资料 第1章. AI通识与基础 - 飞书云文档
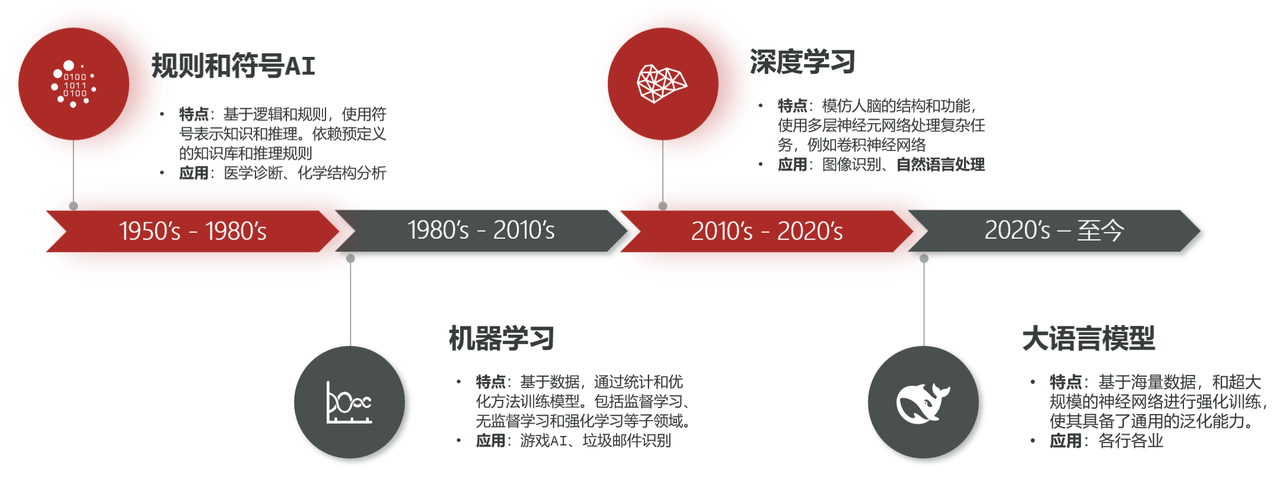
人工智能发展
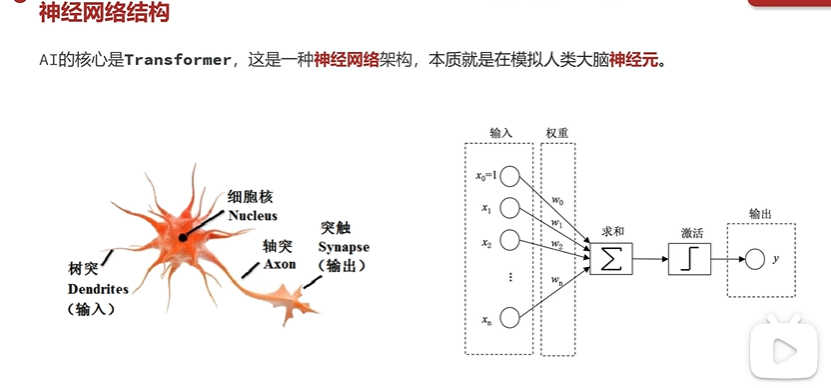
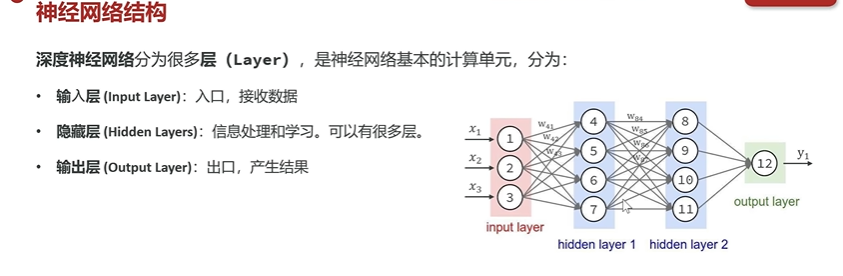
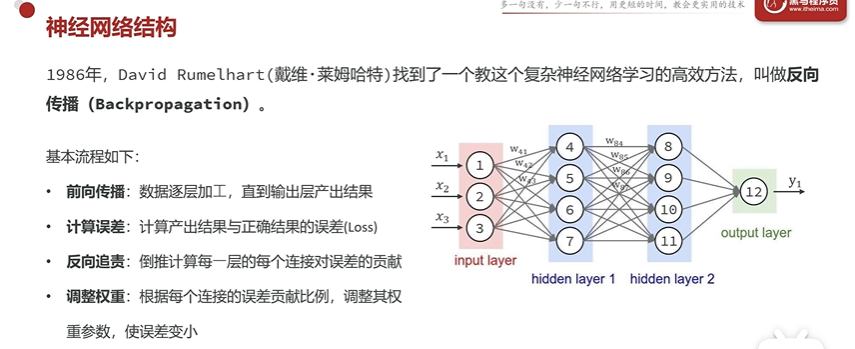
神经网络
类的大脑是由很多神经元细胞 构成,AI神经网络的本质就是在模拟人类大脑神经元
大语言模型

2003年,图灵奖得主约书亚·本吉奥 (Yoshua Bengio )的一篇名为《A neural probabilistic language model》的论文开创了**神经网络语言模型(Neural Network Language Model,NNLM)**的先河
词向量 (Word Embedding)
-
每个词语都可以经过模型运算转化为一个多维向量(也就是一个浮点数数组,GPT3采用12288维向量)
-
通过训练使模型计算出的多维向量 与文字语义 产生关联,使多维空间中的不同方向表示不同语义
Lanchain
Lanchain : 用于快速构建智能体,可兼容任何模型提供商。
LangGraph: 从底层一步步控制智能题的构建,包括记忆(Memory),人机协调(HITL)等
