文章目录
摘要
本周主要工作是对上周提出的想法进行实验,希冀找到一个真正有效的视觉监督,实现多语言的泛化。但是实验的效果比较差,对失败的原因和做法进行了分析。
Abstract
The main work this week was to experiment with the ideas proposed last week, hoping to find a truly effective visual supervision to achieve multilingual generalization. However, the experimental results were rather poor, and the reasons for the failure and the approaches were analyzed.
1 语义监督
经过上个星期的实验,发现ViT的注意力并不聚集在字形区域,分析认为是因为模型没有从风格图片中提取对应的内容特征,因为缺少区域检测损失,模型选择从背景和风格中提取一些内容无关的特征,来伪装内容特征。
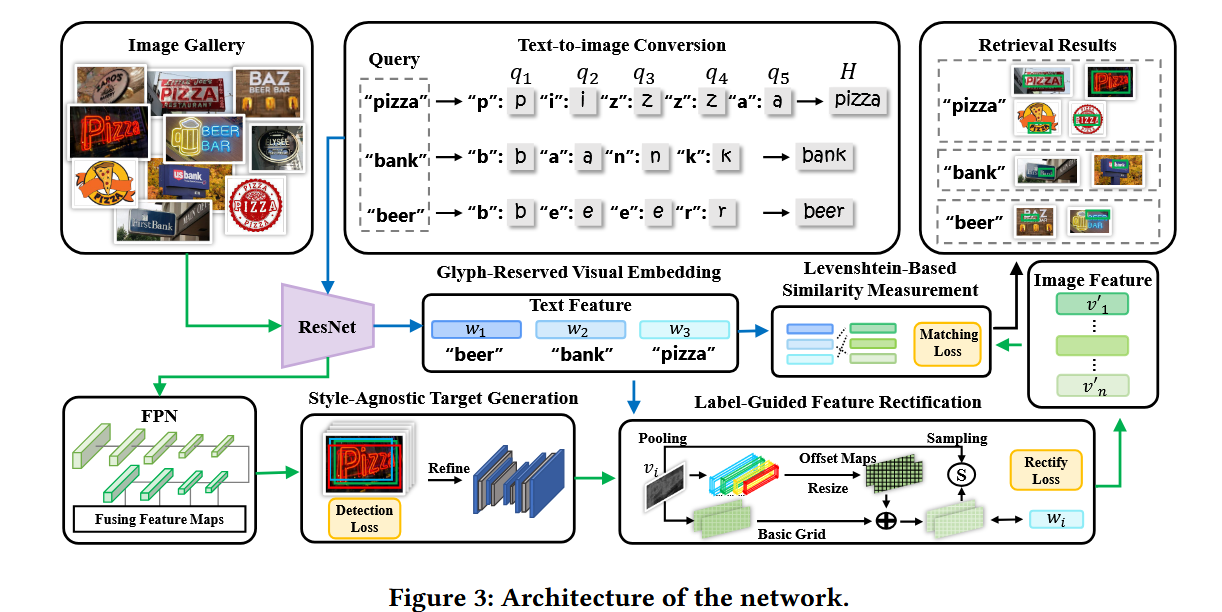
可以看到模型在左下角有一个FCOS的检测模块,经过这个检测模块可以很好的定位到文本区域,减少背景和风格的干扰,更好的对齐两个不同域的图片。
于是,在此之上,尝试通过其他的方法弥补缺少区域检测损失的缺点:
1、交叉注意力查询,字形图片和风格图片经过ViT分别获取到内容特征 g g g和 s s s,然后由特征 g g g去查询
s s s的特征,通过内容特征查询引导s来自字形区域。
2、对比学习将所有不同的背景、风格但是内容相同的图片提取到相同的内容特征。
3、MAE重建或者打乱patch顺序再重建。
经过对三个想法的实验,发现是无效的,无效的原因是:
1、字形图片提取到的内容特征,其实是arial字体、水平位置,而风格图片可能是Monaco字体、倾斜10度的字体,模型缺少语言监督,ViT对字形图片提取到的只是形状特征,字形图片和风格图片的形状差异,并不能让ViT从图片中提取到应该具有的内容特征。
2、风格图片之间的差异很大,即使内容相同,模型也可以不依靠内容特征来区分内容相同和不同的图片,其实在更早之前就已经尝试过 2 × 2 × 2 2\times 2 \times 2 2×2×2的数据组,两种字体、背景、内容构成差异,让模型在组内对比学习内容特征,其实并不能解决问题,对比损失的样本组的数量小,跨样本组之间的对比没有意义,因为内容、背景、字体都不同。
3、MAE重建和打乱顺序重建,MAE出现的情况是,模型更多的在注意背景,根据背景来重建图片,即使掩码比率已经又75%,打乱顺序,只会对部分字形的连接点有注意力。
一直以来都是在寻找一个视觉上的监督,拉近两个不同的域,但是在缺少了语义的强监督,仅靠自监督或者对比学习不能确保模型真正的在注意到内容特征,即使可以学习到监督也是需要加入其他的监督信号,或者构造更对比的任务。
2 场景文本编辑
一直寻找的视觉监督是为了泛化场景文本编辑,因为语义监督或者OCR模型会导入字典和语言限制,模型的多语言编辑受制于字典和可识别的语言,于是把输入的文本数据提前转变为字形图片,可以提前完成模态的对齐,避免语言的限制。但是正如上面所总结的,缺少了这种视觉的监督,这种视觉的监督也很难在循环自监督训练中有效的工作。
循环重建过程:
i m g 1 + t e x t 2 = i m g 2 + t e x t 1 ′ , i m g 2 + t e x t 1 ′ = t e x t 2 ′ img1+text2=img2+text1',img2+text1'=text2' img1+text2=img2+text1′,img2+text1′=text2′
L o s s = L ( t e x t 2 , t e x t 2 ′ ) + L ( t e x t 1 , t e x t 1 ′ ) + L ( i m g 1 , i m g 1 ′ ) Loss=L(text2,text2')+L(text1,text1')+L(img1,img1') Loss=L(text2,text2′)+L(text1,text1′)+L(img1,img1′)
缺少了中间对img2的监督,模型会不在img2进行生成,或者只是将图片切成两块,将头部放置到尾部的位置,将尾部放置到头部的位置,即使识别损失很高,但是还是为了降低感知损失和L1损失,所以达到局部最优。
i m g 1 + g l y p h 2 = i m g 2 + g l y p h 1 ′ , i m g 2 + g l y p h 1 ′ = i m g 1 ′ img1+glyph2=img2+glyph1',img2+glyph1'=img1' img1+glyph2=img2+glyph1′,img2+glyph1′=img1′
L o s s = L ( g l y p h 1 , g l y p h 1 ′ ) + L ( i m g 1 , i m g 1 ′ ) + L ( g l y p h 2 , g l y p h 2 ′ ) Loss=L(glyph1,glyph1')+L(img1,img1')+L(glyph2,glyph2') Loss=L(glyph1,glyph1′)+L(img1,img1′)+L(glyph2,glyph2′)
采用字形视觉监督,强调中间过程的生成必须要生成,但是并没有对img2的监督,模型通过平均像素,生成一堆符合损失的马赛克,绕过损失函数的限制。
总结
经过一直的实验验证,视觉监督无法解决问题,纯自监督学习,并不能学习到有效的编辑,后续将会对有监督和语义监督进行新的探索。