在大模型时代,RAG(Retrieval-Augmented Generation,检索增强生成)已经成为知识问答、智能客服、企业知识库等场景的标配方案。而 RAG 的核心,正是向量数据库。本文将带你系统了解开源分布式向量数据库 Milvus,从架构、核心概念到索引选型,一文掌握。
一、为什么是 Milvus?
Milvus 是由 Zilliz 开源的分布式向量数据库,专为大规模向量检索场景设计。在众多向量数据库(Faiss、Chroma、Weaviate、Pinecone 等)中,Milvus 凭借以下优势成为生产环境的主流选择:
| 优势 | 说明 |
|---|---|
| 高性能检索 | 支持十亿级向量毫秒级响应 |
| 弹性扩展 | 计算与存储分离,按需扩缩容 |
| 生态完善 | 全面对接 LangChain、LlamaIndex、Dify 等主流 RAG 框架 |
| 多索引支持 | FLAT、IVF、HNSW、SCANN、DISKANN 等全家桶 |
| 云原生 | 容器化部署,K8s 友好 |
二、Milvus 架构总览
Milvus 采用高度解耦的分层架构,每一层都可以独立扩展,整体架构如下图所示:
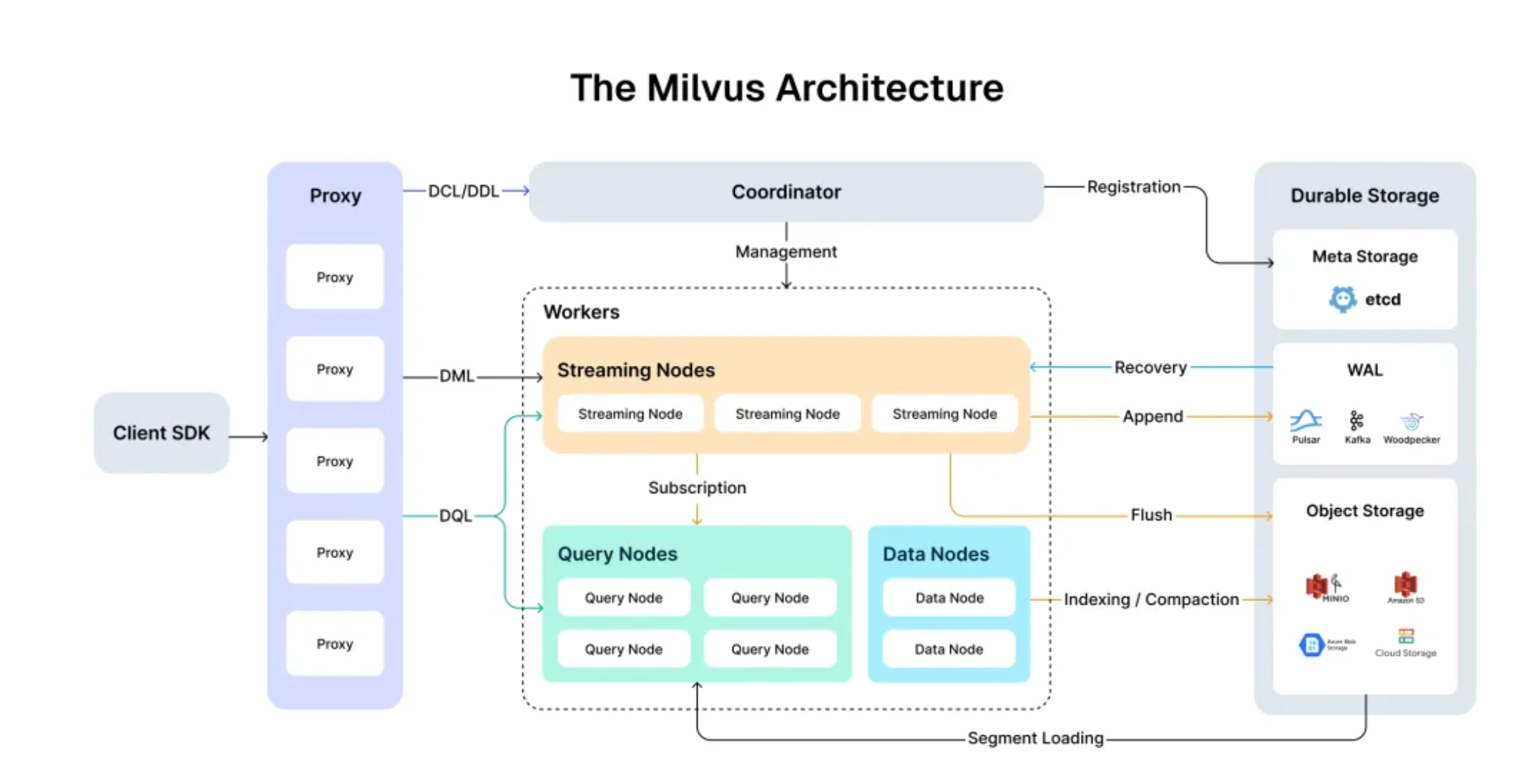
整体可以拆解为四大组件:
① Proxy(接入层)
- 客户端 SDK 的入口
- 负责请求路由、负载均衡、结果聚合
- 无状态,可水平扩展
② Coordinator(协调层)
- 集群大脑,负责元数据管理、负载均衡、节点注册
- 处理 DDL(建表、建索引)、DCL(权限)类请求
③ Workers(执行层)
- Streaming Nodes:处理实时数据流的写入
- Query Nodes:负责向量检索查询
- Data Nodes:负责数据持久化、索引构建、Compaction
④ Durable Storage(存储层)
- Meta Storage:etcd,存放集群元信息
- WAL(预写日志):Pulsar / Kafka / Woodpecker,保证写入可靠性
- Object Storage:MinIO / S3 / 阿里 OSS / GCS,存放向量数据和索引文件
这种"无状态计算 + 共享存储"的架构,是 Milvus 能够弹性扩展、应对海量数据的关键。
三、核心概念速览
在动手之前,先建立基本的概念模型。可以把 Milvus 类比为关系型数据库:
| Milvus 概念 | 类比 MySQL | 说明 |
|---|---|---|
| Database | 数据库 | 逻辑隔离单元,多租户场景常用 |
| Collection | 表 | 向量数据的容器,有固定 Schema |
| Field | 列 | 主键、向量字段、标量字段 |
| Entity | 行 | 一条完整数据记录 |
| Partition | 分区 | 集合的子集,加速查询 |
| Index | 索引 | 加快向量检索的核心 |
1. Database(数据库)
组织和管理数据的逻辑单元,用于不同应用或租户的数据隔离。
2. Collection(集合)
向量数据存放的"容器",相当于关系数据库的表:
- 所有向量按业务存储在 Collection 里
- 每个 Collection 有固定的 Schema
- 增删改查都基于 Collection 操作
3. Field(字段)
一个 Collection 包含三类字段:
- 主键字段(必须):唯一标识一条数据
- 向量字段 (必须):需指定维度
dim - 标量字段(可选):int / string / bool 等,用于过滤
4. Entity(实体)
一行完整记录 = 主键 ID + 向量 + 标量字段。