Deep Agents :用于构建复杂的、处理多步骤任务的智能体。
LangSmith : 用于测试、观察、评估。部署智能体。
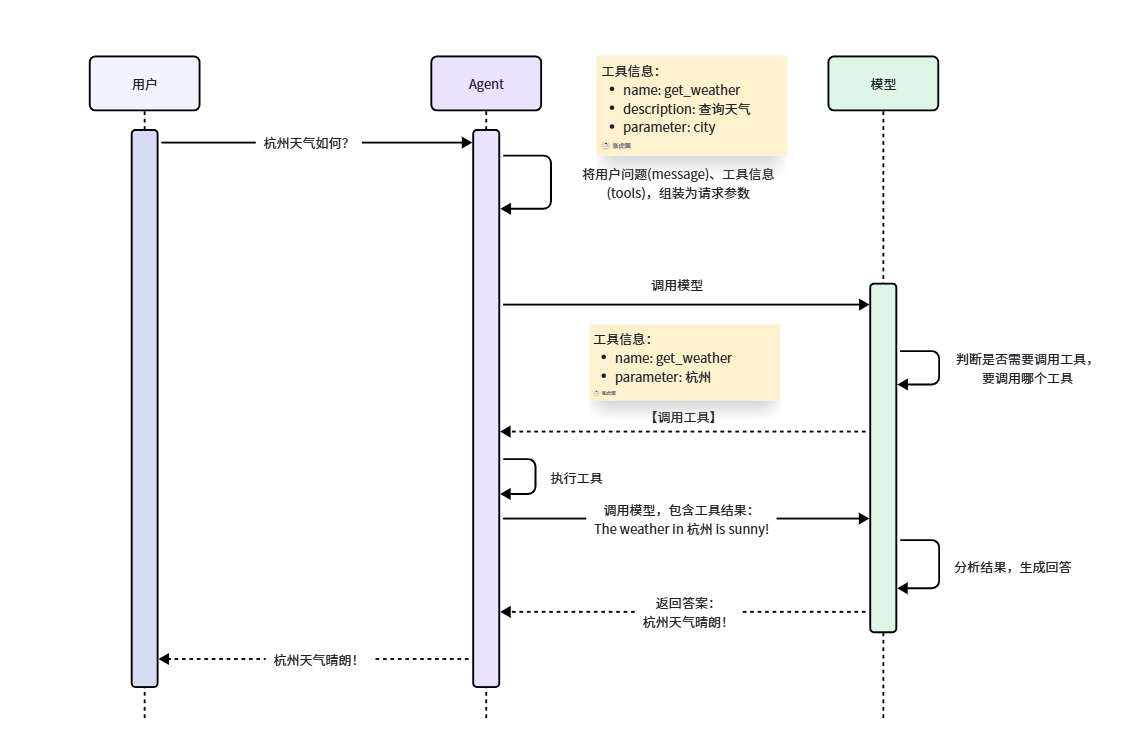
Agent: 一种使用大语言模型(LLM) 来决定应用程序控制的流的系统。
能够感知环境、进行推理、自主决策并采取行动以省市县特定的目标智能系统。
| 特性 | 传统聊天机器人/LLM | AI Agent |
|---|---|---|
| 交互模式 | 被动响应,问一句答一句 | 主动规划,以目标为导向 |
| 执行力 | 停留在文本生成层面 | 能操作软件、发送邮件、分析数据 |
| 自主性 | 需要人类给出详细步骤 | 只需给定最终目标,自主寻找路径 |
Agent的原理
-
Model:负责推理分析、思考,相当于Agent的大脑
-
Tools:负责执行任务,相当于Agent与外界交互的手脚
百炼平台
申请 apikey
python 访问本地 ollama 部署的 qwen3:8b
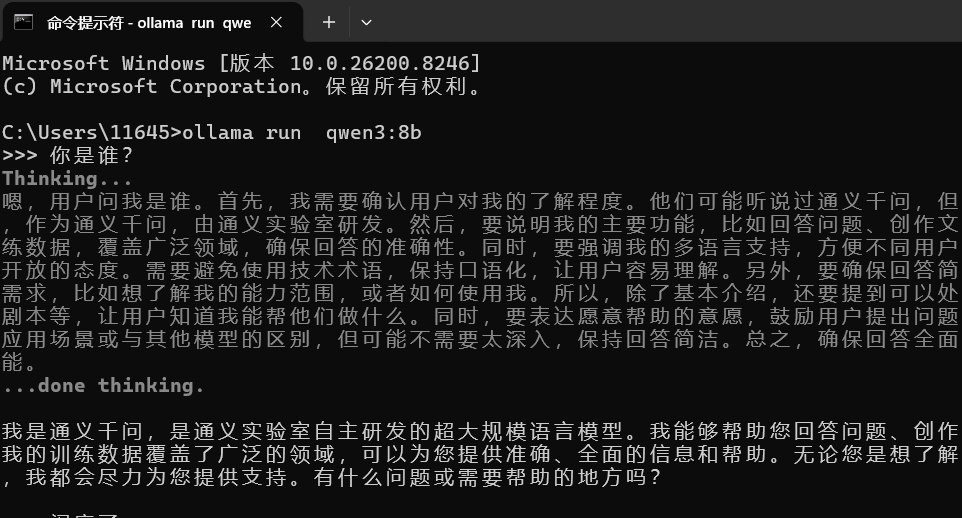
一、先确保 Ollama 已跑 qwen3:8b
ollama run qwen3:8b
看到聊天界面就说明本地模型正常运行。
二、Python 访问本地 Ollama qwen3:8b(完整版代码)
import requests
# 本地 Ollama API 地址
OLLAMA_API_URL = "http://localhost:11434/api/chat"
def chat_qwen3(prompt):
data = {
"model": "qwen3:8b",
"messages": [
{"role": "user", "content": prompt}
],
"stream": False # 非流式,最简单
}
response = requests.post(OLLAMA_API_URL, json=data)
result = response.json()
# 输出回答
print("AI:", result["message"]["content"])
# 测试
if __name__ == "__main__":
user_input = input("你:")
chat_qwen3(user_input)
用 openai 风格调用(兼容你之前的 qwen.py)
正确的 Ollama OpenAI 兼容地址 :base_url="http://localhost:11434/v1"
为什么带上v1?
- 错误:
http://localhost:11434→ 404 - 正确:
http://localhost:11434/v1→ 成功
Ollama 的 OpenAI 兼容接口必须加 /v1 后缀!
