🚀 第一步:上手 ComfyUI 超快!
- 下载安装 :下载官方的 Windows 整合包(
ComfyUI_windows_portable.7z),直接解压就行,可以放在你原来的stable-diffusion-webui平级目录里。 - 共享模型(关键步骤):这样就不用把模型文件再复制一遍,白白浪费上百GB的硬盘空间。
- 找到 ComfyUI 目录下的
extra_model_paths.yaml.example文件。 - 把它复制一份,重命名为
extra_model_paths.yaml。 - 用记事本打开这个文件,找到
base_path:这一行,把路径改成你的 WebUI 根目录路径 (比如E:/stableDiffusion/stable-diffusion-webui),然后保存。 - 这样 ComfyUI 就能直接读取你原来所有的模型了。
- 启动 ComfyUI :解压后的文件夹里有
run_nvidia_gpu.bat脚本,双击启动,等待浏览器自动打开 ComfyUI 界面。
🧪 第二步:生成你的第一个视频 Demo
我们来搭建一个最简单的 AnimateDiff 文生视频 工作流。
- 清空画布 :启动后先点菜单栏的
Manager(管理器)更新 ComfyUI 核心和插件到最新版。然后在画布右键 → 选择Clear All(清空所有节点),用一张干净画布开始。 - 安装扩展 :点击顶部菜单栏的
Manager→Install Custom Nodes(安装自定义节点),在搜索框中输入并安装以下两个插件:
- ComfyUI-AnimateDiff-Evolved
- VideoHelperSuite


安装完成后需要重启 ComfyUI。
- 开始搭建工作流:在空白画布双击鼠标,会弹出搜索框,依次搜索并添加下列核心节点:
CheckpointLoaderSimple→ 加载基础模型。CLIPTextEncode→ 添加两个,一个正向提示词,一个负向提示词。EmptyLatentImage→ 设置视频画幅。
ADE_AnimateDiffLoaderGen1→ 选择运动模块(如mm_sd_v15_v2.ckpt)。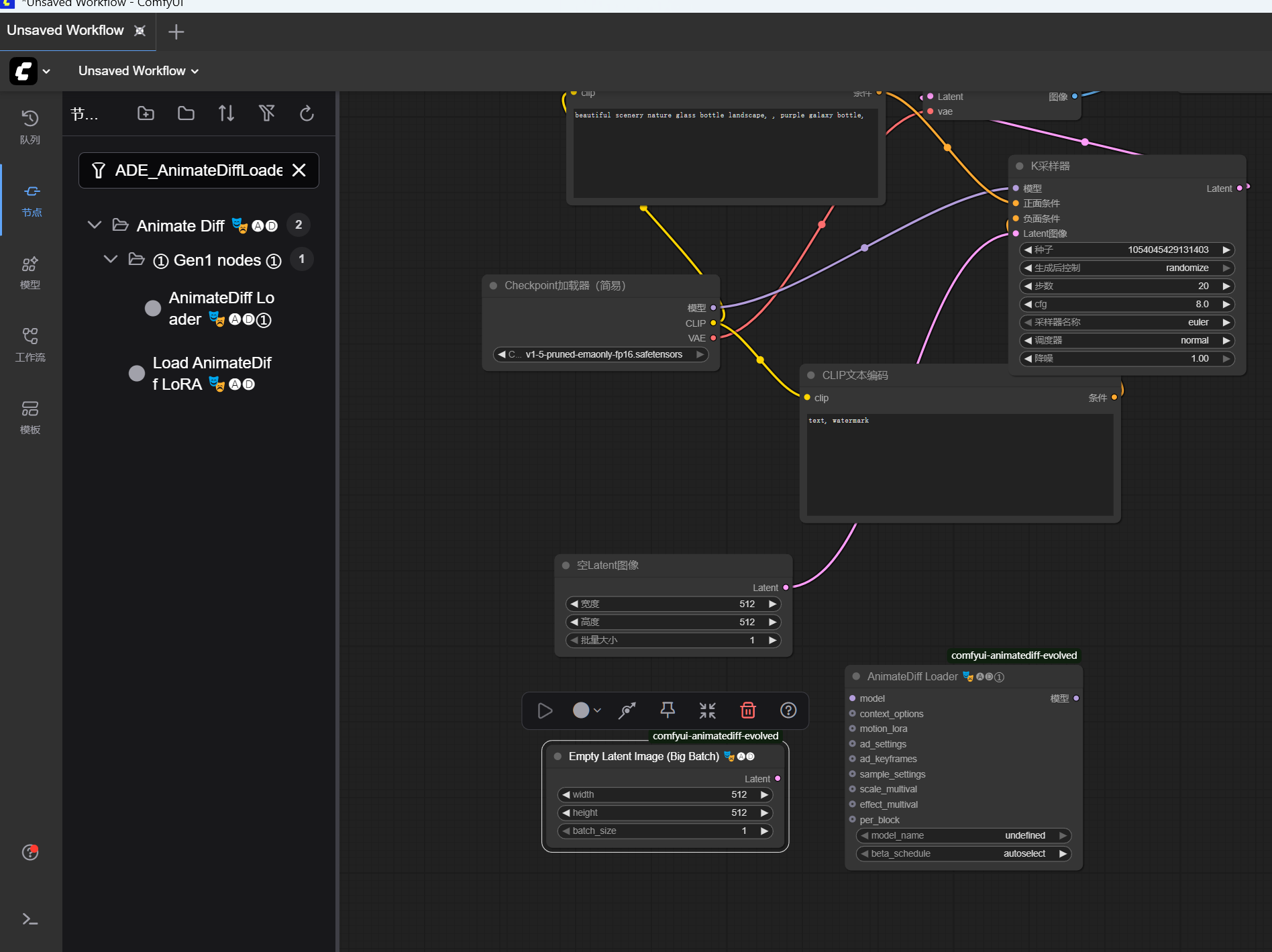
ADE_UseEvolvedSampling→ 配置采样参数。KSampler→ 核心采样器。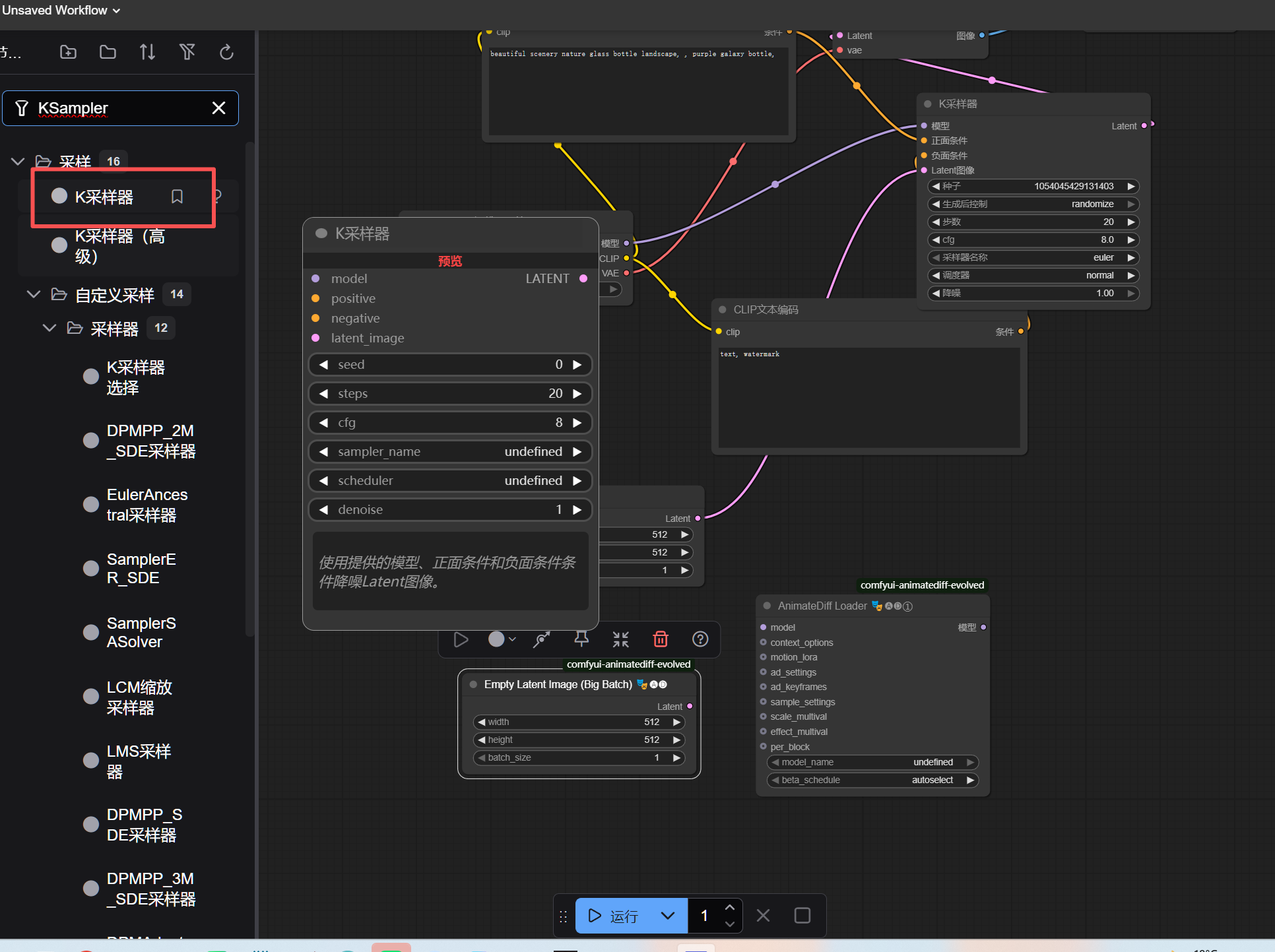
