1.概念
Camera Serial Interface 2 规范定义了一个外设设备(摄像头)与一个主机处理器(基带、应用引擎)之间的接口。目的是为移动应用规定摄像头与主机处理器之间的标准接口。
CSI-2 V1.3支持D-PHY物理层和C-PHY物理层
2.术语
2.1 定义
- CCI (I²C) :支持 I²C NXP01 的 CCI。
- CCI (I3C) :支持 I3C MIPI03 的 CCI。
- CCI (I3C SDR) :支持 I3C SDR 的 CCI。
- CCI (I3C DDR) :支持 I3C DDR 的 CCI。
- Filler(填充元素) :在 CSI-2 数据包之后插入的协议元素,用于确保所有 Lane 的数据传输同时结束。
- Lane(通道) :一种单向、点对点、2 线或 3 线接口,用于高速串行时钟或数据传输;线数取决于使用的 PHY 规范(D-PHY 为 2 线,C-PHY 为 3 线)。使用 D-PHY 的 CSI-2 摄像头接口由一条时钟 Lane 与一条或多条数据 Lane 组成;使用 C-PHY 的 CSI-2 摄像头接口由一条或多条 Lane 组成,每条 Lane 同时传输时钟与数据信息。注意:当描述同时适用于 D-PHY 与 C-PHY 的特性或行为时,本规范有时使用术语 "data Lane" 来同时指代 D-PHY 数据 Lane 与 C-PHY Lane。
- Message(消息) :在 CCI (I²C) 或 CCI (I3C SDR) 中,一条 Message 以 START 或 Repeated START 条件开始,随后是目标从设备地址、R/W 位、其他数据,并以 STOP 或 Repeated START 条件结束。在 CCI (I3C SDR) 中,可以在开头追加一个 START/Repeated START 条件后跟 7'h7E。在 CCI (I3C DDR) 中,一条 Message 以 I3C ENTHDR0 CCC 或 I3C HDR Restart Pattern 开始,随后是 HDR-DDR Command、HDR-DDR Data,并以 I3C HDR Exit Pattern 或 I3C HDR Restart Pattern 结束。
- Operation(操作) :一次操作由一条或多条 Message 组成,以完成读或写。
- Packet(数据包) :按规定方式组织的若干字节,用于在接口上传输数据。所有数据包都有一组最小指定组成部分。字节是组成数据包的基本数据单元。
- Payload(负载) :仅指应用数据------已剔除所有同步、头、ECC、校验和及其他协议相关信息。它是应用处理器与外设之间传输的"核心"。
- Sleep Mode(睡眠模式) :睡眠模式(SLM)是一种仅包含漏电级别功耗的低功耗模式。
- Spacer(间隔字节) :一种可选的 CSI-2 协议元素,可在采用 CSI-2 LRTE 传输的 CSI-2 数据包与 Filler 之后插入;不要将其与 MIPI02 中定义的 C-PHY "Spacer Code" 混淆。
- Transmission(传输) :高速串行数据在总线上有效传输的时段。一次传输的开始与结束分别以 SoT (Start of Transmission) 与 EoT (End of Transmission) 为界。
- Virtual Channel(虚拟通道) :本规范支持最多 32 个外设的多个独立数据流。每个外设的数据流可作为一个虚拟通道。这些数据流可以交织并以顺序数据包形式发送,每个数据包专属于某个外设或通道。包协议中包含将每个数据包关联到其目标外设的信息。
2.2 缩写
| 缩略语 | 全称 / 含义 |
|---|---|
| ALP | Alternate Low Power(替代低功耗) |
| BER | Bit Error Rate(误码率) |
| CCI | Camera Control Interface(摄像头控制接口) |
| CIL | Control and Interface Logic(控制与接口逻辑) |
| CRC | Cyclic Redundancy Check(循环冗余校验) |
| CSI | Camera Serial Interface(摄像头串行接口) |
| CSPS | Chroma Shifted Pixel Sampling(色度偏移像素采样) |
| DDR | Dual Data Rate(双倍数据速率) |
| DI | Data Identifier(数据标识符) |
| DT | Data Type(数据类型) |
| ECC | Error Correction Code(错误纠正码) |
| EoT | End of Transmission(传输结束) |
| EoTp | End of Transmission short packet(传输结束短包) |
| EPD | Efficient Packet Delimiter(高效包分隔符;LRTE 中由 PHY/协议生成的信令) |
| EXIF | Exchangeable Image File Format(可交换图像文件格式) |
| FE | Frame End(帧结束) |
| FS | Frame Start(帧开始) |
| HS | High Speed(高速;操作模式标识) |
| HS-LPS-LS | High speed → Low Power State → High speed 切换(含 LPS 进入与退出延迟) |
| HS-RX | High-Speed Receiver(高速接收器) |
| HS-TX | High-Speed Transmitter(高速发送器) |
| I²C | Inter-Integrated Circuit NXP01 |
| ILR | Interpacket Latency Reduction(包间时延降低) |
| JFIF | JPEG File Interchange Format |
| JPEG | Joint Photographic Expert Group |
| LE | Line End(行结束) |
| LFSR | Linear Feedback Shift Register(线性反馈移位寄存器) |
| LLP | Low Level Protocol(底层协议) |
| LS | Line Start(行开始) |
| LSB | Least Significant Bit(最低有效位) |
| LSS | Least Significant Symbol(最低有效符号) |
| LP | Low-Power(低功耗;操作模式标识) |
| LP-RX | Low-Power Receiver(低功耗接收器,大摆幅单端) |
| LP-TX | Low-Power Transmitter(低功耗发送器,大摆幅单端) |
| LRTE | Latency Reduction Transport Efficiency(时延降低与传输效率) |
| LVLP | Low Voltage Low Power(低电压低功耗) |
| MSB | Most Significant Bit(最高有效位) |
| MSS | Most Significant Symbol(最高有效符号) |
| PDQ | Packet Delimiter Quick(LRTE 中由 PHY 生成与消费的信令) |
| PF | Packet Footer(包尾) |
| PH | Packet Header(包头) |
| PI | Packet Identifier(包标识符) |
| PT | Packet Type(包类型) |
| PHY | Physical Layer(物理层) |
| PPI | PHY Protocol Interface(PHY 协议接口) |
| PRBS | Pseudo-Random Binary Sequence(伪随机二进制序列) |
| RGB | 颜色表示法(Red, Green, Blue 红、绿、蓝) |
| RX | Receiver(接收器) |
| SCL | Serial Clock for CCI(CCI 串行时钟) |
| SDA | Serial Data for CCI(CCI 串行数据) |
| SLM | Sleep Mode(睡眠模式) |
| SoT | Start of Transmission(传输开始) |
| TX | Transmitter(发送器) |
| ULPS | Ultra Low Power State(超低功耗状态) |
| VGA | Video Graphics Array |
| WC | Word Count(字节/字节数) |
| YUV | 颜色表示法(Y 表示亮度,U 与 V 表示色度) |
3.CSI-2概述(OverView)
CSI-2 规范定义了发送端与接收端之间标准的数据传输接口和控制接口。规范定义了两种高速串行数据传输接口选项。
1.D-PHY 物理层 :通常是一条单向差分接口,包含一条 2 线时钟 Lane 与一条或多条 2 线数据 Lane,该接口的物理层由 MIPI Alliance Specification for D-PHY MIPI01 定义,发送端与接收端通常分别是摄像头模组和移动手机引擎中的接收模块。
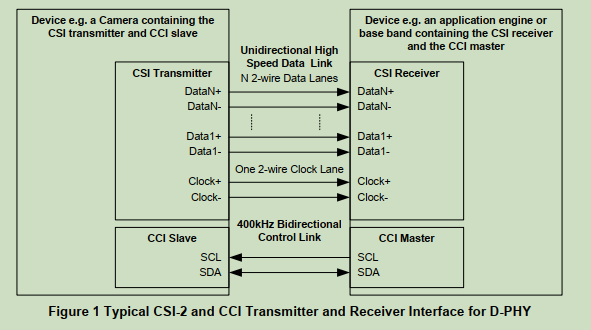
CSI 发送端(如内含 CSI 发送器和 CCI 从设备的摄像头)------ CSI 接收端(如内含 CSI 接收器和 CCI 主设备的应用引擎或基带)。
接口包含:1 条 2 线时钟 Lane(Clock+/Clock-);N 条 2 线数据 Lane(Data1+/Data1- ... DataN+/DataN-,单向高速数据链路);以及 SCL/SDA 双向 400 kHz 控制链路(CCI Master ↔ CCI Slave)。
2.C-PHY 物理层 :常由一条或多条单向 3 线串行数据 Lane 组成,每条 Lane 各自嵌入时钟。该接口的物理层由 MIPI Alliance Specification for C-PHY MIPI02 定义。

CSI 发送端 ↔ CSI 接收端,包含:N 条 3 线 Lane(每条由 DataN_A/DataN_B/DataN_C 组成的单向高速数据链路)以及 SCL/SDA 双向 400 kHz 控制链路
注意:从CSI-2 v3.0 规范开始,连接摄像头与主机/应用处理器的 D-PHY 或 C-PHY 链路的 Lane 1 (即 Figure 1 中的 Data1+/Data1-,或 Figure 2 中的 Data1_A/Data1_B/Data1_C)允许是双向的。
3.1 CSI-2 分层定义(CSI-2 Layer Definitions)

