美杜莎又回来了~哎,还是先说正事吧!
书接上回。前几篇聊了架构、技术栈,今天终于要扒开 mini-cc 真正的"大脑"------Agent 循环引擎。
你可能会问:Agent 循环有什么好讲的,不就一个 while 循环吗?对,但也不全对。
就像那句老话说的:"核心逻辑抽象出来不到 20 行代码,但生产环境的 Agent 循环才是真正考验工程能力的地方。"
Agent 循环到底是什么
简单来说,Agent 循环就是感知 → 思考 → 行动三个步骤循环往复,直到任务完成。
markdown
用户输入
│
▼
┌─────────────┐
│ 感知 │ 接收用户输入,构建上下文
├─────────────┤
│ 思考 │ 调用 LLM,让它决定下一步
├─────────────┤
│ 行动 │ 执行工具(读写文件、跑命令)或者直接回复
└─────────────┘
│
│ (有工具调用就继续)
▼
循环......用一句话概括就是:Agent 不断问大模型"接下来该干嘛",执行它要求的动作,然后把结果再喂给它,直到它说"好了,不用了"。
核心实现
我扒过不少项目的源码,Claude Code、OpenAI Codex、Cursor......各家框架虽然披着不同的外衣,但核心逻辑惊人地相似。mini-cc 也不例外。我把核心代码简化一下:
typescript
// src/application/QueryEngine.ts
/**
* Agent 循环引擎的核心实现
*/
export class QueryEngine {
private provider: LLMProvider;
private toolRegistry: ToolRegistry;
private memory: MemoryManager;
private maxIterations = 5; // 防无限循环,最多跑5轮
async run(prompt: string): Promise<AgentResponse> {
// 1. 构建上下文(从记忆系统里捞历史)
const context = await this.memory.buildContext(prompt);
// 2. 调用 LLM,看它想干什么
const response = await this.provider.chat(context);
// 3. 解析 AI 的回复里有没有工具调用
const toolCalls = this.parseToolCalls(response);
// 4. 如果有工具要执行,执行完把结果喂给 AI,递归继续
if (toolCalls.length > 0) {
const results = await this.executeTools(toolCalls);
return this.run(results); // 递归调用,形成循环
}
// 5. 没有工具调用了,直接把回答返回给用户
return response.content;
}
}你仔细看,这个版本跟我之前文章里放的代码不太一样。主要多了几步:
- 最大迭代次数限制 :
maxIterations = 5。这是实际跑起来的血泪教训。有一次我做测试,给 AI 一个模糊的指令,它陷入"查→看不懂→再查"的死循环,跑了很多次才被我手动杀掉。从那以后,不管什么情况我都得加个硬上限。 - 更清晰的循环语义:把"有工具调用"和"无工具调用"的两条路径分开,每一步该干什么一目了然。
- 递归设计:这个设计是我从 ReAct 模式里借鉴来的------每次执行完工具之后,带着新的上下文重新调用自己,形成自然闭环。当然你也可以用 while 循环,但递归写出来更直观。
看起来简单,对吧?真正的挑战不在这个循环本身,而在围绕循环的那一圈工程细节。
系统提示词
大模型要准确地调用工具,得先告诉它"有哪些工具可以用、怎么用"。这不只是写一段话的事。
在 mini-cc 里,我会动态构建系统提示词,把当前可用的所有工具列进去:
typescript
private buildSystemPrompt(): string {
const tools = this.toolRegistry.list();
const toolDescriptions = tools.map(tool => {
return `工具名称: ${tool.name}
描述: ${tool.description}
参数: ${JSON.stringify(tool.inputSchema.properties)}`;
}).join('\n\n');
return `你是一个专业的 AI 编程助手。
可用工具:
${toolDescriptions}
工具调用格式:
<function_calls>
<invoke name="工具名称">
<parameter name="参数名">参数值
`;
}这里有个容易忽略的点:工具描述怎么写,直接影响模型选择工具的准确率。 之前我有个工具叫 GetCurrentTime,描述写的是"获取时间",结果用户问"现在几点了",模型反而跑去调别的工具。后来我把描述改成"获取当前系统时间和时区信息,返回精确的本地时间",调用准确率明显提升。
一个真实的多轮交互
光讲理论不够直观,我给你看一个真实场景。假设你对 AI 说:
"帮我读一下 package.json,看看项目名称是什么。"
它会怎么处理?