5. Vector(向量)
一组浮点数数组,例如 [0.1, 0.2, 0.3, ..., 0.768]。由 Embedding 模型(如 BGE、OpenAI text-embedding)将文本、图片、音频转换得到。
常见维度:768、1024、1536。
6. Partition(分区)
分区是 Collection 的子集。创建 Collection 时会默认生成 _default 分区。合理使用分区可以缩小扫描范围、显著加速查询(例如按租户、按时间分区)。
7. Index(索引)
没有索引的向量检索 = 全表暴力扫描,对百万级数据基本不可用。索引的设计是 Milvus 的核心,下一节我们重点展开。
四、索引选型:Milvus 的核心战场
Milvus 提供了多种索引类型,每种都有自己的设计哲学和适用场景。下面逐一拆解。
1. FLAT ------ 暴力精准型
原理:保留原始向量,查询时与每个向量逐一比对,没有任何近似。
特点:精度 100%,但速度最慢。
适用:小数据集(10 万以内)、对精度要求极高的场景。
python
# 建立索引
index_params.add_index(
field_name="your_vector_field_name", # 向量字段名
index_type="FLAT", # 索引类型
index_name="vector_index",
metric_type="L2", # L2 距离
params={} # FLAT 不需要额外参数
)
# 在索引上搜索
res = MilvusClient.search(
collection_name="your_collection_name",
anns_field="vector_field",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量
limit=3, # TopK
search_params={"params": {}}
)2. IVF_FLAT ------ 分桶聚类型
原理 :先用 K-Means 把向量聚类成 nlist 个桶,查询时只搜索最相近的 nprobe 个桶。
形象比喻:如果把向量比作书籍,IVF 就是把书按类别放到不同书架上。查询时不再翻遍整个图书馆,只去最相关的几个书架。
nlist:分多少书架nprobe:查多少书架
特点:速度快、精度可控,是最常用、最平衡的索引。
适用:百万级常规业务。
python
# 建立索引
index_params.add_index(
field_name="your_vector_field_name",
index_type="IVF_FLAT",
index_name="vector_index",
metric_type="L2",
params={
"nlist": 64, # nlist 越大,分区越多,单桶数据少 → 查得快但可能漏
}
)
# 在索引上搜索
search_params = {
"params": {
"nprobe": 10, # nprobe 越大越准但越慢;越小越快但容易漏
}
}
res = MilvusClient.search(
collection_name="your_collection_name",
anns_field="vector_field",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=3,
search_params=search_params
)3. IVF_SQ8 ------ 压缩省内存型
原理 :在 IVF_FLAT 基础上,对向量做标量量化(Scalar Quantization)压缩,每个浮点数从 32bit 压缩到 8bit。