在该图中,发送端从 Application 输出像素与控制信号,依次经 Pixel to Byte Packing Formats(像素到字节打包格式) → Low Level Protocol(底层协议) → Lane Management Layer(Lane 管理层) → PHY Layer(物理层) 输出到 N 条单向高速 Lane(D-PHY 还包含一条单向高速时钟 Lane)。接收端反向执行:PHY → Lane Management → Low Level Protocol → Byte to Pixel Unpacking Formats(字节到像素解包格式) → Application。
像素位宽可为 6/7/8/10/12/14/15/16/18/20 或 24 bits;底层协议接口宽度 D-PHY 为 8 bit、C-PHY 为 16 bit
- PHY 层(PHY Layer) :PHY 层规定传输介质(电导体)、输入/输出电路以及从串行比特流中捕获 "1" 与 "0" 的时钟机制。本规范的此部分记录了传输介质特性、信令电气参数,以及(对 D-PHY 物理层选项)时钟与数据 Lane 之间的时序关系。同时还规定了发送端与接收端 PHY 之间用于发送 SoT (Start of Transmission) 与 EoT (End of Transmission) 信号的机制,以及其他可在两端 PHY 之间传递的"带外"信息。比特级与字节级同步机制也属于 PHY 层范畴。PHY 层在 MIPI01 与 MIPI02 中描述。
- 协议层(Protocol Layer) :协议层由若干层级组成,每层各司其职。CSI-2 协议允许在主机处理器单一接口上承载多路数据流。协议层规定了多个数据流如何被打标签和交织,从而使每路数据流均能被正确重建。
- 像素/字节打包/解包层(Pixel/Byte Packing/Unpacking Layer) :CSI-2 规范支持具有不同像素格式的图像应用。在发送端,本层在将数据交给底层协议层之前,将来自应用层的像素打包为字节;在接收端,本层在将数据交给应用层之前,将来自底层协议层的字节解包为像素。该层不会改变 8 bit/像素的数据。
- 底层协议(Low Level Protocol, LLP) :LLP 包括在 SoT 与 EoT 事件之间为串行数据建立比特级与字节级同步、并将数据传递到下一层的机制。LLP 的最小数据粒度为一个字节。LLP 还包含字节内位值含义的分配,即"端序(Endian)"分配。
- Lane 管理(Lane Management) :CSI-2 通过 Lane 数量可缩放以提升性能。本规范不限制数据 Lane 的数量,可根据应用带宽需求选择。接口的发送端将待发送数据流的字节分发("distributor" 功能)到一条或多条 Lane;接收端则从各 Lane 收集字节并合并("merger" 功能)成重组数据流,恢复原始字节顺序。对于 C-PHY 物理层选项,本层仅以字节对(即 16 bit)为单位进行分发或收集。基于每 Lane 的扰码(Scrambling)是可选特性,详见 9.17 节。
协议层中数据被组织为数据包。发送端在 LLP 中为待发送数据附加包头与错误检测信息;接收端则在 LLP 中剥离包头并由相应逻辑解析。错误检测信息可用于检验进入数据的完整性。 - 应用层(Application Layer) :本层描述数据流中数据的更高级编码与解释,超出了本规范范围。CSI-2 规范仅描述像素值到字节的映射。
3.2 CSI-2上下文总览
第 3 章 PHY 选项 → 我用 D-PHY 还是 C-PHY、什么版本
第 4 章 Lane 分发 → 字节流怎么上 N 条 Lane
第 5 章 LLP → 字节流由什么包构成
第 6 章 颜色空间 → 像素值代表什么颜色
第 7 章 数据格式 → 像素如何打包成字节
第 8 章 推荐内存存储 → RX 收完后怎么放内存
附录 A JPEG8 → 特殊场景:JPEG 数据流
附录 E RAW 压缩 → 可选:传输前压缩 RAW2 摄像头控制接口 - Camera Control Interface, CCI
CCI 是一种两线、双向、半双工的串行接口,用于控制发送端。兼容 I²C Fast-mode (Fm) 或 Fast-mode Plus,并兼容 I3C MIPI03 接口的 Single Data Rate (SDR) 或 Double Data Rate (DDR) 协议。CCI 应支持高达 400 kbps 的 Fm 操作及 7-bit 从地址寻址。此外,CCI 还可以可选地支持高达 1 Mbps (Fm+)、12.5 Mbps (SDR) 或 25 Mbps (DDR)。
相关术语:
- CCI (I²C) :支持 I²C 的 CCI;
- CCI (I3C) :支持 I3C 的 CCI;
- CCI (I3C SDR) :支持 I3C SDR 的 CCI;
- CCI (I3C DDR) :支持 I3C DDR 的 CCI;
- 单独的 CCI (无括号)同时表示 CCI (I²C) 与 CCI (I3C)。
CCI 既可与基于 C/D-PHY 的 CSI-2 配合使用,也可独立使用。当 CCI 作为 CSI-2 总线一部分使用时,CSI-2 接收端应配置为 master,CSI-2 发送端应配置为 slave。当 CCI 不与 C/D-PHY 上的 CSI-2 一同使用时,主机应作为 master。CCI 能够在总线上处理多个 slave。
CCI的具体功能取决于具体的器件,参考所使用器件的数据手册
2.1 CCI(IIC)数据传输协议
CCI (I²C) 数据传输协议遵循 I²C 规范。START、Repeated START 和 STOP 条件以及数据传输协议均在 NXP01 中规定。
2.1.1 CCI (I²C) Message 类型
一条基本的 CCI (I²C) Message 由以下部分组成:
- START 或 Repeated START 条件;
- 带 R/W 位的 slave 地址;
- 来自 slave 的 Acknowledge;
- 用于指向 slave 设备内部寄存器的子地址(INDEX)(在 Single Read from Current Location 中不使用);
- 来自 slave 的 Acknowledge 信号(在 Single Read from Current Location 中不使用);
对于 写操作 :
- master 发出的数据字节;
- slave 的 Acknowledge / Negative Acknowledge;
- STOP 或 Repeated START 条件。
对于 读操作 :
- Repeated START 条件(Single Read from Current Location 中不使用);
- 带读位的 slave 地址(同上);
- slave 的 Acknowledge(同上);
- slave 的数据字节;
- master 的 Acknowledge 或 Negative Acknowledge;
- STOP 或 Repeated START 条件。
CCI Slave 可以使用 Repeated START 而非 START/STOP 来支持背靠背 Message。
CCI (I²C) 的 slave 地址长度为 7 bit。
CCI (I²C) 支持"8-bit INDEX + 8-bit data"或"16-bit INDEX + 8-bit data"两种格式,由具体的 slave 设备决定。
2.1.2 CCI (I²C) 读/写操作
CCI (I²C) 兼容设备应支持 Table 1 列出的 4 种读操作和 2 种写操作:
Table 1 CCI (I²C) Read/Write Operations
| 类型 | 操作 | 章节 |
|---|---|---|
| Read | Single Read from Random Location(从随机位置单次读) | 3.1.2.2.1 |
| Read | Sequential Read from Random Location(从随机位置开始的连续读) | 3.1.2.2.2 |
| Read | Single Read from Current Location(从当前位置单次读) | 3.1.2.2.3 |
| Read | Sequential Read from Current Location(从当前位置开始的连续读) | 3.1.2.2.4 |
| Write | Single Write to Random Location(向随机位置单次写) | 3.1.2.2.5 |
| Write | Sequential Write Starting from Random Location(从随机位置开始的连续写) | 3.1.2.2.6 |
每次读/写操作后,slave 设备中的 INDEX 必须自动递增。下面各节也将详细说明这一点。
2.1.3 CCI (I²C) Single Read from Random Location
在从随机位置进行单次读时(见 Figure 4 ),master 先向所需 INDEX 进行一次"哑写(dummy write)"操作,发出 Repeated START 条件,然后再次以读操作寻址 slave。slave 在确认其 slave 地址后,开始将数据输出到 SDA 线上。master 通过发出 Negative Acknowledge 以及 STOP 或 Repeated START 条件来终止读操作。
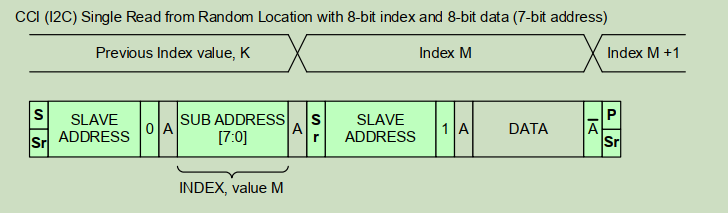
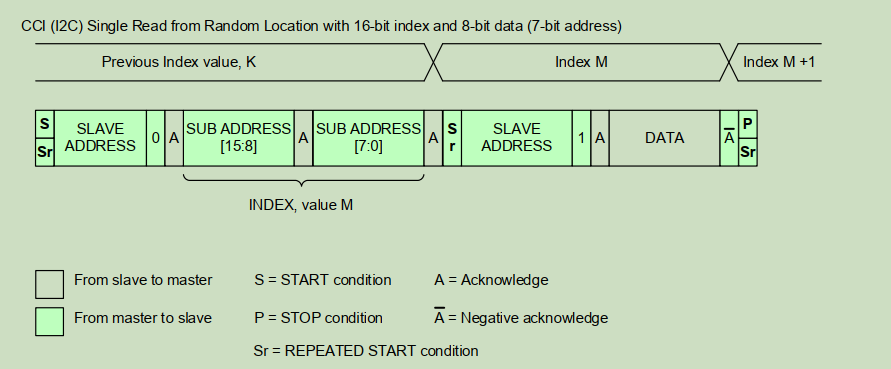
Figure 4 CCI (I²C) Single Read from Random Location :图示展示了两种变体------8-bit 索引 + 8-bit 数据(7-bit 地址)和 16-bit 索引 + 8-bit 数据(7-bit 地址)。在二者中,时序均为:S → SLAVE ADDRESS+W → A → SUB ADDRESS(7:0 或 15:8 + 7:0)→ A → Sr → SLAVE ADDRESS+R → A → DATA → A̅(master 否定应答)→ P/Sr。INDEX 从先前的 K 跳转到 M,读完后变为 M+1。
2.1.4 CCI (I²C) Single Read from Current Location
也可以从最近一次使用的 INDEX 处读取数据,方法是直接以读操作寻址 slave(见 Figure 5 )。slave 通过将上次 INDEX 处的数据放到 SDA 线上来响应。master 通过发出 Negative Acknowledge 及 STOP/Repeated START 条件终止读操作。

Figure 5 CCI (I²C) Single Read from Current Location :S → SLAVE ADDRESS+R → A → DATA → A̅ → P/Sr。INDEX 从 K 自增至 K+1(继续读则继续递增)。
2.1.5 CCI (I²C) Sequential Read Starting from Random Location