VAEDecode→ 将潜空间数据解码为图像。
VHS_VideoCombine(来自VideoHelperSuite) → 把序列帧合并成视频。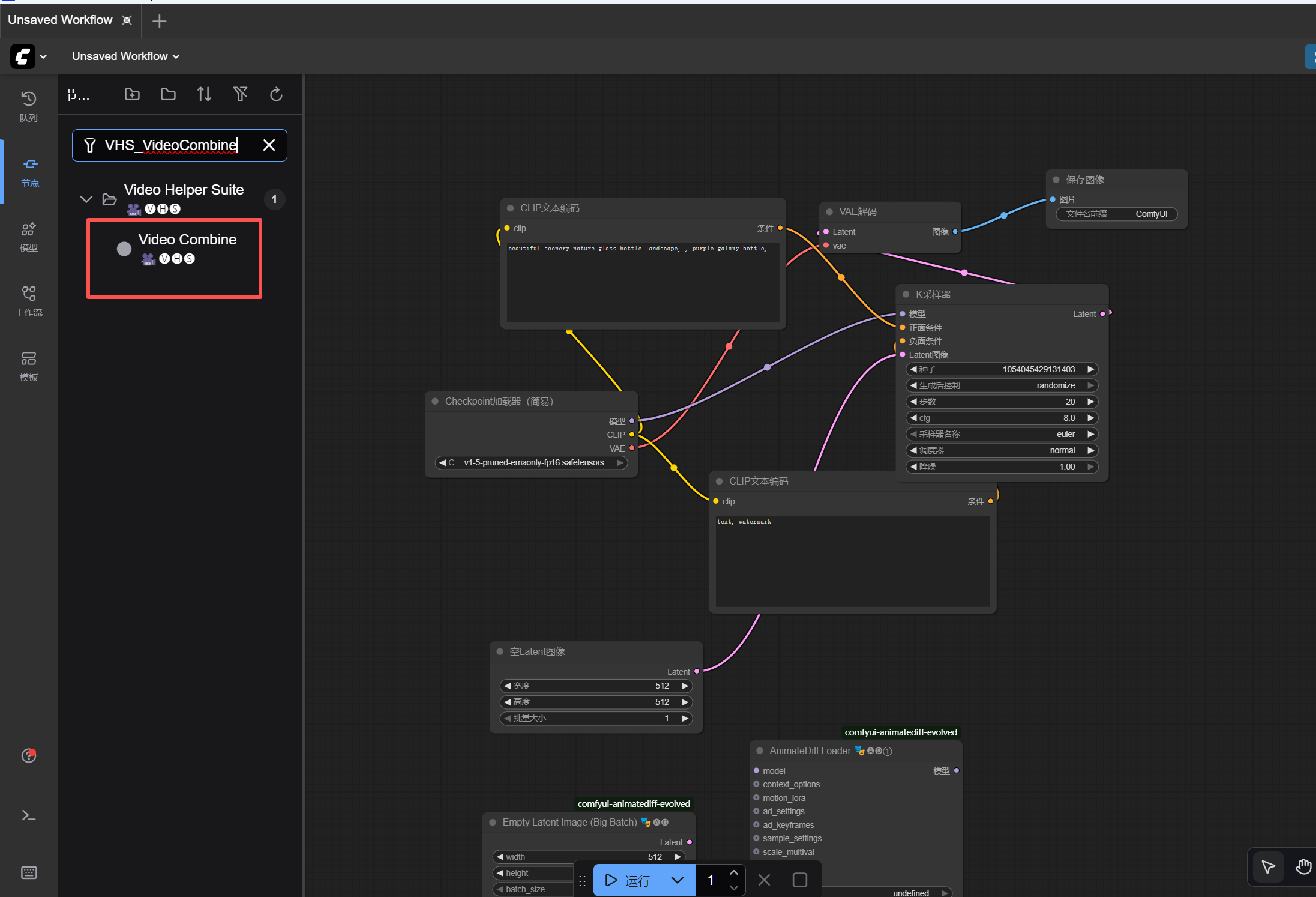
- 连接工作流 :每个节点左边是输入接口,右边是输出接口,按以下顺序把同级接口连起来:直接通过鼠标点击后拉取即可连线,不要通过节点的下图红框的图标,这个不是连线的意思,是取消的隐藏节点的意思(如果不小心操作了,再点击取消即可)
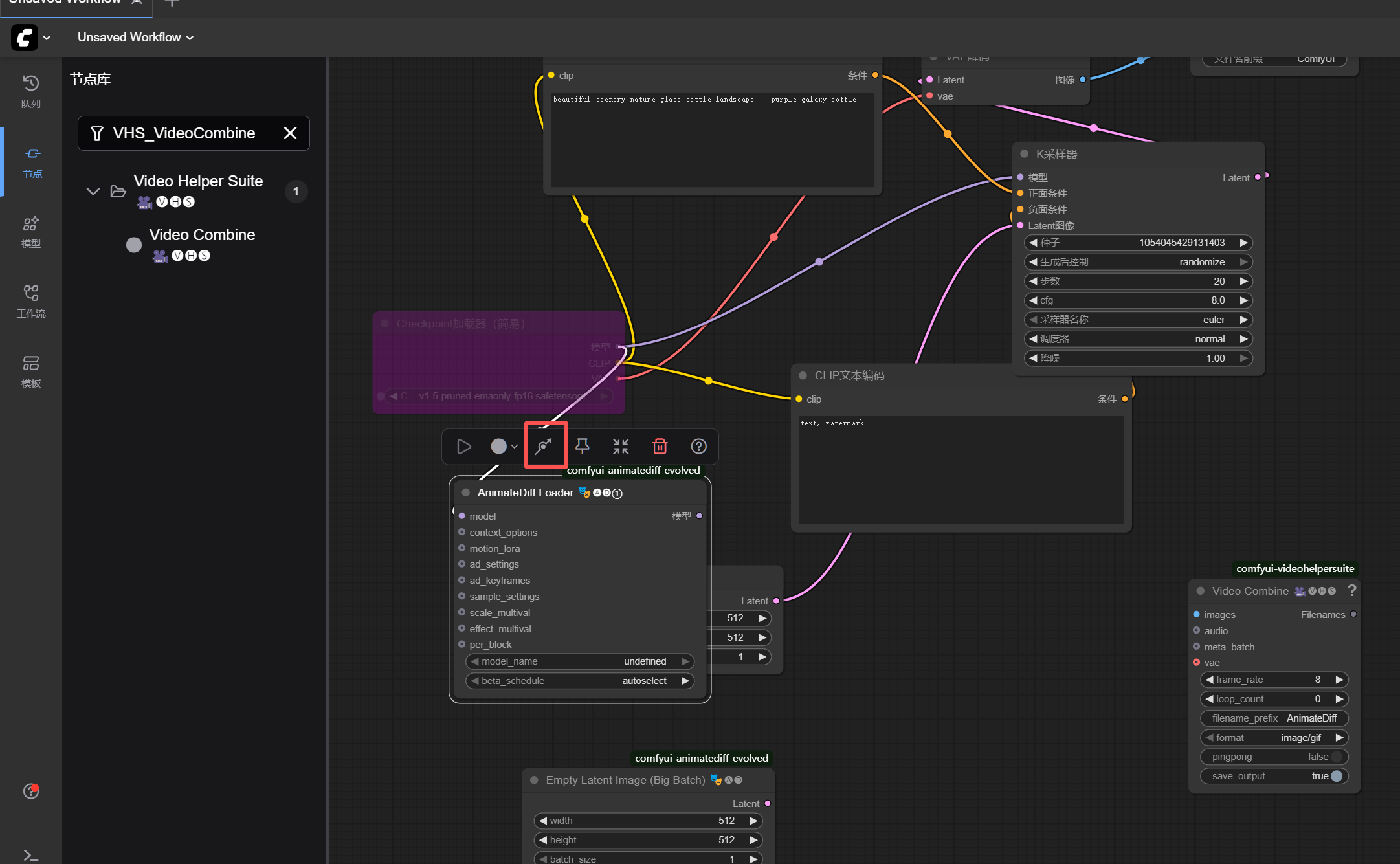
-
CheckpointLoaderSimple的MODEL→ADE_AnimateDiffLoaderGen1的MODEL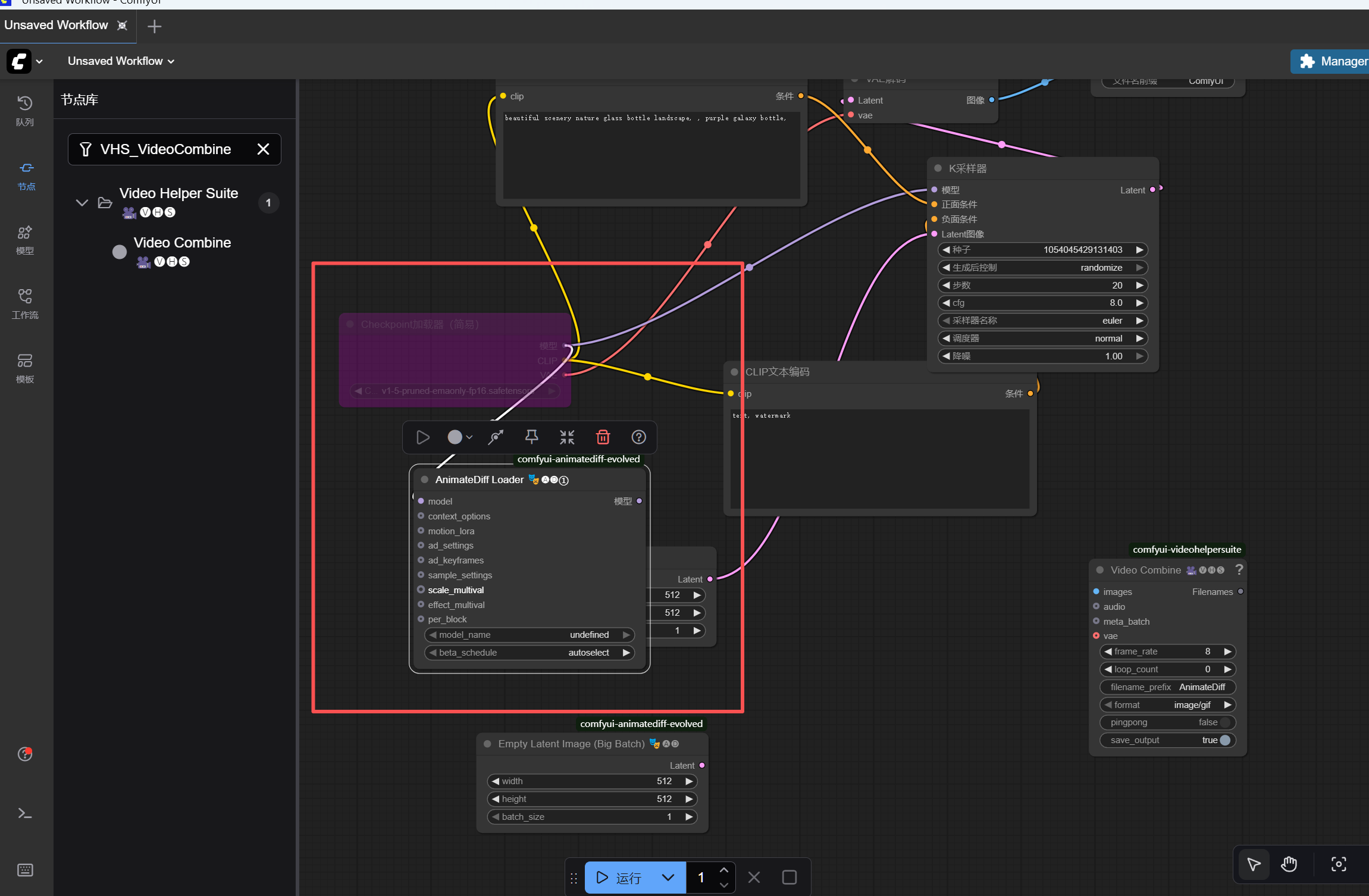

-
CheckpointLoaderSimple的CLIP→ 两个CLIPTextEncode的CLIP
-
CheckpointLoaderSimple的VAE→VAEDecode的VAE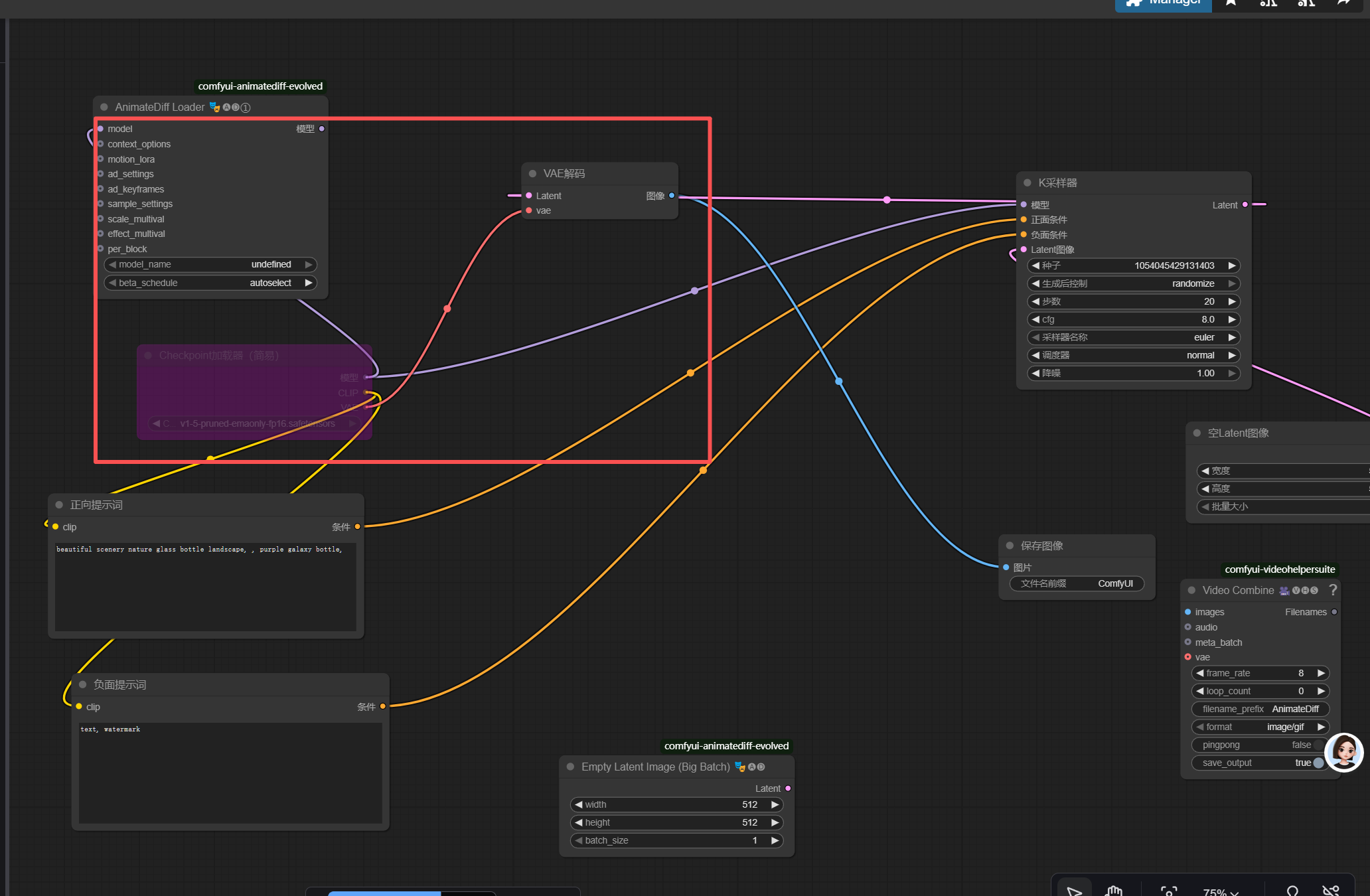
-