特点 :内存占用减少 4 倍,精度略有损失(通常 <2%)。
适用:海量数据、内存吃紧的场景。
python
# 建立索引
index_params.add_index(
field_name="your_vector_field_name",
index_type="IVF_SQ8",
index_name="vector_index",
metric_type="L2",
params={
"nlist": 64,
}
)
# 在索引上搜索
search_params = {"params": {"nprobe": 8}}
res = MilvusClient.search(
collection_name="your_collection_name",
anns_field="vector_field",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=10,
search_params=search_params
)4. HNSW ------ 图结构最强型
原理 :构建一张分层导航小世界图(Hierarchical Navigable Small World)。每个向量节点与若干邻居相连,查询时从顶层稀疏图开始跳跃式搜索,逐层下钻到底层。
形象比喻:像现实中的高速路网,先走高速跨城市,再走国道跨区,最后走小路到门口。
特点 :查询最快、精度最高,但内存占用大、构建慢。
适用:在线高并发、低延迟接口、内存充裕的场景。
python
# 建立索引
index_params.add_index(
field_name="your_vector_field_name",
index_type="HNSW",
index_name="vector_index",
metric_type="L2",
params={
"M": 64, # 每个节点的最大邻居数
"efConstruction": 100 # 构建索引时考虑的候选邻居数
}
)
# 在索引上搜索
search_params = {
"params": {
"ef": 10, # 搜索时考虑的邻居数,越大越准越慢
}
}
res = MilvusClient.search(
collection_name="your_collection_name",
anns_field="vector_field",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=10,
search_params=search_params
)5. SCANN ------ 全能均衡型
原理 :谷歌出品,集 IVF + 量化 + 图索引于一身:
- 像 IVF 一样粗分区,缩小搜索范围
- 像 SQ8 一样量化压缩,控制内存
- 在分区内部构建小型图结构,精细检索
- 最后通过
reorder_k用原始向量重排序,找回精度
特点:速度、精度、内存三者最平衡。
适用:高召回场景、推荐系统、语义搜索。
python
# 建立索引
index_params.add_index(
field_name="your_vector_field_name",
index_type="SCANN",
index_name="vector_index",
metric_type="L2",
params={
"with_raw_data": True, # 是否存储原始向量(用于精确重排序)
}
)
# 在索引上搜索
search_params = {
"params": {
"reorder_k": 10, # 重排序阶段细化的候选数量
"nprobe": 8 # 搜索的分区数
}
}
res = MilvusClient.search(