从随机位置开始的连续读如 Figure 6 所示。master 向所需 INDEX 进行哑写操作,slave Acknowledge 后发出 Repeated START 条件,再以读操作寻址 slave。如果 master 在收到数据后发出 Acknowledge,则相当于通知 slave 从下一个 INDEX 继续读。当 master 读取最后一个数据字节后,发出 Negative Acknowledge 及 STOP/Repeated START 条件。

Figure 6 :与 Figure 4 相比,只是在 master 接收每个 DATA 后均使用 Acknowledge,最后一个 DATA 后才使用 Negative Acknowledge,从而使 slave 自动递增 INDEX 输出 L 字节数据。
2.1.6 CCI (I²C) Sequential Read Starting from Current Location

从当前位置开始的连续读( Figure 7 )与从随机位置开始的连续读类似,唯一的区别是没有哑写操作。master 通过发出 Negative Acknowledge 及 STOP/Repeated START 条件来终止读操作。
2.1.7 CCI (I²C) Single Write to Random Location
向随机位置写一次的操作如 Figure 8 所示。master 发出对 slave 的写操作,待 slave Acknowledge 后再发送 INDEX 与数据。写操作以 master 发出的 STOP 或 Repeated START 条件结束。
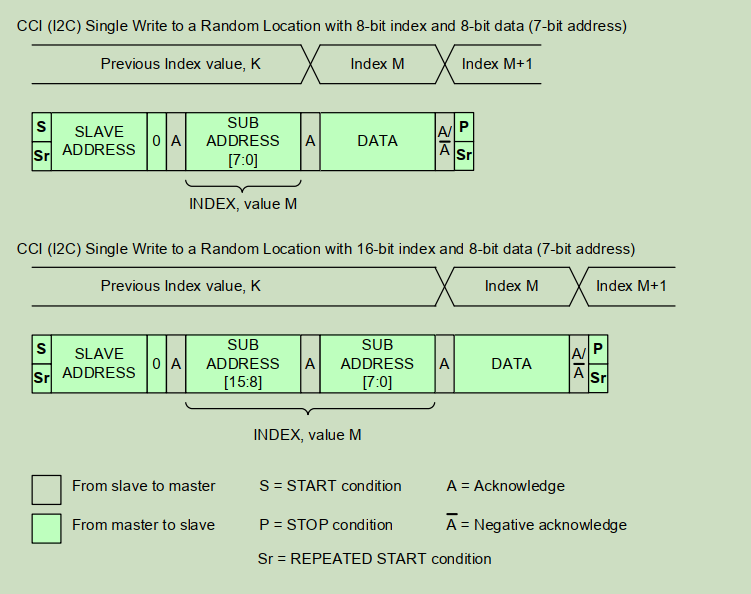
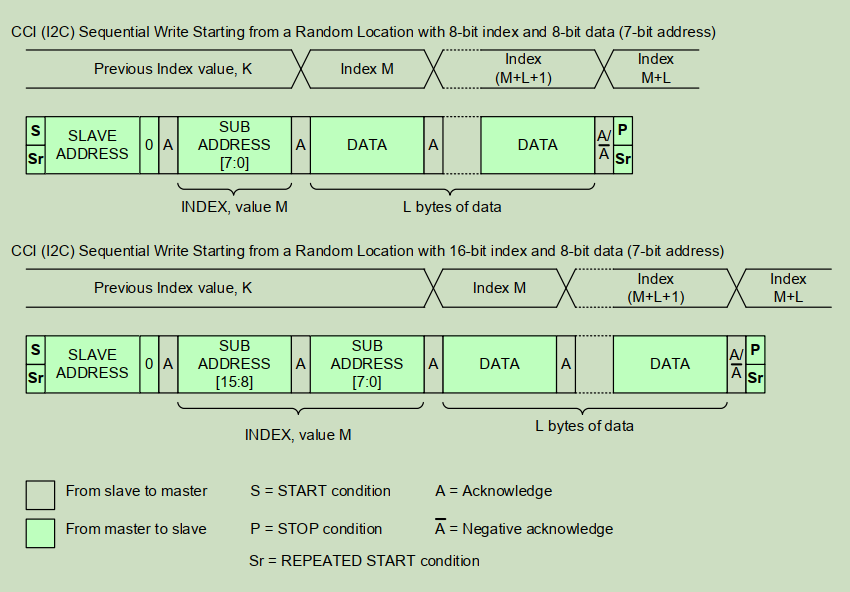
2.1.8 CCI (I²C) Sequential Write Starting from Random Location
从随机位置开始的连续写如 Figure 9 所示。slave 在每接收到一个数据字节后自动递增 INDEX。该操作以 master 发出的 STOP 或 Repeated START 条件结束。
3 物理层 - Physical Layer
CSI-2 v3.0 允许使用的两类 PHY - DPHY和CPHY
3.1 D-PHY物理层选项
- CSI-2 v3.0 兼容的 D-PHY 版本:v1.1、v1.2、v2.0、v2.1、v2.5。规范要求实现至少符合其中一个版本。
- 物理拓扑:1 条时钟 Lane(Clock Lane) + N 条数据 Lane(Data Lane) ,每条 Lane 是 2 线差分对。
- Clock Lane 单向,从 TX → RX 传 DDR 时钟。
- Data Lane 默认单向;但从 v3.0 起,Lane 1 允许做成双向(这是 USL 的前提条件,见 §7.3.1 与 §9.12)。
- 最大数据 Lane 数:规范不给硬性上限,由实现决定,常见 1/2/4/8。
- 速率档位由 D-PHY 规范本身定义(HS-G1 ≤ 1.5 Gbps、HS-G2 ≤ 2.5 Gbps、HS-G3 ≤ 4.5 Gbps;v2.5 起还有 LVLP / Alt-Low-Power 等 5 Gbps+ 档)。CSI-2 这一节不复述这些数字,只说"采用 D-PHY 规范定义的所有适用速率"。
- 必备的 D-PHY 信令:HS(高速差分)、LP(低功耗单端 LP-11/LP-01/LP-10/LP-00)、ULPS(超低功耗状态)、SoT/EoT。
- 可选的 D-PHY 特性,CSI-2 中按需启用:Alternate Low Power(ALP,主要用于 v2.5 的 5 Gbps 档)、Continuous Clock vs. Non-Continuous Clock。
工程意义:
- 选 sensor 时先看它实现的是 D-PHY 哪一版,再看支持几条 Data Lane、什么档位(Gbps/lane)。
- 是否支持 USL → 看它是否实现了"Lane 1 双向"和 ALP 选项
3.2 C-PHY 物理层选项
- CSI-2 v3.0 兼容的 C-PHY 版本:v1.0、v1.1、v1.2、v2.0。
- 物理拓扑:N 条 Lane ,每条 Lane 是 3 线(Trio) ,每条 Lane 自带嵌入式时钟(不再有专用 Clock Lane)。
- 每条 Lane 在每个 UI 内传 1 个 7-symbol → 16 bit 的码字("3-phase 编码")。
- 每条 Lane 默认单向;v3.0 起 Lane 1 也允许双向(USL 用途)。
- 速率衡量单位是 symbols/sec/lane(不是 bit/sec)。每个 symbol 携带约 2.28 bit 信息(16 bit / 7 symbols)。
- 必备的 C-PHY 信令:HS Burst、LP-000/001/010/100、Sync Word、Post Sync 等,全部由 MIPI02 定义。
- 可选特性:ALP(Alternate Low Power) 、Lane De-Skew(多 Lane 去偏移,详见 §8.3.1) 等。
工程意义:
- C-PHY 比 D-PHY 同样数量的物理线产能更高(3 线 vs 2 线,但每对 Trio 抵 D-PHY 的 1 条 Clock + 1 条 Data 之和),多用于高分辨率传感器。
- 接收端 Lane Management 必须以 16 bit(一对字节)为单位做分发/合并。
3.3 PHY对CSI-2 USL特性的支持
USL(Unified Serial Link)的核心思想:把原本走 SCL/SDA 的 CCI 控制链路与高速 CSI-2 数据链路合并到同一对/同一条 Lane 上,省掉物理 CCI 引脚。要做到这一点,PHY 必须额外具备一些能力。
3.3.1 D-PHY 对 USL 的支持要求
PHY 实现若想支持 USL,必须满足以下几条:
- Lane 1 必须支持双向操作("Reverse Direction" 或类似机制,由 D-PHY 规范定义)。这是 USL 让从设备能在同一根线上回传命令响应的物理基础。
- 支持 D-PHY v2.5 起引入的 Alternate Low Power(ALP)模式,并且 ALP 模式下也要能完成方向反转。
- 时钟 Lane 行为要满足 USL 命令流对时钟连续性的要求(具体细节看 §9.12 中 USL 的时序章节)。
- 复位 / 上电时序要与 USL 状态机(§9.12.5)约定的初始 PHY 状态一致。
3.3.2 D-PHY 对 USL 的支持要求
C-PHY 想支持 USL 的实现必须:
- Lane 1 支持双向操作。
- 支持 ALP 模式(C-PHY v1.2 起引入),并且 ALP 状态机要能与方向反转配合。
- 满足 USL 在 C-PHY 上对 Sync Word / Post 序列的额外约束(用于在没有 LP-11 idle 的 ALP 流程中区分命令与数据)。
- 与 D-PHY 相同
3.3.3 D-PHY vs C-PHY
| 维度 | D-PHY 选项 | C-PHY 选项 |
|---|---|---|
| 适用版本 | v1.1 / v1.2 / v2.0 / v2.1 / v2.5 | v1.0 / v1.1 / v1.2 / v2.0 |
| 物理拓扑 | 1 条 Clock Lane + N 条 Data Lane(每条 2 线差分) | N 条 Lane,每条 3 线 Trio,时钟嵌入 |
| 速率单位 | bit/sec/lane | symbol/sec/lane(≈ ×2.28 → bit/sec) |
| Lane 1 双向 | v3.0 起允许(USL 必备) | v3.0 起允许(USL 必备) |
| USL 必备 PHY 特性 | Lane 1 双向 + ALP(v2.5+) | Lane 1 双向 + ALP(v1.2+) |
| 多 Lane De-Skew | 由 D-PHY 自然解决(共享时钟) | 需显式 De-Skew(§8.3.1) |
| Lane Management 粒度 | 1 字节 | 2 字节(16 bit) |
C-PHY相比D-PHY物理产能更高,D-PHY 是 NRZ + DDR :1 个 UI(Unit Interval)= 1 bit。所以 D-PHY 每条数据 Lane 的速率单位就是 bit/s/lane ,比如 2.5 Gbps/lane。C-PHY 不是"每个 UI 1 个 bit",它是 3 线 6 态相位编码:
- 3 根线在每个 UI 里组合出 6 种合法状态("3-phase 6-state");
- 一个 UI 只能搬 1 个 Symbol(log₂6 ≈ 2.58 bit);
- 但 C-PHY 把 7 个连续 Symbol 映射成 16 个 bit (7 × log₂6 ≈ 18 bit 的容量里挤进 16 bit),所以每个 Symbol 平均搬 16/7 ≈ 2.28 bit。
- 速率单位是 Msym/s 或 Gsym/s 每 Lane,再乘 2.28 才换算成 bit/s。
| 物理资源 | D-PHY(HS-G3, 4.5 Gbps/lane) | C-PHY v2.0(≈ 4.5 Gsym/s/lane ≈ 10.28 Gbps/lane) |
|---|---|---|
| 每条 Lane 用线 | 2 根 | 3 根 |
| 每条 Lane 速率 | 4.5 Gbps | ≈10.28 Gbps |
| 4 Lane 需要的总线数 | 2×4 + 2(clk) =10 根 | 3×4 =12 根 |
| 4 Lane 总带宽 | 18 Gbps | ≈41 Gbps |
| bit/s/线("线产能") | 18 / 10 ≈1.8 Gbps/线 | 41 / 12 ≈3.4 Gbps/线 |
工程上的影响:
- 包边界对齐 :CSI-2 的所有包长度其实都是 byte 数。在 D-PHY 上,任何字节数的包都能整数地分到 Lane 上;在 C-PHY 上,包数据如果不是 16-bit 的整数倍,必须靠 Filler(填充字节)补齐,否则末尾凑不出一个完整的 16-bit 码字单元。这就是为什么规范专门定义了 Filler/Spacer 这套元素(参见 §9.11 LRTE 一节)。
- Lane 数选择:C-PHY 上即便你用 1 条 Lane,也是按 16-bit 一组分发;用 N 条 Lane 时,是按 16-bit→Lane0、下一个 16-bit→Lane1...轮转。
- 接收端实现:RX IP 在 C-PHY 模式下,PPI 接口位宽是 16 bit/Lane,MERGE 模块要把所有 Lane 的 16-bit 字按 round-robin 拼回字节流。这与 D-PHY 模式下 8-bit/Lane 的实现是两套数据通路,硬件上往往做成可配置或两套独立逻辑。