ADE_AnimateDiffLoaderGen1的MODEL→ADE_UseEvolvedSampling的MODEL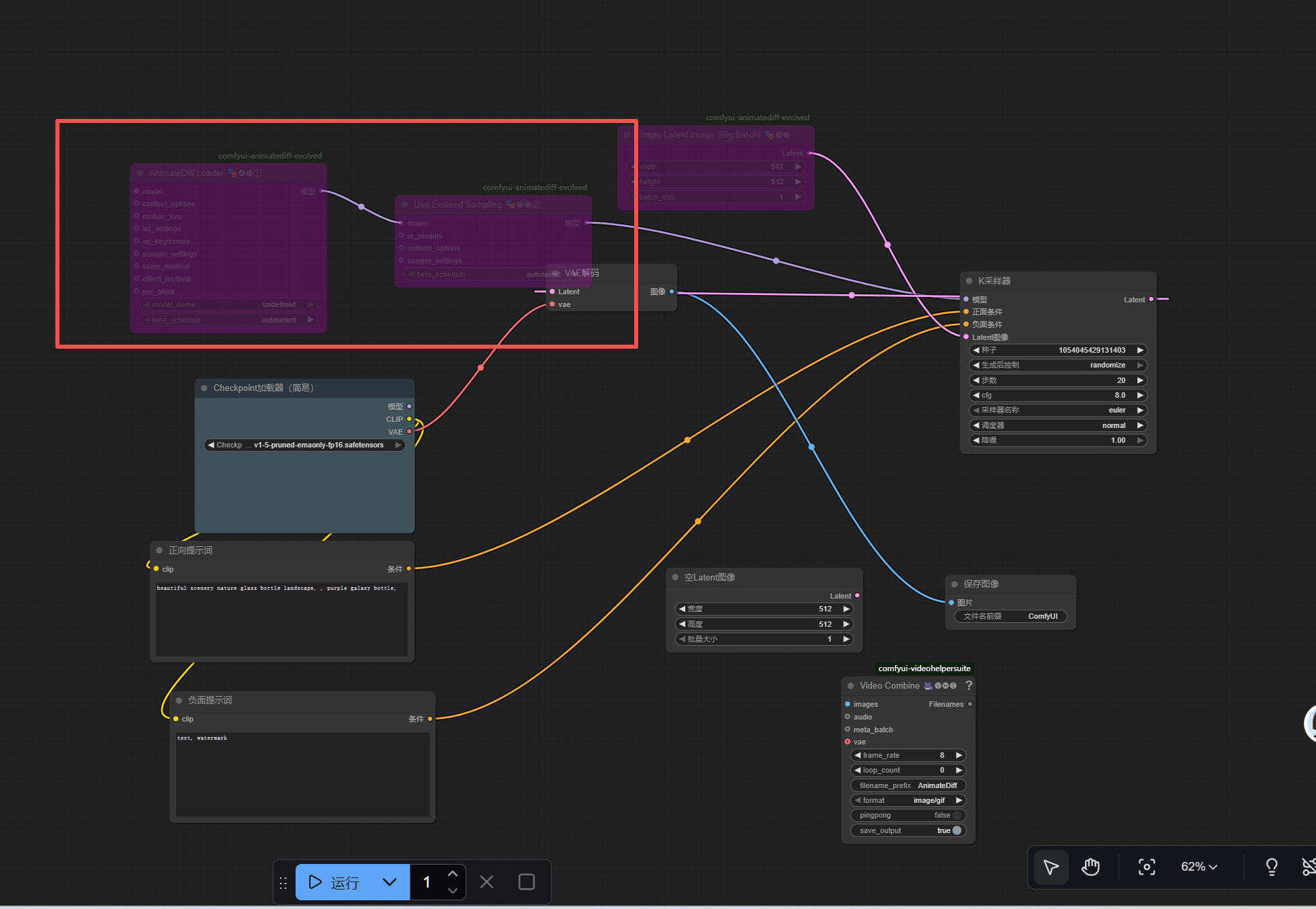
-
ADE_UseEvolvedSampling的MODEL→KSampler的MODEL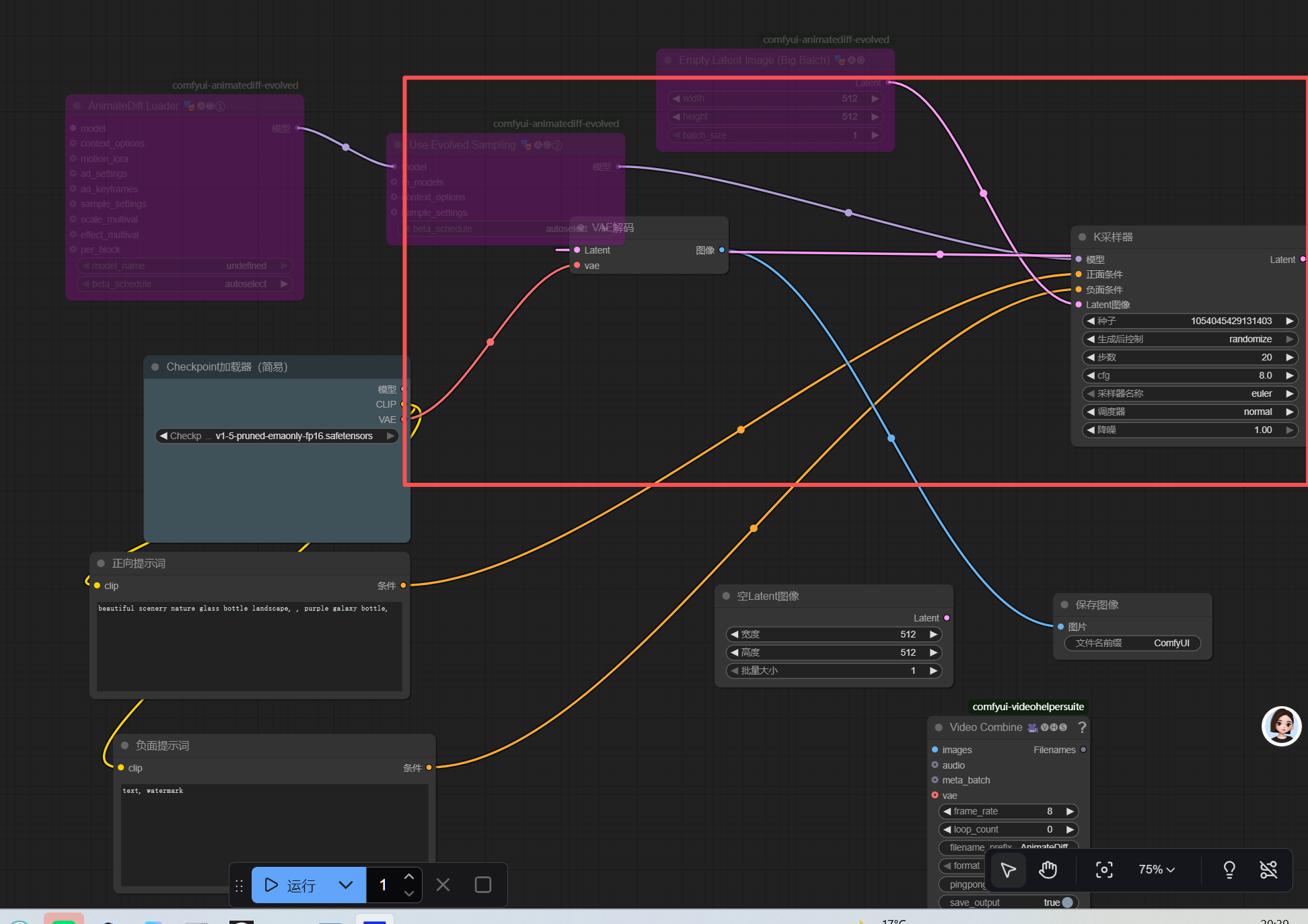
-
EmptyLatentImage的LATENT→KSampler的LATENT_IMAGE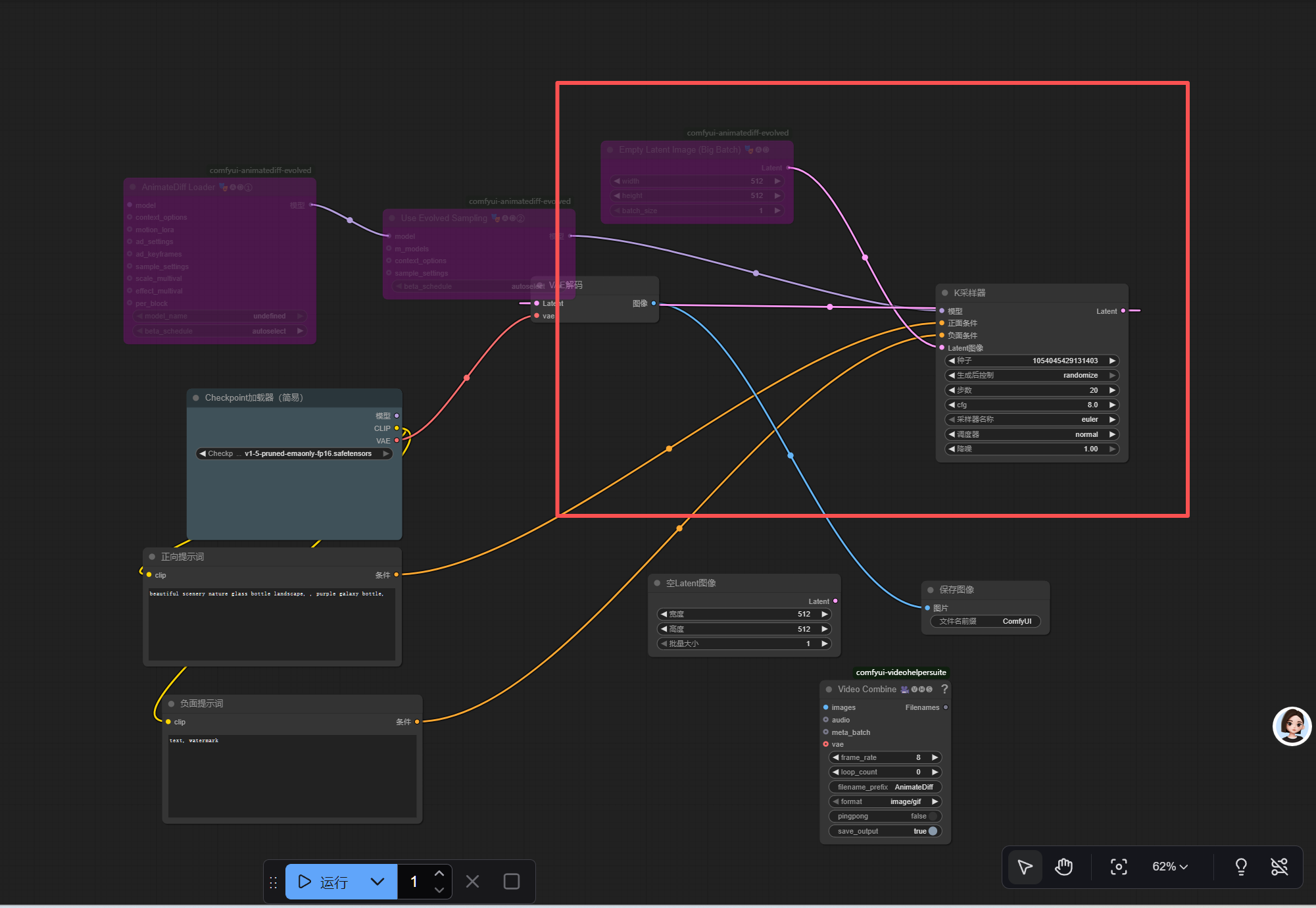
-
两个
CLIPTextEncode的CONDITIONING分别连接KSampler的POSITIVE/NEGATIVE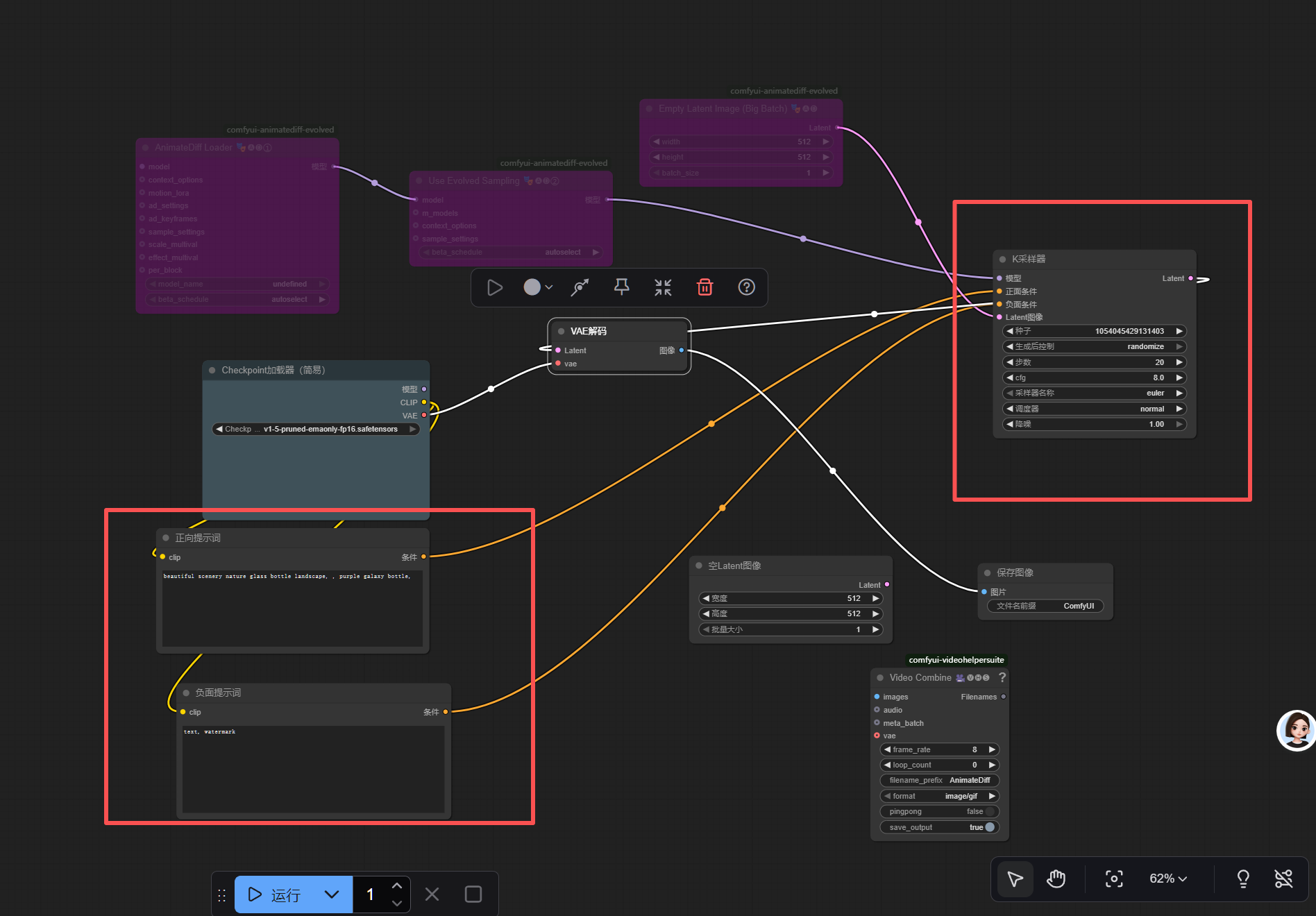
-
KSampler的LATENT→VAEDecode的LATENT -

-
VAEDecode的IMAGE→VHS_VideoCombine的IMAGES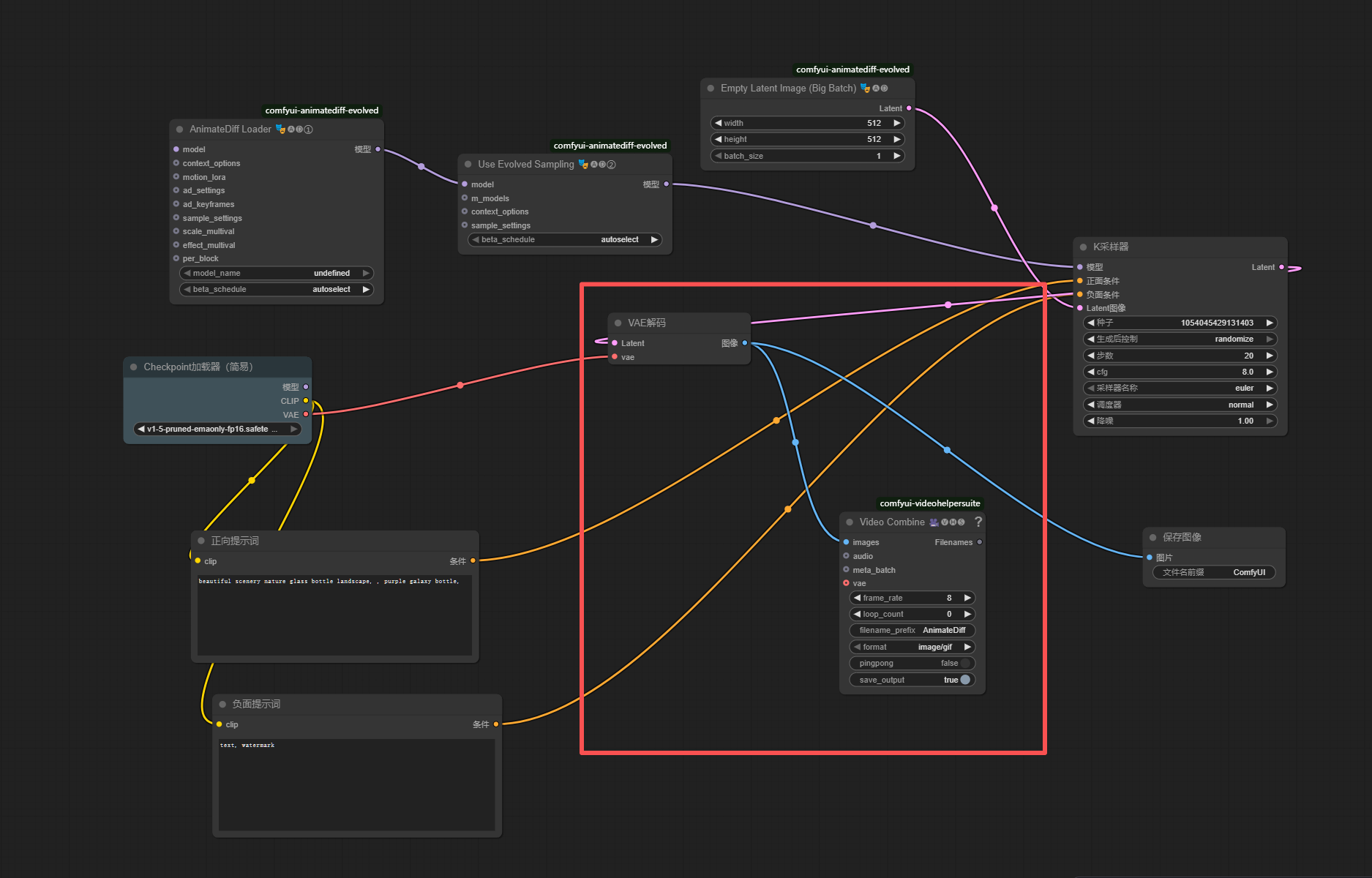
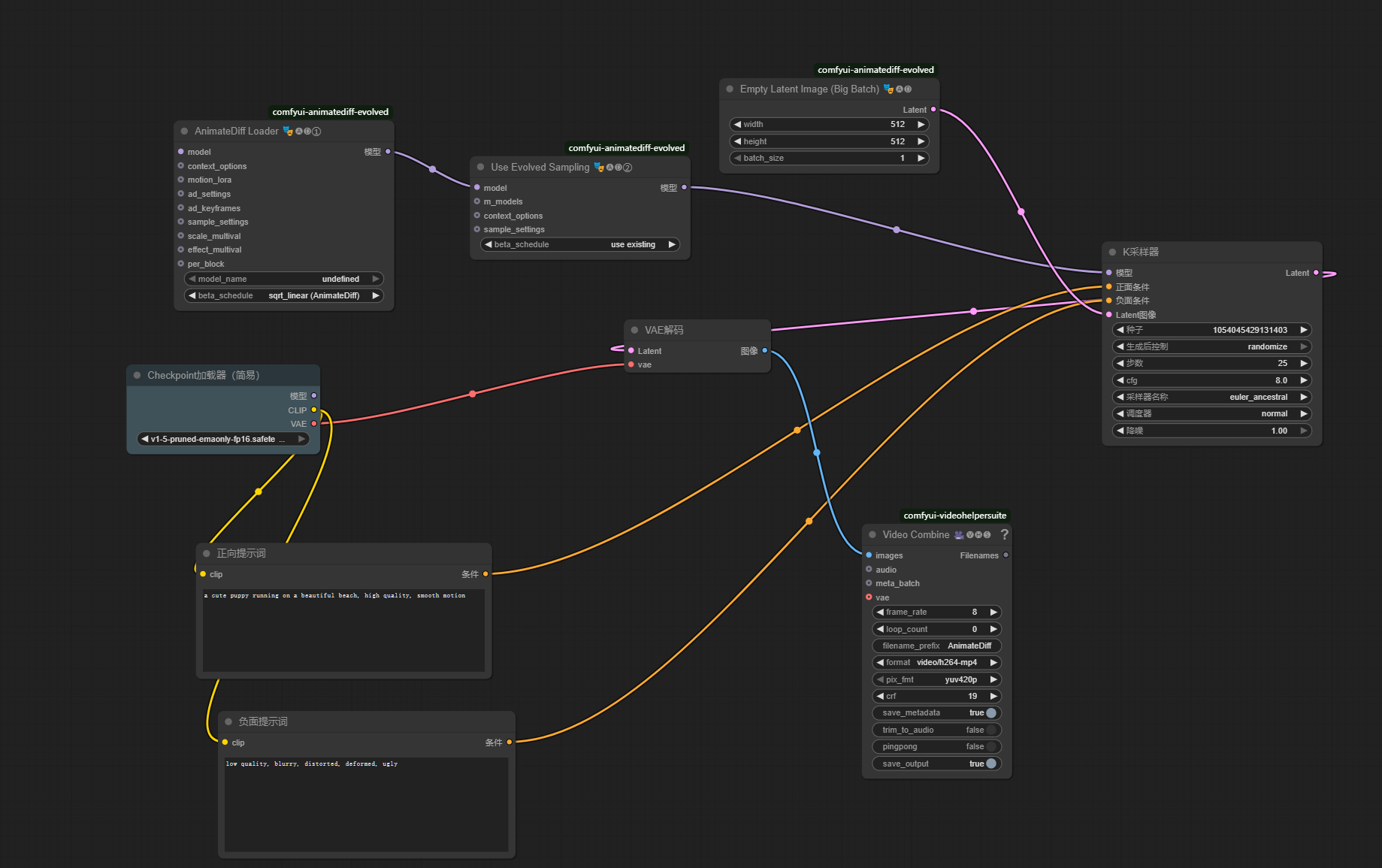