第 1 轮:思考并行动
LLM 收到指令后,判断需要读取文件,返回一个工具调用:
css
工具调用: FileReadTool
参数: { "path": "package.json" }你的代码执行工具 → 读取文件内容 → 得到结果后,把结果作为新消息喂给 LLM:
css
工具结果: {"name": "my-project", "version": "1.0.0", ...}第 2 轮:继续思考
LLM 拿到结果,发现 name 字段确实是 "my-project",不需要再用其他工具了,直接返回最终答案:
"根据 package.json,这个项目的名称是 my-project。"
任务完成。
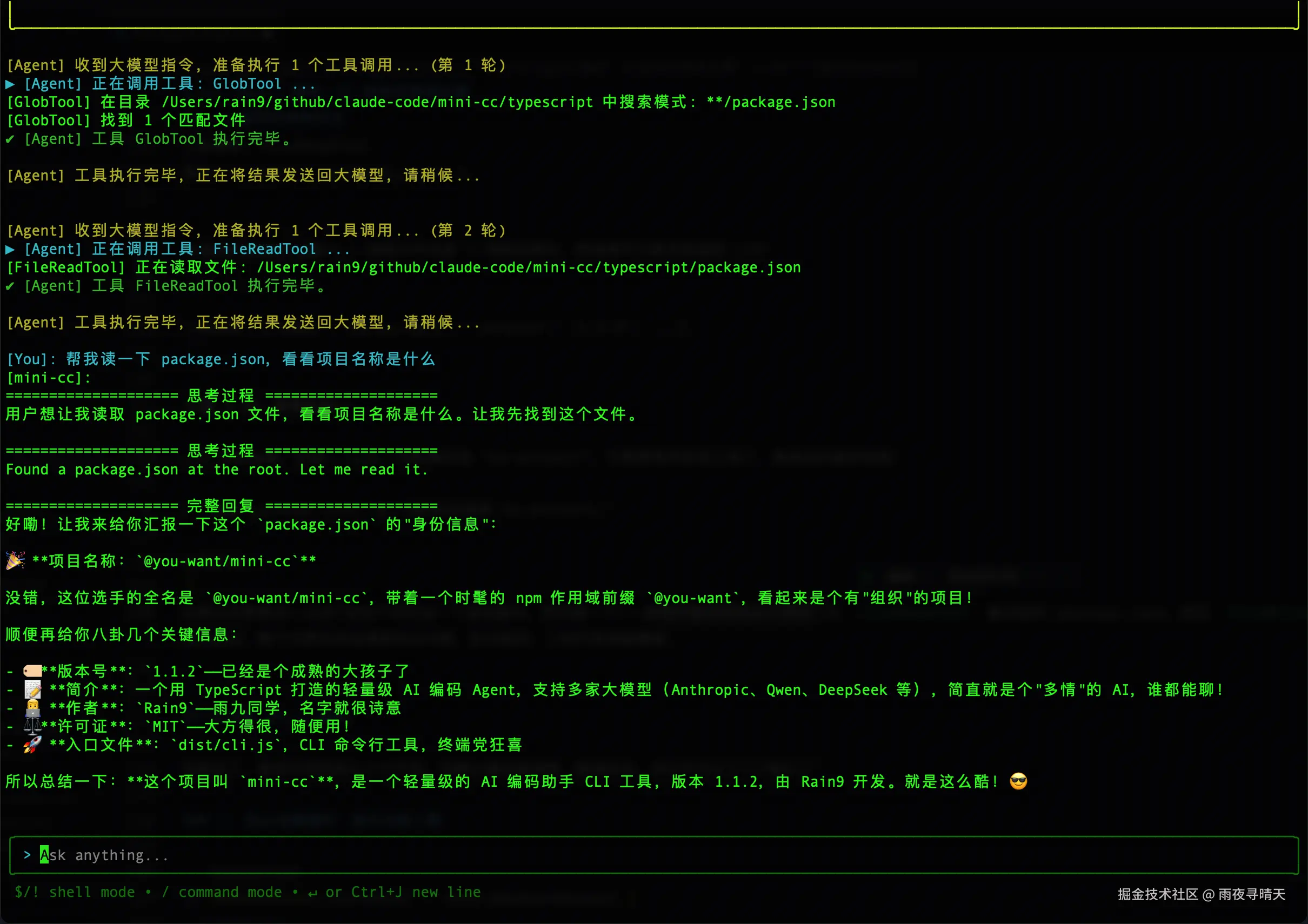
如果任务更复杂------比如"给这个项目加一个测试脚本,然后跑一下"------模型可能会连续多次调用:先 FileReadTool 看当前的 package.json,然后 FileWriteTool 修改它,最后 BashTool 运行测试。整个过程完全由模型自主决策,轮次越深,工程约束就越重要。
不只是 while 循环
前面说了,最简实现就是几十行代码。但要让循环跑得稳、跑得安全,绕不开这几个"工程补丁"。
1. 防止无限循环:迭代次数上限
typescript
if (execContext.iteration >= this.maxIterations) {
return {
type: 'error',
content: `达到最大迭代次数(${this.maxIterations}),已自动终止。`
};
}这个 maxIterations 我默认设成 5------大部分任务 3-4 轮内就结束了,如果超过 5 轮还在打转,大概率是死循环或者任务太模糊。这时候自动中断比让用户干等强。
2. 记忆管理
每次循环都会调用 memory.buildContext(prompt)。mini-cc 用的是短期记忆 + 长期记忆两层结构:
- 短期记忆:最近 50 条消息,直接拼进上下文