- De-Skew:C-PHY 多 Lane 之间的偏移要靠显式 De-Skew 序列对齐到 16-bit 单元边界(§8.3.1),这也是因为对齐粒度是 16 bit 而不是 1 bit。
4 多通道分发与合并 - Multi-Lane Distribution and Merging
本章描述协议层(LLP)输出的是单条字节流,物理层却有多条 Lane 在并行跑,中间这层"分发器/合并器"该如何工作
4.1 核心概念
1.CSI-2 是可缩放的(scalable)------不规定 Lane 数上限,应用按带宽需求选择 1/2/3/4/8 Lane 等。
2.TX 端的 Distributor:把上层协议(LLP)输出的"字节流"按规则轮转(round-robin)分配到N条Lane上
3.RX 端的 Merger :把 N 条 Lane 收到的数据按相反顺序拼回原始字节流,交给 LLP 解析。
4.关键约束:发送/接收两端必须事先知道 Lane 数量 (通常通过 CCI 寄存器配置),否则 round-robin 的对齐方式不一致就会乱码。CSI-2 规范本身不定义自动协商机制。
5.Filler(填充字节)的作用:当包末尾不能整除 Lane 数(D-PHY)或不能整除 16-bit 单元(C-PHY)时,TX 必须补 Filler,使所有 Lane 同时结束该次传输。RX 必须根据 Word Count 字段识别并丢弃 Filler。
4.2 D-PHY物理层的lane Distribution
D-PHY 模式下,字节流按以下格式摊发到 N 条数据 Lane 上
4lane:
原字节流: B0 B1 B2 B3 B4 B5 B6 B7 B8 ...
Lane 0: B0 B4 B8 ...
Lane 1: B1 B5 ...
Lane 2: B2 B6 ...
Lane 3: B3 B7 ...分发粒度 = 1 字节,是D-PHY 上 PPI 接口的天然位宽
轮转方式=Round-Robin,第 0 个字节给 Lane 0,第 1 个字节给 Lane 1,......,第 N 个字节回到 Lane 0,依次类推
所有 Lane 同时启动 SoT、同时结束 EoT
4.2.1 Filter的使用
如果一个包的总字节数 不是 N(Lane 数)的整数倍 ,TX 必须在最后一条 Lane 后补 Filler 字节(值未规定,任意字节即可),使所有 Lane 在同一时刻结束传输。
比如:4 Lane,包含 PH(4) + Payload(13) + PF(2) = 19 byte 的长包。19 / 4 = 4 余 3
Lane 0/1/2 各发 5 个字节;Lane 3 需要补 1 个 Filler,凑成 5 字节,所有 Lane 同时 EoT。
注意:对短包(4 字节),N ≥ 4 时 Lane N-1 后面的 Lane 全部填 Filler。N > 4 时这种方式就显得浪费------这正是后面LRTE 要解决的问题之一。
当Lane为 1 时,就不需要分发了
4.3 D-PHY物理层的lane Distribution
C-PHY 的物理层不是按字节工作的,相比D-PHY规则不一样
3 Lane:
原字节流: B0 B1 | B2 B3 | B4 B5 | B6 B7 | B8 B9 | Ba Bb ...
组成 16-bit: W0 W1 W2 W3 W4 W5
Lane 0: W0 W3
Lane 1: W1 W4
Lane 2: W2 W54.3.1 Filter的使用
C-PHY 上的 Filler 必须两个层次都对齐:
1.包字节数必须凑成 16-bit 整数倍:奇数字节包要补 1 个 Filler 字节凑成偶数
2.凑齐 Word 后还要让 Word 数能被 N(Lane 数)整除:不够的 Lane 后面继续补 Filler Word(每个 Word = 2 byte)
比如3lane,PH(4) + Payload(13) + PF(2) = 19 byte 的长包
1.第一步凑成偶数:补 1 byte → 20 byte = 10 个 Word。
2.第二步分到 3 Lane:10 / 3 = 3 余 1 → Lane 0 拿 4 Word,Lane 1/2 各拿 3 Word,需要再给 Lane 1/2 各补 1 个 Filler Word → 全部 4 Word/Lane
3.总共补了 1 byte + 2 Word = 5 个 Filler 字节。这就是 C-PHY 在小包/Lane 数较多时效率不如 D-PHY 的原因之一
本节还涉及:
C-PHY Sync Word 与 Post 序列的位置:C-PHY每条 Lane 的 burst 头尾各有 PHY 层的 Preamble / Sync Word / Post,这些不计入字节流,由 PHY 自己处理
PPI 接口位宽 :C-PHY 模式下 LLP ↔ Lane Management ↔ PHY 接口都是 16 bit/Lane,硬件实现上与 D-PHY 模式下 8 bit/Lane 是两套数据通路
4.4 多 Lane 互操作性
4.4.1 主要规则
1.TX Lane 数 ≥ RX Lane 数 时怎么办? 规范允许 TX 实现的物理 Lane 数比 RX 端可用的 Lane 数多。但实际工作的 Lane 数必须是双方都支持的最小值,由 CCI 配置决定。多余的 Lane 在工作期间应处于 LP 状态。
2.TX Lane 数 < RX Lane 数 时:RX 多余的 Lane 应保持 LP/未使用状态
3.Lane 数运行时切换:CSI-2 不强制要求支持运行时切换 Lane 数;如果实现支持,必须在 LP 空闲期完成(不能在 HS Burst 中途切)
4.Lane Mapping(Lane 编号与物理引脚的对应):协议层只管 "逻辑 Lane 0 / 1 / 2 ......",物理引脚 A/B/C/D 哪条对应哪个逻辑 Lane 由实现决定(很多 SoC 提供 Lane Swap 寄存器以方便 PCB 布线)
4.4.2 C-PHY Lane De-Skew - Lane去偏移
这是C-PHY独有的问题
问题来源:
D-PHY 的所有数据 Lane 共享同一条 Clock Lane,时钟同源 → 多 Lane 之间的偏移可以由 RX 用接收时钟一次解决。而C-PHY 每条 Lane 自带独立的嵌入式时钟 ,N 条 Lane 之间无固有时钟关系,PCB 走线长度差、TX 内部延迟差都会造成 Lane 间到达时间偏移(Inter-Lane Skew),导致 RX 无法把同时刻发出的 Word 对齐回去。
解决方法:
De-Skew 校准序列。TX 在某些时机(典型场景:链路上电后、长时间 HS 之后)发送一段已知的 De-Skew Pattern,RX 用这个 Pattern 测量每条 Lane 的到达时间偏差,调整内部缓冲对齐,从而把所有 Lane 在 RX 内部"重新对齐"到同一字节边界
触发时机:
规范规定了若干必须或建议执行 De-Skew 的场景(链路初始化、速率切换后、长 burst 之后等);具体序列结构由 MIPI02 C-PHY 规范定义,CSI-2 这一节只是引用并说明在 CSI-2 协议层的触发点。
可选性:
De-Skew 是否实现取决于运行的速率档位------速率较低时单个 UI 较长,Lane 间偏移在容差内,可不做 De-Skew;速率拉高(Gen2/Gen3 以上)后必须做
| 维度 | D-PHY 模式(§8.1) | C-PHY 模式(§8.2) |
|---|---|---|
| 分发粒度 | 1 byte | 16 bit(2 byte 一组的 Word) |
| 字节序 | 直接按字节顺序 | 第一字节 = LSB,第二字节 = MSB |
| 轮转方式 | Round-robin by byte | Round-robin by 16-bit Word |
| Lane 间时钟 | 共享 Clock Lane → 天然同步 | 每 Lane 独立嵌入时钟 → 需 De-Skew |
| 包尾对齐 | Filler 字节凑到 N 整数倍 | 先凑偶数 byte,再凑成 N 的整数倍 Word |
| 同时 SoT/EoT | 物理上必然同时 | 逻辑上要求同时,需 De-Skew 保证 |
| PPI 接口位宽 | 8 bit/Lane | 16 bit/Lane |
| De-Skew | 不需要 | §8.3.1 定义触发点,序列在 MIPI02 |
| Lane Mapping | 由实现决定 | 同左 |
工程角度的影响:
1.Lane 数选择不是越多越好:
- 短包在多 Lane 上会浪费大量 Filler(C-PHY 尤其明显)。
- 高分辨率视频流的连续长包用 4/8 Lane 收益显著;以短包为主的场景(控制、低分辨率元数据)反而 1/2 Lane 更高效。
2.C-PHY 调试时 Lane 间走线长度差要注意
- 必须打开 De-Skew,且要让 PCB 走线长度差控制在 De-Skew 校准能覆盖的范围内,一般 SoC RX 会给出数据手册指标,例如 ±数十 ps
3.包长度规划
如果能控制 sensor 输出的行长(line length),最好让 (行字节数 + PH + PF) 是 N(Lane 数)的整数倍 (D-PHY)或 16-bit × N 的整数倍(C-PHY),可以彻底消除 Filler 开销
4.Lane Swap / Lane Mapping
调试 PCB 反接、误布线时不必改硬件,先看 SoC RX 是否提供 Lane swap 寄存器,逻辑 Lane 0--N 的物理映射可以软件改
5 底层协议 - Low Level Protocol, LLP
子节内容速查表
| 子节 | 内容 | 关键概念 | 是否可选 |
|---|---|---|---|
| 9.1 | 包格式 | PH(4) / PF(2) / Short Pkt(4) | 必须 |
| 9.2 | DI | VC1:0 + DT5:0 | 必须 |
| 9.3 | VC | 4/16/32 VC | 16/32 VC 可选 |
| 9.4 | DT | 64 个码值 | 必须 |
| 9.5 | ECC(D-PHY) | Hamming SECDED | D-PHY 必须 |
| 9.6 | CRC | CRC-16-CCITT | 必须 |
| 9.7 | 包间隔 | LP 切换时序 | 必须遵守 |
| 9.8 | 同步包 | FS/FE 必须,LS/LE 可选 | 部分必须 |
| 9.9 | 通用短包 | DT 0x08--0x0F | 用户可用 |
| 9.10 | LP 间隔示例 | 资料性 | --- |
| 9.11 | LRTE | EPD/PDQ/Spacer | 可选 |
| 9.12 | USL | Lane 1 双向、SNS、ALP | 可选 |
| 9.13 | 加扰 | PRBS-16、附录 G 种子 | 可选 |
| 9.14 | SROI | SEDP、子区域元数据 | 可选 |
| 9.15 | 长度规则 | WC 不含 Filler | 必须 |
| 9.16 | 帧示例 | 资料性 | --- |
| 9.17 | 交织 | DT 交织、VC 交织 | 可选 |