- 设置参数(新手友好值):
- CheckpointLoaderSimple :选择你的 SD 1.5 模型(比如
v1-5-pruned-emaonly.safetensors)。 - 正向提示词 (Positive Prompt) :
a cute puppy running on a beautiful beach, high quality, smooth motion。 - 负向提示词 (Negative Prompt) :
low quality, blurry, distorted, deformed, ugly。 - EmptyLatentImage :
width填512,height填512,batch_size填16(代表生成16帧)。 - ADE_AnimateDiffLoaderGen1 :在
motion_model选项中选择mm_sd_v15_v2.ckpt。 - ADE_UseEvolvedSampling:保持默认即可。
- KSampler :
steps填25,cfg填7.5,sampler_name选euler_ancestral。 - VHS_VideoCombine :
frame_rate填8(代表每秒8帧,会生成2秒视频),format选video/h264-mp4。 - 参数设置之后
- 将模型文件放到 C:\Users\jiao_\AppData\Local\Programs\ComfyUI\resources\ComfyUI\models目录下,
- 修改配置文件,保证运动模型可被加载
- comfyui:
base_path: C:/Users/jiao_/AppData/Local/Programs/ComfyUI/resources/ComfyUI
animatediff_models: |
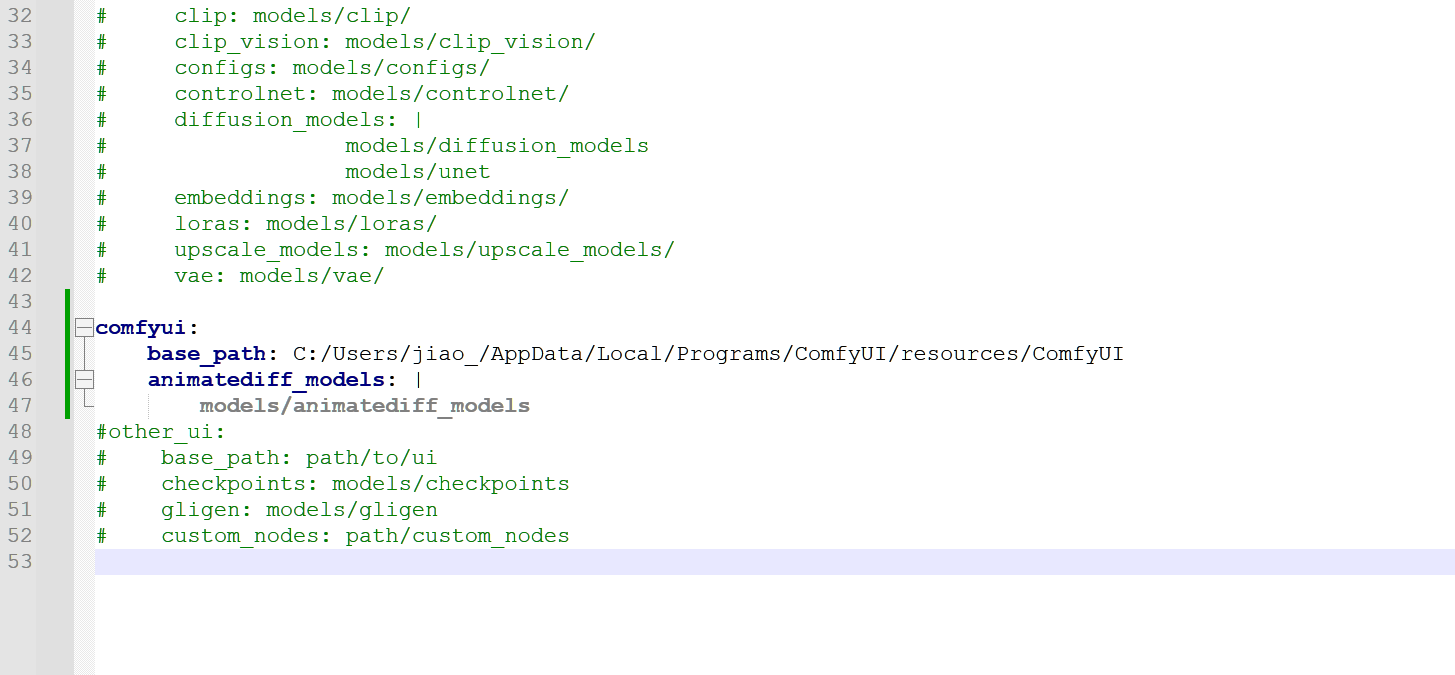
如果点击箭头按钮能选择到模型,则成功

- 生成 :在右侧面板点击
Queue Prompt(添加任务到队列)按钮,一个2秒钟的AI视频就开始生成了。生成的.mp4文件会默认保存在 ComfyUI 的output文件夹中。
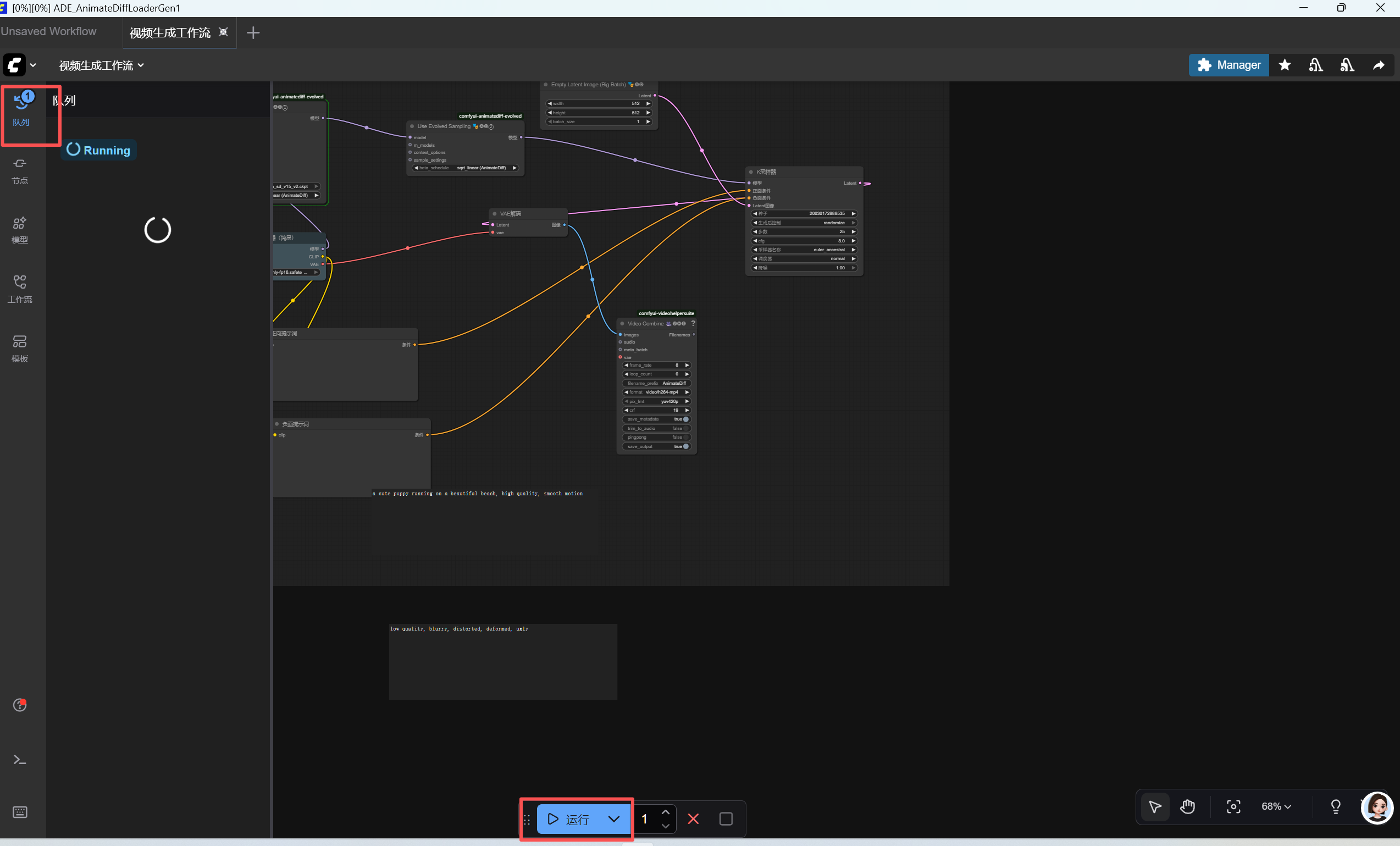

最终生成的视频,可以说更像是几张图片的罗列,并没有连贯性和故事性。实际上是有点类似于gif图片的感觉。没关系,我们先让图片动起来,后面的文章我们详细再进行优化,逐步优化成一个可以作为动物主播的工作流。