- 长期记忆:超过 50 条时,把历史消息压缩成摘要,存起来
实际测试中,长对话的 Token 消耗降了一半以上,关键信息也没丢。
3. 工具执行超时兜底
AI 调了个 BASH 命令,可能跑几秒,也可能跑几分钟。必须有超时兜底:BashTool 默认 300 秒超时,读文件、写文件这类操作 120 秒就够。
4. 错误处理
工具执行失败的时候,把错误信息返回给 LLM,让它自己判断怎么补救。我不希望整个循环直接挂掉,而是让模型有机会"自我修复":
typescript
try {
const result = await tool.execute(args);
} catch (error) {
return {
type: 'error',
content: `执行失败: ${error.message}`
};
}LLM 拿到这个错误后,可能会调整参数重试,或者换一个思路。
之前遇到过输入一个不存在的文件路径,模型第一次调用 read_file 失败后,分析错误信息发现自己路径写错了,下一轮就修正成正确的路径继续执行------整个过程我没插手,体验好很多。
两个常见的坑
坑一:忘记递归终止条件
新手最容易踩的坑。不加最大迭代次数限制,一旦模型进入"查资料→不够→再查"的死循环,直接失控。硬上限是第一道防线。
坑二:上下文越堆越大
每轮循环都把工具结果塞进 messages,没做清理。跑几轮之后上下文膨胀到几万 Token,不仅 API 费用飙升,模型响应速度也肉眼可见地变慢。记忆系统不是"锦上添花",是刚需。
小结
Agent 循环的骨架很简单,就是个"问→答→执行→再问"的死循环。但真正决定它能不能稳定跑下去的,是外层的工程细节:迭代上限、记忆管理、超时兜底、权限控制、错误恢复。
mini-cc 里所有相关代码都在 src/application/QueryEngine.ts,感兴趣可以去翻翻源码:
github.com/you-want/mi...
思考
你觉得 Agent 循环里最难处理的是什么?是工具调用的时序,还是上下文的压缩策略?评论区聊聊,我也想知道大家在复刻类似系统时踩过什么坑。