5.1 包格式
CSI-2 字节流由两类包组成:长包 和短包。
5.1.1 长包 - Long Packet
经典三段结构:
| Packet Header (PH, 4 byte)
| ├─ DI (1 byte) = VC[7:6] + DT[5:0]
| ├─ WC (2 byte) = Word Count,Payload 字节数(不含 PH/PF)
| └─ ECC (1 byte) = 对前 3 byte 的 Hamming 码
| Payload (WC 字节,应用数据)
| Packet Footer (PF, 2 byte) = CRC-16WC 字段范围 0--65535,决定 Payload 长度(注意单位是 byte 而不是 word)
PH 的 ECC 与 PF 的 CRC 是两套独立的差错保护:ECC 保护 PH,CRC 保护 Payload
长包用于像素数据、嵌入数据、用户自定义数据等"有 payload"的场景
5.1.2 短包 - Short Packet
只有 4 byte,结构是:
| DI (1 byte) | Data Field (2 byte) | ECC (1 byte) |- 没有 Payload,没有 PF。
- Data Field 在同步包里被复用为 Frame Number / Line Number;在通用短包里由用户定义。
- 短包用于 FS/FE/LS/LE 同步事件、用户事件标记。
5.2 Data Identifier - DI
DI 是 PH/Short Packet 第 1 个字节,决定了"这个包归谁、是什么":
| Bit | 含义 |
|---|---|
| 7:6 | VC1:0(Virtual Channel 的低 2 bit) |
| 5:0 | DT5:0(Data Type,6 bit,共 64 种) |
演进:v2.0 起规范允许 16 VC 扩展,v2.1 起允许 32 VC,VC 的高位通过 PH 中的额外字段(在 PH 第 2/3 字节里挪出 bit)来携带
5.3 Virtual Channel(VC)
CSI-2 用 VC 在同一物理链路上区分多路独立的数据流(多 sensor、多曝光、HDR、SROI 等都依赖它)
三种规模:
| 规模 | 来源 | VC 位置 |
|---|---|---|
| 4 VC(基本) | v1.0 起 | DI7:6 共 2 bit |
| 16 VC | v2.0 起 | DI7:6 + PH 中保留位的高 2 bit |
| 32 VC | v2.1 起 | DI7:6 + PH 中保留位的高 3 bit |
要点:
- 16/32 VC 模式下,原本"保留必须为 0"的 PH 比特被重新启用,因此ECC 算法也要相应调整(详见 §9.5.2 改进型 Hamming)。
- 16/32 VC 的支持是可选的,两端必须协商一致(通常 CCI 寄存器配置)。
- 同步短包(FS/FE/LS/LE)也带 VC,所以可以做到"VC 0 帧开始 / VC 1 帧开始"独立交织
5.4 Data Type(DT)
DT 是 6 bit,CSI-2 把它划分成几个区段(具体编码值见原文 Table):
| DT 区段 | 用途 |
|---|---|
0x00--0x0F |
同步短包(FS=0x00、FE=0x01、LS=0x02、LE=0x03、保留、Generic Short Packet 0x08--0x0F 等) |
0x10--0x17 |
Generic Long Packet(用户自定义长包 1--4,Null/Blanking 等) |
0x18--0x1F |
YUV 数据(YUV420 8b/10b、Legacy YUV420 8b、YUV422 8b/10b) |
0x20--0x27 |
RGB 数据(RGB444/555/565/666/888) |
0x28--0x2F |
RAW 数据(RAW6/7/8/10/12/14/16/20/24) |
0x30--0x37 |
用户自定义数据格式 1--8 |
0x38--0x3F |
保留 |
工程上,每个sensor出的数据格式(RAW10、YUV422 8bit 等)就对应一个 DT 值;调链路时如果 RX 端 DT 配置错了,CRC 都对,但解出来全乱。
5.5 D-PHY 物理层选项的包头 ECC
ECC 仅在 D-PHY 上使用。C-PHY 的包头不用这套 Hamming 码,因为 C-PHY 自带 7-Symbol→16-bit 编码本身就有强健的 burst 错误检测能力
5.5.1 ECC算法
- 对 PH 前 3 个字节(24 bit)算 8 bit Hamming 码 → 共 32 bit。
- 能力:纠 1 bit 错、检 2 bit 错(SECDED)。
- 16/32 VC 场景下用"改进型 Hamming"------把原来定义为保留位(必须为 0)的几位也纳入 ECC 计算范围
5.5.2 发送/接收侧实现
- TX:按 PH 前 3 byte 对应每个 ECC bit 的 XOR 表生成
- RX:用同样的 XOR 表得到 syndrome,根据 syndrome 决定无错、纠 1 bit 还是报告不可纠错误
5.6 Checksum(CRC-16)
- 仅长包有,放在 PF(包尾)2 byte 里。
- 多项式:
x^16 + x^12 + x^5 + 1(即标准 CRC-CCITT)。 - 初值规定(一般 0xFFFF),从 Payload 第一字节算到最后一字节。
- TX 在 Distribute 之前算(基于完整字节流),RX 在 Merge 之后校验。
- 空 Payload 长包(WC=0)有特殊规定(原文给出固定 CRC 值)。
5.7 Packet Spacing
- 同一 Burst 内连续包之间允许 0 字节间隔(背靠背)。
- 跨 Burst 时,PHY 要进入 LP 状态再回 HS,此过程中的 EoT/SoT 时序由 D-PHY/C-PHY 规范决定,本节只规定协议层视角的"包之间最少要保留多少字节用于 PHY 切换"。
5.8 同步短包
CSI-2 的"帧/行边界"完全靠这 4 种短包:
| 名称 | DT | 作用 | Data Field |
|---|---|---|---|
| FS | 0x00 | Frame Start | Frame Number(可选递增) |
| FE | 0x01 | Frame End | Frame Number |
| LS | 0x02 | Line Start(可选) | Line Number |
| LE | 0x03 | Line End(可选) | Line Number |
- FS、FE 必须有 ;LS、LE 是可选的,多数 sensor 不发。
- VC 信息在 DI 里,所以可以"VC0 FS / VC1 FS"分别表示不同流的帧开始
- Frame Number / Line Number 取值规范允许全 0,也允许递增(用于 RX 检测掉帧)。
5.9 通用短包
DT = 0x08--0x0F 共 8 个码值留给用户自定义短包,Data Field 由用户解释。常用于 sensor 厂商的私有事件标记(如曝光开始、AF 触发)
5.10 使用LP(低功耗)状态时包间隔示例
- 每个包都进 LP 再起 HS(最省功耗,时延大)。
- 多个包在一个 Burst 内连发(折中)。
- 全程 HS 不进 LP(最高吞吐,最费功耗)。
后两种是 §5.11 LRTE 要进一步优化的场景
5.11 LRTE:Latency Reduction Transport Efficiency
5.11.1 ILR - Interpacket Latency Reduction
问题场景:传统 D-PHY 在每个包之间进 LP-11 → 切回 HS → 重发 SoT,这套切换非常耗时(典型 ~100 ns 量级)。对短包密集的场景(很多小 ROI、很多元数据)效率极差。
ILR解决方法:在 PHY 层引入 EPD(Efficient Packet Delimiter) 和 PDQ(Packet Delimiter Quick) 两种"极短"信令,让连续包之间不必进 LP 也能彼此分隔
- EPD:包与包之间用一个短 PHY 信令分隔,不进 LP-11
- PDQ:更短的分隔信令,专门用于背靠背包
- Spacer / Filler:协议层配合 PHY,在包之间插入若干 byte,使 PHY 有足够时间完成分隔操作
5.11.2 ILR与增强传输效率联用
ILR 配合一些增强(如长 Burst 内多包合并)可以把 PHY 利用率拉到接近 100%
5.11.3 LRTE寄存器表
LRTE 涉及若干 CCI 可读寄存器,让 RX 知道 TX 的 LRTE 能力(是否支持 EPD/PDQ、Spacer 长度配置等)。这些寄存器是 LRTE 协商的唯一依据,规范不规定自动协商
工程提示:开 LRTE 后,RX 必须正确实现 EPD/PDQ 检测;很多老 RX IP 不支持 → 错把 EPD 当成乱码。开之前一定查 SoC RX 数据手册。
5.12 USL - 统一串行链路
v3.0 引入的最重大新特性 ,目标:省掉物理 CCI 引脚(SCL/SDA),让控制命令和数据流共享 Lane 1
5.12.1 USL技术概述
- USL服用Lane 1双向能力
- 前向(TX→RX)走数据;反向(RX→TX)走 USL 命令;命令响应再回前向
- 使用 ALP 状态进入反向窗口
5.12.2 USL命令负载结构
USL 命令有专门的命令字格式:包含 Slave Address、寄存器地址、读/写数据、CRC 等。本质上把 I²C/I3C 的语义"包装"到 PHY 反向 Burst 里。
5.12.3 USL操作流程
四类基本操作:
- USL Single Write
- USL Sequential Write
- USL Single Read
- USL Sequential Read
时序上是 RX 端发"命令请求",TX 端在数据流间隙处理并回应
5.12.4 USL命令传输完整性监控
USL 命令带 CRC,并定义了命令丢失/损坏后的重试与超时机制
5.12.5 USL上电/复位,SNS配置与模式切换
- USL 模式不是默认的,需要通过专门的 SNS(Startup Negotiation Sequence) 在上电后协商进入。
- 退出 USL 模式(切回独立 CCI)也有规定流程。
工程注意:USL 虽然省两根线,但增加了 PHY 复杂度(双向、ALP)和软件复杂度(SNS)。车载/工业领域倾向用 USL 节省线束;手机内部短距离反而很少用。
5.13 Data Scrambling
可选特性。目的:降低长串相同码的 EMI 集中辐射,把频谱打散
5.13.1 D-PHY上的加扰 --- 加扰的目的是什么?
- 用 PRBS-16 (多项式
x^16 + x^14 + x^13 + x^11 + 1)对 Payload 字节流逐字节 XOR - 每条 Lane 用不同的种子(保证 Lane 间不相关) ----- 这个种子是什么?