from openai import OpenAI
# 连接本地Ollama
client=OpenAI(base_url="http://localhost:11434/v1",
api_key="no-key") # 随便填一个
completion=client.chat.completions.create(
model="qwen3:8b",
messages=[{"role":"user","content":"你好,介绍一下自己吧!"}]
)
print(completion.choices[0].message.content)流式输出
from openai import OpenAI
# 连接本地Ollama
client=OpenAI(base_url="http://localhost:11434/v1",
api_key="no-key") # 随便填一个
completion=client.chat.completions.create(
model="qwen3:8b",
messages=[{"role":"user","content":"你好,介绍一下自己吧!"}],
stream=True # 流式输出
)
# 安全流式输出
for chunk in completion:
#print("chunk:",chunk)
if chunk.choices:
delta=chunk.choices[0].delta
if delta.content:
print(delta.content,end="",flush=True)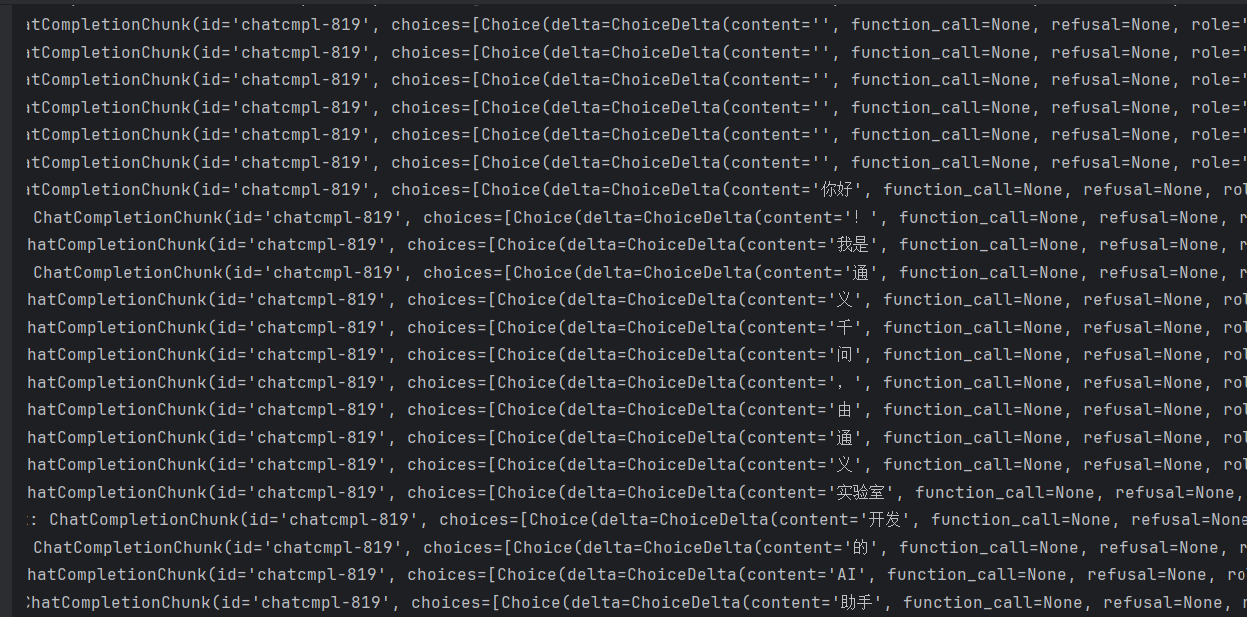
为什么流式输出(stream=True)时,AI 是一个字、一个词往外蹦,而不是一次性整段出来?
因为 大模型本来就是一个字一个字生成的 ,流式输出就是把生成过程实时传给你,所以你看到的就是一个个字 / 词
大模型接口规范
curl -X POST https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": false
}'
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求URL:与平台有关
- DeepSeek官方平台:https://api.deepseek.com/chat/completions
- 阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:http://localhost:11434
- 请求头:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- Content-Type: application/json,请求参数的格式,必须是application/json,稍后解释
- Authorization: Bearer <DeepSeek API Key>,上一节创建的API_KEY
- 请求参数:JSON格式:提示词角色
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
会话记忆问题
大模型的API接口是"无状态"的,服务端不会记录用户请求的上下文。因此我们调用API接口与大模型对话时,每一次对话信息都不会保留,多次对话之间都是独立的,没有关联的。
因此大模型并不知道之前的聊天历史,也就是说大模型是没有记忆的。
要想让大模型有记忆,必须在每次请求时,将之前所有对话的历史拼接好,传递给对话API接口。
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "12个苹果分给3个人,每人能分几个?直接告诉我答案"},
{"role": "assistant", "content": "每人可以分到4个苹果。"},
{"role": "user", "content": "如果是分给4个人呢?"}
],
"stream": false
}环境变量读取
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"),base_url="http://localhost:11434/v1")
print("正在调用大模型")
response=client.chat.completions.create( model="qwen3:8b", messages=[
{"role": "system", "content": "你是一名友好的AI助教。"},
{"role": "user", "content": "你好,你是谁?"}
],
stream=False)
print(response)