💾 第三步:管理你的"黑科技"工作流
成功跑通后,你肯定想保存这来之不易的成果。

- 保存工作流 :点击菜单栏的
Workflow→Save,把当前画布保存为一个.json文件。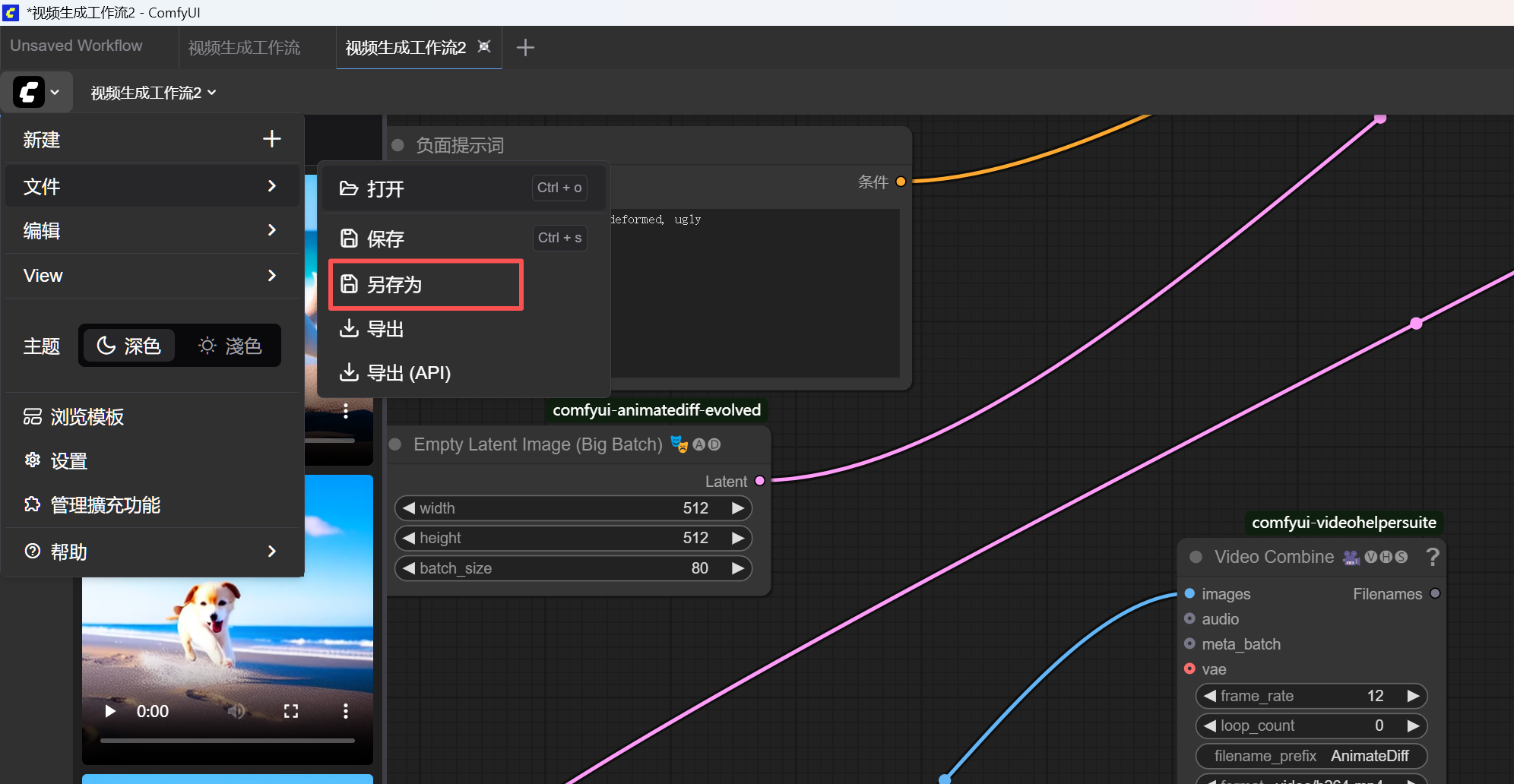
- 加载工作流 :下次使用时直接将
.json文件拖入 ComfyUI 界面,所有节点和参数都会自动还原。
保存后所在路径:C:\Users\jiao_\Documents\ComfyUI\user\default\workflows
之后从该路径加载
🧠 第四步:原理解析(理解为什么这样连接)
- AnimateDiff的核心思想:它并不是"先生成很多图再拼起来",而是在采样阶段,把一组16帧的潜空间数据(latent)作为一个整体去生成。这样模型就能"知道"前后帧的关系,从而产生平滑的运动。
- 关键节点解密:
ADE_AnimateDiffLoaderGen1:负责将运动模块"注入"到基础模型中,赋予其生成连续帧的能力。ADE_UseEvolvedSampling:将标准的采样器"升级"为能处理视频序列的"进化版"采样器。VHS_VideoCombine:核心任务是把解码后的图像序列组合成一个常见的视频文件(如.mp4)。
⚡️ 8GB显存生存指南:速度与效率拉满
对于你的 8GB 显存 RTX 5060,用 ComfyUI 玩视频生成有一些优化技巧:
- 用FP8精度模型 :有些模型(如 Wan 2.2)提供 FP8 精度的版本(
fp8_scaled),相比 FP16 版本能显著降低显存占用,而画质损失微乎其微。 - 启用异步卸载:在显存不够时自动把部分模型搬到内存里,保证不报错。
- 用更高效的新模型 :除了 AnimateDiff,也可以关注一下更新的视频模型,比如 Wan 2.2 和 LTX-Video。LTX-Video 效率非常高,在 8GB 显卡上几分钟就能出一个视频。
导入工作流报错怎么办? 如果提示"节点缺失",先去
Manager → Install Missing Custom Nodes(安装缺失节点),通常就能一键解决。
目前搭建的最小化工作流还比较基础,你可以把这个 .json 工作流发给我看看,我能帮你加点高级功能(像ControlNet 精准控姿势 或者 放大输出尺寸),一步步把你的 AI 视频做得更炫酷!