- PH 与 PF 不加扰(要保证差错保护机制本身能用)
5.13.2 C-PHY上的加扰
- 类似 PRBS,但作用在 16-bit Word 级别
- 因为 C-PHY 有 7-Symbol→16-bit 编码,加扰必须在编码前完成
5.13.3 加扰细节
- 加扰种子在每个 Frame Start 时复位------保证 RX 能确定性地解扰
- TX/RX 必须使用相同的多项式与种子表
- 加扰是"可选启用、必须协商"------通过 CCI 寄存器告知 RX 当前加扰状态
5.14 SROI:Smart Region of Interest(智能感兴趣区域)
SROI是V3.0引入的另一项重要特性:
5.14.1 SROI帧格式简述
传统帧:每行都发,整帧矩形。 SROI 帧:sensor 自己识别出"有意义的子区域"(例如人脸、车牌),只发这些子区域 + 元数据,省带宽。
5.14.2 嵌入数据包的传输与检测
SROI 在帧中插入 SEDP(SROI Embedded Data Packet),用专门 DT 表示"接下来几行属于哪个 ROI"
5.14.3 SROI用例
- 多目标跟踪(每个目标一个 ROI)
- 高动态范围合成(HDR ROI)
- 注视点渲染(中心 ROI 高分辨率,外围低分辨率)
9.14.5 SEDP格式
详细规定 SEDP 字段:ROI ID、坐标 (x, y, w, h)、数据流绑定的 VC/DT 等
工程视角:要用 SROI,sensor、ISP、应用三端都要支持。目前主要在监控、ADAS、AR/VR 摄像头里出现。
5.15 包负载长度规则
集中归纳每种 DT 对 Payload 长度的约束:
- 每种像素 DT 的 Payload 字节数 = 行像素数 × bit/pixel ÷ 8(必要时凑整)。
- 不同 DT 有不同的"Payload 必须是 N byte 整数倍"约束(例如 RAW10 必须 5 byte 一组,YUV422 必须 4 byte 一组)。
- WC 字段必须严格等于 Payload 实际字节数(不含 Filler)------这是 RX 区分 Payload 与 Filler 的依据。
5.16 帧格式示例
给若干典型场景的完整帧结构示意:
- 基本帧:FS → 行长包 ×N → FE
- 带嵌入数据的帧:FS → 嵌入数据长包 → 行长包 ×N → 嵌入数据长包 → FE
- 多 VC 交织帧:VC0 FS → VC0 行 → VC1 FS → VC1 行 → VC0 行 → VC0 FE → VC1 FE
- HDR 多曝光帧:长曝光行 + 短曝光行交替,DT 不同或 VC 不同
5.17 Data Interleaving
CSI-2 允许在同一物理链路上把多路数据流交织发送。两种维度:
5.17.1 数据类型交织(DT interleaving)
同一 VC 下,可以交错发送不同 DT 的长包。常见用途:每行像素后面紧跟一行嵌入数据;HDR 同 VC 不同 DT。
5.17.2 虚拟通道交织(VC Interleaving)
不同 VC 各自独立的数据流交错发送。RX 必须按 VC 拆开缓冲。多 sensor 共享一条 CSI-2 链路时这是核心机制。
重要约束 :交织必须是包级别(一个包发完才能切到另一个流),不能在长包中途切。FS/FE 之间的"帧"是 per-VC 的概念,VC0 的帧和 VC1 的帧可以重叠存在。
5.18 工程场景实用调试手段
1.调链路问题的排查顺序:
先看 SoT/EoT(PHY 层是否打通 -> 看 ECC 是否通过(PH 是否对) -> 看 CRC 是否通过(Payload 是否完整)-> 看 DT 是否匹配(解码是否正确)-> Frame Number 是否连续(是否掉帧)
2.VC两端必须协调一致
用 4 VC 的 RX 接 16 VC 的 TX,TX 把高 VC 位放进 PH 保留位,对面 RX 要么忽略要么报错
3.LRTE/USL/SROI/Scrambling 都是可选 ,开关由 CCI 寄存器控制;任何一个开错都会让 RX 把数据当成噪声丢弃。调试新链路时务必先把这些可选项关掉,跑通基本数据流后再逐项打开。
4.WC字段是RX的唯一依据,Filler 不计入 WC。如果看到 RX 收到的行字节数和 WC 不一致,多半是 TX 在算 Filler 时算错。
5.嵌入数据(DT 0x12)通常放在 FS 之后第一个长包,承载本帧 3A 元数据。Driver 层经常忽略它会导致 ISP 拿不到曝光参数
6.颜色空间 - Colorspace
描述了像素的数值代表什么颜色含义
6.1 RGB颜色空间
- 格式名:sRGB(IEC 61966-2-1)。
- 含义:每个像素由 R、G、B 三个分量组成,每个分量是非线性 gamma 编码后的强度值。
- 取值范围 :每分量
0 ~ 2^N - 1(N 是 bit 深度,详见第 11 章)。0是黑、max是白。 - 位深度选择:4/5/6/8 bit 各分量都允许(对应 RGB444/555/565/666/888)。
- 不规定 alpha 通道------CSI-2 的 RGB 都是纯彩色数据
6.2 YUV颜色空间
- 格式名:ITU-R BT.601(标清)和 BT.709(高清)。规范允许两者,由应用层决定,CSI-2 协议本身不在字节流里区分。
- 含义:Y = 亮度(Luma),U/V(Cb/Cr)= 色度差。
- 采样比 :CSI-2 支持 YUV422 (U/V 水平 1/2 抽样)和 YUV420 (U/V 水平垂直均 1/2 抽样)两种。不支持 YUV444(CSI-2 协议表里没有这个 DT)。
- 位深度:8 bit 和 10 bit。
- 取值范围:BT.601/709 的标准范围(Y: 16--235、UV: 16--240,"video range"),但 CSI-2 不强制 → sensor 也可输出 0--255 的 "full range",由应用约定。
- CSPS(Chroma Shifted Pixel Sampling,色度偏移像素采样):YUV420 子采样时,色度是落在两行像素之间还是落在某一行上的偏移约定。CSI-2 引入这个标记是为了和不同 sensor 厂商的子采样位置对齐。
7.数据格式 - Data Formats
速查表
| DT | 类别 | 位深 | 打包单元(像素→字节) | WC 约束 | 行像素约束 |
|---|---|---|---|---|---|
| 0x10 | Null | 8 | 1→1 | 任意 | 任意 |
| 0x11 | Blanking | 8 | 1→1 | 任意 | 任意 |
| 0x12 | Embedded | 8 | 1→1 | 任意 | 任意 |
| 0x14--0x17 | 用户长包 1--4 | 8 | 1→1 | 任意 | 任意 |
| 0x18 | YUV420 8-bit | 8 | 偶/奇行不同 | 4 倍数 | 偶数 |
| 0x19 | YUV420 10-bit | 10 | 偶/奇行不同 | 5 倍数 | 4 倍数 |
| 0x1A | Legacy YUV420 8-bit | 8 | 偶/奇行不同 | 6 倍数 | 4 倍数 |
| 0x1E | YUV422 8-bit | 8 | 2→4 | 4 倍数 | 偶数 |
| 0x1F | YUV422 10-bit | 10 | 2→5 | 5 倍数 | 偶数 |
| 0x20 | RGB444 | 12 | 2→3 | 3 倍数 | 偶数 |
| 0x21 | RGB555 | 15 | 1→2 | 2 倍数 | 任意 |
| 0x22 | RGB565 | 16 | 1→2 | 2 倍数 | 任意 |
| 0x23 | RGB666 | 18 | 4→9 | 9 倍数 | 4 倍数 |
| 0x24 | RGB888 | 24 | 1→3 | 3 倍数 | 任意 |
| 0x28 | RAW6 | 6 | 4→3 | 3 倍数 | 4 倍数 |
| 0x29 | RAW7 | 7 | 8→7 | 7 倍数 | 8 倍数 |
| 0x2A | RAW8 | 8 | 1→1 | 任意 | 任意 |
| 0x2B | RAW10 | 10 | 4→5 | 5 倍数 | 4 倍数 |
| 0x2C | RAW12 | 12 | 2→3 | 3 倍数 | 偶数 |
| 0x2D | RAW14 | 14 | 4→7 | 7 倍数 | 4 倍数 |
| 0x2E | RAW16 | 16 | 1→2 | 2 倍数 | 任意 |
| 0x2F | RAW20 | 20 | 2→5 | 5 倍数 | 偶数 |
| --- | RAW24 | 24 | 1→3 | 3 倍数 | 任意 |
| 0x30--0x37 | 用户格式 1--8 | 任意 | 任意 | 任意 | 任意 |
7.1 通用8-bit长包数据类型(DT 0x10-0x17)
CSI-2 在 RAW/YUV/RGB 之外还预留了几个与像素无关的通用长包:
| DT | 名称 | 用途 |
|---|---|---|
| 0x10 | Null Data | 无有效内容的填充包,用于占位/对齐 |
| 0x11 | Blanking Data | 行/帧消隐期数据,不参与图像 |
| 0x12 | Embedded 8-bit Non-Image Data | 嵌入数据,承载本帧的曝光、增益、温度等 sensor 元数据 |
| 0x13 | 保留 | --- |
| 0x14--0x17 | Generic Long Packet 1--4 | 用户自定义长包 |