collection_name="your_collection_name",
anns_field="vector_field",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=10,
search_params=search_params
)6. DISKANN ------ 磁盘级低成本型
原理 :把向量本体存放在 SSD 磁盘上,内存中只保留导航图结构。用磁盘换容量。
特点:内存极省,依赖高速 SSD,速度略弱于 HNSW,远超 IVF 系列。
适用:超大规模向量库(十亿级以上)、低成本扩容场景。
⚠️ 注意:Milvus 默认禁用 DISKANN,需要在配置中开启。
bash
# milvus.yaml 配置
common:
DiskIndex:
MaxDegree: 56 # 每个向量最多连多少邻居
SearchListSize: 100 # 搜索时的候选数
PQCodeBudgetGBRatio: 0.125 # 向量压缩比例(压到 1/8)
SearchCacheBudgetGBRatio: 0.1 # 内存缓存预算
BeamWidthRatio: 4 # 磁盘读取并发度索引选型速查表
| 业务场景 | 推荐索引 | 关键理由 |
|---|---|---|
| 数据量小(<10万)、追求绝对精准 | FLAT | 暴力比对,无损 |
| 常规业务,百万级向量 | IVF_FLAT | 平衡好用,工业常青 |
| 海量向量,内存紧张 | IVF_SQ8 | 量化压缩,省内存 |
| 在线高并发,接口低延迟 | HNSW | 速度精度双高,吃内存 |
| 海量数据,高召回需求 | SCANN | 全能选手,工程友好 |
| 十亿级向量,低成本扩容 | DISKANN | SSD 换内存,性价比之王 |
五、相似度量(Metric Type)
索引解决了"怎么查得快",度量方式解决了"怎么定义相似"。Milvus 支持三种主流度量:
| 度量方式 | 含义 | 数值规律 | 适用场景 |
|---|---|---|---|
| L2(欧氏距离) | 向量空间直线距离 | 越小越相似 | 通用,图像特征 |
| IP(内积) | 向量关联程度 | 越大越相似 | 推荐系统、未归一化向量 |
| COSINE(余弦) | 向量方向夹角,不关注长度 | 越大越相似 | 文本语义检索(最常用) |
💡 经验:文本 RAG 场景默认用 COSINE,BGE、OpenAI 等主流 Embedding 模型都是基于余弦相似度训练的。
六、向量检索(Search)
有了向量、索引和度量方式,检索流程就非常清晰了:
业务请求 → 文本/图片 → Embedding 模型 → 查询向量
↓
Milvus(按度量方式在索引中比对)
↓
返回 Top-K 最相似结果一次典型的 RAG 检索流程:
- 用户提问:"Milvus 支持哪些索引?"
- 通过 BGE 模型把问题转成 1024 维向量
- Milvus 在 Collection 中检索 Top-5 相似文档片段
- 把检索结果拼到 Prompt 中,喂给大模型
- 大模型基于上下文生成最终答案
七、写在最后
Milvus 作为生产级向量数据库的代表,其核心价值在于:
- 架构层面:解耦设计,支撑弹性扩展
- 算法层面:索引全家桶,覆盖各类场景
- 生态层面:与 RAG 工具链深度集成
对于刚入门 RAG 的开发者,建议的学习路径:
从 IVF_FLAT 起步 → 数据量上来切 HNSW → 真海量场景再考虑 SCANN / DISKANN
更深入的研究,推荐直接阅读官方文档: 🔗 https://milvus.io/docs/zh/
如果这篇文章对你有帮助,欢迎点赞、收藏、转发三连。