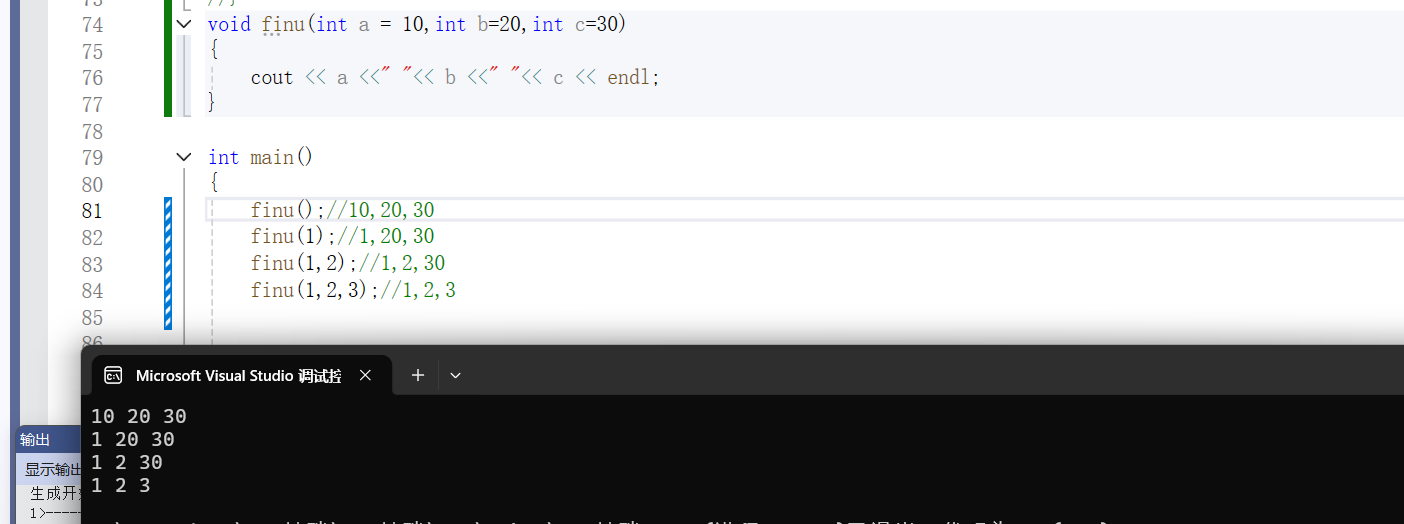 3.2半缺省函数
3.2半缺省函数
C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。
正确示范:
 错误示范:
错误示范:
 (注意)函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
(注意)函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
正确示范:
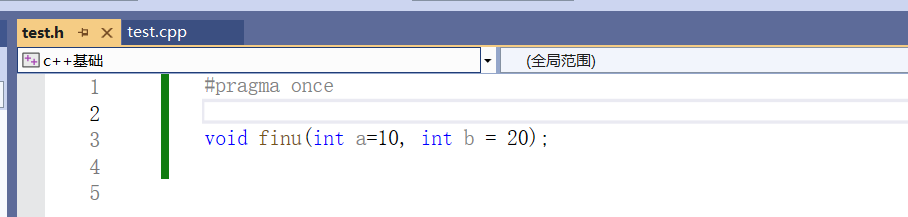
 错误示范:
错误示范:

 编译器执行 finu() 时,只会读取头文件里的函数声明,来识别默认参数;
编译器执行 finu() 时,只会读取头文件里的函数声明,来识别默认参数;
函数具体实现(定义)写在 .cpp 源文件中。
如果声明和定义两边都写默认参数,编译器会出现二义性,不知道该用哪一组默认值,直接报错。
因此C++语法强制规定:默认参数只能写在函数声明里,定义中不能重复写。