打包规则:8 bit/像素,每字节就是一个数据单元,没有特殊位重排,是最简单的一类
7.2 YUV图像数据 (DT 0x18-0x1F)
CSI-2 里 YUV 共 5 种 DT:
| DT | 名称 | 子采样 | 位深 |
|---|---|---|---|
| 0x1A | Legacy YUV420 8-bit | 4:2:0 | 8 |
| 0x18 | YUV420 8-bit | 4:2:0 | 8 |
| 0x19 | YUV420 10-bit | 4:2:0 | 10 |
| 0x1E | YUV422 8-bit | 4:2:2 | 8 |
| 0x1F | YUV422 10-bit | 4:2:2 | 10 |
YUV422 8-bit 打包规则
每 2 个像素打包成 4 字节,按 U-Y-V-Y 顺序(每字节一个分量):
像素 P0 P1 P2 P3
字节 U01 Y0 V01 Y1 U23 Y2 V23 Y3 ...- 行字节数 = 行像素数 × 2。
- WC 必须是 4 的倍数(每 2 像素一组)。
YUV422 10-bit打包规则
每个分量占 10 bit,4 个像素(Y0 Y1 Y2 Y3 + U01 V01 U23 V23 = 8 个 10-bit 分量)= 80 bit = 10 byte:
前 8 个字节:每个字节装一个分量的高 8 bit (MSB)
最后 2 个字节:8 个分量的低 2 bit (LSB) 各塞 2 bit,共 16 bit- WC 必须是 10 的倍数。
- 接收端要按"高 8 在前、低 2 在后"重组每个分量。
YUV420 8-bit/10bit打包规则
YUV420 因为色度子采样在垂直方向也减半,奇数行和偶数行打包不一样:
- 偶数行:包含 Y 和 U/V → 类似 YUV422 的打包方式(但只放一半色度)。
- 奇数行 :只包含 Y,没有色度。
- 因此需要把"两行配对"才能算出完整像素。
具体字节排布规范有详细图示 ----- 此处需要加一副图
Legacy YUV420 8-bit (DT 0x1A)
兼容旧硬件而保留的"老式 4:2:0"打包,与新版 YUV420 (DT 0x18) 字节顺序略有不同------主要差别在 U/V 在字节流中的位置。新设计应优先用 0x18,遇到旧 sensor 再用 0x1A
CSPS
YUV420 的色度采样位置(落在偶数行还是行间)由 sensor 通过 CCI 寄存器告知 RX,CSI-2 字节流本身不带这个信息
7.3 RGB图像数据 (DT 0x20-0x27)
| DT | 名称 | 每像素总位数 | R/G/B 位宽 |
|---|---|---|---|
| 0x20 | RGB444 | 12 bit | 4/4/4 |
| 0x21 | RGB555 | 15 bit | 5/5/5 |
| 0x22 | RGB565 | 16 bit | 5/6/5 |
| 0x23 | RGB666 | 18 bit | 6/6/6 |
| 0x24 | RGB888 | 24 bit | 8/8/8 |
RGB888打包规则
每像素 3 字节,按 B-G-R 顺序:
像素 P0: B0 G0 R0
像素 P1: B1 G1 R1
...- 行字节数 = 行像素数 × 3。
- WC 必须是 3 的倍数。
注意是 B 在前(小端字节序的延伸),不是常见的 RGB 顺序。这是 CSI-2 的一个常见踩坑点------很多 SoC RX 默认按 RGB 顺序解,要软件转换。
RGB565 / 555 / 444 / 666 打包规则
- RGB565 :每像素 16 bit = 2 字节,按
{R[4:0], G[5:0], B[4:0]}拼成 16 bit。具体位排列见 §11.3.3 的图示。 - RGB555:每像素 16 bit(最高位填 0)。
- RGB444:每像素 12 bit,2 个像素打包成 3 字节(24 bit),节省空间。
- RGB666:每像素 18 bit,4 个像素打包成 9 字节(72 bit)。
打包共同规律:位多余不补对齐填零,把多个像素打包成最小整数字节
位序约定
- 字节内:MSB 在前(bit7 是最高位)。
- 字节流方向:像素 0 在前,像素从左到右
7.4 RAW图像数据(DT 0x28-0x2F)
RAW 是 sensor 直出 Bayer 阵列数据(未做去马赛克、未做颜色空间转换),绝大多数手机/车载/工业摄像头用的就是 RAW。共 9 种位深:
| DT | 名称 | 位深 | 像素↔字节关系 |
|---|---|---|---|
| 0x28 | RAW6 | 6 | 4 像素 → 3 byte (24 bit) |
| 0x29 | RAW7 | 7 | 8 像素 → 7 byte (56 bit) |
| 0x2A | RAW8 | 8 | 1 像素 → 1 byte(最直观) |
| 0x2B | RAW10 | 10 | 4 像素 → 5 byte (40 bit) ← 最常用 |
| 0x2C | RAW12 | 12 | 2 像素 → 3 byte (24 bit) |
| 0x2D | RAW14 | 14 | 4 像素 → 7 byte (56 bit) |
| 0x2E | RAW16 | 16 | 1 像素 → 2 byte |
| 0x2F | RAW20 | 20 | 2 像素 → 5 byte (40 bit) |
| --- | RAW24 | 24 | 1 像素 → 3 byte(v2.0 起新增) |
RAW10打包规则
每4个像素打包成5字节,规则如下:
4 个 10-bit 像素:P0 = p0[9:0] P1 = p1[9:0] P2 = p2[9:0] P3 = p3[9:0]
前 4 个字节:装每个像素的高 8 bit (MSB)
Byte0 = P0[9:2]
Byte1 = P1[9:2]
Byte2 = P2[9:2]
Byte3 = P3[9:2]
第 5 个字节:装 4 个像素各自的低 2 bit (LSB)
Byte4 = { P3[1:0], P2[1:0], P1[1:0], P0[1:0] }
↑ bit7..6 bit5..4 bit3..2 bit1..0- 行字节数必须是 5 的倍数 → 行像素数必须是 4 的倍数。
- WC 字段 = 行像素数 × 10 / 8 字节。
- 接收端解包时要把 byte4 拆成 4 段 LSB,分别拼回 P0--P3 的低 2 位
RAW12打包规则
每 2 个像素打包成 3 字节:
P0 = p0[11:0] P1 = p1[11:0]
Byte0 = P0[11:4]
Byte1 = P1[11:4]
Byte2 = { P1[3:0], P0[3:0] }
↑ bit7..4 bit3..0- WC 必须是 3 的倍数 → 行像素必须是偶数。
RAW14 打包规则
每 4 个像素打包成 7 字节:
Byte0 = P0[13:6]
Byte1 = P1[13:6]
Byte2 = P2[13:6]
Byte3 = P3[13:6]
Byte4 = { P1[1:0], P0[5:0] } ← P0 低 6 + P1 低 2
Byte5 = { P2[3:0], P1[5:2] } ← P1 低 6 + P2 低 4
Byte6 = { P3[5:0], P2[5:4] } ← P2 低 6 + P3 低 6- WC 必须是 7 的倍数 → 行像素必须是 4 的倍数。
- 解包逻辑比 RAW10/12 复杂,硬件实现要小心。
RAW20打包规则
每 2 个像素打包成 5 字节:
Byte0 = P0[19:12]
Byte1 = P0[11:4]
Byte2 = P1[19:12]
Byte3 = P1[11:4]
Byte4 = { P1[3:0], P0[3:0] }WC 必须是 5 的倍数 → 行像素必须是偶数
RAW16/RAW24打包规则
每像素 2 byte(RAW16)或 3 byte(RAW24),按小端序排(LSB byte 在前,MSB byte 在后)
RAW6/RAW7打包
低位深(高动态范围相机不用,多见于早期低分辨率 sensor),打包同样遵循"多个像素挤进最少整数字节"的原则:
- RAW6:4 像素 → 3 byte。
- RAW7:8 像素 → 7 byte。
共性总结
所有 RAW 打包遵循同一思路:
- MSB 部分按字节直接放(可能不是 8 位整数倍时用低位填充)。
- LSB 部分集中到末尾的"打包字节"中,按 P0、P1、P2... 的顺序从字节 LSB 端开始填。
- 行像素数必须是"打包单元"像素数的整数倍------这是 CSI-2 给行长度的硬约束。
MSB 各占整字节,LSB 共挤打包字节。
7.5 用户自定义数据格式(DT 0x30--0x37)
预留 8 个 DT 给应用层自定义打包格式。CSI-2 不规定内容,由 sensor 厂商和 ISP 约定。常见用途:
- 私有压缩数据流;
- AI 加速器需要的特殊位宽(例如 RAW18、RAW22);
- 多通道传感器融合数据。
7.6 工程背景相关
- 绝大部分车载/手机 sensor 用 RAW10 ,RAW12 次之。先把 RAW10 的 5-byte 打包记牢,调链路时心算 WC 不会算错。
- WC 计算口诀 :
- WC = 行像素数 × 位深 / 8(向上凑到打包单元的整数倍)。
- WC 不含 Filler,但含可能的"位深整数化填充"。
- 例:1920 像素 × RAW10 → WC = 1920 × 10 / 8 = 2400 byte(恰好整除,无需填充)。
- 行像素数不满足约束怎么办?
- sensor 通常会自动凑到允许的最小整倍数(例如 RAW10 需要 4 像素整倍,1278 像素的 sensor 会输出 1280 像素,多 2 像素无效)。
- 否则就只能 padding 或 cropping。
- 字节内位序与字节序 :
- 字节内统一 MSB 在前(bit7 高)。
- 多字节像素值(RAW16/RAW24)在字节流中LSB byte 在前(小端序)------这点和 RGB888 的 B-G-R 顺序一样容易踩坑,要看 SoC RX 数据手册的解包字节序设置。
- 不同 DT 不能在同一行混发 :一个长包只能是一种 DT。要混合数据(比如同一帧里有 RAW10 像素和 8-bit 嵌入数据),靠 §9.17.1 的 DT 交织------不同包用不同 DT,按行交替。
- YUV420 调试困难:因为奇偶行打包不同,单独看一行收到的字节数会和预期对不上------必须两行配对看。RX IP 通常需要专门的"行计数器"来区分奇偶行。
- DT 配错的典型症状 :
- DT 写成 RAW8 实际收 RAW10 → 图像位移、出现规律性条纹。
- DT 位深一致但顺序错(RGB888 当 BGR888 解)→ 颜色明显偏蓝/偏红。
- YUV422 的 U/V 顺序错 → 肤色偏青/偏紫。
- Sensor 输出对齐到 8 bit 的影响 :很多 ISP 内部按 16 bit 处理,会把 RAW10/12 的原始位左移到 MSB 对齐(即放到 bit15...bit6 位置,低位补 0)。这是 ISP 端的事,与 CSI-2 链路上的 5-byte 打包无关------别把两件事混淆。
8 推荐内存存储 - Recommended Memory Storage
本节描述了数据到了 RX 之后,建议放进内存的字节布局
第7章描述了线上字节序,既为了节省带宽,多个像素被紧凑打包,但 CPU/ISP 在内存中处理时 ,紧凑打包非常不友好------CPU 没有"10 bit 寄存器",每个像素必须按字节边界对齐才能高效读写,第12章的核心思想是RX 端解包时,把每个像素扩展到字节对齐的存储单元(8/16/32 bit)放入内存,方便后续 ISP/CPU 按指针偏移直接读取。本章节不是强制的标准,但几乎所有的SOC的CSI-2 RX IP都按这套布局实现,便于驱动和应用兼容。
通用约定:
行起始(Line Start)字节地址通常按 64 byte / 128 byte 对齐------配合 DMA burst、CPU cache line。
行末尾允许 padding 到对齐边界
像素在内存中按"逻辑顺序"排(即原始 P0、P1、P2... 顺序),而不是线上的打包顺序
多 byte 像素值(10/12/14/16 bit)在内存里通常按小端序存放(LSB byte 在低地址)
8.1 通用/任意数据接收
字节流照原样写入内存,由 CPU 自己解析。适用于 Embedded Data (DT 0x12)、Generic Long Packet 等"非像素"数据
8.2 YUV数据接收
YUV422 8-bit
内存布局保持 U-Y-V-Y 顺序写入,每像素对 4 byte
即"线上字节序 = 内存字节序",最直接
YUV422 10-bit
每个分量从 10 bit 扩展到 16 bit,高 6 bit 补 0 或符号扩展,每像素对 8 byte(4 个 16-bit 分量),CPU 按 uint16_t* 直接索引;缺点:内存占用是 8-bit 版本的两倍
YUV420 8bit/10bit
按 planar(平面) 或 semi-planar(半平面) 存储,分两种推荐方式:
NV12 风格:Y 平面在前(连续),UV 平面在后(U/V 交错)
I420 风格:Y 平面 + U 平面 + V 平面,三个独立平面
协议没规定必须哪种,但 SoC 厂商常选 NV12(Android Camera HAL 默认)
8.3 RGB数据接收
RGB888 :每像素 3 byte 紧密排列 或 4 byte(RGBX,X 为 padding 字节)。后者 CPU 按 32-bit 对齐访问更高效
RGB565 / 555 / 444 / 666:通常每像素扩展到 16 bit 存储(即便不足 16 bit 也凑足 2 byte),高位补 0
字节内位序约定与第 11 章一致(B 在低位、R 在高位,或反之,由 RX 配置决定)
8.4 RAW接收
RAW8
内存中每像素 1 byte,与线上完全一致,无需扩展
RAW10/12/14
推荐两种内存格式:
- Unpacked(解包) :每像素扩展到 16 bit (2 byte) ,多余高位补 0 → CPU/ISP 按
uint16_t*直接读取。这是车载/手机最常用的方式。 - Packed(保持紧凑):保留线上的紧凑打包(RAW10 → 5 byte/4 像素)→ 节省内存(省 20% RAM),但 ISP 必须能读紧凑格式。
MSB / LSB 对齐选择 :解包到 16 bit 时可以"左对齐"(数据放 bit15...bit6)或"右对齐"(数据放 bit9...bit0)。ISP 通常要求左对齐(数据范围统一到 16 bit 满量程,便于黑电平校正、AWB 等流水线)
RAW16/RAW24
直接每像素 2 byte / 3 byte,无需扩展。
RAW24 也可以扩展到 4 byte/像素以便 32-bit 对齐。
RAW6/RAW7/RAW20
推荐解包到 8 bit (RAW6/7) 或 32 bit (RAW20) 存储
8.5 存储格式速查表
| DT | 线上紧凑打包 | 推荐内存格式(最常见) | 内存膨胀比 |
|---|---|---|---|
| RAW8 | 1 byte/px | 1 byte/px | 1.0× |
| RAW10 | 4 px / 5 byte | 2 byte/px(左对齐) | 1.6× |
| RAW12 | 2 px / 3 byte | 2 byte/px | 1.33× |
| RAW14 | 4 px / 7 byte | 2 byte/px | 1.14× |
| RAW16 | 2 byte/px | 2 byte/px | 1.0× |
| RAW20 | 2 px / 5 byte | 4 byte/px | 1.6× |
| RAW24 | 3 byte/px | 3 byte/px 或 4 byte/px | 1.0--1.33× |
| YUV422 8 | 2 byte/px | 2 byte/px (UYVY) | 1.0× |
| YUV422 10 | 5 byte/2px | 8 byte/2px (扩展到 16-bit/分量) | 1.6× |
| YUV420 8 | 6 byte/4px | 6 byte/4px (NV12/I420) | 1.0× |
| RGB888 | 3 byte/px | 3 或 4 byte/px (RGB / RGBX) | 1.0--1.33× |
| RGB565 | 2 byte/px | 2 byte/px | 1.0× |
| RGB444 | 12 bit/px | 2 byte/px (扩展) | 1.33× |
预算帧 buffer 大小时,必须用"内存格式"那一列乘以分辨率,而不是用线上字节数。
8.6 工程背景相关
1.预估帧 buffer 大小永远用第 12 章布局算,不要用线上字节数算:
RAW10 1920×1080 帧 buffer = 1920 × 1080 × 2 = 4.15 MB(不是 2.59 MB)
YUV422 10-bit 1920×1080 = 1920 × 1080 × 4 = 8.3 MB
2.左对齐 vs 右对齐,必须 sensor / RX / ISP 三端一致。常见 bug:sensor 输出右对齐 RAW10,RX 配成左对齐,结果像素值被左移 6 位,整张图变得过亮 64 倍
3.NV12 vs I420 由 SoC + Codec/Display 决定,调通后不要随便切,会触发整条 pipeline 的 stride 重新配置
4.stride(行步长)≠ 行字节数
真实行字节数 = 像素数 × byte/像素
stride = 对齐到 64/128 byte 的下一个边界
行末有 padding 字节,ISP 读取时必须按 stride 跳行,不能按行字节数跳,否则错位
Q&A
1.什么是连续时钟和非连续时钟
"连续时钟"和"非连续时钟"实际上是 D-PHY 规范 (即被CSI-2引用的底层物理层标准)中的概念,在D-PHY中:
- 连续时钟 - Continuous Clock Mode::时钟通道在整个高速传输期间持续发送时钟信号。这种模式简化了接收端的时钟恢复电路设计,但功耗较高。
- 非连续时钟 - Non-Continuous Clock Mode :时钟通道仅在数据包传输前的一小段时间内启动并发送时钟信号(用于同步),然后与数据通道一同进入低功耗状态。这种模式可以显著降低系统功耗,但对接收端的时钟恢复能力要求更高。
2.VS/HS 场同步/行同步概念
VS/HS来自 DVP(Digital Video Port)、BT.656/BT.1120、CCIR-601 等并行视频接口。
物理形态(在DVP上)
PCLK ┐_┐_┐_┐_┐_┐_┐_┐_┐_┐_┐_┐_┐_ ← 像素时钟
DATA[7:0]×××××××××××××××××××××××× ← 8 bit 像素数据
HSYNC ___────────___────────___ ← 行同步:每行有效像素期间为高
VSYNC __________──────________ ← 场同步:一帧的活动区间为高但是在CSI-2上是没有VS/HS 的真实信号线的,CSI-2 是纯串行数据链路 ,整条链路上只有 D-PHY 的差分对(或 C-PHY 的 Trio),没有专门的 VS/HS 引脚 。但是,功能必须保留 ------ ISP 必须知道"哪一帧/哪一行开始/结束",否则没法把数据填进帧 buffer。
CSI-2依靠同步短包替代:
| 传统并行接口 | CSI-2 串行接口 | 备注 |
|---|---|---|
| VSYNC 上升沿 | FS 短包(DT = 0x00,Frame Start) | 每帧必发一次 |
| VSYNC 下降沿 | FE 短包(DT = 0x01,Frame End) | 每帧必发一次 |
| HSYNC 上升沿 | LS 短包 (DT = 0x02,Line Start,可选) | 多数 sensor 不发 |
| HSYNC 下降沿 | LE 短包 (DT = 0x03,Line End,可选) | 多数 sensor 不发 |
| 行像素数据 | 长包(DT = RAW10/YUV422/...)的 Payload | 一行一个长包 |
| 行间隔(HSYNC 低电平期) | 长包之间的 LP / EPD 间隔 | 由 §9.7、§9.10、§9.11 处理 |
| 场间隔(VSYNC 低电平期) | FE 短包到下一个 FS 短包之间的链路空闲期 | 通常进入 LP |
SOC又是如何把CSI-2的FS/FE还原成VS/HS中断的呢?
很多 SoC 的 CSI-2 RX 控制器在驱动层面会模拟出"VSYNC 中断"和"HSYNC 中断",方便老的 V4L2 驱动框架使用:
收到 FS 短包 → 触发 VSYNC IRQ (驱动里常叫 frame_start_irq / vsync_irq / sof_irq)
收到 FE 短包 → 触发 VSYNC End IRQ (frame_end_irq / eof_irq)
收到每个长包结束 → 触发 HSYNC IRQ (line_irq),即便没有 LS/LE 短包也行,因为长包本身的边界就是行边界
所以你在 Linux/Android camera driver 里看到 vsync、hsync、sof 这些字眼,本质都是协议层短包事件被驱动包装成的虚拟中断
HS/VS的工程用法:
1.VS 中断:driver 在此切换 DMA buffer、记录帧时间戳、3A 反馈、外部硬件同步触发(多摄同步、雷达对齐)
2.HS 中断:driver 累加行计数器、监控掉行、触发实时 ISP 调度
3.多摄硬件同步:很多 SoC 把 sensor 的 VS 信号引出 GPIO,作为 sub-sensor 的外部触发输入,实现毫秒/微秒级同步
参考文档:
本文参考2019-09-17_19.05.53_mipi_CSI-2_specification_v3-0.pdf,有选择性翻译总结整理,如果工程调试需要,建议读原文,更详细规范